
|
|
赵杨 , 袁析妮, 陈亚文, 武立强
, 袁析妮, 陈亚文, 武立强
武汉大学信息管理学院 武汉 430072
Zhao Yang, Yuan Xini, Chen Yawen, Wu Liqiang
中图分类号: TP391
通讯作者:
收稿日期: 2018-07-26
修回日期: 2018-08-29
网络出版日期: 2018-11-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】利用机器学习算法对APP广告转化率进行有效预测, 提高广告投放效果, 更好地开展营销活动。【方法】针对APP广告特性, 综合应用梯度提升决策树、随机森林、LightGBM、XGBoost、场感知因子分解机模型、Vowpal Wabbit等机器学习算法构建APP广告转化率预测模型——RF+LXFV, 使用腾讯APP广告数据对模型的有效性与精确性进行检验。【结果】通过对比预测结果, 在Log-Loss(0.105)和AUC(0.786)两个指标上的表现, 发现基于RF+LXFV模型的APP广告转化率预测结果比基于单一机器学习算法的预测结果精确度更高。【局限】未充分考虑广告转化延迟对转化率预测的影响。【结论】RF+LXFV模型是预测APP广告转化率的一种有效方法。
关键词:
Abstract
[Objective] This paper tries to predict the conversion rate of APP advertisements with the help of machine learning algorithms, aiming to improve the effectiveness of advertising and marketing activities. [Methods] First, we examined the characteristics of APP advertisements. Then, we applied four machine learning algorithms to predict their conversion rate. The proposed RF+LXFV model was built with Random Forest, Gradient Boosting Decision Tree, Random Forest, LightGBM, XGBoost, Vowpal Wabbit and Field-aware Factorization Machine. Finally, we evaluated the validity and accuracy of the new model with Tencent APP advertising data. [Results] The prediction results of the proposed model achieved higher accuracy than those of the single algorithm. [Limitations] We did not examine the impacts of advertising transformation delay on prediction. [Conclusions] The proposed RF+LXFV model could predict the conversion rate of APP advertising effectively.
Keywords:
移动网络技术的日新月异与移动商务的广泛开展推动了移动互联网广告行业的迅猛发展。艾瑞咨询的研究报告显示, 2016年网络广告市场规模已达2 902.7亿元, 其中移动网络广告超过60%[1]。随着以智能手机为代表的各类智能化移动终端日益普及, 依托移动APP进行网络广告投放正受到越来越多广告主的青睐。APP广告包括内置视频广告、启动屏广告、横幅广告、积分墙广告、信息流广告等多种形式, 与传统网络广告相比, 具有更强的媒体表现性、信息交互性与推送精准性, 能够更好地实现营销目标[2]。广告点击率(Click-Through Rate, CTR)和转化率(ConVersion Rate, CVR)是衡量广告投放效果的重要指标。其中, 广告点击率指广告正式发布后被用户点击的概率; 转化率则是指用户点击广告后产生实际消费行为的概率。相对于广告点击率, 转化率直接影响着广告主的商业目标与经济效益, 是广告主进行广告付费的关键依据。通过APP广告转化率分析与预测, 不仅能够判断广告投放后的市场效益, 还能进一步明确广告投放对网络消费者行为的影响, 帮助广告主更好地开展营销活动, 实现商业目标。
鉴于此, 本文在综合应用梯度提升决策树(Gradient Boosting Decision Tree, GBDT)、随机森林(Random Forest, RF)、LightGBM、XGBoost、场感知因子分解机模型(Field-aware Factorization Machine, FFM)、Vowpal Wabbit(VW)等机器学习算法的基础上, 提出APP广告转化率综合预测模型——RF+LXFV, 并使用腾讯社交类APP广告的真实数据验证模型的有效性与精确性, 为提高APP广告转化率提供依据。
网络广告点击率与转化率分析是计算广告学中的重要研究课题。特征提取是分析和预测广告点击率与转化率的首要工作, 在已有研究中, Cheng等[3]通过统计分析发现, 用户特征是影响广告点击率的主要因素; Tagami等[4]通过对雅虎网络广告的实证研究, 发现网页特征、用户特征、广告特征、点击特征等是影响广告点击率的重要因素; 李春红等[5]提出基于套索算法(LASSO)的广告点击率特征提取方法, 针对关键词广告提取点击成本、商标信息、地域信息、关键词ID、广告位置等相关特征; 张志强等[6]使用基于张量分解的方法对广告特征进行降维, 针对搜索广告, 将影响点击率的因素分为ID类特征(用户ID、广告ID等)、属性类特征(用户性别、年龄等)和统计类特征(广告历史展现次数、历史点击次数等)。在广告点击率预测方法的研究中, 逻辑回归等广义线性模型是最常用的方法之一[7,8,9], 但逻辑回归模型不能揭示非线性广告特征之间的内在关联, 需要人工进行特征组合、变换和清洗, 极大地降低了广告点击率预测的效率和精度[10]。因此, 国内外学者开始从商务智能视角出发, 应用能自动完成广告特征组合和捕捉非线性关系的模型取代简单的广义线性模型。如Juan等[11]使用基于因子分解机(Factorization Machine, FM)的FFM模型实现对上下文广告的点击率预测; 魏晓航等[12]则将GBDT与FM相结合, 对多媒体展示广告的点击率进行实证研究。这些方法的有效应用不仅丰富了广告点击率预测的研究成果, 也为广告转化率分析和预测提供重要参考。
相比网络广告点击率的研究, 对广告转化率的探索还十分有限。但近年来, 随着以转化率为核心指标的广告付费(Cost Per Action, CPA)模式的兴起, 转化率分析与预测问题正引起研究者的高度关注。顾智宇等[13]通过统计发现, 搜索广告的转换率在数值上比点击率低两个数量级, 极不平衡的训练样本对转化率预测结果准确性造成很大影响, 需要应用更有效的模型提高预测准确性。然而, 目前大多数研究仍使用单一机器学习算法预测广告转化率, 如吴英[14]运用逻辑回归的方法对搜索平台广告转化率进行研究; 纪文迪[15]则使用威布尔分布改进的逻辑回归方法预测电子商务网站的广告转化率。此外, 在移动APP广告的研究中, 对转化率预测的探索尚未展开, 大多成果仍是对移动APP广告形式[2]、定价策略[16]、投放效果评价[13]等问题的分析。
综上, 国内外学者对网络广告点击率和转化率的研究产出诸多有价值的成果, 为本文奠定了坚实的理论基础。但在现有研究中, 针对网络广告转化率的预测大多使用单一的机器学习算法, 受到模型自身适用性与预测能力的限制, 难以得到更精准的结果。随着机器学习技术的快速发展, 综合应用多种机器学习算法进行广告转化率预测正逐渐成为重要手段, 能够弥补单个算法的不足, 获得更优的预测结果[17,18]。因此, 本文基于机器学习混合算法构建APP广告转化率预测模型——RF+LXFV。
明确影响APP广告转化率的关键因素是进行转化率预测的重要前提。根据文献综述, 影响网络广告转化率的主要因素可以归纳为广告特征、用户特征、商品特征和情境特征4大类。APP广告作为一种重要的网络广告形式, 同样受到这4类因素的影响。
(1) 广告特征
广告特征反映广告在展现形式、内容和广告投放者等诸多方面的属性, 能够对用户感官与情感体验产生刺激作用, 进而影响用户转化行为。具体而言, 广告特征主要包括:
①展现形式特征: 指广告展现方式所具有的能影响 广告转化率的基本特征, 如广告动态与静态特征、视觉特 征等。
②内容特征: 指广告主要内容所具备的能影响广告转化率的基本特征, 如内容形式、所用素材、角色人物等。
③广告主特征: 指投放广告的商家所具有的能影响广告转化率的基本特征, 如商家所属行业领域、企业规模、经营情况、知名度等。
(2) 用户特征
用户是APP广告的直接受众, 也是转化行为的具体实施者。用户对APP广告的体验与态度在很大程度上影响转化行为[19]。用户的体验与态度除了受广告特征的影响外, 还会受到用户自身因素的影响, 如用户的年龄、性别以及用户对APP广告的偏好和对广告营销商品的需求等。具体可分为三种:
①属性特征: 包括用户的年龄、性别、学历、职业、婚恋状态、常住地等背景信息。
②偏好特征: 反映用户对某类APP广告的喜好程度, 一般通过用户点击广告的行为表现。
③需求特征: 反映用户对广告所营销的某类商品或服务的具体需求, 一般通过用户点击广告后的购买或使用行为表现。
(3) 商品特征
商品(或服务)是APP广告营销的对象, 商品外观、类型、功能、价格等属性特征是影响用户需求与消费行为的主要因素。用户在点击APP广告后往往会跳转到商品详情页面, 仔细了解商品的各类特征, 从而做出购买决策。因此, 商品特征对用户点击后的消费转化行为有着更直接的影响。
(4) 情境特征
在移动网络环境下, APP广告具有更强的情境依赖性, 可随情境变化动态改变展现形式、播放方式与呈现内容, 帮助广告主开展个性化与精准化营销, 刺激用户产生更多的转化行为。APP广告的情境特征主要包括两类:
①广告位特征: 表示广告在APP软件中展示的具体位置, 如启动页广告、弹出页广告、通栏位广告等。
②用户情境特征: 表示用户在浏览、点击广告时所处的地理位置、时间、网络环境以及使用的移动终端设备等特征。
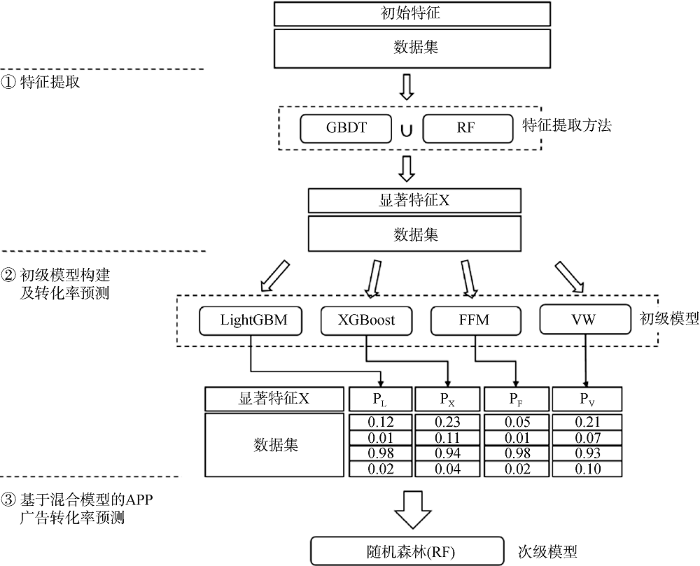
现有的广告点击率和转化率预测方法往往只采用一种或两种机器学习算法, 在高维特征提取、稀疏 数据处理、非线性关系挖掘等问题上存在很大的局限性[20]。鉴于此, 本文在综合多种机器学习算法的基础上, 提出APP广告转化率预测的混合模型, 其主要原理如图1所示。使用梯度提升决策树(GBDT)[21]和随机森林算法(RF)[22]从样本中提取对APP广告转化率有显著影响的关键特征X; 使用LightGBM、XGBoost[23]、FFM[11]和VW[24] 4种机器学习算法构建初级模型, 分别预测每条样本的广告转化概率P; 再将得到的广告转化概率预测结果P与提取到的显著特征X输入到RF构建的次级模型中用于最终训练。
(1) 特征提取
从繁杂的因素中提取对用户转化行为具有显著影响的关键特征, 是预测广告转化率的重要基础。随着APP广告的数据维度不断提高, 通过机器学习方法进行特征提取逐渐成为一种重要手段。本文使用GBDT和RF两种机器学习算法, 提取影响APP广告转化率的显著特征。通过对样本的初始特征集进行训练和预测, 可计算出各项特征对广告转化率的影响权重, 通过权重排序提取前N个特征作为显著特征, 用于模型构建。
(2) 初级模型构建及转化率预测
确定影响APP广告转化率的显著特征后, 使用由LightGBM、XGBoost、FFM和VW 4种机器学习算法构建的初级模型对数据集进行第一轮训练, 预测每条样本在不同算法下的广告转化率。
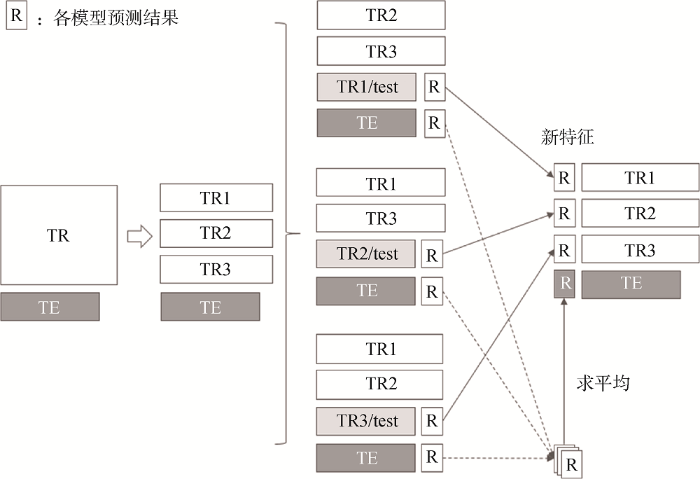
①将样本数据划分为训练集TR和测试集TE两个部分, 并将TR平均分为三组, 记为{TR1, TR2, TR3};
②将三组训练数据两两组合得到{TR2, TR3}、{TR1, TR3}、{TR1, TR2}, 用于4个初级模型的训练;
③分别预测每组测试集({TR1/test, TE}、{TR2/test, TE}、{TR3/test, TE})的广告转化率;
④合并{TR1/test, TR2/test, TR3/test}的预测结果, 得到训练集TR中所有样本在4种不同算法下求得的广告转化率;
⑤对测试集TE的预测结果求平均值, 得到测试集TE的广告转化率预测结果。
通过这种方法既能得到所有样本在4种算法下的广告转化率, 又能避免测试集数据用于训练而影响预测科学性。数据集的划分和预测结果的合并过程如图2所示。
(3) 基于混合模型的APP广告转化率预测
将初级模型求得的4个广告转化率预测结果与样本数据集共同用于基于RF算法的次级模型中, 训练和预测APP广告转化率。相对于LightGBM、XGBoost、FFM、VW等复杂的机器学习算法, RF的计算复杂度 较低, 收敛较快, 适合最后的模型训练和预测。将提 取的显著特征X构成的数据集和由初级模型得到的 广告转化率预测值PL、PX、PF、PV输入基于RF 算法的次级模型中进行训练, 得到训练后的最终预测模型, 将其应用于APP广告转化率预测, 得到最终预测值。将初级模型的预测结果代入次级模型训练, 能够进一步提高RF算法的预测性能, 使决策树快速收敛, 在提高模型预测精度的同时也极大地提高了预测效率。
本文样本数据来源于2017年腾讯社交广告大赛①(①http://algo.tpai.qq.com)。该赛事面向国内外高校大学生, 以移动APP广告为研究对象, 要求参赛者利用大赛提供的真实广告数据预测广告转化率, 以优化广告投放效果, 提升广告投资回报率。大赛提供的腾讯社交广告相关特征数据包括广告特征数据(广告主ID、推广计划ID、广告ID和素材ID)、用户特征数据(用户ID、年龄、性别、用户是否已安装该APP、用户安装同类APP的个数、用户点击该APP广告的次数等)、APP特征数据(APPID、APP分类和APP平台)、情境特征数据(广告位ID、推广平台ID、广告位类型、联网方式和运营商), 并针对每条数据样本给出用户转化行为数据(转化记为1, 未转化记为0)作为预测标签。
本文主要采用Log函数与Sigmoid函数对数据进行归一化处理。首先应用Log函数将特征值归到 [0, 10], 再应用Sigmoid函数将特征值归到[0, 1], 变换函数如公式(1)所示。此外, 对于用户年龄、学历、常住地、籍贯、APP分类、广告位类型、联网方式等取值范围较小的特征, 采用最大值-最小值法进行数据归一化处理。
$f\text{(}x\text{)}=1/(1+\exp (-\log (x)))$ (1)
经过数据预处理, 最终得到844 341条APP广告数据。选取90%的数据作为训练集, 其余10%作为测试集, 正样本(点击后转化)与负样本(点击后未转化)分布情况如表1所示。
表1 样本分布情况
| 数据集 | 正样 本数(条) | 负样 本数(条) | 样本 总数(条) | 正样本 占比 |
|---|---|---|---|---|
| 训练集 | 27 236 | 732 671 | 759 907 | 0.0358 |
| 测试集 | 2 414 | 82 020 | 84 434 | 0.0285 |
通过Python调用scikit-learn算法包中的RF和GBDT, 对初始特征进行筛选, 确定影响广告转化率的显著特征。在默认参数基础上, 设定RF子模型的数量为32, 树最大深度为40, 节点分裂时最大的特征数为8, 线程数为8; 设定GBDT模型最大迭代次数为100, 收缩步长为1, 子采样为0.8。通过计算特征权重并对结果进行排序, 分别从两个模型中提取出前10个特征建立特征集如表2所示。通过计算两个特征集的并集, 确立13个影响APP广告转化率的显著特征如表3所示。
表2 基于RF和GBDT算法得到的两个特征集
| 随机森林(RF) | 梯度提升决策树(GBDT) | ||
|---|---|---|---|
| 特征 | 权重 | 特征 | 权重 |
| clickCount | 0.120 | advertiserID | 0.111 |
| positionID | 0.098 | positionID | 0.091 |
| residence | 0.086 | creativeID | 0.088 |
| age | 0.067 | adID | 0.086 |
| adID | 0.064 | appCategory | 0.080 |
| appCount | 0.057 | clickCount | 0.080 |
| positionType | 0.048 | campaignID | 0.070 |
| appID | 0.048 | connectionType | 0.068 |
| connectionType | 0.045 | age | 0.063 |
| creativeID | 0.043 | appID | 0.060 |
表3 APP广告转化率预测显著特征表
| 特征 种类 | 特征名 | 变量名 | 变量解释 |
|---|---|---|---|
| 广告 特征 | 广告主ID | advertiserID | 唯一标识一个特定的广告投放商家 |
| 推广计划ID | campaignID | 唯一标识一个特定的广告推广计划 | |
| 广告ID | adID | 唯一标识一个特定的广告 | |
| 素材ID | creativeID | 唯一标识广告中使用的素材 | |
| 用户 特征 | 年龄 | age | 用户的年龄, 取值范围[0, 80], 其中0表示未知 |
| 常住地 | residence | 用户长期居住地, 千位和百位表示省份, 十位和个位表示省内城市, 编号0表示未知 | |
| 用户安装同类APP的个数 | appCount | 用户通过广告推荐下载并安装过的相同类型的APP数量, 由用户安装流水表统计得到 | |
| 用户点击该APP广告的次数 | clickCount | 用户点击当前广告的次数, 由用户点击记录表统计得到 | |
| 商品 特征 | APPID | appID | 广告中推广的APP编号, 不同广告可指向同一个APP |
| APP分类 | appCategory | APP开发者设定的APP类目标签, 分为两层, 使用3位数字编码, 百位数表示一级类目, 十位和个位表示二级类目 | |
| 情境 特征 | 广告位ID | positionID | 广告在APP中投放的具体位置编号 |
| 广告位类型 | positionType | 人工定义的一套广告位分类标准, 如启动屏广告位、Banner广告位等 | |
| 联网方式 | connectionType | 用户所使用的移动终端设备当前的联网方式, 包括2G、3G、4G、WiFi和未知 |
本文使用LightGBM、XGBoost、FFM、VW和RF机器学习算法分别对初级模型和次级模型进行训练。通过参数调整, 设定XGBoost的决策树最大深度为15, 采用的分类方法为逻辑回归, 收缩步长为0.02, 随机种子数为999; 设定FFM的迭代次数为10, 惩罚参数为0.0001, 隐变量个数为15; 设定RF的子模型数量为32, 树最大深度为40, 节点分裂时最大的特征数为8; LightGBM和VW则使用默认参数。在此基础上, 使用样本中的训练集训练由以上5种机器学习算法分别构建的5个单一预测模型, 将测试集的预测结果与真实数据对比, 计算Log-Loss值[25]和AUC值评估预测准确性[26]。
按照RF+LXFV预测模型构建流程, 使用同样的参数设置对训练集进行训练, 将测试集的预测结果与真实数据对比, 计算得到RF+LXFV模型的Log-Loss值和AUC值。
表4比较了5个单一模型与RF+LXFV模型的Log-Loss值和AUC值。可以看出, 在5个模型中, RF模型的Log-Loss值最低, 约为0.113; XGBoost模型的AUC值最高, 约为0.775, 说明相对于其他单一模型, RF模型和XGBoost模型的预测能力更优。本文构建的RF+LXFV模型Log-Loss值约为0.105, AUC值约为0.786, 无论从Log-Loss值还是AUC值上来看, RF+LXFV模型的精度与性能都更好, 这证明了综合多种算法构建的模型在APP广告转化率预测的准确性与有效性上要优于单一算法构建的模型。
表4 各模型的Log-Loss值和AUC值对照表
| 预测模型 | Log-Loss | AUC |
|---|---|---|
| LightGBM | 0.11648306368 | 0.74722242761 |
| XGBoost | 0.12105592334 | 0.77485575487 |
| FFM | 0.12200810476 | 0.69786947007 |
| VW | 0.14191362554 | 0.69648447941 |
| RF | 0.11342799887 | 0.77356316492 |
| RF+LXFV | 0.10512076579 | 0.78637268084 |
此外, 正样本累积分布是衡量模型性能的另一个重要指标[27]。将RF+LXFV模型预测的转化率结果按照降序排序并均分成10组, 每组作为一个等级计算出正样本累计分布表, 如表5所示。RF+LXFV模型在第5级时已覆盖83.7%的正样本, 说明RF+LXFV模型在APP广告转化率预测上有非常出色的表现。
表5 RF+LXFV正样本累积分布
| 级别 | 正样本数 | 负样本数 | 样本总数 | 正样本累计分布 |
|---|---|---|---|---|
| 1 | 1 143 | 7 302 | 8 445 | 47.3% |
| 2 | 304 | 8 139 | 8 443 | 59.9% |
| 3 | 226 | 8 218 | 8 444 | 69.3% |
| 4 | 185 | 8 258 | 8 443 | 76.9% |
| 5 | 164 | 8 280 | 8 444 | 83.7% |
| 6 | 141 | 8 302 | 8 443 | 89.6% |
| 7 | 101 | 8 342 | 8 443 | 93.7% |
| 8 | 88 | 8 356 | 8 444 | 97.4% |
| 9 | 45 | 8 398 | 8 443 | 99.2% |
| 10 | 17 | 8 425 | 8 442 | 100% |
移动互联网广告的快速发展在给广告主和APP运营商带来经济效益与社会效益的同时, 也给互联网广告业带来了机遇和挑战。衡量APP广告投放效果并有效提高其转化率是当前网络广告研究领域的热点。针对APP广告的复杂特性, 采用机器学习技术对广告转化率进行分析和预测, 不仅能够帮助广告主明确广告受众、广告位置、推广计划等因素对广告投放效果的具体影响, 调整广告推广方案, 还能指导APP运营商合理制定广告价格, 优化广告位布局, 同时也能给APP用户带来更好的广告体验, 刺激转化行为。本文采用多种机器学习算法构建RF+LXFV混合模型, 对APP广告转化率进行预测, 通过使用腾讯社交广告大赛提供的真实广告数据, 对比混合预测模型与单一预测模型的准确性与有效性, 发现混合模型能够更精准地预测APP广告转化率。本研究的不足之处在于未充分考虑广告转化延迟对转化率预测的影响。在今后的研究中, 可以从转化延迟性问题上进行拓展, 优化现有模型, 进一步提高APP广告转化率预测的精确度和时效性。
赵杨: 提出研究思路, 设计研究方案, 论文最终版本修订;
袁析妮: 文献调研, 论文起草;
袁析妮, 陈亚文: 数据预处理与分析;
武立强: 模型构建与数据预处理。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: yangzhao_0813@whu.edu.cn。
[1] 赵杨, 袁析妮, 陈亚文, 武立强. 腾讯社交广告大赛数据.xls. 2017年腾讯社交广告大赛数据.
| [1] |
网络广告规模2902.7亿元, 电商广告首超搜索居榜首 [OL]. [The Scale of Online Advertising is 290.27 Billion Yuan, Occupy a Layer Proportion than Searchads [OL]. [ |
| [2] |
移动互联网时代的APP广告浅析 [J].
2007年,苹果公司前首席执行官Steve Jobs推出了第一代iPhone.作为一款真正意义上的智能触屏手机,在极大程度上带动了整个手机行业的革新和移动互联网的蓬勃发展.人们使用网络的习惯,逐渐从传统使用PC电脑上网,转变为更加依赖移动设备上网.随着平板电脑和智能手机的普及,Wi-Fi、3G、4G对流量限制的解放,以及苹果公司App Store生态系统带来的全新交互体验促使APP受众和APP开发者大幅度增加,人们逐渐习惯于使用APP客户端上网.而APP涉及的领域,从最初的工具型APP到娱乐、出行、购物等无所不及,APP成为人们工作和生活中不可或缺的一部分.对于APP开发者,需要一种将流量变现的方式,而对于广告主,广告投放需要随消费者的注意力而迁移.因此,APP成为广告主投放广告炙手可热的新平台,APP广告也随之兴起.
Analysis of APP Advertising in the Age of Mobile Internet [J].
2007年,苹果公司前首席执行官Steve Jobs推出了第一代iPhone.作为一款真正意义上的智能触屏手机,在极大程度上带动了整个手机行业的革新和移动互联网的蓬勃发展.人们使用网络的习惯,逐渐从传统使用PC电脑上网,转变为更加依赖移动设备上网.随着平板电脑和智能手机的普及,Wi-Fi、3G、4G对流量限制的解放,以及苹果公司App Store生态系统带来的全新交互体验促使APP受众和APP开发者大幅度增加,人们逐渐习惯于使用APP客户端上网.而APP涉及的领域,从最初的工具型APP到娱乐、出行、购物等无所不及,APP成为人们工作和生活中不可或缺的一部分.对于APP开发者,需要一种将流量变现的方式,而对于广告主,广告投放需要随消费者的注意力而迁移.因此,APP成为广告主投放广告炙手可热的新平台,APP广告也随之兴起.
|
| [3] |
Personalized Click Prediction in Sponsored Search [C]// |
| [4] |
CTR Prediction for Contextual Advertising: Learning-to-Rank Approach [C]// |
| [5] |
基于LASSO变量选择方法的网络广告点击率预测模型研究 [J].https://doi.org/10.13860/j.cnki.sltj.20160922-022 URL [本文引用: 1] 摘要
与传统的的媒体营销模式相比,搜索引擎广告因其精准和投入低等特点获得巨大成功。但已有的搜索引擎广告点击率模型不能有效解决数据量大及特征维度高的问题,使预测结果的准确性大打折扣。本文构建了一种基于LASSO变量选择方法的广告点击率预测模型,能有效克服现有广告点击率模型在处理数据高维性和稀疏性方面的不足。利用某公司的竞价数据对模型进行验证,结果表明影响广告点击率的关键因素是广告关键词中的商标信息、地域信息和每点击成本。该研究结果为企业制定搜索引擎广告营销策略提供一定的理论依据。
Research on Search Engine Advertisement Click Rate Prediction Model Based on LASSO Variable Selection Method [J].https://doi.org/10.13860/j.cnki.sltj.20160922-022 URL [本文引用: 1] 摘要
与传统的的媒体营销模式相比,搜索引擎广告因其精准和投入低等特点获得巨大成功。但已有的搜索引擎广告点击率模型不能有效解决数据量大及特征维度高的问题,使预测结果的准确性大打折扣。本文构建了一种基于LASSO变量选择方法的广告点击率预测模型,能有效克服现有广告点击率模型在处理数据高维性和稀疏性方面的不足。利用某公司的竞价数据对模型进行验证,结果表明影响广告点击率的关键因素是广告关键词中的商标信息、地域信息和每点击成本。该研究结果为企业制定搜索引擎广告营销策略提供一定的理论依据。
|
| [6] |
基于特征学习的广告点击率预估技术研究 [J].https://doi.org/10.11897/SP.J.1016.2016.00780 URL [本文引用: 1] 摘要
搜索广告中的点击率预估问题在信息检索和机器学习等领域一直是研究的热点.目前通过设计特征提取方案获得特征和针对用户点击行为建模等方法,并没有充分考虑广告数据具有的高维稀疏性、特征之间存在高度非线性关联的特点,致使信息利用不充分.为了降低数据稀疏性和充分挖掘广告数据中隐藏的规律,该文提出了面向广告数据的稀疏特征学习方法.该方法基于张量分解实现特征降维,并充分利用深度学习技术刻画数据中的非线性关联,以解决高维稀疏广告数据的特征学习问题,实验结果验证了文中提出的方法能够有效地提升广告点击率的预估精度,达到了预期效果.
Research on Advertising Click-Through Rate Estimation Based on Feature Learning [J].https://doi.org/10.11897/SP.J.1016.2016.00780 URL [本文引用: 1] 摘要
搜索广告中的点击率预估问题在信息检索和机器学习等领域一直是研究的热点.目前通过设计特征提取方案获得特征和针对用户点击行为建模等方法,并没有充分考虑广告数据具有的高维稀疏性、特征之间存在高度非线性关联的特点,致使信息利用不充分.为了降低数据稀疏性和充分挖掘广告数据中隐藏的规律,该文提出了面向广告数据的稀疏特征学习方法.该方法基于张量分解实现特征降维,并充分利用深度学习技术刻画数据中的非线性关联,以解决高维稀疏广告数据的特征学习问题,实验结果验证了文中提出的方法能够有效地提升广告点击率的预估精度,达到了预期效果.
|
| [7] |
Simple and Scalable Response Prediction for Display Advertising [J].https://doi.org/10.1145/2532128 URL [本文引用: 1] 摘要
Clickthrough and conversation rates estimation are two core predictions tasks in display advertising. We present in this article a machine learning framework based on logistic regression that is specifically designed to tackle the specifics of display advertising. The resulting system has the following characteristics: It is easy to implement and deploy, it is highly scalable (we have trained it on terabytes of data), and it provides models with state-of-the-art accuracy.
|
| [8] |
Scalable Distributed Inference of Dynamic User Interests for Behavioral Targeting [C]// |
| [9] |
Predicting Clicks: Estimating the Click-through Rate for New Ads [C]// |
| [10] |
基于张量分解的实时竞价广告响应预测方法[D] .Response Prediction on Real Time Bidding via Tensor Factorization[D]. |
| [11] |
Field-aware Factorization Machines for CTR Prediction [C]// |
| [12] |
大数据平台下的互联网广告点击率预估模型 [J].https://doi.org/10.16208/j.issn1000-7024.2017.09.038 URL [本文引用: 1] 摘要
现存的广告点击率预估模型提取的特征维数较多,数据量较大,使得传统平台在应用时压力大,反应时间较长。针对这一问题,提出梯度提升决策树与因子分解机相结合的广告点击率预估模型,将基础特征库里的连续特征离散化,利用梯度提升决策树对输入特征进行非线性转化,利用Hadoop大数据平台进行分布式训练,高效快速地提取出高层特征,利用因子分解机融合模型解决不均衡分类问题,利用AUC指标对模型进行评估,与常用广告点击率预估模型进行对比。实验结果表明,大数据平台以及并行化的应用使特征提取更加高效,模型解决了分类不均问题,具有更好的广告点击率预估效果。
Internet CTR Prediction Model on Big Data Platform [J].https://doi.org/10.16208/j.issn1000-7024.2017.09.038 URL [本文引用: 1] 摘要
现存的广告点击率预估模型提取的特征维数较多,数据量较大,使得传统平台在应用时压力大,反应时间较长。针对这一问题,提出梯度提升决策树与因子分解机相结合的广告点击率预估模型,将基础特征库里的连续特征离散化,利用梯度提升决策树对输入特征进行非线性转化,利用Hadoop大数据平台进行分布式训练,高效快速地提取出高层特征,利用因子分解机融合模型解决不均衡分类问题,利用AUC指标对模型进行评估,与常用广告点击率预估模型进行对比。实验结果表明,大数据平台以及并行化的应用使特征提取更加高效,模型解决了分类不均问题,具有更好的广告点击率预估效果。
|
| [13] |
基于转化的互联网广告技术研究 [J].https://doi.org/10.3969/j.issn.1003-0077.2014.02.022 URL Magsci [本文引用: 2] 摘要
基于转化的互联网广告方式根据用户在浏览广告后的购买等行为对广告效果进行衡量,极大利用了互联网广告的独特优势,成为了未来互联网广告发展的趋势。该文介绍了基于转化的互联网广告的运行方式,分析了其行业应用,进一步地总结了该领域的当前研究成果,包括基于转化的竞价机制设计、转化率预测、基于转化的广告排序等。最后在此基础上,分析了存在的问题并展望未来的研究方向。
A Survey of Conversion-based Internet Advertising Model [J].https://doi.org/10.3969/j.issn.1003-0077.2014.02.022 URL Magsci [本文引用: 2] 摘要
基于转化的互联网广告方式根据用户在浏览广告后的购买等行为对广告效果进行衡量,极大利用了互联网广告的独特优势,成为了未来互联网广告发展的趋势。该文介绍了基于转化的互联网广告的运行方式,分析了其行业应用,进一步地总结了该领域的当前研究成果,包括基于转化的竞价机制设计、转化率预测、基于转化的广告排序等。最后在此基础上,分析了存在的问题并展望未来的研究方向。
|
| [14] |
基于贝叶斯方法的网络广告预测模型研究[D] .Online Advertising Prediction Model Based on Bayesian Method[D] . |
| [15] |
时间敏感的转化率预测和归因分析[D] .Time-aware Conversion Prediction and Attribution Analysis[D] . |
| [16] |
移动互联网时代移动广告定价模型研究——以腾讯公司微信公众账号广告为例[D] .Mobile Advertising Pricing Model Researching of Mobile Internet Era——With Tencent Micro-Channel Public Account Ads[D] . |
| [17] |
Research on CTR Prediction for Contextual Advertising Based on Deep Architecture Model [J]. |
| [18] |
基于用户相似度和特征分化的广告点击率预测研究 [J].Study on Advertising Click-through Rate Prediction Based on User Similarity and Feature Differentiation [J]. |
| [19] |
基于联合聚类与用户特征提取的协同过滤推荐算法 [J].
协同过滤利用与目标用户相似性较高的邻居对其他产品的评价来预测目标用户对特定产品的喜好程度,用户间的相似性定义至关重要。传统协同过滤算法定义相似性时不考虑用户偏好,为了解决这一问题,本文提出基于联合聚类的协同过滤算法。该算法利用联合聚类识别用户偏好,定义用户偏好相似性。当可用数据还包括用户的属性信息时,算法提取有共同偏好的用户的公共特征,进一步定义基于属性的相似性,结合属性相似性与打分相似性产生推荐。实验用MovieLens数据验证推荐算法的准确性,实验结果表明本文算法可以处理极度稀疏数据,且预测的打分更加准确,推荐排名靠前的电影更受用户喜爱。
Collaborative Filtering Algorithm Based on Bi-clustering and User Attribution Extraction [J].
协同过滤利用与目标用户相似性较高的邻居对其他产品的评价来预测目标用户对特定产品的喜好程度,用户间的相似性定义至关重要。传统协同过滤算法定义相似性时不考虑用户偏好,为了解决这一问题,本文提出基于联合聚类的协同过滤算法。该算法利用联合聚类识别用户偏好,定义用户偏好相似性。当可用数据还包括用户的属性信息时,算法提取有共同偏好的用户的公共特征,进一步定义基于属性的相似性,结合属性相似性与打分相似性产生推荐。实验用MovieLens数据验证推荐算法的准确性,实验结果表明本文算法可以处理极度稀疏数据,且预测的打分更加准确,推荐排名靠前的电影更受用户喜爱。
|
| [20] |
基于随机森林算法的推荐系统的设计与实现 [J].
如今随着推荐系统势头的加强,如何对用户行为进行快速而准确的预测变得愈加重要。通过分析网上社区帖子的点赞和点踩数据,实现了基于随机森林的推荐系统。该系统将实际问题转化为分类模型,并实现了数据处理、特征提取和参数调整。同时,该系统还对用户浏览帖子后是否产生交互行为进行了预测。最后,通过实验仿真并利用F1值对实验结果进行评估。实验结果证明了系统的有效性和效率。
Design and Implementation of Recommender System Based on Random Forest Algorithm [J].
如今随着推荐系统势头的加强,如何对用户行为进行快速而准确的预测变得愈加重要。通过分析网上社区帖子的点赞和点踩数据,实现了基于随机森林的推荐系统。该系统将实际问题转化为分类模型,并实现了数据处理、特征提取和参数调整。同时,该系统还对用户浏览帖子后是否产生交互行为进行了预测。最后,通过实验仿真并利用F1值对实验结果进行评估。实验结果证明了系统的有效性和效率。
|
| [21] |
互联网广告点击率预估模型中特征提取方法的研究与实现 [J].https://doi.org/10.3969/j.issn.1001-3695.2017.02.003 URL [本文引用: 1] 摘要
互联网广告是一个具有上千亿元规模的市场,广告的点击率(CTR)是互联网广告投放效果的重要指标。在广告点击率预估模型中,特征提取是关键因素,特征的好坏直接影响到最终模型的效果。针对如何提高广告点击率预估效率问题,在Hadoop大数据平台环境中,提出了基于梯度提升决策树(gradient boost decision tree,GBDT)模型的多维特征提取方法。该方法利用原始数据构建多维基础特征库,并将基础特征库中除ID类特征以外的其余特征输入GBDT模型进行特征刷选,得到高层特征,进一步进行分类。该方法的使用不仅减少了特征提取的人工成本和时间成本,也在很大程度上提升了模型的精度。
Research and Implementation of Feature Extraction Methods on Internet CTR Prediction Model [J].https://doi.org/10.3969/j.issn.1001-3695.2017.02.003 URL [本文引用: 1] 摘要
互联网广告是一个具有上千亿元规模的市场,广告的点击率(CTR)是互联网广告投放效果的重要指标。在广告点击率预估模型中,特征提取是关键因素,特征的好坏直接影响到最终模型的效果。针对如何提高广告点击率预估效率问题,在Hadoop大数据平台环境中,提出了基于梯度提升决策树(gradient boost decision tree,GBDT)模型的多维特征提取方法。该方法利用原始数据构建多维基础特征库,并将基础特征库中除ID类特征以外的其余特征输入GBDT模型进行特征刷选,得到高层特征,进一步进行分类。该方法的使用不仅减少了特征提取的人工成本和时间成本,也在很大程度上提升了模型的精度。
|
| [22] |
集成随机森林的分类模型 [J].https://doi.org/10.3969/j.issn.1001-3695.2015.06.005 URL [本文引用: 1] 摘要
与集成学习相比,针对单个分类器不能获得相对较高而稳定的准确率的问题,提出一种分类模型.该模型可集成多个随机森林,并以带阈值的多数投票法作为结合方法;模型实现主要分为建立集成分类模型、实例初步预测和结合分析三个层次.MapReduce编程方式实现的分类模型以P2P流量识别为例,分别与单个随机森林和集成其他算法进行对比,实验表明提出模型能获得更好的P2P流量识别综合分类性能,该模型也为二类型分类提供了一种可行的参考方法.
Classification Model Based on Ensemble Random Forests [J].https://doi.org/10.3969/j.issn.1001-3695.2015.06.005 URL [本文引用: 1] 摘要
与集成学习相比,针对单个分类器不能获得相对较高而稳定的准确率的问题,提出一种分类模型.该模型可集成多个随机森林,并以带阈值的多数投票法作为结合方法;模型实现主要分为建立集成分类模型、实例初步预测和结合分析三个层次.MapReduce编程方式实现的分类模型以P2P流量识别为例,分别与单个随机森林和集成其他算法进行对比,实验表明提出模型能获得更好的P2P流量识别综合分类性能,该模型也为二类型分类提供了一种可行的参考方法.
|
| [23] |
Deep Embedding Forest: Forest-based Serving with Deep Embedding Features [C]// |
| [24] |
面向大规模服务性能预测的在线学习方法 [J].Online Learning Approach for Performance Prediction in Large-Scale Service Computing [J]. |
| [25] |
Asymptotic Log-Loss of Prequential Maximum Likelihood Codes [C]// |
| [26] |
AUC: A Misleading Measure of the Performance of Predictive Distribution Models [J].https://doi.org/10.1111/j.1466-8238.2007.00358.x URL [本文引用: 1] 摘要
The area under the receiver operating characteristic (ROC) curve, known as the AUC, is currently considered to be the standard method to assess the accuracy of predictive distribution models. It avoids the supposed subjectivity in the threshold selection process, when continuous probability derived scores are converted to a binary presence bsence variable, by summarizing overall model performance over all possible thresholds. In this manuscript we review some of the features of this measure and bring into question its reliability as a comparative measure of accuracy between model results. We do not recommend using AUC for five reasons: (1) it ignores the predicted probability values and the goodness-of-fit of the model; (2) it summarises the test performance over regions of the ROC space in which one would rarely operate; (3) it weights omission and commission errors equally; (4) it does not give information about the spatial distribution of model errors; and, most importantly, (5) the total extent to which models are carried out highly influences the rate of well-predicted absences and the AUC scores.
|
| [27] |
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}