
|
|
郭少卿
Guo Shaoqing
中图分类号: G250.76
通讯作者:
收稿日期: 2017-11-5
修回日期: 2017-12-2
网络出版日期: 2018-01-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
展开
摘要
【目的】科技论文中数值指标的大小有多种描述形式, 本文旨在从不同形式的描述句中准确识别数值指标的实际取值。【方法】分析数值指标句中指标实体与数字实体间最小句法树路径, 采用远程监督学习数值指标句的句法特征及描述特征, 从领域候选句中识别数值指标句; 利用少量语义标注数据学习“大于”、“小于”、“等于”、“倍数” 4类取值关系模板, 通过模板识别数值指标句的取值关系类别, 依据不同取值关系模板对应的数值指标实际取值换算关系计算指标实际数值的大小。【结果】在气候变化领域和天文学领域开展实验, F值分别达到82.35%和77.55%, 识别效果达到同类研究平均水平之上。【局限】以单句为数据单元开展识别研究, 对于跨句间的指标取值问题未做考虑。【结论】本方法能够有效识别单句中数值指标的实际取值, 识别过程不需要大量人工标注语料, 迁移到其他领域时不做额外处理, 系统性能不会明显下降, 具有一定的实用性。
关键词:
Abstract
[Objective] This paper aims to identify the actual value of numerical indicators from the scientific literatures. [Methods] Firstly, we analyzed the Shortest-Path-Tree between the indicator and the digital entities. Then, we used by distant supervision to learn the syntactic and description characteristics of the numerical indicator sentence. Third, we created four types of relationship templates of “more than”, “less than”, “equal” and “times”. Finally, we obtained the real value of these indicators. [Results] We examined the proposed method in the fields of climate changes and astronomy. The F-values were 82.35% and 77.55%, which were above the average of related studies. [Limitations] We did not investigate the indicator real value across multiple sentences. [Conclusions] The proposed method could help us obtain the actual value of numerical indicators effectively.
Keywords:
科技论文中含有丰富的指标信息,它是量化研究者在某一研究领域取得进展的主要形式。数值指标是取值类型为数值型的指标, 取值由数字和计量单位两部分构成。从领域科技论文中识别数值指标的取值, 就是要从相应的描述句中发现并抽取指标实际对应的数值及单位信息。它能帮助研究者从量化的角度纵览所研究方向的实际进展, 从中发现重要研究线索及研究数据。
数值指标取值问题是数值抽取领域的重要研究内容。在已有研究中, 无论是单一指标数值抽取还是多指标数值抽取, 大多是将句子中出现的数值直接作为指标的实际取值, 没有考虑相对取值问题。如, 例句1 “Today’s temperature has risen by about 5 ℃ above yesterday’s value”, 温度指标的真实取值应为(yesterday’s value + 5) ℃, 若直接将5℃作为指标取值, 显然不符合句子的真实含义, 影响了指标取值识别的准确率。
针对这种数值指标实际取值问题, 本文利用远程监督学习指标实体与数值实体间的句法特征及描述特征识别数值指标句, 利用少量语义标注数据中学习“大于”、“小于”、“等于”、“倍数”这4类取值关系模板, 通过取值关系模板找出数值指标实际取值的换算关系, 最终计算或表示出指标实际数值的大小。
在数值抽取领域, 指标取值问题的研究常用规则或监督学习方法。Maiya等[1]根据不同单位类型归纳多套正则表达式, 识别带单位的数值短语; Santos等[2]利用领域本体构建规则识别生物领域的实验参数; 毋菲[3]利用决策树判断句法树中的节点是否为目标节点, 从而识别新闻语料中的事件论元值; Sarker[4]将词共现、词相似度、段落结构作为特征加入SVM对句子进行二分类, 识别描述实验规模的句子。该类研究具有成熟的方法体系, 较好的识别效果, 可有效获得需要的数值实体或句子, 但所用方法与具体应用高度关联, 缺乏泛化能力。
利用简单的语义信息, 以{指标, 数值}二元组形式表示指标取值关系是指标取值研究的另一种途径。Sarath等[5]利用CRF和正则表达式分别识别电子病例中医疗指标和数值, 利用SVM二分类判断两者是否具有取值关系, 获得医疗指标取值; Murata等[6]利用相似方法, 引入单位特征, 识别新闻语料中指标取值。模板方法在该类研究中被引入; 杨少华等[7]提出算法对html页面进行模板学习, 利用所得模板自动地从网页中识别指标取值; Madaan等[8]使用远程监督发现模板, 借助人工构建的外部知识库学习语料中模板, 获得取值。该类研究不再局限于一个具体目标, 而是为一类指标找出取值, 但实际效果大多取决于领域的大小、语料数量、质量等因素, 同时存在语义缺失问题。
当前不少研究开始尝试从数值指标句语义理解的角度识别指标的取值。吴胜等[9]利用词性、句法树等特征生成候选主体集, 用J-W距离打分得到取值主体; Lee等[10]统计指标和命名实体共现概率, 提出基于概率计算的打分方法获得指标主体; Davidov等[11]归纳模板在海量数据中识别单个主体的多个属性取值, 获得对应量词、系动词作为后续研究的基础; Chaganty等[12]利用RNN将指标取值映射到“解释短语库”中的短语, 生成句子对取值本身的大小进行解释。目前语义信息识别研究尚未形成系统性的方法体系, 不同研究在表达语义信息的方式上也存在差异。
与其他类型的句子相比, 数值指标句包含4个基本要素: 指标名称、数字、单位和谓词, 部分数值指标句中还含有主体等要素, 如图1所示。指标与数值间存在取值关系, 指标flow rate的取值为5/min。为了与数值抽取领域相关术语保持一致, 本文将识别过程中的指标名称作为指标实体, 数字和单位合称为数值实体。
科技论文中指标和数值间取值关系的表达方式复杂多样, 相近的表达方式可被概括为一种模式, 如“… (指标)is(值)…”、“…(值)of(指标)…”、“…(指标)equal(值)…”, 同一种模式的句法特征高度相似, 且在指标和数值间拥有相同的特征词。
根据指标数值句中数值和实际值的关系, 可将数值指标句取值关系分为两大类:
(1) 直接取值, 如: length is 5cm, 实际值等于句子中的数值, 将这类取值关系称为“等于”关系;
(2) 相对取值, 如: length is 5cm longer than the other, 句子中包含一个基准实体, 数值和基准实体间存在比较关系, 实际值可通过数值和基准实体按一定方式换算得到, 又可细分为“大于”、“小于”、“倍数”三类。存在相对取值的数值指标句中往往具有一些特定的关键字, 如: higher、above等, 称这类词为比较词, 数值实体附近的比较词及上下文词性特征有效地揭示了取值关系类型。取值关系共细分为4类, 相应实例如表1所示。
表1 取值关系类型及实例
| 取值关 系类型 | 实例 |
|---|---|
| 等于关系 | …annual precipitation measured in this study is 734mm… |
| 大于关系 | …temperature has risen by about 5 ℃ above yesterday… |
| 小于关系 | …CO2 concentration is 5% lower than the PM10 concentration… |
| 倍数关系 | …capacity of this bottle is 2/3 of the other one… |
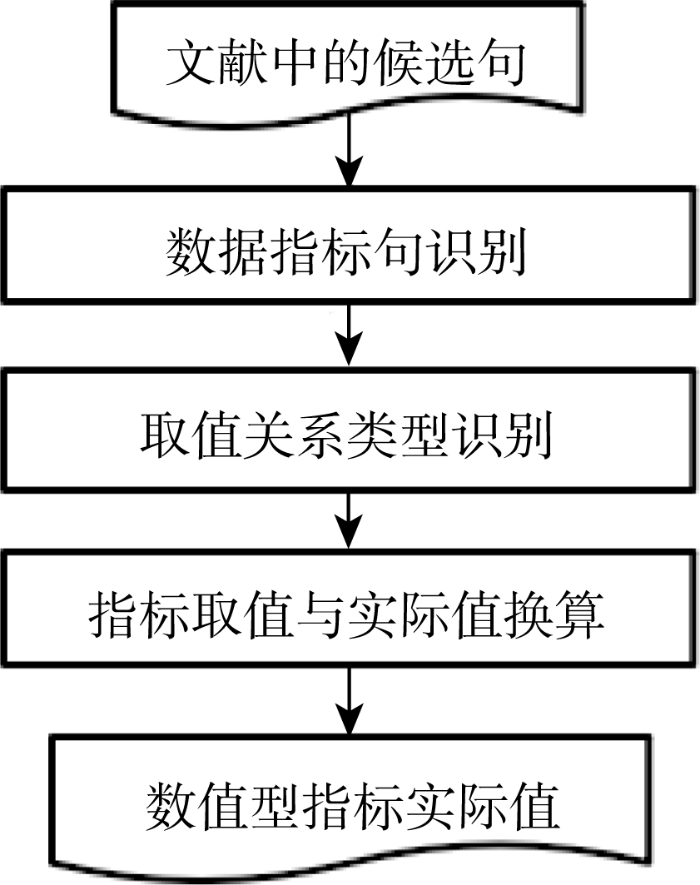
数值指标实际取值识别流程如图2所示。
主要包括数值指标句识别、取值关系类型识别和实际取值换算三部分内容。数值指标句识别主要解决从领域论文句子集中识别同时包含指标实体和取值实体的句子集; 取值关系类型识别主要是判断数值指标句中指标实体与数值实体间属于何种取值关系, 如直接取值或相对取值, 对于相对取值关系再做进一步细分, 如“大于关系”、“小于关系”、“倍数关系”等; 实际值换算则是根据取值关系类型选择相应换算关系计算出实际数据。
数值指标句识别的本质是发现候选句中的指标和数值是否具有取值关系, 利用句法树路径和对应特征
词将数值指标句的句法特征、描述特征表示成模板形式, 将候选句与学习得到的句法树路径模板进行匹配完成识别。
数值指标通常具有若干常用单位, 如: length和m、cm、km等; temperature和k、℃、℉等, 若候选句中的单位是指标的常用单位之一, 则该单位对应的数值和指标间极大可能存在取值关系, 利用该假设引入远程监督, 学习具有取值关系的句法树路径模板。远程监督[13]用于解决监督学习需要海量标注数据的问题, 其按照一定假设将外部知识库中实例映射到未标注数据中, 从而得到需要的训练数据。例如, 外部知识库中包含取值关系实例{指标: sea level pressure, 单位: hPa}, 则将未标注语料中所有同时包含指标“sea level pressure”单位“hPa”的句子看作具有取值关系的句子, 用于模板学习。
(1) 候选句的句法树路径模板生成
为生成句法树路径模板, 需要先对候选句中指标、数字、单位进行识别。指标由外部给定, 通过文本匹配, 得到指标实体; 数字特征明显, 通过正则表达式 (\\d((\\d?\\d?[, ]\\d{2,3}([, ]\\d{2,3})*|\\d*))(\\.(\\d[\\d\\s]*\\ d|\\d))?)匹配得到; 单位形式复杂, 传统正则表达式方法[1]工作量大, 识别范围有限, 利用单位本体, 从单位本体中获得各类基本单位, 结合AC自动机算法[14]进行单位识别, 可有效识别科技论文中复杂的单位, 如: lmin-1, mgμmol-1等, 单位和数字组成数值实体。
对候选句进行句法分析, 得到句法分析树。在指标、数字、单位所对应的节点中挑选最左节点和最右节点, 并得到两者的最近公共父节点, 以最左、最右节点和最近公共父节点为边界, 在句法分析树中截取子树, 得到最小句法树(SPT)[15]。最小句法树的外侧分支即为句法树路径, 将最小句法树包含的动词、介词、比较词作为特征词, 对应到句法树路径中, 得到句法树路径模板。
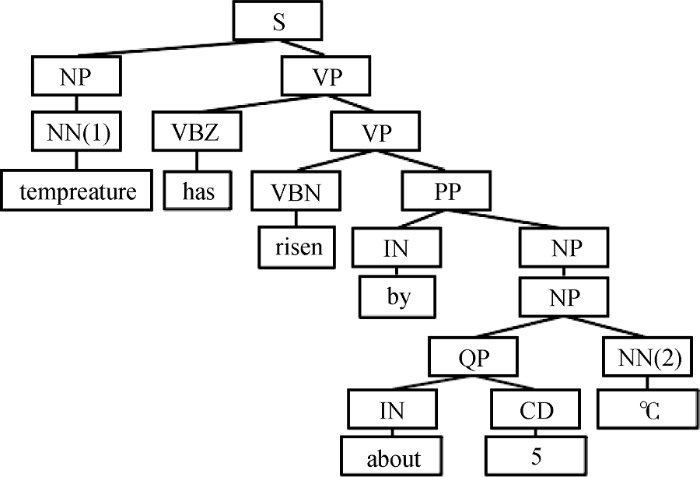
以例句1为例, 指标实体tempreature, 数字5, 单位℃, 最左节点为指标实体对应节点NN(1), 最右节点为单位对应节点NN(2), 两者最近公共父节点为S, 由此可得最小句法树如图3所示。句法树路径NP|VP|VP|PP|NP, 对应特征词has(VP)、risen(VP)、by(PP)、about(NP), 可由此得到NP|VP|VP|PP[by]|NP等4个模板。
(2) 远程监督学习句法树路径模板
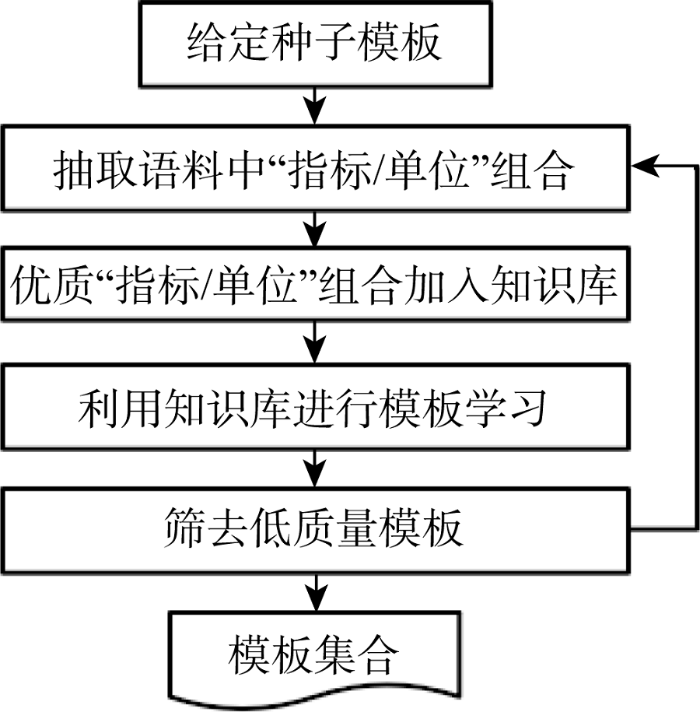
远程监督依赖外部知识库, 在指标取值任务中尚未找到可用知识库。本文利用人工归纳的种子模板初始化模板库, 抽取“指标/单位”构建知识库, 随后利用知识库中实例开始远程监督学习, 通过迭代抽取同时扩展知识库、模板库。外部知识库中实例形如{指标: I, 单位: U}, 具体流程如图4所示。
首先初始化模板库, 随后不断将优质“指标/单位”组合加入外部知识库, 优质模板加入模板库, 迭代至所有可学习语料均被学习完时终止。
①给定种子模板
分析语料, 归纳若干优质模板作为种子模板, 种子模板必须能有效识别数值指标句, 获得大量、优质的“指标/单位”组合, 避免迭代初期因有效“指标/单位”组合较少导致迭代终止。
②获得“指标/单位”组合
遍历语料中的句子, 利用已有模板进行匹配, 识别数值指标句, 取出句子中指标、单位, 组成“指标/单位”组合。
③优质“指标/单位”组合加入知识库
优质的“指标/单位”组合具有普遍性, 可用于发现大量正确模板。部分已有模板匹配得到的“指标/单位”组合质量较差, 主要原因为: 由错误的模板匹配所得; 文献作者自创、独有的指标单位组合。通过计算置信度, 给定最低置信度阈值, 可有效筛去低质量“指标/单位”组合, 如公式(1)所示。
$conf(I,U)=\frac{count(I\cap U)}{count(I)}$ (1)
其中, I代表指标, U代表单位, count(I)和count(I∩U)分别表示语料中指标I出现的次数和指标I、单位U同时出现的次数。将筛选后的“指标/单位”加入外部知识库, 对知识库进行扩展。第一次执行该步骤时, 是在对外部知识库进行初始化。
④模板的学习
从知识库中选取置信度最高且未学习的“指标/单位”组合, 获得语料中所有同时包含该指标和单位的句子, 将这些句子中指标和取值之间的句法树路径模板加入到模板库中。
⑤过滤低质量模板
错误的模板会导致数值指标句识别错误。由于远程监督所依赖的假设并不总是正确, 即无法保证所有同时包含给定“指标/单位”组合的句子一定存在取值关系, 因此迭代过程中可能会得到错误的模板。计算模板的支持度, 给定最低支持度阈值, 可有效筛去错误的模板, 提升模板库质量, 如公式(2)所示。
$\sup (T)=\frac{count(T)}{count(R)}$ (2)
其中, T代表单个模板, R代表该模板中的路径, count(T)指单个模板出现的次数, count(R)指所有得到的模板中路径为R的模板出现的次数(即同一路径不同特征词)。同时, 优质模板的出现频次往往较高, 筛去出现频次小于给定阈值的模板, 可有效避免错误模板。模板出现频次与训练语料大小相关, 因此不能直接给定模板出现频次最低阈值。优质模板的数量往往和模板总量呈正相关, 应给定一个比例, 从而计算出模板集合中应该保留的模板数。将模板集合中的模板依据出现频次排序, 过滤排序后超过应保留模板数的模板。
(3) 模板匹配识别“指标数值句”
若候选句的句法树路径模板存在于模板库中, 则认为候选句是数值指标句。同时, 利用规则方法判断指标和数值是否存在于同一子句中, 只有存在时才进行模板匹配, 可有效提升识别正确率。
取值关系类型识别的本质是判断指标和取值间的取值关系属于“大于”、“小于”、“等于”、“倍数”当中的哪一类, 实质上为比较关系识别[16], 利用“比较词”和词性标注序列将上下文词性特征表示成模板形式, 将数值指标句与取值关系类型模板匹配进行识别。
(1) 数值指标句取值关系类型模板生成
取值关系类型模板是带有“比较词”的词性标注序列, 需要通过指标、数值实体及数值实体对应的从句, 结合“比较词”得到。
在数值指标句的句法分析树中利用规则方法判断数值实体是否具有相关从句, 若有则获得从句的文本。对数值指标句进行词性标注, 以指标实体、数值实体、从句三者当中最左边的词为起点, 最右边的词为终点, 对词性标注序列进行截取。在截取后的序列中, 查找是否有“比较词”存在, 若不存在则模板为空, 若存在则取比较词前后N(N为窗口大小)个词性标注, 不足N个按最大值取, 组成取值关系类型模板。
以例句1为例, 指标实体temperature, 数值实体5℃, 数值对应从句above yesterday’s value, 最左为指标实体, 最右为从句中value, 截取得到词性标注序列如图5所示。设定N=3, 得到取值关系类型模板为IN|CD|NN|IN[above]|NN|POS|NN。
(2) 利用比较词和少量语义标注数据学习模板
取值关系类型模板的产生依赖于“比较词”, 针对取值关系类型识别制作“比较词”词典, 词典中包含词性、词组、单词三种“比较词”, 部分“比较词”如表2所示。
表2 部分“比较词”词典
| JJR(词性) | BRB(词性) | as…as(词组) | Of NN(词性+词组) |
|---|---|---|---|
| Above | Over | Below | Under |
| Twice | Thrice | Half | More |
| Before | Behind | Ahead | …… |
选取若干取值关系类型为“大于”、“小于”、“倍数”的数值指标句作为训练语料, 并对其取值关系类型进行标记, 利用“比较词”词典自动从语料中生成模板, 模板的取值类型为对应数值指标句人工标注的类型。
(3) 模板匹配发现取值关系类型
将数值指标句中带“比较词”的词性标注序列分别与“大于”、“小于”、“倍数”三类取值关系模板进行匹配, 若与其中某一类模板匹配成功即意味着数值指标句的取值关系为该类型, 若三套模板均不匹配, 则取值关系为“等于”。
基准实体和数值实体代入换算关系得到实际值。基准实体利用句法分析树查找得到, 一般找到句法分析树中数值所对应的从句节点, 取节点中深度最小的NP节点的文本, 即为基准实体, 如例句1中的“yesterday’s value”。
针对不同的取值关系, 指标取值与实际值之间具有不同的换算关系, 按取值关系和单位分类共归纳出6种换算关系。将数值实体与基准实体代入换算关系中, 即可换算得到指标真实取值, 换算关系如表3所示。
表3 换算关系
| 类型 | 取值关系 | 换算关系 |
|---|---|---|
| 大于类型 | %、times等倍数单位 | Baseline entity × ( 1 + value unit ) |
| 其他单位 | ( Baseline entity + value ) unit | |
| 小于类型 | %、times等倍数单位 | Baseline entity × ( 1 - value unit ) |
| 其他单位 | ( Baseline entity - value ) unit | |
| 倍数/分数类型 | 所有单位 | Baseline entity × value [%] |
| 等于类型 | 所有单位 | Value unit |
以气候变化领域和天文学领域科技论文为实验数据, 下载1970年1月至2017年1月发表于气候变化领域Environmental Research Letters等78本SCI期刊的全文数据, 共31 430篇; 下载2007年1月年至2017年1月发表于天文学领域Advances in Space Research期刊的全文数据共5 433篇。以EPA (U.S. Environmental Protection Agency)发布的气候变化指标[17]为指导, 选取128个高频指标。在气候变化领域全文数据中挑选包含这些指标的数值句共计144 519句, 作为数值指标句识别的训练语料, 同时人工标注178句包含各类比较关系的句子作为“取值关系类型识别”的训练数据。人工标注400句气候变化领域数值指标句, 共有数值指标取值597个, 作为测试集, 标注300句天文学领域数值指标句, 共有数值指标取值380个, 作为跨领域的测试集。测试集中包含指标实际值、单位、取值类型, 只有当识别结果与三者均相同时, 才判定实验结果正确。词性标注及句法分析使用Stanford CoreNLP[18]完成。
给定种子模板NN|NP|PP[of]|NP|CD、NN|NP|VP [is]|NP|CD, 设定“指标/单位”置信度阈值为30%, 有效模板比例为35%, 模板支持度阈值为20%, 学习句法树路径模板, 给定人工标注语料, 设定词性标注序列窗口大小为3, 学习取值关系类型模板。
利用气候变化领域科技文献为训练数据进行实验。数值指标句识别任务中, 经远程监督学习, 得到外部知识库与句法树路径模板库, 如表4和表5所示。
表4 部分“指标/单位”组合
| 指标 | 单位 | 指标 | 单位 |
|---|---|---|---|
| Mass median diameter | mm | Survival rate | % |
| Vechicle speed | kmh-1 | Total weight | kg |
| Scattering angle | ° | …… | |
表5 部分句法树路径模板
| 模板 | 频次 | 支持度 | 模板 | 频次 | 支持度 |
|---|---|---|---|---|---|
| NN|NP|PP[of]|NP|CD | 1591 | 65.61% | NN|NP|VP[be]|PP|NP|CD | 766 | 53.75% |
| NN|NP|PP[between]|NP|CD | 228 | 9.41% | NN|NP|VP|PP[from]|NP|CD | 510 | 35.79% |
| … | … | … | … | … | … |
学习得到的模型在气候变化领域测试集上的测试结果正确率为78.15%, 召回率为81.21%, F值为79.11%; 在天文学领域测试集上的测试结果正确率为79.06%, 召回率为72.18%, F值为75.46%。实验结果显示虽然数值指标实际值识别的召回率较好, 但正确率较低。
通过对实验数据及结果进行分析, 发现主要是数值指标句识别中, 当一个句子存在多个指标和对应取值时, 容易将一个指标的取值误判为另一个指标的取值, 导致正确率下降, 如: length is 5cm, distance is 20cm, 将20cm误识别为length的取值。其根本原因是句法树路径模板只关注指标和取值间能揭示取值关系的特征词, 如: is、of等, 而不关注其他词, 无法判断指标和取值是否存在于同一子句中。故加入规则方法进行子句判断, 仅当指标和数值存在于同一子句中, 认为其可能含有取值关系。同时, 有少量数值指标句中指标和取值存在于不同子句中, 如: length has changed, which is increased to 5cm, 受子句判断影响, 无法被召回。通过加入人工归纳的常用、优质模板, 并为这些模板赋予高优先级, 保证召回率。在气候变化领域测试集上的优化结果如表6所示。
表6 优化结果分析
| 流程 | 正确率 | 召回率 | F值 |
|---|---|---|---|
| (1) 原识别流程 | 78.15% | 81.21% | 79.11% |
| (2) 将子句判断加入(1)中 | 85.31% | 75.62% | 80.18% |
| (3) 将常用模板加入 (1)(2)中 | 84.01% | 80.76% | 82.35% |
使用优化后的模型再次进行实验。最终在气候变化领域测试集上正确率为84.01%, 召回率为80.76%, F值为82.35%; 在天文学领域测试集上正确率为84.24%, 召回率为72.01%, F值为77.55%, 整体识别效果较好。对上述实验过程及结果进行总结, 得出以下结论。
(1) 利用远程监督学习和监督学习相结合的方式, 有效地获得了数值指标句中取值关系的相关特征, 从而识别出指标的字面取值, 计算或表示出实际取值。
(2) 子句判断可有效弥补句法树路径模板无法判断取值和指标是否同时存在与一个子句中的缺陷, 从而为指标找出正确的取值, 提升正确率。
(3) 由子句判断带来的召回率下降, 可通过人工加入常用、优质模板的方式避免, 提升召回率。
(4) 当前实验结果中存在的主要错误是将指标的对应条件识别为取值造成, 因指标条件与取值表达方式往往相同, 仅使用句法树路径模板无法进行分辨。可通过进一步研究, 找出识别条件与取值的特征, 提高识别效果。
(5) 由天文学领域测试结果可见, 迁移到其他领域进行识别时, 正确率保持原有水平, 召回率受到领域影响下降, 总体效果较好。召回率下降主要是受领域内独有的单位和取值关系表达方式影响所致, 可通过增量学习以提升召回率。
综上所述, 本文可在人工标注数据较少的条件下, 有效地识别科技文献中数值的实际取值, 且在领域迁移时不需要进行额外操作, 系统性能不会明显下降, 为工程应用提供了可行性。根据文献[19]所述, 本文对数值信息的识别效果达到同类研究的平均水平之上。
本文针对领域科技论文中数值指标的实际取值问题开展研究, 从指标与数值间的语义关系识别入手, 通过远程监督学习数值指标句的句法特征及描述特征, 从领域候选句中识别数值指标句; 利用少量语义标注数据学习“大于”、“小于”、“等于”、“倍数”4类取值关系模板, 通过模板识别数值指标句的取值关系类别, 利用不同模板实际取值换算关系计算实际数值大小。从气候变化领域和天文学领域的实验结果来看, 该方法能够有效识别单句中数值指标的实际取值, 识别过程不需要大量人工标注语料, 迁移到其他领域时不做额外处理系统性能不会明显下降, 具有一定的实用性。但目前研究仍局限于单句中, 对于跨句中的指标取值问题未做涉及。在后续研究中将进一步优化识别效果, 同时考虑跨句问题, 使识别性能达到工程应用的水平。
郭少卿: 设计并实施技术方案和技术路线, 采集、清洗数据, 实验的分析和验证, 论文起草及最终版本修订;
乐小虬: 提出论文研究方向和主要研究思路, 优化研究方案及技术路线的设计, 论文修改。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: lexq@mail.las.ac.cn。
[1] 郭少卿, 乐小虬. Climate_astronomy_result.txt. 气候变化领域和天文学领域测试集实验结果.
| [1] |
Mining Measured Information from Text [C]// |
| [2] |
Applying a Text Mining Framework to the Extraction of Numerical Parameters from Scientific Literature in the Biotechnology Domain [J].https://doi.org/10.14201/ADCAIJ20121118 URL [本文引用: 1] 摘要
divScientific publications are the main vehicle to disseminate information in the field of biotechnology for wastewater treatment. Indeed, the new research paradigms and the application of high-throughput technologies have increased the rate of publication considerably. The problem is that manual curation becomes harder, prone-to-errors and time-consuming, leading to a probable loss of information and inefficient knowledge acquisition. As a result, research outputs are hardly reaching engineers, hampering the calibration of mathematical models used to optimize the stability and performance of biotechnological systems. In this context, we have developed a data curation workflow, based on text mining techniques, to extract numerical parameters from scientific literature, and applied it to the biotechnology domain. A workflow was built to process wastewater-related articles with the main goal of identifying physico-chemical parameters mentioned in the text. This work describes the implementation of the workflow, identifies achievements and current limitations in the overall process, and presents the results obtained for a corpus of 50 full-text documents./div
|
| [3] |
数值信息的抽取方法研究 [D].Research on Value Extraction from Chinese Text [D]. |
| [4] |
Automated Extraction of Number of Subjects in Randomised Controlled Trials [L]. |
| [5] |
Numerical Atrribute Extraction from Clinical Texts [L]. |
| [6] |
Extraction and Visualization of Numerical and Named Entity Information from a Large Number of Documents [C]// |
| [7] |
针对模板生成网页的一种数据自动抽取方法 [J].https://doi.org/10.3724/SP.J.1001.2008.00209 URL [本文引用: 1] 摘要
当前,Web上的很多网页是动态生成的,网站根据请求从后台数据库中选取数据并嵌入到通用的模板中,例如电子商务网站的商品描述网页.研究如何从这类由模板生成的网页中检测出其背后的模板,并将嵌入的数据(例如商品名称、价格等等)自动地抽取出来.给出了模板检测问题的形式化描述,并深入分析模板产生网页的结构特征.提出了一种新颖的模板检测方法,并利用检测出的模板自动地从实例网页中抽取数据.与其他已有方法相比,该方法能够适用于"列表页面"和"详细页面"两种类型的网页.在两个第三方的测试集上进行了实验,结果表明,该方法具有很高的抽取准确率.
Yanbo. Automatic Data Extraction from Template- Generated Web Pages [J].https://doi.org/10.3724/SP.J.1001.2008.00209 URL [本文引用: 1] 摘要
当前,Web上的很多网页是动态生成的,网站根据请求从后台数据库中选取数据并嵌入到通用的模板中,例如电子商务网站的商品描述网页.研究如何从这类由模板生成的网页中检测出其背后的模板,并将嵌入的数据(例如商品名称、价格等等)自动地抽取出来.给出了模板检测问题的形式化描述,并深入分析模板产生网页的结构特征.提出了一种新颖的模板检测方法,并利用检测出的模板自动地从实例网页中抽取数据.与其他已有方法相比,该方法能够适用于"列表页面"和"详细页面"两种类型的网页.在两个第三方的测试集上进行了实验,结果表明,该方法具有很高的抽取准确率.
|
| [8] |
Numerical Relation Extraction with Minimal Supervision [C]// |
| [9] |
中文文本中实体数值型关系无监督抽取方法 [J].https://doi.org/10.14188/j.1671-8836.2016.06.011 URL [本文引用: 1] 摘要
中文实体间的数值型关系抽取有着广泛的应用前景,目前常用的实体关系抽取一般采用有监督抽取方法,且多用于短文本和简单句,并不适合处理海量复杂句.针对来自于网络的大量复杂文本,本文提出了一种中文实体数值型关系的无监督抽取方法.在中文分词、词性标注等自然语言处理结果的基础上,首先经过句式分析并采用选择树算法构建候选集,接着利用Jaro-Winkler距离进行候选集筛选,最后抽取得到数值型三元组关系.本文在钢铁、船舶、房地产3个行业的数据上进行了实验,结果表明,该方法抽取中文实体数值型关系是有效的.
Unsupervised Extraction of Attribute-Value Entity Relation from Chinese Texts [J].https://doi.org/10.14188/j.1671-8836.2016.06.011 URL [本文引用: 1] 摘要
中文实体间的数值型关系抽取有着广泛的应用前景,目前常用的实体关系抽取一般采用有监督抽取方法,且多用于短文本和简单句,并不适合处理海量复杂句.针对来自于网络的大量复杂文本,本文提出了一种中文实体数值型关系的无监督抽取方法.在中文分词、词性标注等自然语言处理结果的基础上,首先经过句式分析并采用选择树算法构建候选集,接着利用Jaro-Winkler距离进行候选集筛选,最后抽取得到数值型三元组关系.本文在钢铁、船舶、房地产3个行业的数据上进行了实验,结果表明,该方法抽取中文实体数值型关系是有效的.
|
| [10] |
Attribute Extraction and Scoring: A Probabilistic Approach [C]// |
| [11] |
Extraction and Approximation of Numerical Attributes from the Web [C]// |
| [12] |
How Much is 131 Million Dollars? Putting Numbers in Perspective with Compositional Descriptions [C] // |
| [13] |
Distant Supervision for Relation Extraction Without Labeled Data [C]// |
| [14] |
Efficient String Matching: An Aid to Bibliographic Search [J].https://doi.org/10.1145/360825.360855 URL [本文引用: 1] |
| [15] |
Exploring Syntactic Features for Relation Extraction Using a Convolution Tree Kernel [C]// |
| [16] |
Identifying Comparative Sentences in Text Documents [C]// |
| [17] |
|
| [18] |
The Stanford CoreNLP Natural Language Processing Toolkit [C]// |
| [19] |
数值信息抽取研究进展综述 [J].Numerical Information Extraction: A Review of Research [J]. |

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}