
|
|
刘东苏, 霍辰辉
西安电子科技大学经济与管理学院 西安 710071
Liu Dongsu, Huo Chenhui
中图分类号: N99 TP391
通讯作者:
收稿日期: 2017-10-13
修回日期: 2017-11-17
网络出版日期: 2018-03-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】基于LSH算法将图像匹配应用到图像推荐模型中, 与传统推荐模型结合, 提高推荐结果准确度。【方法】提取图像SIFT特征作为图像匹配标准, 改进基于p-Stable Distribution的LSH算法, 实现高维度下大量图片的搜索匹配, 最后融合现有协同过滤算法提出ICF-LSH推荐算法构建融合推荐模型, 并采用Python语言予以实现。【结果】使用不同的数据集对本文提出的算法进行验证, 实验表明改进的LSH算法对召回率和错误率都有一定的优化, 通过匹配耗时和Hash表长度可知该算法优化了内存利用和搜索匹配效率。由融合推荐模型的平均绝对误差MAE和精确度Precision可知, 相对传统的协同过滤推荐算法, 本文提出的ICF-LSH推荐算法提高了推荐结果的精准度。【局限】在提取图像特征时仅使用SIFT特征, 后续研究中可以尝试使用多种图像特征作为匹配依据, 提高匹配结果的可靠性。【结论】图像匹配算法基于LSH进行了一定改进, 提高了图像相似度匹配的效率, 此外, 本文提出的融合推荐模型能显著提升推荐效果。
关键词:
Abstract
[Objective] This paper developed an image recommendation model based on feature matching technique and the LSH algorithm, aiming to improve the accuracy of recommendations. [Methods] First, we extracted the image’s SIFT features as the matching criteria. Then, we modified the LSH algorithm to retrieve images in high dimensional settings. Finally, we proposed an ICF-LSH algorithm based on the collaborative filtering techniques to build fusion recommendation model. [Results] We examined the proposed algorithm with various datasets and achieved better recall and precision rates for image recommendation. [Limitations] Only used the SIFT feature to extract image features. More research is needed to explore other matching features. [Conclusions] The proposed model improves the performance of image matching and recommendation systems.
Keywords:
推荐系统是一项类似于搜索引擎的信息过滤技术, 系统根据物品的描述信息和用户的历史行为习惯, 建立推荐模型, 通过该模型可以对用户没有接触过的物品进行评分预测, 然后经过评分的排序过滤, 最终给用户推荐最高预测评分的若干个物品[1]。在推荐模型中, 核心部分为推荐算法。目前, 主流研究的推荐算法均采用商品内容的文本特征, 基于内容的推荐主要考虑商品内容信息, 协同过滤推荐主要考虑相似项目或者相似用户的购买行为信息。实际应用中, 电商网站的商品信息不仅包含文本信息也包含大量的商品图片信息, 同时, 用户对在线商品的关注点也更多地从文本描述转为视觉图像特征。相比文本, 图像数据通常提供了更为丰富的有关产品属性的相关信息。例如, 在电子商务平台上, 对于一件服装, 商家通常会配合产品基本信息展示多张图像, 以直观的方式向消费者展示商品的颜色、形状、纹理、样式、以及穿着效果等信息, 其中有些信息单纯凭借文本并不能充分有效表达, 因此利用商品信息中的图像信息具有重要意义。
以往由于技术发展的局限性, 除了文本数据和用户行为数据, 图像数据的作用很少在推荐系统相关文献中被提及。然而, 伴随着计算机计算能力的不断提升, 计算机视觉领域的研究取得了突破性进展[2,3], 从海量非结构化图像数据中提取有价值的信息得以实现。
本文结合计算机图像处理领域的研究成果, 将基于尺度不变特征变换(Scale Invariant Feature Transform, SIFT)算法提取的图像特征作为推荐依据引入到商品推荐模型中, 并改进局部敏感哈希(Locality Sensitive Hashing, LSH)算法用于大量商品图像的搜索匹配, 完善现有推荐模型的工作流程, 构建基于图像匹配和改进LSH算法的推荐模型, 提出ICF-LSH融合推荐算法, 从而优化推荐效果, 并通过实验验证了改进的LSH算法和ICF-LSH算法的有效性。
推荐模型中使用的推荐算法主要有三种: 基于内容的推荐算法、协同过滤推荐算法和混合推荐算法[4]。基于内容的推荐根据商品内容信息进行推荐, 考虑的主要是商品自身属性、商品详情信息等, 通过这些文本来发现商品的关键描述特性, 从而将用户浏览历史相似度较高的商品推荐给特定用户。协同过滤推荐主要根据相似用户的购买行为进行推荐, 依赖的是最近邻用户的意见。当需要对特定用户进行推荐时, 通过检索与该用户有相似兴趣的近邻用户的购买记录和具体评价信息来推荐商品。混合推荐是将基于内容推荐与协同过滤推荐进行结合完成推荐, 一定程度解决了单一推荐引起的冷启动、稀疏性、局限性等问题。de Campos等[5]、Melville等[6]表明, 使用混合算法进行推荐比单一算法准确率更高。
混合推荐算法虽然解决了一些单一算法产生的问题, 但还存在不足之处:
(1) 推荐源单一。目前电商网站的商品信息不仅包含文本描述信息也含有大量的图像内容, 用户对在线商品的关注点也更多地从文本描述转为视觉图像特征。
(2) 用户对推荐结果的需求越来越个性化, 推荐算法需要更充分地挖掘用户接触的信息。
(3) 用户希望可以通过浏览图片就能得到感兴趣商品或者相似商品的信息, 希望能够通过图片检索即能获取商品详情和购买链接。
基于以上不足, He等[7]利用商品的图像数据和已有的训练好的深度神经网络模型进行潜在因子的学习, 由于考虑了商品本身的内容信息, 因此一定程度解决了商品冷启动问题。苏栋梁[8]将图像相似性和近邻用户的推荐结合到一起, 采用视觉词汇树对图像特征进行降维处理, 提出融合图像相似性和协同过滤的个性化推荐算法。朱鹏新[9]研究基于图像内容商品检索系统, 并用LDA主题模型对商品进行分类, 完成不同种类的推荐(基于图像内容的电商物品检索与推荐系统研究)。目前应用图像检索技术的网站有网上购物商城Amazon①(①https://www.amazon.com.)、基于图像内容检索的产品比较与购物网站Empora②(②http://www.empora.com.)、Google图像搜索软件Google Goggles③(③http://www.google.com/mobile/goggles/#logo.)等。但是这些系统处理的图像特征比较局限, 通常对一些不易受视觉场景变化影响并且具有文字特征的商品如书籍、CD、商标等具有较好的查询效果。对于更一般性的易受视觉场景变化影响, 甚至容易发生变形的物体还没有很好的检索精度。
本文在图像匹配和相似性检索方面主要应用了LSH(局部敏感哈希)算法, 其基本思想是在空间中距离较近的数据点会映射到相同的哈希值上, 而距离较远的数据点映射到相同哈希值的概率很低。这样就可以对查询点的近邻与远邻进行区分, 从而快速找出近邻[10,11,12]。在对LSH算法的研究方面, 曹玉东等[13]结合半监督机器学习技术改进LSH算法, 基于改进的 LSH算法构建垃圾图像特征库索引, 提高了图像型垃圾邮件的过滤速度。龚卫国等[14]为实现图像间的快速准确配准, 在LSH算法基础上, 根据随机选择的若干子向量构建哈希索引结构, 以缩减构建索引数据的维数和搜索的范围, 从而缩短建立索引的时间, 提出一种高效的高维特征向量检索算法——改进的LSH (ELSH)算法用以图像特征间的检索配对, 从而实现图像间的配准。
通过以上分析, 基于图像的检索和推荐在商品推荐系统中具有重要价值。本文结合计算机图像处理领域的研究成果, 将基于SIFT特征的图像匹配引入到商品推荐模型中, 改进基于p-Stable Distribution的LSH算法, 用于大量商品图像的搜索匹配, 构建基于图像匹配和改进LSH算法的推荐模型, 提出ICF-LSH融合推荐算法, 提升推荐准确度。
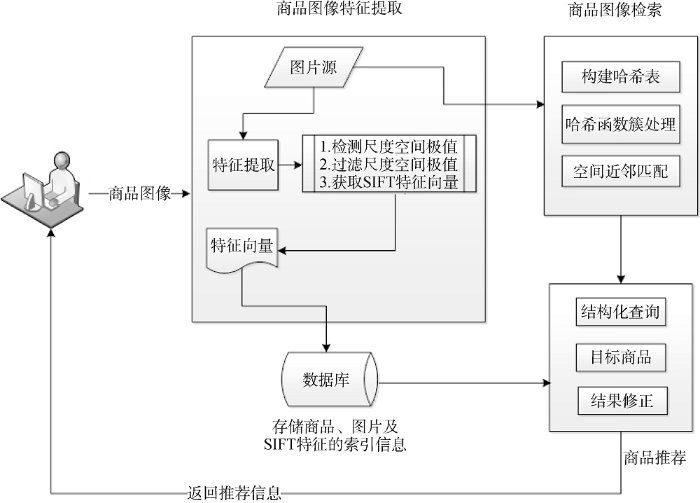
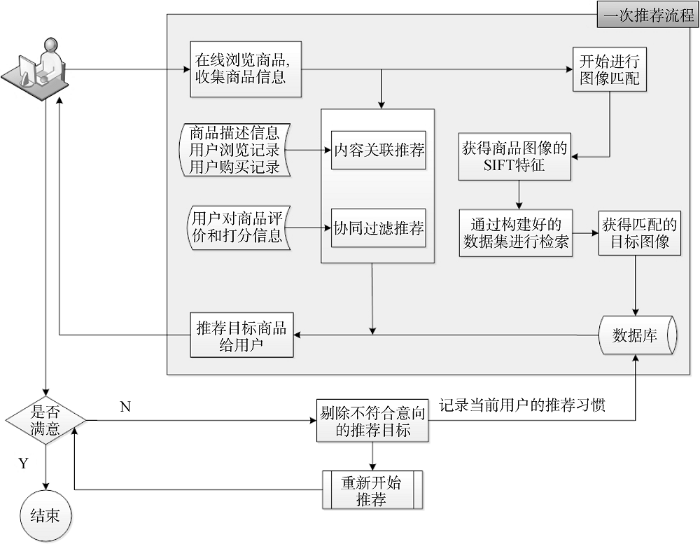
本文推荐模型构建分为三个步骤: 图像特征提取与线性匹配; 高维空间下大量图像的快速、准确搜索匹配, 采用基于p-Stable Distribution的LSH算法完成; 结合现有的商品推荐系统, 构建融合图像特征和现有推荐算法的推荐模型。
商品图像特征提取中, 关键内容为提取图像的SIFT特征值。商品图像搜索中, 为避免线性匹配的方法带来的匹配时间随数据集的增长而线性增长的问题, 使用基于p-Stable Distribution的LSH算法进行相似搜索。为避免拥有相同数据指纹的数据向量被映射到同一个Hash Bucket中, 使用训练数据集构建预定义的Hash Table, 在进行匹配时从中取出每一个节点元素的所有Hash Bucket, 得到目标图片的特征向量落入的Bucket中的Key Point索引, 之后寻找到与其匹配度较高的图片。推荐模型构建中, 使用匹配的图片信息作为依据, 通过对数据库的结构化查询将图片所对应的商品推荐给用户。本文具体研究流程如图1所示。
图像匹配是图像处理中的热点和难点, 也是关键技术问题之所在。随着现代信息技术的不断发展和推进, 该技术已被广泛应用在目标识别与追踪、计算机视觉和图像分析等领域。目前主要的匹配方法大致分为两类: 灰度匹配和特征匹配。灰度匹配计算量较大, 在对实时性结果要求较高的系统中不太适用。图像特征匹配的研究中常用的几种图像内容特征主要是PHOG 特征、CEDD 特征、SIFT 特征等[15], 其中SIFT特征在图像特征匹配[16]、图像拼接[17]、识别[18,19,20]、检索等方面有大量应用。
Lowe[21]提出了一种高效的图像局部特征描述算法——SIFT, 即提取关键点并计算其特征向量。SIFT算子对应的是图像的局部特征描述, 对图像发生的各类变化, 例如图像视角的旋转、图像本身的放大或缩小、光照发生变化等, SIFT特征都会保持不变, 具有良好的稳定性[15]。在实际应用环境中, 图像的拍摄会受到光照、拍摄角度、后期制作以及拍摄设备等诸多外界因素的影响, 图像的颜色、亮度和饱和度都会发生很大的变化, 使得提取出的图像特征差异很大, 因此在提取图像特征的过程中选取合适的图像特征非常重要[22]。鉴于SIFT特征的稳定性, 本文提取的图像特征主要为SIFT特征。
在对目标图像进行分析并提取图像的SIFT特征之后, 需要将其与图像库中已经保存的图像的SIFT特征进行相似度匹配[15]。当需要匹配的图片量较少时, 可以采用线性匹配方法。首先提取目标图像的关键特征点, 用特征向量表示, 之后使用欧氏距离作为匹配标准。在欧几里得空间中, 点$x~=({{x}_{1}},\cdots ,{{x}_{n}})$和$y=({{y}_{1}},\cdots ,{{y}_{n}})$之间的欧氏距离如公式(1)所示。
$\begin{align} & d(x,y)=\sqrt{{{({{x}_{1}}-{{y}_{1}})}^{2}}+{{({{x}_{2}}-{{y}_{2}})}^{2}}+\cdots +{{({{x}_{n}}-{{y}_{n}})}^{2}}} \\ & \ \ \ \ \ \ \ \ \ \ =\sqrt{\sum\limits_{i=1}^{n}{{{({{x}_{i}}-{{y}_{i}})}^{2}}}} \\ \end{align}$(1)
目标图片的特征点描述因子是一组$n$维向量, 因此可以最终计算得到的欧氏距离是一组长度为$n$的数组, $n$维向量的每一维欧氏距离可以使用NumPy内置的算法linalg给出。
本文对两张样例图片的特征进行匹配识别, 默认选取100个关键点进行匹配, 匹配算法使用KNN, 以多维空间中向量的欧式距离作为特征点、是否相似作为匹配依据, 最终结果由Python提供的matplotlib库进行可视化输出, 如图2所示。
样例图片的拍照角度和光照条件有很大区别, 由于SIFT特征能很好地均衡这些客观因素, 在进行特征匹配时, 提取到的特征点在多维空间中能被准确地标记出来, 因此给出的匹配结果比较准确, 样例图片中的文字和袋鼠图形均能很准确地被标记成相似特征。
但是在推荐系统的构建和电子商务网站中, 并不能简单地对图片组进行两两配对, 因此需要完善图像搜索匹配算法, 避免这种线性匹配带来的长耗时。
进行目标商品推荐时, 大量的商品图片信息将以多维特征向量的形式存放在训练数据集中, 若使用线性匹配的方法将输入图像与数据集中所有的图像进行特征匹配, 匹配时间会随数据集的增长而线性增长。在进行图像匹配时, 需要考虑效率和准确性, 保证推荐系统能在较短时间内得出相似度较高的目标图像[23]。
为解决线性匹配效率低的问题, Indyk[24]提出了局部敏感哈希算法(LSH), 核心思想是设计一种特殊的Hash函数, 使得两个相似度很高的数据以较高的概率映射成同一个Hash值, 而相似度很低的数据会以极低的概率映射成同一个Hash值。
最常见多维欧几里得空间采用欧氏距离进行度量, LSH的局部采样一般是基于海明距离的, 比较不同Hash值的海明距离作为相似度衡量依据, 为避免将欧式距离映射到海明空间再进行距离比较, Datar等[25]提出基于p-Stable Distribution的LSH算法来进行欧几里得空间的相似搜索, 利用p-Stable分布可以有效地近似处理高维特征向量, 并在保证度量距离的同时, 对高维特征向量进行降维。
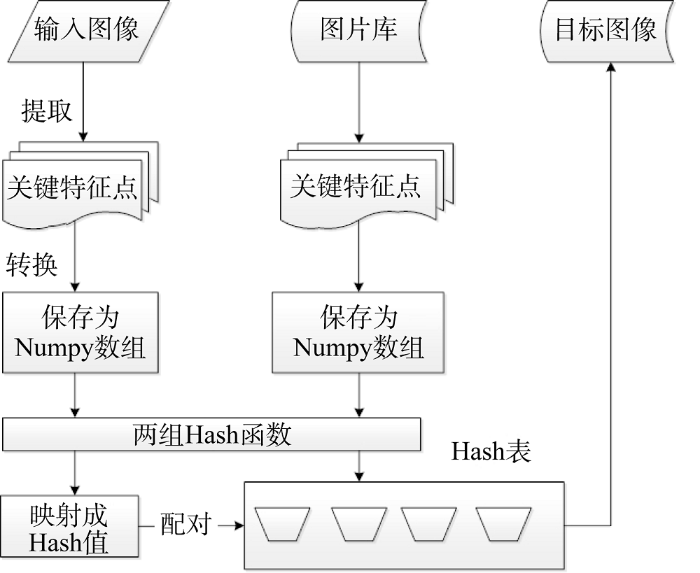
在提取了商品图片的特征向量之后, 分别得到最邻近匹配对和次邻近匹配对, 计算两组匹配对的欧氏距离, 将其与匹配阈值进行对比, 在阈值之内的即可认为是可以匹配的目标。大量图像搜索匹配模型的主要工作原理如图3所示。
(1) 建立数据索引关系
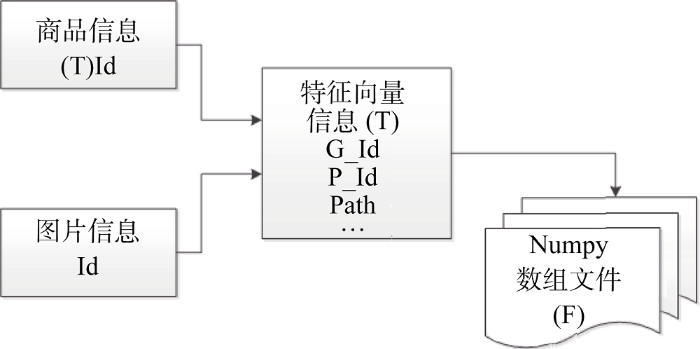
使用特定的图片集合, 将所有图片的描述因子分别计算出来, 将基本信息存入数据库中; 将描述因子转换成特征向量并使用Numpy数组格式保存为磁盘文件, 并将这些特征向量数组作为数据集, 在这个过程中使用商品Id、图片Id和关键点Id建立索引关系, 便于从数据库中以特征向量查找商品信息。
数据集的基本结构如图4所示, 其中T表示数据表, F表示磁盘文件。数据集通过关系型数据库建立了商品信息和图像特征之间的索引关系, 匹配算法通过推荐样本的图像特征给出符合预期的目标图像特征, 即图4中的Numpy数组标识, 之后通过结构化查询就可以取得推荐的目标商品。
(2) 获取推荐样本
加入另一件商品, 首先计算得到商品图片信息的特征向量, 通过Hash函数将其转换成一组特定的Hash值。
记${{h}_{a,b}}(v):{{R}_{d}}\to N$为一个$d$维特征向量$v$到一个整数集的Hash值映射。哈希函数中有两个随机变量$a$和$b$, 其中$a$为一个$d$维向量, 每一维是一个独立选择满足p-Stable分布的随机变量, $b$为$[0,w]$范围内的随机数, $w$是多维空间坐标系的直线分段长度, 对于一个固定的$a$, $b$, 则哈希函数定义为公式(2)[10]。
${{h}_{a,b}}(v)=[\frac{a\cdot v+b}{w}]$ (2)
对于一个随机选取的Hash函数${{h}_{a,b}}(v)$, 定义$c=\left| \left| {{v}_{1}}-{{v}_{2}} \right| \right|p$, ${{f}_{p}}(t)$为p-Stable分布的概率密度函数的绝对值, 那么特征向量${{v}_{1}}$和${{v}_{2}}$映射到一个随机向量$a$上的距离是$\left| a\cdot {{v}_{1}}-a\cdot {{v}_{2}} \right|<w$, 即$|({{v}_{1}}-{{v}_{2}})\cdot a|<w$, 根据p-Stable分布的特性, $\left| \left| {{v}_{1}}-{{v}_{2}} \right| \right|pX=\left| cX \right|<w$, 其中随机变量$X$满足p-Stable分布。
可得其碰撞概率$p(c)$计算方法如公式(3)[26]所示。
$P(c)=P{{r}_{(a,b)}}[{{h}_{a,b}}({{v}_{1}})={{h}_{a,b}}({{v}_{2}})]=\int_{\ 0}^{\ w}{\frac{1}{c}}{{f}_{p}}(\frac{t}{c})(1-\frac{t}{w})dt$ (3)
这个碰撞概率就是向量v1, v2落在同一个Hash桶内的概率。通过公式(3)计算空间中两个特征向量落在同一分段线段上的概率, 作为样本图像与目标图像的近似度的衡量依据。
(3) 搜索与特征匹配
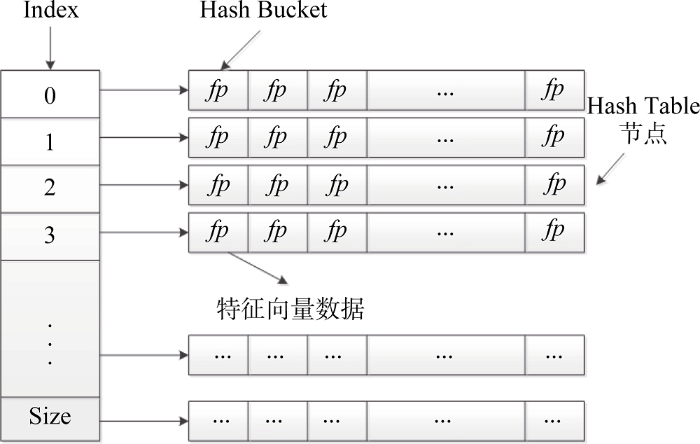
根据给定的图像特征进行搜索匹配的关键步骤是构建一个Hash表, 用于存储所有特征向量到Hash值数集的映射。为了提高匹配结果的准确性, 减少错误率, 需要设计多个Hash函数对特征向量进行计算, 得到向量的多组Hash值, 在数据集中匹配并选取任一对等的Hash值, 即可作为匹配目标。这种做法虽然降低了错误率, 但是还存在不足之处, 并不能解决误报问题, 同时将一组Hash函数计算的Hash值数组作为Hash Bucket的标识也存在问题, 不仅算法的空间复杂度高, 而且在进行实际查询时非常耗时, 造成效率低的问题。
为了解决上述问题, 本文设计两个Hash函数${{H}_{1}}$和${{H}_{2}}$, 如公式(4)和公式(5)所示。
${{H}_{1}}{{Z}_{k}}\to \{0,1,2,\cdots ,size-1\}$ (4)
${{H}_{2}}{{Z}_{k}}\to \{0,1,2,\cdots ,C\}$, $C$是一个大素数 (5)
函数${{H}_{1}}$将一个$k$个数组成的整数向量${{Z}_{k}}$映射到Hash Table的某一个位置上, 其中$size$是Hash Table的长度; 函数${{H}_{2}}$将一组Hash值进行合并处理得到特定的标识。这两个函数具体的算法如公式(6)和公式(7)所示, 其中, ${{r}_{i}}$, ${{{r}'}_{i}}$是两个随机整数, $tableSize$表示Hash Table的长度。
${{h}_{1}}({{a}_{1}},{{a}_{2}},\cdots ,{{a}_{k}})=((\sum\limits_{i=1}^{k}{{{r}_{i}}{{a}_{i}}})modC)mod tableSize$ (6)
${{h}_{2}}({{a}_{1}},{{a}_{2}},\cdots ,{{a}_{k}})=(\sum\limits_{i=1}^{k}{{{{{r}'}}_{i}}{{a}_{i}}})modC$ (7)
将${{H}_{2}}$计算的结果称为一个数据向量的“指纹”, 该值是由数据向量的$k$个Hash值计算得到的, 而${{H}_{1}}$相当于数据向量的指纹在Hash Table中的索引, 通过这两个值可以快速定位数据向量在Hash Table中的位置。
使用这两个函数, Hash Table可以通过以下步骤构建:
①从设计好的Hash函数族中, 随机选取$L$组Hash函数, 每组由$k$个构成, 记为$\{{{g}_{1}}(\cdot ),{{g}_{2}}(\cdot ),\cdots ,{{g}_{L}}(\cdot )\}$, 其中${{g}_{i}}(\cdot )=({{h}_{1}}(\cdot ),{{h}_{2}}(\cdot ),\cdots ,{{h}_{k}}(\cdot ))$;
②每个数据向量经过${{g}_{i}}(\cdot )$被映射成一个整型向量, 记为$({{x}_{1}},\cdots ,{{x}_{k}})~$;
③将步骤②生成的$({{x}_{1}},\cdots ,{{x}_{k}})~$通过${{H}_{1}}$、${{H}_{2}}$计算得到两个数值: $index$和$fp$, 前者是Hash Table的索引, 后者是数据向量对应的Hash指纹。若其中有数据向量拥有相同的数据指纹, 则必然会被映射到同一个Hash Bucket中, 如图5所示。
最终, 需要一些训练数据集来构建预定义的Hash Table, 在进行匹配时从中取出每一个节点元素的所有Hash Bucket, 得到目标图片的特征向量落入的Bucket中的Key Point索引, 之后寻找到与其匹配度较高的图片, 将图片所对应的商品推荐给用户。
(1) 推荐模型结构图
构建图像特征匹配的推荐模型的工作流程如下:
①收集图片数据集和对应的商品信息, 提取SIFT特征并构建数据索引;
②构建数据集的Hash表;
③引入推荐样本图片, 根据图片搜索匹配算法得到目标图片;
④进行结构化查询, 将目标图片对应的商品信息推荐给用户。
现有的商品推荐系统推荐算法分析结果是基础依据, 在此基础上加入图像匹配推荐部分, 整体结构模型如图6所示。
推荐模型的关键部分是将基于内容推荐算法或协同过滤推荐算法与本文改进的图像特征搜索匹配算法进行融合, 完成推荐过程。本文的融合策略中主要采用的传统推荐算法为基于项目的协同过滤推荐算法(Item-based Collaborative Filtering, ICF), 与本文改进的LSH算法融合后, 提出融合推荐算法, 并将该算法命名为ICF-LSH融合推荐算法。
(2) ICF-LSH融合推荐算法
假设$S(Im)$是基于项目的协同过滤推荐集合, $S(Pn)$是基于图像相似性匹配的推荐集合, $S(Un)$是与图像对应的商品项目集合。根据数据集计算得到项目集合的个数, 设定$\left| S(Im) \right|=m$,$S(Pn)=\text{ }S(Un)=n$, 定义融合权重因子$\partial $如公式(8)所示。
$\partial =\frac{m}{m+n}$ (8)
根据ICF算法, 可以将用户$u$对商品$j$的兴趣定义为公式(9)。
${{R}_{uj}}=\sum\limits_{i\in N(u),j\in S(i,K)}{{{w}_{ji}}{{r}_{ui}}}$ (9)
其中, $N(u)$是用户$u$感兴趣的商品集合, $S(i,K)$是与物品$j$最相似的$K$个项目集合, ${{w}_{ji}}$是物品$j$和$i$的相似度, ${{r}_{ui}}$是用户$u$对物品$i$的兴趣, ${{w}_{ji}}$由公式(10)给出。
${{w}_{ji}}=\frac{|N(i)\ \bigcap N(j)|}{\sqrt{|N(i)\bigcup N(j)|}}$ (10)
其中, $N(i)$表示对物品$i$感兴趣的用户数, $N(j)$表示对物品$j$感兴趣的用户数。在加入图像相似性度量标准之后, 本文提出ICF-LSH融合推荐算法, 该算法将用户对物品的兴趣定义为公式(11), 其中$\overline{{{R}_{j}}}$是所有用户对该商品的平均兴趣评分。
$U{{R}_{uj}}=\partial \times {{R}_{uj}}+(1-\partial )\times \overline{{{R}_{j}}}\times \left( \sum\limits_{i\in N(u),j\in S(i,K)}{\frac{1}{\sqrt{1+{{({{h}_{j}}-{{h}_{i}})}^{2}}}}} \right)$ (11)
本文采用的数据集为: MIR-Flickr的25K子集缩略图[27]和使用Python语言在Amazon网站爬取的服装商品信息。MIR-Flickr 25K子集图片分辨率为64*64, 肉眼识别度很低。服装信息数据集包括商品评价、商品描述、商品图片及推荐目标商品等6 058条有效信息, 其中用户评分数值从1到5, 用户对不同商品的评分表示对该商品的兴趣程度。每件商品包含一张图片, 并且包含网站给出的10个最优推荐结果。首先使用MIR-Flickr图片数据集验证改进的图像匹配算法的准确性和效率, 之后使用爬取的服装商品数据集作为实验数据, 将单独使用ICF算法的推荐结果和ICF-LSH融合推荐算法的推荐结果进行对比。
(1) 主要参数指标
本文提出的图像匹配算法的关键衡量指标主要由以下几方面构成: 结果精度、匹配速度和空间要求。结果精度通常使用召回率和错误率作为衡量指标。假定$q$是输入的图像, $I(q)$是符合匹配特征的结果数量, $A(q)$是实际得到的结果数量, 那么召回率$Recall$可定义为公式(12)。
$Recall=\frac{|A(q)\bigcap I(q)|}{|I(q)|}$ (12)
理想情况下, 召回率的值为1, 表明返回的结果完全符合匹配特征。此外, 错误率也是一个衡量匹配结果精度的指标, 假定取$K$个目标结果, 则错误率$Error Ratio$定义为公式(13)。
$Error Ratio=\frac{1}{|Q|K}\sum\limits_{q\in Q}{\sum\limits_{k=1}^{K}{\frac{_{\mathop{d}_{\mathop{LSH}_{k}}}}{d_{k}^{*}}}}$ (13)
其中, $Q$表示图像集合, ${{d}_{LS{{H}_{k}}}}$是一个Hash函数返回的第$k$个最匹配的结果, $\mathop{d}_{k}^{*}$是目标真正匹配的结果, $Error Ratio$体现的是Hash函数计算的结果与目标结果之间的差异。绝对理想的状况下错误率是0, 说明通过Hash函数计算的匹配结果与目标匹配结果完全一致。
匹配速度和空间要求分别使用一次匹配推荐耗时和Hash表长度作为衡量依据。本次实验$w$取值为0.7, $C$取值为${{2}^{32}}-5$, $K$取值为20。
(2) 模型算法验证分析
实验结果数据在Windows系统生成, 硬件环境为双核CPU主频2.5GHz, L2缓存大小为3MB, 8GB RAM和512GB(7200RPM)机械硬盘。分别取2 000, 4 000, 6 000, 8 000张图片作为训练数据集, 得到的部分数据如表1所示。
表1 训练结果数据
| 数据集大小 | 召回率 | 错误率 | 匹配耗时(s) | Hash表长度 |
|---|---|---|---|---|
| 2 000 | 0.82 | 1.421 | 0.042 | 12 |
| 4 000 | 0.90 | 1.337 | 0.069 | 19 |
| 6 000 | 0.93 | 1.223 | 0.085 | 34 |
| 8 000 | 0.96 | 1.069 | 0.126 | 47 |
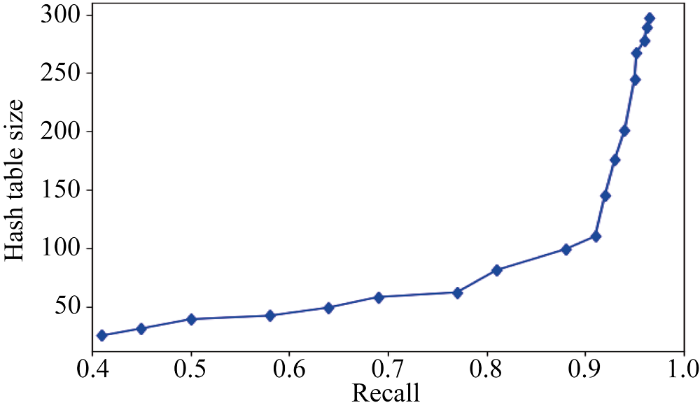
表1中Hash表是实验过程中衡量内存消耗的主要指标, 该表过大时会导致一次匹配耗时延长, 同时也会降低系统性能。通过多次对样本匹配的结果分析, 输出Hash表长度与召回率之间的关系如图7所示。
分析表1和图7, 通过召回率、错误率等指标, 得知该推荐算法匹配结果正确性较高, 通过匹配耗时指标结果得知, 该推荐算法运算速度较快, 通过匹配耗时和Hash表长度指标以及Hash表长度与召回率关系曲线得知, 随着数据集增大和匹配结果不断优化、提升, 匹配耗时会增加, 同时内存占用会急剧提升。
假设不引入Hash函数${{H}_{1}}$和${{H}_{2}}$, 仅使用公式(2)给出的Hash函数构建Hash表, 引入同样的数据集得到的部分结果如表2所示。
表2 不引入H1和H2的训练结果数据
| 数据集大小 | 召回率 | 错误率 | 匹配耗时(s) | Hash表长度 |
|---|---|---|---|---|
| 2 000 | 0.41 | 5.913 | 0.142 | 25 |
| 4 000 | 0.50 | 5.673 | 0.278 | 39 |
| 6 000 | 0.64 | 4.825 | 0.455 | 49 |
| 8 000 | 0.77 | 4.546 | 0.724 | 61 |
通过多次分析样本匹配的结果, 输出Hash表长度与召回率之间的关系如图8所示。
对比并分析表1、表2和图7、图8得知: 本文提出的改进LSH算法, 引入不同的Hash函数, 可以对图片搜索匹配效果进行优化, 并降低实际匹配过程中的内存消耗, 同时, 也能很好地提升图片搜索匹配结果的准确度, 降低耗时。
(1) 主要参数指标
对于推荐结果的质量评价指标主要有: 平均绝对误差、均方根误差、精确度、结果覆盖率等, 本文主要选取平均绝对误差MAE(Mean Absolute Error)和精确度Precision作为评价依据。
设商品集合为$\{{{i}_{1}},{{i}_{2}},\cdots ,{{i}_{N}}\}$, 用户对实际商品的评分集合为$\{{{r}_{1}},{{r}_{2}},\cdots ,{{r}_{N}}\}$, 使用兴趣定义公式(11)得到的评分集合为$\{{{p}_{1}},{{p}_{2}},\cdots ,{{p}_{N}}\}$, MAE的计算如公式(14)所示。
$MAE=\frac{\sum\limits_{i=1}^{N}{|{{p}_{i}}-{{r}_{i}}|}}{N}$ (14)
设T=|{r1, r2, …, rN}|, 表示数据集中评分数目总数, $R=\left| \left\{ {{r}_{i}}:{{r}_{i}}\in T,\text{ }{{r}_{i}}={{p}_{i}} \right\} \right|$, 表示预测评分与实际评分相等的商品总数, Precision的计算如公式(15)所示。
$Precision=\frac{|R|}{|T|}$ (15)
本次实验$\partial $分别取1和0.6用于计算单独使用ICF和使用融合算法的$U{{R}_{uj}}$值, $K$取值为10, 其他参数与前文保持一致。
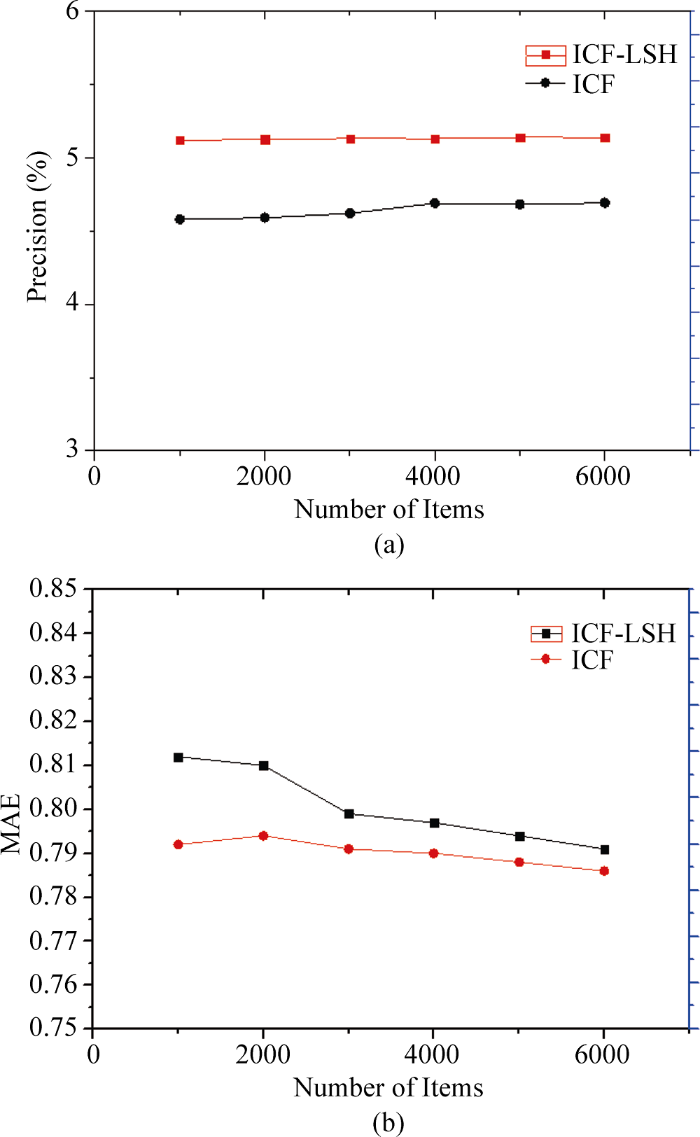
(2) 推荐质量对比分析
将服装信息数据集使用ICF算法和ICF-LSH融合推荐算法分别进行分析, 结果如图9所示。ICF-LSH融合推荐算法比单独使用ICF算法得到更高的推荐精度, 并且随着项目数量(Number of Items)的增加而增大。在平均绝对误差值(MAE)上, ICF-LSH融合推荐算法也要低于使用ICF算法的结果, 并且随着项目数量的增加而有所减小。因此本文提出的融入商品图像特征信息的ICF-LSH融合算法能够优化推荐效果。
本实验结果印证了协同过滤算法虽然被证实为当前推荐系统领域表现较好的算法之一, 但是由于现实环境中的数据集稀疏等问题, 导致推荐效果远没有达到理想状况。而采用的CIF-LSH算法, 引入商品图片特征信息, 推荐效果得到显著提升。
推荐系统主要以商品文本内容信息或用户行为特征作为推荐标准, 但是, 有些信息单纯凭借文本并不能进行充分表达, 因此, 提取商品图像特征并将其作为推荐依据具有重要意义。
本文的主要成果和创新之处在于改进了基于p-Stable Distribution的LSH算法, 并结合协同过滤算法提出ICF-LSH推荐算法, 加入商品图片特征信息作为推荐依据, 优化推荐结果。使用SIFT算法提取图像特征, 改进LSH算法, 引入不同的Hash函数, 实现了对搜索模型的优化, 并降低实际匹配过程中的内存消耗, 同时降低了推荐耗时。将改进的LSH算法与协同过滤算法进行融合, 提出ICF-LSH算法, 并通过实验证明了该算法的正确性和有效性。
本文仅使用SIFT特征作为图像相似的衡量标准, 但图像特征还有其他类型如CURF特征等, 因此, 未来需要加入更多的图像特征提高图像搜索匹配和推荐结果准确度。此外, 目前只考虑将商品图像信息与协同过滤进行融合, 后续研究可以加入商品文本内容信息进行综合建模并进行推荐。
刘东苏: 修订论文, 论文结构修订;
霍辰辉: 设计并实现算法, 分析实验结果, 起草论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: huochenhui1008@163.com。
[1] 刘东苏, 霍辰辉. mirflickr25k.zip. MIR-Flickr的25K缩略图.
[2] 刘东苏, 霍辰辉. Amazon.xlsx. 服装商品信息.
| [1] |
基于深度学习的协同过滤模型研究 [D].A Study on Collaborative Filtering Model Based on Deep Learning [D]. |
| [2] |
ImageNet Classification with Deep Convolutional Neural Networks [C]// |
| [3] |
Deep Learning [J].https://doi.org/10.1038/nature14539 URL [本文引用: 1] |
| [4] |
一种基于信任的协同过滤推荐模型 [J].https://doi.org/10.3778/j.issn.1002-8331.1507-0016 URL Magsci [本文引用: 1] 摘要
传统的协同过滤推荐技术主要基于用户-项目评价数据集进行挖掘推荐,没有有效地利用用户通信上下文信息,从而制约其进一步提高推荐的精确性。针对传统协同过滤推荐算法存在的推荐精度不高的弊端,在协同过滤算法中融入通信上下文信息,引入了通信信任、相似信任和传递信任三个信任度,并提出了一种基于信任的协同过滤推荐模型。通过公开数据集验证测试,证明提出的推荐算法较传统的协同过滤推荐技术在推荐准确性上有较大提高。
Collaborative Filtering Recommendation Model Based on Trust [J].https://doi.org/10.3778/j.issn.1002-8331.1507-0016 URL Magsci [本文引用: 1] 摘要
传统的协同过滤推荐技术主要基于用户-项目评价数据集进行挖掘推荐,没有有效地利用用户通信上下文信息,从而制约其进一步提高推荐的精确性。针对传统协同过滤推荐算法存在的推荐精度不高的弊端,在协同过滤算法中融入通信上下文信息,引入了通信信任、相似信任和传递信任三个信任度,并提出了一种基于信任的协同过滤推荐模型。通过公开数据集验证测试,证明提出的推荐算法较传统的协同过滤推荐技术在推荐准确性上有较大提高。
|
| [5] |
Combining Content-based and Collaborative Recommendations: A Hybrid Approach Based on Bayesian Networks [J].https://doi.org/10.1016/j.ijar.2010.04.001 URL [本文引用: 1] 摘要
Recommender systems enable users to access products or articles that they would otherwise not be aware of due to the wealth of information to be found on the Internet. The two traditional recommendation techniques are content-based and collaborative filtering. While both methods have their advantages, they also have certain disadvantages, some of which can be solved by combining both techniques to improve the quality of the recommendation. The resulting system is known as a hybrid recommender system. In the context of artificial intelligence, Bayesian networks have been widely and successfully applied to problems with a high level of uncertainty. The field of recommendation represents a very interesting testing ground to put these probabilistic tools into practice. This paper therefore presents a new Bayesian network model to deal with the problem of hybrid recommendation by combining content-based and collaborative features. It has been tailored to the problem in hand and is equipped with a flexible topology and efficient mechanisms to estimate the required probability distributions so that probabilistic inference may be performed. The effectiveness of the model is demonstrated using the MovieLens and IMDB data sets.
|
| [6] |
Content-boosted Collaborative Filtering for Improved Recommendations [C]// |
| [7] |
VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback [C]// |
| [8] |
融合图像相似性与协同过滤的个性化推荐算法研究 [D].Research on Personalized Recommendation Algorithm Integrating Image Similarity and Collaborative Filtering [D]. |
| [9] |
基于图像内容的电商物品检索与推荐系统研究 [D].Research of Content-based Commercial Product Image Retrieval and Recommendation System [D]. |
| [10] |
Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality [J]. |
| [11] |
Locality Sensitive Hashing for Similarity Search Using Map Reduce on Large Scale Data[A]//Language Processing and Intelligent Information Systems [M]. |
| [12] |
Near-optimal Hashing Algorithms for Approximate Nearest Neighbor in High Dimensions [C]// |
| [13] |
基于改进的局部敏感哈希算法实现图像型垃圾邮件过滤 [J].https://doi.org/10.3969/j.issn.1001-3695.2016.06.021 URL [本文引用: 1] 摘要
提出一种快速的图像型垃圾邮件过滤方案,结合半监督机器学习技术改进局部敏感哈希(LSH)算法,基于改进的LSH算法构建垃圾图像特征库索引,提高图像的查找速度。搜集并构造了60 000个垃圾图像样本,实验结果表明,利用改进的LSH算法能有效地提高垃圾图像的过滤速度。
Image Spam Filtering with Improved LSH Algorithm [J].https://doi.org/10.3969/j.issn.1001-3695.2016.06.021 URL [本文引用: 1] 摘要
提出一种快速的图像型垃圾邮件过滤方案,结合半监督机器学习技术改进局部敏感哈希(LSH)算法,基于改进的LSH算法构建垃圾图像特征库索引,提高图像的查找速度。搜集并构造了60 000个垃圾图像样本,实验结果表明,利用改进的LSH算法能有效地提高垃圾图像的过滤速度。
|
| [14] |
基于改进局部敏感散列算法的图像配准 [J].https://doi.org/10.3788/OPE.20111906.1375 URL Magsci [本文引用: 1] 摘要
为实现图像间的快速准确配准,在局部敏感散列(LSH)算法基础上,提出一种高效的高维特征向量检索算法—改进的LSH(ELSH)算法用以图像特征间的检索配对,从而实现图像间的配准。该配准算法首先采用尺度不变特征变换(SIFT)算法提取图像的特征点并进行描述,得到图像的高维特征向量。然后,根据随机选择的若干子向量构建哈希索引结构,以缩减构建索引数据的维数和搜索的范围,从而缩短建立索引的时间。最后,根据数据随机取样一致性(RANSAC)剔除错误点。实验结果表明,与BBF (Best-Bin-First)和LSH算法相比,ELSH算法不但提高了匹配点对的准确性同时也缩短了匹配时间,其特征匹配时间分别减少了49.9%和37.9%。实验表明该算法可以快速、精确地实现图像间的配准。
Image Registration Based on Extended LSH [J].https://doi.org/10.3788/OPE.20111906.1375 URL Magsci [本文引用: 1] 摘要
为实现图像间的快速准确配准,在局部敏感散列(LSH)算法基础上,提出一种高效的高维特征向量检索算法—改进的LSH(ELSH)算法用以图像特征间的检索配对,从而实现图像间的配准。该配准算法首先采用尺度不变特征变换(SIFT)算法提取图像的特征点并进行描述,得到图像的高维特征向量。然后,根据随机选择的若干子向量构建哈希索引结构,以缩减构建索引数据的维数和搜索的范围,从而缩短建立索引的时间。最后,根据数据随机取样一致性(RANSAC)剔除错误点。实验结果表明,与BBF (Best-Bin-First)和LSH算法相比,ELSH算法不但提高了匹配点对的准确性同时也缩短了匹配时间,其特征匹配时间分别减少了49.9%和37.9%。实验表明该算法可以快速、精确地实现图像间的配准。
|
| [15] |
基于深度学习特征的图像推荐系统 [D].Image Recommendation System Based on the Image Features Obtained from Deep Learning [D]. |
| [16] |
基于SIFT算法的图像目标匹配与定位 [J].
针对仅应用SIFT算法无法准确定位的问题提出了一种将SIFT算法、马氏距离和仿射变换相结合的匹配定位方法。利用SIFT算法进行图像初次匹配,同时对初次匹配的特征点进行马氏距离计算,尽可能的剔除误配点,接着结合仿射模型计算出仿射变换的参数,最后根据目标模板的形心和仿射变换参数求出复杂环境中图像目标的形心位置坐标。实验结果表明了该方法在忽略几何畸变的情况下,对目标准确定位具有较强的适应性,能够实现在复杂环境中检测目标,并获取目标的形心坐标。
Matching and Location of Image Object Based on SIFT Algorithm [J].
针对仅应用SIFT算法无法准确定位的问题提出了一种将SIFT算法、马氏距离和仿射变换相结合的匹配定位方法。利用SIFT算法进行图像初次匹配,同时对初次匹配的特征点进行马氏距离计算,尽可能的剔除误配点,接着结合仿射模型计算出仿射变换的参数,最后根据目标模板的形心和仿射变换参数求出复杂环境中图像目标的形心位置坐标。实验结果表明了该方法在忽略几何畸变的情况下,对目标准确定位具有较强的适应性,能够实现在复杂环境中检测目标,并获取目标的形心坐标。
|
| [17] |
Vision Based Localization of a Small UAV for Generating a Large Mosaic Image [C]// |
| [18] |
3维物体SIFT特征的提取与应用 [J].https://doi.org/10.11834/jig.20100516 Magsci [本文引用: 1] 摘要
SIFT(scale-invariant feature transform)算法自提出以来,就因其优越的性能(尺度不变性、旋转不变性、抗噪声能力强、受光照变化影响小等),而备受图像图形领域研究者的青睐。该算法的核心特征(SIFT特征)基于局部梯度,能够抵抗图像大幅度的伸缩、旋转等,很好地满足了3维物体识别的实际需要。而SIFT特征对投影变换的相对敏感性恰可用于3维模型的视点空间划分,且划分依据与匹配依据一致,能够有效提高匹配准确度。合理设置SIFT算法的阈值还可以有效处理物体背景分割等技术问题。通过充分的预处理,能够有效降低SIFT算法计算复杂度高,使得系统基本达到实时匹配。总之,将SIFT特征应用在3维物体识别系统中的视点空间划分、背景物体分割、模式特征匹配等模块,可以有效地提高系统的识别速度与效率,增强系统的稳定性。
Extraction and Application of 3D Object SIFT Feature [J].https://doi.org/10.11834/jig.20100516 Magsci [本文引用: 1] 摘要
SIFT(scale-invariant feature transform)算法自提出以来,就因其优越的性能(尺度不变性、旋转不变性、抗噪声能力强、受光照变化影响小等),而备受图像图形领域研究者的青睐。该算法的核心特征(SIFT特征)基于局部梯度,能够抵抗图像大幅度的伸缩、旋转等,很好地满足了3维物体识别的实际需要。而SIFT特征对投影变换的相对敏感性恰可用于3维模型的视点空间划分,且划分依据与匹配依据一致,能够有效提高匹配准确度。合理设置SIFT算法的阈值还可以有效处理物体背景分割等技术问题。通过充分的预处理,能够有效降低SIFT算法计算复杂度高,使得系统基本达到实时匹配。总之,将SIFT特征应用在3维物体识别系统中的视点空间划分、背景物体分割、模式特征匹配等模块,可以有效地提高系统的识别速度与效率,增强系统的稳定性。
|
| [19] |
3D Scene’s Object Detection and Recognition Using Depth Layers and SIFT-based Machine Learning [J].https://doi.org/10.1007/3DRes.03(2011)6 URL [本文引用: 1] 摘要
This paper presents a novel system that is fusing efficient and state-of-the-art techniques of stereo vision and machine learning, aiming at object detection and recognition. To this goal, the system initially creates depth maps by employing the Graph-Cut technique. Then, the depth information is used for object detection by separating the objects from the whole scene. Next, the Scale-Invariant Feature Transform (SIFT) is used, providing the system with unique object feature key-points, which are employed in training an Artificial Neural Network (ANN). The system is then able to classify and recognize the nature of these objects, creating knowledge from the real world.
|
| [20] |
Novel Averaging Window Filter for SIFT in Infrared Face Recognition [J].https://doi.org/10.3788/COL URL [本文引用: 1] |
| [21] |
Distinctive Image Features from Scale-Invariant Keypoints [J].https://doi.org/10.1023/B:VISI.0000029664.99615.94 URL [本文引用: 1] |
| [22] |
基于内容的图像检索系统中高维索引技术的研究 [D].Research on High-dimensional Indexing Technology in Content-based Image Retrieval System [D]. |
| [23] |
基于差分和特征不变量的运动目标检测与跟踪 [J].https://doi.org/10.3321/j.issn:1004-924X.2007.04.021 URL Magsci [本文引用: 1] 摘要
提出了一种基于改进的图像差分算法与特征不变量匹配的目标识别方法。通过三帧差值法获得了更完整清晰的目标轮廓,并基于该轮廓信息构造了一个具有平移、大小和旋转不变性的特征不变量;然后提出动态极值匹配法,利用特征曲线的极值信息点进行识别匹配,并动态替换原特征模版。实验结果表明,该方法能够准确识别目标,显著地提高识别跟踪效率,并且适用于检测运动姿态发生变化的目标。对于分辨率为288×352像素,每像素8位量化的序列图像,处理每帧图像平均用时0.011 74 s,其中特征提取与匹配过程平均用时0.005 476 s,能够实现对运动目标的实时分析,可同时满足运动目标识别跟踪中实时性和准确率的要求。
New Method for Detecting and Tracking of Moving Target Based on Difference and Invariant [J].https://doi.org/10.3321/j.issn:1004-924X.2007.04.021 URL Magsci [本文引用: 1] 摘要
提出了一种基于改进的图像差分算法与特征不变量匹配的目标识别方法。通过三帧差值法获得了更完整清晰的目标轮廓,并基于该轮廓信息构造了一个具有平移、大小和旋转不变性的特征不变量;然后提出动态极值匹配法,利用特征曲线的极值信息点进行识别匹配,并动态替换原特征模版。实验结果表明,该方法能够准确识别目标,显著地提高识别跟踪效率,并且适用于检测运动姿态发生变化的目标。对于分辨率为288×352像素,每像素8位量化的序列图像,处理每帧图像平均用时0.011 74 s,其中特征提取与匹配过程平均用时0.005 476 s,能够实现对运动目标的实时分析,可同时满足运动目标识别跟踪中实时性和准确率的要求。
|
| [24] |
Embeddings and Data Stream Computation [C]// |
| [25] |
Locality-sensitive Hashing Scheme Based on P-stable Distributions [C]// |
| [26] |
Optimal Data-Dependent Hashing for Approximate Near Neighbors [C]// |
| [27] |
The MIR-Flickr Retrieval Evaluation [EB/OL]. [ |

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}