
|
|
李贺, 祝琳琳 , 闫敏, 刘金承, 洪闯
, 闫敏, 刘金承, 洪闯
吉林大学管理学院 长春 130022
Li He, Zhu Linlin, Yan Min, Liu Jincheng, Hong Chuang
中图分类号: G203
通讯作者:
收稿日期: 2018-04-8
修回日期: 2018-06-19
网络出版日期: 2018-12-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】探究如何从信息数量庞杂冗余、内容质量参差不齐的开放式创新社区中识别出高度有用的用户反馈信息。【方法】以信息采纳模型为理论基础, 抓取小米MIUI社区官方论坛23 137条Bug反馈信息作为研究对象, 利用二元逻辑回归, 从信息质量和信息源可信性两个维度探讨影响开放式创新社区信息有用性的因素。【结果】在信息质量方面, 信息及时性对信息有用性有正向影响, 信息完整性对信息有用性有影响, 信息语义性对信息有用性有负向影响; 在信息源可信性方面, 用户先前经验不会影响信息有用程度, 但用户主动贡献程度对信息有用性有正向影响。【局限】仅研究一个社区的一个版块, 结果欠缺普适性。【结论】本研究提取的信息有用性关键影响因素能够有效提升开放式创新社区中用户信息有用性识别的效率与准确度。
关键词:
Abstract
[Objective] The paper aims to identify useful message from open innovation community with numerous redundant and low quality information. [Methods] First, we retrieved 23,137 users’ comments on programming bugs from the official Xiaomi MIUI Forum based on the information adoption model. Then, we applied binary logistic regression method to explore factors affecting the usefulness of these comments. [Results] The timeliness of information had positive impact on their usefulness, the integrity of information also affected their usefulness, and the semantics of information had negative effects on their usefulness. The users’ previous experience did not influence the usefulness of information. However, users’ previous contribution had positive effects on the usefulness of information. [Limitations] The research data was collected from small portion of one community, which might yield biased results. [Conclusions] This paper could help us effectively identify usefulness information from open innovation communities.
Keywords:
清科研究中心发布的《2016年中国大企业开放式创新发展研究报告》指出, 2009年-2013年, 世界150强企业年报中提及开放式创新的平均次数增长了51.6%, 开放式创新在大企业中的接受度不断提升, 为大企业持续带来发展新动能[1]。2003年, 美国学者Chesbrough[2]首次提出开放式创新, 强调突破组织边界束缚, 寻求外部知识来源及合作机会。Bullinger等[3]指出, 开放式创新是以用户为中心的创新。用户是产品和服务的使用者和评价者, 对产品和服务的实际有效性存在预期并能提供丰富的创新思想[4]。在网络迅猛发展的Web2.0时代和开放式创新背景下, 开放式创新社区成为最受欢迎的开放式创新实施机制之一, 为用户创新提供更广泛的空间[5]。开放式创新社区是基于互联网的协同创新平台, 强调企业外部用户的创新贡献, 聚焦产品问题解决或产品方案开发, 逐渐成为企业知识创新的重要来源, 例如戴尔IdeaStorm社区、星巴克MyStarbucks社区、小米MIUI社区官方论坛及海尔众创意社区等均是开放式创新社区的典型代表。
目前, 国内外学者关于开放式创新社区的研究主要集中在社区用户识别、运营管理和创新绩效等方面。Martinez-Torres等[6]结合社会网络分析方法, 以戴尔IdeaStorm社区作为研究案例, 利用群体智能的方法识别社区中的用户。廖晓等[7]基于加权聚类网络, 通过采集开放式创新社区内容, 对社区知识发现进行建模并提出分析方法。戚桂杰等[8]以星巴克MyStarbucks社区为例, 采集用户创意数量、创意综合得分、创意获得评论的数量和对其他用户创意的评论数量4项指标, 采用聚类算法划分用户类型。Gangi等[9]提出在线用户社区成功整合到组织创新过程中可能面临的4个主要挑战, 即理解发布的想法、确定最佳想法、平衡社区需求透明度与向竞争对手披露的关系以及维持社区, 并提出7条克服这些挑战的建议。李奕莹等[10]基于创新价值链视角, 提出开放式创新社区成功运营的关键因素。詹湘东[4]通过案例分析, 证明开放式创新社区终端用户的有效融入能提高组织获取外部创新源的能力, 提升创新效率。
根据现有的国内外研究成果, 虽然能够对开放式创新社区中的优秀用户进行有效识别, 通过用户的正确分类改进创意信息评估过程, 但是对信息质量本身进行评估的研究相对较少。由于开放式创新社区每天都会产生成百上千的用户反馈信息, 社区维护及管理人员需要对每条信息逐一进行详细阅读、评估、筛选、判定、回复等, 这将耗费大量人力物力, 降低开放式创新社区的运行效率。同时, 社区中存在信息质量参次不齐、信息主题归类混乱、同类信息重复提交、问题反馈不完全等问题, 这些问题会严重阻碍社区维护及管理人员及时发现有价值信息, 甚至会淹没真正有价值的反馈信息, 造成有用信息丢失。因此, 本文基于信息采纳模型, 以小米MIUI社区官方论坛的Bug反馈板块作为研究对象, 运用Python语言和SPSS软件, 结合语义主题挖掘, 提取影响信息有用性的关键影响 因素, 对开放式创新社区信息的有用性识别进行实证分析。
信息采纳模型(Information Adoption Model, IAM)起源于精细加工可能性模型(Elaboration Likelihood Model, ELM) [11], 即信息接收者会受到两条路线上的信息影响, 分别是中心路线和边缘路线。中心路线指信息的核心, 而边缘路线指与信息核心间接相关的问题。之后, Sussman等[12]在技术接受模型(Technology Acceptance Model, TAM)和双加工模型(Dual Process Model, DPM)的基础上融合精细加工可能性模型, 提出信息采纳模型, 理论模型如图1所示。
信息采纳模型包括4个要素, 即信息质量、信息源可信性、信息有用性和信息采纳。信息质量代表中心路线, 信息源可信性代表边缘路线, 二者是预测信息有用性的重要影响因子。在低水平的精细加工下(边缘路线), 信息接收者受到一些简单决策规则的影响, 例如信息来源的可信度; 在高度精细加工下(中心路线), 信息接收者受到仔细分析信息质量和论据的影响。同时, 信息有用性在影响过程和信息采纳之间起到中介作用。
信息采纳模型是研究信息有用性时最常用的理论模型, 该模型解释了信息接收者如何受以计算机为传播平台的信息的影响。Shu等[13]和Erkan等[14]在社交媒体背景下使用该模型; Cheung等[15]在在线论坛的背景下应用该模型; Salehi-Esfahani等[16]应用该模型的改进模型探讨在线评论信息的有用性。在开放式创新社区中, 用户与平台管理者以社区平台为媒介进行产品沟通, 管理者对用户反馈信息的处理实际上是评估该信息是否有用, 进而决定是否采纳的过程。这些步骤与信息采纳模型中的信息处理过程一致, 因此本文选择该模型作为开放式创新社区信息有用性研究的理论基础。
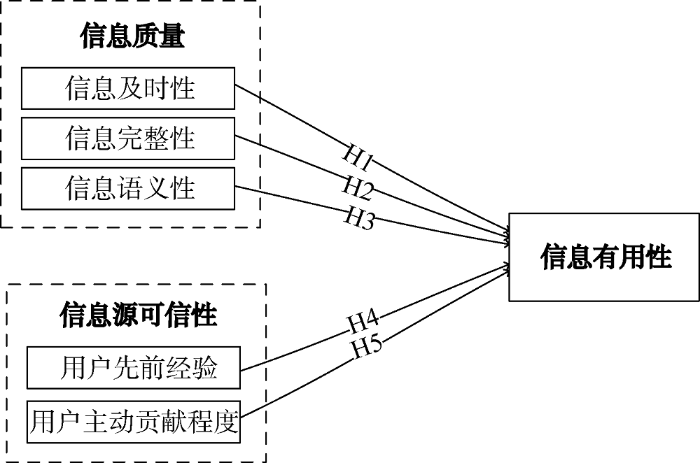
本研究借鉴信息采纳模型基础框架, 结合开放式创新社区特征和具体情境, 对信息质量和信息源可信性这两个维度的测量进行重新识别、划分并提出研究假设。
(1) 信息质量
目前, 针对信息质量的测量有多种划分方式, Wixom等[17]提出信息质量测量的4个维度: 完整性、准确性、及时性和格式, 是信息质量测量中被广泛认可和常用的组成部分。完整性指信息来源提供所有必要内容的程度; 准确性代表用户对信息正确的看法; 及时性代表用户对信息最新和及时程度的看法; 格式指用户对信息呈现效果的看法。Wang等[18]从用户角度出发, 提出衡量信息质量的4个维度: 内在信息质量、情境信息质量、可存取性信息质量和形式信息质量。Wang等[19]认为信息质量是一个多层次多维度的概念, 测量维度包含可存取性、可理解性、完整性、可靠性, 在可理解性下又细分为语法可理解和语义可理解。Xiang等[20]指出, 衡量信息质量的一个重要度 量是语义特征, 即语言实体之间词语主题和语义的 关系。
本文借鉴各项研究中对信息质量的测度, 根据对开放式创新社区实际内容呈现情况的了解, 从信息质量的及时性、完整性、语义性三个角度提出以下假设:
H1: 信息及时性影响开放式创新社区信息有用性。
H2: 信息完整性影响开放式创新社区信息有用性。
H3: 信息语义性影响开放式创新社区信息有用性。
(2) 信息源可信性
信息源定义为发起信息并向人们表达意见的人, 信息源可信性具体表现为专业性和真实性[21]。在开放式创新社区中, 用户就是产生创新思路的源泉, 因此强调以用户为中心。Lohan等[22]提出, 以用户为中心包含收集和了解用户需求、收集和使用用户信息、接收和利用用户反馈、改善用户关系, 并且通过案例分析指出用户身份、用户位置、用户个性、团队与用户的先前经验这4个要素对以用户为中心的影响。Gretzel等[23]指出, 信息有用性取决于评论者感知的经验水平。Mcauley等[24]交替使用“经验”(Experience)和“专业知识”(Expert)两个词, 指出人们更倾向于接受具有高可信度的信息源传播的信息。
在开放式创新研究中, 原欣伟等[25]结合领先用户特征, 基于机器学习算法识别领先用户。领先用户的概念由Von Hippel提出[26], 根据用户在创新意愿和创新能力等方面的差异, 将用户分为普通用户和领先用户。与被动的贡献相比, 领先用户以积极主动的方式提供的贡献包含更多新颖的见解[27]。
本文借鉴各项研究中对信息源可信性的测度, 根据开放式创新社区中用户身份信息的呈现情况, 从信息源可信性中信息发布者的先前经验和主动贡献程度两个角度提出以下假设:
H4: 用户先前经验影响开放式创新社区信息有用性。
H5: 用户主动贡献程度影响开放式创新社区信息有用性。
基于上述研究假设, 本文研究模型如图2所示。
(1) 数据采集
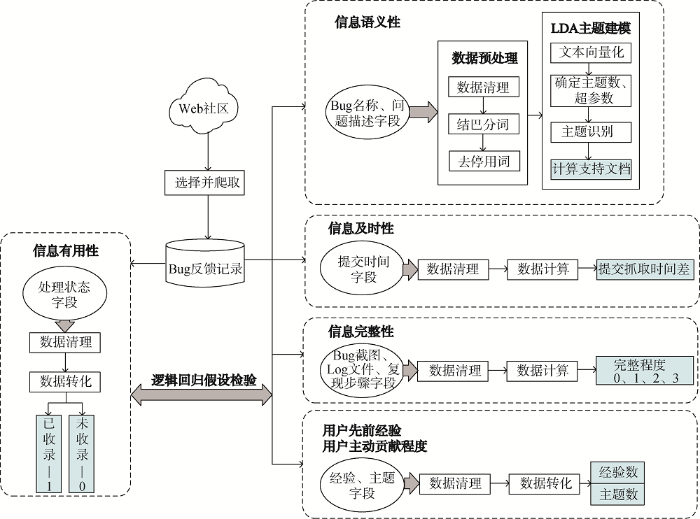
小米MIUI社区官方论坛(简称MIUI社区)是国内典型的开放式创新社区, 该社区通过互联网收集大量用户信息与需求, 把用户参与纳入到产品发展与品牌树立中, 让用户参与产品设计与反馈。本研究选取MIUI社区中的Bug反馈板块, 在Python中引入urllib模块, 编写爬虫程序, 抓取内容如下:
①该板块一级目录下的提交时间、处理状态、Bug名称、提交人字段;
②Bug名称二级目录下的问题描述、复现步骤、Bug截图、Log文件字段;
③提交人二级目录下的经验、发布主题字段。爬取时间为2018年1月31日。由于Bug反馈信息板块仅显示第1-999页的反馈信息, 因此最终共采集数据23 189条。
(2) 数据清理
本研究共采集到23 189条数据, 为保证研究数据的准确性, 需要删除清理的数据包括: MIUI开发组/热心解答组发布的关于反馈方式模板、格式问题或对某些问题的统一解答的置顶文章8条; 关于问题解答及汇总的精华帖2条; MIUI资源组后续考虑开发的帖子1条; 发布时间久远的帖子2条; 非中文字符及无意义字符数据的帖子39条。最后保留23 137条反馈数据作为分析样本。
(3) 数据预处理
数据预处理是对文本类型数据的处理, 包括分词和去停用词。
分词: 抓取到的文本数据需要将其切分成一个个独立的词。该部分分词采用编程语言Python, 引入jieba模块运行结巴中文分词包, 形成不同的反馈信息词袋(Bag of Words)。
去停用词: 文本数据中或多或少会出现无实际意义的词, 称为停用词, 需要将这些词去除。本研究采用哈尔滨工业大学停用词表, 由于网络信息文本的多样性, 笔者还在表中添加了部分停用词表中没有的符号。
本研究需预处理的文本是Bug名称和问题描述字段, 处理结果为文本语义主题挖掘提供数据准备。
为验证研究假设, 设置信息及时性、信息完整性、信息语义性、用户先前经验、用户主动贡献程度为自变量, 信息有用性为因变量。
(1) 信息及时性
笔者与社区开发组人员私信交流得知, 开发组管理人员会根据Bug处理进度修改反馈信息的处理状态, 因此信息时效性尤为重要。本研究关注信息提交时间与抓取时间的间隔(以天为单位), 计算方式如公式(1)所示。
$X1=T-t$ (1)
其中, X1代表信息及时性, T代表信息抓取时间, 即2018年1月31日, t代表信息提交时间。若信息提交时间为2018年1月28日, 则$X1=31-28=3$。
(2) 信息完整性
虽然社区中的Bug反馈信息会有Bug名称和问题的文字描述, 但是有时候社区管理者会回复如“Log文件中没有有效信息, 请下次重启后及时抓取Log”等类似的留言。准确的Bug复现步骤有助于测试人员在短时间内准确发现并修改Bug, 减少试错时间。因此, 根据社区该板块实际填写的内容, 本研究将信息完整性进一步划分为是否有Bug截图、是否有Log文件、是否有复现步骤三个子变量, 每个子变量是一个二分类变量, 有记为1, 无记为0。计算方式如公式(2)所示。
$X2=\left\{ \begin{matrix} 3\ \ (三者均有) \\ 2\ \ (仅有两者) \\ 1\ \ (仅有一者) \\ 0\ \ (三者均无) \\\end{matrix} \right.\quad\quad\quad\quad(2)$
其中, X 2代表信息完整性, 这里将信息完整性量化处理为取值仅为0、1、2、3的变量, 数值越大, 说明该条反馈信息越完整。
(3) 信息语义性
语义即信息的含义, 只有识别出信息本身的含义, 才能够客观地评价信息质量。通过主题模型挖掘的主题可以帮助人们理解海量文本背后隐藏的语义[28]。主题模型主要包括隐式狄利克雷分布(Latent Dirichlet Allocation, LDA)、潜在语义索引(Latent Semantic Indexing, LSI)、潜在语义分析模型(Latent Semantic Analysis, LSA)、概率潜在语义模型分析(Probabilistic Latent Semantic Analysis, PLSA)。其中, LDA主题模 型[29]是近年来文本挖掘领域的一个热门研究方向, 主要应用于微博[30]、健康社区[31]、论坛[32]、政务新闻[33]、投诉文本[28]等研究领域。
对信息语义性的量化研究主要通过LDA模型识别出全部反馈信息的多个主题, 分别统计每个主题下属于该主题的反馈信息数量, 即支持文档数, 并将该数值作为该主题下全部支持文档(反馈信息)的语义性量化结果。某目标文档话题的支持文档越多, 说明该主题被反馈的次数越多, 该目标文档反映的主题越热门。本文借鉴前人研究, 将LDA应用在开放式创新社区中。
①LDA主题模型
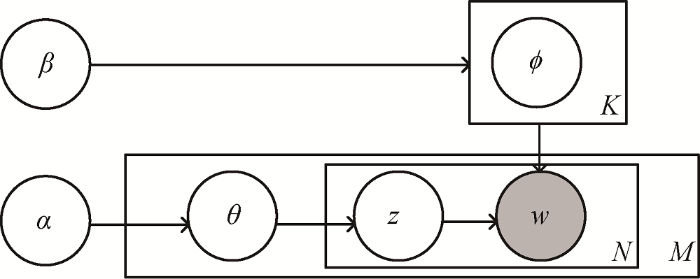
LDA主题模型[34]由Blei等于2003年提出, 是一种无监督机器学习算法, 运用词袋模型简化问题复杂性。LDA是用于发现文档集合中出现的抽象“主题”的三层贝叶斯概率模型, 包含文档、主题、词语三个层次。它的主要思想是, 每一篇文档是一些隐藏的主题构成的概率分布, 每一个主题是多个单词构成的概率分布, 这些分布均服从Dirichlet 先验分布。LDA主题模型的原理可用“盘子表示法”(Plate Notation)表示, 如图3所示。
其中, 阴影圆圈表示可观测变量, 非阴影圆圈表示潜在变量, 箭头表示两变量间的条件依赖性, 方框表示重复抽样, 重复次数在方框右下角。具体符号含义如表1[35]所示, 超参数α和β利用Gibbs采样方法进行估计, 分别设置为50/K和0.01[36]。
②困惑度
在LDA模型中, 主题数目K的选择是一个关键问题, 研究者会根据待解决问题的实际情况或经验选择K。另一种客观的方法由LDA原作者Blei等提出[34], 即计算整个文档集的困惑度(Perplexity)。困惑度指标是确定模型最优主题数目的一种方法, 反映模型泛化能力, 该值越小, 表示该模型的泛化能力越强, 性能越优[37]。困惑度计算方法如公式(3)[30]所示。
$perplexity\text{(}D\text{)}=\exp \left\{ -\frac{\mathop{\sum }_{d=1}^{M}logp({{w}_{d}})}{\mathop{\sum }_{d=1}^{M}{{N}_{d}}} \right\}$ (3)
其中, D表示测试的文档集, 共M篇文档, Nd表示每篇文档d中的总词语数, wd表示文档d中的词语, p(wd)表示文档d中每个词wd产生的概率乘积结果(文档-词语概率矩 阵可通过文档-主题概率矩阵与主题-词语概率矩阵相乘 得到)。
③支持文档
根据LDA的思想, 每一篇文档由多个不同主题根据一定的概率值产生[34]。徐佳俊等[32]认为如果一个文档中有不少于某百分比的词是由话题z生成的, 则认为此文档是话题z的支持文档。在MIUI社区的Bug反馈板块中, 通常用户反馈的每条信息主题都是唯一的, 根据支持文档的界定, 选择每一个文档中概率值最大的主题作为该文档主题, 认为此文档是该主题的支持文档。例如, 假设有Dn个反馈文档, 若D1、D2、D3三个文档均属于主题Tx, 则主题Tx的支持文档数为3, 于是, D1、D2、D3三个反馈文档的信息语义性均被赋值为3; 若文档D4属于主题Ty, 则主题Ty的支持文档数为1, 文档D4的信息语义性被赋值为1。显然, 文档D1、D2、D3的语义性量化结果大于文档D4, 主题Tx的反馈热度大于主题Ty。
每一条反馈信息代表一个文档, 为实现信息语义性的量化过程, 在Python中安装并引入LDA模块; 编写程序计算各个主题个数K的困惑度值, 选出最优主题数K; 设置超参数和迭代次数, 运行LDA模型识别文档的主题; 计算每个主题的支持文档数, 对每条反馈信息的语义性进行量化赋值。
(4) 用户先前经验
用户先前经验可以通过MIUI社区中每个用户的经验值体现, 经验值代表用户过去经验的累加成果, 该指标是用户在社区中的历史经验。
(5) 用户主动贡献程度
用户的主动贡献会带来更多新颖的见解, 在MIUI社区中, 用户的主题数值代表该用户过去主动发布的帖子数量, 是衡量用户历史主动贡献程度的重要指标。
(6) 信息有用性
在MIUI社区的Bug反馈板块中, 已处理的每条反馈都会以印章方式标注其处理状态, 分别是: 已收录、处理中、待讨论、请补充、确认解决、未解决、已答复、已关联、已解决和已提交。
笔者与开发组人员通过私信交流了解到, “已收录”表示已交给开发人员并需要进行修复的问题; “请补充”通常是缺少复现步骤、文件等详细完整反馈内容, 或是开发人员、其他用户已对其回复或提出解决方法, 并未达到可以将其收录的程度; “已答复”通常是不算Bug的问题, 可能是今后优化的方向, 已经得到回复或解答; “已解决”和“确认解决”通常是问题已经修复或正在修复, 也可能是系统升级之后已经解决完毕; “处理中”通常是此问题正在积极解决、已经在处理进程中或已经修复; “待讨论”通常是反馈问题不明确且有待讨论; “未解决”通常是开发测试时没有出现过此情况; “已提交”通常是反馈问题已提交完毕; “已关联”通常是指有相似的反馈问题。
除“已收录”处理状态外, 其他状态都在一定程度上反映该反馈信息的不完整性、滞后性、不明确性、重复性等。本研究认为, 处理状态为已收录的信息代表当前时间实时最有用的反馈信息。将用户反馈信息按照有用程度分级, 已收录信息记为1、其他状态信息记为0。
本研究变量量化设计说明如表2所示。
表2 研究变量量化设计说明
| 变量类型 | 变量名 | 量化方法 | 测度类型 |
|---|---|---|---|
| 自变量 | 信息及时性(X1) | 提交时间与抓取时间差 | 比率变量 |
| 信息完整性(X2) | 根据Bug截图、Log文件、复现步骤有无, 取值为0,1,2,3 | 顺序变量 | |
| 信息语义性(X3) | 信息所属主题的全部支持文档数 | 比率变量 | |
| 用户先前经验(X4) | MIUI社区中每个用户的经验值 | 比率变量 | |
| 用户主动贡献程度(X5) | MIUI社区中每个用户的主题值 | 比率变量 | |
| 因变量 | 信息有用性(Y) | 已收录状态为1, 其他为0 | 名义变量 |
基于上述数据采集、预处理和变量设计过程, 本文总体研究流程设计如图4所示。
(1) 确定主题数
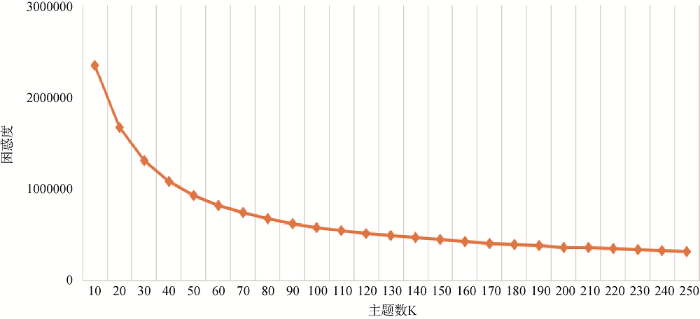
训练分词之后的文本数据, 绘制出主题数与困惑度分布折线图如图5所示。按照文献[34], 当困惑度值的下降曲线变得平缓时, 模型达到最优, 所以K的最佳取值应该在200左右, 结合社区该板块内容主题的实际划分情况, 本研究取主题数K=200。参数α和β分别设置为50/K和0.01, 即α=50/200, β=0.01。
(2) 主题及支持文档
由于篇幅限制, 仅列出支持文档数最多的前20个主题以及每一个主题下概率最高的前10个词语, 如表3所示。
表3 主题、词语及支持文档数(部分)
| 主题 | 支持文档数 | 词语 |
|---|---|---|
| 16 | 512 | 耗电 太快 用电 排行 不敢 好点 玩玩 更快 极度 优化 |
| 14 | 360 | 闪退 就会 阴阳师 退后 没事 终结者 填充 成语 蓝光 多久 |
| 2 | 335 | 手势 全面 返回 全屏 闪屏 桌面 底部 触发 操作 灵敏度 |
| 10 | 309 | 小时 没电 充满 耗电 两个 满电 半个 玩游戏 三个 不到 |
| 68 | 307 | 相册 图片 照片 分享 私密 发送 相片 缩略图 美化 图库 |
| 179 | 307 | 音乐 播放 网易 歌曲 暂停 播放器 歌词 酷狗 听歌 一首 |
| 42 | 293 | 运行 停止 屡次 错误报告 信条 看书 星火 用个 还好 适用 |
| 1 | 292 | 论坛 miui 分屏 帖子 新版 板块 哔哩 解答 发帖 版块 |
| 121 | 264 | 解锁 指纹 人脸 指纹识别 录入 屏后 解开 录取 手指 平面 指纹锁 |
| 104 | 263 | 公交 nfc 充值 刷卡 地铁 一卡通 成功 余额 开通 重庆 |
| 100 | 259 | 耗电 很快 超级 快如闪电 非常 越来越快 特快 巨快 闪电 虚电 |
| 131 | 255 | 视频 播放 观看 爱奇艺 本地 优酷 腾讯 播放器 暂停 视频卡 |
| 15 | 250 | 流量 校正 套餐 剩余 校准 监控 查询 统计 矫正 联通 |
| 119 | 238 | 电话 打电话 接电话 挂断 接听 拨打 接通 免提 接听电话 进来 |
| 5 | 237 | 录制 声音 屏幕 系统 录屏 麦克风 扬声器 选项 白点 内录 |
| 36 | 234 | 桌面 动画 回到 返回 退回 过渡 主页 效果 闪动 过度 |
| 71 | 230 | 开机 关机 自动关机 定时 电源 开关机 自动开机 按住 百分之五十 定时开关 |
| 41 | 223 | 状态栏 颜色 白色 背景 黑色 看不见 变成 看不清 白条 变色 |
| 124 | 221 | 死机 重启 经常 频繁 卡机 强制 卡主 关键 改写 同样 |
| 23 | 219 | 后台 程序 锁定 运行 进程 圆角 自启 上锁 限制 后台任务 |
其中, 主题16支持文档数最多, 该主题下的词语体现用户对手机耗电问题的反馈。总的来说, 用户反馈的Bug问题多在手机系统底层(如耗电、闪退、重启)、多媒体应用(如相册、音乐、视频)和系统应用(如指纹、公交卡)方面。
(1) 描述性统计分析
各变量的描述性统计结果如表4所示。其中, 变量X4的最小值为负数, 笔者追溯源数据发现该用户的经验值确实为-56, 所以并未将其剔除。
表4 描述性统计分析结果
| 及时性X1 | 完整性X2 | 语义性X3 | 经验X4 | 主动贡献X5 | 信息有用性Y | |
|---|---|---|---|---|---|---|
| 均值 | 24.21 | 1.27 | 165.27 | 2 489.60 | 34.53 | 0.17 |
| 标准差 | 11.83 | 0.57 | 93.68 | 6 120.40 | 102.57 | 0.38 |
| 极小值 | 0 | 0 | 16 | -56.00 | 1 | 0 |
| 极大值 | 45 | 3 | 512 | 182 092.00 | 2 958 | 1 |
各自变量之间的相关系数如表5所示。通常系数大于0.75说明两变量具有较强的共线性。变量X4与X5相关系数为0.677, 相关性较强, 但二者的方差膨胀因子为1.85(小于10), 容差为0.54(大于0.5), 因此排除二者的共线性关系。
表5 变量相关系数
| 及时性 X1 | 完整性X2 | 语义性 X3 | 经验 X4 | 主动贡献X5 | |
|---|---|---|---|---|---|
| 及时性X1 | 1 | -0.043 | -0.021 | 0.024 | 0.026 |
| 完整性X2 | -0.043 | 1 | -0.048 | 0.097 | 0.094 |
| 语义性X3 | -0.021 | -0.048 | 1 | -0.012 | -0.020 |
| 经验X4 | 0.024 | 0.097 | -0.012 | 1 | 0.677 |
| 主动贡献X5 | 0.026 | 0.094 | -0.020 | 0.677 | 1 |
(2) 逻辑回归分析
本文自变量为信息有用性并将其量化为是否收录, 是一个标准的二分类变量, 采用SPSS软件的二元逻辑回归方法进行假设检验[38]。模型系数综合检验如表6所示, χ2=70.906, P=0.000<0.05; H-L检验如表7所示, P=0.078>0.05, 所以该模型拟合良好。
①信息质量
逻辑回归分析结果如表8所示。
表8 逻辑回归分析结果
| B | Sig. | Exp(B) | |
|---|---|---|---|
| 及时性X1 | 0.006 | 0.000 | 1.006 |
| 完整性X2 | / | 0.011 | |
| 完整性X2(1) | 0.724 | 0.008 | 2.062 |
| 完整性X2(2) | 0.703 | 0.008 | 2.019 |
| 完整性X2(3) | 0.622 | 0.020 | 1.862 |
| 语义性X3 | -0.001 | 0.000 | 0.999 |
| 经验X4 | 0.000 | 0.215 | 1.000 |
| 主动贡献X5 | 0.001 | 0.002 | 1.001 |
1)信息及时性X1的系数为正且P值显著(P=0.000), 表明信息及时性影响开放式创新社区信息有用性, 且影响为正, H1得到支持, 即反馈信息提交时间距离当前越远, 该信息被收录的可能性越大, 每增加1个单位, 可能性是原来的1.006倍。
2)对于多分类变量完整性X2, P值显著(P=0.011), 表明信息完整性影响开放式创新社区信息有用性, H2得到支持。其中, 设置得分“3”为参照组, X2(1)、X2(2)、X2(3)分别代表得分为0、1、2, 4种完整程度的信息有用程度不相同且均显著。根据X1、X2、X3的系数B及比数比Exp(B), 完整性为0、1、2的信息有用程度均高于完整性为3的反馈信息。
3)信息语义性X3的系数为负且P值显著(P=0.000), 表明信息语义性影响开放式创新社区信息有用性, 且影响为负, H3得到支持, 即反馈信息支持文档数越大, 该信息被收录的可能性越小, 每增加1个单位, 可能性减少为原来的0.999倍。一般来说, 大多数用户都会反馈的主题体现了该信息主题的热度, 但是同时也面临着相似主题重复反馈的问题。对于成熟的手机系统, Bug问题是少数的, 一旦大多数用户都检测到同一主题的问题, 则该反馈信息的有用程度会在一定程度上减少, 反而是提及相对较少、新颖正确的反馈信息有用性更强。
②信息源可信性
用户经验X3的P值不显著(P=0.215), 表明用户先前经验不会影响开放式创新社区信息有用性, H4没有得到支持。用户主动贡献程度X5的系数为正且P值显著(P=0.002), 表明用户主动贡献程度影响开放式创新社区信息有用性, 且影响为正, H5得到支持, 即用户过去主动贡献的信息越多, 该用户反馈的信息被收录的可能性越大, 每增加1个单位, 可能性是原来的1.001倍。
全部假设检验结果如表9所示。
表9 假设检验结果
| 类别 | 假设 | 结果 |
|---|---|---|
| 信息质量 | H1: 信息及时性影响开放式创新社区信息有用性 | 支持 |
| H2: 信息完整性影响开放式创新社区信息有用性 | 支持 | |
| H3: 信息语义性影响开放式创新社区信息有用性 | 支持 | |
| 信息源 可信性 | H4: 用户先前经验影响开放式创新社区信息有用性 | 不支持 |
| H5: 用户主动贡献程度影响开放式创新社区信息有用性 | 支持 |
本文以从MIUI社区获取的23 137条Bug反馈为研究对象, 基于信息采纳模型, 利用二元逻辑回归, 从信息质量和信息源可信性两个影响维度, 对开放式创新社区中大量用户反馈信息进行有用性识别。研究结果表明, 在信息质量方面, 信息及时性对信息有用性有正向影响, 信息完整性对信息有用性有影响, 信息语义性对信息有用性有负向影响; 在信息源可信性方面, 用户主动贡献程度对信息有用性有正向影响。在以往研究基础上, 本研究融入信息质量维度, 并通过主题分析挖掘文本语义和主题热度, 研究结果更加客观准确, 是对开放式创新社区信息有用性识别研究的有效补充。基于以上结论, 笔者对开放式创新社区的运营管理提出如下建议。
(1) 重视热度不高的反馈主题, 便于挖掘潜在创意信息。本研究发现并非热度高的话题其信息价值越高。比如在主题识别结果中, 热度不高的Topic191反馈的是手机APP下载安装问题, 但是它的收录比例为20%(6/30), 远高于社区中第一热点话题Topic16的收录比例0.6%(3/512)。热度高的主题相对缺乏新颖性, 因此社区管理者应多关注用户反馈的“小众”主题信息, 从中发现更具价值的创意。
(2) 重视社区优质用户反馈, 实现对用户的重点管理。历史主动贡献度高的用户是社区活跃的优质用户, 他们不只浏览信息, 还能够主动在社区中发现信息、贡献信息、交流信息。因此, 该类用户是开放式创新社区中宝贵的创新资源, 管理者应该加以重视和 维护。
(3) 建立社区内部评分排序系统, 实现对信息价值的评估。社区后台应根据信息及时性、完整性、语义性、用户主动贡献程度几个指标建立对反馈信息评分的排序系统, 实现对信息价值的准确评估, 提高识别效率。
本研究也存在一些局限性, 样本选取较少, 缺少对机型、版本号等调节变量的分析。在后续研究中, 将进一步扩展研究对象和研究变量的范围, 探究开放式创新社区中不同板块信息有用性的差异。
李贺: 提出研究思路, 审阅、修改论文, 论文最终版本修订;
祝琳琳: 设计研究方案, 实现模型代码, 撰写论文;
闫敏: 清理数据;
刘金承: 采集数据;
洪闯: 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: zhulinlinjlu@163.com。
[1] 祝琳琳. miuiData.csv. 社区爬取的全部数据.
[2] 祝琳琳. topicModel.ipynb. 分词、去停用词、主题计算等程序.
[3] 祝琳琳. variableData.xls. 回归分析所用的变量量化数据.
| [1] |
2016年中国大企业开放式创新发展研究报告 [EB/OL]. (Research Report on Open Innovation and Development of Chinese Large Enterprises in 2016 [EB/OL]. ( |
| [2] |
|
| [3] |
Innovation Contests—Where are We? [C]// |
| [4] |
基于用户创新社区的开放式创新研究 [J].https://doi.org/10.3969/j.issn.1002-6711.2013.08.007 URL [本文引用: 2] 摘要
使用组织产品和服务的实际终端用户是开放式创新的创新源。但许多组织缺乏用于理解和采纳终端用户思想的能力,担心失去对创新过程的控制,导致许多组织很难吸收这些创新源。在已有研究基础上,构建将终端用户融入组织创新过程的集成模式:优化管理领先用户、采用有针对性的用户工具、有效嵌入人力资源、集成组织与用户创新社区。提出基于社会关系网络的领先用户扩散模式。利用对戴尔公司IdeaStorm网站的案例研究,分析基于用户创新社区的各种模式的实施与管理,提出可以进一步研究的问题。
The Research on Open Innovation Based on User Innovation Community [J].https://doi.org/10.3969/j.issn.1002-6711.2013.08.007 URL [本文引用: 2] 摘要
使用组织产品和服务的实际终端用户是开放式创新的创新源。但许多组织缺乏用于理解和采纳终端用户思想的能力,担心失去对创新过程的控制,导致许多组织很难吸收这些创新源。在已有研究基础上,构建将终端用户融入组织创新过程的集成模式:优化管理领先用户、采用有针对性的用户工具、有效嵌入人力资源、集成组织与用户创新社区。提出基于社会关系网络的领先用户扩散模式。利用对戴尔公司IdeaStorm网站的案例研究,分析基于用户创新社区的各种模式的实施与管理,提出可以进一步研究的问题。
|
| [5] |
在线用户创新社区的知识创造——研究综述与理论分析框架 [J].https://doi.org/10.13833/j.cnki.is.2017.07.028 URL [本文引用: 1] 摘要
【目的/意义】作为互联网时代的创新平台,具有典型开放式创新特征的在线用户创新社区逐渐成为企业创新知识的重要来源。揭示在线用户创新社区的知识创造机理不仅有助于揭示此类社区的知识创造规律,更具有指导类似社区提升创新能力的实践意义。【方法/过程】本文在系统梳理相关研究文献基础上,深入分析了此类社区的知识创造过程、促进知识创造过程的关键驱动因素以及一系列情境条件的影响,提出了在线用户创新社区知识创造机理的一个理论分析框架。【结果/结论】研究结果凸显了领先用户、社区互动、外部信息等驱动因素以及一系列情境条件在社区知识创造过程不同环节所发挥的独特作用,对加深此类社区知识创造机理理解提供有益参考。
Knowledge Creation of Online User Innovation Communities: A Research Review and Theoretical Analysis Framework [J].https://doi.org/10.13833/j.cnki.is.2017.07.028 URL [本文引用: 1] 摘要
【目的/意义】作为互联网时代的创新平台,具有典型开放式创新特征的在线用户创新社区逐渐成为企业创新知识的重要来源。揭示在线用户创新社区的知识创造机理不仅有助于揭示此类社区的知识创造规律,更具有指导类似社区提升创新能力的实践意义。【方法/过程】本文在系统梳理相关研究文献基础上,深入分析了此类社区的知识创造过程、促进知识创造过程的关键驱动因素以及一系列情境条件的影响,提出了在线用户创新社区知识创造机理的一个理论分析框架。【结果/结论】研究结果凸显了领先用户、社区互动、外部信息等驱动因素以及一系列情境条件在社区知识创造过程不同环节所发挥的独特作用,对加深此类社区知识创造机理理解提供有益参考。
|
| [6] |
Identification of Innovation Solvers in Open Innovation Communities Using Swarm Intelligence [J].https://doi.org/10.1016/j.techfore.2016.05.007 URL [本文引用: 1] 摘要
61Identification of innovation solvers using their participation characteristics61Application of swarm intelligence to solve problems with excess zeros61Innovation solvers share some of the features of lead users.61Innovation-solvers are more involved with a reduced part of the network.
|
| [7] |
基于聚类的用户创新社区知识网络建模及分析 [J].
针对用户创新社区知识网络建模时,网络社区存在的海量信息内容特征的多样性,采用传统的方法在进行挖掘时,由于信息内容可挖掘特征存在的关联性低,使得最优信息内容特征的挖掘不准确,选出大量的无关信息内容特征,导致建模精确度低.提出基于加权聚类网络的企业社区用户创新知识发现、建模及分析方法.在Web内容挖掘基础上,对高频特征词进行聚类,并根据内容进行标记并命名,与高频词合并形成创新知识点集,考虑词频以及知识点间隶属关系,构建用户创新知识的加权网络模型,并对用户创新知识深入分析.分析结果可以用加权的层次网络表示出来.实验结果证明,采用上述建模精确度高,并为企业发现和分析用户创新知识提供更有效的工具.
Modeling and Analysis of Users’ Knowledge Network in Innovative Community Based on Clustering [J].
针对用户创新社区知识网络建模时,网络社区存在的海量信息内容特征的多样性,采用传统的方法在进行挖掘时,由于信息内容可挖掘特征存在的关联性低,使得最优信息内容特征的挖掘不准确,选出大量的无关信息内容特征,导致建模精确度低.提出基于加权聚类网络的企业社区用户创新知识发现、建模及分析方法.在Web内容挖掘基础上,对高频特征词进行聚类,并根据内容进行标记并命名,与高频词合并形成创新知识点集,考虑词频以及知识点间隶属关系,构建用户创新知识的加权网络模型,并对用户创新知识深入分析.分析结果可以用加权的层次网络表示出来.实验结果证明,采用上述建模精确度高,并为企业发现和分析用户创新知识提供更有效的工具.
|
| [8] |
企业开放式创新社区在线用户贡献度研究 [J].https://doi.org/10.6049/kjjbydc.2016010256 URL [本文引用: 1] 摘要
企业开放式创新社区是一种基于Internet的虚拟创新平台,能为企业创新提供丰富的用户生成内容UGC。为了帮助企业有效管理社区用户及其UGC,首先基于开放式创新理论,以星巴克的开放式创新社区为例,通过4个用户行为衡量指标(Ideas_submitted、Ideas_points、Comments_submitted和Comments_received)对用户样本进行聚类分析。然后,从用户对企业创新的贡献度和对社区互动的贡献度两个维度分析具有不同行为特征的在线用户对企业的贡献,进而得出6种不同类型的用户角色,以期在丰富理论研究的同时指导企业开放式创新社区的用户管理实践。
Research on the Contribution Degrees of Online Users in the Open Innovation Communities for Enterprises [J].https://doi.org/10.6049/kjjbydc.2016010256 URL [本文引用: 1] 摘要
企业开放式创新社区是一种基于Internet的虚拟创新平台,能为企业创新提供丰富的用户生成内容UGC。为了帮助企业有效管理社区用户及其UGC,首先基于开放式创新理论,以星巴克的开放式创新社区为例,通过4个用户行为衡量指标(Ideas_submitted、Ideas_points、Comments_submitted和Comments_received)对用户样本进行聚类分析。然后,从用户对企业创新的贡献度和对社区互动的贡献度两个维度分析具有不同行为特征的在线用户对企业的贡献,进而得出6种不同类型的用户角色,以期在丰富理论研究的同时指导企业开放式创新社区的用户管理实践。
|
| [9] |
Getting Customers’ Ideas to Work for You: Learning from Dell How to Succeed with Online User Innovation Communities [J]. |
| [10] |
创新价值链视角下企业开放式创新社区管理的系统动力学研究 [J].https://doi.org/10.14134/j.cnki.cn33-1336/f.2017.06.006 URL [本文引用: 1] 摘要
在互联网思维、企业转型、平台战略的推动下,越来越多企业将开放式创新社区作为其创新过程中的重要节点,通过开放式创新社区从外部用户寻找、识别、获取和利用各种创新资源,促进企业内部创新绩效的提升。文章基于创新价值链视角,将企业开放式创新社区的管理过程分为创意产生、创意转化和创意扩散三个重要环节,以资源基础观和动态能力观为理论基础,构建企业开放式创新社区的系统动力学模型。通过仿真模拟发现,用户个性化需求、用户奖励水平、用户生成内容以及企业动态能力是开放式创新社区成功运营的关键影响因素。文章旨在为企业能够对开放式创新社区实施有效管理提供新的思路。
System Dynamic Analysis on Managing the Open Innovation Communities for Enterprises from the View of Innovation Value Chain [J].https://doi.org/10.14134/j.cnki.cn33-1336/f.2017.06.006 URL [本文引用: 1] 摘要
在互联网思维、企业转型、平台战略的推动下,越来越多企业将开放式创新社区作为其创新过程中的重要节点,通过开放式创新社区从外部用户寻找、识别、获取和利用各种创新资源,促进企业内部创新绩效的提升。文章基于创新价值链视角,将企业开放式创新社区的管理过程分为创意产生、创意转化和创意扩散三个重要环节,以资源基础观和动态能力观为理论基础,构建企业开放式创新社区的系统动力学模型。通过仿真模拟发现,用户个性化需求、用户奖励水平、用户生成内容以及企业动态能力是开放式创新社区成功运营的关键影响因素。文章旨在为企业能够对开放式创新社区实施有效管理提供新的思路。
|
| [11] |
Communication and Persuasion: Central and Peripheral Routes to Attitude Change[A]// Schlüsselwerke der Medienwirkungsforschung [M]. |
| [12] |
Informational Influence in Organizations: An Integrated Approach to Knowledge Adoption [J].https://doi.org/10.1287/isre.14.1.47.14767 URL [本文引用: 2] 摘要
This research investigates how knowledge workers are influenced to adopt the advice that they receive in mediated contexts. The research integrates the Technology Acceptance Model (Davis 1989) with dual-process models of information influence (e.g., Petty and Cacioppo 1986, Chaiken and Eagly 1976) to build a theoretical model of information adoption. This model highlights the assessment of information usefulness as a mediator of the information adoption process. Importantly, the model draws on the dual-process models to make predictions about the antecedents of information usefulness under different processing conditions. The model is investigated qualitatively first, using interviews of a sample of 40 consultants, and then quantitatively on another sample of 63 consultants from the same international consulting organization. Data reflect participants' perceptions of actual e-mails they received from colleagues consisting of advice or recommendations. Results support the model, suggesting that the process models used to understand information adoption can be generalized to the field of knowledge management, and that usefulness serves a mediating role between influence processes and information adoption. Organizational knowledge work is becoming increasingly global. This research offers a model for understanding knowledge transfer using computer-mediated communication.
|
| [13] |
Influence of Social Media on Chinese Students’ Choice of an Overseas Study Destination: An Information Adoption Model Perspective [J].https://doi.org/10.1080/10548408.2014.873318 URL [本文引用: 1] 摘要
This study is an experimental investigation of the influence of social media on choosing an overseas study destination. The elaboration likelihood model of communication and persuasion provides a conceptual basis for this study. Data was collected through convenience sampling of Chinese students from three Brisbane tertiary institutions. Participants were provided with one of the four treatments with manipulated stimuli. Results suggest that social media content is an influential factor in determining destination attractiveness, and may, if correctly specified, facilitate high elaboration and generate corresponding positive or negative impressions of the study destination from students.
|
| [14] |
The Influence of eWOM in Social Media on Consumers’ Purchase Intentions: An Extended Approach to Information Adoption [J].https://doi.org/10.1016/j.chb.2016.03.003 URL [本文引用: 1] 摘要
61We examine the influence of eWOM in social media on consumers' purchase intentions.61We develop a new conceptual model through extending the IAM by considering the TRA.61We validate our model, which is Information Acceptance Model (IACM), through SEM.61We show the determinants of eWOM in social media that influence purchase intention.
|
| [15] |
The Impact of Electronic Word-of-Mouth [J].https://doi.org/10.1108/10662240810883290 URL [本文引用: 1] |
| [16] |
Investigating Information Adoption Tendencies Based on Restaurants’ User-Generated Content Utilizing a Modified Information Adoption Model [J].https://doi.org/10.1080/19368623.2016.1171190 URL [本文引用: 1] 摘要
AbstractSocial media has boosted information sharing and user-generated content. Consequently, many restaurant goers rely on online reviews for dining recommendations. This study adds to the sparse literature on the influence of review extremeness, source credibility, website quality, and information usefulness on information adoption. Most notably, a modified information adoption model with the addition of website quality was tested in the context of restaurant review websites. Respondents answered survey questions based on what they saw in a simulated restaurant review website which depicted one of eight scenarios. Results showed that the more negative a review, the more useful it is perceived to be. Perceived source credibility of the review writer was positively related to the perceived information usefulness. The only component of website quality that played a significant role in determining information adoption tendency of the review readers was the quality of the information disseminated in the web...
|
| [17] |
A Theoretical Integration of User Satisfaction and Technology Acceptance [J].https://doi.org/10.1287/isre.1050.0042 URL [本文引用: 1] 摘要
In general, perceptions of information systems (IS) success have been investigated within two primary research streams-the user satisfaction literature and the technology acceptance literature. These two approaches have been developed in parallel and have not been reconciled or integrated. This paper develops an integrated research model that distinguishes beliefs and attitudes about the system (i.e., object-based beliefs and attitudes) from beliefs and attitudes about using the system (i.e., behavioral beliefs and attitudes) to build the theoretical logic that links the user satisfaction and technology acceptance literature. The model is then tested using a sample of 465 users from seven different organizations who completed a survey regarding their use of data warehousing software. The proposed model was supported, providing preliminary evidence that the two perspectives can and should be integrated. The integrated model helps build the bridge from design and implementation decisions to system characteristics (a core strength of the user satisfaction literature) to the prediction of usage (a core strength of the technology acceptance literature).
|
| [18] |
Beyond Accuracy: What Data Quality Means to Data Consumers [J].https://doi.org/10.1080/07421222.1996.11518099 URL [本文引用: 1] 摘要
Poor data quality (DQ) can have substantial social and economic impacts. Although firms are improving data quality with practical approaches and tools, their improvement efforts tend to focus narrowly on accuracy. We believe that data consumers have a much broader data quality conceptualization than IS professionals realize. The purpose of this paper is to develop a framework that captures the aspects of data quality that are important to data consumers. A two-stage survey and a two-phase sorting study were conducted to develop a hierarchical framework for organizing data quality dimensions. This framework captures dimensions of data quality that are important to data consumers. Intrinsic DQ denotes that data have quality in their own right. Contextual DQ highlights the requirement that data quality must be considered within the context of the task at hand. Representational DQ and accessibility DQ emphasize the importance of the role of systems. These findings are consistent with our understanding that high-quality data should be intrinsically good, contextually appropriate for the task, clearly represented, and accessible to the data consumer. Our framework has been used effectively in industry and government. Using this framework, IS managers were able to better understand and meet their data consumers' data quality needs. The salient feature of this research study is that quality attributes of data are collected from data consumers instead of being defined theoretically or based on researchers' experience. Although exploratory, this research provides a basis for future studies that measure data quality along the dimensions of this framework.
|
| [19] |
Toward Quality Data: An Attribute-based Approach [J].https://doi.org/10.1016/0167-9236(93)E0050-N URL [本文引用: 1] 摘要
ABSTRACT "November 1992."
|
| [20] |
A Comparative Analysis of Major Online Review Platforms: Implications for Social Media Analytics in Hospitality and Tourism [J].https://doi.org/10.1016/j.tourman.2016.10.001 URL [本文引用: 1] 摘要
61We applied text analytics to compare three major online review platforms, namely, TripAdvisor, Expedia, and Yelp.61Findings show discrepancies in the representation of hotel product on these platforms.61Information quality, measured by linguistic and semantic features, sentiment, rating, and usefulness, varies considerably.61This study is the first to comparatively explore data quality in social media studies in hospitality and tourism.61This study highlights methodological challenges and contributes to the theoretical development of social media analytics.
|
| [21] |
什么样的评论更容易获得有用性投票——以亚马逊网站研究为例 [J].
【目的】购物网站评论系统中的投票机制有利于帮助消费者筛选出高质量评论。本文以评论有用性投票数为研究对象,探讨什么样的评论更容易获得有用性投票。【方法】以信息采纳理论和负面偏差理论为基础,基于亚马逊购物网站中的12 393条手机评论数据,结合文本分析与零膨胀负二项回归分析方法,从评论者信度、评论信息质量、评论极性三个方面探究评论有用性投票影响因素。【结果】研究结果表明,评论者有用性、评论信息量、评论回复数、极端评分、评论文本消极倾向对评论有用性投票数具有积极正向影响。评论者发表评论数、评论者是否确认购买对评论有用性投票数有负向影响。【局限】仅以手机这一搜索型产品为研究对象,研究结果欠缺普适性。【结论】本文研究成果对于改善电子商务评论排序系统具有借鉴意义。
Identifying Reviews with More Positive Votes——Case Study of Amazon.cn [J].
【目的】购物网站评论系统中的投票机制有利于帮助消费者筛选出高质量评论。本文以评论有用性投票数为研究对象,探讨什么样的评论更容易获得有用性投票。【方法】以信息采纳理论和负面偏差理论为基础,基于亚马逊购物网站中的12 393条手机评论数据,结合文本分析与零膨胀负二项回归分析方法,从评论者信度、评论信息质量、评论极性三个方面探究评论有用性投票影响因素。【结果】研究结果表明,评论者有用性、评论信息量、评论回复数、极端评分、评论文本消极倾向对评论有用性投票数具有积极正向影响。评论者发表评论数、评论者是否确认购买对评论有用性投票数有负向影响。【局限】仅以手机这一搜索型产品为研究对象,研究结果欠缺普适性。【结论】本文研究成果对于改善电子商务评论排序系统具有借鉴意义。
|
| [22] |
Examining Customer Focus in IT Project Management: Findings from Irish and Norwegian Case Studies [J]. |
| [23] |
Online Travel Review Study: Role&Impact of Online Travel Reviews[R] . |
| [24] |
From Amateurs to Connoisseurs: Modeling the Evolution of User Expertise Through Online Reviews [C]// |
| [25] |
基于用户特征抽取和随机森林分类的用户创新社区领先用户识别研究 [J].
【】为了发挥用户创新社区及领先用户在企业开放式创新中的作用, 对用户创新社区情境下的领先用户识别方法进行研究。【】结合领先用户特征, 利用用户创新社区中的用户数据, 从用户内容信息和行为数据两方面抽取用户特征, 并在此基础上提出基于随机森林分类的领先用户识别方法。并以小米社区的MIUI论坛为例进行实例分析。【】实验结果表明, 本文提出的识别方法在领先用户和非领先用户之间具有较好的区分度。【】不同产品领域用户创新社区的用户生成内容和行为数据有一定差异, 本文仅以讨论小米手机操作系统的MIUI论坛为例, 涉及其他产品领域用户创新社区时, 用户特征抽取和相应的训练模型可能需要依具体情况适当调整。【】本文方法是一种适合用户创新社区情境的领先用户识别方法, 可以和传统方法有机结合, 以进一步提高此类社区领先用户识别的效率和效力。
Identifying Lead Players of User Innovation Communities Based on Feature Extraction and Random Forest Classification [J].
【】为了发挥用户创新社区及领先用户在企业开放式创新中的作用, 对用户创新社区情境下的领先用户识别方法进行研究。【】结合领先用户特征, 利用用户创新社区中的用户数据, 从用户内容信息和行为数据两方面抽取用户特征, 并在此基础上提出基于随机森林分类的领先用户识别方法。并以小米社区的MIUI论坛为例进行实例分析。【】实验结果表明, 本文提出的识别方法在领先用户和非领先用户之间具有较好的区分度。【】不同产品领域用户创新社区的用户生成内容和行为数据有一定差异, 本文仅以讨论小米手机操作系统的MIUI论坛为例, 涉及其他产品领域用户创新社区时, 用户特征抽取和相应的训练模型可能需要依具体情况适当调整。【】本文方法是一种适合用户创新社区情境的领先用户识别方法, 可以和传统方法有机结合, 以进一步提高此类社区领先用户识别的效率和效力。
|
| [26] |
Lead Users: A Source of Novel Product Concepts [J].https://doi.org/10.1287/mnsc.32.7.791 URL [本文引用: 1] 摘要
Accurate marketing research depends on accurate user judgments regarding their needs. However, for very novel products or in product categories characterized by rapid change-such as "high technology" products-most potential users will not have the real-world experience needed to problem solve and provide accurate data to inquiring market researchers. In this paper I explore the problem and propose a solution: Marketing research analyses which focus on what I term the "lead users" of a product or process. Lead users are users whose present strong needs will become general in a marketplace months or years in the future. Since lead users are familiar with conditions which lie in the future for most others, they can serve as a need-forecasting laboratory for marketing research. Moreover, since lead users often attempt to fill the need they experience, they can provide new product concept and design data as well. In this paper I explore how lead users can be systematically identified, and how lead user perceptions and preferences can be incorporated into industrial and consumer marketing research analyses of emerging needs for new products, processes and services.
|
| [27] |
Virtual Lead User Communities: Drivers of Knowledge Creation for Innovation [J].https://doi.org/10.1016/j.respol.2011.08.006 URL [本文引用: 1] 摘要
This study examines the creation of innovation-related knowledge in virtual communities visited mainly by lead users. Such communities enable firms to access a large number of lead users in a cost-efficient way. A propositional framework relates lead users’ characteristics to unique virtual community features to examine their potential impact on the development of valuable innovation knowledge. The authors empirically validate this framework by analyzing online contributions of lead users for mobile service innovation projects. The findings indicate that the value of their contributions stems from their ability to suggest solutions instead of simply describing problems or stating customer needs. Lead users’ technical expertise also makes them particularly well-suited to develop new functionalities, but less so for design and usability improvements. The digital context favors the creation of explicit knowledge that can be easily integrated into the development of new products. Finally, contributions given by lead users in a proactive way contain more novel insights than reactive contributions such as answers to community members’ questions. The findings should help managers stimulate, identify, and improve the use of lead users’ input in virtual communities.
|
| [28] |
基于LDA模型的移动投诉文本热点话题识别 [J].
【目的】运用中文信息处理和话题识别与追踪的方法,从大量移动投诉文本中找出有价值的信息。【方法】从分析投诉文本的特点入手,使用k-means先对文本聚类。利用LDA对每个类进行建模,提取话题,并从词频、词跨度和词长三方面计算每个话题中词的权值,把权重最大的词作为该话题的标签,并计算每个话题的文档分布概率均值。对具有相同标签的话题,先按照均值最大的原则去掉重复标签话题,再对所有话题计算文档支持率,并将文档支持率作为话题的热度,通过热度区分热点话题和一般话题。【结果】对投诉文本进行时间上的建模,通过对比一般话题和热点话题,得出热点话题的支持文档率至少是一般话题的3倍,支持文档率变化趋势也比一般话题高,说明本文算法是有效的。【局限】没有考虑到话题之间的语义关系。【结论】利用LDA模型对移动投诉话题检测初探的方法是比较合理和有效的,对今后此领域的研究具有一定的借鉴意义。
Identifying Hot Topics from Mobile Complaint Texts [J].
【目的】运用中文信息处理和话题识别与追踪的方法,从大量移动投诉文本中找出有价值的信息。【方法】从分析投诉文本的特点入手,使用k-means先对文本聚类。利用LDA对每个类进行建模,提取话题,并从词频、词跨度和词长三方面计算每个话题中词的权值,把权重最大的词作为该话题的标签,并计算每个话题的文档分布概率均值。对具有相同标签的话题,先按照均值最大的原则去掉重复标签话题,再对所有话题计算文档支持率,并将文档支持率作为话题的热度,通过热度区分热点话题和一般话题。【结果】对投诉文本进行时间上的建模,通过对比一般话题和热点话题,得出热点话题的支持文档率至少是一般话题的3倍,支持文档率变化趋势也比一般话题高,说明本文算法是有效的。【局限】没有考虑到话题之间的语义关系。【结论】利用LDA模型对移动投诉话题检测初探的方法是比较合理和有效的,对今后此领域的研究具有一定的借鉴意义。
|
| [29] |
Dynamic Topic Models [C]// |
| [30] |
基于LDA模型和微博热度的热点挖掘 [J].https://doi.org/10.13266/j.issn.0252-3116.2014.05.010 URL [本文引用: 2] 摘要
分析传统LDA模型在进行微博热点挖掘时所得概率结果抽象且难以结合实际解释的缺点;考虑到微博本身的数据特点和信息论中信息量的观点,提出微博热度的概念,并将其引入到LDA模型的热点挖掘研究中,构建基于微博热度的LDA模型;通过API采集微博数据上的实验,证明新方法与旧方法具有相同的性能,而且能得到更直观的微博热度表,并得出更具有说服力的挖掘结论。
Hotspot Mining Based on LDA Model and Microblog Heat [J].https://doi.org/10.13266/j.issn.0252-3116.2014.05.010 URL [本文引用: 2] 摘要
分析传统LDA模型在进行微博热点挖掘时所得概率结果抽象且难以结合实际解释的缺点;考虑到微博本身的数据特点和信息论中信息量的观点,提出微博热度的概念,并将其引入到LDA模型的热点挖掘研究中,构建基于微博热度的LDA模型;通过API采集微博数据上的实验,证明新方法与旧方法具有相同的性能,而且能得到更直观的微博热度表,并得出更具有说服力的挖掘结论。
|
| [31] |
网络健康社区中的主题特征研究 [J].https://doi.org/10.13266/j.issn.0252-3116.2015.012.015 URL [本文引用: 1] 摘要
[目的/意义]探究不同类型网络社区中健康主题特征分布,促使各网站平台能够更好地提供在线健康信息服务。[方法/过程]以糖尿病为例,选取来自健康论坛的社会化标签和社会化问答社区的问答记录作为研究对象;通过数据编码和文本处理的方法,得到八大类主题,并比较两种网络社区中该八大主题分布情况的异同。[结果/结论]两种网络社区中糖尿病主题冷热分布大体趋于一致。在最为用户所关注的主题上,两类社区各有侧重,分别是"诊断和检查"、"社会生活"。以上探讨和发现对在线健康信息服务质量的提升有诸多启示。
Research on Theme Features in Online Health Community [J].https://doi.org/10.13266/j.issn.0252-3116.2015.012.015 URL [本文引用: 1] 摘要
[目的/意义]探究不同类型网络社区中健康主题特征分布,促使各网站平台能够更好地提供在线健康信息服务。[方法/过程]以糖尿病为例,选取来自健康论坛的社会化标签和社会化问答社区的问答记录作为研究对象;通过数据编码和文本处理的方法,得到八大类主题,并比较两种网络社区中该八大主题分布情况的异同。[结果/结论]两种网络社区中糖尿病主题冷热分布大体趋于一致。在最为用户所关注的主题上,两类社区各有侧重,分别是"诊断和检查"、"社会生活"。以上探讨和发现对在线健康信息服务质量的提升有诸多启示。
|
| [32] |
基于LDA模型的论坛热点话题识别和追踪 [J].
语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型。该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的。实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行。<br>
LDA Based Hot Topic Detection and Tracking for the Forum [J].
语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型。该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的。实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行。<br>
|
| [33] |
基于LDA的国内电子政务研究主题演化及可视化分析 [J].https://doi.org/10.3969/j.issn.1008-0821.2017.04.025 URL [本文引用: 1] 摘要
为了更好地了解国内电子政务研究发展阶段,推动电子政务学科发展,本文提出将主题模型应用在电子政务研究主题演化分析中.电子政务主题演化能够挖掘出电子政务研究热点,在电子政务学科建设方面具有一定的理论和实践意义.本研究收集了中国知网中1999-2016年以电子政务为主题的实验数据,采用LDA模型抽样得到每年的文档主题,将采样的主题通过社会网络等方法进行可视化分析.根据主题演化分析结果,本文将国内电子政务研究划分为3个阶段:起步阶段、快速发展阶段、平稳发展阶段,本文还分析了目前国内电子政务研究的热点,展望了国内电子政务研究趋势.
Theme Evolvement and Visual Analysis of Domestic E-government Research Based on LDA [J].https://doi.org/10.3969/j.issn.1008-0821.2017.04.025 URL [本文引用: 1] 摘要
为了更好地了解国内电子政务研究发展阶段,推动电子政务学科发展,本文提出将主题模型应用在电子政务研究主题演化分析中.电子政务主题演化能够挖掘出电子政务研究热点,在电子政务学科建设方面具有一定的理论和实践意义.本研究收集了中国知网中1999-2016年以电子政务为主题的实验数据,采用LDA模型抽样得到每年的文档主题,将采样的主题通过社会网络等方法进行可视化分析.根据主题演化分析结果,本文将国内电子政务研究划分为3个阶段:起步阶段、快速发展阶段、平稳发展阶段,本文还分析了目前国内电子政务研究的热点,展望了国内电子政务研究趋势.
|
| [34] |
Latent Dirichlet Allocation [J]. |
| [35] |
一种基于LDA主题模型的评论文本情感分类方法 [J].https://doi.org/10.16337/j.1004-9037.2017.03.023 URL [本文引用: 2] 摘要
针对互联网出现的评论文本情感分析,引入潜在狄利克雷分布(Latent Dirichlet allocation,LDA)模型,提出一种分类方法。该分类方法结合情感词典,依据指定的情感单元搭配模式,提取情感信息,包括情感词和上、下文。使用主题模型发掘情感信息中的关键特征,并融入到情感向量空间中。最后利用机器学习分类算法,实现中文评论文本的情感分类。实验结果表明,提出的方法有效降低了特征向量的维度,并且在文本情感分类上有很好的效果。
Method of Sentiment Analysis for Comment Texts Based on LDA [J].https://doi.org/10.16337/j.1004-9037.2017.03.023 URL [本文引用: 2] 摘要
针对互联网出现的评论文本情感分析,引入潜在狄利克雷分布(Latent Dirichlet allocation,LDA)模型,提出一种分类方法。该分类方法结合情感词典,依据指定的情感单元搭配模式,提取情感信息,包括情感词和上、下文。使用主题模型发掘情感信息中的关键特征,并融入到情感向量空间中。最后利用机器学习分类算法,实现中文评论文本的情感分类。实验结果表明,提出的方法有效降低了特征向量的维度,并且在文本情感分类上有很好的效果。
|
| [36] |
LDA-based Document Models for Ad-Hoc Retrieval [C]// |
| [37] |
A Density-based Method for Adaptive LDA Model Selection [J].https://doi.org/10.1016/j.neucom.2008.06.011 URL [本文引用: 1] 摘要
Topic models have been successfully used in information classification and retrieval. These models can capture word correlations in a collection of textual documents with a low-dimensional set of multinomial distribution, called “topics”. However, it is important but difficult to select the appropriate number of topics for a specific dataset. In this paper, we study the inherent connection between the best topic structure and the distances among topics in Latent Dirichlet allocation (LDA), and propose a method of adaptively selecting the best LDA model based on density. Experiments show that the proposed method can achieve performance matching the best of LDA without manually tuning the number of topics.
|
| [38] |
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}