1 引 言
随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] 。科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的。在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献。在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] 。针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境。形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势。近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域。
本文在形式概念分析理论的基础上, 提出一种融合浏览和搜索的交互式知识地图建构方法, 挖掘并揭示学术资源中隐含的知识结构, 帮助用户认知信息空间, 快速聚焦核心知识节点、提高搜索效率。具体来说, 主要研究以下两个问题: 如何挖掘文献集中隐含的知识概念及其关联以实现基于语义的文献资源组织?如何构建并展示基于查询式的可交互知识地图以帮助用户快速定位所需资源?
2 学术资源中的知识概念
学术文献的集合, 不仅是外在物理层次的文献单元的集合, 更是内在认知层次的知识概念以及概念之间关系的集合。情报学的重要任务之一就是组织知识(而不仅仅是文献)以便人们更有效地利用知识。早在1975年情报学家Brookes[14 ] 就提出知识地图的概念, 他认为在文献知识中找出它们的交集和相互制约因素可以追寻到人对思想和知识的需求, 同时指出可以把各个知识单元概念作为节点, 通过学科认知地图简洁明了地标示出人类的知识结构。
目前图书情报领域对“知识单元概念”的研究理论有一些探讨。部分学者认为知识单元是文献单元中的知识内容单元[15 ] 。一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] 。从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] 。以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念。因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念。正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念。比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性。这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部。属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存。内涵是对一切外延特征的概括, 外延是内涵表述的具体化。在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合。这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义。可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大。比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延。另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的。
3 基于形式概念分析的学术文献隐含概念挖掘及关系识别
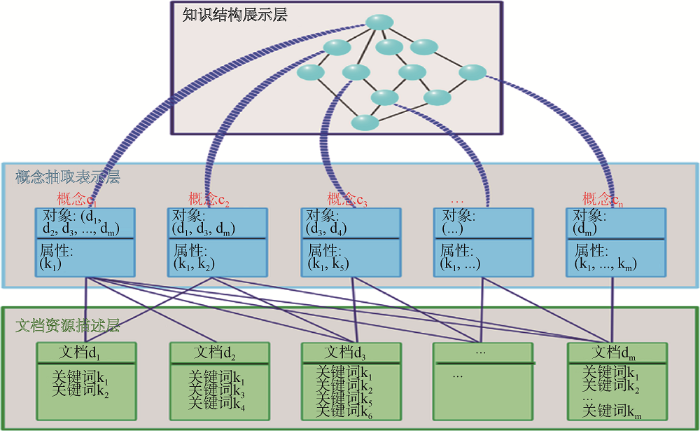
基于“概念是由外延和内涵组成的思想单元”, Wille[23 ] 提出形式概念分析理论, 通过挖掘对象和属性间的二元关系建立概念层次结构, 是知识发现的重要方法。本文使用形式概念分析方法对文档空间进行建模, 挖掘文档空间中的隐含概念并且识别概念之间的关系, 具体建模过程如图1 所示。
第一层是文档资源描述层, 构建形式背景表达和记录文档(对象)与关键词(属性)之间的二元关系; 第二层是概念抽取表示层, 凭借形式背景中对象与属性的二元关系提取所有隐含概念; 第三层是知识结构展示层, 识别概念间的层次关系并对概念及其关系进行图形化展示。
3.1 文档空间中形式背景的构建
概念是从文档空间中提取出来, 依赖于一定的背景知识而存在的。使用FCA挖掘隐含概念的关键, 在于把文档空间中对象、属性以及它们之间的关联关系映射到形式化的背景中去, 即生成形式背景。形式背景是对象、属性及其间关系的描述。本文将文档空间中的文献看作形式概念分析中的对象, 将其特征词看作形式概念分析中的属性, 基于文档和特征词之间的关系, 构建形式背景, 给出文档空间中形式背景的定义如下。
定义1: 文档空间的形式背景是一个三元组S=(D,K,R), 其中D={d1,d2,···,dn}为文献集合(对象集), K={k1,k2,···,km}为特征词集合(属性集), R为D与K之间的二元关系, 即R⊆D×K。若(d,k)∈R, 则表示文档d(对象)具有特征词k(属性)。
在形式背景中, 对象是文档, 有多少篇文档就有多少个对象。属性是文档的特征词, 但不是所有词汇都能作为属性。属性词汇选择标准如下:
(1) 表达文档主题, 即对于单篇文章是重要的词汇;
(2) 在文献集合中有一定代表性, 即满足条件(1), 但在文献集合中出现频率非常低的词汇也不能作为 属性。
综合来说, 属性词汇既能反映单篇文章的特性又能一定程度上反映文献集合的特性。假设由11篇文档(d1-d11)组成文献集合, 最后选取6个代表文献集合内容的属性特征词(k1-k6), 这11篇文档和6个属性词构成的形式背景如表1 所示。
其中, 每一行代表一个对象(文档), 每一列代表一个属性(特征词), 如果文献di包含特征词kj, 用X表示; 如果di不包含kj, 则用空格表示。
3.2 隐含概念的挖掘
概念挖掘是文档语义组织的基础, 从文档空间的形式背景中识别出每一个隐含的概念是探索文档空间的核心问题。结合形式概念分析方法, 本文给出文档空间中隐含概念的定义如下。
定义2: 在形式背景(D,K,R)中, 一个序偶(A,B)表示一个形式概念(简称概念)。当且仅当A⊆D, B⊆K, 且满足Aʹ=B, Bʹ=A时, 称A为概念(A, B)的外延, B为概念(A, B)的内涵。其中,
$\mathrm{{A}'}=\left\{ k\in K\text{ }\!\!|\!\!\text{ }\left( d,k \right)\in \mathrm{R},\forall \mathrm{d}\in \mathrm{A} \right\}$
${B}'=\left\{ \mathrm{d}\in \mathrm{D}\text{ }\!\!|\!\!\text{ }\left( \mathrm{d},\mathrm{k} \right)\in R,\forall \mathrm{k}\in \mathrm{B} \right\}$
A是这个概念的文档集合, B是A中文档所共同拥有的特征词集合。
从形式背景中提取隐含概念的具体步骤如下:
①在形式背景S=(D,K,R)中, 求文档集合D的所有子集;
②每一个子集A中文档所具有的全部特征词构成特征词集合A’(A’∈K);
③求A’中所有特征词对应的文档, 构成文档集合A’’。如果(A’’,A’)是第一次生成, 那么(A’’,A’)就是一个隐含 概念。
该过程的伪代码算法如下:
While 某种条件为真do
For某个子集A⊆ D
计算A的属性集合, 记为A’
计算A’对应的对象集合, 记为A’’
End For
if(A’,A’’)是第一次生成
Then(A’,A’’)是一个概念
End if
End while
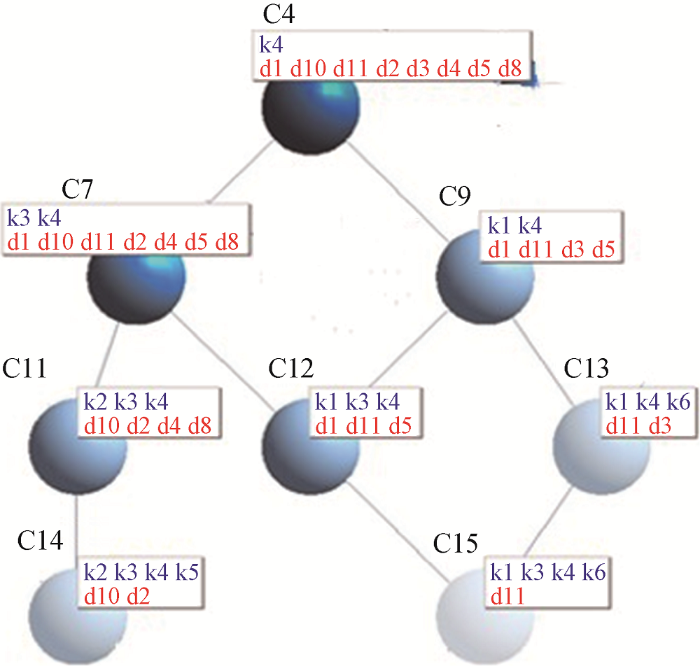
以表1 中所示的形式背景为例, 从中挖掘出16个概念如表2 所示。
3.3 概念之间关系的识别及展示
概念之间的关系是通过偏序关系识别的。偏序关系的定义如下: 对于形式背景中的两个概念(A1 , B1 ), (A2 , B2 ), 如果A1 ⊆A2 (等价于B2 ⊆B1 ), 则称(A1 , B1 )是(A2 , B2 )的子概念, (A2 , B2 )是(A1 , B1 )的父概念, 并记作(A1 , B1 )≤(A2 , B2 ), 关系≤表示概念间的偏序关系, 也叫做泛化-例化关系。若两个概念之间存在偏序关系, 它们就是父子关系; 若两个概念具有相同的父概念, 它们就是处于同一层级的兄弟概念。形式背景下所有概念连同它们之间的泛化-特化关系构成一个概念格, 描述对象及其属性和关系的一种逻辑组织结构。这种组织结构既不是树状结构也不是简单的网状结构, 而是一种具有层级的网状结构。
表1 形式背景中隐含的概念及其关系以概念格的形式展示如图2 所示。
图2 中共包含16个节点, 每个节点表示一个概念, 节点间的连线揭示了概念间的偏序关系。可以看出, 概念格将更抽象化(包含属性较少)的概念上浮作为上层节点, 较为具体(包含属性较多)的概念下移作为下层节点, 实现清晰的分层表达。最顶层的概念(C1)外延包含形式背景中的所有文档, 其内涵为空集, 表示形式背景中的11篇文献没有共同属性。第二层的4个概念(C2-C5)揭示了11篇文档的核心词汇k2、k3、k4和k1。第三层的概念内涵更为丰富, 为两个属性词汇的组合, 如C7的内涵是k3和k4, 它是二层概念C3和C4的子概念, 所以在图中呈现网状结构。类似的概念节点还有C8和C9。第4层表示更为细粒度的概念, 内涵分别为三个属性词的集合; 而第5层显示拥有4个属性词集合作为内涵的概念, C14和C15。最底层概念C16的内涵为形式背景中所有特征词的集合, 其外延为空集, 表明没有一篇文献包含形式背景中所有的特征词。在概念格中, 下层概念节点的内涵继承了其上层节点的所有内涵, 上层概念的外延包含了下层概念的所有外延。概念格能够将文档集合隐含的概念及其层次关系清晰地展现出来, 方便用户认知。
4 基于查询的交互式知识地图建构
由于信息空间的语义复杂性, 展示整个信息空间的概念格会产生概念数目众多、概念层次复杂等问题, 不利于用户对信息空间的认知。为了给用户提供更加友好直观的界面, 需要根据用户的查询输入推送局部知识地图。在局部知识地图中以用户输入的检索式为中心, 展示与之关联的概念节点, 方便用户以查询式为核心浏览和探索文档集合。具体来说, 构建交互式知识地图的第一步是构建基于查询式的局部知识地图, 第二步是优化局部知识地图。
在构建局部知识地图时, 首先生成基于用户查询式的相关概念集合Cqr。将查询式q与概念格中每一个概念节点Ci(Ai, Bi)的内涵相匹配, 若查询式的词被包括在一个概念的内涵中, 即q∈Bi, 且Ai不为空集, 则该概念被选中为相关概念。反之, 若查询式的词不在某概念的内涵中, 即q$\notin $Bi, 则该概念被剔除出去。以此得到与查询式相关的所有概念集合Cqr。最终只有概念集合Cqr中的概念及它们之间的偏序关系被保留并展现给用户, 其他概念及关联则被隐藏。例如当用户提交查询式k4时, 与k4相关的概念有8个, 分别是C4、C7、C9、C11、C12、C13、C14、C15, 那么由这8个概念及其偏序关系组成的概念格就构成局部知识地图, 如图3 所示。在这个局部知识地图中用户可以点击任何一个概念如C7, 系统将重复上面的过滤过程, 挑选出包含所选概念C7内涵的所有概念, 概念C7及其子概念C11、C12、C14、C15将作为新的局部知识地图反馈给用户, 如图4 所示。
为满足用户个性化的需求, 反馈给用户的局部知识地图能够根据用户设定的广度和深度进行调整, 若用户设定广度为w , 深度为l , 系统会将与选定概念相似度最接近的w 个概念作为第一层子概念, 并删除层次大于l+ 1的所有子节点。两个概念$\text{Ci}(\text{Ai},\text{Bi})和\text{Cj}(\text{Aj},\text{Bj})$.之间的相似度综合考虑概念的属性相似度和对象相似度两部分, 采用Jaccard系数计算如公式(1)所示。
$\text{sim(Ci},\text{Cj)}={{w}_{1}}\times \frac{\left| \text{Bi}\cap \text{Bj} \right|}{\left| \text{Bi}\cup \text{Bj} \right|}+{{w}_{2}}\times \frac{\left| \text{Ai}\cap \text{Aj} \right|}{\left| \text{Ai}\cup \text{Aj} \right|}$ (1)
其中, w 1 , w 2 分别是属性和对象的权重, 满足w 1 + w 2 =1。根据概念格的对偶原理[24 ] , 概念的对象和属性地位等同, 所以本文取w 1 =w 2 =0.5。根据公式(1)能够计算出概念节点之间的相似度, 在满足用户设定阈值的情况下, 本文尽可能地筛选出概念相似度大的节点对知识地图进行优化, 以期在有限的知识地图中展示出和用户密切相关的知识单元, 提高信息搜寻效率。
5 面向学术搜索的交互式知识地图的应用
国际会议论文具有新颖性和前沿性, 大多涉及热点问题, 是重要的学术文献来源。因此以信息检索顶级会议ACM SIGIR中的论文作为研究实例, 验证本文提出方法的有效性和实用性。
5.1 数据预处理
选取SIGIR国际会议在2006年-2016年间收录的693篇论文为研究对象, 获取每篇论文的题目、摘要、关键词和全文, 利用TF-IDF算法计算每篇论文的关键词向量。通常一篇论文的标引关键词不超过8个, 因此选取每篇论文权重前8的关键词作为属性词汇, 共获得1 310个不重复的关键词。对其中部分语义非常相近的词汇进行合并后, 剩余882个关键词。按照属性词汇的选择标准, 选择词频大于7的高频词作为代表性词汇(占总词频的58%), 最终得到179个高频特征词。根据693篇文档和179个关键词的对应关系生成形式背景${{\text{M}}_{693\times 179}}$, 部分形式背景如图5 所示。其中, 每一行代表一个文档, 每一列代表一个特征词。若文档包含该特征词, 则该行与该列交叉处用“×”表示, 否则为空。基于该形式背景共挖掘出1 307个概念, 这些概念连同它们之间的泛化-特化关系, 构成文档空间的概念格。
5.2 基于交互式知识地图的检索过程
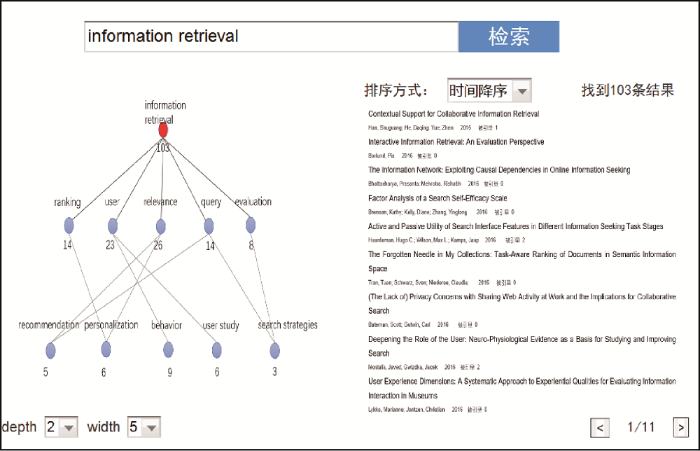
当用户输入检索词“information retrieval”时, 系统会在整个概念格中匹配与“information retrieval”相关的概念, 并根据用户设定的阈值, 深度为2, 广度为5, 生成局部知识地图如图6 所示。
其中, 圆圈表示概念节点, 顶部圆圈代表用户当前聚焦的概念。在知识地图中, 每个节点都有直接上级节点的全部属性, 因此在图上只展示概念在细化过程中增加的属性, 每个节点的全部属性可以从节点的上下位关系中推导出来。对于节点的对象, 本文用文档数量标注。顶级概念的属性包含一个特征词“information retrieval”, 它的外延包含103篇文献。第二层概念除了继承第一层概念的属性, 还拥有各自的属性特征词, 分别是relevance、user、query、ranking和evaluation这几个主题, 外延分别有26、23、14、14、8篇文献。第三层概念继承第二层概念的属性, 还拥有各自的属性特征词, 分别是behavior、personalization、user study、recommendation和search strategies, 外延分别有9、6、6、5、3篇文献, 显示了更细粒度的概念。同一层级中, 从中间向两侧按文档数量递减排列。从知识地图中, 用户可以清晰地识别出文献集合中隐含的知识概念及其关系。图6 右侧是与知识地图中用户初始目标节点相对应的检索结果, 除按时间降序外, 还可按照被引量排序。
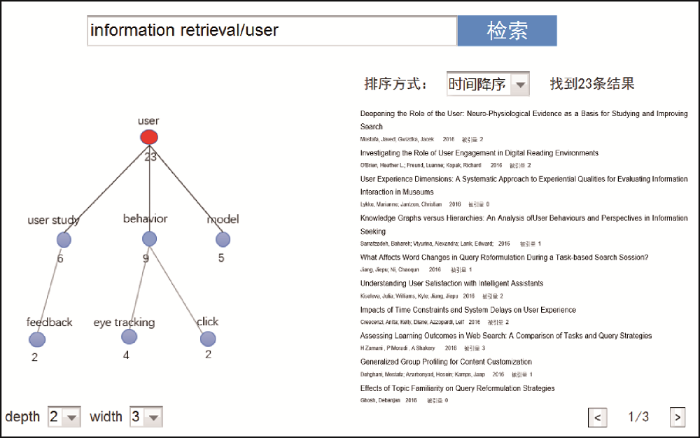
用户在浏览知识地图时可以双击地图中任意节点, 系统将显示以被点击节点为中心的知识地图。如用户双击图6 中user(因继承上层属性, 实际上是information retrieval/user)对应的节点, 就能得到以该节点为顶点(内涵是information retrieval/user, 外延为包含这两个属性词汇的23篇文档)的知识地图, 如图7 所示。
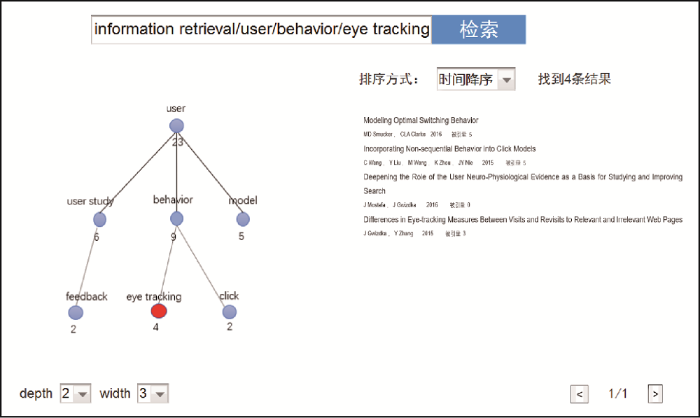
浏览图7 中的知识地图时, 可以继续点击下层的概念细化检索需求。用户如果点击information retrieval/user/behavior/eye tracking对应的节点, 由于该节点已是所在路径的最下层节点, 知识地图结构保持不变, 右侧则反馈与该节点对应的4篇文档, 如图8 所示。
上述实例展示了用户和知识地图的交互过程, 当然用户的选择并不局限于上述模式, 用户可以点击知识地图中的任意概念, 系统均能实时动态更新知识地图, 帮助用户精练检索结果文档集。
6 讨 论
形式概念分析是建立在形式化和概念层次结构上的数学分支, 由于形式概念分析与概念格理论在知识发现方面具有独特优势, 许多学者将形式概念分析应用于信息检索领域。相比于本体自上而下的知识组织方式, FCA提供一种自下而上的知识挖掘和组织方法, 具有灵活、动态和客观的优势。FCA通过对概念的全新定义, 实现了文档与文档、词汇与词汇的双层次聚类, 并且通过概念格节点的泛化关系与特化关系将这种双层聚类展现出来。
形式概念分析已被应用在信息检索的浏览、导航、查询式重构和聚焦搜索等方面。Poelmans等[25 ] 通过FCA探测警察局报告中的非结构化数据, 帮助工作人员探索和定义调查范围内的隐含概念。SearchSleuth系统[26 ] 使用概念格分析搜索概念, 识别出搜索概念的上级、下级和同级节点, 帮助用户构建合适的检索式。CreChainDo[27 ] 和CREDO[28 ] 两个系统展示了FCA在信息导航方面的应用, 以树状结构呈现概念间的关系, 通过用户和概念层次的交互实现信息导航。Dunaiski等[10 ] 利用概念格聚类学术文献, 用户通过浏览和点击标签云实现搜索的聚焦, 精练检索结果。
本文构建的基于形式概念分析的交互式知识地图实现了浏览、检索、查询式重构与聚焦搜索4个功能的融合。局部知识地图呈网状展现, 还原知识结构网状链接的本质, 更加符合人类脑海中一贯的知识组织认知方式, 有助于用户认知信息空间。本文在概念格的可视化方面也有改进, 以往概念格展示中存在格节点横向过度扩张和线段交叉的问题, 容易增加用户认知负荷。本文设计了用户自定义的广度和深度调节功能, 有效缓解用户认知负荷, 帮助用户快速聚焦核心知识节点、提高搜索效率。
7 结 语
在大数据时代, 海量学术资源降低了信息检索的效率, 如何快速查询到所需文献是科研人员亟待解决的难题。本文尝试从语义组织和用户交互两个方面探讨这个问题的解决方案。一方面, 利用形式概念分析方法挖掘并可视化文档空间中的概念及概念间的关系, 语义化、形式化地揭示文档空间隐含的知识结构, 为文献空间隐含概念关系挖掘和表示提供了一种可行的解决方案。另一方面, 利用知识地图将文献空间中的核心知识节点可视化, 并且提供迭代交互功能帮助用户快速聚焦和扩展查询。案例分析表明, 这种融合浏览和搜索功能的知识地图能够增强用户与系统的认知交互, 帮助用户快速精练检索结果集, 提高获取信息的效率。
本研究既关注对学术资源的组织, 解决文档中隐含知识难以发现、知识表示不够的问题, 还从用户层面出发, 帮助用户实时地和系统进行交互, 从而快速聚焦和逐步精练检索结果集。相比于反馈线性结果的学术搜索系统, 知识地图这种展示形式不仅能加深用户对学术资源空间的理解, 还能实现导航功能, 给用户带来良好的交互体验, 拓宽对学术搜索系统的研究思路。
本文的研究仍存在不足, 当用户输入的多个查询词没有完全匹配的概念时, 系统不能自动识别出关联概念。在下一步工作中, 将进行词汇的语义相似度计算研究, 以解决多个查询词与概念的智能匹配问题。
作者贡献声明
刘萍: 论文主题选取, 研究框架设计及论文修改;
李亚楠: 收集资料, 数据分析及论文撰写;
郁聪: 清洗和处理数据。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: pliuleeds@126.com。
[1] 刘萍, 李亚楠, 郁聪. SIGIR会议论文题目和关键词.xlsx. SIGIR国际会议在2006年-2016年间收录的693篇论文.
参考文献
文献选项
[1]
Parolo P D B Pan R K Ghosh R et al . Attention Decay in Science
[J]. Journal of Informetrics , 2015 , 9 (4 ): 734 -745 .
https://doi.org/10.1016/j.joi.2015.07.006
URL
[本文引用: 1]
[2]
孟小峰 , 慈祥 . 大数据管理: 概念、技术与挑战
[J]. 计算机研究与发展 , 2013 , 50 (1 ): 146 -169 .
URL
Magsci
[本文引用: 1]
摘要
云计算、物联网、社交网络等新兴服务促使人类社会的数据种类和规模正以前所未有的速度增长,大数据时代正式到来.数据从简单的处理对象开始转变为一种基础性资源,如何更好地管理和利用大数据已经成为普遍关注的话题.大数据的规模效应给数据存储、管理以及数据分析带来了极大的挑战,数据管理方式上的变革正在酝酿和发生.对大数据的基本概念进行剖析,并对大数据的主要应用作简单对比.在此基础上,阐述大数据处理的基本框架,并就云计算技术对于大数据时代数据管理所产生的作用进行分析.最后归纳总结大数据时代所面临的新挑战.
(Meng Xiaofeng Ci Xiang Big Data Management: Concepts, Techniques and Challenges
[J]. Journal of Computer Research & Development , 2013 , 50 (1 ): 146 -169 .)
URL
Magsci
[本文引用: 1]
摘要
云计算、物联网、社交网络等新兴服务促使人类社会的数据种类和规模正以前所未有的速度增长,大数据时代正式到来.数据从简单的处理对象开始转变为一种基础性资源,如何更好地管理和利用大数据已经成为普遍关注的话题.大数据的规模效应给数据存储、管理以及数据分析带来了极大的挑战,数据管理方式上的变革正在酝酿和发生.对大数据的基本概念进行剖析,并对大数据的主要应用作简单对比.在此基础上,阐述大数据处理的基本框架,并就云计算技术对于大数据时代数据管理所产生的作用进行分析.最后归纳总结大数据时代所面临的新挑战.
[3]
Yu J Wu H Tao C et al .Acquisition and Representation of Knowledge for Academic Field
[C]// Proceedings of the 2016 Asia-Pacific Web Conference. Springer , 2016 : 289 -297 .
[本文引用: 1]
[4]
张进 , 袁泽林 , 陆伟 . 信息检索可视化的主流路径
[J]. 图书情报知识 , 2008 (5 ): 24 -27 .
URL
[本文引用: 1]
摘要
可视化主要是利用人的视觉来理解信息。人的视觉系统是信息获取的主要渠道,据研究,人类70%的信息主要是通过视觉来获取的。科学家们发现,视觉不仅是信息获取的手段,同时也是信息处理的手段。这种处理不是线性的,而是并行的处理过程。并行的处理过程在效率和方式上都比线性处
(Zhang Jin Yuan Zelin Lu Wei Introduction to Mainstream Information Retrieval Visualization Approaches
[J]. Documentation, Information & Knowledge , 2008 (5 ): 24 -27 .)
URL
[本文引用: 1]
摘要
可视化主要是利用人的视觉来理解信息。人的视觉系统是信息获取的主要渠道,据研究,人类70%的信息主要是通过视觉来获取的。科学家们发现,视觉不仅是信息获取的手段,同时也是信息处理的手段。这种处理不是线性的,而是并行的处理过程。并行的处理过程在效率和方式上都比线性处
[5]
Kara S Alan ö Sabuncu O et al .An Ontology-based Retrieval System Using Semantic Indexing
[J]. Information Systems , 2012 , 37 (4 ): 294 -305 .
https://doi.org/10.1016/j.is.2011.09.004
URL
[本文引用: 1]
摘要
78 We introduce a scalable semantic information retrieval framework. 78 The framework is applied to soccer domain. 78 Each game is kept as a separate individual model and used to infer knowledge. 78 The inferred knowledge is indexed using the inverted index structure. 78 Our contribution is the way we deal with scalability and semantic querying.
[6]
Castells P Fernández M Vallet D An Adaptation of the Vector-Space Model for Ontology-Based Information Retrieval
[J]. IEEE Transactions on Knowledge & Data Engineering , 2007 , 19 (2 ): 261 -272 .
https://doi.org/10.1109/TKDE.2007.22
URL
[本文引用: 1]
摘要
Semantic search has been one of the motivations of the semantic Web since it was envisioned. We propose a model for the exploitation of ontology-based knowledge bases to improve search over large document repositories. In our view of information retrieval on the semantic Web, a search engine returns documents rather than, or in addition to, exact values in response to user queries. For this purpose, our approach includes an ontology-based scheme for the semiautomatic annotation of documents and a retrieval system. The retrieval model is based on an adaptation of the classic vector-space model, including an annotation weighting algorithm, and a ranking algorithm. Semantic search is combined with conventional keyword-based retrieval to achieve tolerance to knowledge base incompleteness. Experiments are shown where our approach is tested on corpora of significant scale, showing clear improvements with respect to keyword-based search
[7]
周文 . 基于概念的若干知识表示模型及相关方法研究[D]
. 上海: 上海大学 , 2007 .
[本文引用: 1]
(Zhou Wen Several Concept-based Knowledge Representations and Related Approaches[D]
. Shanghai: Shanghai University , 2007 .)
[本文引用: 1]
[8]
Qadi A E Ghali B E Aboutajddine D. Improving Information Retrieval by Query Expansion Using Formal Concept Analysis and Related Queries
[A]// Artificial Intelligence and Hybrid Systems [M]. iConcept Press, 2013 .
[本文引用: 1]
[9]
Qadi A E Aboutajedine D Ennouary Y Formal Concept Analysis for Information Retrieval
[J]. International Journal of Computer Science & Information Security , 2010 , 7 (2 ): 119 -125 .
[本文引用: 1]
[10]
Dunaiski M Greene G J Fischer B Exploratory Search of Academic Publication and Citation Data Using Interactive Tag Cloud Visualizations
[J]. Scientometrics , 2017 , 110 (3 ): 1539 -1571 .
https://doi.org/10.1007/s11192-016-2236-3
URL
[本文引用: 2]
摘要
Abstract Acquiring an overview of an unfamiliar discipline and exploring relevant papers and journals is often a laborious task for researchers. In this paper we show how exploratory search can be supported on a large collection of academic papers to allow users to answer complex scientometric questions which traditional retrieval approaches do not support optimally. We use our ConceptCloud browser, which makes use of a combination of concept lattices and tag clouds, to visually present academic publication data (specifically, the ACM Digital Library) in a browsable format that facilitates exploratory search. We augment this dataset with semantic categories, obtained through automatic keyphrase extraction from papers titles and abstracts, in order to provide the user with uniform keyphrases of the underlying data collection. We use the citations and references of papers to provide additional mechanisms for exploring relevant research by presenting aggregated reference and citation data not only for a single paper but also across topics, authors and journals, which is novel in our approach. We conduct a user study to evaluate our approach in which we asked 34 participants, from different academic backgrounds with varying degrees of research experience, to answer a variety of scientometric questions using our ConceptCloud browser. Participants were able to answer complex scientometric questions using our ConceptCloud browser with a mean correctness of 73%, with the user prior research experience having no statistically significant effect on the results.
[11]
滕广青 , 崔林蔚 . 大学图书馆网络用户柔性化细分
[J]. 图书馆学研究 , 2017 (2 ): 44 -51 .
URL
[本文引用: 1]
摘要
图书馆用户研究是图书馆学研究领域中的重要内容,有助于图书馆有的放矢地提供知识服务。运用K-Means快速聚类分析的方法,以问卷调查所获得的大学图书馆网络用户的信息行为数据为基础数据源,进行大学图书馆网络用户的初始细分。在此基础上借助形式概念分析(FCA)的方法构建大学图书馆网络用户概念格,基于用户概念格对大学图书馆网络用户进行柔性化细分。研究表明,大学图书馆网络用户细分呈现多维性、灵活性与交叠性的特征。
(Teng Guangqing Cui Linwei Flexible Segmentation on Network Users of University Library
[J]. Research on Library Science , 2017 (2 ): 44 -51 .)
URL
[本文引用: 1]
摘要
图书馆用户研究是图书馆学研究领域中的重要内容,有助于图书馆有的放矢地提供知识服务。运用K-Means快速聚类分析的方法,以问卷调查所获得的大学图书馆网络用户的信息行为数据为基础数据源,进行大学图书馆网络用户的初始细分。在此基础上借助形式概念分析(FCA)的方法构建大学图书馆网络用户概念格,基于用户概念格对大学图书馆网络用户进行柔性化细分。研究表明,大学图书馆网络用户细分呈现多维性、灵活性与交叠性的特征。
[12]
Sun X Chen Y Li B et al .Exploring Software Engineering Data with Formal Concept Analysis
[C]// Proceedings of the 1st International Workshop on Data Analysis Patterns in Software Engineering. IEEE , 2013 : 14 -16 .
[本文引用: 1]
[13]
Orphanides C Akhgar B Bayerl P S Discovering Knowledge in Online Drug Transactions Using Conceptual Graphs and Formal Concept Analysis
[C]// Proceedings of the 7th Intelligence and Security Informatics Conference. IEEE , 2016 : 100 -103 .
[本文引用: 1]
[14]
Brookes B C The Foundations of Information Science Part I. Philosophical Aspects
[J]. Journal of Information Science , 1980 , 2 (3-4 ): 125 -133 .
https://doi.org/10.1109/HICSS.1989.48136
URL
[本文引用: 1]
摘要
The study characterizes social epistemology, appropriates some contemporary thinkers for its agenda, and examines some prevailing theories about the foundations of information science. It is argued that the only adequate foundation for information science must be transdisciplinary, lying in the field of social epistemology.
[15]
王子舟 , 王碧滢 . 知识的基本组分——文献单元和知识单元
[J]. 中国图书馆学报 , 2003 , 29 (1 ): 5 -11 .
https://doi.org/10.3969/j.issn.1001-8867.2003.01.001
URL
[本文引用: 1]
摘要
知识组织是当代图书馆学的重要命题,知识组织是以知识组分为基础的,文献单元和知识单元是客观知识的基本组分,二者既有区别,又有联系,不能有所偏废。基于知识组分的知识组织有其涵义,原理和方法。 ...全文
(Wang Zizhou Wang Biying The Basic Components of Knowledge ——Literature Unit and Knowledge Unit
[J]. Journal of Library Science in China , 2003 , 29 (1 ): 5 -11 .)
https://doi.org/10.3969/j.issn.1001-8867.2003.01.001
URL
[本文引用: 1]
摘要
知识组织是当代图书馆学的重要命题,知识组织是以知识组分为基础的,文献单元和知识单元是客观知识的基本组分,二者既有区别,又有联系,不能有所偏废。基于知识组分的知识组织有其涵义,原理和方法。 ...全文
[16]
温有奎 , 徐国华 . 知识元链接理论
[J]. 情报学报 , 2003 , 22 (6 ): 665 -670 .
[本文引用: 1]
(Wen Youkui Xu Guohua Knowledge Element Linking Theory
[J]. Journal of the China Society for Scientific and Technical Information , 2003 , 22 (6 ): 665 -670 .)
[本文引用: 1]
[17]
温有奎 , 徐端颐 , 潘龙法 . 基于XML平台的知识元本体推理
[J]. 情报学报 , 2004 , 23 (6 ):643 -648 .
https://doi.org/10.3969/j.issn.1000-0135.2004.06.001
URL
[本文引用: 1]
摘要
传统信息检索系统不能满足人们的知识需求的根本原因在于知识组织的深度在文献层次上,解决的办法是将文献知识的控制单位深入到知识的最小单位——知识元层次上。本体论和XML工具为实现文本知识元计算机抽取及知识推理提供了通用的基础平台。
(Wen Youkui Xu Duanyi Pan Longfa Ontology Reasoning of Knowledge Element Based on XML Platform
[J]. Journal of the China Society for Scientific and Technical Information , 2004 , 23 (6 ): 643 -648 .)
https://doi.org/10.3969/j.issn.1000-0135.2004.06.001
URL
[本文引用: 1]
摘要
传统信息检索系统不能满足人们的知识需求的根本原因在于知识组织的深度在文献层次上,解决的办法是将文献知识的控制单位深入到知识的最小单位——知识元层次上。本体论和XML工具为实现文本知识元计算机抽取及知识推理提供了通用的基础平台。
[18]
文庭孝 , 侯经川 , 龚蛟腾 , 等 . 中文文本知识元的构建及其现实意义
[J]. 中国图书馆学报 , 2007 , 33 (6 ): 91 -95 .
https://doi.org/10.3969/j.issn.1001-8867.2007.06.019
URL
[本文引用: 1]
摘要
中文文本知识元的构建是解决汉语自动分词问题,实现对中文自然语言理解,并对知识内容进行操作、管理之基础。应当以汉语主题词为基础,构建中文文本知识元,建立知识元数据库,完成对知识内容的自由操作和管理。图1。参考文献26。
(Wen Tingxiao Hou Jingchuan Gong Jiaoteng et al .On the Construction of Chinese Text Knowledge Elements and Its Practical Significance
[J]. Journal of Library Science in China , 2007 , 33 (6 ): 91 -95 .)
https://doi.org/10.3969/j.issn.1001-8867.2007.06.019
URL
[本文引用: 1]
摘要
中文文本知识元的构建是解决汉语自动分词问题,实现对中文自然语言理解,并对知识内容进行操作、管理之基础。应当以汉语主题词为基础,构建中文文本知识元,建立知识元数据库,完成对知识内容的自由操作和管理。图1。参考文献26。
[19]
贾茜 , 张斌 . 基于认知语言学的文献主题元语义表示与结构分析
[J]. 情报理论与实践 , 2015 , 38 (2 ): 6 -10 .
https://doi.org/10.16353/j.cnki.1000-7490.2015.02.002
URL
[本文引用: 1]
摘要
文章对关键词进行分解,抽取学 科意义上的最小不可分词,以此表征主题元。借鉴认知语言学中的层次模型与概念整合的相关研究,详述了主题元的语义表示,同时论述了利用主题元进行认知结构 分析的基本过程。在方法论上,研究从物理统计分析层面拓展到认知层面,补充了知识网络方法。
(Jia Qian Zhang Bin Meta-semantic Representation and Structure Analysis of Literature Themes Based on Cognitive Linguistics
[J]. Information Studies: Theory and Application , 2015 , 38 (2 ): 6 -10 .)
https://doi.org/10.16353/j.cnki.1000-7490.2015.02.002
URL
[本文引用: 1]
摘要
文章对关键词进行分解,抽取学 科意义上的最小不可分词,以此表征主题元。借鉴认知语言学中的层次模型与概念整合的相关研究,详述了主题元的语义表示,同时论述了利用主题元进行认知结构 分析的基本过程。在方法论上,研究从物理统计分析层面拓展到认知层面,补充了知识网络方法。
[20]
姜永常 . 基于知识元语义链接的知识网络构建
[J]. 情报理论与实践 , 2011 , 34 (5 ): 50 -53 .
URL
[本文引用: 1]
摘要
本文基于Brookes文献中的知识节点及Swanson文献间的隐性关联概念,提出了一种基于知识元本体语义链接的知识网络实现流程。文中给出了文献单元和Web信息的知识元认知抽取方法,知识元本体的结构建立和语义互联,以及利用ProtÉgÉ技术实现基于知识元语义链接的知识网络构建步骤。
(Jiang Yongchang Knowledge Network Construction Based on Semantic Linking of Knowledge Element
[J]. Information Studies: Theory and Application , 2011 , 34 (5 ): 50 -53 .)
URL
[本文引用: 1]
摘要
本文基于Brookes文献中的知识节点及Swanson文献间的隐性关联概念,提出了一种基于知识元本体语义链接的知识网络实现流程。文中给出了文献单元和Web信息的知识元认知抽取方法,知识元本体的结构建立和语义互联,以及利用ProtÉgÉ技术实现基于知识元语义链接的知识网络构建步骤。
[21]
Lee J H Segev A Knowledge Maps for E-learning
[J]. Computers & Education , 2012 , 59 (2 ): 353 -364 .
https://doi.org/10.1016/j.compedu.2012.01.017
URL
[本文引用: 1]
摘要
Maps such as concept maps and knowledge maps are often used as learning materials. These maps have nodes and links, nodes as key concepts and links as relationships between key concepts. From a map, the user can recognize the important concepts and the relationships between them. To build concept or knowledge maps, domain experts are needed. Therefore, since these experts are hard to obtain, the cost of map creation is high. In this study, an attempt was made to automatically build a domain knowledge map for e-learning using text mining techniques. From a set of documents about a specific topic, keywords are extracted using the TF/IDF algorithm. A domain knowledge map (K-map) is based on ranking pairs of keywords according to the number of appearances in a sentence and the number of words in a sentence. The experiments analyzed the number of relations required to identify the important ideas in the text. In addition, the experiments compared K-map learning to document learning and found that K-map identifies the more important ideas. [All rights reserved Elsevier].
[22]
Evans V. How Words Mean: Lexical Concepts, Cognitive Models, and Meaning Construction [M]. Oxford : Oxford University Press , 2009 .
[本文引用: 1]
[23]
Wille R Restructing Lattice Theory: An Approach Based on Hierarchies of Concepts
[C]// Proceedings of the 7th International Conference on Formal Concept Analysis. 2009 : 314 -339 .
[本文引用: 1]
[24]
Ganter B Wille R Formal Concept Analysis: Mathematical Foundations
[M]. Springer , 1999 .
[本文引用: 1]
[25]
Poelmans J Elzinga P Dedene G Retrieval of Criminal Trajectories with an FCA-based Approach
[C]// Proceedings of the 2013 Formal Concept Analysis Meets Information Retrieval: Workshop Co-located with the 35th European Conference on Information Retrieval. 2013 : 83 -94 .
[本文引用: 1]
[26]
Ducrou J Eklund P W SearchSleuth: The Conceptual Neighbourhood of a Web Query
[C]// Proceedings of the 5th International Conference on Concept Lattices and Their Applications. 2007 , 331 : 249 -259 .
[本文引用: 1]
[27]
Nauer E Toussaint Y CreChainDo: An Iterative and Interactive Web Information Retrieval System Based on Lattices
[J]. International Journal of General Systems , 2009 , 38 (4 ): 363 -378 .
https://doi.org/10.1080/03081070902857613
URL
[本文引用: 1]
摘要
This paper presents an iterative and interactive information retrieval (IR) system for Web search using formal concept analysis (FCA). FCA provides a natural way to organise objects according to their properties and it has been used in recent work to organise search engine results. The navigation over the lattice helps the user to explore a structured and synthetic result. Such a lattice contains concepts that are relevant and others that are not relevant regarding a given IR task. In this way, lattices are introduced in an interactive and iterative system. The user expresses his negative or positive agreement with some concept of the lattice in respect of his objective of IR. These user choices are converted into operations over the lattice. The lattice is dynamically updated for a better fit to the request.
[28]
Carpineto C Romano G Exploiting the Potential of Concept Lattices for Information Retrieval with CREDO
[J]. Journal of Universal Computer Science , 2004 , 10 (8 ): 985 -1013 .
[本文引用: 1]
Attention Decay in Science
1
2015
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
大数据管理: 概念、技术与挑战
1
2013
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
大数据管理: 概念、技术与挑战
1
2013
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
Acquisition and Representation of Knowledge for Academic Field
1
2016
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
信息检索可视化的主流路径
1
2008
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
信息检索可视化的主流路径
1
2008
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
An Ontology-based Retrieval System Using Semantic Indexing
1
2012
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
An Adaptation of the Vector-Space Model for Ontology-Based Information Retrieval
1
2007
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
基于概念的若干知识表示模型及相关方法研究[D]
1
2007
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
基于概念的若干知识表示模型及相关方法研究[D]
1
2007
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
Improving Information Retrieval by Query Expansion Using Formal Concept Analysis and Related Queries
1
2013
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
Formal Concept Analysis for Information Retrieval
1
2010
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
Exploratory Search of Academic Publication and Citation Data Using Interactive Tag Cloud Visualizations
2
2017
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
... 形式概念分析已被应用在信息检索的浏览、导航、查询式重构和聚焦搜索等方面.Poelmans等[25 ] 通过FCA探测警察局报告中的非结构化数据, 帮助工作人员探索和定义调查范围内的隐含概念.SearchSleuth系统[26 ] 使用概念格分析搜索概念, 识别出搜索概念的上级、下级和同级节点, 帮助用户构建合适的检索式.CreChainDo[27 ] 和CREDO[28 ] 两个系统展示了FCA在信息导航方面的应用, 以树状结构呈现概念间的关系, 通过用户和概念层次的交互实现信息导航.Dunaiski等[10 ] 利用概念格聚类学术文献, 用户通过浏览和点击标签云实现搜索的聚焦, 精练检索结果. ...
大学图书馆网络用户柔性化细分
1
2017
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
大学图书馆网络用户柔性化细分
1
2017
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
Exploring Software Engineering Data with Formal Concept Analysis
1
2013
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
Discovering Knowledge in Online Drug Transactions Using Conceptual Graphs and Formal Concept Analysis
1
2016
... 随着网络技术的发展, 学术资源数量呈现爆炸式增长, 科研人员在更新领域知识和搜寻相关文献时面临巨大挑战[1 ] , 常常陷入信息迷航和信息过载的困 境[2 ,3 ] .科研人员获取文献的主要来源是学术资源数据库(如中国知网、Web of Science等), 通过分类检索和关键词搜索两种方式获取文献, 但这两种方式往往是分离的.在分类浏览时, 一方面新手用户对分类体系不熟悉, 很难快速找到所需分类类目; 另一方面相关文献可能分散在不同类目下, 分类浏览会漏掉一些重要文献.在使用关键词搜索文献时, 用户通常难以用精准的查询式表明自己的信息需求, 同时检索结果的线性排列割裂了文档的内在语义关联, 使检索结果中的文档对象呈现孤立状态[4 ] .针对以上问题, 有学者提出基于本体的信息检索方法[5 ,6 ] , 这种方法一定程度上解决了词的语义概念及相关关系问题, 但是现阶段构建领域本体的流程和方法还不够成熟, 本体技术在信息检索领域的应用面临许多困境.形式概念分析(Formal Concept Analysis, FCA)具有严密的数学理论、良好的逻辑推理性和自动化的构建方式[7 ] , 在概念挖掘以及概念关系识别方面有独特优势.近年来, 形式概念分析被广泛地应用在信息检索[8 ,9 ] 、Web挖掘[10 ] 、数字图书馆[11 ] 、软件工程[12 ] 和知识发现[13 ] 领域. ...
The Foundations of Information Science Part I. Philosophical Aspects
1
1980
... 学术文献的集合, 不仅是外在物理层次的文献单元的集合, 更是内在认知层次的知识概念以及概念之间关系的集合.情报学的重要任务之一就是组织知识(而不仅仅是文献)以便人们更有效地利用知识.早在1975年情报学家Brookes[14 ] 就提出知识地图的概念, 他认为在文献知识中找出它们的交集和相互制约因素可以追寻到人对思想和知识的需求, 同时指出可以把各个知识单元概念作为节点, 通过学科认知地图简洁明了地标示出人类的知识结构. ...
知识的基本组分——文献单元和知识单元
1
2003
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
知识的基本组分——文献单元和知识单元
1
2003
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
知识元链接理论
1
2003
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
知识元链接理论
1
2003
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
基于XML平台的知识元本体推理
1
2004
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
基于XML平台的知识元本体推理
1
2004
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
中文文本知识元的构建及其现实意义
1
2007
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
中文文本知识元的构建及其现实意义
1
2007
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
基于认知语言学的文献主题元语义表示与结构分析
1
2015
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
基于认知语言学的文献主题元语义表示与结构分析
1
2015
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
基于知识元语义链接的知识网络构建
1
2011
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
基于知识元语义链接的知识网络构建
1
2011
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
Knowledge Maps for E-learning
1
2012
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
1
2009
... 目前图书情报领域对“知识单元概念”的研究理论有一些探讨.部分学者认为知识单元是文献单元中的知识内容单元[15 ] .一些学者认为知识元是知识被分解成可独立使用的最小单位[16 ,17 ] , 由代表词的知识因子与知识关联组成, 即知识元本身应是完整的知识表达; 有学者认为知识单元是表达知识内容的主题词或关键词集合[18 ] ; 还有学者认为知识单元是由语义链连接的主题元[19 ] .从实践上看, 大多数知识地图以及知识网络研究在知识节点的表达形式上比较单一, 主要是抽取文献中的重要词汇作为概念节点[20 ,21 ] .以认知语言学理论为基础, 本文认为词汇是概念的重要属性, 但是词汇本身并不等同于概念.因为单个词汇在不同语境中有不同的指代功能, 无法使用单个词汇塑造一个十分精准的概念.正如英国认知语言学学会主席Evans教授所言[22 ] , 与词相关的意义具有多变的本质, 词义是易变的、开放的、高度依赖于其所在的话语语境, 通过词汇的语义整合才能塑造较为精准且不同粒度的概念.比如整合“图书馆”、“用户”和“信息行为”三个语义关联的词汇能产生一个细粒度的概念, 在这个概念中, “图书馆”、“用户”和“信息行为”三个词整合在一起作为它的属性.这里要指出的是, 虽然属性是创造概念和区分概念的重要基础, 但是属性本身并不是概念的全部.属性表达概念的内涵, 而概念的外延, 即具有概念所反映的特有属性的所有事物, 也是不可或缺的, 两者互为依存.内涵是对一切外延特征的概括, 外延是内涵表述的具体化.在本文中, 内涵是词汇的整合, 外延是包含特定词汇的文献集合.这样一种以内涵和外延两种基本特征规范的概念既符合人类认知, 也扩充了以往对知识概念的定义.可以看到, 内涵越大, 外延就越小; 内涵越小, 外延就越大.比如当概念的内涵是“图书馆”时, 所有主题是图书馆的文献都是它的外延; 而当概念的内涵是“图书馆”、“用户”和“信息行为”的集合时, 只有同时包含这三个主题的文献才是它的外延.另一方面, 外延限制了内涵, 也就是不同的文献集合决定不同的概念属性, 词汇间的整合不是任意的. ...
Restructing Lattice Theory: An Approach Based on Hierarchies of Concepts
1
2009
... 基于“概念是由外延和内涵组成的思想单元”, Wille[23 ] 提出形式概念分析理论, 通过挖掘对象和属性间的二元关系建立概念层次结构, 是知识发现的重要方法.本文使用形式概念分析方法对文档空间进行建模, 挖掘文档空间中的隐含概念并且识别概念之间的关系, 具体建模过程如图1 所示. ...
Formal Concept Analysis: Mathematical Foundations
1
1999
... 其中, w 1 , w 2 分别是属性和对象的权重, 满足w 1 + w 2 =1.根据概念格的对偶原理[24 ] , 概念的对象和属性地位等同, 所以本文取w 1 =w 2 =0.5.根据公式(1)能够计算出概念节点之间的相似度, 在满足用户设定阈值的情况下, 本文尽可能地筛选出概念相似度大的节点对知识地图进行优化, 以期在有限的知识地图中展示出和用户密切相关的知识单元, 提高信息搜寻效率. ...
Retrieval of Criminal Trajectories with an FCA-based Approach
1
2013
... 形式概念分析已被应用在信息检索的浏览、导航、查询式重构和聚焦搜索等方面.Poelmans等[25 ] 通过FCA探测警察局报告中的非结构化数据, 帮助工作人员探索和定义调查范围内的隐含概念.SearchSleuth系统[26 ] 使用概念格分析搜索概念, 识别出搜索概念的上级、下级和同级节点, 帮助用户构建合适的检索式.CreChainDo[27 ] 和CREDO[28 ] 两个系统展示了FCA在信息导航方面的应用, 以树状结构呈现概念间的关系, 通过用户和概念层次的交互实现信息导航.Dunaiski等[10 ] 利用概念格聚类学术文献, 用户通过浏览和点击标签云实现搜索的聚焦, 精练检索结果. ...
SearchSleuth: The Conceptual Neighbourhood of a Web Query
1
2007
... 形式概念分析已被应用在信息检索的浏览、导航、查询式重构和聚焦搜索等方面.Poelmans等[25 ] 通过FCA探测警察局报告中的非结构化数据, 帮助工作人员探索和定义调查范围内的隐含概念.SearchSleuth系统[26 ] 使用概念格分析搜索概念, 识别出搜索概念的上级、下级和同级节点, 帮助用户构建合适的检索式.CreChainDo[27 ] 和CREDO[28 ] 两个系统展示了FCA在信息导航方面的应用, 以树状结构呈现概念间的关系, 通过用户和概念层次的交互实现信息导航.Dunaiski等[10 ] 利用概念格聚类学术文献, 用户通过浏览和点击标签云实现搜索的聚焦, 精练检索结果. ...
CreChainDo: An Iterative and Interactive Web Information Retrieval System Based on Lattices
1
2009
... 形式概念分析已被应用在信息检索的浏览、导航、查询式重构和聚焦搜索等方面.Poelmans等[25 ] 通过FCA探测警察局报告中的非结构化数据, 帮助工作人员探索和定义调查范围内的隐含概念.SearchSleuth系统[26 ] 使用概念格分析搜索概念, 识别出搜索概念的上级、下级和同级节点, 帮助用户构建合适的检索式.CreChainDo[27 ] 和CREDO[28 ] 两个系统展示了FCA在信息导航方面的应用, 以树状结构呈现概念间的关系, 通过用户和概念层次的交互实现信息导航.Dunaiski等[10 ] 利用概念格聚类学术文献, 用户通过浏览和点击标签云实现搜索的聚焦, 精练检索结果. ...
Exploiting the Potential of Concept Lattices for Information Retrieval with CREDO
1
2004
... 形式概念分析已被应用在信息检索的浏览、导航、查询式重构和聚焦搜索等方面.Poelmans等[25 ] 通过FCA探测警察局报告中的非结构化数据, 帮助工作人员探索和定义调查范围内的隐含概念.SearchSleuth系统[26 ] 使用概念格分析搜索概念, 识别出搜索概念的上级、下级和同级节点, 帮助用户构建合适的检索式.CreChainDo[27 ] 和CREDO[28 ] 两个系统展示了FCA在信息导航方面的应用, 以树状结构呈现概念间的关系, 通过用户和概念层次的交互实现信息导航.Dunaiski等[10 ] 利用概念格聚类学术文献, 用户通过浏览和点击标签云实现搜索的聚焦, 精练检索结果. ...

 , 李亚楠
, 李亚楠




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}