
|
|
徐路路, 王效岳 , 白如江, 周彦廷
, 白如江, 周彦廷
山东理工大学科技信息研究所 淄博 255049
Xu Lulu, Wang Xiaoyue, Bai Rujiang, Zhou Yanting
中图分类号: G250
通讯作者:
收稿日期: 2017-11-1
修回日期: 2017-12-8
网络出版日期: 2018-03-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】为提升科技文献文本内容语义理解, 对基金项目文本中的新兴趋势进行探测。【方法】提出一种基于DTM模型和文本特征分析的基金项目新兴趋势探测方法, 利用文本挖掘技术深入文本内容并分析基金摘要特征要素, 识别主题概率分布并构造基于文本特征要素的新兴主题探测公式, 对NSF数据库石墨烯领域中的新兴趋势进行探测与分析。【结果】通过文献调查法和专家咨询法, 表明该方法能够更加快速准确地识别基金项目中的新兴趋势主题, 弥补了单一主题维度进行主题探测的不足, 为科技创新决策提供情报支撑服务。【局限】仅从资助金额强度、资助时长、资助主题三个方面分析基金项目, 需进一步拓展和探索符合其文本特征的因素并对其进行多因素融合分析。【结论】本文提出的新兴趋势模型可更加快速准确地识别其新兴趋势主题。
关键词:
Abstract
[Objective] This study tries to extract more semantic information from the science and technology literature, aiming to identify emerging trends from the documents of fund projects. [Methods] First, we proposed a new trend detection method based on the DTM model and text analytics. Then, we identified the topic probability distribution of the fund projects and constructed a new theme detection formula based on the text features. Finally, we detected the emerging trends in the field of NSF graphene. [Results] The proposed method identified emerging trends of fund projects and provided information for technology innovation. [Limitations] We only examined the fund project documents from the perspectives of the amount, length, and theme of funding. [Conclusions] The proposed method could effectively identify emerging trends of fund projects.
Keywords:
随着科技演变和学科交叉加速发展, 科技文献的数量呈指数倍数增长[1]。大数据时代下, 如何从大量科技文献识别学科领域最新研究前沿与动态, 尤其是学科主题下的新兴趋势, 对于学科建设与发展起着重要的促进作用。我国已经在能源、生态、空间等诸多领域取得显著的研究成果, 逐渐由科技跟跑者向全球科技并行者转变[2]。因此, 新兴趋势的主题识别与探测, 对于我国科技政策制定与大势研判亦具有重要指导意义。众多学科领域新兴趋势探测取得一定成果, 但也存在一些问题, 如多数新兴趋势探测以论文为分析数据源, 而论文数据具有明显的“时滞性”; 同时, 新兴趋势探测的方法存在一定不足, 如共被引、引文耦合等传统情报学分析方法难以深入文本内容进行有效识别, 以上问题限制了学科内新兴趋势的探测与揭示。
基金项目是经过领域专家同行评议和决策者认可的科技文献形式, 其研究内容相比较期刊论文、会议等文献形式可以更早地反映某领域的研究前沿以及新兴的发展趋势[3]。但基金项目数据与论文数据在叙述结构、外在属性、形式结构等文本特征存在明显差异, 尚未形成基金文本特征表示框架。因此, 本文尝试利用DTM模型进行主题识别并融合基金项目资助时间、资助金额等特征要素, 构造基于基金项目文本的新兴趋势探测公式, 以期为新兴趋势探测提供一种新思路、新视角。
基于时序对基金项目文本中代表未来发展方向的新兴趋势进行探测是本文的研究重点, 因此识别文本中主题及表示动态时序主题链是本文的首要任务。在新兴趋势探测中形成了众多方法, 如词频分析、共词聚类、社区算法、主题模型等, 其中, 利用主题模型分析大规模非结构化文档集被证明是有效方法之一, 并在社交网络、图像识别和计算生物学等领域得到广泛应用。
2003年, Blei等首次提出LDA模型, 基于统计概率层面表达词间语义层次关系, 掀起了主题识别与探测的热潮[4]。之后, 相关研究人员基于LDA模型进一步拓展和丰富主题概率识别模型, 如PLDA模型[5]、TNG模型[6]、文本集合的后离散概率模型[7]以及DTM模型[8]等。2012年, Li等实验表明DTM模型(Dynamic Topic Models)可以动态处理具有时间戳的文档数据集, 实现动态主题识别与追踪, 迅速准确捕捉主题的动态特征, 从而识别领域内主题和主题词的协同演变脉络[9]。2015年, Wang等采用新闻语料基于DTM模型识别有序集合的潜在主题模型并建立变分推理模型以解决数据源的离散化分布, 实验证明DTM模型可有效识别细粒度主题模型[10]。利用DTM模型进行主题识别, 相较于词频、共词等基于主题词的主题识别方法具有良好的语义表达水平[11]。
因此, 本文选用DTM模型进行主题识别, 表征动态时序主题链发展变化, 揭示学科领域内新兴趋势。
如何探测科技文献中学科发展的最新趋势一直是情报分析人员的关键任务之一。情报学领域存在较多与新兴趋势类似或含义相同的概念, 如Roy等提出的初始趋势[12]、Price提出的研究前沿[13]与Kontostathis等定义的新兴趋势(Emerging Trend)[14]概念相近, 均反映某一学科领域具有发展潜力的研究方向和主题内容。
近年来, 新兴趋势的识别与探测得到了相关学者与情报分析人员的广泛关注, 并进一步丰富了新兴主题研究内容和方法。2006年, Hoang提出新兴主题测量指标, 利用论文外在属性确定主题的新颖度指标[15]。2014年, 范云满等利用TNG主题概率识别模型探测主题, 融合探测指标并形成新兴主题探测表格, 得到深度学习相关领域的最新学科研究主题[16]。
从科技文献中识别和探测新兴趋势已成为众多学者关注和研究的重点, 并取得了一定的研究成果, 但也存在一些不足, 如多数围绕论文数据展开研究, 只分析了主题外部特征, 对于主题动态时序变化揭示力度不够, 未考虑研究主题内部的内容变化, 以上问题限制了新兴主题研究的准确性和有效性。
政府资助的基金研发项目经过评审并得到专家认可, 蕴含着众多前瞻性的新兴发展趋势, 对国家的科学研究进程具有重要指导意义。因此, 针对政府资助项目文本尤其是美国、欧洲等科技知识密集区的文本数据进行新兴趋势探测, 对于我国政府科技政策制定和优先发展领域筛选具有指导性意义。
2005年, 杨俊林等对美国国家科学基金会(National Science Foundation, NSF)在理论与计算化学项目的资助情况进行分析并前瞻性预判该领域的最新发展趋势[17]。2013年, 杨荔媛等从项目数量、项目类型、项目主题等方面对“图书馆、情报与档案管理”研究领域的国家社会科学基金和自然科学基金项目进行新兴主题分析[18]; 对该学科进行基金项目现状与主题趋势分析的相关学者还有赵蓉英等[19]、李英[20]、梁伟波[21]。
在以政府资助项目文本的新兴主题前沿研究中主要采用两种方法: 一种是基于词频、共词分析等传统计量学分析方法, 该方法未深入到项目文本内容进行主题描述, 存在时滞性的问题; 另一种是基于文本挖掘技术(如条件随机场模型和语义标注技术等)进行主题探测和识别, 缺乏准确、科学的针对政府资助项目的指标体系, 对新兴主题的探测不够深入和全面。
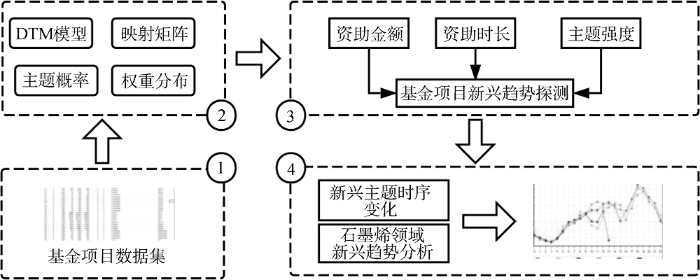
为有效前瞻地探测基金项目数据中的主题及新兴趋势, 本文提出基于DTM模型和文本特征分析的基金项目新兴趋势探测研究方法, 具体流程如图1所示。以NSF石墨烯基金项目数据作为研究对象, 利用DTM模型识别基金项目文本中的动态研究主题, 然后利用本文构建的新兴趋势探测公式进行新兴主题探测, 最后得出石墨烯领域值得关注的新兴趋势主题, 为我国石墨烯学科建设及发展方向政策制定提供情报参考服务。
(1) NSF数据获取与预处理。确定研究领域, 构建检索式, 登录美国国家科学基金会(NSF)官网获取其资助的石墨烯基金项目数据; 然后进行文本格式转换、句子级别抽取、去除停用词、分词等处理, 并进行时间切片为后续研究提供支持。
(2) 基金项目文本主题表征。利用DTM模型识别出蕴含在NSF数据中的研究主题, 构建主题-文档和主题-主题词矩阵, 得到主题及主题词权重分配, 从而为计算主题相关基金项目的资助时间、金额等指标奠定基础。
(3) 新兴趋势探测公式构建。基于基金项目的文本特征及外在属性进行文本分析, 并根据主题周期发展阶段特点提出新兴趋势探测公式, 综合考虑资助强度、资助时长、主题强度等多重指标, 探测出值得关注的石墨烯领域新兴趋势主题。
(4) 石墨烯领域新兴趋势分析。对探测出的新兴趋势主题进行函数拟合构建, 分析主题在时间维度上的动态时序变化, 揭示石墨烯领域发展新动向。
本文采用GitHub中基于R语言实现DTM源码进行建模分析, 实现主题探测, 源码地址为https://github. com/Blei-Lab/dtm/tree/master/dtm。
基金项目数据与论文数据存在一定共性, 如题名、摘要、关键词等结构化信息, 但基金项目也具有特有的叙述结构、文本内容以及属性特征, 如基金项目中的项目资助起止时间、项目资助金额、主题资助强度等特征。因此, 对基金项目文本进行特征分析, 总结其特征属性及关键内容组成, 并依此制定相应评价指标, 可有效提高基金项目的新兴趋势探测的精确度和科学性, 基金项目文本特征分析如表1所示。
表1 基金项目文本特征分析
| 文本特征 | 内容 | 分析 | 设计指标 | 实现方式 |
|---|---|---|---|---|
| Title | 项目申请名称 | 该部分为基金项目文本信息, 主要揭示申请项目方法、流程、框架等主题信息, 可通过主题探测模型分析获得。 | 主题强度 | 可利用DTM模型进行文本内容主题探测识别 |
| Abstract | 摘要信息 | |||
| StartDate | 申请项目的批准日期 | 该部分为基金项目的批准日期及结项日期, 即为项目执行期限, 资助期限越长表示该基金项目重要性越强。 | 资助时长 | 利用基金项目起止日期计算可得 |
| EndDate | 申请项目的结项日期 | |||
| Awarded Amount | 申请项目资助金额 | 该部分为基金项目的资助金额, 以供研究人员进行科学研究经费开支, 资助金额越大说明基金委员评审专家认为该主题研究意义和价值越大。 | 资助强度 | 分析基金项目中资助金额指标可得 |
其中, 基金项目的题名、关键词等信息强度是进行新兴趋势分析的基础, 本文利用DTM模型识别其中蕴含的研究主题, 构建主题-基金项目文本矩阵和主题-主题词矩阵, 表达语义关系。在此基础上, 通过主题和对应基金项目的映射, 可以进一步分析主题的资助时间、资助金额和中心性等情况, 并进行权重分配处理, 使得基金项目文本特征三要素统一表征。
Tu等[22]利用主题发文量构造新颖度、被引量等文献计量学指标表达论文中蕴含新兴主题的发展趋势, 并将主题与所有主题的平均水平进行对比, 得出学科领域值得关注的新兴的主题信息。本文借鉴其评价方法体系并分析基金项目文本特征, 对基金项目文本中的新兴趋势进行分析和探测。
基金项目新兴趋势是指尚未引起广泛关注的主题, 但其具有巨大的研究价值和实践意义, 对于学科未来发展起重要引导作用。主题具有独特的发展周期, 微观表现为主题的产生、发展、分裂、融合以及衰老等特征, 宏观表现为新兴时期、发展时期、衰老时期等不同时间序列的特征。本文根据不同主题发展周期可分为新兴主题、热门主题、衰老主题以及潜在新兴主题等4种类型, 如表2所示。
表2 基金项目主题分类
| 主题 | t时期 | t+1时期 | 主题特点 | 主题分类 |
|---|---|---|---|---|
| 主题1 | 低于平均主题水平 | 高于平均主题水平 | 该主题研究热度发展迅速、呈上升趋势, 主题资助金额明 显提升、科研单位及产出增加 | 新兴主题 |
| 主题2 | 高于平均主题水平 | 高于平均主题水平 | 该主题持续研究热度较高、资助金额及科研单位较多、资 助时长较长 | 热门主题 |
| 主题3 | 高于平均主题水平 | 低于平均主题水平 | 该主题前期发展较好、资助金额及科研单位较多, 但逐渐 衰老, 研究主题存在老化现象 | 衰老主题 |
| 主题4 | 低于平均主题水平 | 低于平均主题水平 | 该主题研究水平持续低于平均值、但主题资助金额有所提 升、成果产出逐渐积累、主题发展潜力大 | 潜在新兴主题 |
其中, 新兴主题代表未来的研究方向和研究动机, 其资助金额逐渐增多, 研究机构和研发人员趋于稳定发展, 因此, 是最具有研究价值意义的主题类型。新兴趋势的探测需要细化研究阶段和研究时期, 分析每个时期的主题探测以及主题所体现出资助强度、资助时间等外在信息的变化, 本文将新兴主题分为潜在阶段和突破阶段, 并借鉴文献[16]对其具体特征进行分析, 如表3所示。
表3 新兴趋势主题阶段特征分析
| 主题类型 | 阶段 | 主题特点 | 指标特点 |
|---|---|---|---|
| 新兴趋势 | 潜在阶段 | 研究热度明显上升、论文数少、被引量少、基金项 目数较少、发展趋势明显 | 资助金额、时长等特征要素低于同时期 不同主题平均值 |
| 新兴趋势 | 突破阶段 | 研究热度轻微上升并趋于平稳、论文数较多、基金 项目数较多、出现理论奠基性论文、发展趋势减缓 | 资助金额、时长等特征要素高于同时期 不同主题平均值 |
通过主题阶段特征分析可得, 新兴趋势所体现的潜在阶段和突破阶段分别是与主题平均值的比较大小来确定, 若低于同时期不同主题平均值则定义新兴趋势为潜在阶段, 反之为突破阶段。因此, 为有效融合基金项目中资助强度、资助时长、主题强度等特征, 对新兴趋势进行量化判别, 本文需构造主题探测公式以及均值公式进行比较分析, 进而利用新兴趋势探测公式得到值得关注的新兴主题。
(1) 主题探测公式
Tu等[22]利用发文量、被引量等, 构建主题探测及均值分析公式, 本文对其指标和相关评价体系进行修改, 分析基金项目文本特征、外在特征等属性, 提出基于项目文本的主题探测公式, 如公式(1)所示。
$\mathop{DV}_{t}=\alpha \times \mathop{TI}_{t}^{z}+\beta \times \mathop{FAI}_{t}^{z}+(1-\alpha -\beta )\times \mathop{FTI}_{t}^{z}$ (1)
其中, $\mathop{DV}_{t}$是综合考虑项目文本主要特征要素的新兴主题探测值(Detection Value); $\mathop{TI}_{t}^{z}$表示某时间段的主题强度, 该值可通过主题概率识别模型得到(Topic Intensity); $\mathop{FAI}_{t}^{z}$表示在t时间段内主题z下的单项目资助强度(Funding Amount Index); $\mathop{FTI}_{t}^{z}$表示t时间段内主题z单项目的资助时长(Funding Time Index); $\alpha $, $\beta $为基金项目要素调谐系数, 归一化调节参量使得后续要素有效融合, 取值范围为(0,1)。具体参数构造如公式(2)和公式(3)所示。
$FAI_{t}^{z}=\frac{\mathop{Sum}_{t}^{FA}(z)}{P{{C}_{t}}(z)}$ (2)
其中, $\mathop{Sum}_{t}^{FA}(z)$表示t时间段内围绕主题z的政府资助项目的累计资助金额总和; $\mathop{PC}_{t}(z)$反映t时间段内的政府资助项目数量(Program Count); $\mathop{FAI}_{t}^{z}$表示在t时间段内主题z下的单项目资助强度。该参数可以反映某主题下单个项目的资助额度, 排除不同主题项目数的不同所带来的差异, 一定程度反映该主题的研究价值, 因此, 资助金额参数越大, 说明该主题研究意义越大, 其前瞻价值越高。
$\mathop{FTI}_{t}^{z}=\frac{\mathop{Sum}_{t}^{FT}(z)}{P{{C}_{t}}(z)}$ (3)
其中, $\mathop{Sum}_{t}^{FT}(z)$表示在t时间段内研究主题z资助时长; $\mathop{PC}_{t}(z)$反映t时间段内的政府资助项目数量; $\mathop{FTI}_{t}^{z}$表示t时间段内主题z单项目的政府资助时长。该参数从时间维度量化分析, 资助时间越长则说明该主题研究意义以及重要性越大。
(2) 均值公式
均值公式是指对上述主题探测公式中同时间段内的所有主题进行求和均值处理, 该公式反映了t时间段内的总体主题的主题强度、资助强度以及资助时长的平均水平和发展趋势。利用该公式与主题探测公式比较可以判定主题的类型及新兴趋势主题的发展阶段, 具体如公式(4)[16]所示。
$\mathop{ADV}_{t}=\alpha \times \mathop{ATI}_{t}+\beta \times \mathop{AFAI}_{t}+(1-\alpha -\beta )\times \mathop{AFTI}_{t}$ (4)
其中, $\alpha $、$\beta $为调谐系数; $\mathop{ATI}_{t}$表示平均主题强度, 可由不同主题权重值平均处理得到(Average Detection Value); $AFA{{I}_{t}}$表示t时间段内多个主题资助金额参数的平均值; $AFT{{I}_{t}}$表示t时间段内所有主题资助时长的平均值。通过调谐系数可以得到均值公式值$\mathop{ADV}_{t}$,该值反映基金项目文本t时间段所有主题的平均强度, 是衡量单个主题的基准值。
$\mathop{AFAI}_{t}=\frac{\mathop{FAI}_{t}^{z}}{T{{C}_{t}}}$ (5)
$\mathop{FAI}_{t}^{z}$表示资助金额参数, 反映单主题下单项目的资助金额; $\mathop{TC}_{t}$表示一定时期内政府资助项目中主题数量的总和(Topic Count); $\mathop{AFAI}_{t}$表示特定时间段内多个主题资助金额参数的平均值。
$\mathop{AFTI}_{t}=\frac{\mathop{FTI}_{t}^{z}}{T{{C}_{t}}}$ (6)
$\mathop{FTI}_{t}^{z}$表示资助时长参数, 反映单主题下单项目的资助时间; $\mathop{TC}_{t}$表示一定时期内政府资助项目中主题数量的总和; $\mathop{AFTI}_{t}$表示特定时间段内多个主题资助时长参数的平均值。
(3) 新兴主题探测公式
利用主题探测公式与均值公式进行对比, 例如在t时间段内, DVt<ADVt , 且随着时间发展, 存在t+1时间段, DVt>ADVt , 则说明该主题为新兴趋势主题, 本文研究旨在探测基金项目中蕴含的新兴主题, 因此, 为更好表达和探测, 本文引入新兴主题探测公式(Emerging Topic Detection), 计算如公式(7)所示。
$\mathop{ETD}_{t}=\mathop{DV}_{t}-\mathop{ADV}_{t}$ (7)
公式(7)是对公式(1)和公式(4)的差值处理, 其值表示单个主题的探测值与平均水平的差值, 若低于平均水平, 则为负数; 若高于平均水平, 则为正数。通过引入新兴主题探测公式, 可以更为直观地表达新兴趋势主题的发展水平, 揭示主题动态演化过程。
(1) 研究领域与数据检索
美国科研水平在世界处于前列, 而美国国家科学基金会NSF 资助的基金项目代表了美国相关研究领域的最高水平。因此, 以美国国家科学基金会所资助的石墨烯相关基金项目数据为数据源, 识别石墨烯领域的新兴趋势主题。
数据库: 美国国家科学基金会NSF基金项目数据; 时间跨度: 2004年至2016年(2004年科学家首次提炼出单原子层石墨烯); 检索式; Keyword=“grapheme” or “Graphene”; 检索结果: 714项。检索时间: 2017-10-15。数据格式为.xls, 数据分为AwardNumber、AwardedAmount、OrganizationPhone、StartDate、Abstract等字段, 剔除机构组织者、联系方式等无关字段, 最终保留资助序列号、资助起止时间、摘要等5部分有效字段。
(2) 数据预处理
检索数据集时间跨度13年, 2004年-2016年NSF政府资助石墨烯领域项目总体呈现增长趋势, 尤其是2009年以后项目数量增幅明显, 其中, 从NSF资助机构角度, 工程学部(Engineering)和数理科学学部(Mathematical & Physical Sciences)是主要的资助学科机构, 围绕石墨烯材料性能、化学工艺以及通信网络应用等方面展开, 如表4所示。
表4 NSF 各机构对石墨烯研究的支持情况
| 学部(Directorate) | 机构(Organization) | 项目数/项 |
|---|---|---|
| 工程(Engineering) | 电子、通信与网络系统 | 101 |
| 土木、机械和制造业创新 | 94 | |
| 产业创新与合作 | 42 | |
| 新兴前沿办公室 | 8 | |
| 工程教育和中心 | 13 | |
| 计算机信息科学与工程 (Computer & Information Science & Engineering) | 计算和通信基础 | 9 |
| 计算机和网络系统 | 7 | |
| 先进基础设施 | 3 | |
| 数理科学 (Mathematical & Physical Sciences) | 材料研究 | 216 |
| 化学 | 45 | |
| 物理 | 14 | |
| 天文科学 | 1 | |
| 数学研究 | 12 | |
| 生物科学 (Biological Sciences) | 生物基础设施 | 5 |
新兴主题探测在于第一时间发现具有较大潜力而未引起广泛关注的主题, 因此, 将子时期单位设置为一年可较早识别短时间内突发主题词。为保证足够数据进行主题分析, 本文选取政府资助数量较多的2008年为时间起始, 以每年为时间单位进行细粒度时间切片处理, 得到9个子时期。
(1) DTM模型主题识别
通过不同主题识别模型的实验与结果对比, 发现DTM对于主题词识别效果较好, 主题新颖度较高, 同时可识别动态时序主题链并予以表征。利用DTM主题模型, 通过9个子时期的分析数据集细粒度时间切片并进行主题建模。为了提高主题识别的准确性, 对主题数量和困惑度对应关系进行实验, 实验表明当主题数量为90时折线变化趋势逐渐稳定, 虽然主题越多困惑度越小, 但会造成过度拟合, 因此最终确定主题数量为90, 即每子时期的模型主题数阈值设为10, 共得到90个时期主题及900个主题词。依据文档-主题(Document-Topics)矩阵和主题-主题词(Topic-Words)矩阵的对应关系可以得到主题和基金项目的映射关系和主题表征结果, 为实验中统计分析基金项目的资助时间、资助金额和主题中心性奠定基础, 基金文本主题表征如表5所示。
表5 部分基金文本主题表征(部分)
| Award Number | Start Date | State | Award Instrument | End Date | Awarded Amount | Topic |
|---|---|---|---|---|---|---|
| 0747684 | 02/01/2008 | MN | Standard Grant | 01/31/2014 | $423,486.00 | Topic1 |
| 0748910 | 02/01/2008 | CA | Continuing Grant | 07/31/2013 | $511,207.00 | Topic8 |
| 0756958 | 08/01/2008 | UT | Continuing Grant | 07/31/2011 | $75,000.00 | Topic2 |
| 0802216 | 07/01/2008 | AZ | Standard Grant | 09/30/2011 | $315,243.00 | Topic1 |
| 0805220 | 06/15/2008 | OH | Continuing Grant | 05/31/2011 | $422,811.00 | Topic5 |
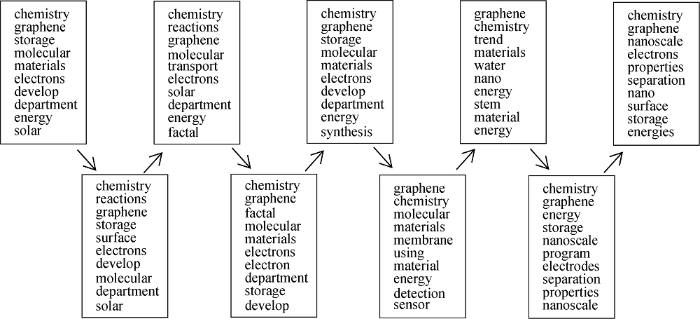
采用点积余弦相似度算法计算主题相似度以构建石墨烯领域主题演化图, 设定阈值Y, 相似度大于Y, 判定相邻子时期的两个主题具有演化关系, 以此表达主题发展的前继和后驱, 确定主题演化脉络。最终利用DTM模型识别基金项目中的9个子时期主题动态链, 为后续根据新兴主题探测公式进行新兴主题探测做好基础性工作, 如图2展示的其中一条主题链, 该主题围绕石墨烯制备方法、化学特性展开研究, 探索了纳米级材料的性能结构、石墨烯表面微观形貌结构以及能量存储等特性。
(2) 新兴趋势探测
①DVt计算
本文提出新兴趋势探测公式由主题探测以及均值公式两部分组成, 参量权重分配如下: 主题强度为0.4, 资助强度为0.3, 资助时长为0.3。初步计算得到主题探测工作值, 如表6所示。
表6 DVt计算结果
| 主题 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|---|---|---|---|---|
| Topic0 | 0.536806 | 0.385843 | 0.701674 | 0.660604 | 1.065147 | 1.033578 | 1.946747 | 1.308421 | |
| Topic1 | 0.679784 | 0.818186 | 0.658238 | 1.208104 | 1.047232 | 1.070715 | 1.442418 | 1.041759 | 1.504981 |
| Topic2 | 1.121281 | 0.818186 | 0.801484 | 0.699304 | 0.811001 | 1.070715 | 0.96507 | 1.182918 | 0.58696 |
| Topic3 | 0.916347 | 0.979223 | 1.070715 | 1.033578 | 1.845305 | 1.218901 | |||
| Topic4 | 0.658238 | 0.787752 | 0.84818 | 0.903286 | 0.979223 | 0.94795 | 0.819842 | ||
| Topic5 | 0.679784 | 2.794199 | 1.407899 | 0.913776 | 0.653303 | 0.84818 | 1.442418 | 0.970248 | 0.952771 |
| Topic6 | 1.373507 | 2.794199 | 1.201312 | 1.308421 | 0.750168 | 0.84818 | 0.710484 | 0.755196 | 0.674185 |
| Topic7 | 0.916347 | 0.653303 | 0.703973 | 1.033578 | 1.493767 | 1.208104 | |||
| Topic8 | 1.373507 | 2.794199 | 1.201312 | 1.308421 | 1.845305 | 2.767026 | 1.507944 | 1.041759 | 2.190124 |
| Topic9 | 1.121281 | 1.116123 | 1.201312 | 1.208104 | 1.918824 | 0.84818 | 0.710484 | 0.755196 | 0.548143 |
②ETDt计算
利用本文提出的新兴趋势探测公式对主题探测公式进一步修正, 均值公式是融合资助强度、资助时长、主题强度三种要素参量的均值计算, 此处通过数学计算推导可得其数值为1, 因此划定阈值为1。新兴趋势探测公式计算结果如表7所示。
表7 ETDt计算结果
| 主题 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 |
|---|---|---|---|---|---|---|---|---|---|
| Topic0 | -0.46319 | -0.61416 | -0.29833 | -0.3394 | 0.06515 | 0.03358 | 0.94675 | 0.30842 | |
| Topic1 | -0.32022 | -0.18181 | -0.34176 | 0.2081 | 0.04723 | 0.07071 | 0.44242 | 0.04176 | 0.50498 |
| Topic2 | 0.121281 | -0.18181 | -0.19852 | -0.3007 | -0.189 | 0.07071 | -0.03493 | 0.18292 | -0.41304 |
| Topic3 | -0.08365 | -0.02078 | 0.07071 | 0.03358 | 0.8453 | 0.2189 | |||
| Topic4 | -0.34176 | -0.21225 | -0.15182 | -0.09671 | -0.02078 | -0.05205 | -0.18016 | ||
| Topic5 | -0.32022 | 1.7942 | 0.4079 | -0.08622 | -0.3467 | -0.15182 | 0.44242 | -0.02975 | -0.04723 |
| Topic6 | 0.37351 | 1.7942 | 0.20131 | 0.30842 | -0.24983 | -0.15182 | -0.28952 | -0.2448 | -0.32582 |
| Topic7 | -0.08365 | -0.3467 | -0.29603 | 0.03358 | 0.49377 | 0.2081 | |||
| Topic8 | 0.37351 | 1.7942 | 0.20131 | 0.30842 | 0.8453 | 1.76703 | 0.50794 | 0.04176 | 1.19012 |
| Topic9 | 0.12128 | 0.11612 | 0.20131 | 0.2081 | 0.91882 | -0.15182 | -0.28952 | -0.2448 | -0.45186 |
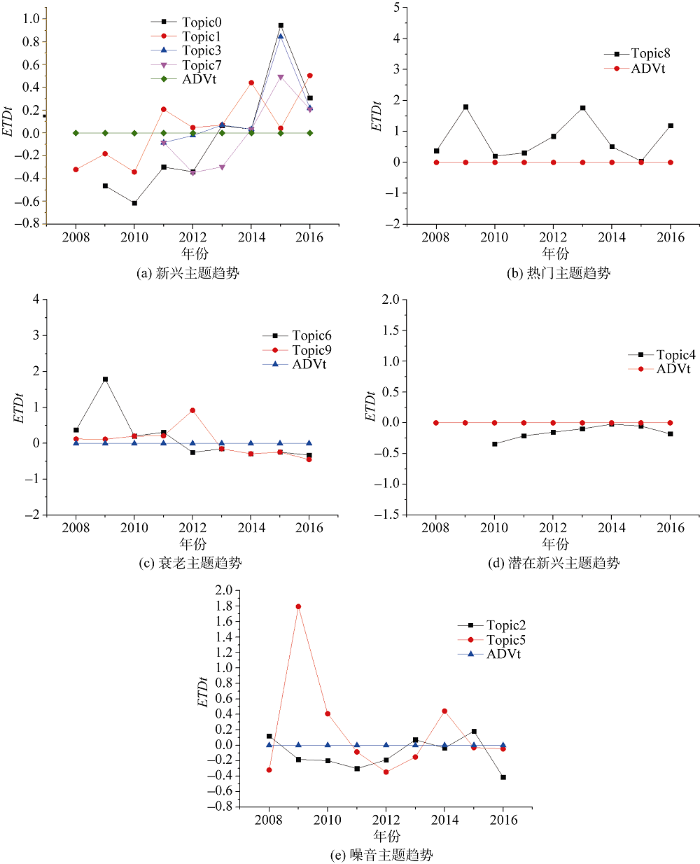
分析可得, Topic0、Topic1、Topic3以及Topic7为新兴势主题, 存在两组噪音数据分别为Topic2与Topic5, Topic8为持续热门主题, Topic6与Topic9在主题发展前期高于平均值, 后期发展滞后低于均值, 因此判定为衰老主题, Topic4为潜在新兴主题。利用绘图工具Origin8.0进行函数拟合与曲线绘制, 横坐标为2008年-2016年9个子时期参数, 纵坐标为各个主题的当年度的探测值, 其主题类型按顺序分别为新兴主题、热门主题、衰老主题以及潜在新兴主题和噪音主题, 绘制图形如图3所示。
(3) 新兴趋势分析
利用DTM模型以及依据基金文本特征分析的新兴趋势探测公式得到石墨烯的新兴主题共有4个, 分别为Topic0、Topic1、Topic3、Topic7, 该主题为未来石墨烯领域研究的重要部署领域和优先发展方向。结合新兴主题及相应主题权重对石墨烯领域未来发展趋势进行分析与讨论, 新兴主题及主题词如表8所示。
表8 石墨烯新兴趋势主题及主题词权重列表
| 主题 | 主题词权重列表 |
|---|---|
| Topic0: optical | optical(53)|graphene(21)|radiation(20)|light(18) |investigate(16)|terahertz(14)|infrared(14)|electrical(13)|nanomanufacturing(12)|layer(12) |
| Topic1: detection | detection(36)|water(25)|sensor(21)|system(20)|lead(17) |sensors(14)|based(14)|physics(13)|electrons(11) |
| Topic3: energy | energy(28)|material(26)|chemistry(23)|program(19) |infrared(19)|project(18)|faculty(14)|chemical(13) |stem(13)|precursor(11) |
| Topic7: chemistry | chemistry(23)|graphene(19)|nanoscale(19)|electrons(18) |properties (17)|separation(17)|nano(16)|surface(16) |storage(15)|energies(14) |
基于本文实验结果, 石墨烯领域新兴趋势研究围绕4方面展开, 如石墨烯光学特性研究分析(optical)、石墨烯探测设备(detection)的研制与开发应用、石墨烯能量储存机制研究与初级粒子分析(energy)以及石墨烯化学制备、化学修饰等技术研究(chemistry)。Topic0中石墨烯光学特性研究将围绕石墨烯电导率、介电常数以及载流子迁移率等光学特性展开, 开发太赫兹(terahertz)通信元件等; 进行光学传感与光储存以及光数据保存等相关研究, 进一步探索石墨烯在光学领域的性质与纳米级制造设备(nanomanufacturing)是该领域的重要发展趋势。Topic1揭示石墨烯探测设备领域发展, 例如基于电子空穴对分离的金属接触性光电探测器、利用离子体载流的共振型光电探测器以及双栅极型探测器和微腔探测等光电探测装置的应用与开发, 目前基于石墨烯探测器检测波幅范围进一步拓展, 可探测紫外线到红外波的光, 因此, 该领域具有较为广泛的前景和应用路径, 将成为石墨烯领域未来重要的研究内容。Topic3围绕石墨烯化学特性展开能量储存机制研究, 例如利用电调谐带内跃迁密度研究与探测远红外光线(infrared)的能量存储; 基于石墨烯储能特性对光数据保存并进行光能量的储存、转化与提取。探测石墨烯与光能、化学能等领域相互协同机制, 拓展石墨烯在光学领域的特性与应用是未来发展趋势之一。Topic7是对石墨烯化学制备工艺方法的研究, 探索石墨烯化学特性与相关化学衍生物的性能, 例如在石墨烯材料中添加羧基、羟基等功能基团, 提高其应用性能与特定功能优化, 观察石墨烯纳米材料纤维形貌结构, 转化为导电高分子、金属纳米粒子等复合材料, 该主题研究前景与应用价值较大, 是值得关注的新兴趋势主题。
本文提出基于DTM模型和文本特征分析的基金项目新兴趋势探测方法, 旨在识别具有前瞻价值信息的基金项目文本中新兴趋势主题。首先, 利用DTM模型识别基金数据研究主题; 然后, 分析基金项目的文本特征, 提出资助强度、资助时长与主题强度三要素相融合的新兴趋势探测公式, 并依据主题生命周期相关理论将新兴趋势的发展定性分为潜在阶段与突破阶段, 更好地识别出面向未来发展动向的新兴趋势。最后, 进行NSF资助石墨烯领域的实证研究, 通过文献调查法和领域专家咨询法证明该探测方法的可行性和有效性。
同时本文存在一定不足: 首先根据文本特征分析的资助强度、资助时长以及主题强度要素进行新兴趋势探测, 融合的指标较为片面以及指标权重分配较为主观, 未来研究应进一步丰富和拓展量化指标, 如机构研究水平以及该基金对应论文研究成果等并进一步动态调整验证权重分析, 可更为准确探测基金项目数据; 其次, 本文针对基金项目文本展开研究, 在未来新兴趋势的探测与评估中可进一步研究规划文本等其他分析数据源, 综合评估和分析以为科技政策制定者提供完善而准确的决策参考和决策指导。
徐路路: 数据的获取、清洗与实验, 论文起草;
王效岳: 提出研究框架和研究主题;
白如江: 论文修改;
周彦廷: 部分项目数据的清洗。
所有作者声明不存在利益冲突关系。
支撑数据由作者自储存, E-mail: 706763298@qq.com。
[1] 徐路路. rar.NSF. 石墨烯基金数据.
[2] 徐路路. rar.NSF. 石墨烯DTM模型处理数据.
| [1] |
海量网络学术文献自动分类系统 [J].https://doi.org/10.7536/j.issn.0252-3116.2013.16.022 URL [本文引用: 1] 摘要
随着Internet的发展, 互联网上的学术文献数量呈指数增长,很难为科研工作者所利用,因此亟需一种方法对海量的网络学术文献进行自动的搜集、整理、分类。在前期充分的实验论证 后,设计实现一个海量网络学术文献自动分类系统,该系统使用模块化设计,包括学术文献自动抓取模块、学术文献词-文档矩阵处理模块、本体集成模块以及基于 语义驱动的分类模块。实验证明,该系统可以有效地完成海量学术文献的自动抓取、处理和分类工作。
An Automatic Classification System of Mass Online Academic Literatures [J].https://doi.org/10.7536/j.issn.0252-3116.2013.16.022 URL [本文引用: 1] 摘要
随着Internet的发展, 互联网上的学术文献数量呈指数增长,很难为科研工作者所利用,因此亟需一种方法对海量的网络学术文献进行自动的搜集、整理、分类。在前期充分的实验论证 后,设计实现一个海量网络学术文献自动分类系统,该系统使用模块化设计,包括学术文献自动抓取模块、学术文献词-文档矩阵处理模块、本体集成模块以及基于 语义驱动的分类模块。实验证明,该系统可以有效地完成海量学术文献的自动抓取、处理和分类工作。
|
| [2] |
从“跟跑者”向“并行者” “领跑者”转变 [EB/OL]. [ |
| [3] |
国际科技前沿分析的方法和途径 [J].
<html dir="ltr"><head><title></title></head><body>指出国际科技前沿是世界科技强国的科技规划、战略、路线图、资助机构通过各类计划、项目最新资助的战略投资重点领域,这些战略投资重点领域代表了国际科技发展趋势,反映了科技强国政府、主流科技共同体和决策者的所思、所想、所为,直接反映国际科技前沿领域或科技前沿主题。认为国际科技前沿可划分为未来科技前沿和当前科技前沿。探讨未来科技前沿和当前科技前沿的分析方法、实施途径、获取信息的渠道,结合近年在学科战略情报服务中的实践工作,梳理并整理归纳一个遴选和确定符合我国国情的目标领域的分析框架,希望对以后的工作有所借鉴。</body></html>
Methods and Approaches of International S&T Front Analysis [J].
<html dir="ltr"><head><title></title></head><body>指出国际科技前沿是世界科技强国的科技规划、战略、路线图、资助机构通过各类计划、项目最新资助的战略投资重点领域,这些战略投资重点领域代表了国际科技发展趋势,反映了科技强国政府、主流科技共同体和决策者的所思、所想、所为,直接反映国际科技前沿领域或科技前沿主题。认为国际科技前沿可划分为未来科技前沿和当前科技前沿。探讨未来科技前沿和当前科技前沿的分析方法、实施途径、获取信息的渠道,结合近年在学科战略情报服务中的实践工作,梳理并整理归纳一个遴选和确定符合我国国情的目标领域的分析框架,希望对以后的工作有所借鉴。</body></html>
|
| [4] |
Latent Dirichlet Allocation [J]. |
| [5] |
PLDA: Parallel Latent Dirichlet Allocation for Large-Scale Applications [C] // |
| [6] |
Topical N-Grams: Phrase and Topic Discovery, with an Application to Information Retrieval [C]// |
| [7] |
Studying the History of Ideas Using Topic Models [C]// |
| [8] |
Dynamic Topic Models [C]// |
| [9] |
Adding Community and Dynamic to Topic Models [J].https://doi.org/10.1016/j.joi.2011.11.004 URL [本文引用: 1] 摘要
The detection of communities in large social networks is receiving increasing attention in a variety of research areas. Most existing community detection approaches focus on the topology of social connections (e.g., coauthor, citation, and social conversation) without considering their topic and dynamic features. In this paper, we propose two models to detect communities by considering both topic and dynamic features. First, the Community Topic Model (CTM) can identify communities sharing similar topics. Second, the Dynamic CTM (DCTM) can capture the dynamic features of communities and topics based on the Bernoulli distribution that leverages the temporal continuity between consecutive timestamps. Both models were tested on two datasets: ArnetMiner and Twitter. Experiments show that communities with similar topics can be detected and the co-evolution of communities and topics can be observed by these two models, which allow us to better understand the dynamic features of social networks and make improved personalized recommendations.
|
| [10] |
Continuous Time Dynamic Topic Models [C]// |
| [11] |
Online Multiscale Dynamic Topic Models [C]// |
| [12] |
Methodologies for Trend Detection in Textual Data Mining [J].
ABSTRACT We present two methodologies for the detection of emerging trends in the area of textual data mining. These manual methods are intended to help us improve the performance of our existing fully automatic trend detection system [3].
|
| [13] |
Networks of Scientific Papers [J].https://doi.org/10.1126/science.149.3683.510 URL [本文引用: 1] |
| [14] |
A Survey of Emerging Trend Detection in Textual Data Mining [J]. |
| [15] |
Emerging Trend Detection from Scientific Online Documents [D]. |
| [16] |
基于LDA与新兴主题特征分析的新兴主题探测研究 [J].https://doi.org/10.3772/j.issn.1000-0135.2014.07.003 URL [本文引用: 3] 摘要
本文尝试基于LDA主题模型探测文档集中的新兴主题.本文采用主题的新颖度、发文量指标,并引入被引量,得到新兴主题的特征指标,在此基础上对主题在进入成熟阶段前各个时期的特征进行了分析.并提出了针对上述新兴主题探测指标,基于LDA主题模型抽取文档的语义主题词,利用文档-主题矩阵建立主题和文档的映射,得到主题的新颖度指标和发文量指标、被引量指标,并形成新兴主题探测表格和探测曲线VDP,从而探测出新兴主题,并对新兴主题VDP与基线VDP距离的发展趋势进行预测,根据拟合的曲线对其进行分析,得到最值得关注的新兴主题.
Detection of Emerging Topics Based on LDA and Feature Analysis of Emerging Topics [J].https://doi.org/10.3772/j.issn.1000-0135.2014.07.003 URL [本文引用: 3] 摘要
本文尝试基于LDA主题模型探测文档集中的新兴主题.本文采用主题的新颖度、发文量指标,并引入被引量,得到新兴主题的特征指标,在此基础上对主题在进入成熟阶段前各个时期的特征进行了分析.并提出了针对上述新兴主题探测指标,基于LDA主题模型抽取文档的语义主题词,利用文档-主题矩阵建立主题和文档的映射,得到主题的新颖度指标和发文量指标、被引量指标,并形成新兴主题探测表格和探测曲线VDP,从而探测出新兴主题,并对新兴主题VDP与基线VDP距离的发展趋势进行预测,根据拟合的曲线对其进行分析,得到最值得关注的新兴主题.
|
| [17] |
从美国国家科学基金会近年资助的理论与计算化学项目看该领域的发展趋势 [J].https://doi.org/10.3969/j.issn.1000-8217.2005.05.008 URL [本文引用: 1] 摘要
简要分析了美国国家科学基金会近年来对理论与计算化学项目的资助情况并与我国国家自然科学基金委员会对该领域的支持项目进行了简单对比。
View of the Development Trend in This Field from the Theoretical and Computational Chemistry Projects Funded by the National Science Foundation of the United States in Recent Years [J].https://doi.org/10.3969/j.issn.1000-8217.2005.05.008 URL [本文引用: 1] 摘要
简要分析了美国国家科学基金会近年来对理论与计算化学项目的资助情况并与我国国家自然科学基金委员会对该领域的支持项目进行了简单对比。
|
| [18] |
我国图书馆、情报与档案管理学科的研究现状——基于2000-2006年国家社会科学基金和自然科学基金立项的分析 [J].https://doi.org/10.3969/j.issn.1000-7490.2007.06.010 URL [本文引用: 1] 摘要
以"图书馆、情报与档案管理"一级学科2000年以来的国家社会科学基金和自然科学基金项目为研究对象,从项目数量、项目类型、负责人及其单位、项目主题等方面进行了全面系统的比较分析,在此基础上探讨该学科的研究现状,并预测其未来走势,以期能对该学科的研究有一定的参考和启示作用,达到促进学科建设和发展的目的。
The Research Status of National Library, Information and Archives Management Discipline Based on the Analysis of the National Social Science Fund and the Natural Science Foundation from 2000 to 2006 [J].https://doi.org/10.3969/j.issn.1000-7490.2007.06.010 URL [本文引用: 1] 摘要
以"图书馆、情报与档案管理"一级学科2000年以来的国家社会科学基金和自然科学基金项目为研究对象,从项目数量、项目类型、负责人及其单位、项目主题等方面进行了全面系统的比较分析,在此基础上探讨该学科的研究现状,并预测其未来走势,以期能对该学科的研究有一定的参考和启示作用,达到促进学科建设和发展的目的。
|
| [19] |
透视“图书馆、情报与档案管理”学科的研究主题与趋势——以2001-2012年国家科学基金为研究视角 [J].Perspective on the Subject and Trend of the “Library, Information and Archives Management”: A Perspective of the National Science Foundation from 2001 to 2012 [J]. |
| [20] |
我国图书情报与档案管理学科研究现状剖析——基于2009-2013年国家自然科学基金和国家社会科学基金立项的分析 [J].https://doi.org/10.13266/j.issn.0252-3116.2014.09.004 URL [本文引用: 1] 摘要
以图书情报与档案管理学科2009-2013年的国家社会科学基金和国家自然科学基金项目立项情况为研究对象,从立项数量、立项类型、立项单位及其所属行业、项目负责人以及项目的主题内容特征等方面进行系统分析比较,在此基础上探讨该学科的研究现状和研究热点,并预测其未来的发展趋势。
Analysis on the Research Status of Library Information and Document Management Science in China: Based on Projects Granted by the National Natural Science Foundation of China and the National Social Science Foundation of China from 2009 to 2013 [J].https://doi.org/10.13266/j.issn.0252-3116.2014.09.004 URL [本文引用: 1] 摘要
以图书情报与档案管理学科2009-2013年的国家社会科学基金和国家自然科学基金项目立项情况为研究对象,从立项数量、立项类型、立项单位及其所属行业、项目负责人以及项目的主题内容特征等方面进行系统分析比较,在此基础上探讨该学科的研究现状和研究热点,并预测其未来的发展趋势。
|
| [21] |
美国NSF资助物流项目的知识图谱分析 [J].Knowledge Mapping Analysis on the Logistics Projects Founded by National Science Foundation in the United States [J]. |
| [22] |
Indices of Novelty for Emerging Topic Detection [J].https://doi.org/10.1016/j.ipm.2011.07.006 URL [本文引用: 2] 摘要
Emerging topic detection is a vital research area for researchers and scholars interested in searching for and tracking new research trends and topics. The current methods of text mining and data mining used for this purpose focus only on the frequency of which subjects are mentioned, and ignore the novelty of the subject which is also critical, but beyond the scope of a frequency study. This work tackles this inadequacy to propose a new set of indices for emerging topic detection. They are the novelty index (NI) and the published volume index (PVI). This new set of indices is created based on time, volume, frequency and represents a resolution to provide a more precise set of prediction indices. They are then utilized to determine the detection point (DP) of new emerging topics. Following the detection point, the intersection decides the worth of a new topic. The algorithms presented in this paper can be used to decide the novelty and life span of an emerging topic in a specific field. The entire comprehensive collection of the ACM Digital Library is examined in the experiments. The application of the NI and PVI gives a promising indication of emerging topics in conferences and journals.
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}