
|
|
俞琰 , 赵乃瑄
, 赵乃瑄
Yu Yan, Zhao Naixuan
中图分类号: G250
通讯作者:
收稿日期: 2018-03-5
修回日期: 2018-05-19
网络出版日期: 2018-11-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】提出一种领域停用词自动选取方法, 以提高专利主题分析的区分度和质量。【方法】针对要进行专利主题分析的目标集, 引入专利辅助集, 提出基于辅助集文档频率和类别熵两个指标, 衡量词语在辅助集中分布情况, 自动识别领域停用词。【结果】实验结果表明, 基于辅助集的领域停用词选取方法能够提高专利主题分析的区分度和质量。【局限】辅助集的选取类型和数量有待进一步研究。【结论】基于辅助集的领域停用词选取方法能够有效地衡量词的分布特征, 从而更准确地选取专利主题分析中的领域停用词。
关键词:
Abstract
[Objective] This paper proposes a new method to automatically choose domain specific stopwords, aiming to improve the performance of patent topic analysis. [Methods] First, we introduced an auxiliary set and proposed two indexes of document frequency and entropies among categories based on this auxiliary set. Then, we measured the distribution of words from the auxiliary set to choose the domain specific stopwords automatically. [Results] The proposed method improved the quality of identified patent topics. [Limitations] The types and members of the auxiliary set need to be further studied. [Conclusions] The proposed stopwords selection methods could measure the characteristics of words, which helps us find the domain specific stopwords for patent analysis more effectively.
Keywords:
有效的专利文本分析能够判断领域技术热点、识别领域核心技术, 预测领域技术发展趋势, 帮助研发人员从中获得启发与借鉴, 从而缩短创新设计时间、节约创新设计经费。特别地, 不同于传统的文本分析方法, 专利主题分析通过研究专利文本集中词语共现的概率分布, 挖掘专利文本隐含的语义信息, 从而揭示专利文本深层次的知识结构[1,2,3,4,5,6,7,8,9,10]。
然而, 在专利主题分析过程中, 专利文本中包含较少信息的停用词频繁出现在多个主题中, 导致训练收敛速度变慢, 主题间分布相似性提高, 不能明显区别各个主题, 对专利主题分析结果产生负面影响[11]。为了避免这种情况, 在专利主题分析中, 通常在构建主题模型之前借助预先定义的通用停用词表, 删除专利文本中的停用词, 以提高主题分析的区分度和建模质量。然而, 这种方法并不能完全过滤掉表意性较差的领域停用词, 例如, 专利文本中常出现“方法”、“包含”、“发明”等信息量少且区分度低的领域停用词, 这些领域停用词不包含在通用停用词表中, 不能很好地表示专利文本的语义信息, 影响专利主题分析的质量。为此, 一些研究在专利主题分析之前, 手工选取领域停用词。如, 吴菲菲等[8]在专利主题分析中手工去除专利描述常用词(如“comprise”“include”“claim”等)以及学术词汇(如“method”“advantage”等)。Chen等[3]在专利主题分析之前, 借助维基百科移除专利权力要求书中高频单词(如“claimed”“comprising”“invention”等); 借助诺丁汉大学通用学术单词列表, 去除使用最频繁的100个学术单词(如“research”“approach”等)。
手工选取领域停用词费时费力, 而自动选取领域停用词可根据实际处理文本集的不同而自动构造合适的停用词, 灵活性强, 更具潜力。因此, 本文针对专利文本的特点, 引入辅助集衡量词的分布特征, 以自动选取领域停用词, 从而提高专利主题分析的质量。
停用词被认为是无实际语义信息、无区分度的词。它们构成了文本数据的大部分, 在文本分析过程中存在很大的干扰性, 不仅携带较少的信息, 还会对其他词语产生一定的抑制作用, 很大程度上影响文本处理的效率和准确性。去除停用词被广泛使用于各种文本分析领域。如, Frakes等[11]在信息检索的研究中认为自动索引阶段提早考虑消除出现频率过高的停用词可以提高检索速度, 减少检索存储空间并且不会降低检索结果的准确性。Silva等[12]验证了基于支持向量机的文本分类器在去除停用词之后, 准确率有所提高。官琴等[13]选取百度停用词表、哈尔滨工业大学停用词表以及四川大学机器智能实验室停用词表, 对不同聚类结果进行效果评估。研究结果表明停用词表对于文本聚类准确度有很大的影响, 构建或选取适宜的停用词表极为重要。总的来说, 停用词的选取对文本分析结果异常重要, 去除停用词是文本预处理中十分重要的一个步骤。
停用词可分为通用停用词和领域停用词两大类。目前已有一些公开发表的通用停用词表, 但是这些通用停用词表不能完全过滤掉表意性较差的词语。领域停用词因领域与数据集不同而不同。例如, 词语“学习”在教育领域可能是一个领域停用词, 但是在计算机科学领域可能不是一个领域停用词。领域停用词已被应用于人力资源管理[14]、生物信息、基因本体[15]、信息检索[16]和电子商务[17]等领域之中。
相较于手工选取领域停用词, 目前通常采用基于词频和文档频率的统计方法自动选取领域停用词。基于词频的领域停用词自动选取理论依据是若一个词在文本集中大量出现, 则认为该词是领域停用词。在这种方法中, 统计词在文本集合中的词频, 并根据词频降序排列, 选择前n个词作为领域停用词。基于文档频率的领域停用词自动选取方法则通过计算词在语料集中的文档频率, 判断词是否为领域停用词。其理论假设是当一个词在大量文本中出现时, 该词不具有较强的文本区分能力, 可被认为是领域停用词。
此外, 一些研究者尝试采取其他方法自动选取领域停用词。例如, Lo等[18]针对信息检索, 提出一种基于词语的随机抽样抽取方法, 并提出最有效的停用词表是经典的停用词表和新方法自动抽取的停用词表的融合。Hao等[19]提出χ2-统计方法, 产生家具种类查询的停用词, 以加速电子商务网站信息检索过程。Sinka等[20]提出单词熵概念, 使用聚类和随机检索算法优化, 自动选取停用词。Jungiewicz等[21]基于观察: 每个文本的停用词的出现次数的分布通常遵循一个典型的随机变量模型, 并开发了一个非监督方法自动产生停用词。Makrehchi等[22]假设停用词具有最小信息和预测能力, 提出后向过滤级别性能和数据稀疏索引的概念, 从一个标记集合中自动产生停用词, 用于文本分类。顾益军等[23]分别计算词条在语料库中各个句子内发生的概率和包含该词的句子在语料库中的概率, 在词基础上计算联合熵, 依据联合熵选取停用词。巩政等[24]采用联合熵算法初步确定蒙古文停用词, 从初步确定的蒙古文停用词中去掉蒙古文实体名词及同形异义词, 再通过对英文停用词和蒙古文停用词的词性比较, 确定蒙古文停用词表。珠杰等[25]结合现有停用词的处理技术, 研究基于统计的藏文停用词选取方法, 通过实验分析了词项频率、文档频率、熵等方法的藏文停用词选取情况, 提出藏文叙词、特殊动词和自动处理方法相结合的藏文停用词选取方法。
总的来说, 专利中领域停用词有其自身特点, 这些方法并不适用于专利文本处理。如, 采用词频或文档频率进行停用词的自动选取方法中, 一些领域术语可能也同样在语料集中大量出现, 不能简单地删除。基于联合熵的停用词选取计算词在句子中出现频率与包含该词的句子频率的联合熵, 而在专利文本中, 包含某词条的句子很少重复出现, 所以, 使用基于联合熵选择领域停用词不具可行性。
在专利主题分析中, 根据词语包含信息的多少, 可将词语粗略地分为领域术语和领域停用词两大类。其中, 领域术语包含较多领域知识, 而领域停用词则包含较少的领域知识。通过分析可以发现, 领域术语通常和分析的特定主题类别相关, 仅在特定主题类别专利文本集中大量出现, 在其他主题类别专利文本集中很少出现, 甚至不出现。而领域停用词则不仅在特定主题类别专利文本中大量出现, 也在其他主题类别专利文本集中频繁出现。因此, 针对要进行专利主题分析的目标集, 本文引入包含其他类别专利文本数据的辅助集, 提出两个指标衡量目标集中词语在辅助集的分布情况, 从而区分领域术语和领域停用词, 以识别目标集中的领域停用词。
具体地, 相对于要进行专利主题分析的目标集(Target Set, TS), 本文引入包含C1, C2,···, Cn等n个类别的辅助集(Auxiliary Set, AS), 每个类别包含若干个相关专利文本。利用辅助集AS, 提出基于辅助集文档频率(Auxiliary Set based Document Frequency, ASDF)和基于辅助集类别熵(Auxiliary Set based Entropy between Categories, ASEC)的两个领域停用词选取 方法。
(1) 基于辅助集文档频率的领域停用词选取
基于辅助集文档频率的领域停用词选取方法通过计算目标集中词语在辅助集中出现的文档频率, 以选取领域停用词, 其理论假设是当目标集中的一个词在辅助集的大量文本中出现, 则该词与目标集相关度低, 被认为是目标集的领域停用词。例如, “发明”一词在辅助集多个文本中出现, 具有较高的辅助集文档频率, 被认为是领域停用词; 相反, 目标集的领域术语仅在相关目标集中具有较高的文档频率, 在辅助集中很少, 甚至不出现。从而可以区分目标集的领域术语与领域停用词。
具体地, 目标集TS中词语w在辅助集AS中的文档频率ASDF(w)定义如公式(1)所示。
$ASDF(w)=\sum\nolimits_{i=1}^{n}{df(w,{{C}_{i}})}$ (1)
其中, df (w, Ci)表示词语w在类别Ci中的文档频率。ASDF(w)越大, 表明辅助集中包含词语w的专利文本越多, 则越可能是领域停用词。
(2) 基于辅助集类别熵的领域停用词选取
基于辅助集类别熵的领域停用词选取方法通过信息熵衡量词语在辅助集中的分布情况。熵是物理学的一个概念, 用于描述事物无序性的参数, 熵越大, 则无序性越强。信息熵是信息论中的重要概念, 用来度量信息的不确定程度。一个系统的信息熵度量信息的无组织程度, 信息熵越大, 事件越不确定; 反之, 信息熵越小, 事件越确定。专利中领域停用词通常在各类别间文本中均匀出现。而词在类别间分布情况可以使用信息熵衡量, 以度量词语在辅助集不同类别文本中的分布情况。
具体地, 词语w在辅助集AS中类别熵ASEC(w)计算如公式(2)所示。
$ASEC(w)=-\sum\limits_{i=1}^{n}{\frac{df(w,{{C}_{i}})+\varepsilon }{DF(w,AS)+\varepsilon }\times lb\frac{df(w,{{C}_{i}})+\varepsilon }{DF(w,AS)+\varepsilon }}$(2)
其中, df (w, Ci)表示词w在类别Ci中的文档频率; DF (w, AS)表示词w在辅助集AS中的文档频率, 定义见公式(1); ε为很小的值, 避免对数和分母为零。由公式(2)可知, 当词语w在辅助集AS所有类别中分布越均匀时, 类别信息熵ASEC(w)越大, 则词语w越可能是停用词。
为了验证提出模型的有效性, 选取智能语音相关专利文本进行实验。智能语音是人机交互模式的新选择。借助于移动互联网、机器学习领域中深度学习技术以及大数据语料库的积累, 智能语音技术的实用化发展突飞猛进, 在电信、金融、汽车电子、家电、教育、玩具、智能手机、移动互联网等领域已得到广泛应用。本文实验基于中国国家知识产权局专利数据库, 以“智能语音or语音识别or语音合成or自然语言理解or语音交互or语音技术or语音控制”作为检索式, 检索2013年-2017年中国发明公开专利文献(检索日期为2017年8月1日)。通过数据清洗、去重后, 最终得到5 325条专利, 获取专利标题和摘要作为待分析的目标集。目标集中专利IPC统计信息如图1所示。可见, 目标集专利主要分属于G10、G06、H04和G05等4个大类。
为了选取领域停用词, 分别采取两种策略获取辅助集:
(1) 辅助集1
根据专利IPC, 排除目标集所在的G部和H部, 分别从A-F部中随机选取与目标集同一时期, 即2013年-2017年的2 000条中国发明公开专利文本标题和摘要作为辅助集1。通过这种策略选取的辅助集和目标集因为属于不同的IPC部, 所以相似性小。
(2) 辅助集2
由于目标集主要属G部, 因此从目标集所属的IPC部G中, 排除目标集所属G10、G06、G05, 从G01、G02、G03、G07、G08、G09和G11随机选取与目标集同一时期的2 000条中国发明公开专利文本标题和摘要作为辅助集2。通过这种策略选取的辅助集和目标集同属于G部, 但属于不同的大类, 具有一定的相似性。
辅助集的基本信息如表1所示。
表1 辅助集基本信息
| 数据集类型 | 类别 | 文本量 |
|---|---|---|
| 辅助集1 | A 人类生活必需(农、轻、医) | 2000 |
| B 作业; 运输 | 2000 | |
| C 化学; 冶金 | 2000 | |
| D 纺织; 造纸 | 2000 | |
| E 固定建筑物(建筑、采矿) | 2000 | |
| F 机械工程; 照明; 加热; 武器; 爆破 | 2000 | |
| 辅助集2 | G01 测量; 测试 | 2000 |
| G02 光学 | 2000 | |
| G03 摄影术; 电影术; 利用了光波以外其它波的类似技术; 电刻术; 全息摄影术 | 2000 | |
| G07 核算装置 | 2000 | |
| G08 信号装置 | 2000 | |
| G09 教育; 密码术; 显示; 广告; 印鉴 | 2000 | |
| G11 信息存储 | 2000 |
首先对目标集、辅助集1以及辅助集2进行文本预处理。文本预处理包括使用结巴分词进行分词, 使用哈尔滨工业大学停用词表移除通用停用词, 将英文大写转化为小写等工作。
经过预处理后的语料集, 采用不同的停用词选取指标与策略选取领域停用词。
在目标集中移除选取的领域停用词, 使用LDA(Latent Dirichlet Allocation)模型[26]建立主题模型。LDA是一种常用的主题模型, 由于其参数简单, 不产生过拟合现象, 因而逐渐成为主题模型的研究热点。在LDA建模过程中, 参数估计采用Gibbs采样算法。主题模型设置为α=50/K、β=0.01, Gibbs采样迭代次数参数为2 000, 保存迭代参数为1 000。主题数K通过计算目标集中仅去除通用停用词之后的专利主题模型的困惑度选取最优值, 采用五折交叉验证。根据计算, 实验设定目标集的主题数K=10。
借助KL距离衡量主题的区分度。KL距离常用来衡量两个概率分布的距离。平均KL距离定义如公式(3)所示。
$\begin{align} & avg\_KL=\frac{\sum\nolimits_{i=1}^{K}{\sum\nolimits_{j=1}^{K}{KL({{\phi }_{i}}||{{\phi }_{j}})}}}{{{K}^{2}}} \\ & KL({{\phi }_{i}}||{{\phi }_{j}})=\sum\nolimits_{v=1}^{V}{{{\phi }_{iv}}\log \frac{{{\phi }_{iv}}}{{{\phi }_{jv}}}} \\ \end{align}$ (3)
其中, φiv表示主题i中词语wv的概率, K表示目标集中单词数。由于KL距离是不对称的, 但是φi和φj相似性度量是对称的, 故将公式进行调整, 采用对称的Jensen-Shannon距离度量两个主题距离, 具体计算如公式(4)所示。
$JS({{\phi }_{i}},{{\phi }_{j}})=\frac{KL({{\phi }_{i}},{{\phi }_{j}})+KL({{\phi }_{j}},{{\phi }_{i}})}{2}$ (4)
此时, avg_KL值越大, 表明主题与主题之间的距离越远, 主题的可区分性越高。由于大概率的前若干词语更能够体现主题的信息, 因此, 本文计算每个主题的前300个词, 即K=300。
利用ASDF与ASEC两种方法, 分别在辅助集1与辅助集2上进行领域停用词选取实验。为了便于比较, 引入三个传统的在目标集上的方法作为基本方法选取领域停用词:
(1) TF: 依据词语在目标集中出现的词频, 若一个词语大量出现时, 则被认为是领域停用词;
(2) DF: 依据词语在目标集中的文档频率, 选取文档频率最高的若干词作为领域停用词;
(3) TF-IDF: 扩展经典的词频-逆文档频率方法, 其中, TF指词语在目标集中出现的频率, IDF为目标集中文档总数除以该词在目标集中的文档频率得到的商取对数。TF-IDF值越小, 越可能是领域停用词。
表2列出不同方法选取的前20个领域停用词。
表2 Top 20领域停用词选取结果
| 数据集 | 方法 | 领域停用词 |
|---|---|---|
| 目标集 | TF | 语音 模块 所述 识别 控制 一种 本发明 方法 信息 包括 装置 进行 用户 系统 智能 信号 中 连接 数据 用于 |
| DF | 语音 一种 本发明 包括 识别 进行 方法 所述 公开 控制 装置 中 系统 模块 用户 信息 提供 实现 接受 智能 | |
| TF-IDF | 模块 所述 信息 控制 智能 信号 单元 装置 用户 终端 设备 数据 系统 机器人 识别 方法 第一 用于 连接 音频 | |
| 辅助集1 | ASDF | 一种 本发明 包括 上 公开 所述 中 连接 方法 设置 具有 涉及 装置 进行 设有 结构 内 后 提供 提高 |
| ASEC | 公开 涉及 具有 中 所述 装置 进行 提供 连接 上 提高 设置 后 结构 内 简单 设有 技术 效果 领域 | |
| 辅助集2 | ASDF | 一种 本发明 包括 所述 方法中 提供 上 公开 装置 进行 用于具有 系统 连接 控制 第一 设置 时 涉及 |
| ASEC | 提供 中 装置 上 公开 所述 用于 方法 进行 具有 涉及 时 连接 设置 控制 第一 系统 能够 实现 技术 |
在表2中, 仅使用目标集的TF、DF以及TF-IDF方法选取的领域停用词除了信息量很少的词, 如“本发明”、“包括”等之外, 也包括 “语音”、“模块”等领域术语。这是由于在目标集中, 领域停用词和领域术语均可能大量出现, 仅使用基于目标集的词频和文档频率很难区分它们。相反, 辅助集1和辅助集2中ASDF和ASEC方法识别的停用词包含更少的领域信息。ASDF和ASEC通过辅助集识别的词在不同类别的专利文本中均广泛分布, 更加可能为领域停用词。
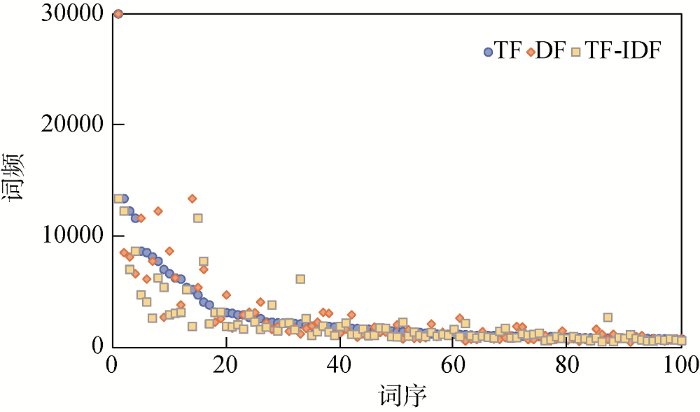
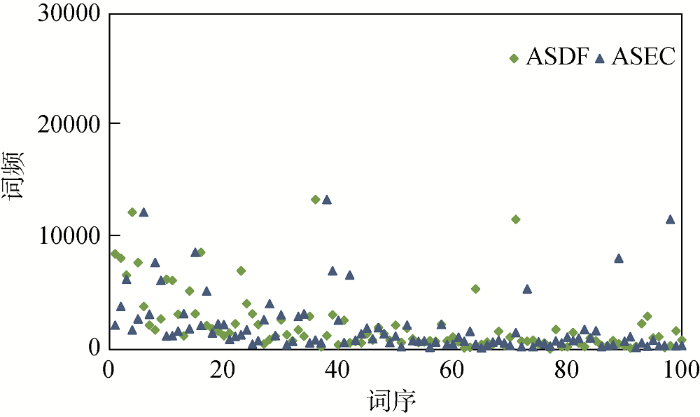
图2至图4为不同方法选取的前100个领域停用词的词序-词频散点图。由图2可见, 使用目标集选取的领域停用词在词序-词频空间上总体遵循1/|x|图形分布, 三种方法分布趋势基本一致, 这是由于专利文本摘要较短, 反复出现的词语次数并不多。由图3、图4可见, 相对于目标集选取的领域停用词, 使用辅助集选取的领域停用词在词序-词频空间上分布更为相似。
表3为不同方法选取的前100个领域停用词的交集数目。可以看出, 相同数据集中, 各种方法产生的领域停用词差异较小, 不同数据集, 各种方法产生领域停用词差异较大。
表3 领域停用词交集数
| 数据集 | 方法 | 目标集 | 辅助集1 | 辅助集2 | ||||
|---|---|---|---|---|---|---|---|---|
| TF | DF | TF-IDF | ASDF | ASEC | ASDF | ASEC | ||
| 目标集 | TF | |||||||
| DF | 81 | |||||||
| TF-IDF | 88 | 69 | ||||||
| 辅助集1 | ASDF | 42 | 49 | 34 | ||||
| ASEC | 40 | 49 | 34 | 95 | ||||
| 辅助集2 | ASDF | 63 | 71 | 54 | 62 | 61 | ||
| ASEC | 60 | 70 | 52 | 64 | 65 | 93 | ||
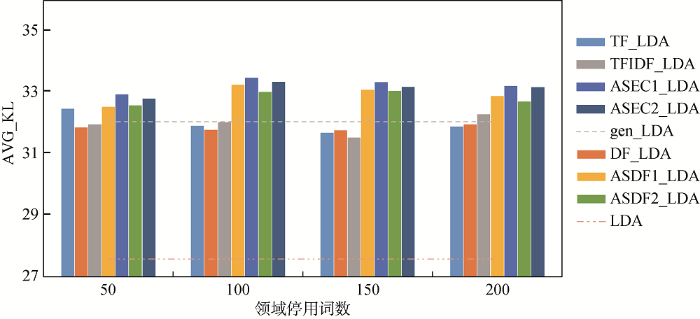
为评估本文提出的停用词选取方法对专利主题分析质量的影响, 实验分别依据5.1节选取领域停用词策略, 分别生成50、100、150、200个领域停用词, 利用移除领域停用词生成不同的专利文本集, 分别学习专利主题模型。表4列出了不同策略所对应的主题模型。为了便于比较, 实验引入没有移除任何停用词和仅仅移除通用停用词的主题模型, 作为基本模型, 分别称为LDA和gen-LDA。结果如图5所示。
表4 不同停用词移除方法对应的主题模型
| 数据集 | 停用词选取方法 | 主题模型 |
|---|---|---|
| 目标集 | 通用停用词+TF | TF_LDA |
| 通用停用词+DF | DF_LDA | |
| 通用停用词+TF-IDF | TFIDF_LDA | |
| 辅助集1 | 通用停用词+ASDF | ASDF1_LDA |
| 通用停用词+ASEC | ASEC1_LDA | |
| 辅助集2 | 通用停用词+ASDF | ASDF2_LDA |
| 通用停用词+ASEC | ASEC2_LDA |
(1) gen_LDA的平均KL大于LDA的平均KL, gen_LDA使用哈尔滨工业大学停用词表移除停用词, LDA模型没有移除任何停用词, 这表明通过移除通用停用词能够提高主题模型的质量;
(2) TF_LDA、DF_LDA、TFIDF_LDA平均KL距离均高于LDA的平均KL距离, 但是常常低于gen_LDA模型的平均KL距离。TF_LDA、DF_LDA和TFIDF_LDA均使用目标集, 利用词频或文本频率选取停用词, 这表明使用传统的目标集方法移除停用词并不能明显提高主题模型的区分度, 究其原因在于仅仅根据目标集的词频和文档频率不能准确地区分词语包含语义信息的多寡;
(3) ASDF1_LDA、ASEC1_LDA、ASDF2_LDA和ASEC2_LDA的平均KL均大于gen_LDA, 这表明利用辅助集选取停用词能够产生比传统方法更好的结果, 究其原因是因为利用辅助集能够更准确地识别信息量少的词语;
(4) ASDF1_LDA略优于ASDF2_LDA, ASEC1_LDA略优于ASEC2_LDA, 这表明利用 辅助集1得到的主题模型略优于辅助集2得到的 主题模型, 选择不相似的专利文本作为辅助集效果更好;
(5) ASEC1_LDA优于ASDF1_LDA, ASEC1_LDA优于ASDF1_LDA, 这表明使用类别信息熵ASEC方法度量词的分布好于使用文档频率ASDF方法, 原因是ASEC更细致地刻画词语分布, 从而产生更加精确的领域停用词。
为了得到直观效果, 实验分别给出使用专利主题文本中通常使用的方法, 即gen_LDA和5.2节中最优结果, 即移除100个领域停用词的ASEC1_LDA模型主题的前5个词, 如表5所示。
表5 专利主题模型比较
| 主题 | gen-LDA | ASEC1_LDA |
|---|---|---|
| 0 | 语音 识别 输入 用于 发明 | 数据 音频 识别 语音 生成 |
| 1 | 系统 交互 智能 机器人 基于 发明 | 特征 模型 合成 训练 解码 |
| 2 | 模块 系统 语音 技术 计算机 | 模块 电路 无线 传感器 通信 |
| 3 | 信号 连接 电路 述 发明 | 计算机 汉语 方案 输入 程序 |
| 4 | 控制 语音 指令 发明 用于 | 语音 装置 检测 判断 车载 |
| 5 | 数据 中 方法 文本 音频 包括 | 信息 移动 服务器 发送 播放 |
| 6 | 语音 方法 特征 模型 进行 | 语音 信号 输入 输出 声音 |
| 7 | 发明 进行 检测 时 识别 方法 | 系统 交互 机器人 智能 平台 |
| 8 | 信息 用户 语音 方法 述 | 装置 安装 电子 开关 显示屏 |
| 9 | 述 装置 上 智能 包括 | 语音 指令 命令 智能家居 遥控器 |
由表5可见, gen_LDA仅仅使用停用词表去除通用停用词, 而ASEC1_LDA则在去除通用停用词基础上, 利用辅助集通过类别熵选取停用词, 移除领域停用词。在gen_LDA主题模型中, 常出现一些表意性较差的词, 如“发明”、“方法”、“技术”、“包括”等。相比于传统gen_LDA方法, ASEC1_LDA模型利用辅助集, 根据类别熵, 自动选取信息量小和区分度低 的词作为领域停用词, 使得主题一致性较强, 更易于理解。
针对专利主题分析中领域停用词选取尚未有相关研究, 以及目前其他文本分析中常见领域停用词自动选取可能存在的问题, 本文根据专利文献的特点, 引入辅助集, 提出文档频率和类别熵, 衡量词的分布情况, 以自动选取领域停用词, 用于专利主题模型分析, 以提高专利主题模型的区分度与建模质量。实验表明相比于传统的领域停用词选取方法, 使用本文提出的基于辅助集的领域停用词选取方法能够更好地衡量词的分布特征, 更好地构建专利主题模型, 增加专利主题之间的距离, 增加可区分度。在后续的研究中, 将进一步研究辅助集选取的种类与规模对领域停用词选取及对专利主题分析的影响。
俞琰: 设计并实现算法, 撰写论文;
赵乃瑄: 提供研究思路, 采集数据, 分析实验结果, 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: yuyanyuyan2004@126.com。
[1] 俞琰. artificialVicePatent.xlsx. 智能语音专利文本集.
[2] 俞琰. haStopWordsList.txt. 哈尔滨工业大学停用词表.
[3] 俞琰. auPatent.xlsx. 辅助专利文本集.
[4] 俞琰. modelResult.rar. 建模算法和结果.
| [1] |
PatentMiner: Topic-driven Patent Analysis and Mining [C]// |
| [2] |
Identifying Technological Topics and Institution-topic Distribution Probability for Patent Competitive Intelligence Analysis: A Case Study in LTE Technology [J].https://doi.org/10.1007/s11192-014-1342-3 URL [本文引用: 1] 摘要
An extended latent Dirichlet allocation (LDA) model is presented in this paper for patent competitive intelligence analysis. After part-of-speech tagging and defining the noun phrase extraction rules, technological words have been extracted from patent titles and abstracts. This allows us to go one step further and perform patent analysis at content level. Then LDA model is used for identifying underlying topic structures based on latent relationships of technological words extracted. This helped us to review research hot spots and directions in subclasses of patented technology in a certain field. For the extension of the traditional LDA model, another institution-topic probability level is added to the original LDA model. Direct competing enterprises distribution probability and their technological positions are identified in each topic. Then a case study is carried on within one of the core patented technology in next generation telecommunication technology-LTE. This empirical study reveals emerging hot spots of LTE technology, and finds that major companies in this field have been focused on different technological fields with different competitive positions.
|
| [3] |
A Fuzzy Approach for Measuring Development of Topics in Patents Using Latent Dirichlet Allocation [C]// |
| [4] |
Generating Patent Development Maps for Technology Monitoring Using Semantic Patent-topic Analysis [J].https://doi.org/10.1016/j.cie.2016.06.006 URL [本文引用: 1] 摘要
Patent development maps (PDMs) are a useful visual and monitoring tool for technology-trend identification, and therefore proper technology planning, because they provide an overall understanding of a technology historical development and current stage. The rapid increase in technical data, however, has made it costly and time-consuming to monitor the technology development progress manually. Although some studies have suggested how to identify development paths among patents, little attention has been paid to synthetic consideration of the two core factors for PDMs: 1) the succession relationship among patents in terms of technological content, and 2) the technological taxonomies of individual patents. Therefore, this paper suggests a semantic patent topic analysis-based bibliometric method for PDM generation. The method consists of 1) collecting and preprocessing patents, 2) structuring each patent into a term vector, 3) identifying the technological taxonomies of patents by applying latent Dirichlet allocation, and 4) visualizing the development paths among patents through sensitivity analyses based on semantic patent similarities and citations. This method is illustrated using patents related to 3D printing technology. This method contributes to quantifying PDM generation and, in particular, will become a useful monitoring tool for effective understanding of the technologies including massive patents.
|
| [5] |
Firms’ Knowledge Profiles: Mapping Patent Data with Unsupervised Learning [J].https://doi.org/10.1016/j.techfore.2016.09.028 URL [本文引用: 1] 摘要
Patent data has been an obvious choice for analysis leading to strategic technology intelligence, yet, the recent proliferation of machine learning text analysis methods is changing the status of traditional patent data analysis methods and approaches. This article discusses the benefits and constraints of machine learning approaches in industry level patent analysis, and to this end offers a demonstration of unsupervised learning based analysis of the leading telecommunication firms between 2001 and 2014 based on about 160,000 USPTO full-text patents. Data were classified using full-text descriptions with Latent Dirichlet Allocation, and latent patterns emerging through the unsupervised learning process were modelled by company and year to create an overall view of patenting within the industry, and to forecast future trends. Our results demonstrate company-specific differences in their knowledge profiles, as well as show the evolution of the knowledge profiles of industry leaders from hardware to software focussed technology strategies. The results cast also light on the dynamics of emerging and declining knowledge areas in the telecommunication industry. Our results prompt a consideration of the current status of established approaches to patent landscaping, such as key-word or technology classifications and other approaches relying on semantic labelling, in the context of novel machine learning approaches. Finally, we discuss implications for policy makers, and, in particular, for strategic management in firms.
|
| [6] |
基于LDA模型的专利信息聚类技术 [J].
无线自组网按需平面距离矢量路由(AODV)算法在路由发现过程中会产生大量的广播消息,消耗了大量网络资源,严重影响了网络的服务质量(QoS)。针对这个不足,提出了一种跨层服务质量保障机制。使用了以信噪比(SNR)确定下一跳节点为准则的增强型无线自组网按需平面距离矢量路由(E-AODV)算法,并且应用了无线传输控制协议(WTCP)来提高数据传输可靠性。仿真结果表明,所提机制可以有效地将网络中的数据交付时延(DDL)减少近56%,同时将数据交付率(DDR)提高近24%。
Patent Information Clustering Technique Based on Latent Dirichlet Allocation Model [J].
无线自组网按需平面距离矢量路由(AODV)算法在路由发现过程中会产生大量的广播消息,消耗了大量网络资源,严重影响了网络的服务质量(QoS)。针对这个不足,提出了一种跨层服务质量保障机制。使用了以信噪比(SNR)确定下一跳节点为准则的增强型无线自组网按需平面距离矢量路由(E-AODV)算法,并且应用了无线传输控制协议(WTCP)来提高数据传输可靠性。仿真结果表明,所提机制可以有效地将网络中的数据交付时延(DDL)减少近56%,同时将数据交付率(DDR)提高近24%。
|
| [7] |
基于LDA主题模型的专利内容分析方法 [J].
主题模型是一种有效提取大规模文本隐含主题的建模方法.本文将Latent Dirichlet Allocation (LDA)主题模型引入专利内容分析领域,实现专利主题划分,解决以往专利主题分类过于粗泛、时效性差、缺乏科学性等问题.并在原有模型基础上构建LDA机构-主题模型,对专利知识主体和客体联合建模,实现专利主题和机构之间内在关系分析.最后,以通信产业LTE技术领域为例,验证该模型可以有效用于专利主题划分,实现各主题下专利知识主体竞争态势测度.
Patent Content Analysis Method Based on LDA Topic Model [J].
主题模型是一种有效提取大规模文本隐含主题的建模方法.本文将Latent Dirichlet Allocation (LDA)主题模型引入专利内容分析领域,实现专利主题划分,解决以往专利主题分类过于粗泛、时效性差、缺乏科学性等问题.并在原有模型基础上构建LDA机构-主题模型,对专利知识主体和客体联合建模,实现专利主题和机构之间内在关系分析.最后,以通信产业LTE技术领域为例,验证该模型可以有效用于专利主题划分,实现各主题下专利知识主体竞争态势测度.
|
| [8] |
基于AToT模型的技术主题多维动态演化分析——以石墨烯技术为例 [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.013 URL [本文引用: 2] 摘要
[目的/意义]基于AToT模型的多维动态演化分析,不仅可以全面地了解技术主题的动态变化,把握不同时期不同企业的技术布局变化,还可以掌握产业链各环节的技术发展状态,为企业创新提供强有力的决策支持.[方法/过程]首先提取专利文献摘要中的名词或者名词短语,然后利用AToT模型揭示专利文献中隐含的主题演化及专利权人的技术关注点,最后结合产业链信息把握产业各个环节的发展状况.[结果/结论]实验结果证明,该方法能够高效地分析专利的内容,揭示企业技术主题的动态演化过程.
Multi-dimension Dynamic Evolution Analysis of Technology Topics Based on AToT by Taking Grapheme Technology as an Example [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.013 URL [本文引用: 2] 摘要
[目的/意义]基于AToT模型的多维动态演化分析,不仅可以全面地了解技术主题的动态变化,把握不同时期不同企业的技术布局变化,还可以掌握产业链各环节的技术发展状态,为企业创新提供强有力的决策支持.[方法/过程]首先提取专利文献摘要中的名词或者名词短语,然后利用AToT模型揭示专利文献中隐含的主题演化及专利权人的技术关注点,最后结合产业链信息把握产业各个环节的发展状况.[结果/结论]实验结果证明,该方法能够高效地分析专利的内容,揭示企业技术主题的动态演化过程.
|
| [9] |
基于LDA模型和分类号的专利技术演化研究 [J].https://doi.org/10.3969/j.issn.1008-0821.2017.05.003 URL [本文引用: 1] 摘要
[目的 /意义]运用概率主题模型全面研究专利文献主题演化,分析专利技术发展过程及趋势。[方法/过程]LDA模型按时间窗口对专利文本建模,困惑度确定最优主题数,按专利文本结构特性提取主题向量,采用JS散度度量主题之间的关联,引入IPC分类号度量技术主题强度,最后实现主题强度、主题内容和技术主题强度3方面的演化研究。[结果 /结论]实验结果表明:该方法能够深入挖掘专利文献的主题,可以较好地分析专利技术随时间的演化规律,帮助相关从业人员了解专利技术的演化过程及趋势。
Research on Patent Technology Evolution Based on LDA Model and Classification Number [J].https://doi.org/10.3969/j.issn.1008-0821.2017.05.003 URL [本文引用: 1] 摘要
[目的 /意义]运用概率主题模型全面研究专利文献主题演化,分析专利技术发展过程及趋势。[方法/过程]LDA模型按时间窗口对专利文本建模,困惑度确定最优主题数,按专利文本结构特性提取主题向量,采用JS散度度量主题之间的关联,引入IPC分类号度量技术主题强度,最后实现主题强度、主题内容和技术主题强度3方面的演化研究。[结果 /结论]实验结果表明:该方法能够深入挖掘专利文献的主题,可以较好地分析专利技术随时间的演化规律,帮助相关从业人员了解专利技术的演化过程及趋势。
|
| [10] |
层次主题模型在技术演化分析上的应用研究 [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.014 URL [本文引用: 1] 摘要
[目的/意义]采用hLDA从专利语料库中抽取层次主题,以描述隐藏在专利文本中的技术结构,并基于层次主题随时间变化情况进行技术演化分析。[方法/过程]从专利术语中获取闭频繁项集,并基于此建立关联规则网络来度量术语的重要性和术语间语义关系强弱,进而对语料库进行重构,并对不同时间片段的专利集合进行层次主题结构抽取。[结果/结论]将本方法应用于硬盘驱动器磁头领域的专利数据分析,实证结果表明该方法是一种可行和有效的技术演化分析方法。
Application of Hierarchical Topic Model on Technological Evolution Analysis [J].https://doi.org/10.13266/j.issn.0252-3116.2017.05.014 URL [本文引用: 1] 摘要
[目的/意义]采用hLDA从专利语料库中抽取层次主题,以描述隐藏在专利文本中的技术结构,并基于层次主题随时间变化情况进行技术演化分析。[方法/过程]从专利术语中获取闭频繁项集,并基于此建立关联规则网络来度量术语的重要性和术语间语义关系强弱,进而对语料库进行重构,并对不同时间片段的专利集合进行层次主题结构抽取。[结果/结论]将本方法应用于硬盘驱动器磁头领域的专利数据分析,实证结果表明该方法是一种可行和有效的技术演化分析方法。
|
| [11] |
Information Retrieval: Data Structures and Algorithms [M]. |
| [12] |
The Importance of Stop Word Removal on Recall Values in Text Categorization [C] // |
| [13] |
中文文本聚类常用停用词表对比研究 [J].Chinese Stopwords for Text Clustering: A Comparative Study [J]. |
| [14] |
A Hybrid Approach to Concept Extraction and Recognition-based Matching in the Domain of Human Resources [C]// |
| [15] |
An Application of Text Categorization Methods to Gene Ontology Annotation [C]// |
| [16] |
|
| [17] |
Impact of Domain-specific Stop-word Lists on ECommerce Website Search Performance [J]. |
| [18] |
Automatically Building a Stopword List for an Information Retrieval System [J]. |
| [19] |
Automatic Identification of Stop Words in Chinese Text Classification [C]// |
| [20] |
Evolving Better Stoplists for Document Clustering and Web Intelligence [C]// |
| [21] |
Unsupervised Keyword Extraction from Polish Legal Texts [C]// |
| [22] |
Extracting Domain-specific Stopwords for Text Classifiers [J].https://doi.org/10.3233/IDA-150390 URL [本文引用: 1] |
| [23] |
中文停用词表的自动选取 [J].https://doi.org/10.3969/j.issn.1001-0645.2005.04.014 URL [本文引用: 1] 摘要
通过对现有基于统计的停用词选取方法的考察,提出了一种新的停用词选取方法.用该方法分别计算词条在语料库中各个句子内发生的概率和包含该词条的句子在语料库中的概率,在此基础上计算它们的联合熵,依据联合熵选取停用词.将该方法与传统方法选取的停用词表进行了对比,并比较了将各种方法用于文本分类的预处理时对分类效果的影响.实验结果表明,该方法更好地避免了语料的行文格式对停用词选取的影响,比传统方法更适用于文本分类的预处理.
Automatic Selection of Chinese Stoplist [J].https://doi.org/10.3969/j.issn.1001-0645.2005.04.014 URL [本文引用: 1] 摘要
通过对现有基于统计的停用词选取方法的考察,提出了一种新的停用词选取方法.用该方法分别计算词条在语料库中各个句子内发生的概率和包含该词条的句子在语料库中的概率,在此基础上计算它们的联合熵,依据联合熵选取停用词.将该方法与传统方法选取的停用词表进行了对比,并比较了将各种方法用于文本分类的预处理时对分类效果的影响.实验结果表明,该方法更好地避免了语料的行文格式对停用词选取的影响,比传统方法更适用于文本分类的预处理.
|
| [24] |
蒙古文停用词和英文停用词比较研究 [J].https://doi.org/10.7666/d.y1887441 URL Magsci [本文引用: 1] 摘要
该文采用联合熵算法(Union Entropy,UE)初步确定了蒙古文停用词,接着从初步确定的蒙古文停用词中去掉蒙古文实体名词及同形异义词,再通过对英文停用词和蒙古文停用词的词性比较,确定了蒙古文停用词表。最后用蒙古文停用词表和英文停用词表进行了文档信息检索的对比实验。实验结果表明,用该文所述方法确定的蒙古文停用词表进行蒙古文文档检索,比用英文停用词翻译成蒙古文进行蒙古文文档检索的准确率更高。
A Comparative Study on Between Mongolian Stop Words and English Stop Words [J].https://doi.org/10.7666/d.y1887441 URL Magsci [本文引用: 1] 摘要
该文采用联合熵算法(Union Entropy,UE)初步确定了蒙古文停用词,接着从初步确定的蒙古文停用词中去掉蒙古文实体名词及同形异义词,再通过对英文停用词和蒙古文停用词的词性比较,确定了蒙古文停用词表。最后用蒙古文停用词表和英文停用词表进行了文档信息检索的对比实验。实验结果表明,用该文所述方法确定的蒙古文停用词表进行蒙古文文档检索,比用英文停用词翻译成蒙古文进行蒙古文文档检索的准确率更高。
|
| [25] |
藏文停用词选取与自动处理方法研究 [J].https://doi.org/10.3969/j.issn.1003-0077.2015.02.015 URL Magsci [本文引用: 1] 摘要
停用词的处理是文本挖掘中一个关键的预处理步骤。该文结合现有停用词的处理技术,研究了基于统计的藏文停用词选取方法,通过实验分析了词项频率、文档频率、熵等方法的藏文停用词选用情况,提出了藏文虚词、特殊动词和自动处理方法相结合的藏文停用词选取方法。实验结果表明,该方法可以确定一个较合理的藏文停用词表。
Research on Tibetan Stop Words Selection and Automatic Processing Method [J].https://doi.org/10.3969/j.issn.1003-0077.2015.02.015 URL Magsci [本文引用: 1] 摘要
停用词的处理是文本挖掘中一个关键的预处理步骤。该文结合现有停用词的处理技术,研究了基于统计的藏文停用词选取方法,通过实验分析了词项频率、文档频率、熵等方法的藏文停用词选用情况,提出了藏文虚词、特殊动词和自动处理方法相结合的藏文停用词选取方法。实验结果表明,该方法可以确定一个较合理的藏文停用词表。
|
| [26] |
Latent Dirichlet Allocation [J]. |

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}