
|
|
李伟卿
Li Weiqing
中图分类号: TP393 G35
通讯作者:
收稿日期: 2017-07-21
修回日期: 2017-10-28
网络出版日期: 2018-01-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】基于大规模评论数据, 提出一种产品特征词典的构建方法, 以提升识别产品特征的查准率和查全率。【方法】在人工标注的基础上, 基于同义词林的扩展, 以及大规模评论文本的词向量训练, 计算词语的语义相似度和相关性, 进行特征的识别与归并, 进而形成产品特征词典。【结果】本文选取手机、相机、图书三类产品的评论数据进行实验, 平均查准率和平均查全率分别为0.774和0.855。结果显示, 该方法具有一定的普适性。【局限】标注及验证需大量人工参与, 自动化程度不够; 没有考虑评论中的隐含特征。【结论】通过与已有研究比较, 验证了本文提出方法的有效性, 特别在查全率上具有显著的提升。
关键词:
Abstract
[Objective] This paper proposes a method to build product feature dictionary based on large scale review data, aiming to improve its precision and recall. [Methods] First, we constructed a seed dictionary by manually labeling and extending the synonym forest. Then we trained the word vector with large scale product reviews to calculate the semantic similarity and relevance of words. Finally, we identified and categorized the product features to construct the dictionary. [Results] We chose product reviews on mobile-phones, cameras and books to examine the proposed model, which had average precision and recall of 0.774 and 0.855. [Limitations] The proposed method required a great deal of human participation at the marking and verification stages, while it did not consider the implied features of product reviews. [Conclusions] The proposed method could effectively build feature dictionary with better recall.
Keywords:
海量的网络评论信息蕴含用户的观点、态度和情感, 它们大多是非结构化的文本信息[1]。这些蕴含情感信息的文本在个性化推荐、情感分析、舆情监控、观点挖掘等许多方面都有应用价值[2]。从这些文本信息中挖掘用户所关注、喜爱、挑剔的产品特征, 不仅可以在产品推荐上提升效果, 而且可以帮助生产者与销售商改进产品缺陷, 提升服务质量, 以增强竞争力[3]。因而, 对网络评论的情感分析(即观点挖掘)便成为研究热点, 而非结构化文本的观点挖掘, 主要涉及产品特征的提取, 情感倾向的分析, 以及产品比较信息的挖掘[4]。其中, 产品特征的提取作为观点挖掘的前提与基础工作, 其准确性和查全率的保障非常重要[5]。
近年来, 国内外学者对于产品特征-观点对的分析挖掘取得了长足的进展; 在方法与实践上都有不少的成果。如Liu等[6]率先提出应用关联规则的方法, 实验中的查全率和查准率都有不错表现; Popescu等[7]利用konwitall系统, 根据有监督的学习方法建立一个产品特征集合, 基于相关领域的训练样本集计算词语的点互信息(PMI), 进行贝叶斯分类以提取产品特征; Somprasertsri等[8]基于句法信息和语义信息, 提出一种利用句法间的依存关系进行特征-观点对的提取; 吴苏红等[9]则基于中文句子的依存句法, 设计特征的识别算法和特征观点对的抽取算法。
这些方法大多都是基于小规模的网络用户评论数据集进行实验, 并取得较好的实验效果, 但是小规模的数据集未必能覆盖海量网络数据的特征, 本文试图基于大体量的评论语料, 寻求更为准确、查全率更高的特征抽取方法, 并构建相关产品的特征词典。
史伟等[5]认为已有的特征提取方法大多基于统计学理论, 其基本思路是根据预定义的规则统计特定领域内名词出现的频率以识别显式产品特征。孟园等[10]认为产品特征及观点的抽取方法主要分为监督学习方法和非监督学习方法。郗亚辉等[11]将中英文产品特征抽取的方法归结为5类: 人工定义的方法、人工定义特征的表达模式以筛选产品特征的方法、抽取名词与名词短语的方法、学习产品特征的表达模式抽取特征的方法、利用分类算法抽取产品特征的方法。
人工定义的方法, 可以很精确地识别出产品特征, 但是必定繁琐耗时, 而且很难将所有的产品特征挖掘出来, 其查全率比较低, 不适合如今的海量数据环境。因此, 很多研究者抽取产品特征时, 会基于一定的评论语料, 以人工定义的产品特征, 或者人工定义的特征-观点表达式作为先验, 结合相应的统计、机器学习算法进行训练、扩展、分类以获得更为准确、全面的产品特征。本文基于文献[11]的总结, 并结合对现有文献的归纳, 在特征挖掘算法层面, 将现有的产品特征挖掘的算法归结为三类:
(1) 基于关联规则的分类方法提取产品特征属性;
(2) 基于通用知识库和语料库进行特征提取与归并的监督或者半监督方法;
(3) 基于依存句法的特征-观点对的提取与识别。
基于关联规则的分类方法提取特征, 需要针对特定的语言特点和风格特征, 但大体上都分为以下步骤: 评论语料的分词以及词性标注、创建关联规则事务文件找到频繁项集、邻近规则剪枝及独立支持度剪枝、特征子集的过滤与补充。
如Liu等[6]首先标注所有评论训练集中的词性, 抽取频繁项以提取英文评论中的产品特征并将名词和名词短语组成事务文件; 利用关联规则挖掘算法获取产品特征; 利用表达模式进一步抽取未标注的产品特征, 其平均查全率达到80%, 平均查准率达到72%。而Aravindan 等[12]采用近邻规则和独立支持度规则对Liu等[6]的方法进行过滤改进。李实等[13]则探索了在中文领域的基于关联规则分类的产品特征挖掘算法, 对手机、数码相机、图书等5种产品进行特征挖掘, 其平均查全率为77.8%, 而平均查准率只有63.6%。可以看出这些方法在中英文领域都具有一定的有效性, 但是还有不小的提升空间。
知识库和语料库的差别在于: 知识库主要提供词与词之间的关系, 而语料库反映的是词语在语料中的关系, 如位置信息、共现信息、情感信息。此类方法一般采用人工定义部分特征项, 借助通用知识库(如WordNet、HowNet)进行特征的识别与归并。其中大部分方法都运用两个理论方法: 点互信息(Pointwise Mutual Information, PMI)理论和Bootstrapping理论。点互信息理论是计算两个词语同时出现的概率, 以计算词语之间的相关性, 一般用来衡量两个词间的独立性, 但是PMI仅能用来判断两个词的共现程度, 不足以判断一个词的极性[14]。Bootstrapping是一种被广泛用于知识获取的机器学习技术, 它是一种循序渐进的学习算法, 只需要很小数量的种子, 以此为基础, 通过循环迭代, 把种子进行有效的扩充, 最终达到需要的数据规模[15]。
如文献[8]利用WordNet知识库中的词汇层次关系和词态信息识别主题术语的类别, 并利用Web PMI技术计算产品候选特征和产品类型之间的联系对候选特征进行评估, 但是由于通用知识库的局限性, 这种解决方案不能有效地识别领域相关词汇, 比如缩写词、专有名词、网络新词。针对领域词汇的特点, Cheng[16]研究基于本体的主题抽取方法, 采用半自动的方法基于一些现存的本体资源, 构造应用于汽车领域的本体, 将基于规则的命名实体识别技术和信息抽取引擎结合起来, 识别被评价的汽车领域主题词, 提高特征识别的查全率。Wang等[15]则是标注了少量的评论语料库用于构建一个产品特征词和观点词的朴素贝叶斯分类器, 将分类器应用于未标注的评论语料以获取频率最高的几个产品特征词和观点词, 并将其加入初始的种子集, 通过Bootstrapping循环迭代处理以获取所有评论语料中的产品特征和观点。祖李军等[17]提出一种PMI-Bootstrapping算法, 并结合语言规则实现中文网络评论的产品特征抽取, 利用语言规则产生候选特征集, 计算每个候选特征与种子集的加权平均互信息, 将满足阈值的候选特征添加到种子集中, 如此循环迭代, 直到种子集合收敛。
依存句法分析是对自然语言进行自动分析, 以构建句子对应依存树的一种方法, 而特征词和观点词之间具有依存关系, 特征-观点对表现为特征以及观点词语之间的二元对。特征-观点对的句法分析又可以称为识别特征-观点对的表达模式[18]。
Xia等[19]标注了中文产品评论训练集中的词性、观点词、修饰词等元素, 利用这些元素学习得到频繁的产品特征和观点词的表达模式, 再利用这些搭配模式在未标注评论中抽取产品特征以及相应观点。Somprasertsri等[8]标注了评论训练集中的产品特征之后, 基于特征词在句子中的句法信息和语义信息, 构造了一个极大熵的分类器, 抽取所有的名词和形容词作为候选产品特征和观点词, 利用极大熵分类器判断这些名词是否为产品特征。而吴苏红等[9]基于组块的定义, 结合词语之间的依存结构, 定义了三种类型的组块: 名词组块、动词组块和形容词组块, 再利用词与词之间的依存关系和相关词性, 建立由词语构成组块的规则, 基于这些规则获取评论语料中的组块, 识别组块中的候选特征, 并对山西旅游景点评论语料进行提取, 取得了不错的效果, 但是仍存在一些特征-观点对无法识别。
另外也有研究将几种方法相结合以获得更好的特征抽取效果, 如黄永文[20]定义一些常见的产品特征和观点词, 基于这些产品特征和观点词的依存句法关系提取特征-观点对的表达模式, 并采用Bootstrapping方法迭代抽取新的特征词及观点词。陈炯等[21]则是采用词法分析、句法分析、同义词林等多项技术和资源, 挖掘真实语料中蕴藏的语言知识, 提出一种基于模板的产品特征识别方法。孟园等[10]针对中文在线评论产品特征与观点抽取问题, 在改进 HITS 算法基础上, 综合考虑候选特征观点词的关联关系和语义关系构建置信度排序模型, 提取并过滤特征观点词。
近年来, 有不少研究者结合非技术层面的方法对产品特征进行挖掘, 以获得更好的效果, 如Xia[22]等采用数据扩充(Data Expantion)技术对训练数据进行扩展, 采用双向情感分析的方法, 考虑不同极性两方面的评论, 通过情感词的扩充寻找特征, 针对亚马逊的客户评论进行实验, 查准率达到81%。Liu 等[23]采用PMI-IR的方法提取Tweets的特征, 训练多领域Twitter的输入作为分类器, 完成对特定领域的Tweets主题情感分类, 平均查准率为55%, 召回率52%, 还有很大的提升空间。Hai等[24]基于中文的依存句法关系, 通过对不同的两个领域的语料进行统计分析(一个领域内的语料, 一个非相关语料), 利用其观点特征差异, 挖掘手机产品的特征, 平均查准率为0.65, 召回率为0.61, 在效果的表现上还有待提高。
从实验结果上看, 这些方法在产品特征提取的效果上都有不错的表现, 但大多是在较小数据集上进行实验得到的结果。如文献[9,13,21]针对每种产品分别采用100条、150条、681条评论数据进行特征提取的实验, 一方面考虑便于用人工的方法对实验效果进行准确的判断; 另一方面由于大体量的数据在计算上不适合使用这些方法。例如文献[13]中基于关联规则的特征挖掘, 在频繁项的提取与归纳过程中需要大量的统计、支持度、置信度计算; 文献[21]中的基于依存句法的特征挖掘算法, 其模式的定义、构建与拓展会占用很大的空间, 且在模式匹配与特征识别的过程中需要多次循环, 时间复杂度和空间复杂度上都很难运用大规模的数据进行实验。
如今大规模的网络用户评论数据为更精准的观点挖掘提供了条件。因此, 本文试图基于大体量的评论语料, 寻求更为准确、查全率更高的特征抽取方法, 并基于大规模的语料构建产品特征词典。本文的研究思路如下:
(1) 根据小规模的语料库人工标注各类产品的特征词;
(2) 基于同义词林对这些特征词进行语义相似度的计算, 进行特征的归并与特征种子词的扩展;
(3) 基于Word2Vec技术对产品评论信息的大规模语料库进行训练, 得到候选特征词的词向量;
(4) 循环迭代计算候选特征词与各种子词之间的语义相似度及相关度, 将相似度或者相关度达到0.8以上的词语加入到该类特征词库中, 循环迭代计算, 直至种子词库收敛, 得到最终的产品特征词典。
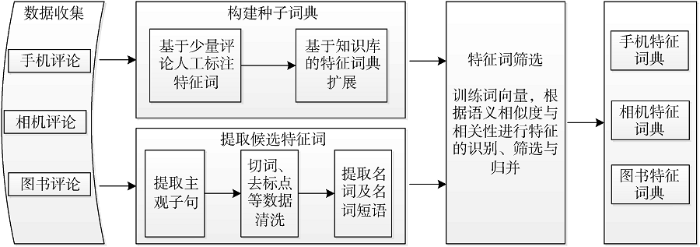
Asghar等[25]通过对60多篇相关文献的整理研究, 将特征提取的步骤总结为: 数据预处理、特征识别与选择、特征分类、特征词的去重与清洗。基于此, 并结合中文语言的特性, 本文提出基于同义词林与词向量的产品特征提取及词典构建方法, 如图1所示。
本文采用基于同义词林的方法进行特征种子词扩展, 是因为同义词林中的词语编码结构良好地体现了词语之间的语义层次关系; 而在特征词筛选归并时选用Word2Vec工具, 是因为其特征向量的方法将实例关系表示成高维特征空间中的一个向量, 其特征包括词汇、组块、句法和语义各种信息[26]。融合两种工具即可结合基于依存句法的方法和基于知识库及语料库的方法对特征词进行识别和筛选。
在文献[13, 21]中, 都是选取“手机”、“数码相机”、“mp3”、“图书(杜拉拉升职记)”的产品评论作为实验数据, 进行产品特征的识别提取。为了便于进行比较验证, 本文也拟选用这些产品的网络评论进行实验。考虑到“mp3”已是过时产品, 用户量较小, 评论数据也较少, 最终选用“手机”、“数码相机”、“图书”三类产品的网络评论数据进行实验。针对这三类产品, 从电商网站各爬取30万条评论数据, 每一条评论数据中包括产品信息和用户信息、评分信息、评论文本等内容。
产品的特征主要有两个来源: 产品的参数说明和产品评论文本。通过抽取产品说明中的相关信息, 可以获取有关产品的基础特征。而从评论文本中抽取的产品特征可扩充本体中的同义词集[27]。
本文通过每类产品的说明得到相关的基础特征, 针对每样产品各选取100条评论数据, 人工提取这100条评论中所提到的该种产品特征, 进行标注、归并与分类, 建立特征种子集合。
而图书比较特殊, 因为它的参数说明中没有相关的特征属性介绍, 只有出版社、语种、重量、尺寸等客观信息, 其特征属性只能通过评论数据进行标注获得。标注方法依据文献[28]的研究成果, 将图书的属性分为7类进行标注, 人工标注的图书的特征集合如表1所示。
表1 人工标注的图书特征集合
| 属性 | 举例 |
|---|---|
| 内容 | 内容 思想 思维 观念 理论 意思 |
| 结构和语言 | 结构 构造 构思 布局 组织 条理 语言 言辞 语句 讲话 说话 叙述 |
| 实用性 | 实用性 实用 应用 有用 用处 |
| 趣味性 | 趣味 兴趣 乐趣 |
| 专业性 | 深度 难度 难题 难点 难处 |
| 价格 | 价钱 价位 价值 |
| 质量 | 包装 封面 印刷 封皮 纸张 装订 质量 品质 质地 包裹 封装 封皮 书皮 书面 |
根据人工标注的种子词以及哈工大同义词林①(①http://ir.hit.edu.cn/demo/ltp/Sharing_Plan.htm.)对产品特征词进行扩展。同义词林是一个通用的语义知识库, 不仅包括一个词语的同义词, 也包含它的相关词。这里根据同义词林寻找与种子词库中的特征词语义相似度高的词汇加入到特征种子词库中, 采用田久乐等[29]提出一种基于同义词林的词语相似度的计算方法, 将与种子词语义相似度超过0.8的词语提取作为候选词。
候选词相似度计算完成后, 会发现基于同义词林提取的与种子词相似度高的词汇, 很大一部分是无法代表产品的属性与特征, 需要处理与剔除。例如“屏幕”这个属性, 同义词林中与其相似度高的有“幕、幕布、帷幕、银幕、天幕、荧幕、荧屏、触摸屏、宽荧幕、字幕、战幕、显示屏”, 显然对于手机这一产品, 只有“触摸屏”和“显示屏”可作为属性特征, 而对于电脑, 只有“显示屏”可作为其属性特征。所以根据相似度提取完同义词林中的候选词特征后, 需剔除无法作为产品特征而又与种子词相似度较高的词语。
由于本文方法是基于海量的评论语料提取产品特征, 所以需要尽量去除数据中的噪音, 这里首先剔除评论中的客观子句。一般评论都是由主观子句和客观子句组成, 主观子句主要描述评论者对事物的看法, 包含有褒贬意义成分的语句; 而客观句一般是对事实的陈述, 不包括观点的表达, 对于分析评论的情感倾向毫无帮助, 例如“手机昨天收到的, 外形跟想象的一样漂亮, 但是操作感觉有点难”, 这条评论一共有三个子句, 第一句就是客观子句, 不含任何情感, 第二、三个句子则是主观子句, 包含观点的表述, 并且表述的对象分别是“外形”和“操作”这两个特征。
首先需要对评论语料进行分句处理, 用户评论的长度一般比较简短, 而且很多用户都用空格进行分割, 本文依据标点和空格对评论进行分句, 采用文献[30]中的方法, 分析出子句类型, 保留主观子句。
对保留的主观子句进行分词, 本文采用Python所带的中文分词组件Jieba①(①https://github.com/fxsjy/jieba/tree/jieba3k.)完成评论语料的分词。Jieba支持三种分词模式: 精确模式、全模式和搜索引擎模式。精确模式试图将句子切分成准确的中文词语, 而全模式试图把句子中所有可以成词的词语都扫描出来。为了提高实验的查准率, 选用精确模式进行分词。
对分词后的评论语料进行词性标注。自1960年以来, 词性标注技术在自然语言处理领域就受到广泛的关注与应用, 而在产品特征提取的过程中主要关注的是名词及名词短语[31]。这里采用文献[13]的中文基本名词短语提取模型提取基本名词以及名词短语。统计提取出的名词及名词短语中的频繁项, 并去掉其中的单字名词。中文的一个单字可以标注为名词, 这是中文特有的情况, 但是从中文评论中产品特征的人工标注结果可以看出, 基本没有单字名词作为属性特征; 去掉表示产品型号的名词, 一般为字母加数字如“mate9”、“Iphone7”等, 去掉通用名词如“机子”、“手机”、“相机”、“机器”等; 去掉品牌信息名词如“苹果”、“华为”、“索尼”等。将经过以上处理的名词短语集合作为候选特征集。
特征分类是将表示相同特征概念的特征词归为一个特征类, 对于情感分析具有至关重要的作用[32]。Asghar等[25]将英文领域的特征选择及归并方法分为4种: 基于自然语言处理、基于启发式算法、基于统计学原理、基于聚类与混合的算法。而国内也有学者使用词语语义相似度计算的方法对特征进行选择与归并, 但应用在特定产品的特征分类时, 准确度还不够。例如很多学者直接用基于知网的WordSimilarity 计算词语语义相似度的方法, 对产品特征词进行分类, 其效果并不好, 例如“系统”和“操作系统”的相似度只有0.09, 而“屏幕”和“电池”的相似度有0.89 [33]。因而本文结合通用知识库以及Word2Vec②(②https: / /code.Google.com /p /word2vec/)的词向量训练, 以提高特征发现与归并的查准率。
随着神经网络和机器学习的发展, 词向量的概念在自然语言处理领域流行起来, 杨阳等[34]提出一种基于Word2Vec训练词向量以发现网络情感新词的方法, 使用大连理工情感词典本体作为种子词, 训练语料库的词向量, 计算其与种子词的余弦相似度, 以判别网络新词的情感倾向。
Word2Vec是Google公司在2013年开放的一款用于训练词向量的软件工具, 它可以根据给定的语料库, 通过优化后的训练模型快速有效地将一个词语的意义表达成向量形式, 词向量的每一维都代表一定的语义或者语法特征, 其思想就是将词语的不同句法和语义特征分布到向量的每一个维度去表示[34]。
运用Word2Vec工具将预处理后的名词及名词短语集合训练成词向量。将各产品的语料进行切词后, 作为输入文件并指定合适的训练参数, 对其进行词向量训练, 这里采用Mikolov等[35]提出的Skip-gram模型, 训练完后, 采用余弦相似度计算方法, 使用人工标注的特征词作为种子词, 计算候选种子词库中的名词短语与各种子词之间的余弦相似度, 将相似度大于0.8的词语加入到种子词库中。
本文采用自然语言处理领域普遍使用的性能评估指标(查准率、查全率)对所得到的产品特征词典进行评估。查准率描述的是本文采用这种方法挖掘出的产品属性数有多少是真正的产品属性; 查全率描述的是本文方法挖掘出的真实的产品属性与未挖掘出的产品属性的一个比值, 查准率和查全率的计算分别如公式 (1)和公式(2)所示。
$P=\frac{A}{A+B}$ (1)
$C=\frac{A}{A+C}$ (2)
其中, A表示运用本文方法, 采用训练数据挖掘出的真实产品属性, A+B表示本文方法挖掘出的所有产品属性; C为采用测试数据得到的特征词语集, 找出其中不在A中的名词及名词短语, 然后判断它们是否为产品属性, 如果是产品属性记为集合C。本文采用专家打分的方法判断候选特征词属于A、B还是C, 对于有争议的词语, 找出其使用语境, 并进行小组讨论, 直到结果一致。
为了保证实验结果的稳定性, 采用Bootstrapping方法检验查准率。将每一类产品的30万条评论平均分为6组, 每组5万条评论数据, 每次选取4组进行特征词提取实验, 得到每次实验的特征词典和查准率, 共进行15次实验。综合得到的产品特征词典如表2和表3所示(由于篇幅的关系, 仅展示手机和图书的特征词典), 平均查准率如表4所示。
表2 手机特征词典
| 编号 | 类型 | 手机特征词 |
|---|---|---|
| 1 | 屏幕 | 屏幕 桌面 触摸屏 显示屏 屏 弧面 质量 触屏 曲屏 分辨率 亮度 显示 界面 |
| 2 | 电池 | 电池 时间 待机 充电器 容量 充电 快充 电量 耗电量 用电 时长 |
| 3 | 摄像 | 摄像 拍照 摄像头 闪光灯 照相 像素 自拍 柔光 背景 清晰度 色彩 摄影 镜头 画面感 相素 神器 画质 美颜 效果 |
| 4 | 内存与处理 | 性能 速度 系统 运行速度 兼容性 卡 不卡 卡顿 处理器 开机 反应速度 延迟 网速 卡机 内存 死机 |
| 5 | 配件 | 壳 膜 玻璃膜 保护膜 套 壳子 钢化膜 手机套 贴膜 |
| 6 | 系统与软件 | 版本 功能 软件 智能 程序 系统 操作 |
| 7 | 游戏 | 游戏 娱乐 玩游戏 手游 王者荣耀 荣耀 斗地主 麻将 |
| 8 | 多媒体 | 多媒体 收音机 声音 语音 铃声 耳机 音质 音乐 视频 音响 电影 蓝光 音量 播放器 电视剧 音箱 听歌 播放 电视剧 画质 效果 |
| 9 | 外形 | 外形 机身 手感 体积 外观 缝隙 重量 质感 工艺 颜色 触感 外表 线条 机身 样子 造型 设计 个性 |
| 10 | 服务 | 售后 服务 物流 客服 态度 口碑 顺丰 卖家 |
| 11 | 价格 | 价格 价钱 性价比 降价 打折 定价 标价 钱 |
表3 图书特征词典
| 编号 | 类型 | 图书属性词 |
|---|---|---|
| 1 | 内容 | 思想 内容 主题 话题 故事 精神 心灵 内涵 理念 思想 思维 观念 理论 形象 事件 思路 深思 感觉 问题 爱情 想象 内心 观点 心理 文化 心理学 理论 人性 兴趣 思维 感情 无法 味道 情感 速度 心情 精神 体会 心灵 意思 答案 能力 习惯 哲学 大学 视角 梦想 科学 心态 性格 技巧 篇幅 用心 章节 数据 记忆 传统 学术 思路 题目 情绪 计划 灵魂 天堂 动机 理念 意识 情 理性 深思 观念 功力 个性 精髓 理想 笔触 悬念 意见 新意 高度 次数 趣味 小心 规划 幻想 路线 意义 情节 意境 人文 核心 意境 寓意 |
| 2 | 结构和语言 | 结构 情节 构造 构思 布局 文风 组织 条理 细节 题材 形式 篇幅 章节 体系 历史 世界 地方 结局 结果 方式 方面 方法 经历 基本 角度 过程 关系 原因 现实 道理 案例 实际 结尾 情况 印象 手法 体验 逻辑 类型 事件 背景 形式 经验 信息 全书 效果 系统 关键 重点 艺术 例子 案件 环境 现象 形象 模式 状态 特点 线索 事物 路 方向 哲理 命运 秘密 亲情 概念 范围 办法 目标 市场 理由 区别 内涵 缘故 场景 特色 本质 领域 步骤 目的 脉络 通篇 文笔 语言 字里行间 言辞 语句 语法 讲话 说话 叙述 情绪 笔触 风格 情感 口味 文字 风格 字体 色彩 单词 词 画 画面 话题 目 词汇 句子 文 错字 语句 外文 |
| 3 | 实用性 | 电子版 实用性 实用 应用 有用 用处 有效 利用 帮助 技能 瑕疵 亮点 缺点 优点 弱点 |
| 4 | 趣味性 | 爱好 吸引力 趣 风趣 无趣 有趣 趣味 兴趣 乐趣 意味 意思 儿童 |
| 5 | 难度和专业性 | 深度 难度 难 难题 难点 难处 困难 经典 可读性 代表作 习题 技术 课程 教程 试题 新闻 商务 物理 教科书 漫画 电视剧 著作 |
| 6 | 价格 | 价格 价钱 价 标价 钱 价位 值 价值 性价比 降价 定价 |
| 7 | 质量 | 精装 平装 盗版 外观 包装 用纸 封面 画质 装帧 印刷 封皮 纸张 装订 质量 品质 质 质地 印 包裹 封装 封皮 书皮 书面 手感 纸质 手感 表面 水平 样子 标准 水准 |
表4 产品特征查准率比较
| 产品名称 | Hu等[6] 实验 | 李实等[13] 实验 | 陈炯等[21] 实验 | 本实验 |
|---|---|---|---|---|
| 手机 | 0.718 | 0.633 | 0.759 | 0.786 |
| 数码相机 | 0.71 | 0.611 | 0.755 | 0.747 |
| 图书 | / | 0.629 | 0.737 | 0.791 |
对于查全率, 由于测试数据与训练数据量级上的巨大差距, 因此从未被训练的手机评论中抽取评论较长的10组评论数据(每组100条), 根据公式(2)计算第一组评论的查全率, 然后逐次增加, 直到查全率的值趋于稳定时停止, 如表5所示。
表5 产品特征查全率比较
| 产品名称 | Hu等[6] 实验 | 李实等[13] 实验 | 陈炯等[21] 实验 | 本实验 |
|---|---|---|---|---|
| 手机 | 0.761 | 0.689 | 0.653 | 0.832 |
| 数码相机 | 0.792 | 0.805 | 0.741 | 0.849 |
| 图书 | / | 0.917 | 0.682 | 0.883 |
对得到的手机产品特征词典进行分析, 发现手机最终可分为11类特征, 共计特征词141个; 其中有32个不认为是产品特征, 如:
(1) 单字的词如“屏”、“壳”等;
(2) 与特征关联度高但是不代表产品特征的名词如“时间”、“版本”等;
(3) 专有名词如“王者荣耀”等;
(4) 与几类属性相关度都比较高的重复名词如“效果”、“质量”等。
另外, 本文方法未能识别出的特征词主要有“mp3”、“cpu”等英文单词, 或者是“送的东西”这种口语化词汇, 另外还有一些“适合老年人使用”、“适合妹子用”等一些隐性特征。
综合三种产品实验结果并与文献[13]以及文献[21]的结果进行比较(如表4和表5所示), 由于本文是基于大规模评论数据进行的特征提取实验, 无法采用与文献[13, 21]同样的数据进行实验比较, 而文献[13, 21]的方法在不做优化的情况下又不适用于大规模的数据, 所以只能选用与文献[13, 21]来源相同的三种产品评论数据实验进行比较。本实验的平均查全率达到0.855, 平均查准率为0.774。说明本文提出的方法具有一定的有效性, 在特征识别的查准率上还有很大提升空间, 这也是因为本文将语料库中的语言规律和句法关系的分析工作全部依赖Word2Vec这一工具, 而Word2Vec需要足够大的语料库进行训练, 其准确性才能得到保障。本文方法在查全率上的表现是比较好的, 是因为本文方法采用人工标注, 并结合通用知识库同义词林进行扩展, 再结合评论语料进行补充, 人工参与度高, 信息来源丰富; 另外一方面是因为采用大规模的语料库进行实验, 能覆盖到大量的网络词汇。
本文基于前人的研究提出一种新的产品特征提取方法, 基于通用知识库以及大规模语料库相结合的半监督学习的特征提取。本文主要贡献如下:
(1) 梳理总结了现有的产品特征提取算法, 从特征挖掘算法层面对特征提取方法进行分类, 并总结这些方法的优缺点。
(2) 提出基于大规模语料库的特征提取新方法, 改进产品特征提取的效果。
(3) 构建部分产品的特征词词典, 并为其他产品的特征提取提供思路。
当然, 本研究也存在如下不足:
(1) 在标注与扩展环节需要有大量的人工操作, 效率不高;
(2) 本文方法只能识别显性的特征词, 而网络评论中也有大量的隐性特征, 如“适合初学者”意指操作简单, 但本文的方法是无法识别这样的隐性特征的。有研究者通过研究跨领域两种语料的相关性与相异性, 抽取产品特征, 提高特征抽取的查准率[30], 后续可以借鉴这种思路对于本文方法进行完善和改进。
李伟卿: 构建实验模型, 负责实验, 论文撰写;
王伟军: 提出研究命题和研究思路, 论文修改。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: liwq@mails.ccnu.edu.cn。
[1] 李伟卿. 产品评论数据.txt. 爬取的手机、图书、数码相机评论文本数据.
[2] 李伟卿. 手机、图书、数码相机的特征词典.xls. 最终得到的产品特征词典.
| [1] |
Sentiment Analysis and Opinion Mining from Social Media: A Review [J]. |
| [2] |
Opinion-Mining Methodology for Social Media Analytics [J].https://doi.org/10.3837/tiis.2015.01.024 URL [本文引用: 1] 摘要
Social media have emerged as new communication channels between consumers and companies that generate a large volume of unstructured text data. This social media content, which contains consumers opinions and interests, is recognized as valuable material from which businesses can mine useful information; consequently, many researchers have reported on opinion-mining frameworks, methods, techniques, and tools for business intelligence over various industries. These studies sometimes focused on how to use opinion mining in business fields or emphasized methods of analyzing content to achieve results that are more accurate. They also considered how to visualize the results to ensure easier understanding. However, we found that such approaches are often technically complex and insufficiently user-friendly to help with business decisions and planning. Therefore, in this study we attempt to formulate a more comprehensive and practical methodology to conduct social media opinion mining and apply our methodology to a case study of the oldest instant noodle product in Korea. We also present graphical tools and visualized outputs that include volume and sentiment graphs, time-series graphs, a topic word cloud, a heat map, and a valence tree map with a classification. Our resources are from public-domain social media content such as blogs, forum messages, and news articles that we analyze with natural language processing, statistics, and graphics packages in the freeware R project environment. We believe our methodology and visualization outputs can provide a practical and reliable guide for immediate use, not just in the food industry but other industries as well.
|
| [3] |
Sentiment Analysis and Opinion Mining Within Social Networks Using Konstanz Information Miner [J]. |
| [4] |
Using Text Mining and Sentiment Analysis for Online Forums Hotspot Detection and Forecast [J].https://doi.org/10.1016/j.dss.2009.09.003 URL [本文引用: 1] 摘要
Text sentiment analysis, also referred to as emotional polarity computation, has become a flourishing frontier 26 in the text mining community. This paper studies online forums hotspot detection and forecast using 27 sentiment analysis and text mining approaches. First, we create an algorithm to automatically analyze the 28 emotional polarity of a text and to obtain a value for each piece of text. Second, this algorithm is combined 29 with K-means clustering and support vector machine (SVM) to develop unsupervised text mining approach. 30 We use the proposed text mining approach to group the forums into various clusters, with the center of each 31 representing a hotspot forum within the current time span. The data sets used in our empirical studies are 32 acquired and formatted from Sina sports forums, which spans a range of 31 different topic forums and 33 220,053 posts. Experimental results demonstrate that SVM forecasting achieves highly consistent results 34 with K-means clustering. The top 10 hotspot forums listed by SVM forecasting resembles 80% of K-means 35 clustering results. Both SVM and K-means achieve the same results for the top 4 hotspot forums of the year. 36(c) 2009 Published by Elsevier B.V. 37
|
| [5] |
基于微博的产品评论挖掘: 情感分析的方法 [J].https://doi.org/10.3772/j.issn.10000135.2014.012.008 URL [本文引用: 2] 摘要
针对微博中的海量产品评论信息,提出了一种基于模糊观点词的产品评论情感极性和强度计算方法。该算法运用规范化的TFIDF加权方法提取产品特征,基于知网构建模糊观点词词库,应用BMI (Balanced Mutual Information)方法进行特征词和观点词关联度计算,因而有效解决了微博产品评论中特征-观点对的提取问题。通过微博文本影响力分析,结合对微博文本中的情感语义因素定量计算,提高了微博产品评论情感分析的准确率。给出了应用该方法的具体步骤,通过实验分析发现本文构建的算法在各方面的表现都处于不错的水平并具有很好的应用性。
Product Reviews Mining from Microblogging Based on Sentiment Analysis [J].https://doi.org/10.3772/j.issn.10000135.2014.012.008 URL [本文引用: 2] 摘要
针对微博中的海量产品评论信息,提出了一种基于模糊观点词的产品评论情感极性和强度计算方法。该算法运用规范化的TFIDF加权方法提取产品特征,基于知网构建模糊观点词词库,应用BMI (Balanced Mutual Information)方法进行特征词和观点词关联度计算,因而有效解决了微博产品评论中特征-观点对的提取问题。通过微博文本影响力分析,结合对微博文本中的情感语义因素定量计算,提高了微博产品评论情感分析的准确率。给出了应用该方法的具体步骤,通过实验分析发现本文构建的算法在各方面的表现都处于不错的水平并具有很好的应用性。
|
| [6] |
Opinion Observer: Analyzing and Comparing Opinions on the Web [C]// |
| [7] |
Extracting Product Features and Opinions from Reviews[A]// Natural Language Processing and Text Mining [M]. |
| [8] |
Mining Feature-Opinion in Online Customer Reviews for Opinion Summarization [J].https://doi.org/10.3217/jucs-016-06-0938 URL [本文引用: 3] 摘要
Online customer reviews is considered as a significant informative resource which is useful for both potential customers and product manufacturers. In web pages, the reviews are written in natural language and are unstructured-free-texts scheme. The task of manually scanning through large amounts of review one by one is computational burden and is not practically implemented with respect to businesses and customer perspectives. Therefore it is more efficient to automatically process the various reviews and provide the necessary information in a suitable form. The high-level problem of opinion summarization addresses how to determine the sentiment, attitude or opinion that an author expressed in natural language text with respect to a certain feature. In this paper, we dedicate our work to the main subtask of opinion summarization. The task of product feature and opinion extraction is critical to opinion summarization, because its effectiveness significantly affects the performance of opinion orientation identification. It is important to properly identify the semantic relationships between product features and opinions. We proposed an approach for mining product feature and opinion based on the consideration of syntactic information and semantic information. By applying dependency relations and ontological knowledge with probabilistic based model, the result of our experiments shows that our approach is more flexible and effective.
|
| [9] |
基于依存关系的旅游景点评论的特征-观点对抽取 [J].https://doi.org/10.3969/j.issn.1003-0077.2012.03.020 URL [本文引用: 2] 摘要
特征-观点对的抽取是观点挖掘中重要的研究课题之一,本文利用依存语法对句子的分析,研究了评论文本中特征-观点对的抽取。利用词对间的依存关系,构建了用于获取含情感倾向组块的规则以及候选评价对象的识别算法,在此基础上,设计了具有情感倾向的特征-观点对的抽取算法。本文对山西旅游景点评论语料进行了特征-观点对的抽取,实验结果表明,整体的F1值达到了87.10%,验证了算法的有效性。
Feature-Opinion Extraction in Scenic Spots Reviews Based on Dependency Relation [J].https://doi.org/10.3969/j.issn.1003-0077.2012.03.020 URL [本文引用: 2] 摘要
特征-观点对的抽取是观点挖掘中重要的研究课题之一,本文利用依存语法对句子的分析,研究了评论文本中特征-观点对的抽取。利用词对间的依存关系,构建了用于获取含情感倾向组块的规则以及候选评价对象的识别算法,在此基础上,设计了具有情感倾向的特征-观点对的抽取算法。本文对山西旅游景点评论语料进行了特征-观点对的抽取,实验结果表明,整体的F1值达到了87.10%,验证了算法的有效性。
|
| [10] |
中文评论产品特征与观点抽取方法研究 [J].Extracting Product Feature and User Opinion from Chinese Reviews [J]. |
| [11] |
产品评论挖掘研究综述 [J].https://doi.org/10.3778/j.issn.1002-8331.2008.36.010 URL [本文引用: 2] 摘要
产品评论挖掘是以Web上用户发表的产品评论为挖掘对象,采用自然语言处理技术,从大量的文 本数据中发现关于产品的功能和性能的评价信息的过程。产品评论挖掘是一个新兴的研究领域,是对自然语言描述的无结构数据进行数据挖掘的典型代表。产品评论 中挖掘得到的信息不仅可以帮助生产厂商改进产品,还可以帮助用户合理的购买产品。对产品评论挖掘进行了全面深入地讨论,介绍了产品评论挖掘系统的通用框 架,然后对产品特征提取、主观句定位、用户态度提取、态度极性判定、挖掘结果显示这5个子任务进行了详细地阐述,最后介绍了产品评论挖掘的最新方向。
A Survey of Product Reviews Mining [J].https://doi.org/10.3778/j.issn.1002-8331.2008.36.010 URL [本文引用: 2] 摘要
产品评论挖掘是以Web上用户发表的产品评论为挖掘对象,采用自然语言处理技术,从大量的文 本数据中发现关于产品的功能和性能的评价信息的过程。产品评论挖掘是一个新兴的研究领域,是对自然语言描述的无结构数据进行数据挖掘的典型代表。产品评论 中挖掘得到的信息不仅可以帮助生产厂商改进产品,还可以帮助用户合理的购买产品。对产品评论挖掘进行了全面深入地讨论,介绍了产品评论挖掘系统的通用框 架,然后对产品特征提取、主观句定位、用户态度提取、态度极性判定、挖掘结果显示这5个子任务进行了详细地阐述,最后介绍了产品评论挖掘的最新方向。
|
| [12] |
Feature Extraction and Opinion Mining in Online Product Reviews [C]// |
| [13] |
中文网络客户评论的产品特征挖掘方法研究 [J].Mining Features of Products from Chinese Customer Online Reviews [J]. |
| [14] |
基于知网的模糊情感本体的构建研究 [J].https://doi.org/10.3772/j.issn.1000-0135.2012.06.005 URL [本文引用: 1] 摘要
构建模糊情感本体是在线评论情感分析的基础.针对在线评论情感表达的多样性和模糊性,将情感本体划分为评价词本体和情感词本体,利用模糊理论和知网相关概念,构建模糊情感本体的基本模型.根据评价词和情感词的各自特点,运用模糊化处理和语义相似度的相关理论,分别对评价词模糊本体和情感词模糊本体的情感类型和隶属度进行了相应处理.并通过与点互信息方法比较,验证了情感本体模型在自动获取情感类方面的有效性,最后进行了相关数据统计.
Study on Construction of Fuzzy Emotion Ontology Based on HowNet [J].https://doi.org/10.3772/j.issn.1000-0135.2012.06.005 URL [本文引用: 1] 摘要
构建模糊情感本体是在线评论情感分析的基础.针对在线评论情感表达的多样性和模糊性,将情感本体划分为评价词本体和情感词本体,利用模糊理论和知网相关概念,构建模糊情感本体的基本模型.根据评价词和情感词的各自特点,运用模糊化处理和语义相似度的相关理论,分别对评价词模糊本体和情感词模糊本体的情感类型和隶属度进行了相应处理.并通过与点互信息方法比较,验证了情感本体模型在自动获取情感类方面的有效性,最后进行了相关数据统计.
|
| [15] |
Bootstrapping both Product Properties and Opinion Words from Chinese Reviews with Cross-Training [ |
| [16] |
Automatic Topic Term Detection and Sentiment Classification for Opinion Mining [D]. |
| [17] |
中文网络评论中提取产品特征的研究 [J].Research of Extracting Product Features from Chinese Online Reviews [J]. |
| [18] |
汉语组块的定义和获取 [C]//Research on Definition and Acquisition of Chunk [C] // |
| [19] |
The Unified Collocation Framework for Opinion Mining [C]// |
| [20] |
中文产品评论挖掘关键技术研究 [D].Research on Key Mining Technologies of Product Reviews in Chinese [D]. |
| [21] |
面向中文客户评论的产品属性抽取方法研究 [J].https://doi.org/10.3969/j.issn.1000-7024.2012.03.080 URL [本文引用: 3] 摘要
针对现有的中文客户评论产品属 性识别方法存在的不足,通过采用词法分析、句法分析、同义词词林等多项技术和资源,挖掘真实语料中蕴藏的语言知识,提出了一种基于模板的产品属性识别方 法。该方法对评论语料进行词法、句法分析和人工标注,从标注结果中综合分析和归纳评论句的全局语言规则,提取属性词和评价词之间的词性和依存关系序列,借 助同义词词林构建产品属性模板,使用属性模板识别产品属性。对比实验结果表明了提出方法的有效性。
Research on Product Feature Extraction from Chinese Customer Reviews [J].https://doi.org/10.3969/j.issn.1000-7024.2012.03.080 URL [本文引用: 3] 摘要
针对现有的中文客户评论产品属 性识别方法存在的不足,通过采用词法分析、句法分析、同义词词林等多项技术和资源,挖掘真实语料中蕴藏的语言知识,提出了一种基于模板的产品属性识别方 法。该方法对评论语料进行词法、句法分析和人工标注,从标注结果中综合分析和归纳评论句的全局语言规则,提取属性词和评价词之间的词性和依存关系序列,借 助同义词词林构建产品属性模板,使用属性模板识别产品属性。对比实验结果表明了提出方法的有效性。
|
| [22] |
Dual Sentiment Analysis: Considering Two Sides of One Review [J].https://doi.org/10.1109/TKDE.2015.2407371 URL [本文引用: 1] 摘要
中国科学院机构知识库(中国科学院机构知识库网格(CAS IR GRID))以发展机构知识能力和知识管理能力为目标,快速实现对本机构知识资产的收集、长期保存、合理传播利用,积极建设对知识内容进行捕获、转化、传播、利用和审计的能力,逐步建设包括知识内容分析、关系分析和能力审计在内的知识服务能力,开展综合知识管理。
|
| [23] |
TASC: Topic-Adaptive Sentiment Classification on Dynamic Tweets [J].https://doi.org/10.1109/TKDE.2014.2382600 URL [本文引用: 1] 摘要
Sentiment classification is a topic-sensitive task, i.e., a classifier trained from one topic will perform worse on another. This is especially a problem for the tweets sentiment analysis. Since the topics in Twitter are very diverse, it is impossible to train a universal classifier for all topics. Moreover, compared to product review, Twitter lacks data labeling and a rating mechanism to acquire sentiment labels. The extremely sparse text of tweets also brings down the performance of a sentiment classifier. In this paper, we propose a semi-supervised topic-adaptive sentiment classification (TASC) model, which starts with a classifier built on common features and mixed labeled data from various topics. It minimizes the hinge loss to adapt to unlabeled data and features including topic-related sentiment words, authors' sentiments and sentiment connections derived from“@” mentions of tweets, named as topic-adaptive features. Text and non-text features are extracted and naturally split into two views for co-training. The TASC learning algorithm updates topic-adaptive features based on the collaborative selection of unlabeled data, which in turn helps to select more reliable tweets to boost the performance. We also design the adapting model along a timeline (TASC-t) for dynamic tweets. An experiment on 6 topics from published tweet corpuses demonstrates that TASC outperforms other well-known supervised and ensemble classifiers. It also beats those semi-supervised learning methods without feature adaption. Meanwhile, TASC-t can also achieve impressive accuracy and F-score. Finally, with timeline visualization of “river” graph, people can intuitively grasp the ups and downs of sentiments' evolvement, and the intensity by color gradation.
|
| [24] |
Identifying Features in Opinion Mining via Intrinsic and Extrinsic Domain Relevance [J].https://doi.org/10.1109/TKDE.2013.26 URL [本文引用: 1] 摘要
The vast majority of existing approaches to opinion feature extraction rely on mining patterns only from a single review corpus, ignoring the nontrivial disparities in word distributional characteristics of opinion features across different corpora. In this paper, we propose a novel method to identify opinion features from online reviews by exploiting the difference in opinion feature statistics across two corpora, one domain-specific corpus (i.e., the given review corpus) and one domain-independent corpus (i.e., the contrasting corpus). We capture this disparity via a measure called domain relevance (DR), which characterizes the relevance of a term to a text collection. We first extract a list of candidate opinion features from the domain review corpus by defining a set of syntactic dependence rules. For each extracted candidate feature, we then estimate its intrinsic-domain relevance (IDR) and extrinsic-domain relevance (EDR) scores on the domain-dependent and domain-independent corpora, respectively. Candidate features that are less generic (EDR score less than a threshold) and more domain-specific (IDR score greater than another threshold) are then confirmed as opinion features. We call this interval thresholding approach the intrinsic and extrinsic domain relevance (IEDR) criterion. Experimental results on two real-world review domains show the proposed IEDR approach to outperform several other well-established methods in identifying opinion features.
|
| [25] |
A Review of Feature Extraction in Sentiment Analysis [J].
ABSTRACT Rapid increase in internet users along with growing power of online review sites and social media has given birth to Sentiment analysis or Opinion mining, which aims at determining what other people think and comment. Sentiments or Opinions contain public generated content about products, services, policies and politics. People are usually interested to seek positive and negative opinions containing likes and dislikes, shared by users for features of particular product or service. Therefore product features or aspects have got significant role in sentiment analysis. In addition to sufficient work being performed in text analytics, feature extraction in sentiment analysis is now becoming an active area of research. This review paper discusses existing techniques and approaches for feature extraction in sentiment analysis and opinion mining. In this review we have adopted a systematic literature review process to identify areas well focused by researchers, least addressed areas are also highlighted giving an opportunity to researchers for further work. We have also tried to identify most and least commonly used feature selection techniques to find research gaps for future work.
|
| [26] |
《同义词词林》在中文实体关系抽取中的作用 [J].https://doi.org/10.3969/j.issn.1003-0077.2014.02.014 URL [本文引用: 1] 摘要
语义信息在命名实体间语义关系抽取中具有重要的作用。该文以《同义词词林》为例,系统全面地研究了词汇语义信息对基于树核函数的中文语义关系抽取的有效性,深入探讨了不同级别的语义信息和一词多义等现象对关系抽取的影响,详细分析了词汇语义信息和实体类型信息之间的冗余性。在ACE2005中文语料库上的关系抽取实验表明,在未知实体类型的前提下,语义信息能显著提高抽取性能;而在已知实体类型的情况下,语义信息也能明显提高某些关系类型的抽取性能,这说明《词林》语义信息和实体类型信息在中文语义关系抽取中具有一定的互补性。
The Effect of TongYiCi CiLin in Chinese Entity Relation Extraction [J].https://doi.org/10.3969/j.issn.1003-0077.2014.02.014 URL [本文引用: 1] 摘要
语义信息在命名实体间语义关系抽取中具有重要的作用。该文以《同义词词林》为例,系统全面地研究了词汇语义信息对基于树核函数的中文语义关系抽取的有效性,深入探讨了不同级别的语义信息和一词多义等现象对关系抽取的影响,详细分析了词汇语义信息和实体类型信息之间的冗余性。在ACE2005中文语料库上的关系抽取实验表明,在未知实体类型的前提下,语义信息能显著提高抽取性能;而在已知实体类型的情况下,语义信息也能明显提高某些关系类型的抽取性能,这说明《词林》语义信息和实体类型信息在中文语义关系抽取中具有一定的互补性。
|
| [27] |
网络商品评论的特征—情感词本体构建与情感分析方法研究 [J].Research on Construction of Feature-Sentiment Ontology and Sentiment Analysis [J]. |
| [28] |
基于用户偏好与商品属性情感匹配的图书个性化推荐研究 [J].Personalized Book Recommendation Based on User Preferences and Commodity Features [J]. |
| [29] |
基于同义词词林的词语相似度计算方法 [J].https://doi.org/10.3969/j.issn.1671-5896.2010.06.011 URL [本文引用: 1] 摘要
为解决词语相在语义网自适应学习系统中相似度计算不清的问题,以同义词词林为基础,提出并实现了一种基于同义词词林的词语相似度计算方法,充分分析并利用了同义词词林的编码及结构特点。该算法同时考虑了词语的相似性,和词语的相关性。进行人工测试,替换测试以及与当前流行的基于"知网"的词语相似度算法对比测试的结果表明,该算法与人们思维中的相似度值基本一致,有较高的准确性。
Words Similarity Algorithm Based on Tongyici Cilin in Semantic Web Adaptive Learning System [J].https://doi.org/10.3969/j.issn.1671-5896.2010.06.011 URL [本文引用: 1] 摘要
为解决词语相在语义网自适应学习系统中相似度计算不清的问题,以同义词词林为基础,提出并实现了一种基于同义词词林的词语相似度计算方法,充分分析并利用了同义词词林的编码及结构特点。该算法同时考虑了词语的相似性,和词语的相关性。进行人工测试,替换测试以及与当前流行的基于"知网"的词语相似度算法对比测试的结果表明,该算法与人们思维中的相似度值基本一致,有较高的准确性。
|
| [30] |
Extracting Product Features from Online Reviews for Sentimental Analysis [C]// |
| [31] |
FEROM: Feature Extraction and Refinement for Opinion Mining [J].https://doi.org/10.4218/etrij.11.0110.0627 URL [本文引用: 1] 摘要
Opinion mining involves the analysis of customer opinions using product reviews and provides meaningful information including the polarity of the opinions. In opinion mining, feature extraction is important since the customers do not normally express their product opinions holistically but separately according to its individual features. However, previous research on feature-based opinion mining has not had good results due to drawbacks, such as selecting a feature considering only syntactical grammar information or treating features with similar meanings as different. To solve these problems, this paper proposes an enhanced feature extraction and refinement method called FEROM that effectively extracts correct features from review data by exploiting both grammatical properties and semantic characteristics of feature words and refines the features by recognizing and merging similar ones. A series of experiments performed on actual online review data demonstrated that FEROM is highly effective at extracting and refining features for analyzing customer review data and eventually contributes to accurate and functional opinion mining.
|
| [32] |
Sentiment Analysis and Opinion Mining [J].https://doi.org/10.1007/978-1-4899-7502-7_907-1 URL [本文引用: 1] 摘要
With the rapid growth of social media, sentiment analysis, also called opinion mining, has become one of the most active research areas in natural language processing. Its application is also widespre
|
| [33] |
基于特征本体的微博产品评论情感分析 [J].
[目的/意义] 微博平台产品评论的特征级情感分析问题具有其特殊性,为了对特征分类,解决隐式特征的识别问题,并分析特征情感,提出一种基于特征本体的产品评论情感分析方法。[方法/过程] 该方法利用构建的特征本体对特征词分类,通过计算情感词与特征的搭配权重来识别隐式特征,并构建领域情感词典和微博表情符号词典,计算微博产品评论的特征情感极性和强度。[结果/结论] 构建方法模型,通过采集微博评论数据设计实验,验证了提出方法的有效性。
Study on Evolution Process of Network Information Ecological Chain from the Perspective of Complex Networks [J].
[目的/意义] 微博平台产品评论的特征级情感分析问题具有其特殊性,为了对特征分类,解决隐式特征的识别问题,并分析特征情感,提出一种基于特征本体的产品评论情感分析方法。[方法/过程] 该方法利用构建的特征本体对特征词分类,通过计算情感词与特征的搭配权重来识别隐式特征,并构建领域情感词典和微博表情符号词典,计算微博产品评论的特征情感极性和强度。[结果/结论] 构建方法模型,通过采集微博评论数据设计实验,验证了提出方法的有效性。
|
| [34] |
基于词向量的情感新词发现方法 [J].https://doi.org/10.6040/j.issn.1671-9352.3.2014.255 URL [本文引用: 2] 摘要
词语级的情感倾向性分析一直是文本情感计算领域的热点研究方向,如何自动识别情感新词,并判断其情感倾向性已经成为当前亟待解决的问题。首先用基于统计量的方法识别微博语料中的新词,然后利用神经网络去训练语料中词语的词向量,从语料自身挖掘出词与词之间的相关性,最后提出了基于词向量的情感新词发现方法。实验表明该方法可以有效应用于情感新词发现。
New Methods for Extracting Emotional Words Based on Distributed Representations of Words [J].https://doi.org/10.6040/j.issn.1671-9352.3.2014.255 URL [本文引用: 2] 摘要
词语级的情感倾向性分析一直是文本情感计算领域的热点研究方向,如何自动识别情感新词,并判断其情感倾向性已经成为当前亟待解决的问题。首先用基于统计量的方法识别微博语料中的新词,然后利用神经网络去训练语料中词语的词向量,从语料自身挖掘出词与词之间的相关性,最后提出了基于词向量的情感新词发现方法。实验表明该方法可以有效应用于情感新词发现。
|
| [35] |
Efficient Estimation of Word Representations in Vector Space [OL].
Abstract: We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}