
|
|
杨震 , 王红军, 周宇
, 王红军, 周宇
中国人民解放军电子工程学院 合肥 230037
Yang Zhen, Wang Hongjun, Zhou Yu
中图分类号: TP391
通讯作者:
收稿日期: 2017-09-6
修回日期: 2017-11-13
网络出版日期: 2018-03-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】研究一种新的聚类算法, 以改进密度峰值聚类算法无法自动计算截断距离以及需要人工参与选择聚类中心的不足。【方法】首先提出一种基于信息熵的截断距离自适应算法, 实现了DPC算法截断距离的自适应; 然后根据排序图中权值的斜率变化趋势确定拐点, 自动划分出聚类中心与非聚类中心的界限, 实现聚类中心的自动选择。【结果】通过在UCI数据集与人工数据集上的仿真实验, 对DBSCAN算法、DPC算法、DGCCD算法、ACP算法与ADPC算法进行聚类性能的比较, 结果表明ADPC算法不仅能够自动选择截断距离与聚类中心, 在准确率、标准互信息(NMI)、F-measure值等性能上也有较大的提升, 同时证明了改进算法在处理移动终端定位数据上的有效性。【局限】主要针对低维度数据集, 面对高维度数据集略显乏力, 同时未能兼顾处理大数据集时的效率问题。【结论】ADPC算法能够准确选择聚类中心和截断距离, 对于低维度、任意形状簇的处理效果良好。
关键词:
Abstract
[Objective] This paper develops a new clustering algorithm, aiming to automatically calculate the cut-off distance and select the cluster centers. [Methods] First, we proposed a new adaptive algorithm based on information entropy and the cut-off distance. Then, we extracted the cluster centers, with the help of inflection points determined by the slope trend of the weight in the sorting chart. Finally, we evaluated the performance of the ADPC algorithm to those of the DBSCAN, DPC, DGCCD, and ACP algorithms using UCI and manmade datasets. [Results] The ADPC algorithm automatically identified the cluster centers and significantly improved the precision, F-measure, normalized mutual information measurement and runtime. [Limitations] The proposed algorithm’s performance with high-dimension data as well as its efficiency to process large data sets need to be improved. [Conclusions] The proposed ADPC algorithm could effectively identify clustering centers and the cut-off distance with low-dimension or arbitrary data sets.
Keywords:
聚类是指按照研究对象的某个特征, 对其进行无监督的分类, 即无须预先设定分类标准, 根据研究对象自身的相似度差异, 使不同簇之间的研究对象具有最小相似性, 同一簇内的研究对象具有最大相似性[1]。目前, 聚类分析在反恐、市场分析[2]、信息安全[3]、舆情监控、金融和娱乐等领域都有广泛的应用。
传统的聚类方法有基于划分的K-means算法、K-medoids算法和CLARANS算法; 基于层次的BIRCH算法、CURE算法和Chameleon算法; 基于网格的STING算法、CLIQUE算法和Wave-Cluster算法; 基于模型的统计学方法和神经网络方法; 基于密度的DBSCAN算法和OPTICS算法[4]。
其中基于密度的聚类方法根据数据点的密集程度对数据集进行聚类, 其优势在于对不规则类簇聚类效果良好, 因此在空间位置点的聚类分析中应用广泛。基于密度的聚类方法中, OPTICS算法并不对数据集进行聚类, 而是为数据集生成簇次序, 反映数据集的密度分布结构, 为输入参数的设置提供参考信息, 但是OPTICS的计算是基于整个数据集的, 导致了算法扩展性较低, 算法并行化和增量化的代价较大[5], 实际应用相对较少。DBSCAN算法属于经典的基于密度的聚类算法, 应用较为广泛, 但是由于它采用全局唯一的密度参数, 导致该算法对输入参数十分敏感, 并且对非均匀密度数据集聚类的效果不太理想[6]。针对DBSCAN算法的不足, 文献[7]提出一种改进算法, 即AV-DBSCAN算法, 该算法是一种参数自适应的改进算法, 通过M-近邻有向图间接得到输入参数, 降低了人为选择参数的困难与算法对输入参数的敏感性, 某种程度上克服了DBSCAN算法输入参数难以确定的缺点, 但其依然采用全局唯一的密度参数, 对非均匀密度数据集聚类的效果改善不大。
针对上述基于密度聚类方法所存在的问题和不足, 文献[8]提出一种新的基于密度的聚类方法—— DPC算法(Density Peaks Clustering Algorithm), 与经典的密度聚类算法相比, 该算法原理简单, 仅需要一个输入参数dc, 且无需迭代, 可对各种形状的点簇进行聚类分析。但该算法不足之处在于需要经过决策图人工选取聚类中心, 这不仅增加了算法的冗余性, 而且存在人为主观的隐患。
因此, 本文针对文献[8]研究的DPC算法的不足, 提出一种改进的基于密度的自适应DPC算法—— ADPC算法(Adaptive Density Peaks Clustering Algorithm)。该算法可基于信息熵自动选择恰当的截断距离, 并根据排序图中权值的斜率变化趋势自动划分聚类中心与非聚类中心的界限, 由此实现聚类中心的自动选择, 提高算法效率和准确率。
DPC算法基于这样一个假设: 对于一个数据集, 聚类中心被一些低局部密度的数据点包围, 而且这些低局部密度的点距离其他高局部密度的点的距离都比较大, 唯一的输入参数为截断距离${{d}_{c}}$。其中${{d}_{c}}$用百分比表示, 将所有数据点两两之间的距离升序排列, ${{d}_{c}}$取这个距离集合中的某个百分比所对应的距离值。在此模型中, 对于一个待聚类的数据集$S=\left\{ {{x}_{i}} \right\}_{i=1}^{N}$, 需要计算的量有两个: 各数据点的局部密度${{\rho }_{i}}$以及各数据点与高密度点的最小距离${{\delta }_{i}}$, 其中局部密度的计算采用截断核和高斯核两种方式。
(1) 截断核
${{\rho }_{i}}=\sum\limits_{j}{\chi ({{d}_{ij}}-{{d}_{c}})}$ (1)
$\chi (x)=\left\{ _{0\ \ \ \ \ x\ge 0}^{1\ \ \ \ \ \ x0} \right.$ (2)
其中, ${{d}_{ij}}$表示数据点${{x}_{i}}$和${{x}_{j}}$之间的某种距离, ${{d}_{c}}$为用户预先指定的距离阈值(通常可取为所有数据点之间的距离升序排列后的前1%至2%)。由公式(1)和公式(2)可以看出, ${{\rho }_{i}}$表示的是以数据点${{x}_{i}}$为圆心, 以${{d}_{c}}$为半径的圆内的数据点数量(不包括圆心自身)。
(2) 高斯核
${{\rho }_{i}}=\sum\limits_{j}{{{e}^{-{{\left( \frac{{{d}_{ij}}}{{{d}_{c}}} \right)}^{2}}}}}$ (3)
观察公式(1)与公式(3), 可以发现截断核得出的为离散值, 高斯核得出的为连续值。截断核容易导致不同的数据点具有相同的局部密度值, 不利于后续的排序工作, 因此本文采用高斯核进行局部密度的计算。
${{\delta }_{i}}$为数据点$i$到具有更高局部密度的数据点$j$的最小距离, 定义如公式(4)所示。
$\underset{{{\rho }_{i}}<{{\rho }_{j}}}{\mathop{\min }}\,({{d}_{ij}})$ (4)
对具有全局最高密度的数据点$k$, ${{\delta }_{k}}$定义为数据点$k$与其余数据点之间的最大距离。
至此, 对数据集$S$中的每个数据点, 可以计算出它的局部密度${{\rho }_{i}}$以及最小距离${{\delta }_{i}}$, DPC算法将同时拥有较大的${{\rho }_{i}}$和${{\delta }_{i}}$值的数据点视为聚类中心, 并将剩余的数据点分配到距离各自最近的聚类中心所在的簇。为了区分噪声点, DPC算法定义了边界区域密度簇A中与其他簇的任意数据点的距离小于${{d}_{c}}$的数据点总数即为簇A的边界区域密度, 簇A中局部密度小于边界密度的点即为噪声点。文献[8]给出了如图1所示的决策图。
图1(a)为所有数据点的分布情况, 红色和蓝色边缘的点分别表示红、蓝两个类簇, 黑色边缘的点为噪声点。图1(b)为决策图, 横轴代表局部密度${{\rho }_{i}}$, 纵轴代表最小距离${{\delta }_{i}}$, 1号数据点和10号数据点的${{\rho }_{i}}$和${{\delta }_{i}}$均远远大于剩余点, 因此, 1号数据点被选作蓝色类簇的聚类中心, 10号数据点被选作红色类簇的聚类中心。
DPC算法存在两个方面的不足。一方面, DPC算法的输入参数${{d}_{c}}$是依靠经验值由人工选择的, Rodriguez等[8]给出的参考建议是选择所有数据点之间的距离升序排列后的前1%至2%作为截断距离${{d}_{c}}$, 但是对于不同样本数及分布结构的数据集, 这种笼统的参数选择方法产生的聚类效果往往与真实情况相去甚远[9]。以两种极端情况来看, 若${{d}_{c}}$>${{d}_{\max }}$, 则会导致数据集中所有数据点具有相同的局部密度, 从而使所有数据点聚于同一个类簇中; 若${{d}_{c}}$<${{d}_{\min }}$, 则会导致数据集中的每个数据点“自成一派”。另一方面, DPC算法是根据决策图的分布情况人为地选择聚类中心, 对于一些决策图复杂的数据集, 仅凭经验往往会造成聚类中心被多选或少选, 从而导致聚类效果的不理想[10], 可见DPC算法在选取聚类中心时没有合理的标准, 存在主观臆断的不足。
DPC算法由Rodriguez等[8]于2014年提出, 关于该算法的改进文献数量不多。其中文献[11]提出了一种基于网格的DPC改进算法——DGCCD算法。该算法通过建立网格对象集, 辅助聚类中心的人为决策, 大幅提高了算法效率, 很大程度上解决了DPC算法处理大数据集时计算速度太慢的缺点, 但是牺牲了一定的聚类精度。文献[12]基于PHA算法的思想, 提出了ACP算法, 该算法假定势能的分布具有类似年轮的特点, 通过计算各个潜在聚类中心的势能, 并为每个数据点定义一个父节点, 结合数据点自身的势能与各点至父节点的距离, 最终实现聚类中心的自动选择, 但该算法没有考虑截断距离的自适应。文献[13]则将DPC算法应用到图像检索中, 并取得了良好的效果。
综上所述, 基于DPC算法的改进多数集中于对DPC算法的某一个参数实现辅助决策或自适应, 或是将DPC算法应用于某个领域以获得更好的效果。
基于DPC算法的思想, 本文从两个方面提出性能更为优越的改进算法, 即通过信息熵的分布实现截断距离自适应的方法, 借助排序图斜率变化趋势实现聚类中心的自动选择, 并将该改进算法应用在移动终端位置数据上。
本文研究和改进的ADPC算法实质为通过截断距离的自适应和聚类中心的自动选择以实现数据集聚类。
在DPC算法中, 同时拥有较大局部密度和最小距离的数据点即为潜在的聚类中心, 考虑一个综合二者的值${{\gamma }_{i}}$, 如公式(5)所示。
${{\gamma }_{i}}\text{=}{{\rho }_{i}}{{\delta }_{i}}$ (5)
ADPC算法首先对${{\rho }_{i}}$和${{\delta }_{i}}$进行归一化处理, 然后求出各数据点的${{\gamma }_{i}}$, 将它们降序排列, ${{\gamma }_{i}}$越大的数据点越有可能是聚类中心。
为了直观地展示${{d}_{c}}$和${{\gamma }_{i}}$之间的关系, 公式(5)也可表示为公式(6)。
${{\gamma }_{i}}\text{=}{{\delta }_{i}}\sum\limits_{j}{{{e}^{-{{\left( \frac{{{d}_{ij}}}{{{d}_{c}}} \right)}^{2}}}}}$ (6)
基于${{\gamma }_{i}}$求取信息熵的最小值实现自适应截断距离, 以及求取斜率变化趋势的最大值实现聚类中心的自动选择, 是ADPC算法的研究重点。
本文提出一种基于信息熵最小化的截断距离自适应方法。信息论中将熵作为系统不确定性的度量, 熵值越大, 系统的不确定性就越强。信息熵的计算如公式(7)所示。
$H=-\sum\limits_{i=1}^{n}{{{p}_{i}}}\log {{p}_{i}}$ (7)
同样, 将熵的定义引申到本文算法中, 用$\gamma $值替代信息熵公式中的概率值, 即$\gamma $值越大, 其所对应的数据点被选作聚类中心的概率也越大。若数据集中各点具有相同的$\gamma $值, 则系统的不确定性最大, 此时确定聚类中心的难度也最高。反之, 若熵值达到最小, 则$\gamma $值的分布差异特征最为明显, 也最容易确定聚类中心。
结合公式(6)和公式(7), 本文给出截断距离${{d}_{c}}$和熵值$H$的关系式如公式(8)所示。
$H=-\sum\limits_{i=1}^{n}{({{\delta }_{i}}\sum\limits_{j}{{{e}^{-{{\left( \frac{{{d}_{ij}}}{{{d}_{c}}} \right)}^{2}}}}})}\log ({{\delta }_{i}}\sum\limits_{j}{{{e}^{-{{\left( \frac{{{d}_{ij}}}{{{d}_{c}}} \right)}^{2}}}}})$ (8)
令截断距离${{d}_{c}}$从零逐渐增大, 找到使熵值$H$达到最小值的${{d}_{c}}$, 并将它作为最优的截断距离进行下一步的聚类, 从而实现了截断距离的自适应。
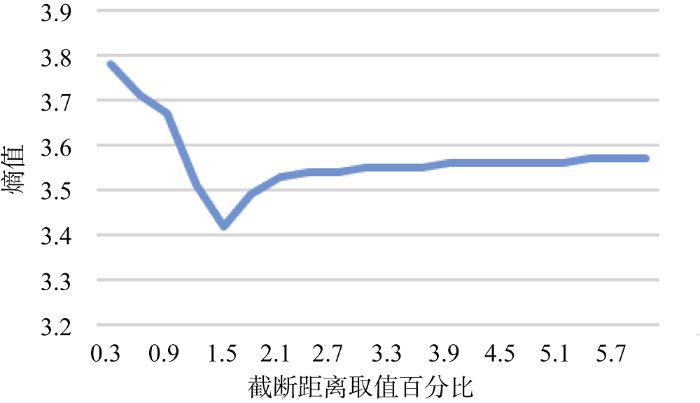
以文献[8]的数据集为例进行计算, 得到如图2所示的结果, 可以看出: 当熵值达到最小时, 截断距离的取值百分比为1.5%, 可见, 该方法可以实现截断距离的自适应。
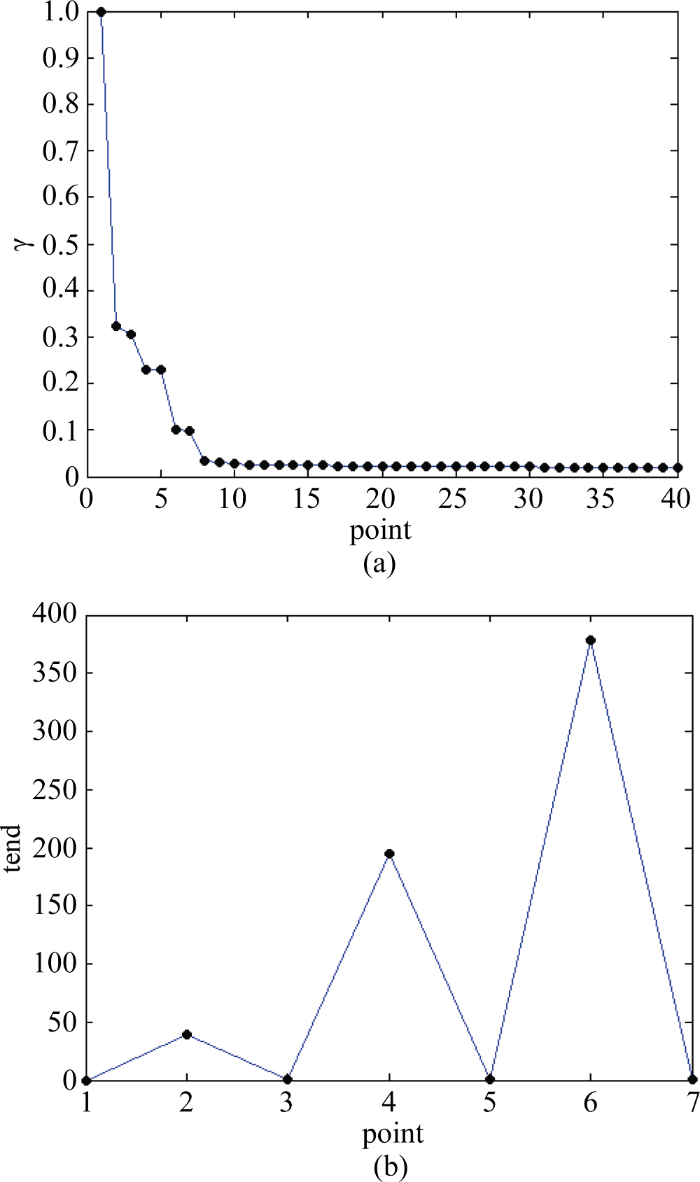
以文献[8]给出的2 000个随机样本点为例, 选取前1.5%的${{d}_{c}}$值, 并计算前40个${{\gamma }_{i}}$, 然后根据所得结果利用MATLAB生成决策图, 结果如图3(a)所示, 前5个点为实际聚类中心, 从聚类中心到第一个非聚类中心有一个陡峭的下降趋势, 因此本文用斜率的变化趋势自动选择聚类中心, 定义这个变化趋势为$ten{{d}_{i}}$, 如公式(9)所示。
$ten{{d}_{i}}=(i-1)\frac{{{\gamma }_{i-1}}-{{\gamma }_{i}}}{{{\gamma }_{i}}-{{\gamma }_{i+1}}}$ (9)
考虑到实际中可能会有类似于图3(a)中从点1到点2的斜率变化趋势, 对$ten{{d}_{i}}$引入权值$i-1$, 但随着数据点序号的增大, 权值$i-1$可能会导致$ten{{d}_{i}}$迅速增大, 从而产生错误的判断。对此, 将排序图中所有${{\gamma }_{i}}$的平均值作为阈值$\theta $以解决权值会导致$ten{{d}_{i}}$迅速增大的问题。首先从40个数据点中筛选出$\gamma $值大于阈值$\theta $的数据点, 并计算出筛选后的数据点的$tend$值, 如图3(b)所示, 经过筛选后还剩下7个数据点, 可以看到在第6个点的$tend$值最大, 因此将前5个点选为潜在聚类中心。DPC算法能很好地将${{\rho }_{i}}$很小、${{\delta }_{i}}$很大的数据点划分为离群点, 但是单单依靠${{\rho }_{i}}$与${{\delta }_{i}}$的乘积选取聚类中心可能会导致多选聚类中心: 对于${{\rho }_{i}}$很大、${{\delta }_{i}}$较小的点, 即对同一个簇内距离相近的高密度点, 可能会错误地将它们都选作聚类中心而导致簇的分裂。因此, 将根据公式(8)得到的最优${{d}_{c}}$值设为潜在聚类中心的距离阈值, 防止算法将${{\rho }_{i}}$很大、${{\delta }_{i}}$较小的点错判为聚类中心。
由此得到改进算法的具体步骤如下:
①计算各数据点归一化后的${{\rho }_{i}}$与${{\delta }_{i}}$的乘积${{\gamma }_{i}}$。
②求出使熵值最小的dc。
③对各数据点的${{\gamma }_{i}}$降序排列, 并根据数据集的总点数选定合适数量的点数按降序生成排序图。
④对${{\gamma }_{i}}$排序图中各点的$\gamma $值求平均值$\theta $, 将$\theta $作为阈值筛选出${{\gamma }_{i}}$大于$\theta $的数据点。
⑤根据斜率变化趋势公式, 求出筛选完毕的数据点的$tend$值。
⑥将$tend$值最大的数据点$i$之前的$i-1$个数据点看作潜在聚类中心。
⑦将第一个数据点作为实际聚类中心, 判断第二个数据点与它的距离是否小于距离阈值${{d}_{c}}$, 若小于, 则将第二个数据点作为非聚类中心处理, 否则, 将第二个数据点作为实际聚类中心。
⑧依次类推, 判断第$k$个潜在聚类中心与所有实际聚类中心的距离是否大于距离阈值, 再根据判断结果将其作为实际聚类中心或非聚类中心处理。
⑨根据所有选出的实际聚类中心, 对剩下的数据点完成聚类过程。
为了验证ADPC算法的效果, 在人工数据集[14,15]、UCI数据集[16]等常规测试数据集上进行测试, 首先在聚类效果图上对DBSCAN算法、DPC算法、DGCCD算法[11]、ACP算法[12]与ADPC算法进行对比; 然后在 准确率、标准互信息(NMI)、F-measure值和运行时间等参数上对比上述算法。实验环境为Windows10 64位操作系统, Intel Core i7-6700HQ @2.60GHz CPU, 8GB内存, 使用MATLAB2014a 进行仿真实验。此外, 为检验ADPC算法的普适性, 在完成常规数据集仿真的基础上, 采用GeoLife数据集[17,18,19]对移动终端定位数据进行聚类测试。测试的地图平台为百度地图。
聚类效果图的对比采用L3[14]和R15[15]两个人工数据集进行, 数据集基本参数如表1所示。
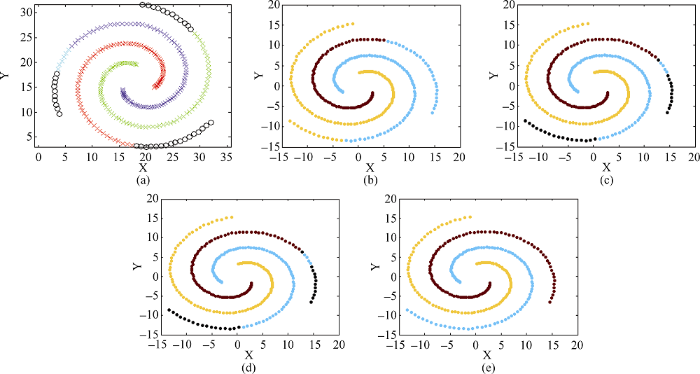
L3数据集样本数与类别数少, 因此在聚类中心的选择上难度较低; 但其呈线性环状分布, 这种特殊的分布对截断距离的选择提出更高的要求。图4依次为DBSCAN算法、DPC算法、DGCCD算法、ACP算法和ADPC算法的聚类效果图。
由图4可见, 由于L3的类别数少, 因此对上述算法来说, 在聚类中心的选择上难度不大。可以看出, 图4(a)中DBSCAN算法聚类图中产生了一系列黑色的噪声点, 图4(c)和图4(d)分别为ACP算法和DPC算法的聚类图, 同样存在和图4(a)类似的情况, 图4(b)为DGCCD算法的聚类图, 可以看到DGCCD算法虽然没有出现噪声点的情况, 但是出现了混乱的聚类结果。这些都是由于L3特殊的分布形状, 导致它对聚类算法的参数设置十分敏感, 图4(e)中ADPC算法的截断距离自适应很好地解决了参数敏感问题, 聚类效果良好。
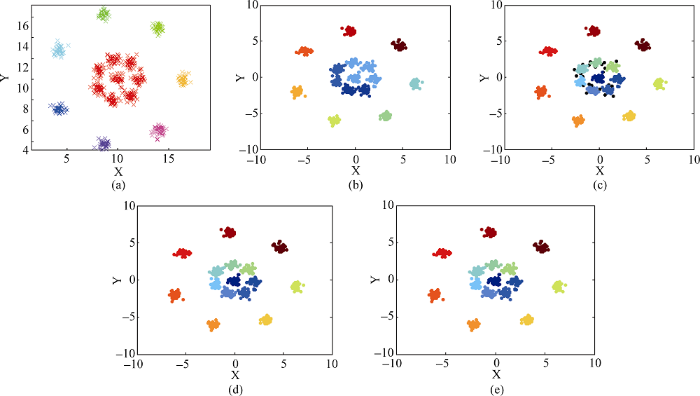
图5(a)-图5(e)依次为DBSCAN算法、DPC算法、DGCCD算法、ACP算法和ADPC算法的聚类效果图。R15数据集由中间紧密相连的8个类簇以及周围环绕的7个类簇组成, 外部的7个类簇间距较大, 相对而言容易聚类, 但其中间的8个类簇距离太近, 在采用传统DPC算法聚类时由于主观性的原因, 容易对决策图上的聚类中心产生误判, 导致将各簇混为一簇处理的聚类。图5(a)和图5(b)分别为DBSCAN算法和DPC算法聚类图, 均为少选聚类中心的情况; 图5(c)、图5(d)和图5(e)的算法中都加入了聚类中心自动选择的改进, 因此都准确选择了聚类中心的个数。其中图5(c)为DGCCD算法聚类图, 该方法为了大幅提高运行速度, 牺牲了一定的聚类精度, 因此聚类图中存在少许黑色噪声点。图5(d)和图5(e)所表示的ACP算法与ADPC算法对R15数据集的聚类效果良好。
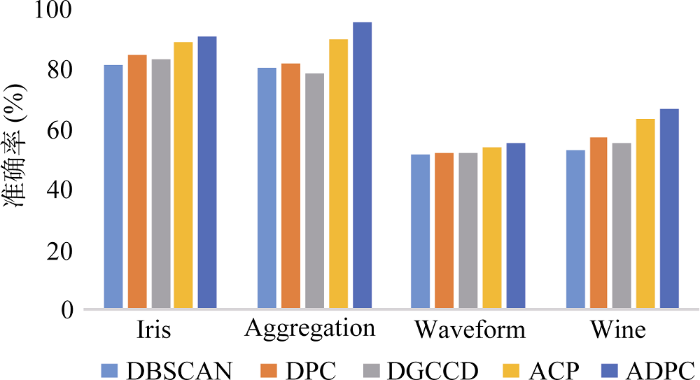
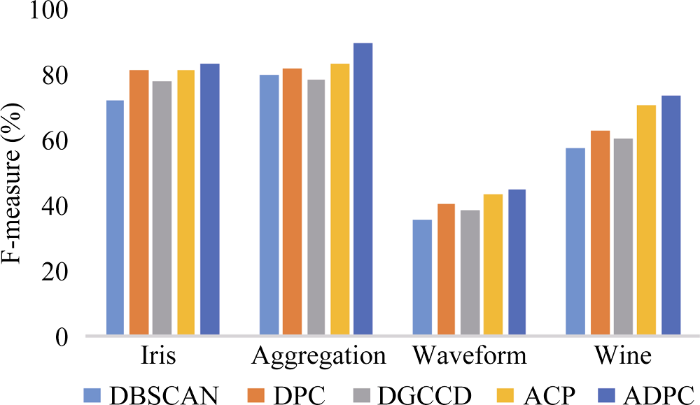
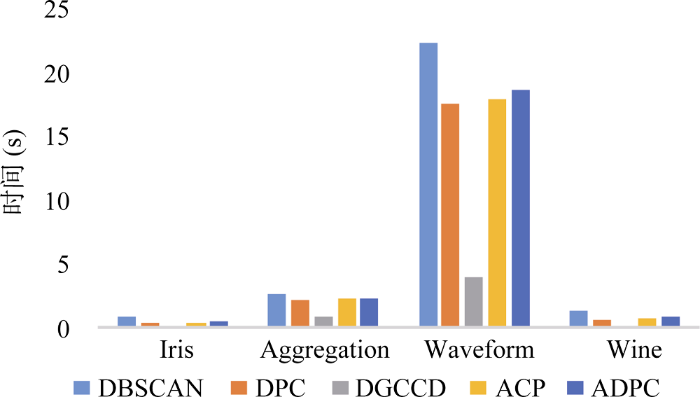
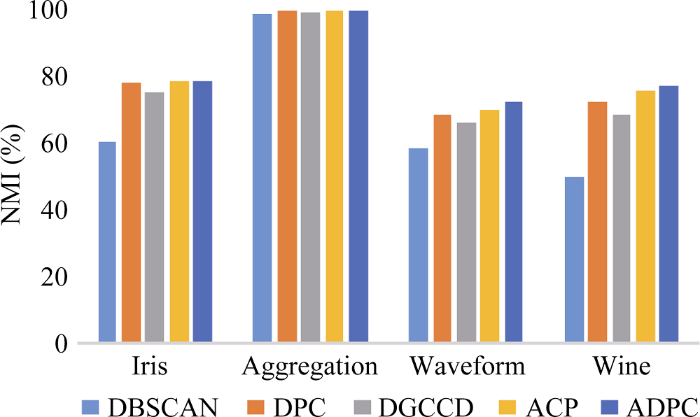
本实验采用UCI数据集, 在聚类准确率、标准互信息、F-measure值以及算法运行时间上对DBSCAN算法、DGCCD算法、DPC算法、ACP算法以及ADPC算法这5种算法进行对比, 数据集信息如表2所示。
将${{P}_{j}}$设为已知的人工标注过的簇, ${{C}_{i}}$为经过聚类后的簇。
(1) 准确率
$P({{P}_{j}},{{C}_{i}})=\frac{|{{P}_{j}}\ \bigcap {{C}_{i}}|}{|{{C}_{i}}|}$ (10)
(2) 召回率
$R({{P}_{j}},{{C}_{i}})=\frac{|{{P}_{j}}\ \bigcap {{C}_{i}}|}{|{{P}_{j}}|}$ (11)
(3) F-measure
$F({{P}_{j}},{{C}_{i}})=\frac{2\cdot P({{P}_{j}},{{C}_{i}})\cdot R({{P}_{j}},{{C}_{i}})}{P({{P}_{j}},{{C}_{i}})+R({{P}_{j}},{{C}_{i}})}$ (12)
(4) 标准互信息
$NMI({{P}_{j}},{{C}_{i}})=\frac{I({{P}_{j}},{{C}_{i}})}{\sqrt{H({{P}_{j}})H({{C}_{i}})}}$ (13)
其中准确率和召回率是信息检索、人工智能和搜索引擎的设计中很重要的几个概念和指标, F-measure是准确率和召回率的加权调和平均, 常用于评价分类、聚类模型的好坏。互信息是信息论中一种有用的信息度量, 它可以看成是一个随机变量中包含的关于另一个随机变量的信息量, 通常用互信息作为特征词和类别之间的测度。这4种参数的值均介于0到1之间, 越接近1表示聚类效果越好。实验结果如图6至图9所示。
从图6至图9可以看出, 在算法准确率、F-measure值以及标准互信息上, 整体呈现出ADPC>ACP> DPC>DGCCD>DBSCAN的趋势, DBSCAN算法作为早期的经典密度聚类算法, 一直被广泛使用, 这也说明了DPC算法在很大程度上已经超越了该经典算法。另外, DGCCD算法以牺牲少许聚类精度为代价, 换来运行效率上的大幅提升, 从图8可以看出, 该算法的运行时间显著短于其他算法, 因此在面对大数据集时该算法较有优势。ACP算法加入了基于势能的聚类中心自动选择, 性能优于DPC算法。本文提出的ADPC算法同时兼顾了聚类中心与截断距离的自适应, 仿真结果在5种算法中最为优越, 但是其运行时间还是略高于其他算法, 如何在提升聚类性能的同时兼顾效率, 将是下一步研究的重点。
近年来, 随着智能移动终端的普及, 其记录下的海量数据已成为目前研究分析的热点, 尤其移动终端记录的定位数据不仅能够真实地反映出用户的日常生活而且可以挖掘和推测用户的兴趣爱好和下一步行动。聚类分析则是智能移动终端位置信息数据挖掘中常用的分析方法之一。
为验证所研究的聚类算法的普适性, 本文采用GeoLife数据集进行仿真测试。GeoLife数据集是由微软亚洲研究院在2007年-2012年这5年间对182名用户的移动终端采集得到的, 该数据集的数据点连续性强、采样率高, 较为准确地展示了用户的移动轨迹。
本文采用GeoLife数据集中4号用户三天内的定位点, 以百度地图为平台, 测试ADPC算法对真实定位数据点的聚类效果。
图10(a)为4号用户三天内的原始位置点, 共有794个, 图10(b)为对图10(a)进行基于速度的剪枝处理, 筛除掉行进中的无意义点, 剩余473个位置点, 接着用ADPC算法对它们进行聚类, 总共有紫色、桃红色、青色、绿色及蓝色5个类簇, 黑色的X代表未被滤除的噪声点。
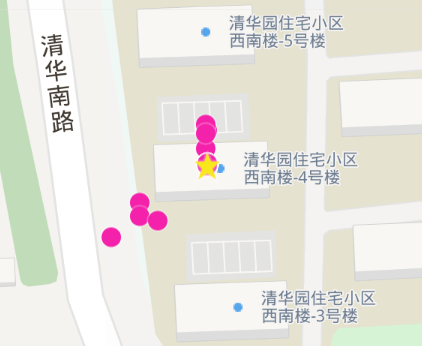
图11黄色五角星图标代表该类簇的聚类中心。数据点主要集中在清华园住宅小区西南楼-4号楼附近, 说明这栋楼是该用户常去的地点之一, 因此初步推断这栋楼可能是该用户的住宅。
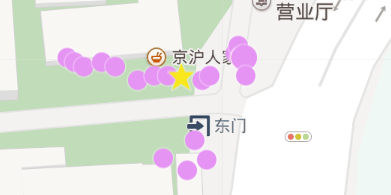
如图12所示, 数据点主要集中在京沪人家饭店附近, 因此初步推断该用户经常在此饭店用餐。
如图13所示, 数据点主要集中在圆明园地铁站附近, 因此初步推断该用户经常通过该站乘坐地铁出行。
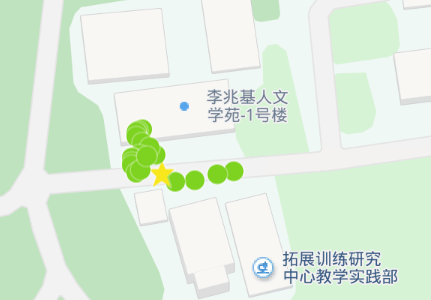
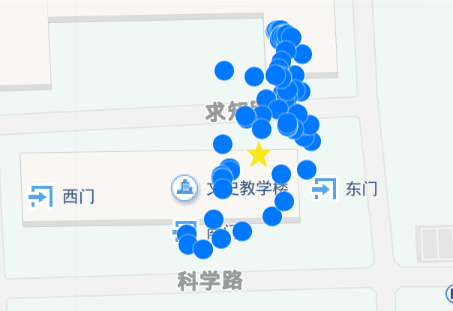
如图14和图15所示, 数据点主要集中在人文学苑与文史教学楼附近, 因此初步推断该用户经常来此上课或教学。
结合上述分析, 可以粗略推断出该用户的特征: 该用户居住在清华园住宅小区西南楼-4号楼, 常在京沪人家餐厅用餐, 经常在圆明园站乘坐地铁出行, 职业可能是人文学苑的老师或学生。
综上所述, ADPC算法对移动终端定位数据具有较好的聚类效果, 能够有效发现用户常去的兴趣点以及筛选掉用户定位轨迹中不具有特殊意义的噪声点, 为进一步挖掘用户的兴趣爱好等信息提供良好的条件。
针对基于密度的DPC算法需要依靠经验输入截断距离以及人工选择聚类中心的不足, 本文提出一种基于信息熵的参数自适应方法, 以及基于斜率变化趋势的聚类中心自动选择方法, 可以克服人工选择依靠主观经验所带来的隐患, 提高了算法的准确率和F-measure值等参数。仿真实验首先在人工数据集上采用直观的聚类效果图对DBSCAN算法、DPC算法、DGCCD算法、ACP算法以及ADPC算法进行对比, 然后在UCI数据集上通过准确率、标准互信息、F-measure值以及运行时间等参数对上述4种算法与ACP算法进行对比。从仿真结果可以看出, ADPC算法性能优于其他算法, 说明ADPC算法能够准确选择聚类中心和截断距离, 对于低维度、任意形状簇的处理效果良好。但是ADPC算法的运行时间略长于DPC算法及ACP算法, 如何在提升性能的同时兼顾效率将是下一步研究的重点。最后用GeoLife数据集测试了聚类算法对移动终端数据的普适性, 结果表明ADPC算法处理此类数据集时也具有较好的性能。
杨震: 提出研究思路, 采集分析数据;
杨震, 王红军: 进行实验, 起草并修改论文;
杨震, 王红军, 周宇: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: eei_yz@163.com。
[1] 杨震. 数据集.rar. UCI数据集及Geo-life数据集.
[2] 杨震. 算法.rar. UPC算法及ADPC算法.
| [1] |
Approximate Distributed K-Means Clustering over a Peer-to-Peer Network [J].https://doi.org/10.1109/TKDE.2008.222 URL [本文引用: 1] 摘要
Data intensive peer-to-peer (P2P) networks are finding increasing number of applications. Data mining in such P2P environments is a natural extension. However, common monolithic data mining architectures do not fit well in such environments since they typically require centralizing the distributed data which is usually not practical in a large P2P network. Distributed data mining algorithms that avoid large-scale synchronization or data centralization offer an alternate choice. This paper considers the distributed K-means clustering problem where the data and computing resources are distributed over a large P2P network. It offers two algorithms which produce an approximation of the result produced by the standard centralized K-means clustering algorithm. The first is designed to operate in a dynamic P2P network that can produce clusterings by ldquolocalrdquo synchronization only. The second algorithm uses uniformly sampled peers and provides analytical guarantees regarding the accuracy of clustering on a P2P network. Empirical results show that both the algorithms demonstrate good performance compared to their centralized counterparts at the modest communication cost.
|
| [2] |
The Research on Media Audience Market Segmentation Based on Cluster Analysis [J].https://doi.org/10.4028/www.scientific.net/AMR.219-220.84 URL [本文引用: 1] 摘要
This paper is based on the theories of consumer market segmentation. With the use of Cluster Analysis and regarding the characters of media market, the article also analyzes the Index System of Audience Structure. With the help of SPSS statistical analysis software, we will set a new analysis system about media audience structure, which has multiple indicators. In addition, there is one specific case about classification and structure of the television audience.
|
| [3] |
|
| [4] |
|
| [5] |
一种基于网格与加权信息熵的OPTICS改进算法 [J].https://doi.org/10.3969/j.issn.1000-3428.2017.02.034 URL [本文引用: 1] 摘要
针对现有OPTICS算法时间复杂度高且不适用于数据密集型环境的问题,提出一种基于网格与加权信息熵的改进算法。将数据集合划分为一定数量的网格单元,引入加权信息熵,自适应计算每个网格单元的最小密度阈值。对满足最小密度阈值的网格单元定义密集格的概念,利用质心点代替网格数据点集的方法对数据点进行压缩。采用Geolife Trajectories数据集对算法性能进行测试,从理论分析和实验结果两方面证明了改进算法的有效性。
An Improved OPTICS Algorithm Based on Grid and Weighted Information Entropy [J].https://doi.org/10.3969/j.issn.1000-3428.2017.02.034 URL [本文引用: 1] 摘要
针对现有OPTICS算法时间复杂度高且不适用于数据密集型环境的问题,提出一种基于网格与加权信息熵的改进算法。将数据集合划分为一定数量的网格单元,引入加权信息熵,自适应计算每个网格单元的最小密度阈值。对满足最小密度阈值的网格单元定义密集格的概念,利用质心点代替网格数据点集的方法对数据点进行压缩。采用Geolife Trajectories数据集对算法性能进行测试,从理论分析和实验结果两方面证明了改进算法的有效性。
|
| [6] |
一种改进的DBSCAN聚类算法 [J].
提出一种改进的DBscan聚类算法.该算法的改进基于以下两点:(1)针对DBscan算法核心点随机选取导致计算量大的缺点,提出选取距离最远且在ε距离内点的个数大于Minpts的点为核心点的方法;(2)针对DBscan算法由于ε和Minpts参数全局唯一性导致聚类质量差的缺点,提出二次聚类的方法,即计算被误判的噪声点到各个族中心的距离,把该噪声点归入距离最近的族.同时,算法采用轮廓系数来衡量算法的聚类质量.实验结果表明该算法相比原始的DBscan聚类算法具有更好的执行效率和聚类质量.
An Improved DBSCAN Clustering Algorithm [J].
提出一种改进的DBscan聚类算法.该算法的改进基于以下两点:(1)针对DBscan算法核心点随机选取导致计算量大的缺点,提出选取距离最远且在ε距离内点的个数大于Minpts的点为核心点的方法;(2)针对DBscan算法由于ε和Minpts参数全局唯一性导致聚类质量差的缺点,提出二次聚类的方法,即计算被误判的噪声点到各个族中心的距离,把该噪声点归入距离最近的族.同时,算法采用轮廓系数来衡量算法的聚类质量.实验结果表明该算法相比原始的DBscan聚类算法具有更好的执行效率和聚类质量.
|
| [7] |
基于DBSCAN的自适应非均匀密度聚类算法研究 [D].Research on Adaptive Varied Density Clustering Algorithm Based on DBSCAN [D]. |
| [8] |
Clustering by Fast Search and Find of Density Peaks [J].https://doi.org/10.1126/science.1242072 URL [本文引用: 9] |
| [9] |
一种改进的搜索密度峰值的聚类算法 [J].https://doi.org/10.11992/tis.201512036 URL [本文引用: 1] 摘要
聚类是大数据分析与数据挖掘的基础问题。刊登在2014年《Science》杂志上的文章《Clustering by fast search and find of density peaks》提出一种快速搜索密度峰值的聚类算法,算法简单实用,但聚类结果依赖于参数dc的经验选择。论文提出一种改进的搜索密度峰值的聚类算法,引入密度估计熵自适应优化算法参数。对比实验结果表明,改进方法不仅可以较好地解决原算法的参数人为确定的不足,而且具有相对更好的聚类性能。
An Improved Clustering Algorithm That Searches and Finds Density Peaks [J].https://doi.org/10.11992/tis.201512036 URL [本文引用: 1] 摘要
聚类是大数据分析与数据挖掘的基础问题。刊登在2014年《Science》杂志上的文章《Clustering by fast search and find of density peaks》提出一种快速搜索密度峰值的聚类算法,算法简单实用,但聚类结果依赖于参数dc的经验选择。论文提出一种改进的搜索密度峰值的聚类算法,引入密度估计熵自适应优化算法参数。对比实验结果表明,改进方法不仅可以较好地解决原算法的参数人为确定的不足,而且具有相对更好的聚类性能。
|
| [10] |
自动确定聚类中心的密度峰聚类 [J].https://doi.org/10.3778/j.issn.1673-9418.1510049 URL Magsci [本文引用: 1] 摘要
密度峰聚类是一种新的基于密度的聚类算法,该算法不需要预先指定聚类数目,能够发现非球形簇。针对密度峰聚类算法需要人工确定聚类中心的缺陷,提出了一种自动确定聚类中心的密度峰聚类算法。首先,计算每个数据点的局部密度和该点到具有更高密度数据点的最短距离;其次,根据排序图自动确定聚类中心;最后,将剩下的每个数据点分配到比其密度更高且距其最近的数据点所属的类别,并根据边界密度识别噪声点,得到聚类结果。将新算法与原密度峰算法进行对比,在人工数据集和UCI数据集上的实验表明,新算法不仅能够自动确定聚类中心,而且具有更高的准确率。
Density Peaks Clustering by Automatic Determination of Cluster Centers [J].https://doi.org/10.3778/j.issn.1673-9418.1510049 URL Magsci [本文引用: 1] 摘要
密度峰聚类是一种新的基于密度的聚类算法,该算法不需要预先指定聚类数目,能够发现非球形簇。针对密度峰聚类算法需要人工确定聚类中心的缺陷,提出了一种自动确定聚类中心的密度峰聚类算法。首先,计算每个数据点的局部密度和该点到具有更高密度数据点的最短距离;其次,根据排序图自动确定聚类中心;最后,将剩下的每个数据点分配到比其密度更高且距其最近的数据点所属的类别,并根据边界密度识别噪声点,得到聚类结果。将新算法与原密度峰算法进行对比,在人工数据集和UCI数据集上的实验表明,新算法不仅能够自动确定聚类中心,而且具有更高的准确率。
|
| [11] |
一种基于密度和网格的簇心可确定聚类算法 [J].
以网格化数据集来减少聚类过程中的计算复杂度,提出一种基于密度和网格的簇心可确定聚类算法.首先网格化数据集空间,以落在单位网格对象里的数据点数表示该网格对象的密度值,以该网格到更高密度网格对象的最近距离作为该网格的距离值;然后根据簇心网格对象同时拥有较高的密度和较大的距离值的特征,确定簇心网格对象,再通过一种基于密度的划分方式完成聚类;最后,在多个数据集上对所提出算法与一些现有聚类算法进行聚类准确性与执行时间的对比实验,验证了所提出算法具有较高的聚类准确性和较快的执行速度.
A Density-based and Grid-based Cluster Centers Determination Clustering Algorithm [J].
以网格化数据集来减少聚类过程中的计算复杂度,提出一种基于密度和网格的簇心可确定聚类算法.首先网格化数据集空间,以落在单位网格对象里的数据点数表示该网格对象的密度值,以该网格到更高密度网格对象的最近距离作为该网格的距离值;然后根据簇心网格对象同时拥有较高的密度和较大的距离值的特征,确定簇心网格对象,再通过一种基于密度的划分方式完成聚类;最后,在多个数据集上对所提出算法与一些现有聚类算法进行聚类准确性与执行时间的对比实验,验证了所提出算法具有较高的聚类准确性和较快的执行速度.
|
| [12] |
自动确定聚类中心的势能聚类算法 [J].
本发明公开了一种自动确定聚类中心的势能聚类算法,主要解决基于势能的快速层次聚类算法(PHA)需人为设置聚类数目,且其分配机制仅依据距离大小,削弱了势能影响这两个缺陷。该方法首先求出每个数据点的势能,将各数据点势能从小到大排列起来,然后找到每个数据点的父节点并计算数据点到父节点的距离,接着计算各点的γi值,根据各点的γi值,在一维空间中使用K62means算法对数据点进行聚类(K恒为2),选取数据点少的一类作为聚类中心集。确定聚类中心后,每个聚类中心各代表一类,将剩余数据点归入势能比其小且与其距离最近的样本所在类簇。本发明不仅能够自动确定聚类数目,而且具有更高的准确率,实用性更强。
Potential Clustering by Automatic Determination of Cluster Center [J].
本发明公开了一种自动确定聚类中心的势能聚类算法,主要解决基于势能的快速层次聚类算法(PHA)需人为设置聚类数目,且其分配机制仅依据距离大小,削弱了势能影响这两个缺陷。该方法首先求出每个数据点的势能,将各数据点势能从小到大排列起来,然后找到每个数据点的父节点并计算数据点到父节点的距离,接着计算各点的γi值,根据各点的γi值,在一维空间中使用K62means算法对数据点进行聚类(K恒为2),选取数据点少的一类作为聚类中心集。确定聚类中心后,每个聚类中心各代表一类,将剩余数据点归入势能比其小且与其距离最近的样本所在类簇。本发明不仅能够自动确定聚类数目,而且具有更高的准确率,实用性更强。
|
| [13] |
快速搜索密度峰值聚类在图像检索中的应用 [J].Application of Fast Search Density Peak Clustering in Image Retrieval [J]. |
| [14] |
Robust Path-based Spectral Clustering [J].https://doi.org/10.1016/j.patcog.2007.04.010 URL [本文引用: 2] |
| [15] |
A Maximum Variance Cluster Algorithm [J].https://doi.org/10.1109/TPAMI.2002.1033218 URL [本文引用: 2] 摘要
We present a partitional cluster algorithm that minimizes the sum-of-squared-error criterion while imposing a hard constraint on the cluster variance. Conceptually, hypothesized clusters act in parallel and cooperate with their neighboring clusters in order to minimize the criterion and to satisfy the variance constraint. In order to enable the demarcation of the cluster neighborhood without crucial parameters, we introduce the notion of foreign cluster samples. Finally, we demonstrate a new method for cluster tendency assessment based on varying the variance constraint parameter
|
| [16] |
UCI Machine Learning Repository [EB/OL]. [ |
| [17] |
|
| [18] |
|
| [19] |
GeoLife: A Collaborative Social Networking Service among User, Location and Trajectory [J].
People travel in the real world and leave their location history in a form of trajectories. These trajectories do not only connect locations in the physical world but also bridge the gap between people and locations. This paper introduces a social networking service, called GeoLife, which aims to understand trajectories, locations and users, and mine the correlation between users and locations in terms of user-generated GPS trajectories. GeoLife offers three key applications scenarios: 1) sharing life experiences based on GPS trajectories; 2) generic travel recommendations, e.g., the top interesting locations, travel sequences among locations and travel experts in a given region; and 3) personalized friend and location recommendation.
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}