1 引 言
科技文献是记录科学技术知识或信息的载体, 是科研人员在科学实践中总结出的智慧结晶, 能够反映出科学领域的发展状况。近年来, 随着计算机技术与信息技术的不断发展, 科技文献等文本信息呈爆炸式增长, 与日俱增的海量信息与科研人员有限精力之间的矛盾日益凸显, 如何从数量庞大的文献资源中识别出某学科领域的主题结构以及其演化趋势, 从而把握该领域的研究重点和热点, 从总体上了解其发展趋势, 成为科研人员亟待解决的问题之一。
科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果。主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法。之后, 研究人员在LDA主题模型的基础上进行大量扩展研究。其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象。ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析。同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题。综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能。
本文将运用改进的ToT主题模型 (Content Similarity-Topics over Time, CSToT)进行文献主题发现和演化分析实验, 通过引入新的主题强度计算方法获取更具有区分度的主题强度值, 同时引入夹角余弦相似度算法构建主题内容上的演化体系, 以解决ToT模型不能分析主题内容演化的问题。选取国内情报学领域作为研究对象, 从主题强度和文献内容两个层面剖析该领域研究主题结构及其演化发展走势, 揭示其研究特点。
2 模型构建
2.1 Topics over Time模型
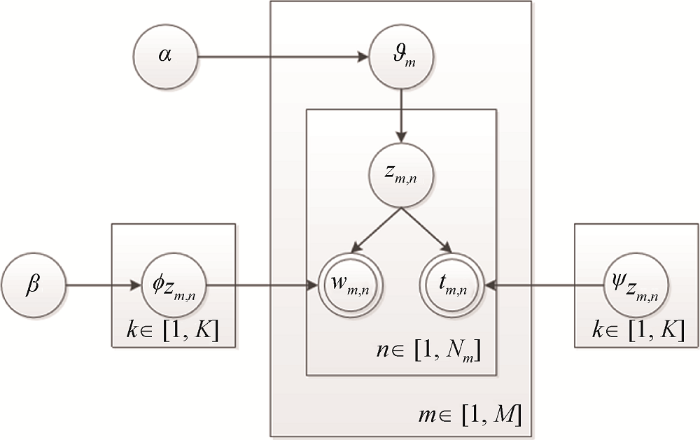
LDA是一个文档主题生成模型, 也称为三层(文档, 主题, 词)贝叶斯概率模型。该模型假设文档是由若干主题以一定概率混合而成, 而主题是词的概率分布。ToT模型[13 ] 是在LDA模型的基础上提出的, 是一个文档主题与时间戳的生成模型, 如图1 [13 ] 所示。
(1) 对于每个主题$k\in [1,K]$, 根据${{\phi }_{ k}}\text{ }\!\!\tilde{\ }\!\!\text{ }Dir(\beta )$, 得到主题k 上词汇的多项式分布参数${{\phi }_{\text{ }k}}$;
(2) 对于每篇科技文献$m\in [1,M]$: 根据${{\vartheta }_{m}}\text{ }\!\!\tilde{\ }\!\!\text{ }Dir(\alpha )$, 得到文献m 上主题的多项式分布参数${{\vartheta }_{m}}$;
对于在文献m 中的每个词n ∈[1, Nm ]:
①根据多项式分布${{\vartheta }_{m}}$随机得到一个主题zm , n
②根据多项式分布${{\phi }_{\text{ }{{z}_{m,n}}}}$随机得到一个词汇wm , n
③根据Beta分布${{\psi }_{{{z}_{m,n}}}}$随机得到一个时间戳tm , n
与其他主题演化模型不同, ToT模型不依赖于马尔可夫假设, 而是认为每个主题与时间戳的连续分布相关联, 文档中主题的混合分布受到词共现和文档时间戳的共同影响, 有效地解决了时间粒度选取问题。
2.2 CSToT模型设计
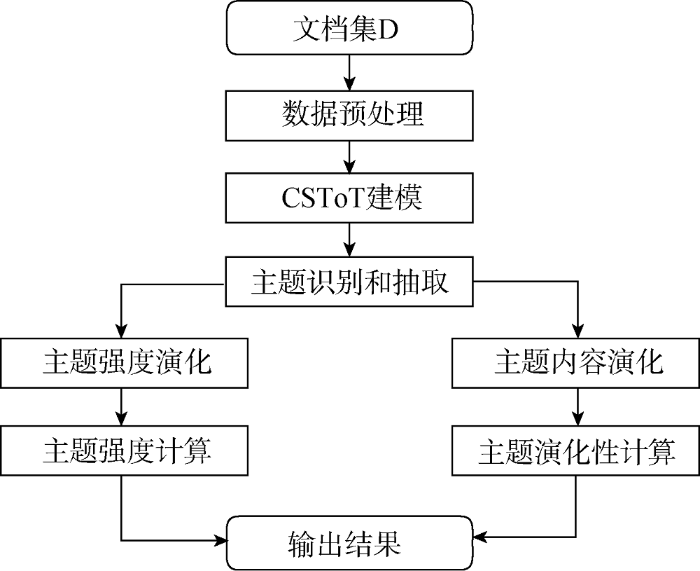
本文基于Python语言完成主题识别和演化分析的整个实验过程。基于CSToT模型分析国内情报学研究主题及发展变化过程, 模型流程框架如图2 所示。
(1) 主题强度演化计算
主题是关键词的集合, 主题Z 在某个时间区间t 中的强度取决于该主题关联词的强度之和, 可由公式(1)[18 ] 计算得到。
${{S}_{z,t}}=\frac{\mathop{\sum }^{}\ n({{w}_{i,t}})\rho ({{w}_{i}})}{\mathop{\sum }^{}\ \rho ({{w}_{i}})}$ (1)
其中, ${{S}_{z,t}}$表示主题Z 在时间区间t 的强度值, $n({{w}_{i,t}})$表示该主题关联词wi 在时间区间t 中的频数, $\rho ({{w}_{i}})$是主题关联词wi 的权重。再对其进行归一化处理, 可由公式(2)计算得出(K 为主题数目)。
${{{S}'}_{z,t}}=\frac{{{S}_{z,t}}}{\mathop{\sum }_{z=1}^{K}{{S}_{z,t}}}$ (2)
(2) 主题内容演化计算
采用夹角余弦相似度算法构建不同年度主题之间的演化关系, 设置主题演化的阈值, 两个主题间的相似度大于阈值说明具有一定的演化关系, 小于阈值则说明不具备演化关系。根据不同年度主题的相似度, 构建主题演化体系。夹角余弦相似度计算如公式(3)[19 ] 所示。
$sim\text{(}{{z}_{t,i}},{{z}_{t+n,j}}\text{)}=\frac{\mathop{\sum }_{{{w}_{k}}}p\text{(}{{w}_{k}}\left| {{z}_{t,i}}\text{)}p({{w}_{k}} \right|{{z}_{t+n,j}})}{\sqrt{\mathop{\sum }_{{{w}_{k}}}p{{({{w}_{k}}\left| {{z}_{t,i}}{{)}^{2}}\mathop{\sum }_{{{w}_{k}}}p({{w}_{k}} \right|{{z}_{t+n,j}})}^{2}}^{{}}}}$ (3)
其中, zt , i t 时间段的第i 个主题,$p\text{(}{{w}_{k}}\left| {{z}_{t,j}}\text{)} \right.$表示第k 个关键词在t 时间段中第i 个主题上出现的概率, wk 表示第k 个关键词。
3 实证分析
3.1 数据来源
选取CNKI作为数据采集渠道, 并以《情报学报》、《情报资料工作》、《图书情报知识》、《图书与情报》、《现代图书情报技术》、《情报杂志》、《情报科学》、《图书情报工作》、《情报理论与实践》9种情报学领域期刊的学术论文为主要数据来源, 并设置时间跨度为2012年 - 2016年, 去除通讯、书评、会议通知、卷首语等不相关文献后获得12 095篇文献。下载论文题录信息(标题、关键词、作者等), 从中抽取并整合论文关键词作为主题识别的数据源, 具体如表1 所示。
3.2 数据预处理
基于Python, 选择哈尔滨工业大学停用词表对文本数据集进行去除停用词操作, 共获得46 700个关键词。CSToT主题建模时, 主题模型参数的经验值取值为: α =50.0, β =0.1[20 ] , 迭代次数为1 000。选取多个主题数进行实验, 结果发现抽取数据集排名最靠前的10个主题大类, 其概括性最好、冗余度低, 因此模型主题数阈值设为10, 并通过建模得到对应主题的关键词时间序列分布、文本集在某个时间段t 中的各个主题分布概率以及模型的对数似然估计的下界值等参数值。
3.3 困惑度分析
困惑度[21 ] 是衡量主题模型有效性的常用指标之一, 其数值越小, 表明主题模型建模效果越好, 预测能力也越强, 如公式(4)所示。
$Perplexity(D)=\exp \left\{ -\frac{\sum\limits_{d=1}^{M}{\log \ p({{w}_{d}})}}{\sum\limits_{d=1}^{M}{{{N}_{d}}}} \right\}$ (4)
其中, D 为文本集, wd 和Nd 分别为文档d 中的词及词数目。
动态主题模型(Dynamic Topic Model, DTM)是揭示文本主题及其变化的强大工具之一, 通过获取主题的动态特征识别主题结构及其演化关系[22 ] 。本文比较CSToT模型以及DTM模型在不同时间片段的困惑度, 计算结果如图3 所示。
可以发现, CSToT模型在各个时间片段的困惑度都要小于DTM, 说明CSToT模型比DTM效果更佳, 在实际应用中更能清晰表达主题结构及演化关系。
3.4 结果分析
(1) 情报学文献主题识别
基于CSToT模型抽取上述9种期刊在2012年-2016年期间排名靠前的10个主题大类, 每个主题大类下根据研究内容选择与该主题匹配度排名靠前的10个词表示若干小类。具体结果以热力图的形式展示, 与主题匹配度越高的词颜色越深, 如图4 所示。
图4 2012年-2016年国内情报学文献主题结构
国内情报学领域在2012年-2016年期间研究重点集中于“信息服务”、“文献计量学”、“竞争情报”、“知识共享”、“信息检索”、“网络舆情”、“数据挖掘”以及“开放获取”等方面。涉及“信息服务”的有Topic1, Topic4和Topic10。其中, Topic4是关于企业、政府等机构利用信息技术提供服务的研究, 包括“云计算”、“信息管理”、“电子政务”等方面的应用; Topic10是关于信息服务在图书馆中的应用, 包括“数字图书馆”、“移动图书馆”等; 而Topic1描述的是大数据环境下用户对信息服务的体验以及评价, 说明国内学者不仅关注信息服务的具体内容, 也重视服务质量。Topic2主要涉及“文献计量学”研究, 其内容包括“引文分析”、“社会网络分析”、“h指数”、“评价指标”、“期刊评价”等相关的文献计量方法以及应用研究。Topic3主要涉及“企业”、“竞争情报”等情报分析方面的内容以及“突发事件”这类应急管理和风险管理相关的内容。Topic5主要包括“虚拟社区”、“社会化媒体”等网络社区以及“知识共享”等社区用户行为方面的研究。Topic6主要内容是“信息检索”, 包括信息需求以及信息检索技术应用研究。Topic7和Topic9都涉及到“信息传播”问题, Topic7侧重于信息安全以及利用技术手段进行“网络舆情”识别和分析的问题, 而Topic9更重视信息开放获取的研究状况, 其内容包括信息开放过程中涉及到的知识产权、隐私权等法律问题以及“机构知识库”等资源开放和资源共享方面的研究。Topic8主要是关于“数据挖掘”领域的研究。
(2) 主题强度演化
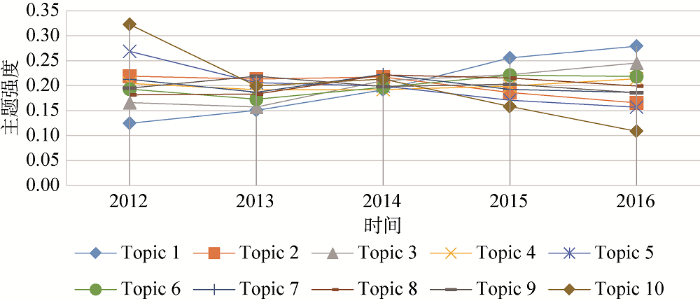
为了总体、直观地展现各主题强度变化趋势, 利用公式(1)和公式(2)计算文本集主题强度值以折线图展示, 得出各主题强度变化规律, 如图5 所示。
图5 2012年-2016年情报学主题强度演化趋势
国内情报学领域文献主题演化趋势分为4个类型: 上升型、下降型、稳定型和波动型。上升型主题说明其从整体上被关注的程度越来越高, 主题变得越来越重要; 下降型主题说明其从整体上被关注的程度越来越低, 主题变得越来越不重要; 稳定型主题说明在某个研究时间区间内该主题被关注程度基本不变, 波动比较小, 主题发展比较稳定, 主题研究程度较为成熟; 波动型主题说明在某个研究时间区间内该主题被关注程度反复变化, 波动比较大。
对2012年-2016年国内情报学主题强度演化分析, 可以看出Topic1、Topic3属于上升型, 总体发展态势良好, 呈现上升趋势, 说明国内学者越来越注重“信息服务质量与评价”以及“竞争情报分析”等方面的研究, 并日趋成熟。Topic5和Topic10属于下降型, 说明近5年关于“知识共享”、“图书馆信息服务”等方面的研究关注度逐年下降, 其重要程度也变得越来越低。Topic2、Topic4、Topic6和Topic8是属于稳定型, 说明国内关于“文献计量学”、“企业信息服务”、“政府信息服务”、“信息检索”、“数据挖掘”等领域的研究趋向稳定, 主题研究程度较为成熟。Topic7和Topic9属于波动型, 说明国内关于“网络舆情”、“开放获取”等方面研究的关注度时高时低。
(3) 主题内容演化
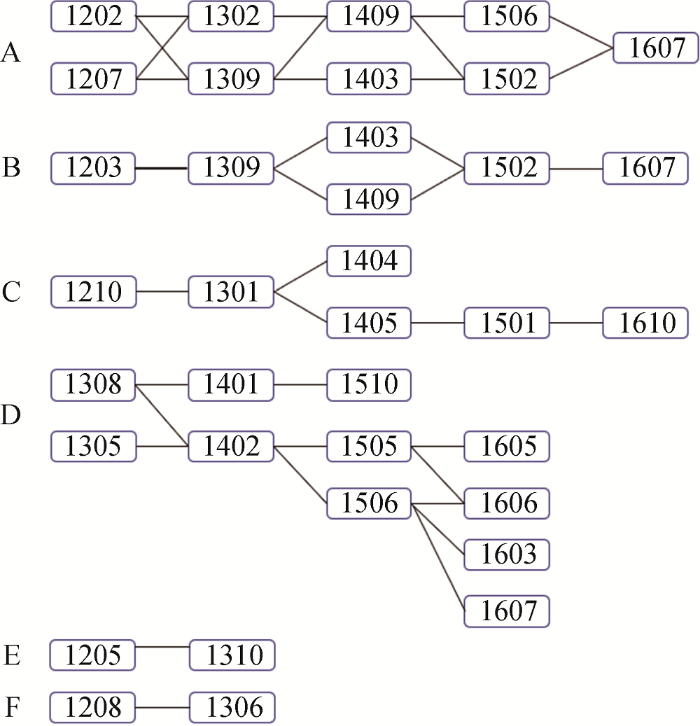
将数据集按时间分区, 分别得到2012年-2016年的数据集, 基于CSToT模型分别对每年度内文本数据集进行主题识别, 每年度抽取出10个主题, 每个主题用对应的编号表示, 例如2012年Topic1用编号“1201”表示, 各主题用10个相关联的关键词描述。依据公 式(3)计算各年度之间的主题相似度, 在相似度计算结果基础上构建主题演化网络, 网络节点表示为各年度主题, 如果两个主题间具有一定的演化关系, 代表这两个主题的网络节点之间将用一条线连接。最终结果如图6 所示。
图6 2012年-2016年国内情报学主题演化网络
国内情报学领域在2012年-2016年的主题可以分为6条演化路线, 由编号A~F表示, 分别为“信息管理与信息共享”、“信息技术方法及应用”、“服务质量评价”、“知识管理”、“信息组织与信息分析”、“信息服务模式”。部分主题与其他主题关联度不大, 不具有继承性, 因此并没有体现在主题演化网络图中, 可能的原因是与这些主题相关的研究较少, 在主题结构识别中并不能形成独立的主题, 而与该主题相关联的词融入到其他主题中。
通过观察演化路线可知, 文献主题演化过程中存在4种形式: 主题产生、主题分化、主题交融和主题消亡。不同演化形式的组合可以形成不同的演化路线。国内情报学领域在2012年-2016年的主题演化路线呈现如下特征。
①主题的分化和交融。如主题演化路线A, 它由各年度子主题1202、1207、1302、1309、1403、1409、1502、1506、1607等连接而成, 具体如表2所示。关于信息管理与信息共享的演化方向, 体现从不同类型信息资源的管理到信息开放与共享, 最后集中于信息资源利用的演化过程。
②主题的不断分化。如主题演化路线D, 由各年度子主题1305、1308、1401、1402、1505、1506、1510、1603、1605、1606、1607连接而成, 如表3 所示。关于知识管理的演化方向, 研究之初侧重于知识管理理论与知识共享方面的研究, 之后是知识管理在企业、国家政府、科研机构中的应用研究以及知识传播研究。
③主题的收缩。如主题演化路线F, 由各年度子主题1208、1306连接而成, 如表4 所示, 收缩的原因可能在于研究对象的减少或者转移。
4 结 语
本文提出一种改进的主题演化模型CSToT, 通过建模识别科技文献主题结构, 运用夹角余弦相似度算法获取各年度主题间相似性, 进而推出主题内容上的演化关系, 弥补ToT模型在该方面的局限性。同时, 本文考虑到同一主题在不同时间段的区分度, 引入新的主题强度计算方法。以情报学领域9种期刊为数据源进行主题挖掘, 并从主题强度和主题内容两个角度进行演化关系研究。实验结果表明, CSToT模型具有可行性和有效性。未来研究将进一步考虑主题强度计算方式和主题内容演化性的问题, 以期能获得更佳的实验结果。
作者贡献声明
何伟林: 设计研究思路, 提出研究框架, 设计并完成实验, 撰写论文;
奉国和: 修改论文;
谢红玲: 收集和整理数据。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: willin_he@foxmail.com。
[1] 何伟林, 奉国和, 谢红玲. data.rar. 训练语料.
[2] 何伟林, 奉国和, 谢红玲. timestamps.txt. 时间戳集合.
[3] 何伟林, 奉国和, 谢红玲. stopwords.txt. 停用词集合.
参考文献
文献选项
[1]
赵蓉英 , 魏明坤 . 基于引文分析视角的知识管理主题研究——以图书情报领域为例
[J]. 情报科学 , 2017 , 35 (6 ): 3 -8 .
[本文引用: 1]
(Zhao Rongying Wei Mingkun Research on the Subject of Knowledge Management Based on Citation Analysis: From the Perspective of Library and Information Science
[J]. Information Science , 2017 , 35 (6 ): 3 -8 .)
[本文引用: 1]
[2]
方瑀绅 . 科技教育研究主题发展趋势的引文分析: 1994-2013
[J]. 中国图书馆学报 , 2016 , 42 (1 ): 109 -125 .
https://doi.org/10.13530/j.cnki.jlis.161009
URL
[本文引用: 1]
摘要
为鉴往知来,本研究运用引文分析方法,探讨近20年来(1994—2013年)科技教育研究的主题演进状况。样本取自Wo S数据库的SSCI、SCI和A&HCI,共1 196篇,过滤后为1 009篇文献,共30 825条引文。1以五年为一个阶段,分析文献数量持续增加情况,各阶段的成长率分别为第I-II阶段为85.45%,第II-III阶段为62.26%,第III-IV阶段为55.79%;2关键词的使用由技职训练转向师资培育、工程和创造力;3高被引期刊主要有《科技与师资教育》(JTTE)等,被引用期刊由技职教育转向设计与科技、工程教育和科技教师;4I-IV阶段的主题类别领域包含经济、技职、法律、专业和教育;5被引用最多的作者与机构都来自美国;6科技教育与技职、商业、科学、工程、数学等多学科关系密切。本研究结果有助于了解国际科技教育研究主题演进与现况,并预测未来几年的研究趋势。
(Fang Yushen Trends of Research Topics in the Technology Education: A Citation Analysis from 1994 to 2013
[J]. Journal of Library Science in China , 2016 , 42 (1 ): 109 -125 .)
https://doi.org/10.13530/j.cnki.jlis.161009
URL
[本文引用: 1]
摘要
为鉴往知来,本研究运用引文分析方法,探讨近20年来(1994—2013年)科技教育研究的主题演进状况。样本取自Wo S数据库的SSCI、SCI和A&HCI,共1 196篇,过滤后为1 009篇文献,共30 825条引文。1以五年为一个阶段,分析文献数量持续增加情况,各阶段的成长率分别为第I-II阶段为85.45%,第II-III阶段为62.26%,第III-IV阶段为55.79%;2关键词的使用由技职训练转向师资培育、工程和创造力;3高被引期刊主要有《科技与师资教育》(JTTE)等,被引用期刊由技职教育转向设计与科技、工程教育和科技教师;4I-IV阶段的主题类别领域包含经济、技职、法律、专业和教育;5被引用最多的作者与机构都来自美国;6科技教育与技职、商业、科学、工程、数学等多学科关系密切。本研究结果有助于了解国际科技教育研究主题演进与现况,并预测未来几年的研究趋势。
[3]
储节旺 , 钱倩 . 基于词频分析的近10年知识管理的研究热点及研究方法
[J]. 情报科学 , 2014 , 32 (10 ): 156 -160 .
[本文引用: 1]
(Chu Jiewang Qian Qian Analysis of Research Focus and Research Methods in the Field of Knowledge Management During the Past Decade
[J]. Information Science , 2014 , 32 (10 ): 156 -160 .)
[本文引用: 1]
[4]
郑彦宁 , 许晓阳 , 刘志辉 . 基于关键词共现的研究前沿识别方法研究
[J]. 图书情报工作 , 2016 , 60 (4 ): 85 -92 .
https://doi.org/10.13266/j.issn.0252-3116.2016.04.012
URL
[本文引用: 1]
摘要
[目的/意义]研究分析已有研究前沿识别方法的利弊,建立一套相对比较合理的研究前沿识别方法模型,高效快速地辅助科研管理者和政策制定者识别研究前沿。[方法/过程]在总结研究前沿的定义、归纳研究前沿特性的基础上界定研究前沿的内涵,进而提出识别研究前沿的两个指标:研究主题年龄和研究主题关注作者数量,构建基于关键词共现的研究前沿识别方法,并在LED领域进行应用分析。[结果/结论]研究结果表明该方法不仅可以识别研究前沿,而且可以有效地跟踪研究前沿的产生、成长、消退、消失过程。
(Zheng Yanning Xu Xiaoyang Liu Zhihui Study on the Method of Identifying Research Fronts Based on Keywords Co-occurrence
[J]. Library and Information Service , 2016 , 60 (4 ): 85 -92 .)
https://doi.org/10.13266/j.issn.0252-3116.2016.04.012
URL
[本文引用: 1]
摘要
[目的/意义]研究分析已有研究前沿识别方法的利弊,建立一套相对比较合理的研究前沿识别方法模型,高效快速地辅助科研管理者和政策制定者识别研究前沿。[方法/过程]在总结研究前沿的定义、归纳研究前沿特性的基础上界定研究前沿的内涵,进而提出识别研究前沿的两个指标:研究主题年龄和研究主题关注作者数量,构建基于关键词共现的研究前沿识别方法,并在LED领域进行应用分析。[结果/结论]研究结果表明该方法不仅可以识别研究前沿,而且可以有效地跟踪研究前沿的产生、成长、消退、消失过程。
[5]
唐果媛 . 基于共词分析法的学科主题演化研究方法的构建
[J]. 图书情报工作 , 2017 , 61 (23 ): 100 -107 .
https://doi.org/10.13266/j.issn.0252-3116.2017.23.012
URL
[本文引用: 1]
摘要
[目的/意义]相比于以单纯的关键词统计排序为主的词频分析法,和以文献作为分析对象、需要庞大的引文索引作为基础的共引分析法,共词分析法具有一定的优势。因此,基于共词分析法来研究学科主题演化规律。[方法/过程]构建基于共词分析法的学科主题演化研究方法,包括4个模块,分别是:数据准备、演化阶段划分、主题识别和主题演化分析。[结果/结论]在主题识别阶段改进了词频g指数来选取共词分析的对象;在主题演化分析模块,提出从静态和动态两个角度来分析学科主题的演化情况,构建三维战略坐标来进行静态分析,并构建学科主题演化现象识别模型来进行动态分析。
(Tang Guoyuan Building the Method System of the Subject Theme Evolution Based on the Co-word Analysis Method
[J]. Library and Information Service , 2017 , 61 (23 ): 100 -107 .)
https://doi.org/10.13266/j.issn.0252-3116.2017.23.012
URL
[本文引用: 1]
摘要
[目的/意义]相比于以单纯的关键词统计排序为主的词频分析法,和以文献作为分析对象、需要庞大的引文索引作为基础的共引分析法,共词分析法具有一定的优势。因此,基于共词分析法来研究学科主题演化规律。[方法/过程]构建基于共词分析法的学科主题演化研究方法,包括4个模块,分别是:数据准备、演化阶段划分、主题识别和主题演化分析。[结果/结论]在主题识别阶段改进了词频g指数来选取共词分析的对象;在主题演化分析模块,提出从静态和动态两个角度来分析学科主题的演化情况,构建三维战略坐标来进行静态分析,并构建学科主题演化现象识别模型来进行动态分析。
[6]
Deerwester S Indexing by Latent Semantic Analysis
[J]. Journal of the American Society for Information Science , 1990 , 41 (6 ): 391 -407 .
https://doi.org/10.1002/(ISSN)1097-4571
URL
[本文引用: 1]
[7]
Hofmann T Probabilistic Latent Semantic Analysis
[C]// Proceedings of the 15th Conference on Uncertainty in Artificial Intelligence. 1999 : 289 -296 .
[本文引用: 1]
[8]
Blei D M Ng A Y Jordan M L et al .Latent Dirichlet Allocation
[J]. Journal of Machine Learning Research , 2003 , 3 (2 ): 993 -1022 .
[本文引用: 1]
[9]
Blei D M Lafferty J D Dynamic Topic Models
[C]// Proceedings of the 23rd International Conference on Machine Learning. New York: ACM , 2006 : 113 -120 .
[本文引用: 1]
[10]
齐亚双 , 祝娜 , 翟羽佳 . 基于DTM的国内外情报学研究主题热度演化对比研究
[J]. 图书情报工作 , 2016 , 60 (16 ): 99 -109 .
URL
[本文引用: 1]
摘要
[目的 /意义]为揭示情报学领域近15年的研究方向和发展演化情况,了解和掌握研究主题热度的动态变化。[方法 /过程]基于动态主题模型(Dynamic Topic Model),以国内外情报学领域影响因子较高的6本核心期刊作为数据集,分析国内外情报学研究主题演化过程,从主题热度的宏观维度和词语变化的微观角度入手,对比分析主题的研究内容和研究热度异同点,以期为我国情报学研究提供参考和借鉴。[结果 /结论]研究结果表明,国内情报学研究内容偏重实际应用,国外偏重于技术与方法的创新;同一研究主题在不同时期涉及研究内容差别明显,导致其研究热度随着时间推移发生变化;相对于国内,国外情报学研究主题传承性和递进性更强,热度变化较小。
(Qi Yashuang Zhu Na Zhai Yujia A Comparative Study on Topic Heats Evolution in the Field of Information Science Between the Domestic and Foreign Research Based on DTM
[J]. Library and Information Service , 2016 , 60 (16 ): 99 -109 .)
URL
[本文引用: 1]
摘要
[目的 /意义]为揭示情报学领域近15年的研究方向和发展演化情况,了解和掌握研究主题热度的动态变化。[方法 /过程]基于动态主题模型(Dynamic Topic Model),以国内外情报学领域影响因子较高的6本核心期刊作为数据集,分析国内外情报学研究主题演化过程,从主题热度的宏观维度和词语变化的微观角度入手,对比分析主题的研究内容和研究热度异同点,以期为我国情报学研究提供参考和借鉴。[结果 /结论]研究结果表明,国内情报学研究内容偏重实际应用,国外偏重于技术与方法的创新;同一研究主题在不同时期涉及研究内容差别明显,导致其研究热度随着时间推移发生变化;相对于国内,国外情报学研究主题传承性和递进性更强,热度变化较小。
[11]
Wang C Blei D M Heckerman D Continuous Time Dynamic Topic Models
[OL]. arXiv Preprint, arXiv: 1206 .3298 .
[本文引用: 1]
[12]
刘良选 , 黄梦醒 . 一种面向词汇突发的连续时间主题模型
[J]. 计算机工程 , 2016 , 42 (11 ): 195 -201 .
https://doi.org/10.3969/j.issn.1000-3428.2016.11.032
URL
Magsci
[本文引用: 1]
摘要
针对传统基于多项式分布的主题模型不能较好地刻画文档中词汇突发的现象,综合考虑文本集固有的时间信息,提出一种面向词汇突发的Dirichlet组合多项式(DCM)连续时间主题模型。采用DCM分布对文本集中的词汇突发现象进行建模,利用Beta分布刻画文本集中的时间特征,通过Gibbs采样和不动点迭代法实现模型参数的估计。实验结果表明,在预设主题数目较少的情况下,与ToT和DCMLDA模型相比,该模型具有明显的泛化性能优势,并且可以有效揭示出文本集中潜在的主题演化趋势。
(Liu Liangxuan Huang Mengxing A Continuous-time Topic Model for Word Burstiness
[J]. Computer Engineering , 2016 , 42 (11 ): 195 -201 .)
https://doi.org/10.3969/j.issn.1000-3428.2016.11.032
URL
Magsci
[本文引用: 1]
摘要
针对传统基于多项式分布的主题模型不能较好地刻画文档中词汇突发的现象,综合考虑文本集固有的时间信息,提出一种面向词汇突发的Dirichlet组合多项式(DCM)连续时间主题模型。采用DCM分布对文本集中的词汇突发现象进行建模,利用Beta分布刻画文本集中的时间特征,通过Gibbs采样和不动点迭代法实现模型参数的估计。实验结果表明,在预设主题数目较少的情况下,与ToT和DCMLDA模型相比,该模型具有明显的泛化性能优势,并且可以有效揭示出文本集中潜在的主题演化趋势。
[13]
Wang X MCCallum A Topics Over Time: A Non-Markov Continuous-time Model of Topical Trends
[C]// Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM , 2006 : 424 -433 .
[本文引用: 3]
[14]
Alsumalt L Barbara D Domeniconi C Online LDA: Adaptive Topic Models for Mining Text Streams with Applications to Topic Detection and Tracking
[C]// Proceedings of the 8th IEEE International Conference on Data Mining. IEEE , 2008 : 3 -12 .
[本文引用: 1]
[15]
何建云 , 陈兴蜀 , 杜敏 , 等 . 基于改进的在线LDA模型的主题演化分析
[J]. 中南大学学报: 自然科学版 , 2015 , 46 (2 ): 547 -553 .
URL
[本文引用: 1]
摘要
为了解决OLDA模型中的主题混合和新主题不能及时发现的问题,基于OLDA模型提出一种改进的在线LDA模型(improved online LDA,IOLDA)。该模型根据主题强度为每个主题设置不同的遗传度,提出一种新的主题强度度量方法,根据文档-主题分布的集中程度为文档设置不同的权值,该方法可以有效降低宽泛主题的强度得分;利用模型主题对齐的特点,采用Jensen-Shannon距离横向计算话题间的关联。实验结果表明:本文提出的方法能够有效地在线分析主题的演化。
(He Jianyun Chen Xingshu Du Min et al .Topic Evolution Analysis Based on Improved Online LDA Model
[J]. Journal of Central South University: Science and Technology , 2015 , 46 (2 ): 547 -553 .)
URL
[本文引用: 1]
摘要
为了解决OLDA模型中的主题混合和新主题不能及时发现的问题,基于OLDA模型提出一种改进的在线LDA模型(improved online LDA,IOLDA)。该模型根据主题强度为每个主题设置不同的遗传度,提出一种新的主题强度度量方法,根据文档-主题分布的集中程度为文档设置不同的权值,该方法可以有效降低宽泛主题的强度得分;利用模型主题对齐的特点,采用Jensen-Shannon距离横向计算话题间的关联。实验结果表明:本文提出的方法能够有效地在线分析主题的演化。
[16]
陈兴蜀 , 高悦 , 江浩 , 等 . 基于OLDA的热点话题演化跟踪模型
[J]. 华南理工大学学报: 自然科学版 , 2016 , 44 (5 ): 130 -136 .
https://doi.org/10.3969/j.issn.1000-565X.2016.05.020
URL
[本文引用: 1]
摘要
为了发现论坛数据中感兴趣的话题并对话题进行演化跟踪,文中首先利用潜在狄利克雷分配(LDA)模型将文本由词汇空间降维到主题空间,然后采用聚类算法在主题空间对文本集进行聚类,并利用文中提出的热点话题检测方法得出热点话题.基于发现的热点话题,文中提出了基于在线LDA(OLDA)话题模型的论坛热点话题演化跟踪模型(HTOLDA),该模型只选择热点话题进行先验传递,并通过设置同一话题相邻时间片的语义距离来判断话题的状态.实验结果表明,HTOLDA模型对各个时间片的论坛数据集的建模能力优于OLDA模型,并能够有效地对论坛中的热点话题进行演化跟踪.
(Chen Xingshu Gao Yue Jiang Hao et al .OLDA-Based Model for Hot Topic Evolution and Tracking
[J]. Journal of South China University of Technology: Natural Science Edition , 2016 , 44 (5 ): 130 -136 .)
https://doi.org/10.3969/j.issn.1000-565X.2016.05.020
URL
[本文引用: 1]
摘要
为了发现论坛数据中感兴趣的话题并对话题进行演化跟踪,文中首先利用潜在狄利克雷分配(LDA)模型将文本由词汇空间降维到主题空间,然后采用聚类算法在主题空间对文本集进行聚类,并利用文中提出的热点话题检测方法得出热点话题.基于发现的热点话题,文中提出了基于在线LDA(OLDA)话题模型的论坛热点话题演化跟踪模型(HTOLDA),该模型只选择热点话题进行先验传递,并通过设置同一话题相邻时间片的语义距离来判断话题的状态.实验结果表明,HTOLDA模型对各个时间片的论坛数据集的建模能力优于OLDA模型,并能够有效地对论坛中的热点话题进行演化跟踪.
[17]
裴可锋 , 陈永洲 , 马静 . 基于OLDA的可变在线主题演化模型
[J]. 情报科学 , 2017 , 35 (5 ): 63 -68 .
[本文引用: 1]
(Pei Kefeng Chen Yongzhou Ma Jing Variable Online Theme Evolution Model Based on OLDA
[J]. Information Science , 2017 , 35 (5 ): 63 -68 .)
[本文引用: 1]
[18]
史明哲 , 吴国栋 , 张倩 , 等 . 多主题受限玻尔兹曼机的长尾分布推荐研究
[J]. 小型微型计算机系统 , 2018 , 39 (2 ): 304 -309 .
URL
[本文引用: 1]
摘要
随着电子商务的快速发展,网络销售已成为一个重要的商品销售方式,而在线商品销售的长尾效应,也成为电子商务研究中亟待解决的问题.由于对冷门商品的评价数量少,导致现存的推荐算法很难使用户关注长尾商品,影响了长尾商品的销售,如何提高对长尾商品的推荐显得十分重要.本文提出L_RRBM(Latent Dirichlet Allocation-Real Restricted Boltzmann Machines)算法,通过提取用户偏好及商品的主题,结合改进受限玻尔兹曼机对商品未知主题权重的预测,以解决对长尾商品的推荐问题.试验结果表明了本文推荐算法的有效性和可行性.
(Shi Mingzhe Wu Guodong Zhang Qian et al .Research on the Long Tail Distribution Recommendation of the Multi-topic and RBM
[J]. Journal of Chinese Computer Systems , 2018 , 39 (2 ): 304 -309 .)
URL
[本文引用: 1]
摘要
随着电子商务的快速发展,网络销售已成为一个重要的商品销售方式,而在线商品销售的长尾效应,也成为电子商务研究中亟待解决的问题.由于对冷门商品的评价数量少,导致现存的推荐算法很难使用户关注长尾商品,影响了长尾商品的销售,如何提高对长尾商品的推荐显得十分重要.本文提出L_RRBM(Latent Dirichlet Allocation-Real Restricted Boltzmann Machines)算法,通过提取用户偏好及商品的主题,结合改进受限玻尔兹曼机对商品未知主题权重的预测,以解决对长尾商品的推荐问题.试验结果表明了本文推荐算法的有效性和可行性.
[19]
王行甫 , 付欢欢 , 王琳 . 基于余弦相似度和实例加权改进的贝叶斯算法
[J]. 计算机系统应用 , 2016 , 25 (8 ): 166 -170 .
[本文引用: 1]
(Wang Xingfu Fu Huanhuan Wang Lin Improved Naïve Bayes Algorithm Based on Weighted Instance with Cosine Similarity
[J]. Computer Systems and Applications , 2016 , 25 (8 ): 166 -170 .)
[本文引用: 1]
[20]
史庆伟 , 乔晓东 , 徐硕 , 等 . 作者主题演化模型及其在研究兴趣演化分析中的应用
[J]. 情报学报 , 2013 , 32 (9 ): 912 -919 .
https://doi.org/10.3772/j.issn.1000-0135.2013.09.002
URL
[本文引用: 1]
摘要
从海量科技文献中自动挖掘隐含主题、研究人员的研究兴趣及其演化规律是信息服务迈向知识服务需要解决的关键问题之一。目前的方法多从静态的角度分析文献主题、科研人员的研究兴趣,而演化分析的方法主要集中文档的内部特征,即文档内容本身,很少考虑作者等外部特征。基于此,本文在AT和ToT模型的基础上构建了作者主题演化(AToT)模型,并给出了一种估计AToT模型参数的吉布斯采样方法。该模型集成了AT和ToT模型的优势,不仅可以揭示科技文献中隐含的主题、作者的研究兴趣,而且可以挖掘研究兴趣随时间变化的规律。最后,以1740篇NIPS会议论文集作为实验数据,通过与AT模型的对比分析验证了AToT模型的可行性和有效性。
(Shi Qingwei Qiao Xiaodong Xu Shuo et al .Author-Topic Evolution Model and Its Application in Analysis of Research Interests Evolution
[J]. Journal of the China Society for Scientific and Technical Information , 2013 , 32 (9 ): 912 -919 .)
https://doi.org/10.3772/j.issn.1000-0135.2013.09.002
URL
[本文引用: 1]
摘要
从海量科技文献中自动挖掘隐含主题、研究人员的研究兴趣及其演化规律是信息服务迈向知识服务需要解决的关键问题之一。目前的方法多从静态的角度分析文献主题、科研人员的研究兴趣,而演化分析的方法主要集中文档的内部特征,即文档内容本身,很少考虑作者等外部特征。基于此,本文在AT和ToT模型的基础上构建了作者主题演化(AToT)模型,并给出了一种估计AToT模型参数的吉布斯采样方法。该模型集成了AT和ToT模型的优势,不仅可以揭示科技文献中隐含的主题、作者的研究兴趣,而且可以挖掘研究兴趣随时间变化的规律。最后,以1740篇NIPS会议论文集作为实验数据,通过与AT模型的对比分析验证了AToT模型的可行性和有效性。
[21]
Sugimoto C R Li D Russell T G et al .The Shifting Sands of Disciplinary Development: Analyzing North American Library and Information Science Dissertations Using Latent Dirichlet Allocation
[J]. Journal of the Association for Information Science & Technology , 2011 , 62 (1 ): 185 -204 .
[本文引用: 1]
[22]
徐路路 , 王效岳 , 白如江 , 等 . 基于DTM模型和文本特征分析的基金项目新兴趋势探测研究——以NSF石墨烯领域为例
[J]. 数据分析与知识发现 , 2018 , 2 (3 ): 87 -97 .
URL
[本文引用: 1]
摘要
【目的】为提升科技文献文本内容语义理解,对基金项目文本中的新兴趋势进行探测。【方法】提出一种基于DTM模型和文本特征分析的基金项目新兴趋势探测方法,利用文本挖掘技术深入文本内容并分析基金摘要特征要素,识别主题概率分布并构造基于文本特征要素的新兴主题探测公式,对NSF数据库石墨烯领域中的新兴趋势进行探测与分析。【结果】通过文献调查法和专家咨询法,表明该方法能够更加快速准确地识别基金项目中的新兴趋势主题,弥补了单一主题维度进行主题探测的不足,为科技创新决策提供情报支撑服务。【局限】仅从资助金额强度、资助时长、资助主题三个方面分析基金项目,需进一步拓展和探索符合其文本特征的因素并对其进行多因素融合分析。【结论】本文提出的新兴趋势模型可更加快速准确地识别其新兴趋势主题。
(Xu Lulu Wang Xiaoyue Bai Rujiang et al .Detecting Emerging Trends of Funds Based on DTM Model and Text Analytics: Case Study of NSF Graphene Field
[J]. Data Analysis and Knowledge Discovery , 2018 , 2 (3 ): 87 -97 .)
URL
[本文引用: 1]
摘要
【目的】为提升科技文献文本内容语义理解,对基金项目文本中的新兴趋势进行探测。【方法】提出一种基于DTM模型和文本特征分析的基金项目新兴趋势探测方法,利用文本挖掘技术深入文本内容并分析基金摘要特征要素,识别主题概率分布并构造基于文本特征要素的新兴主题探测公式,对NSF数据库石墨烯领域中的新兴趋势进行探测与分析。【结果】通过文献调查法和专家咨询法,表明该方法能够更加快速准确地识别基金项目中的新兴趋势主题,弥补了单一主题维度进行主题探测的不足,为科技创新决策提供情报支撑服务。【局限】仅从资助金额强度、资助时长、资助主题三个方面分析基金项目,需进一步拓展和探索符合其文本特征的因素并对其进行多因素融合分析。【结论】本文提出的新兴趋势模型可更加快速准确地识别其新兴趋势主题。
基于引文分析视角的知识管理主题研究——以图书情报领域为例
1
2017
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于引文分析视角的知识管理主题研究——以图书情报领域为例
1
2017
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
科技教育研究主题发展趋势的引文分析: 1994-2013
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
科技教育研究主题发展趋势的引文分析: 1994-2013
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于词频分析的近10年知识管理的研究热点及研究方法
1
2014
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于词频分析的近10年知识管理的研究热点及研究方法
1
2014
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于关键词共现的研究前沿识别方法研究
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于关键词共现的研究前沿识别方法研究
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于共词分析法的学科主题演化研究方法的构建
1
2017
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于共词分析法的学科主题演化研究方法的构建
1
2017
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
Indexing by Latent Semantic Analysis
1
1990
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
Probabilistic Latent Semantic Analysis
1
1999
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
Latent Dirichlet Allocation
1
2003
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
Dynamic Topic Models
1
2006
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于DTM的国内外情报学研究主题热度演化对比研究
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于DTM的国内外情报学研究主题热度演化对比研究
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
Continuous Time Dynamic Topic Models
1
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
一种面向词汇突发的连续时间主题模型
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
一种面向词汇突发的连续时间主题模型
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
Topics Over Time: A Non-Markov Continuous-time Model of Topical Trends
3
2006
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
... LDA是一个文档主题生成模型, 也称为三层(文档, 主题, 词)贝叶斯概率模型.该模型假设文档是由若干主题以一定概率混合而成, 而主题是词的概率分布.ToT模型[13 ] 是在LDA模型的基础上提出的, 是一个文档主题与时间戳的生成模型, 如图1 [13 ] 所示. ...
... [13 ]所示. ...
Online LDA: Adaptive Topic Models for Mining Text Streams with Applications to Topic Detection and Tracking
1
2008
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于改进的在线LDA模型的主题演化分析
1
2015
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于改进的在线LDA模型的主题演化分析
1
2015
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于OLDA的热点话题演化跟踪模型
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于OLDA的热点话题演化跟踪模型
1
2016
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于OLDA的可变在线主题演化模型
1
2017
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
基于OLDA的可变在线主题演化模型
1
2017
... 科技文献主题识别方法主要包括引文分析法[1 ,2 ] 、词频分析法[3 ] 、共词分析法[4 ,5 ] 、主题模型法[6 ,7 ] 等, 其中引文分析法通过研究科技文献间的引用关系得出某一科学领域的发展脉络, 在一定程度上体现主题间的关联性, 但因为时滞性的问题容易丢失前沿领域的相关文献; 词频分析法利用关键词词频探测某领域的发展动向, 高频词能有效识别研究热点, 而低频词有助于预测新兴主题, 但是仅仅依据词频识别文献主题显得过于单薄, 一般结合其他方法开展研究; 共词分析法克服词频独立性的缺点, 利用词与词之间的关系得到文献主题之间的关系, 但该方法无法解决由一词多义或者一义多词等引起的歧义问题, 导致无法获得理想的主题挖掘效果.主题模型作为对科技文献进行语义抽取的一种算法有效地解决了上述问题, Blei等[8 ] 提出的概率主题模型 (Latent Dirichlet Allocation, LDA)凭借其突出的文本降维能力, 能够有效地从海量文献中快速识别其隐含主题, 引起众多研究人员的关注并成为主题挖掘的主要方法.之后, 研究人员在LDA主题模型的基础上进行大量扩展研究.其中, 在模型中引入文本时间属性是目前研究的热点, 如文本集 合的先离散概率模型 (Dynamic Topic Model, DTM)[9 ,10 ] 假设主题会随着时间而变化, 将语料库离散到各个时间区间中, 分别对各个时间区间的文本进行建模, 进而对文本主题演化进行分析; 连续时间动态主题模型 (Continuous Time Dynamic Topic Model, CTDTM)[11 ] 利用布朗运动约束主题的演化, 并在参数演化过程中引入文本时间信息, 以解决时间粒度选取的问题; DCMCTM (Dirichlet Compound Multinomial Continuous-time Topic Model)[12 ] 综合文本数据的时间信息, 并采用DCM分布对文本进行建模, 有效地刻画了文档中词汇突发现象.ToT(Topics over Time)[13 ] 主题模型假设文本主题以及文本时间信息会影响主题词多项式分布的生成, 因此将文本中的时间信息作为可观测连续变量引入模型中, 其优势在于不存在时间粒度的选取问题, 缺陷在于不能从内容层面上进行主题演化分析.同时, 为了实现对实时更新的文本内容进行主题演化分析, 学者相继提出一系列在线主题演化模型, 如OLDA (Online Latent Dirichlet Allocation)模型[14 ] 将文本集离散到不同的时间区间, 并对每个区间的文本集进行主题建模, 利用主题的历史分布作为当前时间区间进行主题挖掘的先验知识, 但OLDA模型没有考虑具有不同演化能力的主题, 为解决此问题, 一种改进的在线LDA 模型(Improved Online LDA, IOLDA)[15 ] 被提出, 根据主题强度为每个主题设置不同的遗传度, 改善了模型识别混合主题和新主题的能力, 根据文档-主题分布的集中程度为文档设置不同的权值, 有效降低宽泛主题的强度得分, 方便在线分析主题的强度演化和内容演化; HTOLDA(Hot Topic Online Latent Dirichlet Allocation)[16 ] 模型能够将演化能力强的热点话题与演化能力弱的非热点话题在先验传递时区分对待, 并且考虑新出现的词语对建模的影响; VOLDA(Variable Online Latent Dirichlet Allocation)[17 ] 模型利用主题语义距离, 在引入变长演化矩阵定义方法的基础上设计权重计算方法及模型优化方法, 减少旧主题对新主题的影响, 并且改善主题混合、主题表示能力弱的问题.综上所述, 相比于引文分析、词频分析、共词分析等方法, 主题模型在科技文献主题识别过程中具有更好的语义表达功能. ...
多主题受限玻尔兹曼机的长尾分布推荐研究
1
2018
... 主题是关键词的集合, 主题Z 在某个时间区间t 中的强度取决于该主题关联词的强度之和, 可由公式(1)[18 ] 计算得到. ...
多主题受限玻尔兹曼机的长尾分布推荐研究
1
2018
... 主题是关键词的集合, 主题Z 在某个时间区间t 中的强度取决于该主题关联词的强度之和, 可由公式(1)[18 ] 计算得到. ...
基于余弦相似度和实例加权改进的贝叶斯算法
1
2016
... 采用夹角余弦相似度算法构建不同年度主题之间的演化关系, 设置主题演化的阈值, 两个主题间的相似度大于阈值说明具有一定的演化关系, 小于阈值则说明不具备演化关系.根据不同年度主题的相似度, 构建主题演化体系.夹角余弦相似度计算如公式(3)[19 ] 所示. ...
基于余弦相似度和实例加权改进的贝叶斯算法
1
2016
... 采用夹角余弦相似度算法构建不同年度主题之间的演化关系, 设置主题演化的阈值, 两个主题间的相似度大于阈值说明具有一定的演化关系, 小于阈值则说明不具备演化关系.根据不同年度主题的相似度, 构建主题演化体系.夹角余弦相似度计算如公式(3)[19 ] 所示. ...
作者主题演化模型及其在研究兴趣演化分析中的应用
1
2013
... 基于Python, 选择哈尔滨工业大学停用词表对文本数据集进行去除停用词操作, 共获得46 700个关键词.CSToT主题建模时, 主题模型参数的经验值取值为: α =50.0, β =0.1[20 ] , 迭代次数为1 000.选取多个主题数进行实验, 结果发现抽取数据集排名最靠前的10个主题大类, 其概括性最好、冗余度低, 因此模型主题数阈值设为10, 并通过建模得到对应主题的关键词时间序列分布、文本集在某个时间段t 中的各个主题分布概率以及模型的对数似然估计的下界值等参数值. ...
作者主题演化模型及其在研究兴趣演化分析中的应用
1
2013
... 基于Python, 选择哈尔滨工业大学停用词表对文本数据集进行去除停用词操作, 共获得46 700个关键词.CSToT主题建模时, 主题模型参数的经验值取值为: α =50.0, β =0.1[20 ] , 迭代次数为1 000.选取多个主题数进行实验, 结果发现抽取数据集排名最靠前的10个主题大类, 其概括性最好、冗余度低, 因此模型主题数阈值设为10, 并通过建模得到对应主题的关键词时间序列分布、文本集在某个时间段t 中的各个主题分布概率以及模型的对数似然估计的下界值等参数值. ...
The Shifting Sands of Disciplinary Development: Analyzing North American Library and Information Science Dissertations Using Latent Dirichlet Allocation
1
2011
... 困惑度[21 ] 是衡量主题模型有效性的常用指标之一, 其数值越小, 表明主题模型建模效果越好, 预测能力也越强, 如公式(4)所示. ...
基于DTM模型和文本特征分析的基金项目新兴趋势探测研究——以NSF石墨烯领域为例
1
2018
... 动态主题模型(Dynamic Topic Model, DTM)是揭示文本主题及其变化的强大工具之一, 通过获取主题的动态特征识别主题结构及其演化关系[22 ] .本文比较CSToT模型以及DTM模型在不同时间片段的困惑度, 计算结果如图3 所示. ...
基于DTM模型和文本特征分析的基金项目新兴趋势探测研究——以NSF石墨烯领域为例
1
2018
... 动态主题模型(Dynamic Topic Model, DTM)是揭示文本主题及其变化的强大工具之一, 通过获取主题的动态特征识别主题结构及其演化关系[22 ] .本文比较CSToT模型以及DTM模型在不同时间片段的困惑度, 计算结果如图3 所示. ...

 , 奉国和, 谢红玲
, 奉国和, 谢红玲




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}