
|
|
程秀峰
Cheng Xiufeng
中图分类号: G25
通讯作者:
收稿日期: 2018-04-13
修回日期: 2018-05-23
网络出版日期: 2018-12-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】协助相关决策部门监督和管理网络舆情, 探测可能成为舆情关注焦点的新兴话题。【方法】提出网络问答社区中新兴话题的识别标准和依据, 并基于知乎问答社区, 利用CART决策树对识别过程进行实证研究。【结果】对于网络问答社区, CART决策树在新兴话题的识别与预测方面具有较好的准确性和适用性。【局限】实验数据只占知乎所有话题板块的一小部分, 为验证该方法的有效性, 需要进一步扩展数据集。【结论】基于CART决策树的网络问答社区新兴话题识别方法能够有效预测新兴话题, 可为网络问答社区的热点话题筛选机制提供参考。
关键词:
Abstract
[Objective] This paper tries to identify the trending topics, aiming to help the decision-making agencies manage online public opinion. [Methods] Firstly, we proposed the criteria to detect the trending topics of Q&A community. Then, we conducted an empirical study on China’s Zhihu Q&A community using the CART decision tree algorithm. [Results] The CART decision tree predicted the trending topics. [Limitations] We only collected data from a small portion of all topics on Zhihu. More data is needed for future studies. [Conclusions] The proposed method based on the CART decision tree algorithm could effectively predict trending topics in the Q&A community, which help us choose popular contents.
Keywords:
网络问答社区(Q&A Community)是以问题为核心、交互为手段、共享为模式的知识平台, 用户能在其中充分参与任何问题的交流与分享[1]。网络问答社区是当下流行的社交网络形态之一, 其话题具有特殊性, 既有传统社交、新闻媒体的数据稀疏、内容庞杂的特点, 又有树形话题结构所独有的内在关联性和逻辑性。
新兴话题(Emerging Topics)是话题流行或爆发之前的早期存在状态[2], 在实时性需求较高的媒体与社交平台上, 某些新兴话题往往能够很快发酵成为舆情关注的焦点, 进而在网络中迅速传播。现有问答社区缺乏有效而准确的识别(预测)机制, 无法在短时间内甄别出容易演变成热点话题的新兴话题。这会导致决策部门因未能及时发现潜在热点而延误事件处理, 且随着时间推移, 某些话题甚至会不断发酵, 造成虚假信息、恶意言论的不可控传播。
机器学习中的决策树(Decision Tree)是一种通过计算已知事件概率构建分类树判断可能事件概率的一种监督学习方法, 被广泛用于分类与回归任务中, 具有直观、高效、可测等优点[3], 十分适合对网络问答社区中的话题进行分类与识别。
国内外关于决策树的研究非常活跃, 而话题识别与探测相关研究发展相对滞后。目前, 新兴话题识别研究对象主要集中在微博、文献摘要、论坛等内容[4,5], 其核心问题是新兴话题的早期发现。传统的基于聚 类[6]、模型[7]、矩阵相似度[8]等方法虽具有识别能力, 但在海量数据处理、实时性、预测准确性、易用性等方面存在瓶颈[2]。
从内容识别上看, 新兴话题虽具有很高的内容独特性, 但往往需要足够的语料规模才能保证话题发现的性能, Mehrotra等提出的基于LDA模型的微博新兴话题检测方法得到广泛认可[9]; 从行为分析上看, 考虑用户社交过程中的异常行为来挖掘新兴话题的方法也获得关注[10]; 从传播学角度看, 新兴话题传播具有很强的时效性和爆发性, 当前研究在识别新兴话题的时效性方面取得了较大突破[11]。
通过梳理相关文献发现, 学界将内容与行为相结合进行新兴话题识别的研究尚有一定的发展空间。同时, 很大一部分研究仅对已有信息进行分类与发现[5], 并没有引入预测的概念; 再者, 很多研究是针对传统话题检测的不足进行局部改善, 对于机器学习算法多持保留态度[12]。
在数据挖掘领域, 大多数复杂的机器学习算法计算过程晦涩难懂, 无法满足简明性需求。而决策树具备简洁高效的特点, 适合商业部署与应用[13,14], 在Quinlan提出传统决策树ID3算法后[15], 出现了一系列衍生算法及相关优化策略[16]。在实践中也有许多衍生算法的应用, 比如通过设置用户分类测试属性识别出广告用户, 以此达到话题过滤目的[17]; 又或是计算特征词对短文本信息流进行划分的信息增益率, 形成决策树检测模型对样本进行检测[18], 但都存在标准设置缺乏依据、筛选方法未有效结合话题内容的问题。
本文采用分类与回归树(Classification And Regression Tree, CART)算法对新兴话题进行识别, 因其利用Gini值最小作为分界点选取标准, 而且是一棵二叉树, 具有计算量小、速度快、易于解释的优点, 在相对短的时间内处理大量真实数据的效果较好。
(1) 概 念
网络问答社区中的话题是一系列相关子问题的集合。以知乎为例, 其全部话题通过父子关系构成一个有根无循环的有向图, 根话题是所有话题的最顶层父话题, 呈现树状结构。用户所提问题构成某个话题的全部内容, 不同的问题由用户标注其父话题, 然后系统通过标签将问题分类。因此, 识别新兴话题的核心是分析用户所提问题。本文不强调区分“问题”与“话题”的区别。
(2) 特 征
新兴话题具有热点话题的一般特征, 但是两者存在时间和发展上的差异, 前者更具特殊性。新兴话题的具体特征如下:
①吸引力较强: 新兴话题能够吸引更多的社区用户关注, 促使用户积极参与到相关话题的讨论中, 并产生转发、评论、点赞等一系列行为[19]。
②参与度较高: 在一段可检测的时间范围内, 关注新兴话题的人数、问题回答数都会在较高水平上持续增长。
③影响力较大: 一些突发事件在短时间内引起民众的广泛关注, 而与事件相关的新兴话题也能够在社区中迅速引起热议, 产生巨大影响力。
④内容多样性: 用户可以围绕新兴话题展开各种讨论, 即使问题单一, 用户也会有不同解读, 使得话题的回答内容丰富多样。
⑤间隔时间短: 一方面, 用户围绕某一事实提出的新兴话题间隔时间短, 易于集中爆发; 另一方面, 每一新兴话题的回答时间间隔也较短[20]。
⑥具备关键节点: 新兴话题之所以能够成为热点话题, 重要原因在于有关键用户参与讨论。此类用户由于自身受关注程度较高, 能够较快吸引其他用户对此话题的关注[21]。
⑦传播速度快: 在新问题提出后的短时间内, 如果迅速吸引大量用户, 必然得到大量推送, 传播范围也会具有扩散效应。
构建基于CART决策树算法的新兴话题识别标准体系应当注意两个基本原则, 一是新兴话题的识别标准必须适合决策树训练集对于属性节点的独立要求, 同时具有较高区别效度; 二是具体的标准应当适应网络问答社区目前的形式, 便于采集、处理和分析数据。因此根据上述一般特征, 构建新兴话题识别标准。
(1) 问题关注度
新兴问题通常在初期就呈现出吸引力较强、参与度较高的特征, 并且随时间推移, 其影响力迅速扩大。因此, 短时间内关注度剧增是判断问题属于新兴问题的首要标准。笔者采用浏览次数、关注人数和回答数量三个二级标准对问题关注度进行描述, 如公式(1)和公式(2)所示。
$F=\alpha \times L(t\text{)+}\beta \times N\text{(}t\text{)+}\gamma \times P\text{(}t)$ (1)
$\left\{ \begin{align} & L(t)=\delta \times {{l}_{\left| {{t}_{2}}-{{t}_{1}} \right|}} \\ & N(t)=\varepsilon \times {{n}_{\left| {{t}_{2}}-{{t}_{1}} \right|}} \\ & P(t)=\theta \times {{p}_{\left| {{t}_{2}}-{{t}_{1}} \right|}} \\ \end{align} \right.$ (2)
其中, $\alpha $、$\beta $与$\gamma $分别为浏览次数、关注人数与回答数量的权值, $\alpha$+$\beta $+$\gamma $=1, 结合网络问答社区特点, 回答数量更能体现出高关注度的内涵, 因此本文取$\alpha $=0.25, $\beta $=0.25, $\gamma $=0.5。$\delta $、$\varepsilon $与$\theta$分别为参数, 本文取$\delta \text{=}\varepsilon \text{=}\theta \text{=}1$, 某一问题在时间区间[t1, t2]内被浏览的次数为L(t), 关注人数为N(t), 回复数量为P(t)。
(2) 问题内聚度
问题的回答是用户对客观世界的认识表达。对于新兴话题而言, 问题与回答之间的密切程度决定了问题的内聚性。因此, 一个问题的不同回答与问题本身的相关度是一个重要判断标准。采用问题内聚度对此进行描述, 如公式(3)-公式(5)所示。
$K=\sum\limits_{i=1}^{P}{G({{f}_{i}})}$ (3)
$G({{f}_{i}})=\frac{{{f}_{i}}}{\max ({{f}_{1}},{{f}_{2}},...,{{f}_{p}})}$ (4)[22]
$\left\{ \begin{align} & TF-ID{{F}_{i}}=T{{F}_{i,j}}\times ID{{F}_{i}} \\ & T{{F}_{i,j}}=\frac{{{n}_{i,j}}}{\sum\limits_{k}{{{n}_{k,j}}}} \\ & ID{{F}_{i}}=\text{log}\frac{\left| D \right|}{\left| \left\{ j:{{t}_{i}}\in {{d}_{j}} \right\} \right|} \\ \end{align} \right.$ (5)[23]
公式(3)表示对每一个回答的G(fi)值进行累计, 得到问题的内聚度K; 公式(4)表示G(fi)为第i个回答的TF-IDF值与所有回答中最大TF-IDF值的比值; 公式(5)表示本文选定的f特征是话题检测和跟踪技术中的TF-IDF距离, fi为第i位回答者内容的TF-IDF值。
(3) 问题影响度
拥有大量追随者的关键用户比普通用户影响力更大, 其行为会产生扩散效应。因此, 关键用户的相关特征是判断该问题影响度的重要因素。本文采用问题影响度对此进行描述, 如公式(6)和公式(7)所示。
$Q=\sum\limits_{i=1}^{S}{{{\lambda }_{i}}}$ (6)
${{\lambda }_{i}}=\varphi \times A+\eta \times B+\mu \times C+\sigma \times D+\omega \times E$ (7)
其中, λi为第i位参与回答用户的关键程度, S为回答问题的人数, 通过累计回答问题的全部用户关键度, 可以得出该问题的综合影响度。$\varphi \eta \mu \sigma $与$\omega $分别为对应的权值, $\varphi \text{+}\eta \text{+}\mu \text{+}\sigma \text{+}\omega \text{=}1$, 本文取$\varphi \text{=}\eta \text{=}\mu \text{=}\sigma \text{=}\omega \text{=}0.2$, λi值可选取网络问答社区中的具体指标计算。本文对用户的关注数(A)、关注者数(B)、发表数量(C)、获得总赞同数(D)以及参与公共编辑 次数(E)直接累加计算。实测数据说明, 利用简单的统计学方法识别用户关键度也能得到较好结果[24]。
综上, 本文结合新兴话题特征, 设置问题关注度、问题内聚度以及问题影响度三个一级标准, 并在此基础上设置相应的二级标准, 以此作为识别新兴问题方法的整体参照, 具体如表1所示。
表1 新兴话题识别模式特征—标准对应表
| 特征 | 一级标准 | 二级标准 |
|---|---|---|
| ①吸引力较强 | A问题关注度 | A1浏览次数 |
| ②参与度较高 | A2关注人数 | |
| ③影响力较大 | A3回答数量 | |
| ④内容多样性 | B问题内聚度 | B1回答相近度 |
| ⑤间隔时间短 | B2粒度特征值 | |
| ⑥具备关键节点 | C问题影响度 | C1用户关键度 |
| ⑦传播速度快 |
(1) 传统的决策树算法
在几种典型的决策树分类算法中, ID3算法[25]适用于处理离散值, 采用信息增益值最大的特征作为根节点, 自顶向下进行搜索; 而C4.5算法[26]是ID3算法的扩展, 能够处理连续值, 并且通过信息增益率选择属性, 消除信息增益指标导致的问题。
在处理问题关注度、问题内聚度以及问题影响度等独立属性的过程中, 由于属性的可取值数目不再有限, 此时最基本的策略是采用决策树C4.5算法中的二分法机制对连续属性进行离散化处理[26]。然而, 决策树C4.5算法也存在不足, 遇到连续属性要进行多次的顺序扫描和排序, 生成多叉树的效率不高, 此外, 由于C4.5算法生成的决策树模型复杂度过大, 还会出现过度拟合的情况, 导致决策树生成规则难于理解[27]。
(2) CART算法
本文采用的CART算法可以处理高度倾斜或多态的数值型数据, 也可处理顺序或无序的类属型数 据[28]。CART决策树选择具有最小Gini系数值的属性作为测试属性, 并按照节点的测试属性采用二元递归分割的方式把每个内部节点分割成两个子节点, 递归形成一棵结构简洁的二叉树。
与传统的C4.5算法相比, CART算法的优势在于:
①样本数量较多时, 二叉树模型的运算效率高于多叉树的运算效率;
②由于二叉树不易产生数据碎片, 精确度往往高于多叉树[29];
③二叉树模型简单, 生成的规则易于理解。
假设当前样本集合D中第K类样本所占比例为${{P}_{k}}(K\text{=}1,2,\cdot \cdot \cdot ,\left| y \right|)$, 则数据集D的纯度可用Gini值度量, 如公式(8)所示。
$Gini(D)=\sum\limits_{k=1}^{\left| y \right|}{\sum\limits_{k'\ne k}{{{p}_{k}}{{p}_{k'}}}}=1-\sum\limits_{k=1}^{\left| y \right|}{p_{k}^{2}}$ (8)[30]
$Gini(D)$反映了从数据集D中随机抽取两个样本, 其类别标记不一致的概率, 因此$Gini(D)$越小, 则数据集D的纯度越高, 划分效果越好。
实验数据集来自知乎问答社区的“人工智能”、“科幻”、“自然科学”、“心理学”、“生活”、“电影”、“旅行”、“教育”、“音乐”、“法律”共10个话题板块。
本文提出新兴话题识别方法的目的是预测出具有较大概率演变成热点话题的新兴话题。因此, 实验希望将知乎目前的话题筛选机制与本文提出的识别机制进行对比, 然而知乎话题排名的具体计算方法尚不明确, 故基于本文提出的新兴话题识别标准体系构建两棵决策树, 在此基础上比较预测准确率。
2018年3月9日, 采集在上述话题板块中用户提出的共718个新问题作为实验数据, 获取问题的关注人数、浏览次数、回答数量等相关内容。2018年3月13日, 采集上述问题中进入知乎话题排行榜前300名的具体排名情况, 以此为参考构建决策树Tree1, 并通过计算所有问题的问题关注度、问题内聚度以及问题影响度进行重新排名, 选取合适的问题构建决策树Tree2。
2018年3月13日, 在知乎上述话题板块的热门问题中, 取进入排行榜前136名的问题(记为T1)作为知乎话题分类机制所识别的新兴话题, 取位于排行榜137-250名的问题(记为T2)作为知乎话题分类机制所识别的非新兴话题。根据本文新兴话题的识别标准计算并整理出T1与T2的问题关注度、问题内聚度以及问题影响度。构建决策树之前将知乎问题数据进行格式化处理, 具体如表2和表3所示。
表2 预处理的T1问题数据
| Title | Focus | Cohesion | Impact | Is | Order |
|---|---|---|---|---|---|
| Tree1.Topic1 | 1 379 560 | 8.99 | 502 643 | 1 | 25 |
| Tree1.Topic2 | 9 495 | 9.81 | 83 591 | 1 | 49 |
| Tree1.Topic3 | 356 204 | 8.04 | 522 595 | 1 | 55 |
| Tree1.Topic4 | 51 740 | 8.23 | 89 478 | 1 | 63 |
| Tree1.Topic5 | 347 185 | 9.28 | 994 162 | 1 | 93 |
| Tree1.Topic6 | 3 496 | 1.98 | 8 874 | 1 | 94 |
| Tree1.Topic7 | 8 538 | 3.64 | 597 | 1 | 96 |
| Tree1.Topic8 | 4 361 | 4.41 | 10 818 | 1 | 99 |
| Tree1.Topic9 | 56 159 | 3.33 | 93 735 | 1 | 110 |
| Tree1.Topic10 | 35 877 | 1.82 | 21 288 | 1 | 115 |
| Tree1.Topic11 | 6 600 | 5.86 | 5 318 | 1 | 118 |
| Tree1.Topic12 | 403 128 | 8.66 | 97 756 | 1 | 121 |
| Tree1.Topic13 | 4 249 | 1.89 | 1 108 | 1 | 124 |
| Tree1.Topic14 | 703 195 | 15.20 | 52 308 | 1 | 128 |
| Tree1.Topic15 | 1 327 | 4.31 | 2 760 | 1 | 136 |
表3 预处理的T2问题数据
| Title | Focus | Cohesion | Impact | Is | Order |
|---|---|---|---|---|---|
| Tree1.Topic16 | 109 452 | 15.91 | 109 622 | 0 | 137 |
| Tree1.Topic17 | 95 | 0 | 0 | 0 | 139 |
| Tree1.Topic18 | 648 | 7.18 | 457 | 0 | 145 |
| Tree1.Topic19 | 5 068 | 3.49 | 111 | 0 | 149 |
| Tree1.Topic20 | 950 | 3.27 | 11 670 | 0 | 153 |
| Tree1.Topic21 | 801 | 1.53 | 46 | 0 | 159 |
| Tree1.Topic22 | 1 472 | 1.97 | 44 | 0 | 163 |
| Tree1.Topic23 | 791 | 2.37 | 586 | 0 | 164 |
| Tree1.Topic24 | 426 | 1.83 | 12 650 | 0 | 173 |
| Tree1.Topic25 | 281 | 1.85 | 68 | 0 | 180 |
| Tree1.Topic26 | 871 | 3.39 | 5 181 | 0 | 203 |
| Tree1.Topic27 | 1 196 | 2.11 | 144 588 | 0 | 207 |
| Tree1.Topic28 | 576 | 3.13 | 9 949 | 0 | 209 |
| Tree1.Topic29 | 408 | 1.95 | 16 350 | 0 | 213 |
| Tree1.Topic30 | 463 | 2.46 | 465 | 0 | 234 |
2018年3月13日, 计算所有问题的问题关注度、问题内聚度和问题影响度, 将不同数据按统一标准归一化得出综合排名, 在所有话题中等间距取前15名作为本文话题机制所识别出的新兴话题(记为T3), 再取16-30名作为本文机制所识别出的非新兴话题(记为T4)。
在对数据归一化时, 由于计算问题内聚度Cohesion时采取的TF-IDF算法存在缺陷, 因此对Focus、Impact和Cohesion分别赋权重为2:2:1, 然后将每一类具体值从大到小排序, 最大值记为1, 以此类推, 最后计算各值之和得出新兴话题排名。
根据分类标准进行相关计算, 将知乎问题数据进行格式化处理, 具体如表4和表5所示。
表4 预处理的T3问题数据
| Title | Focus | Cohesion | Impact | Is | Order |
|---|---|---|---|---|---|
| Tree2.Topic1 | 109 452 | 15.91 | 109 622 | 1 | 1 |
| Tree2.Topic2 | 403128 | 8.66 | 97 756 | 1 | 8 |
| Tree2.Topic3 | 14 593 | 5.26 | 2 347 | 1 | 15 |
| Tree2.Topic4 | 2 357 | 3.28 | 36 327 | 1 | 22 |
| Tree2.Topic5 | 217 | 4.29 | 2 751 | 1 | 29 |
| Tree2.Topic6 | 233 | 3.92 | 1 178 | 1 | 36 |
| Tree2.Topic7 | 165 | 4.00 | 700 | 1 | 43 |
| Tree2.Topic8 | 82 | 4.36 | 1 182 | 1 | 50 |
| Tree2.Topic9 | 3 496 | 1.98 | 8 874 | 1 | 57 |
| Tree2.Topic10 | 151 | 2.77 | 1 156 | 1 | 64 |
| Tree2.Topic11 | 170 | 3.03 | 390 | 1 | 71 |
| Tree2.Topic12 | 426 | 1.82 | 12 650 | 1 | 78 |
| Tree2.Topic13 | 294 | 3.46 | 59 | 1 | 85 |
| Tree2.Topic14 | 135 | 2.98 | 246 | 1 | 92 |
| Tree2.Topic15 | 141 | 2.54 | 322 | 1 | 99 |
表5 预处理的T4问题数据
| Title | Focus | Cohesion | Impact | Is | Order |
|---|---|---|---|---|---|
| Tree2.Topic16 | 156 | 1.82 | 8 982 | 0 | 106 |
| Tree2.Topic17 | 102 | 3.78 | 51 | 0 | 113 |
| Tree2.Topic18 | 309 | 1.64 | 1 141 | 0 | 120 |
| Tree2.Topic19 | 865 | 1.34 | 2 178 | 0 | 127 |
| Tree2.Topic20 | 161 | 2.68 | 39 | 0 | 134 |
| Tree2.Topic21 | 75 | 3.26 | 54 | 0 | 141 |
| Tree2.Topic22 | 187 | 2.68 | 27 | 0 | 148 |
| Tree2.Topic23 | 87 | 2.04 | 169 | 0 | 155 |
| Tree2.Topic24 | 57 | 1.81 | 1 350 | 0 | 162 |
| Tree2.Topic25 | 117 | 2.03 | 47 | 0 | 169 |
| Tree2.Topic26 | 56 | 1.78 | 405 | 0 | 176 |
| Tree2.Topic27 | 31 | 1.91 | 1 091 | 0 | 183 |
| Tree2.Topic28 | 130 | 1.99 | 18 | 0 | 190 |
| Tree2.Topic29 | 59 | 1.76 | 239 | 0 | 197 |
| Tree2.Topic30 | 93 | 1.71 | 64 | 0 | 204 |
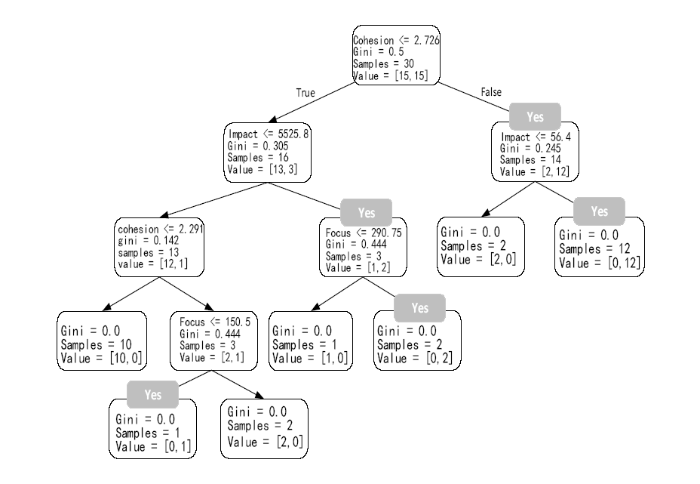
在分别对问题数据进行预处理后, 利用训练集构建决策树Tree1和决策树Tree2, 结果如图1和图2所示。
其中, Gini表示基尼值, Samples表示样本量, Value表示类别区间, Yes表示该类别下的话题均为新兴话题, Focus、Impact、Order含义同前所述。
识别出具有较大潜力在一定时间后演变成热点话题的新兴话题, 并且提前做好舆情措施, 正是本文提出新兴话题识别机制的意义所在, 因此对于该机制的评价也应利用热点话题的判断标准, 检验预测准确率。
目前关于知乎热点话题判断标准的研究尚不完善, 因此结合微博社区热门话题的检测方法, 建立基于评论树的知乎热点话题评判标准, 计算方法如公式(9)所示。
${{R}_{i}}=\theta \frac{1}{p}\sum\limits_{j=1}^{P}{{{C}_{\text{1}j}}}+\mu \frac{1}{M}\sum\limits_{j=1}^{M}{{{C}_{\text{2}j}}}$ (9)[31]
对于一个问题, 感兴趣的用户会对其发表评论, 其他用户又会对某些回答进行相应评价。把直接对问题的回答称为第一层次, 对第一层次回答的评论称为第二层次, 依此类推。其中, Ri表示第i个问题的热度, P表示某个问题的回答数, M表示所有回答的评论数之和, C1j表示第一层次第j个回答的点赞数量, C2j表示第二层次第r个评论的点赞数量。其中$\theta +\mu =1$, 取$\theta =\mu =0.5$。
为比较知乎话题分类机制与本文基于CART决策树的新兴话题识别机制对于新兴话题预测的效果, 于2018年3月19日在上述相同的知乎问答社区10个话题板块下采集670个新问题进行持续观测, 并于2018年3月22日计算出670个新问题的全部相关量, 即问题关注度、问题内聚度和问题影响度, 并将相应计算数据分别导入决策树Tree1和决策树Tree2进行预测, 其中, Tree1预测出的新兴话题记为X1, Tree2预测出的新兴话题记为X2。
2018年3月28日采集上文的670个新问题的全部相关评论, 经过较长时间的酝酿, 新话题已经发展较为成熟, 能够得到较为合理的基于评论树的热点话题排名。
对比两棵决策树预测出的新兴话题与基于评论树进行评分排名得出的热点话题, 得出X1与X2的预测准确率, 具体预测情况如图3所示。
由预测结果可知, 若取话题评论得分前40名为热点话题, 则X1准确率为0.775, X2准确率为0.725; 若取话题评论得分前80名为热点话题, 则X1准确率为0.513, X2准确率为0.525; 若取话题评论得分前120名为热点话题, 则X1准确率为0.342, X2准确率为0.392, 之后, 无论取话题评论得分前160名或前200名时, X2准确率均高于X1。
通过计算发现取话题评论得分前74名为热点话题时, X1与X2的准确率实现第一次相同, 在临界范围(74-76)内X1与X2的预测准确率均相同, 即只要取热点话题数量大于临界值76名时, X2的准确率均要高于X1。
本文针对网络问答社区的话题识别机制存在不足导致新兴话题检测延滞的现状, 结合CART决策树的属性适用原则和网络问答社区的应用场景, 构建具有成为热点话题潜力的新兴话题识别相关标准, 并在知乎问答平台进行实验, 检验基于CART决策树的新兴话题识别方法的应用效果。
研究发现, 基于CART决策树的网络问答社区新兴话题识别方法具有较高的准确性。根据热点话题客观标准取排名前列的话题为热点话题时, 其预测的精准程度与知乎的话题分类机制相差无几; 而根据热点话题客观标准取高于临界值的热点话题数量时, 本文所建识别机制的预测准确程度高于知乎目前的话题分类机制, 并且两者差距在不断拉大。这表明该方法能够有效发现新兴话题, 在实践中可以构建新兴话题库, 为网络问答社区的热点话题排名提供参考, 也有利于早期识别出易于演化成热点话题的新兴话题, 协助企业、政府部门了解舆情, 及时掌握事件发展动态。
本文也存在一定的研究局限, 实验虽然使用知乎问答社区的客观话题数据进行预测, 但是所采集的话题量有限, 样本数据集中在单一话题板块, 样本量还需提高和完善。未来研究可以深入话题内容, 结合知乎不同话题板块的特性, 全面丰富评价指标, 进一步验证该模型的有效性, 并提高实验结果的准确性, 为在网络问答社区中识别新兴话题提供有力基础。
程秀峰: 提出研究思路, 设计研究方法, 论文最终版本修订;
张心怡: 模型构建, 实验分析, 撰写论文;
王宁: 采集、清洗和分析数据。
所有作者声明不存在利益冲突关系。
[1] 王宁. Tree1_xlsx. 通过“知乎”采集、处理的构建决策树Tree1的话题数据.
[2] 王宁. Tree2_xlsx. 通过“知乎”采集并进行计算筛选的构建决策树Tree2的话题数据.
[3] 王宁. Data3_xlsx. 通过“知乎”采集、处理并用于判断决策树预测准确率的话题数据.
| [1] |
Tapping on the Potential of Q&A Community by Recommending Answer Providers [C]// |
| [2] |
在线社交网络中的新兴话题检测技术综述 [J].
新兴话题检测是社交网络研究的热点问题之一。在线社交网络特别是微博的开放性,给话题的流行和爆发提供了前所未有的便利条件。新兴话题是即将流行或爆发的话题,往往伴随着重大的事件或新闻的发生,会产生重大的社会影响,如何在早期识别此类话题,是新兴话题检测研究的主要内容。该文回顾了近年来在新兴话题检测方面的主要进展,分析了新兴话题检测领域面临的挑战,阐述了相关的概念、方法和理论,重点从内容突发特征和信息传播模型两个方面对影响新兴话题检测的方法进行了分析和讨论,并对新兴话题检测的前景做了展望。<br/>
Emerging Topic Detection in Online Social Networks: A Survey [J].
新兴话题检测是社交网络研究的热点问题之一。在线社交网络特别是微博的开放性,给话题的流行和爆发提供了前所未有的便利条件。新兴话题是即将流行或爆发的话题,往往伴随着重大的事件或新闻的发生,会产生重大的社会影响,如何在早期识别此类话题,是新兴话题检测研究的主要内容。该文回顾了近年来在新兴话题检测方面的主要进展,分析了新兴话题检测领域面临的挑战,阐述了相关的概念、方法和理论,重点从内容突发特征和信息传播模型两个方面对影响新兴话题检测的方法进行了分析和讨论,并对新兴话题检测的前景做了展望。<br/>
|
| [3] |
|
| [4] |
Building Fast Decision Trees from Large Training Sets [J].https://doi.org/10.3233/IDA-2012-0542 URL [本文引用: 1] 摘要
ABSTRACT Decision trees are commonly used in supervised classification. Currently, supervised classification problems with large training sets are very common, however many supervised classifiers cannot handle this amount of data. There are some decision tree induction algorithms that are capable to process large training sets, however almost all of them have memory restrictions because they need to keep in main memory the whole training set, or a big amount of it. Moreover, algorithms that do not have memory restrictions have to choose a subset of the training set, needing extra time for this selection; or they require to specify the values for some parameters that could be very difficult to determine by the user. In this paper, we present a new fast heuristic for building decision trees from large training sets, which overcomes some of the restrictions of the state of the art algorithms, using all the instances of the training set without storing all of them in main memory. Experimental results show that our algorithm is faster than the most recent algorithms for building decision trees from large training sets.
|
| [5] |
基于LDA和SNA的在线新闻热点识别研究 [J].https://doi.org/10.3772/j.issn.1000-0135.2016.010.002 URL [本文引用: 2] 摘要
准确识别在线新闻的热点话题,有助于政府了解社会动向、企业洞察消费需求、学者追踪研究热点。为此,提出一种基于隐含狄利克雷分布和社会网络分析的在线新闻文本热点挖掘模型。首先,借助LDA主题模型对同一时期某一领域的新闻文本进行主题词提取,形成主题词共现结构网络。然后,采用社会网络分析方法对共现网络进行分析,构造主题词语的社会网络结构图谱,进行中心性分析、核心-边缘分析和凝聚子群分析,并以"可持续发展"领域为例,对该领域的热点进行识别。最后,分别与TD-IDF和LDA的主题抽取方法对比,并结合百度指数的验证,发现本文的方法能够有效地反映词语的重要程度和分布情况,具有较强的可移植性。
Identifying Hot Topics of Online News Based on LDA and SNA [J].https://doi.org/10.3772/j.issn.1000-0135.2016.010.002 URL [本文引用: 2] 摘要
准确识别在线新闻的热点话题,有助于政府了解社会动向、企业洞察消费需求、学者追踪研究热点。为此,提出一种基于隐含狄利克雷分布和社会网络分析的在线新闻文本热点挖掘模型。首先,借助LDA主题模型对同一时期某一领域的新闻文本进行主题词提取,形成主题词共现结构网络。然后,采用社会网络分析方法对共现网络进行分析,构造主题词语的社会网络结构图谱,进行中心性分析、核心-边缘分析和凝聚子群分析,并以"可持续发展"领域为例,对该领域的热点进行识别。最后,分别与TD-IDF和LDA的主题抽取方法对比,并结合百度指数的验证,发现本文的方法能够有效地反映词语的重要程度和分布情况,具有较强的可移植性。
|
| [6] |
Learning Approaches for Detecting and Tracking News Events [J].https://doi.org/10.1109/5254.784083 URL [本文引用: 1] 摘要
The authors extend existing supervised-learning and unsupervised-clustering algorithms to allow document classification based on the information content and temporal aspects of news events. They've adapted several IR and machine learning techniques for effective event detection and tracking. The article discusses our research using manually segmented documents
|
| [7] |
利用LDA的领域新兴主题探测技术综述 [J].
以LDA为基础,系统梳理新兴主题探测以及主题趋势探测技术中的LDA以及其他LDA改进主题模型的发展现状。介绍LDA的变分推导和Gibbs抽样两种参数推导算法;总结近年来LDA模型的改进,包括对主题演化建模的主题模型、对文档内容和元数据联合建模的模型、采用在线式学习的主题模型及将LDA和引文分析相结合的主题演化方法等,并对不同的改进模型进行深入对比和分析;梳理NIH-VB、TIARA、VxInsight等几种主要的主题模型可视化技术。最后通过对LDA模型的总结分析,探讨利用LDA模型探测领域新兴主题时的关键研究问题。
Review on the LDA-Based Techniques Detection for the Field Emerging Topic [J].
以LDA为基础,系统梳理新兴主题探测以及主题趋势探测技术中的LDA以及其他LDA改进主题模型的发展现状。介绍LDA的变分推导和Gibbs抽样两种参数推导算法;总结近年来LDA模型的改进,包括对主题演化建模的主题模型、对文档内容和元数据联合建模的模型、采用在线式学习的主题模型及将LDA和引文分析相结合的主题演化方法等,并对不同的改进模型进行深入对比和分析;梳理NIH-VB、TIARA、VxInsight等几种主要的主题模型可视化技术。最后通过对LDA模型的总结分析,探讨利用LDA模型探测领域新兴主题时的关键研究问题。
|
| [8] |
Indexing by Latent Semantic Analysis [J].https://doi.org/10.1002/(ISSN)1097-4571 URL [本文引用: 1] |
| [9] |
Improving LDA Topic Models for Microblogs via Tweet Pooling and Automatic Labeling [C]// |
| [10] |
Discovering Emerging Topics in Social Streams via Link-Anomaly Detection [J].https://doi.org/10.1109/TKDE.2012.239 URL [本文引用: 1] |
| [11] |
基于时间序列分析的微博突发话题检测方法 [J].https://doi.org/10.11959/j.issn.1000-436x.2016052 URL [本文引用: 1] 摘要
针对微博信息噪音大、新颖度难以判断的问题,在动量模型的基础上进行优化,提出了基于时序分析的微博突发话题检测方法。通过动量模型提取候选突发特征后,对特征的动量时间序列分别借鉴信号频域分析理论和股票趋势分析理论进行建模,分析特征的频域特性来识别频繁伪突发特征,分析特征的新颖程度来识别间歇性伪突发特征,合并过滤后的有效突发特征形成突发话题。微博数据实验表明,该方法有效提高了突发话题检测的准确率和F值。
Bursty Topic Detection Method for Microblog Based on Time Series Analysis [J].https://doi.org/10.11959/j.issn.1000-436x.2016052 URL [本文引用: 1] 摘要
针对微博信息噪音大、新颖度难以判断的问题,在动量模型的基础上进行优化,提出了基于时序分析的微博突发话题检测方法。通过动量模型提取候选突发特征后,对特征的动量时间序列分别借鉴信号频域分析理论和股票趋势分析理论进行建模,分析特征的频域特性来识别频繁伪突发特征,分析特征的新颖程度来识别间歇性伪突发特征,合并过滤后的有效突发特征形成突发话题。微博数据实验表明,该方法有效提高了突发话题检测的准确率和F值。
|
| [12] |
基于网络问答社区的话题识别与分析——以知乎“老年人”话题为例 [J].https://doi.org/10.13266/j.issn.0252-3116.2016.05.014 URL [本文引用: 1] 摘要
[目的 /意义]针对目前基于网络的话题识别与分析方法的局限性,提出针对网络问答社区的话题识别与分析方法,为此类网站的话题识别与分析提供参考。[方法 /过程]以改进的中文分词技术为基础,构建网络问答社区的话题识别指标,通过线性加权方式计算权重,结合关键词提取方法确定话题关键词,对话题关注焦点进行提取,对分布情况进行测度。依据所提出的改进方法,以知乎网站为数据来源,从话题关键词、关键词分布以及热点子话题3个角度对"老年人"话题焦点进行识别与分析。[结果 /结论]研究表明,该方法具有科学性和可行性,不仅拓展了社会问题的分析数据源,也为"积极开展应对人口老龄化行动"提供了决策依据。
Detection and Analysis of the Topic Based on the Social Q&A Website: A Case Study of “The Elderly” on Zhihu Website [J].https://doi.org/10.13266/j.issn.0252-3116.2016.05.014 URL [本文引用: 1] 摘要
[目的 /意义]针对目前基于网络的话题识别与分析方法的局限性,提出针对网络问答社区的话题识别与分析方法,为此类网站的话题识别与分析提供参考。[方法 /过程]以改进的中文分词技术为基础,构建网络问答社区的话题识别指标,通过线性加权方式计算权重,结合关键词提取方法确定话题关键词,对话题关注焦点进行提取,对分布情况进行测度。依据所提出的改进方法,以知乎网站为数据来源,从话题关键词、关键词分布以及热点子话题3个角度对"老年人"话题焦点进行识别与分析。[结果 /结论]研究表明,该方法具有科学性和可行性,不仅拓展了社会问题的分析数据源,也为"积极开展应对人口老龄化行动"提供了决策依据。
|
| [13] |
Ensemble Methods in Data Mining: Improving Accuracy Through Combining Predictions [M]. |
| [14] |
面向大数据分析的决策树算法 [J].
决策树作为机器学习中的一个预测模型,因其输出结果易于理解和解释,而被广泛应用于各个领域,成为了学术界研究的热点。随着数据产生速度的剧增,由于内存容量和处理器速度等限制,常规的决策树算法无法对大数据集进行处理,因此需要对决策树算法的实现进行针对性的处理。首先阐述了决策树的基本算法和优化方法,在此基础上结合大数据带来的挑战,分类比较了各类针对性算法的优缺点,并介绍了支撑这些算法运行的平台。最后讨论了面向大数据的决策树算法的未来发展方向。
Decision Tree Algorithms for Big Data Analysis [J].
决策树作为机器学习中的一个预测模型,因其输出结果易于理解和解释,而被广泛应用于各个领域,成为了学术界研究的热点。随着数据产生速度的剧增,由于内存容量和处理器速度等限制,常规的决策树算法无法对大数据集进行处理,因此需要对决策树算法的实现进行针对性的处理。首先阐述了决策树的基本算法和优化方法,在此基础上结合大数据带来的挑战,分类比较了各类针对性算法的优缺点,并介绍了支撑这些算法运行的平台。最后讨论了面向大数据的决策树算法的未来发展方向。
|
| [15] |
Simplifying Decision Trees [J].https://doi.org/10.1016/S0020-7373(87)80053-6 URL [本文引用: 1] |
| [16] |
Evolutionary Induction of Mixed Decision Trees [J].https://doi.org/10.4018/IJDWM URL [本文引用: 1] |
| [17] |
微博噪声过滤和话题检测 [J].https://doi.org/10.3969/j.issn.1005-8451.2015.03.005 URL [本文引用: 1] 摘要
针对微博中充斥着的大量广告信息和其它的噪声微博,本文提出了基于C4.5决策树分类算法的用户分类过滤机制和基于特征值的计分过滤方法。利用微博文本的实时性和微博话题的时效性,还提出了一个基于时间参数的相似度计算方法。实验结果表明,该方法能提高对噪声过滤和话题检测的准确率和效率。
Micro-Blog Noise Filtering and Topic Detection [J].https://doi.org/10.3969/j.issn.1005-8451.2015.03.005 URL [本文引用: 1] 摘要
针对微博中充斥着的大量广告信息和其它的噪声微博,本文提出了基于C4.5决策树分类算法的用户分类过滤机制和基于特征值的计分过滤方法。利用微博文本的实时性和微博话题的时效性,还提出了一个基于时间参数的相似度计算方法。实验结果表明,该方法能提高对噪声过滤和话题检测的准确率和效率。
|
| [18] |
基于短文本信息流的热点话题检测 [J].https://doi.org/10.16337/j.1004-9037.2015.02.026 URL [本文引用: 1] 摘要
短文本信息流在传递公开信息时携带了丰富且具有极大价值的信息资源。根据短文本信息流特点,利用训练数据集中的信息熵来构建决策树检测模型进行热点话题检测,该方法先是计算出各话题类别的平均信息量和每个特征词对于短文本信息流进行划分的信息增益率,再通过选择具有最大信息增益率的特征词进行测试,完成自上而下的决策树建树过程,最后利用叶子结点的类型确定热点话题。在真实短信文本信息流上实验表明,该方法具有明显的检测稳定性和较高的数据处理效率。
Hot Topic Detection Based on Short Text Information Flow [J].https://doi.org/10.16337/j.1004-9037.2015.02.026 URL [本文引用: 1] 摘要
短文本信息流在传递公开信息时携带了丰富且具有极大价值的信息资源。根据短文本信息流特点,利用训练数据集中的信息熵来构建决策树检测模型进行热点话题检测,该方法先是计算出各话题类别的平均信息量和每个特征词对于短文本信息流进行划分的信息增益率,再通过选择具有最大信息增益率的特征词进行测试,完成自上而下的决策树建树过程,最后利用叶子结点的类型确定热点话题。在真实短信文本信息流上实验表明,该方法具有明显的检测稳定性和较高的数据处理效率。
|
| [19] |
Indices of Novelty for Emerging Topic Detection [J].https://doi.org/10.1016/j.ipm.2011.07.006 URL [本文引用: 1] 摘要
Emerging topic detection is a vital research area for researchers and scholars interested in searching for and tracking new research trends and topics. The current methods of text mining and data mining used for this purpose focus only on the frequency of which subjects are mentioned, and ignore the novelty of the subject which is also critical, but beyond the scope of a frequency study. This work tackles this inadequacy to propose a new set of indices for emerging topic detection. They are the novelty index (NI) and the published volume index (PVI). This new set of indices is created based on time, volume, frequency and represents a resolution to provide a more precise set of prediction indices. They are then utilized to determine the detection point (DP) of new emerging topics. Following the detection point, the intersection decides the worth of a new topic. The algorithms presented in this paper can be used to decide the novelty and life span of an emerging topic in a specific field. The entire comprehensive collection of the ACM Digital Library is examined in the experiments. The application of the NI and PVI gives a promising indication of emerging topics in conferences and journals.
|
| [20] |
基于用户行为影响的微博突发话题检测方法 [J].https://doi.org/10.3969/j.issn.0253-2778.2017.04.007 URL [本文引用: 1] 摘要
考虑到微博数据存在时序性特征以及包含用户的社交网络行为特征,提出一种动量信号增强模型算法来有效地检测微博突发话题.由于传统模型未考虑微博数据变化以及用户社交行为的影响,为此首次提出影响力因子以及热度因子,用以修正动量模型.为获取影响力因子,将计算出当前时点前给定周期内的数据对当前数据的变化差值的指数累计影响作为影响力的衡量标准,以体现词频在该区间段的重要性.影响力因子将用于修正词频序列,以获取MACD值指标.由于用户的社交行为对话题产生影响巨大,进而提出热度因子用以修正MACD值指标.当模型满足指标阈值时,特征词则列为突发特征词.最后,通过K-means聚类算法将特征词进行归类合并,以获取突发话题.实验结果表明,模型精度能达到81.82%,表现良好.
Bursty Topic Detection Method for Microblog Based on Influence from User Behaviors [J].https://doi.org/10.3969/j.issn.0253-2778.2017.04.007 URL [本文引用: 1] 摘要
考虑到微博数据存在时序性特征以及包含用户的社交网络行为特征,提出一种动量信号增强模型算法来有效地检测微博突发话题.由于传统模型未考虑微博数据变化以及用户社交行为的影响,为此首次提出影响力因子以及热度因子,用以修正动量模型.为获取影响力因子,将计算出当前时点前给定周期内的数据对当前数据的变化差值的指数累计影响作为影响力的衡量标准,以体现词频在该区间段的重要性.影响力因子将用于修正词频序列,以获取MACD值指标.由于用户的社交行为对话题产生影响巨大,进而提出热度因子用以修正MACD值指标.当模型满足指标阈值时,特征词则列为突发特征词.最后,通过K-means聚类算法将特征词进行归类合并,以获取突发话题.实验结果表明,模型精度能达到81.82%,表现良好.
|
| [21] |
Early Detection Method for Emerging Topics Based on Dynamic Bayesian Networks in Micro-Blogging Networks [J].https://doi.org/10.1016/j.eswa.2016.03.050 URL [本文引用: 1] 摘要
Micro-blogging networks have become the most influential online social networks in recent years, more and more people are used to obtain and diffuse information in them. Detecting topics from a great number of tweets in micro-blogging is important for information propagation and business marketing, especially detecting emerging topics in the early period could strongly support these real-time intelligent systems, such as real-time recommendation, ad-targeting, marketing strategy. However, most of previous researches are useful to detect emerging topic on a large scale, but they are not so effective for the early detection due to less informative properties in a relatively small size. To solve this problem, we propose a new early detection method for emerging topics based on Dynamic Bayesian Networks in micro-blogging networks. We first analyze the topic diffusion process and find two main characteristics of emerging topic which areattractivenessandkey-node. Then based on this finding, we select features from the topology properties of topic diffusion, and build a DBN-based model by the conditional dependencies between features to identify the emerging keywords. An emerging keyword not only occurs in a given time period with frequency properties, but also diffuses with specific topology properties. Finally, we cluster the emerging keywords into emerging topics by the co-occurrence relations between keywords. Based on the real data of Sina micro-blogging, the experimental results demonstrate that our method is effective and capable of detecting the emerging topics one to two hours earlier than the other methods.
|
| [22] |
问答社区中回答质量的评价方法研究 [J].https://doi.org/10.3969/j.issn.1003-0077.2011.01.001 URL Magsci [本文引用: 1] 摘要
问答社区已经成为网络信息获取的一种重要渠道,但其信息质量差异较大。该文研究了问答社区中回答质量的评价方法。具体考察了百度知道的问答社区环境,并对其构建了大规模的语料数据。针对百度知道的特点,文本提出的基于时序的特征、基于问题粒度的特征和基于百度知道社区用户的特征,从更多的角度对回答质量进行评价。利用分类学习的框架,该文综合了新设计的三方面特征和经典的文本特征、链接特征,对高质量和非高质量的回答进行分类。基于大规模问答语料的实验表明,在文本特征与链接特征的基础上,基于时序与基于问题粒度的特征能够有效地提高回答质量的评估效果。另外也发现,根据该文的回答质量评价框架做出的质量评分能够有效地预测最佳答案。
Answer Quality Analysis on Community Question Answering [J].https://doi.org/10.3969/j.issn.1003-0077.2011.01.001 URL Magsci [本文引用: 1] 摘要
问答社区已经成为网络信息获取的一种重要渠道,但其信息质量差异较大。该文研究了问答社区中回答质量的评价方法。具体考察了百度知道的问答社区环境,并对其构建了大规模的语料数据。针对百度知道的特点,文本提出的基于时序的特征、基于问题粒度的特征和基于百度知道社区用户的特征,从更多的角度对回答质量进行评价。利用分类学习的框架,该文综合了新设计的三方面特征和经典的文本特征、链接特征,对高质量和非高质量的回答进行分类。基于大规模问答语料的实验表明,在文本特征与链接特征的基础上,基于时序与基于问题粒度的特征能够有效地提高回答质量的评估效果。另外也发现,根据该文的回答质量评价框架做出的质量评分能够有效地预测最佳答案。
|
| [23] |
A Study of Retrospective and Online Event Detection [C]// |
| [24] |
Expertise Networks in Online Communities: Structure and Algorithms [C]// |
| [25] |
Induction of Decision Trees [J]. |
| [26] |
C4.5: Programs for Machine Learning [M]. |
| [27] |
Data Mining: Introductory and Advanced Topics [M]. |
| [28] |
决策树分类技术研究 [J].https://doi.org/10.3969/j.issn.1000-3428.2004.09.038 URL [本文引用: 1] 摘要
决策树分类是一种重要的数据分类技术.ID3、C4.5和EC4.5是建立决策树的常用算法,但目前国内对一些新的决镱树分类算法研究较少.为此,在消化大量文献资料的基础上,研究了CART、SLIQ、SPRINT、PUBLIC等新算法,对各种决策树分类算法的基本思想进行阐述,并分析比较了各种算法的主要特性,为数据分类研究者提供借鉴.
The Study on Decision Tree Classification Techniques [J].https://doi.org/10.3969/j.issn.1000-3428.2004.09.038 URL [本文引用: 1] 摘要
决策树分类是一种重要的数据分类技术.ID3、C4.5和EC4.5是建立决策树的常用算法,但目前国内对一些新的决镱树分类算法研究较少.为此,在消化大量文献资料的基础上,研究了CART、SLIQ、SPRINT、PUBLIC等新算法,对各种决策树分类算法的基本思想进行阐述,并分析比较了各种算法的主要特性,为数据分类研究者提供借鉴.
|
| [29] |
Data Mining: Concepts and Techniques [M]. |
| [30] |
|
| [31] |
基于评论树的微博社区热门话题检测方法 [J].https://doi.org/10.3969/j.issn.1001-3695.2014.12.066 URL [本文引用: 1] 摘要
首先在分析微博文本特点的基础上设计了一种垃圾微博的过滤算法; 针对微博数据稀疏性这一问题,利用社区内部联系紧密的特性,提出了微博评论树的概念和一种话题热度评价模型.最后基于以上两点提出了一种微博社区热门话题 检测方法.真实数据集上的实验表明了过滤的必要性和所提出的微博社区热门话题检测方法的有效性.
Hot Topic Detection Method on Micro-blog Based on Comments Tree [J].https://doi.org/10.3969/j.issn.1001-3695.2014.12.066 URL [本文引用: 1] 摘要
首先在分析微博文本特点的基础上设计了一种垃圾微博的过滤算法; 针对微博数据稀疏性这一问题,利用社区内部联系紧密的特性,提出了微博评论树的概念和一种话题热度评价模型.最后基于以上两点提出了一种微博社区热门话题 检测方法.真实数据集上的实验表明了过滤的必要性和所提出的微博社区热门话题检测方法的有效性.
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}