1 引 言
在当今的大数据时代, 信息过载问题日益突出, 面对海量的信息, 用户需要消耗大量的时间挑选一个物品。为了解决这个问题, 目前主要有两大研究方向: 搜索引擎和推荐系统。通过搜索引擎进行信息检索是建立在目标明确的基础之上, 然而很多时候用户无法准确描述自己的需求, 这时搜索引擎便不能达到预期的效果, 而推荐系统可以利用数据组织与分析技术, 为用户提供精准的个性化推荐服务。目前的推荐技术主要包括基于协同过滤算法的推荐、基于内容的推荐、基于知识的推荐和混合推荐, 其中协同过滤是最成功的推荐算法之一[1 ] 。协同过滤推荐算法不需要搜集到用户和项目的属性信息, 只根据用户的历史评论数据就可以预测用户可能感兴趣的项目, 因此该算法广泛应用于电子商务和互联网推荐系统中, 例如Amazon和Google等。传统的协同过滤算法的思想是通过相似度的计算, 找到目标用户的最近邻, 预测要推荐项目的评分, 然后进行Top-N推荐。但是传统的协同过滤算法计算用户相似度时可分辨性不高, 即对于不同用户的评分向量与目标用户进行相似度计算时, 可能得到相同的相似度; 同时用户的兴趣偏好往往随着时间的推移发生缓慢甚至剧烈的变化, 这些因素都会导致推荐结果偏离用户的实际需求。因此, 本文提出一种基于灰色关联分析和时间因素的协同过滤算法以提高传统协同过滤算法的精度。
2 文献综述
当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量。Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] 。Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] 。Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] 。朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] 。Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] 。Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] 。董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] 。李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] 。陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] 。吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] 。兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] 。杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] 。曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] 。杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] 。邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] 。赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] 。
上述一些改进算法在融合时间因素后均在一定程度上提高了推荐精度, 但没有考虑用户相似度的可分辨性问题, 即计算其他用户与目标用户的相似度时, 不同的评分向量可能得到相同的相似度, 甚至出现计算出的相似度与实际相似度相悖的情况, 如果能提高用户相似度的可分辨性, 推荐精度则可以进一步提高。本文在文献[14,18]等基础上, 提出一种基于灰色关联分析和时间因素的协同过滤算法, 首先利用灰色关联系数进行相似度计算, 由于灰色关联相似度的值是离散分布状态, 因此可以在一定程度上提高相似度的可分辨性, 然后引入时间权重函数计算出评论的时间权重以改进Pearson相关系数相似度, 最后将两种相似度计算方法结合起来形成混合相似度, 据此选取目标用户的近邻并做出推荐。
3 相关准备工作
3.1 传统用户相似度的计算方法
协同过滤算法的核心部分是计算目标用户与评分矩阵中各用户的相似度, 然后将各个相似度进行排序, 较高相似度的用户群作为目标用户的近邻集, 其中相似度计算方法主要有以下三种[19 ] 。
(1) 余弦相似度计算公式
用户间的相似度可以通过向量间的夹角余弦值进行度量, 余弦相似度计算如公式(1)所示。
$sim(u,v)=\frac{(a,b)}{\left| a \right|\left| b \right|}$ (1)
其中, a 和 b 分别表示用户u 和用户v 在n 维项目空间上的评分向量。
(2) Pearson相关系数相似度计算公式
Pearson相关系数(Pearson Correlation Coefficient)用来衡量两个数据集合是否在一条线上, 即衡量定距变量间的线性关系, 其相似度计算如公式(2)所示。
$sim(u,v)=\frac{\sum\limits_{i\in {{I}_{uv}}}{({{R}_{u,i}}-{{{\bar{R}}}_{u}})({{R}_{v,i}}-{{{\bar{R}}}_{v}})}}{\sqrt{\sum\limits_{i\in {{I}_{uv}}}{{{({{R}_{u,i}}-{{{\bar{R}}}_{u}})}^{2}}}}\sqrt{\sum\limits_{i\in {{I}_{uv}}}{{{({{R}_{v,i}}-{{{\bar{R}}}_{v}})}^{2}}}}}$ (2)
其中, Iuv 表示用户u 和用户v 共同评分的项目集合, Ru , i Rv , i u 和用户v 对项目i 的评分, ${{\bar{R}}_{u}}$和${{\bar{R}}_{v}}$分别表示用户u 和用户v 对已评价项目的平均评分。
(3) 修正的余弦相似度计算公式
余弦相似性度量方法中没有考虑不同用户的评分尺度问题, 修正的余弦相似性度量方法通过减去用户对项目的平均评分以改善上述缺陷。
$sim(u,v)=\frac{\sum\limits_{i\in {{I}_{uv}}}{({{R}_{u,i}}-{{{\bar{R}}}_{u}})({{R}_{v,i}}-{{{\bar{R}}}_{v}})}}{\sqrt{\sum\limits_{i\in {{I}_{u}}}{{{({{R}_{u,i}}-{{{\bar{R}}}_{u}})}^{2}}}}\sqrt{\sum\limits_{i\in {{I}_{v}}}{{{({{R}_{v,i}}-{{{\bar{R}}}_{v}})}^{2}}}}}$ (3)
其中, Iuv 表示用户u 和用户v 共同评分的项目集合, Iu 为用户u 评分的项目集合, Iv 为用户v 评分的项目集合, Ru , i Rv , i u 和用户v 对项目i 的评分, ${{\bar{R}}_{u}}$和${{\bar{R}}_{v}}$分别表示用户u 和用户v 对已评价项目的平均评分。
3.2 相似度计算的可分辨性问题
假设推荐系统中有两个用户(u 1 , u 2 )和4个项目ik (k =1,2,3,4), 以下为两个用户在4种情况下的用户-项目评分矩阵:
${{R}_{1}}=\left[ \begin{matrix} 0 & 4 \\ 4 & 4 \\\end{matrix} \right.\ \ \ \ \left. \begin{matrix} 4 & 0 \\ 4 & 0 \\\end{matrix} \right]$ ${{R}_{2}}=\left[ \begin{matrix} 0 & 4 \\ 0 & 4 \\\end{matrix} \right.\ \ \ \ \left. \begin{matrix} 4 & 0 \\ 4 & 4 \\\end{matrix} \right]$
${{R}_{3}}=\left[ \begin{matrix} 3 & 4 \\ 2 & 5 \\\end{matrix} \right.\ \ \ \ \left. \begin{matrix} 3 & 4 \\ 2 & 5 \\\end{matrix} \right]$ ${{R}_{4}}=\left[ \begin{matrix} 4 & 3 \\ 3 & 4 \\\end{matrix} \right.\ \ \ \ \left. \begin{matrix} 4 & 3 \\ 3 & 4 \\\end{matrix} \right]$
观察可知, R 1 和R 2 是两个不同的评分矩阵, 但应用公式(1)计算后发现用户u 1 的行向量和用户u 2 的行向量在R 1 和R 2 的情况下相似度相同; 评分矩阵R 3 中的行向量是线形相关的, 利用公式(2)计算出的相似度为1, 但两个用户的相似度并没有按公式计算出的那么高; 评分矩阵R 4 利用公式(2)计算出的相似度为-1, 两个用户的相似度很低, 然而通过观察两个矩阵可以发现他们有较高的相似度。也就是说, 计算其他用户与目标用户的相似度时, 不同的评分向量可能得到相同的相似度, 也可能出现计算出的相似度与实际相似度相悖的情况, 这就是计算相似度时存在的可分辨性问题。由此可见, 按传统相似度公式计算出的结果无法准确反映用户评分实际的相似度, 这种情况的存在会对推荐精度造成很大的影响。本文引入灰色关联度来解决用户相似度计算中的可分辨性问题。
3.3 灰色关联度
首先给出灰色关联系数和灰色关联度的定义。
定义1 记推荐系统中消除量纲的序列分别为: {y 1 (t )}, {y 2 (t )}, {y 3 (t )},…, {yn (t )}, n 个序列既可表示用户序列也可表示项目序列, 即:
Y 1 ={y 1 (1), y 1 (2), y 1 (3),…, y 1 (t )}, Y 2 ={y 2 (1), y 2 (2), y 2 (3),…, y 2 (t )}, Y 3 ={y 3 (1), y 3 (2), y 3 (3),…, y 3 (t )},……, Yn ={yn (1), yn (2), yn (3),…, yn (t )}.
(1) 选取{y 1 (t )}为母序列, 其余为子序列, 将原始数据做初值化处理[18 ] 。
${{Y}^{}}_{1}=\left\{ \frac{{{y}_{1}}(1)}{{{y}_{1}}(1)},\frac{{{y}_{1}}(2)}{{{y}_{1}}(1)},\frac{{{y}_{1}}(3)}{{{y}_{1}}(1)},...,\frac{{{y}_{1}}(t)}{{{y}_{1}}(1)} \right\}=\{1,{{y}^{}}_{1}(2),{{y}^{}}_{1}(3),\cdots ,{{y}^{}}_{1}(t)\}$
${{Y}^{}}_{2}=\left\{ \frac{{{y}_{2}}(1)}{{{y}_{2}}(1)},\frac{{{y}_{2}}(2)}{{{y}_{2}}(1)},\frac{{{y}_{2}}(3)}{{{y}_{2}}(1)},...,\frac{{{y}_{2}}(t)}{{{y}_{2}}(1)} \right\}=\{1,{{y}^{}}_{2}(2),{{y}^{}}_{2}(3),\cdots ,{{y}^{}}_{2}(t)\}$
${{Y}^{}}_{3}=\left\{ \frac{{{y}_{3}}(1)}{{{y}_{3}}(1)},\frac{{{y}_{3}}(2)}{{{y}_{3}}(1)},\frac{{{y}_{3}}(3)}{{{y}_{3}}(1)},...,\frac{{{y}_{3}}(t)}{{{y}_{3}}(1)} \right\}=\{1,{{y}^{}}_{3}(2),{{y}^{}}_{3}(3),\cdots ,{{y}^{}}_{3}(t)\}$
…… ……
${{Y}^{}}_{n}=\left\{ \frac{{{y}_{n}}(1)}{{{y}_{n}}(1)},\frac{{{y}_{n}}(2)}{{{y}_{n}}(1)},\frac{{{y}_{n}}(3)}{{{y}_{n}}(1)},...,\frac{{{y}_{n}}(t)}{{{y}_{n}}(1)} \right\}=\{1,{{y}^{}}_{n}(2),{{y}^{}}_{n}(3),\cdots ,{{y}^{}}_{n}(t)\}$
(2) 计算各子序列同母序列的绝对差, 计算公式为: △1 i y ‘ 1 (t )-y ‘ i t )|(i =2,3,…,n ; t =1,2,…,n ), 绝对差值计算结果如表1 所示[18 ] 。
从表1 中找出最大值和最小值: △min =0; △max = △max (t )。
(3) 计算关联系数[18 ] :
${{r}_{1i}}=\frac{{{\Delta }_{\min }}+\rho {{\Delta }_{\max }}}{{{\Delta }_{1i}}(t)+\rho {{\Delta }_{\max }}}=\frac{\rho {{\Delta }_{\max }}}{{{\Delta }_{1i}}(t)+\rho {{\Delta }_{\max }}}\text{ }(i=2,3,\cdots ,n)$ (4)
其中, △1 i t )表示母序列和序列i 在第t 个用户的绝对差, ρ ∈(0,1)称为分辨系数, 一般情况下ρ 可取0.1-0.5, ρ 的作用是为消除△max 值过大从而使计算的关联系数r 1 i ρ 的大小得到不同的关联系数, 关联系数计算结果如表2 所示。
定义2 n 个序列Y 1 , Y 2 ,…, Yn 的灰色关联度定义为如公式(5)[18 ] 所示。
${{R}_{ij}}=\frac{1}{n}\sum\limits_{t=1}^{n}{{{r}_{ij}}}(t)$ (5)
其中, n 为两序列数据的个数, rij 为两序列在各点的关联系数。计算母序列同各个子序列的关联度之后, 对关联度进行相关排序, Rij 值越大说明两个序列的相关度越大。
3.4 时间权重函数
考虑到用户兴趣漂移问题的存在, 即用户兴趣往往随着时间的推移而发生变化, 用户近期的评分更能体现其当前的兴趣偏好, 所以一个用户在不同时间的评分对推荐系统产生的影响是不同的, 最近的评分相对于以前的评分更有参考价值, 应该被赋以更高的权重。基于以上分析, 参考文献[14 ], 引入时间权重函数, 如公式(6)所示。
$w(t({{r}_{v,i}}))={{e}^{-[\frac{({{\tau }_{0}}-t({{r}_{v,i}}))}{\lambda }]}}$ (6)
其中, t (rv , i v 对项目i 的评分时间, τ0 表示训练集中评分时的最大时间, λ 表示时间权重。w 取值范围为0-1, 也就是说时间权重函数的值域是[0,1]。可以看出, 用户的评分时间距离当前越近w 就越大; 评分时间权重λ 越大, w 随时间衰减得就越慢。
4 基于灰色关联分析和时间权重函数的协同过滤算法
4.1 混合相似度的计算
首先, 通过灰色关联分析法计算灰色关联相似度作为用户之间的相似度, 由于灰色关联相似度是由离散的关联系数平均值组成, 所以在一定程度上可以提高用户间相似度的可分辨性; 然后, 将灰色关联相似度和公式(9)中的相似度通过调节参数连接起来, 得到混合相似度的计算方法。
(1) 基于灰色关联分析的相似度计算方法
在给出计算方法之前, 首先介绍灰色关联度的两个性质。
设两个序列Y 1 , Y 2 , Y 3 , 则Y 1 、Y 2 两个序列的关联度R 12 和Y 2 、Y 1 的关联度R 21 相等, 即R 12 =R 21 ; 如果R 12 ≥R 13 , R 13 ≥R 23 , 那么有R 12 ≥R 23 。
参考文献[16,18], 本文提出基于灰色关联分析法的用户相似度计算方法, 步骤如下:
①确定n 个用户序列Y 1 , Y 2 ,…, Yn , 对n 个用户序列进行初值化操作。
②选取评分矩阵中的母序列Yu , 即为目标用户, 计算目标用户序列和其余用户序列的绝对差, 由于初值化操作, △min =0, 则目标用户u 和其余用户v (v =1,2,…,n ; v≠u )之间关于项目t (t =1,2,…,m )的灰色关联系数如公式(7)[16 ] 所示。
${{r}_{uv}}(t)=\frac{\rho {{\Delta }_{\max }}}{{{\Delta }_{1i}}(t)+\rho {{\Delta }_{\max }}}$ (7)
③借鉴文献[16 ]中比较向量与参考向量之间关系密切程度的计算方法, 本文提出利用序列之间的关联系数计算目标用户u 和其余用户v 的相似度, 如公式(8)所示。
$si{{m}_{1}}(u,v)=\frac{1}{n}\sum\limits_{t=1}^{n}{{{r}_{uv}}(t)}$ (8)
(2) 基于时间权重函数的相似度计算方法
分析用户评分数据时, 通过引入时间权重函数, 给近期的评分赋以更高的权重, 相对久远的评分赋以较低的权重, 这样可以消除时间因素对推荐系统的影响, 提高推荐精度。根据以上分析, 本文在传统的Pearson公式中引入时间权重函数, 提出修正的相似度计算方法, 如公式(9)所示。
$\begin{align} & si{{m}_{2}}(u,v)= \\ & \frac{\sum\limits_{i\in {{I}_{uv}}}{({{R}_{u,i}}-\overline{{{R}_{u}}}})({{R}_{v,i}}-\overline{{{R}_{v}}})W(t({{r}_{u,i}}))W(t({{r}_{v,i}}))}{\sqrt{\sum\limits_{i\in {{I}_{uv}}}{({{R}_{u,i}}-\overline{{{R}_{u}}}}{{)}^{2}}W{{(t({{r}_{u,i}}))}^{2}}}\sqrt{\sum\limits_{i\in {{I}_{uv}}}{({{R}_{v,i}}-\overline{{{R}_{v}}}}{{)}^{2}}W{{(t({{r}_{v,i}}))}^{2}}}} \\ \end{align}$(9)
(3) 混合相似度计算方法
通过考虑灰色关联分析和时间因素, 在传统的协同过滤算法的基础上进行修正, 本文将两个相似度通过调节参数$\alpha $连接起来, 提出一种混合相似度的计算方法, 也就是将公式(8)和公式(9)进行线性组合, 得到目标用户和其他用户之间的最终的混合相似度, 其计算如公式(10)所示。
$sim'(u,v)=\alpha \ si{{m}_{1}}(u,v)+(1-\alpha )\ si{{m}_{2}}(u,v)$ (10)
其中, $\alpha $是调节参数$\text{ }(0<\alpha <1)$, 当推荐系统中用户兴趣不会随着时间发生改变且评分数据比较有限的情况下, 应提高灰色关联相似度的权重, 此时$\alpha $趋于1; 当推荐系统中评分数据比较多时, 几乎不用考虑数据的稀疏性以及相似度的分辨性问题, 仅仅考虑时间因素就可以提高传统协同过滤算法的推荐精度, 此时$\alpha $趋于0[20 ,21 ] 。
4.2 推荐的产生
根据上述方法可以得出目标用户u 和其他用户v 之间的混合相似度sim '(u ,v ), 选取相似度最高的前N 个用户作为目标用户的最近邻集合M , 在文献[19 ]的基础上, 结合本文提出的混合相似度计算方法对原预测评分公式做出改进, 计算目标用户u 对项目i 的预测评分, 改进后的计算公式如公式(11)所示。
$pred(u,i)=\overline{{{R}_{u}}}+\frac{\sum\limits_{v\in M}{[({{R}_{v,i}}-\overline{{{R}_{v}}})sim'(u,v)]}}{\sum\limits_{v\in M}{[sim'(u,v)]}}$ (11)
其中, M 表示用户u 的最近邻集合, ${{\bar{R}}_{u}}$和${{\bar{R}}_{v}}$分别表示用户u 和用户v 对已评价项目的平均评分, sim '(u ,v )是用户u 和用户v 的混合相似度。
获取目标用户u 对候选项目预测评分最高的前N 个项目作为推荐项目集, 并将其推荐给目标用户u 。
4.3 算法步骤
本文提出的基于灰色关联分析和时间因素的协同过滤算法的输入数据包含: m 个用户对n 个项目的评分矩阵R (m ,n ), 分辨系数ρ , 评分时间t (rv , i τ 0 , 调节参数$\alpha $, 最近邻居数N ; 输出的则是针对目标用户u 的Top-N 推荐项目集。整个过程可以划分为以下4个步骤:
(1) 灰色关联系数和灰色关联度的定义如公式(4)和公式(5)所示, 利用灰色关联系数得出用户灰色关联度相似度公式, 如公式(8)所示。
(2) 建立时间权重函数。利用公式(6)给出时间权重函数, 用来改进传统的Pearson相关相似度计算方法, 如公式(9)所示; 再结合灰色关联相似度得出混合的相似度计算公式, 如公式(10)所示。
(3) 查找最近邻居集。根据目标用户和其余用户相似度的大小, 选取相似度最高的前N 个用户作为目标用户的最近邻居集。
(4) 预测与推送。利用公式(11)根据目标用户与最近邻居集的相似度大小加权计算要推荐项目的评分, 选取前N 项作为Top-N 项目推送给目标用户。
5 实验与结果分析
5.1 数据集
实验采用MovieLens站点(http://movielens.umn.edu)提供的测试数据集。它由美国明尼苏达大学计算机科学与工程学院的GroupLens项目组创办, 接受网络用户对电影的评分并为用户做出推荐, 要求每个用户至少为20部电影评分。这个数据集包括943个用户对 1 682部电影的评分, 评分范围为1-5分, 评分越高, 用户对评分电影的偏好就越高。该数据集的稀疏程度为92.76%。仿真实验随机抽取90%数据作为训练集, 另外10%数据作为测试集。
5.2 评价标准
推荐精度的度量标准主要有统计精度度量方法和决策支持精度度量方法两类, 本实验采用统计精度度量标准中使用最广泛的平均绝对误差(Mean Absolute Error, MAE)作为度量推荐精度的标准。平均绝对误差度量的是预测评分与实际评分之间的偏差, 偏差越小, 算法的推荐精度越高。假设用户对项目的预测评分集合为{P 1 ,P 2 ,…,Pn }, 而相应的用户实际评分集合为{R 1 ,R 2 ,…,Rn }。MAE的计算如公式(12)[16 ] 所示。
$MAE=\frac{\sum\limits_{i=1}^{n}{\left| {{P}_{i}}-{{R}_{i}} \right|}}{n}$ (12)
其中, Pi 表示预测的用户评分, Ri 表示实际的用户评分。
5.3 实验结果分析
本文提出的推荐算法中有两个参数需要确定, 即分辨系数ρ 和调节参数α 。根据这两个参数对算法推荐精度的影响在训练集中确定它们的取值, 并对比在不同近邻数目下传统的协同过滤算法、基于灰色关联分析的协同过滤算法、基于时间因素的协同过滤算法和本文混合算法的推荐精度。
(1) 引入灰色关联分析的理论是为了解决用户相似度可分辨性问题以提高推荐精度, 实验中分辨系数ρ 的取值对MAE的影响如图1 所示。
实验结果表明, 分辨系数为0.35时MAE值为0.61, 即当ρ 取0.35时推荐效果最理想。
(2) 调节参数α 的取值关系到GC-CF和TF-CF在混合算法中的比重, α 为0时, 混合算法只考虑了时间因素, α 为1时, 混合算法只考虑了灰色关联度。调节参数α 取值对MAE的影响如图2 所示。
实验结果表明, α 为0.7时MAE值为0.62, 即当α 取0.7时混合推荐算法的效果最理想。
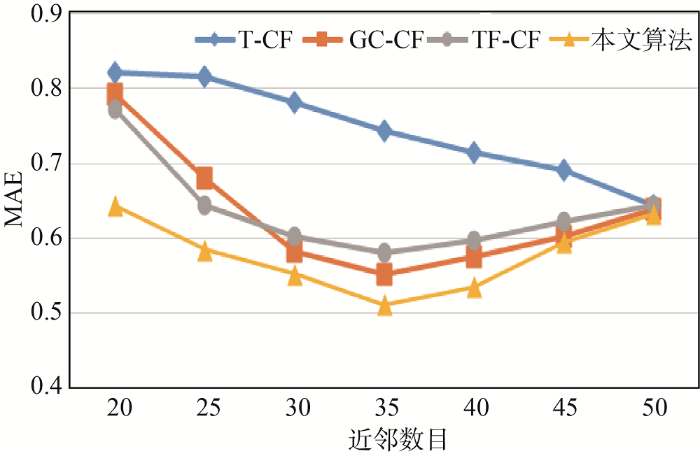
(3) 在确定分辨系数ρ 和调节参数α 的取值之后, 为了验证本文提出的混合相似度计算方法的有效性, 实验以传统的协同过滤算法(T-CF)、基于灰色关联分析的协同过滤算法(GC-CF)和基于时间因素的协同过滤算法(TF-CF)作为对照。根据Herlocker等的研究结果, 最近邻用户数量设为20-50比较合理[22 ] 。因此, 本实验比较了4种算法在最近邻数量为20、25、30、35、40、45和50的情况下MAE的值, 结果如图3 所示。
实验表明, 当近邻数目为35时, MAE值分别是0.744、0.552、0.581和0.522, 本文提出的基于灰色关联分析和时间因素的混合推荐算法在不同近邻数下推荐精确度均优于推荐算法T-CF、GC-CF和TF-CF, 而且从图3 还可以看出, 近邻数为35时推荐效果最佳。
6 结 语
本文提出一种基于灰色关联分析和时间因素的协同过滤算法, 改进了传统协同过滤算法中用户相似度的计算方法, 给出基于灰色关联度的用户相似度计算方法, 并引入时间权重函数改进Pearson相关系数相似度, 将两种相似度计算方法通过调节参数结合起来形成混合相似度, 以解决用户相似度可分辨性和兴趣漂移问题。采用MovieLens数据集进行测试, 取90%的数据作为训练集调试出分辨系数和调节参数的取值, 在不同近邻数的情况下比较T-CF、GC-CF、TF-CF和本文算法的MAE值。实验表明, 本文算法在不同近邻数目下都优于T-CF、GC-CF和TF-CF, 明显提高了推荐精度, 同时也确定了最佳近邻数。但是, 本文算法的时间复杂性比较高, 混合相似度计算耗时较长, 如何精简算法模型以提高效率将是下一步研究的重点。
作者贡献声明
王道平: 提出论文总体研究思路, 设计研究方案, 撰写论文;
蒋中杨: 参与论文总体思路讨论, 重点完成混合相似度计算部分的写作, 修改论文;
张博卿: 采集、清洗和分析数据。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: jzynice@126.com。
[1] 王道平, 蒋中杨, 张博卿. u.data.txt. 本文训练模型所用用户评论数据集.
[2] 王道平, 蒋中杨, 张博卿. recommendation_data.py. 实验所用代码.
参考文献
文献选项
[1]
Ricci F Rokach L Shapira B et al .Recommender Systems Handbook
[M]. Berlin: Springer , 2011 : 145 -186 .
[本文引用: 1]
[2]
Ariyoshi Y Kamahara J A Hybrid Recommendation Method with Double SVD Reduction
[C]// Proceedings of International Conference on Database Systems for Advanced Applications Database System for Advanced Applications , 2010 : 365 -373 .
[本文引用: 1]
[3]
Wang S Xie Y Fang M A Collaborative Filtering Recommendation Algorithm Based on Item and Cloud Model
[J]. Wuhan University Journal of Natual Sciences , 2011 , 16 (1 ): 16 -20 .
https://doi.org/10.1007/s11859-011-0704-4
URL
[本文引用: 1]
摘要
Recommender system is an important content in the research of E-commerce technology. Collaborative filtering recom-mendation algorithm has already been used successfully at recom-mender system. However,with the development of E-commerce,the difficulties of the extreme sparsity of user rating data have become more and more severe. Based on the traditional similarity measuring methods,we introduce the cloud model and combine it with the item-based collaborative filtering recommendation algorithms. The new collaborative filtering recommendation algorithm based on item and cloud model (IC-Based CF) computes the similarity de-gree between items by comparing the statistical characteristic of items. The experimental results show that this method can improve the performance of the present item-based collaborative filtering algorithm with extreme sparsity of data.
[4]
Ma T Guo L Tang M et al .A Collaborative Filtering Recommendation Algorithm Based on Hierarchical Structure and Time Awareness
[J]. IEICE Transactions on Information & Systems , 2016 , 99 (6 ): 1512 -1520 .
https://doi.org/10.1587/transinf.2015EDP7380
URL
[本文引用: 1]
摘要
Abstract User-based and item-based collaborative filtering (CF) are two of the most important and popular techniques in recommender systems. Although they are widely used, there are still some limitations, such as not being well adapted to the sparsity of data sets, failure to consider the hierarchical structure of the items, and changes in users' interests when calculating the similarity of items. To overcome these shortcomings, we propose an evolutionary approach based on hierarchical structure for dynamic recommendation system named Hierarchical Temporal Collaborative Filtering (HTCF). The main contribution of the paper is displayed in the following two aspects. One is the exploration of hierarchical structure between items to improve similarity, and the other is the improvement of the prediction accuracy by utilizing a time weight function. A unique feature of our method is that it selects neighbors mainly based on hierarchical structure between items, which is more reliable than co-rated items utilized in traditional CF. To the best of our knowledge, there is little previous work on researching CF algorithm by combining object implicit or latent object-structure relations. The experimental results show that our method outperforms several current recommendation algorithms on recommendation accuracy (in terms of MAE).
[5]
朱思丞 , 黄瑛 , 孙志锋 . 推荐算法时间动态特性研究进展
[J]. 工业控制计算机 , 2015 , 28 (8 ): 99 -100 .
URL
[本文引用: 1]
摘要
传统推荐算法没有考虑时间效应的影响,而随着用户兴趣、产品流行度等变化,会使得推荐效果受到影响。近年来,越来越多的研究者开始关注推荐系统动态特性,时间信息对推荐系统有重要的作用,将回顾推荐系统主要算法,研究静态模型存在的问题,详细介绍近年来国内外动态推荐算法的研究进展,为后续研究提供参考。
(Zhu Sicheng Huang Ying Sun Zhifeng Research on Progress of Time-based Dynamic Recommender System
[J]. Industrial Control Computer , 2015 , 28 (8 ): 99 -100 .)
URL
[本文引用: 1]
摘要
传统推荐算法没有考虑时间效应的影响,而随着用户兴趣、产品流行度等变化,会使得推荐效果受到影响。近年来,越来越多的研究者开始关注推荐系统动态特性,时间信息对推荐系统有重要的作用,将回顾推荐系统主要算法,研究静态模型存在的问题,详细介绍近年来国内外动态推荐算法的研究进展,为后续研究提供参考。
[6]
Zhang X L Lee T M D, Pitsilis G . Securing Recommender Systems Against Shilling Attacks Using Social-Based Clustering
[J]. Journal of Computer Science and Technology , 2013 , 28 (4 ): 616 -624 .
https://doi.org/10.1007/s11390-013-1362-0
URL
[本文引用: 1]
摘要
Recommender systems (RS) have been found supportive and practical in e-commerce and been established as useful aiding services. Despite their great adoption in the user communities, RS are still vulnerable to unscrupulous producers who try to promote their products by shilling the systems. With the advent of social networks new sources of information have been made available which can potentially render RS more resistant to attacks. In this paper we explore the information provided in the form of social links with clustering for diminishing the impact of attacks. We propose two algorithms, CluTr and WCluTr, to combine clustering with \trust" among users. We demonstrate that CluTr and WCluTr enhance the robustness of RS by experimentally evaluating them on data from a public consumer recommender system Epinions.com.
[7]
Xia C Jiang X Liu S et al .Dynamic Item-based Recommendation Algorithm with Time Decay
[C]// Proceedings of International Conference on Natural Computation (ICNC 2010). 2010 : 242 -247 .
[本文引用: 1]
[8]
董立岩 , 王越群 , 贺嘉楠 , 等 . 基于时间衰减的协同过滤推荐算法
[J]. 吉林大学学报: 工学版 , 2017 , 47 (4 ): 1268 -1272 .
https://doi.org/10.13229/j.cnki.jdxbgxb201704036
URL
[本文引用: 1]
摘要
针对传统的协同过滤算法在计算相似度时未考虑时间因素的影响,导致推荐结果不准确的问题,本文提出将时间因素融入用户项目评分矩阵中,以解决兴趣衰减的问题。首先将遗忘曲线和记忆周期作为时间因素融入算法之中,将艾宾浩斯遗忘曲线用于指数函数拟合,从而获得时间与兴趣衰减的函数关系,以此用于优化用户项目的评分。并将改进的评分矩阵应用到基于项目的协同过滤推荐算法中进行推荐。在评分中加入记忆周期的影响,让目标用户对待预测的项目评分预测更为准确。实验结果表明,改进后的基于时间衰减协同过滤算法在准确性方面有显著的提高。
(Dong Liyan Wang Yuequn He Jia’nan et al .Collaborative Filtering Recommendation Algorithm Based on Time Decay
[J]. Journal of Jilin University: Engineering and Technology Edition , 2017 , 47 (4 ): 1268 -1272 .)
https://doi.org/10.13229/j.cnki.jdxbgxb201704036
URL
[本文引用: 1]
摘要
针对传统的协同过滤算法在计算相似度时未考虑时间因素的影响,导致推荐结果不准确的问题,本文提出将时间因素融入用户项目评分矩阵中,以解决兴趣衰减的问题。首先将遗忘曲线和记忆周期作为时间因素融入算法之中,将艾宾浩斯遗忘曲线用于指数函数拟合,从而获得时间与兴趣衰减的函数关系,以此用于优化用户项目的评分。并将改进的评分矩阵应用到基于项目的协同过滤推荐算法中进行推荐。在评分中加入记忆周期的影响,让目标用户对待预测的项目评分预测更为准确。实验结果表明,改进后的基于时间衰减协同过滤算法在准确性方面有显著的提高。
[9]
李伟霖 , 王成良 , 文俊浩 . 基于评论与评分的协同过滤算法
[J]. 计算机应用研究 , 2017 , 34 (2 ): 361 -364, 412 .
https://doi.org/10.3969/j.issn.1001-3695.2017.02.009
URL
[本文引用: 1]
摘要
针对传统协同过滤算法中存在的数据稀疏性问题,结合用户评分及用户评论信息的特点,提出了基于评论与评分的user-based协同过滤算法和基于评论与评分的item-based协同过滤算法。该算法利用主题模型产生评论主题分布,利用评分数据生成评论态度影响因子,并通过评论态度影响因子来放大评论主题分布中的突出特征,建立更为准确的用户偏好与物品特征,进而进行评分预测与物品推荐。实验结果表明,该算法在稀疏数据集上可以获得较好的推荐效果,提高了推荐质量。
(Li Weilin Wang Chengliang Wen Junhao Collaborative Filtering Recommendation Algorithm Based on Reviews and Ratings
[J]. Application Research of Computers , 2017 , 34 (2 ): 361 -364, 412 .)
https://doi.org/10.3969/j.issn.1001-3695.2017.02.009
URL
[本文引用: 1]
摘要
针对传统协同过滤算法中存在的数据稀疏性问题,结合用户评分及用户评论信息的特点,提出了基于评论与评分的user-based协同过滤算法和基于评论与评分的item-based协同过滤算法。该算法利用主题模型产生评论主题分布,利用评分数据生成评论态度影响因子,并通过评论态度影响因子来放大评论主题分布中的突出特征,建立更为准确的用户偏好与物品特征,进而进行评分预测与物品推荐。实验结果表明,该算法在稀疏数据集上可以获得较好的推荐效果,提高了推荐质量。
[10]
陈海涛 , 宋姗姗 , 李同强 . 基于用户的改进的协同过滤推荐算法
[J]. 情报理论与实践 , 2015 , 38 (9 ): 100 -103, 133 .
https://doi.org/10.16353/j.cnki.1000-7490.2015.09.020
URL
[本文引用: 1]
摘要
现有的基于用户的协同过滤推荐算法使用用户—项目评分矩阵计算用户的评分相似性作为用户的相似度,存在矩阵稀疏的问题,而且不能对用户的兴趣进行动态衡量。由此提出一种改进的基于用户的协同过滤推荐算法,通过历史数据计算用户对各类项目的购买数量比例矩阵,衡量用户对各类项目的兴趣;根据用户购买项目的时间的先后衡量用户兴趣的动态变化。融合以上两点得出用户兴趣相似性作为用户相似性的权重,改进的用户相似性计算方法避免了用户—项目评分矩阵的稀疏性和不能动态衡量用户兴趣变化的问题。采用Movie Lens数据集进行实验,结果表明该算法提高了推荐结果的准确性并且具有稳定性。
(Chen Haitao Song Shanshan Li Tongqiang Improved User-based Collaborative Filtering Recommendation Algorithm
[J]. Information Studies: Theory & Application , 2015 , 38 (9 ): 100 -103, 133 .)
https://doi.org/10.16353/j.cnki.1000-7490.2015.09.020
URL
[本文引用: 1]
摘要
现有的基于用户的协同过滤推荐算法使用用户—项目评分矩阵计算用户的评分相似性作为用户的相似度,存在矩阵稀疏的问题,而且不能对用户的兴趣进行动态衡量。由此提出一种改进的基于用户的协同过滤推荐算法,通过历史数据计算用户对各类项目的购买数量比例矩阵,衡量用户对各类项目的兴趣;根据用户购买项目的时间的先后衡量用户兴趣的动态变化。融合以上两点得出用户兴趣相似性作为用户相似性的权重,改进的用户相似性计算方法避免了用户—项目评分矩阵的稀疏性和不能动态衡量用户兴趣变化的问题。采用Movie Lens数据集进行实验,结果表明该算法提高了推荐结果的准确性并且具有稳定性。
[11]
吴飞 , 余腊生 , 冯梅 . 基于时间效应的协同过滤算法
[J]. 计算机工程与科学 , 2017 , 39 (11 ): 2095 -2101 .
[本文引用: 1]
(Wu Fei Yu Lasheng Feng Mei A Collaborative Filtering Algorithm Based on Time Effect
[J]. Computer Engineering and Science , 2017 , 39 (11 ): 2095 -2101 .)
[本文引用: 1]
[12]
兰艳 , 曹芳芳 . 面向电影推荐的时间加权协同过滤算法的研究
[J]. 计算机科学 , 2017 , 44 (4 ):295 -301, 322 .
[本文引用: 1]
(Lan Yan Cao Fangfang Research of Time Weighted Collaborative Filtering Algorithm in Movie Recommendation
[J]. Computer Science , 2017 , 44 (4 ): 295 -301, 322 .)
[本文引用: 1]
[13]
杨立 , 胡运红 , 邵桂荣 . 融合时间衰减与偏好波动的协同偏好获取方法
[J]. 计算机应用 , 2016 , 36 (7 ): 2011 -2015 .
https://doi.org/10.11772/j.issn.1001-9081.2016.07.2011
URL
Magsci
[本文引用: 1]
摘要
针对现有的推荐系统多采用近邻用户的偏好行为来预测当前用户的偏好,而不考虑用户的偏好会随着时间的变化而改变,影响了推荐准确率的问题,提出了一种基于时间衰减与偏好波动的协同偏好获取方法。首先,基于时间因素、用户历史偏好等获取偏好衰减增量与衰减速度,并据此生成衰减函数,使用衰减函数对用户历史行为数据进行衰减修正;其次,基于用户的历史偏好分布获取其偏好波动幅度;最后,将衰减函数与偏好波动幅度分别加入到最近邻获取与偏好获取流程,协同为用户生成推荐列表。在大规模真实数据集上的实验结果表明,所提出的方法与基于属性评分分布的协同过滤(RDCF)与最优Top-<i>N</i>的协同过滤(OTCF)相比,平均绝对误差(MAE)值分别降低了近6.42%和7.73%。实验结果表明所提方法能够提高推荐准确度,提升推荐质量。
(Yang Li Hu Yunhong Shao Guirong Preference Prediction Method Based on Time Attenuation and Preference Fluctuation
[J]. Journal of Computer Applications , 2016 , 36 (7 ): 2011 -2015 .)
https://doi.org/10.11772/j.issn.1001-9081.2016.07.2011
URL
Magsci
[本文引用: 1]
摘要
针对现有的推荐系统多采用近邻用户的偏好行为来预测当前用户的偏好,而不考虑用户的偏好会随着时间的变化而改变,影响了推荐准确率的问题,提出了一种基于时间衰减与偏好波动的协同偏好获取方法。首先,基于时间因素、用户历史偏好等获取偏好衰减增量与衰减速度,并据此生成衰减函数,使用衰减函数对用户历史行为数据进行衰减修正;其次,基于用户的历史偏好分布获取其偏好波动幅度;最后,将衰减函数与偏好波动幅度分别加入到最近邻获取与偏好获取流程,协同为用户生成推荐列表。在大规模真实数据集上的实验结果表明,所提出的方法与基于属性评分分布的协同过滤(RDCF)与最优Top-<i>N</i>的协同过滤(OTCF)相比,平均绝对误差(MAE)值分别降低了近6.42%和7.73%。实验结果表明所提方法能够提高推荐准确度,提升推荐质量。
[14]
曾安 , 高成思 , 徐小强 . 融合时间因素和用户评分特性的协同过滤算法
[J]. 计算机科学 , 2017 , 44 (9 ): 243 -249 .
https://doi.org/10.11896/j.issn.1002-137X.2017.09.046
URL
[本文引用: 2]
摘要
针对传统协同过滤技术在现实应用中遇到的数据稀疏性问题和局限性,充分挖掘用户评分特性,提出融合时间因素和用户评分特性的协同过滤算法(CF-TP)。引入用户偏好模型,将用户-项目评分矩阵转化为用户-项目偏好得分矩阵,以降低用户评分习惯差异带来的影响。在预测用户对项目的偏好得分时,充分考虑用户之间的非对称影响度,根据用户兴趣随时间的变化引入时间权重函数,以提高top-N推荐的准确率。基于HetRec2011和MovieLens1M数据集的实验结果表明,相对于目前比较流行的算法,所提算法在推荐结果的准确率、召回率、F1值上均有较大的提升,有效提高了推荐系统的推荐质量。
(Zeng An Gao Chengsi Xu Xiaoqiang Collaborative Filtering Algorithm Incorporating Time Factor and User Preference Properties
[J].Computer Science , 2017 , 44 (9 ): 243 -249 .)
https://doi.org/10.11896/j.issn.1002-137X.2017.09.046
URL
[本文引用: 2]
摘要
针对传统协同过滤技术在现实应用中遇到的数据稀疏性问题和局限性,充分挖掘用户评分特性,提出融合时间因素和用户评分特性的协同过滤算法(CF-TP)。引入用户偏好模型,将用户-项目评分矩阵转化为用户-项目偏好得分矩阵,以降低用户评分习惯差异带来的影响。在预测用户对项目的偏好得分时,充分考虑用户之间的非对称影响度,根据用户兴趣随时间的变化引入时间权重函数,以提高top-N推荐的准确率。基于HetRec2011和MovieLens1M数据集的实验结果表明,相对于目前比较流行的算法,所提算法在推荐结果的准确率、召回率、F1值上均有较大的提升,有效提高了推荐系统的推荐质量。
[15]
杨锡慧 , 林鹏 , 周国强 . 基于灰色关联度聚类的协同过滤推荐算法
[J]. 软件导刊 , 2015 , 14 (10 ):29 -34 .
https://doi.org/10.11907/rjdk.151664
URL
[本文引用: 1]
摘要
协同过滤推荐系统是电子商务系统中最成功、最重要的技术之一,而在协同过滤算法中用户相似度的计算是影响算法效率的重要因素。针对传统协同过滤算法中数据稀疏导致的近邻选择不准确问题,引入灰关联分析理论进行项目聚类和用户相似度计算,并以此为基础提出了一种新的协同过滤算法,既解决了对象匹配的不足,又提高了近邻选择的准确性。实验表明,该算法可以有效解决大规模数据下用户评分数据极端稀疏带来的问题,显著提高系统的推荐质量。
(Yang Xihui Lin Peng Zhou Guoqiang Collaborative Filtering Recommendation Algorithm Based on Gray Relational Degree Clustering
[J].Software Guide , 2015 , 14 (10 ): 29 -34 .)
https://doi.org/10.11907/rjdk.151664
URL
[本文引用: 1]
摘要
协同过滤推荐系统是电子商务系统中最成功、最重要的技术之一,而在协同过滤算法中用户相似度的计算是影响算法效率的重要因素。针对传统协同过滤算法中数据稀疏导致的近邻选择不准确问题,引入灰关联分析理论进行项目聚类和用户相似度计算,并以此为基础提出了一种新的协同过滤算法,既解决了对象匹配的不足,又提高了近邻选择的准确性。实验表明,该算法可以有效解决大规模数据下用户评分数据极端稀疏带来的问题,显著提高系统的推荐质量。
[16]
邱桂 , 闫仁武 . 基于灰色关联分析的分布式协同过滤推荐算法
[J]. 计算机应用 , 2016 , 36 (4 ): 1054 -1059 .
https://doi.org/10.11772/j.issn.1001-9081.2016.04.1054
URL
Magsci
[本文引用: 4]
摘要
针对原始的基于用户(User-based)或基于评分项目(Item-based)的协同过滤推荐算法(CFR)大多采用"硬分类"式聚类,且具有数据稀疏性和可扩展性的问题,提出一种基于灰色关联分析的分布式协同过滤推荐算法。算法使用Hadoop分布式计算平台,首先,计算评分矩阵中每个评分项目的灰色关系系数;然后,计算各评分项目的灰色关联度(GRG);最后,根据GRG获得每个评分项目的近邻集合,对不同用户的待预测项目用对应的近邻集合对其评分进行预测。通过在MovieLens数据集上进行实验,与User-based和Item-based的CFR算法相比,该算法平均绝对误差分别下降了1.07%和0.06%,而且随着数据规模的扩展,通过增加集群节点,算法运行效率有相应的提升。实验结果表明,该推荐算法可以有效地实现大规模数据的推荐,并能解决数据可扩展性的问题。
(Qiu Gui Yan Renwu Distributed Collaborative Filtering Recommendation Algorithm Based on Gray Association Analysis
[J]. Journal of Computer Applications , 2016 , 36 (4 ): 1054 -1059 .)
https://doi.org/10.11772/j.issn.1001-9081.2016.04.1054
URL
Magsci
[本文引用: 4]
摘要
针对原始的基于用户(User-based)或基于评分项目(Item-based)的协同过滤推荐算法(CFR)大多采用"硬分类"式聚类,且具有数据稀疏性和可扩展性的问题,提出一种基于灰色关联分析的分布式协同过滤推荐算法。算法使用Hadoop分布式计算平台,首先,计算评分矩阵中每个评分项目的灰色关系系数;然后,计算各评分项目的灰色关联度(GRG);最后,根据GRG获得每个评分项目的近邻集合,对不同用户的待预测项目用对应的近邻集合对其评分进行预测。通过在MovieLens数据集上进行实验,与User-based和Item-based的CFR算法相比,该算法平均绝对误差分别下降了1.07%和0.06%,而且随着数据规模的扩展,通过增加集群节点,算法运行效率有相应的提升。实验结果表明,该推荐算法可以有效地实现大规模数据的推荐,并能解决数据可扩展性的问题。
[17]
赵宏晨 , 翟丽丽 , 张树臣 . 基于灰色关联度聚类与标签重叠因子结合的协同过滤推荐方法研究
[J]. 计算机工程与科学 , 2016 , 38 (1 ): 171 -176 .
URL
Magsci
[本文引用: 1]
摘要
<p>协同过滤算法是目前被广泛运用在推荐系统领域的最成功技术之一,但是面对用户数量的快速增长及相应的评分数据的缺失,推荐系统中的数据稀疏性问题也越来越明显,严重地影响着推荐的质量和效率。针对传统协同过滤算法中的稀疏性问题,采用了基于灰色关联度的方法对用户评分矩阵进行数据标准化处理,得到用户关联度并形成关联度矩阵;然后对关联矩阵中的用户进行关联度聚类,以减少相似性算法的复杂度;之后利用标签重叠因子对传统计算用户相似性的协同过滤算法进行改进,将重叠因子与用户评分以非线性形式进行组合;最后通过实例改进后的算法在推荐精确度上有着较大的提高。</p>
(Zhao Hongchen Zhai Lili Zhang Shuchen A Collaborative Filtering Recommendation Method Based on Clustering of Gray Association Degree and Factors of Tag Overlap
[J]. Computer Engineering and Science , 2016 , 38 (1 ): 171 -176 .)
URL
Magsci
[本文引用: 1]
摘要
<p>协同过滤算法是目前被广泛运用在推荐系统领域的最成功技术之一,但是面对用户数量的快速增长及相应的评分数据的缺失,推荐系统中的数据稀疏性问题也越来越明显,严重地影响着推荐的质量和效率。针对传统协同过滤算法中的稀疏性问题,采用了基于灰色关联度的方法对用户评分矩阵进行数据标准化处理,得到用户关联度并形成关联度矩阵;然后对关联矩阵中的用户进行关联度聚类,以减少相似性算法的复杂度;之后利用标签重叠因子对传统计算用户相似性的协同过滤算法进行改进,将重叠因子与用户评分以非线性形式进行组合;最后通过实例改进后的算法在推荐精确度上有着较大的提高。</p>
[18]
田民 , 刘思峰 , 卜志坤 . 灰色关联度算法模型的研究综述
[J]. 统计与决策 , 2008 (1 ): 24 -27 .
URL
[本文引用: 4]
摘要
本文对现有的灰色关联度算法模型进行了分类综述和评价,发现目前尚未有同时满足规范性和保序性的灰色关联度算法,并分析了其原因。最后,给出了几点研究结论。
(Tian Min Liu Sifeng Bu Zhikun Summary of Gray Correlation Algorithm Model
[J]. Statistics & Decision , 2008 (1 ): 24 -27 .)
URL
[本文引用: 4]
摘要
本文对现有的灰色关联度算法模型进行了分类综述和评价,发现目前尚未有同时满足规范性和保序性的灰色关联度算法,并分析了其原因。最后,给出了几点研究结论。
[19]
马宏伟 , 张光卫 , 李鹏 . 协同过滤推荐算法综述
[J]. 小型微型计算机系统 , 2009 , 30 (7 ): 1282 -1288 .
URL
[本文引用: 2]
摘要
推荐系统是电子商务系统最重要的技术之一,协同过滤推荐是目前应用最广泛和最成功的推荐系统.介绍协同过滤推荐算法的基本思想和最新研究进展,分析目前出现的代表性算法.总结协同过滤推荐算法中的关键问题和相关解决方案,比如相似性比较,数据稀疏性问题,推荐的实时性,推荐策略,评估方法等,同时也对比分析各种方法的优缺点.最后介绍协同过滤推荐算法需要进一步解决的问题和可能的发展方向.
(Ma Hongwei Zhang Guangwei Li Peng Survey of Collaborative Filtering Algorithms
[J]. Journal of Chinese Computer Systems , 2009 , 30 (7 ): 1282 -1288 .)
URL
[本文引用: 2]
摘要
推荐系统是电子商务系统最重要的技术之一,协同过滤推荐是目前应用最广泛和最成功的推荐系统.介绍协同过滤推荐算法的基本思想和最新研究进展,分析目前出现的代表性算法.总结协同过滤推荐算法中的关键问题和相关解决方案,比如相似性比较,数据稀疏性问题,推荐的实时性,推荐策略,评估方法等,同时也对比分析各种方法的优缺点.最后介绍协同过滤推荐算法需要进一步解决的问题和可能的发展方向.
[20]
王茜 , 杨莉云 , 杨德礼 . 面向用户偏好的属性值评分分布协同过滤算法
[J]. 系统工程学报 , 2010 , 25 (4 ): 561 -568 .
URL
[本文引用: 1]
摘要
针对传统协同过滤算法存在的不足,本文充分考虑用户对项目相关属性特征的偏好,将用户对项目的评价转化为用户对项目属性偏好的评分分布;在此基础上,对传统的协同过滤算法的相似性度量方法进行改进,并采用修正的用户偏好数学期望预测模型,提出一种面向用户偏好的属性值评分分布协同过滤推荐算法.实验结果表明,该算法可有效解决传统过滤算法存在的问题,推荐精度显著提高,使推荐服务更好地满足用户的偏好需求.
(Wang Qian Yang Liyun Yang Deli Collaborative Filtering Algorithm Based on Rating Distribution of Attributes Faced User Preference
[J]. Journal of Systems Engineering , 2010 , 25 (4 ): 561 -568 .)
URL
[本文引用: 1]
摘要
针对传统协同过滤算法存在的不足,本文充分考虑用户对项目相关属性特征的偏好,将用户对项目的评价转化为用户对项目属性偏好的评分分布;在此基础上,对传统的协同过滤算法的相似性度量方法进行改进,并采用修正的用户偏好数学期望预测模型,提出一种面向用户偏好的属性值评分分布协同过滤推荐算法.实验结果表明,该算法可有效解决传统过滤算法存在的问题,推荐精度显著提高,使推荐服务更好地满足用户的偏好需求.
[21]
朱国玮 , 周利 . 基于遗忘函数和领域最近邻的混合推荐研究
[J]. 管理科学学报 , 2012 , 15 (5 ): 55 -64 .
https://doi.org/10.3969/j.issn.1007-9807.2012.05.006
URL
[本文引用: 1]
摘要
基于内容过滤和协同过滤是两大最为经典的推荐算法,但基于内容过滤存在新用户问题,没有考虑用户兴趣变化对推荐质量的影响,协同过滤则面临严峻的数据稀疏性和冷启动的挑战.针对这些,提出混合推荐算法:基于非线性逐步遗忘函数建立用户兴趣模型,预测用户未评价商品评分;引入"领域最近邻"处理方法查找目标用户的最近邻,预测未评价商品评分,以此为基础做出推荐.实验结果表明,本文方法能有效提高推荐质量.
(Zhu Guowei Zhou Li Hybrid Recommendation Based on Forgetting Curve and Domain Nearest Neighbor
[J]. Journal of Management Sciences in China , 2012 , 15 (5 ): 55 -64 .)
https://doi.org/10.3969/j.issn.1007-9807.2012.05.006
URL
[本文引用: 1]
摘要
基于内容过滤和协同过滤是两大最为经典的推荐算法,但基于内容过滤存在新用户问题,没有考虑用户兴趣变化对推荐质量的影响,协同过滤则面临严峻的数据稀疏性和冷启动的挑战.针对这些,提出混合推荐算法:基于非线性逐步遗忘函数建立用户兴趣模型,预测用户未评价商品评分;引入"领域最近邻"处理方法查找目标用户的最近邻,预测未评价商品评分,以此为基础做出推荐.实验结果表明,本文方法能有效提高推荐质量.
[22]
Herlocker J Konstan J A Riedl J An Empirical Analysis of Design Choices in Neighborhood-based Collaborative Filtering Algorithms
[J]. Information Retrieval , 2002 , 5 (4 ): 287 -310 .
https://doi.org/10.1023/A:1020443909834
URL
[本文引用: 1]
摘要
Collaborative filtering systems predict a user's interest in new items based on the recommendations of other people with similar interests. Instead of performing content indexing or content analysis, collaborative filtering systems rely entirely on interest ratings from members of a participating community. Since predictions are based on human ratings, collaborative filtering systems have the potential to provide filtering based on complex attributes, such as quality, taste, or aesthetics. Many implementations of collaborative filtering apply some variation of the neighborhood-based prediction algorithm. Many variations of similarity metrics, weighting approaches, combination measures, and rating normalization have appeared in each implementation. For these parameters and others, there is no consensus as to which choice of technique is most appropriate for what situations, nor how significant an effect on accuracy each parameter has. Consequently, every person implementing a collaborative filtering system must make hard design choices with little guidance. This article provides a set of recommendations to guide design of neighborhood-based prediction systems, based on the results of an empirical study. We apply an analysis framework that divides the neighborhood-based prediction approach into three components and then examines variants of the key parameters in each component. The three components identified are similarity computation, neighbor selection, and rating combination.
Recommender Systems Handbook
1
2011
... 在当今的大数据时代, 信息过载问题日益突出, 面对海量的信息, 用户需要消耗大量的时间挑选一个物品.为了解决这个问题, 目前主要有两大研究方向: 搜索引擎和推荐系统.通过搜索引擎进行信息检索是建立在目标明确的基础之上, 然而很多时候用户无法准确描述自己的需求, 这时搜索引擎便不能达到预期的效果, 而推荐系统可以利用数据组织与分析技术, 为用户提供精准的个性化推荐服务.目前的推荐技术主要包括基于协同过滤算法的推荐、基于内容的推荐、基于知识的推荐和混合推荐, 其中协同过滤是最成功的推荐算法之一[1 ] .协同过滤推荐算法不需要搜集到用户和项目的属性信息, 只根据用户的历史评论数据就可以预测用户可能感兴趣的项目, 因此该算法广泛应用于电子商务和互联网推荐系统中, 例如Amazon和Google等.传统的协同过滤算法的思想是通过相似度的计算, 找到目标用户的最近邻, 预测要推荐项目的评分, 然后进行Top-N推荐.但是传统的协同过滤算法计算用户相似度时可分辨性不高, 即对于不同用户的评分向量与目标用户进行相似度计算时, 可能得到相同的相似度; 同时用户的兴趣偏好往往随着时间的推移发生缓慢甚至剧烈的变化, 这些因素都会导致推荐结果偏离用户的实际需求.因此, 本文提出一种基于灰色关联分析和时间因素的协同过滤算法以提高传统协同过滤算法的精度. ...
A Hybrid Recommendation Method with Double SVD Reduction
1
2010
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
A Collaborative Filtering Recommendation Algorithm Based on Item and Cloud Model
1
2011
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
A Collaborative Filtering Recommendation Algorithm Based on Hierarchical Structure and Time Awareness
1
2016
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
推荐算法时间动态特性研究进展
1
2015
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
推荐算法时间动态特性研究进展
1
2015
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
Securing Recommender Systems Against Shilling Attacks Using Social-Based Clustering
1
2013
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
Dynamic Item-based Recommendation Algorithm with Time Decay
1
2010
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于时间衰减的协同过滤推荐算法
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于时间衰减的协同过滤推荐算法
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于评论与评分的协同过滤算法
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于评论与评分的协同过滤算法
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于用户的改进的协同过滤推荐算法
1
2015
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于用户的改进的协同过滤推荐算法
1
2015
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于时间效应的协同过滤算法
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于时间效应的协同过滤算法
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
面向电影推荐的时间加权协同过滤算法的研究
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
面向电影推荐的时间加权协同过滤算法的研究
1
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
融合时间衰减与偏好波动的协同偏好获取方法
1
2016
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
融合时间衰减与偏好波动的协同偏好获取方法
1
2016
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
融合时间因素和用户评分特性的协同过滤算法
2
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
... 考虑到用户兴趣漂移问题的存在, 即用户兴趣往往随着时间的推移而发生变化, 用户近期的评分更能体现其当前的兴趣偏好, 所以一个用户在不同时间的评分对推荐系统产生的影响是不同的, 最近的评分相对于以前的评分更有参考价值, 应该被赋以更高的权重.基于以上分析, 参考文献[14 ], 引入时间权重函数, 如公式(6)所示. ...
融合时间因素和用户评分特性的协同过滤算法
2
2017
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
... 考虑到用户兴趣漂移问题的存在, 即用户兴趣往往随着时间的推移而发生变化, 用户近期的评分更能体现其当前的兴趣偏好, 所以一个用户在不同时间的评分对推荐系统产生的影响是不同的, 最近的评分相对于以前的评分更有参考价值, 应该被赋以更高的权重.基于以上分析, 参考文献[14 ], 引入时间权重函数, 如公式(6)所示. ...
基于灰色关联度聚类的协同过滤推荐算法
1
2015
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于灰色关联度聚类的协同过滤推荐算法
1
2015
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于灰色关联分析的分布式协同过滤推荐算法
4
2016
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
... ②选取评分矩阵中的母序列Yu , 即为目标用户, 计算目标用户序列和其余用户序列的绝对差, 由于初值化操作, △min =0, 则目标用户u 和其余用户v (v =1,2,…,n ; v≠u )之间关于项目t (t =1,2,…,m )的灰色关联系数如公式(7)[16 ] 所示. ...
... ③借鉴文献[16 ]中比较向量与参考向量之间关系密切程度的计算方法, 本文提出利用序列之间的关联系数计算目标用户u 和其余用户v 的相似度, 如公式(8)所示. ...
... 推荐精度的度量标准主要有统计精度度量方法和决策支持精度度量方法两类, 本实验采用统计精度度量标准中使用最广泛的平均绝对误差(Mean Absolute Error, MAE)作为度量推荐精度的标准.平均绝对误差度量的是预测评分与实际评分之间的偏差, 偏差越小, 算法的推荐精度越高.假设用户对项目的预测评分集合为{P 1 ,P 2 ,…,Pn }, 而相应的用户实际评分集合为{R 1 ,R 2 ,…,Rn }.MAE的计算如公式(12)[16 ] 所示. ...
基于灰色关联分析的分布式协同过滤推荐算法
4
2016
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
... ②选取评分矩阵中的母序列Yu , 即为目标用户, 计算目标用户序列和其余用户序列的绝对差, 由于初值化操作, △min =0, 则目标用户u 和其余用户v (v =1,2,…,n ; v≠u )之间关于项目t (t =1,2,…,m )的灰色关联系数如公式(7)[16 ] 所示. ...
... ③借鉴文献[16 ]中比较向量与参考向量之间关系密切程度的计算方法, 本文提出利用序列之间的关联系数计算目标用户u 和其余用户v 的相似度, 如公式(8)所示. ...
... 推荐精度的度量标准主要有统计精度度量方法和决策支持精度度量方法两类, 本实验采用统计精度度量标准中使用最广泛的平均绝对误差(Mean Absolute Error, MAE)作为度量推荐精度的标准.平均绝对误差度量的是预测评分与实际评分之间的偏差, 偏差越小, 算法的推荐精度越高.假设用户对项目的预测评分集合为{P 1 ,P 2 ,…,Pn }, 而相应的用户实际评分集合为{R 1 ,R 2 ,…,Rn }.MAE的计算如公式(12)[16 ] 所示. ...
基于灰色关联度聚类与标签重叠因子结合的协同过滤推荐方法研究
1
2016
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
基于灰色关联度聚类与标签重叠因子结合的协同过滤推荐方法研究
1
2016
... 当前, 国内外研究注重于将传统的协同过滤算法与其他潜在影响因素相结合, 通过构造新的模型形成优势互补, 从而提高推荐质量.Ariyoshi等提出基于协同过滤和内容过滤的双重奇异值分解(SVD)模型来降低数据稀疏性的问题, 从奇异值的角度提高推荐算法的精确度[2 ] .Wang等基于传统的相似性度量方法, 引入云模型, 并将其与基于项目的协同过滤推荐算法相结合, 通过比较项目的统计特征以计算项目之间的相似度[3 ] .Ma等提出一种基于分层结构的动态推荐算法, 一方面探索项目之间的层次结构以提高相似度, 另一方面利用时间权重函数提高预测精度[4 ] .朱思丞等提出将时间因素作为影响因子融入算法中, 使用户的兴趣具有时效性[5 ] .Zhang等将时间作为因变量融合到传统的协同过滤算法中, 旨在消除时间的影响, 提高推荐精度[6 ] .Xia等介绍了时间概念, 并提出一种融合时间函数的计算物品相似度的方法[7 ] .董立岩等在时间概念的基础上, 将反映人们遗忘规律的艾宾浩斯遗忘曲线引入到算法中, 进而改进协同推荐算法[8 ] .李伟霖等通过研究评论文本和数据, 生成评论态度影响因子, 对评论主题分布中的突出特征增加其权重, 建立更为准确的用户偏好与物品特征, 进行评分预测与物品推荐[9 ] .陈海涛等根据用户购买项目的时间先后衡量用户兴趣的动态变化, 将用户兴趣相似性作为用户相似性的权重, 改进的用户相似性计算方法解决了不能动态衡量用户兴趣变化的问题[10 ] .吴飞等将时间因素纳入用户预测评分和用户相似度计算中, 并综合这两个因素来动态分配每一项评分的权重[11 ] .兰艳等在最近邻查找阶段和预测评分阶段采用一种新颖的时间加权函数为项目上的评分赋予不同的时间权重, 这在一定程度上大幅度提高了预测推荐的准确性[12 ] .杨立等基于时间因素、用户历史偏好等获取衰减增量和衰减速度, 并据此生成衰减函数, 使用衰减函数对用户历史行为数据进行衰减修正[13 ] .曾安等在预测用户对项目的偏好得分时, 充分考虑用户之间的非对称影响度, 根据用户兴趣随时间的变化引入时间权重函数, 以提高Top-N的准确率[14 ] .杨锡慧等引入灰色关联分析理论进行项目聚类和用户相似度计算, 并以此为基础提出一种新的协同过滤算法, 提高了近邻选择的准确性[15 ] .邱桂等首先计算评分矩阵中每个评分项目的灰色关联系数, 然后计算各评分项目的灰色关联度以获得每个评分项目的近邻集合[16 ] .赵宏晨等针对传统协同过滤算法中的稀疏问题, 采用基于灰色关联度的方法对用户评分矩阵进行标准化处理, 得到用户关联度并形成关联度矩阵[17 ] . ...
灰色关联度算法模型的研究综述
4
2008
... (1) 选取{y 1 (t )}为母序列, 其余为子序列, 将原始数据做初值化处理[18 ] . ...
... (2) 计算各子序列同母序列的绝对差, 计算公式为: △1 i y ‘ 1 (t )-y ‘ i t )|(i =2,3,…,n ; t =1,2,…,n ), 绝对差值计算结果如表1 所示[18 ] . ...
... (3) 计算关联系数[18 ] : ...
... 定义2 n 个序列Y 1 , Y 2 ,…, Yn 的灰色关联度定义为如公式(5)[18 ] 所示. ...
灰色关联度算法模型的研究综述
4
2008
... (1) 选取{y 1 (t )}为母序列, 其余为子序列, 将原始数据做初值化处理[18 ] . ...
... (2) 计算各子序列同母序列的绝对差, 计算公式为: △1 i y ‘ 1 (t )-y ‘ i t )|(i =2,3,…,n ; t =1,2,…,n ), 绝对差值计算结果如表1 所示[18 ] . ...
... (3) 计算关联系数[18 ] : ...
... 定义2 n 个序列Y 1 , Y 2 ,…, Yn 的灰色关联度定义为如公式(5)[18 ] 所示. ...
协同过滤推荐算法综述
2
2009
... 协同过滤算法的核心部分是计算目标用户与评分矩阵中各用户的相似度, 然后将各个相似度进行排序, 较高相似度的用户群作为目标用户的近邻集, 其中相似度计算方法主要有以下三种[19 ] . ...
... 根据上述方法可以得出目标用户u 和其他用户v 之间的混合相似度sim '(u ,v ), 选取相似度最高的前N 个用户作为目标用户的最近邻集合M , 在文献[19 ]的基础上, 结合本文提出的混合相似度计算方法对原预测评分公式做出改进, 计算目标用户u 对项目i 的预测评分, 改进后的计算公式如公式(11)所示. ...
协同过滤推荐算法综述
2
2009
... 协同过滤算法的核心部分是计算目标用户与评分矩阵中各用户的相似度, 然后将各个相似度进行排序, 较高相似度的用户群作为目标用户的近邻集, 其中相似度计算方法主要有以下三种[19 ] . ...
... 根据上述方法可以得出目标用户u 和其他用户v 之间的混合相似度sim '(u ,v ), 选取相似度最高的前N 个用户作为目标用户的最近邻集合M , 在文献[19 ]的基础上, 结合本文提出的混合相似度计算方法对原预测评分公式做出改进, 计算目标用户u 对项目i 的预测评分, 改进后的计算公式如公式(11)所示. ...
面向用户偏好的属性值评分分布协同过滤算法
1
2010
... 其中, $\alpha $是调节参数$\text{ }(0<\alpha <1)$, 当推荐系统中用户兴趣不会随着时间发生改变且评分数据比较有限的情况下, 应提高灰色关联相似度的权重, 此时$\alpha $趋于1; 当推荐系统中评分数据比较多时, 几乎不用考虑数据的稀疏性以及相似度的分辨性问题, 仅仅考虑时间因素就可以提高传统协同过滤算法的推荐精度, 此时$\alpha $趋于0[20 ,21 ] . ...
面向用户偏好的属性值评分分布协同过滤算法
1
2010
... 其中, $\alpha $是调节参数$\text{ }(0<\alpha <1)$, 当推荐系统中用户兴趣不会随着时间发生改变且评分数据比较有限的情况下, 应提高灰色关联相似度的权重, 此时$\alpha $趋于1; 当推荐系统中评分数据比较多时, 几乎不用考虑数据的稀疏性以及相似度的分辨性问题, 仅仅考虑时间因素就可以提高传统协同过滤算法的推荐精度, 此时$\alpha $趋于0[20 ,21 ] . ...
基于遗忘函数和领域最近邻的混合推荐研究
1
2012
... 其中, $\alpha $是调节参数$\text{ }(0<\alpha <1)$, 当推荐系统中用户兴趣不会随着时间发生改变且评分数据比较有限的情况下, 应提高灰色关联相似度的权重, 此时$\alpha $趋于1; 当推荐系统中评分数据比较多时, 几乎不用考虑数据的稀疏性以及相似度的分辨性问题, 仅仅考虑时间因素就可以提高传统协同过滤算法的推荐精度, 此时$\alpha $趋于0[20 ,21 ] . ...
基于遗忘函数和领域最近邻的混合推荐研究
1
2012
... 其中, $\alpha $是调节参数$\text{ }(0<\alpha <1)$, 当推荐系统中用户兴趣不会随着时间发生改变且评分数据比较有限的情况下, 应提高灰色关联相似度的权重, 此时$\alpha $趋于1; 当推荐系统中评分数据比较多时, 几乎不用考虑数据的稀疏性以及相似度的分辨性问题, 仅仅考虑时间因素就可以提高传统协同过滤算法的推荐精度, 此时$\alpha $趋于0[20 ,21 ] . ...
An Empirical Analysis of Design Choices in Neighborhood-based Collaborative Filtering Algorithms
1
2002
... (3) 在确定分辨系数ρ 和调节参数α 的取值之后, 为了验证本文提出的混合相似度计算方法的有效性, 实验以传统的协同过滤算法(T-CF)、基于灰色关联分析的协同过滤算法(GC-CF)和基于时间因素的协同过滤算法(TF-CF)作为对照.根据Herlocker等的研究结果, 最近邻用户数量设为20-50比较合理[22 ] .因此, 本实验比较了4种算法在最近邻数量为20、25、30、35、40、45和50的情况下MAE的值, 结果如图3 所示. ...

 , 张博卿
, 张博卿




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}