
|
|
俞立平
Yu Liping
中图分类号: G302
通讯作者:
收稿日期: 2017-11-14
修回日期: 2018-01-26
网络出版日期: 2018-06-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】本文提出隐含在科技评价指标中的数据自然权重问题, 并提出了修正方法。【方法】以JCR2016数学期刊和TOPSIS评价方法为例, 分析自然权重对非线性评价方法的影响, 提出动态最大均值逼近标准化方法, 以消除自然权重的影响。【结果】自然权重对非线性评价方法影响较大, 对于加权类非线性评价方法, 设计权重、自然权重和评价方法共同影响实际权重, 对于非加权类线性评价方法, 自然权重和评价方法影响实际权重; 自然权重消除后可以有效降低评价方法对实际权重的影响, 从而充分发挥设计权重的作用, 这符合评价公理; 指标数据分布特点也会影响实际权重。【局限】用来消除自然权重的动态最大均值逼近标准化方法是一种逼近算法, 均值标准化结果难以完全相等。【结论】在科技评价中必须重视自然权重问题, 这是一种系统误差, 消除后才能保证评价公平。
关键词:
Abstract
[Objective] This paper explores the implicit natural weight issues facing the scientific and technology review indexes, and then proposes a method to address them. [Methods] First, we analyzed data from the JCR2016 mathematics journals with the help of TOPSIS method, aiming to find the influence of natural weights on the nonlinear evaluation method. Then, we proposed a method increasing the dynamic maximum mean to the standardized level, aiming to eliminate the impacts. [Results] We found that the natural weights posed significant effects to the Nonlinear Evaluation methods. For the weighted method, the design weights, the natural weights and the evaluation methods all affected the actual weights. For the non-weighted method, the natural weights and the evaluation methods affected the actual weights. Eliminating the natural weights could effectively reduce the influence of the evaluation method on the actual weights, which helps the design weights play a bigger role. The distribution of index data also affected the actual weights. [Limitations] The proposed method is still an approximation algorithm, which could not yield the exactly equal means. [Conclusions] To achieve the fair review for the science and technology products, we must pay attention to the natural weights issues, which is a systematic error.
Keywords:
自然权重就是评价指标数据隐含的权重, 其表现形式是某个指标的均值较大时, 该指标在评价中则占据较大的优势。以中学理科强化班考试为例, 假设只考语文和数学两门功课, 每门满分为100分, 某次统考该班考试数学平均成绩为88分, 语文平均成绩为73分, 从评分标准讲两门功课的权重相等, 权重之比为1:1, 但由于自然权重的存在, 实际两门功课的权重之比为88:73=1.21:1, 即数学成绩好的同学占有优势。
在科技评价中, 自然权重问题尤为突出, 主要是由于科技评价指标数据特点所决定的。Vinkler[1]、Adler等[2]发现引文分布具有右偏性特征。Seglen[3]发现引文数据属于典型的偏态分布, 服从幂律法则。如表1所示, 以JCR2016数学期刊为例, 所有指标均没有通过Jarque-Bera正态分布检验, 并不服从正态分布, 指标平均值相差极大, 数据经百分制标准化转换以后, 影响因子百分位均值最大, 为47.073; 引用半衰期均值最小, 仅为0.680。假设用这两个指标进行评价, 那么引用半衰期指标可以忽略不计, 其自然权重接近0。
表1 JCR2016数学期刊指标描述统计
| 评价指标 | 均值 | 极大值 | 极小值 | 标准差 | 偏度 | 峰度 | JB检验 | 概率 |
|---|---|---|---|---|---|---|---|---|
| 总被引频次 | 7.252 | 100 | 0.521 | 11.467 | 4.016 | 23.612 | 5994.545 | 0.000 |
| 影响因子 | 16.785 | 100 | 4.710 | 12.098 | 3.243 | 17.460 | 3076.852 | 0.000 |
| 他引影响因子 | 15.646 | 100 | 2.675 | 12.098 | 3.308 | 17.983 | 3286.246 | 0.000 |
| 影响因子百分位 | 47.073 | 100 | 0.810 | 27.627 | 0.146 | 1.915 | 15.481 | 0.000 |
| 5年影响因子 | 21.049 | 100 | 5.773 | 14.642 | 2.973 | 14.145 | 1954.897 | 0.000 |
| 特征因子 | 9.292 | 100 | 0.401 | 13.318 | 3.668 | 19.406 | 3956.367 | 0.000 |
| 标准特征因子 | 9.292 | 100 | 0.411 | 13.317 | 3.668 | 19.406 | 3956.613 | 0.000 |
| 论文影响分值 | 13.795 | 100 | 1.164 | 14.562 | 3.484 | 18.406 | 3502.304 | 0.000 |
| 即年指标 | 7.526 | 100 | 0.000 | 8.757 | 5.200 | 47.209 | 25267.110 | 0.000 |
| 被引半衰期 | 21.196 | 100 | 0.000 | 27.304 | 0.995 | 2.651 | 50.026 | 0.000 |
| 引用半衰期 | 0.680 | 100 | 0.000 | 6.839 | 12.356 | 166.623 | 335445.512 | 0.000 |
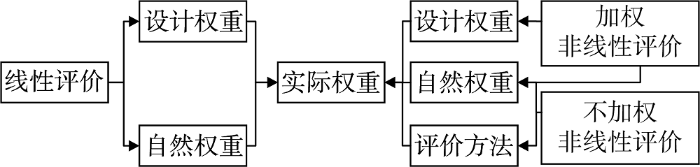
科技评价权重可以分为设计权重、自然权重、实际权重三种, 如图1所示。在日常的科技评价中, 人们往往关注的是设计权重, 这是一种显性权重, 可以通过主观赋权、客观赋权或者主客观赋权方法确定。而自然权重、实际权重是一种隐性权重, 往往没有受到重视。自然权重是评价数据包含的权重, 可以通过评价指标均值所占比重进行确定。实际权重是评价中指标真实重要性的反映, 对于加权汇总类的线性评价, 可以通过计算指标的加权均值比得到; 对于非线性评价, 俞立平等[4,5]提出可以通过计算模拟权重得到, 其原理是对评价得分与评价指标进行回归, 再将回归系数标准化即可。
在科技评价的线性评价方法与非线性评价方法中, 设计权重、自然权重、实际权重之间的关系是不一样的, 如图2所示。评价方法大致可以分为两大类, 一类是线性加权汇总类评价方法, 其原理是将指标标准化, 然后采用不同的方法赋权, 最后进行加权汇总, 如熵权法、变异系数法、概率权法、复相关系数法等。对于线性评价方法, 实际权重由设计权重和自然权重共同确定。第二类是非线性评价, 采用一些评价模型进行评价, 评价结果与评价指标之间是非线性关系。非线性评价方法又分为加权非线性评价和不加权非线性评价两种, 加权非线性评价的实际权重由设计权重、自然权重、评价方法共同确定, 比如加权TOPSIS、VIKOR等。不加权非线性评价的实际权重由自然权重和评价方法共同确定, 比如因子分析、主成分分析等。
研究自然权重对科技评价的影响具有十分重要的意义。在评价中, 真正发挥作用的是实际权重, 当然实际权重也是隐含的。设计权重仅仅是评价者通过主客观方法确定后试图影响评价结果的一种意愿, 究竟在实际权重中有没有体现有待进一步分析。自然权重是隐含在评价指标数据中, 通过隐蔽方式影响指标重要性的权重。无论是线性评价还是非线性评价, 自然权重对实际权重和评价结果均会产生影响, 研究自然权重的影响机制和影响大小, 并对自然权重问题进行修正, 不仅可以深化科技评价理论, 降低科技评价方法导致的系统误差, 而且对于科技评价实践具有重要作用, 有利于评价方法的公平公正, 提高评价的科学性与公信力。
本文揭示了隐藏在科技评价指标中的自然权重问题, 提出动态最大均值逼近标准化方法, 通过标准化后所有指标均值和极大值相等的方法消除自然权重问题, 并以JCR2016数学学科学术期刊和TOPSIS评价方法为例, 比较自然权重消除前后的评价结果。
权重赋值的指导思想是权重确定的首要问题。何强[6]认为从某个特定的优化思想入手, 严格地考察哪种方法在什么具体条件下最优, 或许是从根本上减少权重设计争议的一种行之有效的途径。苏术锋[7]认为数据差异大小不能反映指标的重要程度的高低, 因此数据差异的客观赋权法缺乏理论根据, 是一种存在瑕疵的、有效性不稳定的方法。俞立平等[5]认为主成分或因子分析采用方差贡献率作为权重值得商榷, 应结合专家打分来赋予权重。邹树梁等[8]提出从决策者对属性的重视程度、属性对决策的影响度、属性可靠性三个维度进行权重赋值的方法。王化中等[9]将模糊综合评价中指标权重分为指标重要性权重与指标分类性权重, 认为应该同时考虑这两种权重来进行评价。
在科技评价中, 权重确定方法一直是研究关注的焦点。研究视角包括群评价、模糊评价、主客观评价、非线性评价等方面的权重设定与优化问题, 研究成果众多。Hagerty等[10]同时考虑存在和不存在评价主体的情形, 证明了算术平均赋权在两种情形下都是有助于减少分歧的较优选择。Kahneman等[11]认为决策者概率权函数遵循非线性的形式, 给出一种概率权重函数表达式, 并对其中的参数取值进行估计。Edwards等[12]认为序和法对重要属性赋予的权重值偏低, 不便于方案排序, 进而提出ROC赋权法(Rank Order Centroid Weights), 通过序数的倒数计算权重。周志远等[13]引入一种基于粗糙集的权重确定方法, 以提高情报分析的客观有效性。曹秀英等[14]提出结合决策者权重和粗集理论权重最终确定属性权重。王祖和等[15]针对网络计划技术中多资源均衡所存在的问题, 考虑各资源的重要程度及所有可后移的非关键工作, 以权重方差作为衡量资源均衡效果的数量指标。周辉等[16]依据属性重要性概念, 提出基于信息粒度的属性权重客观确定方法, 弥补了基于Rough集评价的不足。何立华等[17]提出基于聚类的权重设定方法, 将专家权重分为组间权重和组内权重, 改进了专家聚类步骤和组间权重计算方法。张立军等[18]基于结构方程模型, 构建了基于路径系数权重体系的科技成果奖励评价模型。陈亮等[19]提出众里取大规则下由频率确定属性权重的方法, 要求决策者挑选一个最重要属性, 进而通过频率确定属性权重。岳立柱等[20]提出每个决策者均按属性重要程度给出排列, 根据排列信息得到一个综合判断矩阵, 之后确定指标权重。
关于权重的本源问题以及评价结果对权重的影响问题, 现有研究尚未重视。傅蓉[21]认为受考核指标的统计特征、计分方式等影响, 平衡计分卡考核指标的结果权重与初始设定权重相比出现明显差异。俞立平等[4]以CSTPC数据库医学学术期刊为例, 采用非线性评价方法评价, 通过回归分析或排序选择模型计算模拟权重, 发现不同客观评价方法中同一指标的权重差异很大。俞立平等[22]采用传统回归和岭回归计算模拟权重, 进而对TOPSIS权重的单调性进行检验, 发现TOPSIS并不具有权重单调性。
权重确定是评价中的基础问题, 其确定方法研究成果众多, 使得权重确定日益科学合理, 推动了科技评价工作的发展。但是关于权重的异化问题学术界却没有引起足够的重视, 只有少量研究, 并且远不够系统。从现有研究看, 在以下几个方面有待深入:
(1) 自然权重, 或者称为数据权重, 人们仅仅凭经验可以感觉到, 如何进行测定?如何进行不同指标自然权重的比较?
(2) 设计权重、自然权重与实际权重之间的关系如何?
(3) 对于加权非线性评价方法, 自然权重对实际权重影响大小?对于不赋权非线性评价方法, 自然权重对实际权重影响大小?如何对自然权重的影响进行综合评估?
(4) 如何修正自然权重?修正自然权重对非线性评价有什么影响?
自然权重ωS是指标数据所特有的, 具体计算可以用评价指标标准化后的均值占所有指标均值的比重表示, 即对于m个评价对象, n个评价指标, 指标Xij的自然权重, 如公式(1)所示。
${{\omega }_{j}}=\frac{\overline{{{X}_{ij}}}}{\sum\limits_{j=1}^{n}{\overline{{{X}_{ij}}}}}$ (1)
自然权重不具有评价特性, 即不能用在评价中进行加权汇总或代替设计权重用于评价, 但是自然权重隐藏在数据中, 对评价结果或多或少产生影响。
所谓非线性评价, 是指评价结果与评价指标之间并非简单的线性关系。非线性评价可能用到设计权重, 称为加权非线性评价, 也可能用不到, 称为不加权非线性评价。对于非线性评价, 如何对非线性评价的指标重要性进行测度呢?俞立平等[4,5]提出模拟权重的思想, 指出可以用回归、岭回归或偏最小二乘法估计评价得分与评价指标的关系, 再根据回归系数的大小判定不同指标的重要性, 计算得到各指标的模拟权重, 也就是实际权重。之所以采用不同的回归方法, 是为了消除评价指标之间相关性较高导致的多重共线性 影响。
实际权重虽然是通过模拟方法得到, 但是它真实反映了评价中各指标的重要性, 对于评价目的、评价方法选用、评价结果的运用均产生较大的影响。
设计权重是评价开始后确定的, 自然权重和实际权重都可以计算得到, 这样可以进一步分析自然权重对实际权重以及评价结果的影响。有以下三种情况:
(1) 对于线性评价方法, 自然权重与设计权重影响实际权重;
(2) 对于不加权非线性评价方法, 自然权重与评价方法的特质影响实际权重;
(3) 对于加权非线性评价方法, 设计权重、自然权重与评价方法特质共同影响实际权重。
以上三种情况中, 自然权重均影响评价结果, 本文研究比较复杂的第二、第三种情况。
在科技评价中, 人们最为关注的是设计权重, 自然权重和实际权重都是隐含的, 如果由于自然权重的影响, 使得实际权重发生扭曲, 与设计权重相差 较大, 这是要尽量避免的, 所以必须对自然权重进行修正。
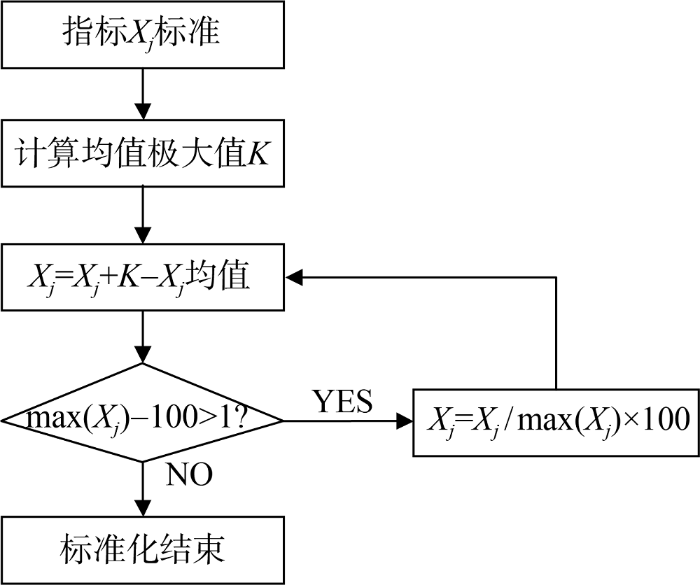
自然权重是由于标准化后的评价指标均值不等引起的, 如果采用某种标准化方法, 使得所有指标的均值和极大值相等, 那么自然权重问题可以迎刃而解。为此, 本文提出动态最大均值逼近标准化方法, 以解决这个问题, 其步骤如图3所示。
(1) 对所有指标进行标准化, 并计算标准化后的均值, 然后找到最大均值K。K的计算如公式(2)所示。
$K=\max (\overline{{{X}_{j}}})$ (2)
(2) 除了均值极大值的指标外, 其他指标需要继续处理, 比如对于指标Xj, 加上$K-\overline{{{X}_{j}}}$, 这样其均值是K, 但极大值为$100+K-\overline{{{X}_{j}}}$, 超过100(假设标准化采取百分制)。
(3) 对Xj进行二次标准化, 全部指标除以极大值$100+K-\overline{{{X}_{j}}}$, 但是又出现新问题, 极大值虽然降到100, 但均值也同样减小, 所以还需要重复步骤(1)。
(4) 如此进行循环, 直到步骤(2)极大值在许可阈值范围内, 比如1%, 即极大值小于101, 至此标准化结束。
这种数据标准化方法具有三个特点: 它是动态的, 需要循环多次; 理论上可以无限逼近步骤(1)的极大值, 但永远会略微超过; 这是一种线性标准化方法, 可以保留原始数据的大量信息, 这对科技评价至关重要。
以上方法还有一个问题, 就是如何保证二次标准化、三次标准化等均值是不断递增的?对此进行证明。第二次标准化时, 需要提高均值, 如公式(3)所示。
${{X}_{j}}'={{X}_{j}}+K-\overline{{{X}_{j}}}$ (3)
下面进行二次标准化, 如公式(4)所示。
${{X}_{j}}''=\frac{{{X}_{j}}+K-\overline{{{X}_{j}}}}{\max ({{X}_{j}}+K-\overline{{{X}_{j}}})}\times 100=\frac{{{X}_{j}}+K-\overline{{{X}_{j}}}}{100+K-\overline{{{X}_{j}}}}\times 100$ (4)
只要证明Xj''的均值递增即可, 也就是说要证明$\overline{{{X}_{j}}''}-\overline{{{X}_{j}}}>0$, 即:
$\begin{align} & \overline{{{X}_{j}}''}-\overline{{{X}_{j}}}=\frac{\sum\limits_{i=1}^{m}{\frac{{{X}_{j}}+K-\overline{{{X}_{j}}}}{100+K-\overline{{{X}_{j}}}}}}{m}-\overline{{{X}_{j}}} \\ & =\frac{\sum\limits_{i=1}^{m}{{{X}_{ij}}}/m+(K-\overline{{{X}_{j}}})-\overline{{{X}_{j}}}-(K-\overline{{{X}_{j}}})\overline{{{X}_{j}}}}{100+K-\overline{{{X}_{j}}}} \\ & =\frac{(K-\overline{{{X}_{j}}})(100-\overline{{{X}_{j}}})}{100+K-\overline{{{X}_{j}}}}>0 \\ \end{align}$ (5)
由于K是所有指标中均值极大值的指标, 而Xj的均值肯定小于标准化的极大值100, 所以式(5)一定是大于0的, 也就是说, 动态最大均值逼近标准化方法是可行的。借助计算机编程, 可以非常方便地进行处理。
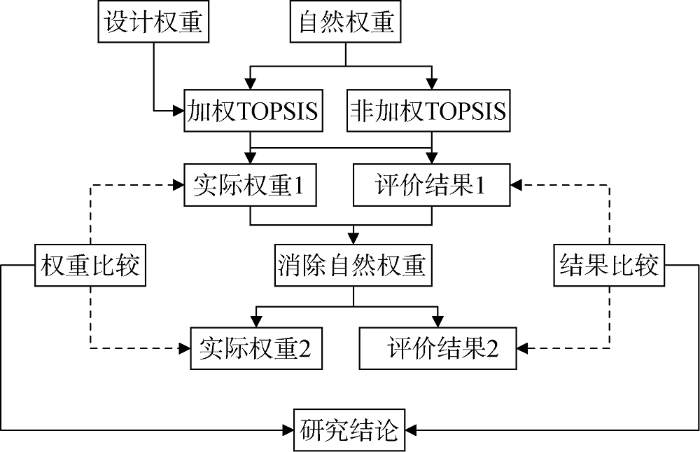
本文的研究框架如图4所示, 以TOPSIS方法为例进行研究, TOPSIS包括加权TOPSIS和非加权TOPSIS, 可以同时研究加权非线性评价方法与不加权非线性评价方法的自然权重问题。非加权TOPSIS的实际权重主要由自然权重、评价方法确定, 而加权TOPSIS评价方法的实际权重主要由设计权重、自然权重和评价方法共同确定。由于评价方法采用的都是TOPSIS, 这样可以重点比较设计权重、自然权重对实际权重的影响。对于加权TOPSIS评价与非加权TOPSIS评价, 分别在消除自然权重前后计算出实际权重与评价结果, 并进行对比, 最终得出结论。
以JCR2016数学期刊为例, 选取他引影响因子、特征因子、总被引频次三个指标, 分别采用加权TOPSIS、非加权TOPSIS进行评价, 并比较自然权重消除前后对评价结果的影响。JCR2016数学期刊共有310种, 由于少数期刊存在数据缺失, 因此进行清洗, 最后得到294种期刊。
(1) 自然权重消除前权重比较
南京大学CSSCI评价中, 他引影响因子的权重为0.8, 总被引频次的权重为0.2, 作为一个算例, 本文继续采用这两个指标, 由于指标数量过少对自然权重的影响难以深入, 于是进一步引入特征因子指标, 以这三个指标评价为例进行说明。他引影响因子是期刊过去两年刊载论文的评价, 总被引频次针对的是期刊创刊以来所有论文的评价, 而特征因子是针对期刊近5年发表论文的评价, 根据时间越接近、权重越大原则, 设定他引影响因子的权重为0.6, 特征因子的权重为0.25, 总被引频次的权重为0.15。
首先将评价指标标准化, 然后计算各指标均值, 他引影响因子均值为15.646, 特征因子均值为9.292, 总被引频次均值为7.252, 进一步计算各指标的均值比, 得到自然权重, 分别为0.486、0.289、0.225。
采用加权TOPSIS进行评价, 然后将评价结果作为因变量, 评价指标作为自变量进行回归, 结果如下:
$\begin{align} & \log (Y)=-5.327+0.976\log ({{X}_{1}})+0.198\log ({{X}_{2}})+0.059\log ({{X}_{3}}) \\ & \text{ }(-123.638)\text{ }(49.835)\ \text{ }(10.411)\text{ }\text{ }(3.591) \\ & {{R}^{2}}=0.956\text{ }(6) \\ \end{align}$
所有回归系数均在1%的水平下通过了统计检验, 模型的拟合优度R2高达0.956, 拟合效果较好, 回归系数分别为0.976、0.198、0.059, 由于已经取了对数, 实际上代表的是各指标的弹性, 相当于指标重要性大小即权重, 进一步权重调整使权重之和为1, 处理后实际权重分别为0.791、0.161、0.048。
加权TOPSIS三种权重比较如表2所示, 原设计权重他引影响因子、特征因子、总被引频次的权重分别为0.60、0.25、0.15, 但由于自然权重和评价方法的影响, 最终实际权重为0.791、0.161、0.048, 他引影响因子权重加大, 而特征因子、总被引频次的权重减小, 这是设计权重、自然权重、TOPSIS方法共同影响的结果。
表2 加权TOPSIS三种权重比较
| 评价指标 | 设计权重 | 自然权重 | 实际权重 |
|---|---|---|---|
| 他引影响因子X1 | 0.60 | 0.486 | 0.791 |
| 特征因子X2 | 0.25 | 0.289 | 0.161 |
| 总被引频次X3 | 0.15 | 0.225 | 0.048 |
(2) 自然权重消除后权重比较
下面采用动态最大均值逼近标准化方法, 对特征因子和总被引频次进行标准化, 以消除自然权重。经过两轮标准化后, 特征因子的均值为15.646, 极大值为100.934<101; 经过三轮标准化, 总被引频次的均值为15.646, 极大值为100.187<101。至此自然权重消除, 或者说自然权重相等, 均为0.333。
继续采用加权TOPSIS进行评价, 并以评价值为因变量, 以消除自然权重后的评价指标为自变量进行回归, 结果如下:
log(Y)=-5.043+0.597log(X1)+0.302log(X2)+0.243log(X3)
(-140.932)(56.696)(12.545)(8.896)
R2=0.973 (7)
所有回归系数均在1%的水平下通过了统计检验, 模型的拟合优度R2高达0.973, 拟合效果极高, 回归系数分别为0.597、0.302、0.243, 表示重要性, 相当于权重, 进一步进行权重调整使权重之和为1, 如表3所示。
表3 消除自然权重后加权TOPSIS权重比较
| 评价指标 | 设计权重 | 自然权重 | 实际权重 |
|---|---|---|---|
| 他引影响因子X1 | 0.60 | 0.333 | 0.523 |
| 特征因子X2 | 0.25 | 0.333 | 0.264 |
| 总被引频次X3 | 0.15 | 0.333 | 0.213 |
在评价时, 设计权重分别为0.60、0.25、0.15, 消除自然权重的影响后, 由于TOPSIS评价方法自身的影响, 实际权重分别为0.523、0.264、0.213, 他引影响因子的权重略有下降, 特征因子、总被引频次的权重略有上升, 这主要是由设计权重和评价方法自身产生的。
(3) 自然权重消除前后评价结果的比较
自然权重消除前, TOPSIS评价得分均值为0.119, 自然权重消除后, TOPSIS评价得分均值为0.145, 对于自然权重消除后排名前30的期刊, 与自然权重消除前相比, 个别期刊排序有变化, 其他基本相同, 这是由于排名靠前的期刊区分度较好所致。选取排名50-79的期刊进行比较, 如表4所示, 可见消除自然权重前后, 评价结果排序差别还是较大的。
表4 自然权重消除前后加权TOPSIS评价结果比较
| 期刊名称 | 消除前 评价值 | 排名 | 消除后 评价值 | 排名 |
|---|---|---|---|---|
| KINET RELAT MOD | 0.178 | 48 | 0.194 | 50 |
| RANDOM STRUCT ALGOR | 0.172 | 51 | 0.194 | 51 |
| INDIANA U MATH J | 0.165 | 53 | 0.192 | 52 |
| J COMB THEORY A | 0.161 | 56 | 0.191 | 53 |
| COMMUN CONTEMP MATH | 0.170 | 52 | 0.188 | 54 |
| ADV CALC VAR | 0.173 | 49 | 0.187 | 55 |
| COMBINATORICA | 0.161 | 55 | 0.182 | 56 |
| MEM AM MATH SOC | 0.153 | 59 | 0.181 | 57 |
| J PURE APPL ALGEBRA | 0.147 | 66 | 0.180 | 58 |
| J ANAL MATH | 0.158 | 58 | 0.179 | 59 |
| ERGOD THEOR DYN SYST | 0.149 | 63 | 0.176 | 60 |
| CAN J MATH | 0.152 | 60 | 0.175 | 61 |
| COMMUN NUMBER THEORY | 0.160 | 57 | 0.173 | 62 |
| EUR J COMBIN | 0.140 | 74 | 0.171 | 63 |
| SCI CHINA MATH | 0.142 | 72 | 0.168 | 64 |
| MOSC MATH J | 0.150 | 61 | 0.167 | 65 |
| POTENTIAL ANAL | 0.146 | 67 | 0.167 | 66 |
| ELECTRON J COMB | 0.134 | 78 | 0.166 | 67 |
| J EVOL EQU | 0.149 | 62 | 0.166 | 68 |
| ELECTRON J DIFFER EQ | 0.138 | 75 | 0.165 | 69 |
| RUSS MATH SURV+ | 0.141 | 73 | 0.165 | 70 |
| ALGEBR NUMBER THEORY | 0.142 | 70 | 0.165 | 71 |
| INTERFACE FREE BOUND | 0.149 | 64 | 0.163 | 72 |
| PAC J MATH | 0.128 | 87 | 0.163 | 73 |
| REND LINCEI-MAT APPL | 0.148 | 65 | 0.162 | 74 |
| REV MAT COMPLUT | 0.146 | 68 | 0.161 | 75 |
| B LOND MATH SOC | 0.129 | 83 | 0.159 | 76 |
| ADV NONLINEAR STUD | 0.142 | 71 | 0.159 | 77 |
| J NUMBER THEORY | 0.125 | 91 | 0.158 | 78 |
| J GEOM ANAL | 0.133 | 79 | 0.158 | 79 |
对于非加权TOPSIS评价, 影响评价结果和实际权重的只有评价方法自身和自然权重, 而没有设计权重。
(1) 自然权重消除前权重比较
将原始指标标准化后采用TOPSIS进行评价, 然后对评价结果与评价指标进行回归, 结果如下:
$\begin{align} & \log (Y)=-5.239+0.790\log ({{X}_{1}})+0.272\log ({{X}_{2}})+0.141\log ({{X}_{3}}) \\ & (-103.347)(34.302)\text{ }(12.164)\ \text{ }(7.331) \\ & {{R}^{2}}=0.943\text{ }(8) \\ \end{align}$
所有回归系数均在1%的水平下通过了统计检验, 模型的拟合优度R2高达0.943, 拟合效果较好, 回归系数分别为0.790、0.272、0.141, 进一步处理得到实际权重, 分别为0.657、0.226、0.117, 其和为1, 如表5所示, 它是由自然权重和TOPSIS评价方法共同影响的。
(2) 自然权重消除后权重比较
为了进一步分析TOPIS评价方法自身的影响, 将自然权重消除后进行评价, 再进行回归, 结果如下:
$\begin{align} & \log (Y)=-4.867+0.349\log ({{X}_{1}})+0.351\log ({{X}_{2}})+0.391\log ({{X}_{3}}) \\ & \text{ }(-152.385)\text{ }(37.073)\text{ }(16.291)\text{ }(16.076) \\ & {{R}^{2}}=0.973\text{ }(9) \\ \end{align}$
所有回归系数也是在1%的水平下通过了统计检验, 模型的拟合优度R2高达0.973, 拟合效果较好, 回归系数分别为0.349、0.351、0.391, 进一步处理得到实际权重, 分别为0.320、0.322、0.358, 其和为1, 如表6所示, 三者大小比较接近, 可见在消除自然权重以后, TOPSIS评价的实际权重有等权重的趋势, 由于自然权重消除, 也不存在设计权重, 所以这是评价方法与指标数据影响的结果。
(3) 自然权重消除前后评价结果的比较
自然权重消除前, TOPSIS评价得分均值为0.106, 自然权重消除后, TOPSIS评价得分均值为0.150, 对于自然权重消除后排名前30的期刊, 与自然权重消除前相比, 有10种期刊排序发生变化。为了更好地比较两者排序的差异, 选取排名50-79的期刊进行比较, 如表7所示, 可见消除自然权重前后, 评价结果排序差别较大。
表7 自然权重消除前后加权TOPSIS评价结果比较
| 期刊名称 | 消除前 评价值 | 排名 | 消除后 评价值 | 排名 |
|---|---|---|---|---|
| MEM AM MATH SOC | 0.142 | 53 | 0.189 | 50 |
| EUR J COMBIN | 0.141 | 54 | 0.189 | 51 |
| NUMER LINEAR ALGEBR | 0.153 | 48 | 0.188 | 52 |
| P ROY SOC EDINB A | 0.146 | 52 | 0.185 | 53 |
| J NUMBER THEORY | 0.133 | 61 | 0.183 | 54 |
| ERGOD THEOR DYN SYST | 0.135 | 59 | 0.182 | 55 |
| RANDOM STRUCT ALGOR | 0.141 | 55 | 0.180 | 56 |
| B LOND MATH SOC | 0.125 | 68 | 0.174 | 57 |
| CAN J MATH | 0.130 | 63 | 0.174 | 58 |
| ELECTRON J DIFFER EQ | 0.125 | 67 | 0.172 | 59 |
| SCI CHINA MATH | 0.128 | 65 | 0.171 | 60 |
| RUSS MATH SURV+ | 0.125 | 70 | 0.170 | 61 |
| CALCOLO | 0.146 | 51 | 0.169 | 62 |
| COMBINATORICA | 0.129 | 64 | 0.168 | 63 |
| ADV DIFFERENTIAL EQU | 0.138 | 57 | 0.168 | 64 |
| SEL MATH-NEW SER | 0.137 | 58 | 0.168 | 65 |
| MATH RES LETT | 0.121 | 71 | 0.168 | 66 |
| J COMB THEORY B | 0.117 | 74 | 0.167 | 67 |
| J INEQUAL APPL | 0.115 | 76 | 0.167 | 68 |
| J INST MATH JUSSIEU | 0.138 | 56 | 0.165 | 69 |
| MATH NACHR | 0.115 | 77 | 0.165 | 70 |
| COMMUN CONTEMP MATH | 0.131 | 62 | 0.164 | 71 |
| J ANAL MATH | 0.125 | 69 | 0.164 | 72 |
| KINET RELAT MOD | 0.134 | 60 | 0.163 | 73 |
| COMMUN PUR APPL ANAL | 0.114 | 78 | 0.159 | 74 |
| CR MATH | 0.107 | 92 | 0.159 | 75 |
| J APPROX THEORY | 0.112 | 81 | 0.159 | 76 |
| SB MATH+ | 0.108 | 88 | 0.157 | 77 |
| DISCRETE COMPUT GEOM | 0.107 | 93 | 0.157 | 78 |
| ALGEBR NUMBER THEORY | 0.118 | 72 | 0.157 | 79 |
(1) 自然权重对非线性评价方法影响较大
自然权重是由于标准化后的评价指标均值不相等产生的, 对于加权类的非线性评价方法而言, 设计权重、自然权重和评价方法自身三个因素决定了评价结果的实际权重; 对于非加权类的非线性评价方法而言, 自然权重与评价方法自身两个因素决定了评价结果的实际权重。并且在两种情况下, 自然权重对评价结果的排序均产生了一定的影响。
(2) 动态最大均值逼近标准化方法可以有效消除自然权重
本文采用动态最大均值逼近标准化方法, 在保证所有评价指标均值相等的同时, 还使得各指标极大值超过设定标准控制在1%以内, 通过这种标准化方法, 可以有效消除自然权重的影响, 使得人们可以从设计权重与评价方法角度进一步提高评价的科学性。
(3) 自然权重消除后可以有效降低评价方法对实际权重的影响
本文通过对TOPSIS实证研究发现, 在不需要加权的TOPSIS评价中, 如果消除了自然权重的影响, 评价指标的实际权重有等权重的趋势, 评价方法对实际权重的影响得到降低。即消除自然权重后, 对于加权TOPSIS, 实际权重主要受设计权重的影响, 对于不需要加权的TOPSIS评价, 实际权重具有等权重性质。进一步可以推论, 在消除自然权重以后, 设计权重将会发挥更大作用, 这符合评价公理。当然这是依据本文数据和TOPSIS方法得出的结论, 有待进一步检验。
(4) 指标数据分布特点也会影响实际权重
本文研究还发现, 在消除自然权重以后, 非加权TOPSIS评价方法的实际权重还是有一定的差异, 产生的原因主要是指标数据分布特点所决定的, 这是一种正常现象。
数学学科比较特殊, 影响因子往往较小, 本文以数学学科为例进行研究, 但并不影响问题的普遍性, 因为文献计量指标的数据分布许多并不服从正态分布, 因此本文问题和方法具有扩展和通用意义, 甚至可以广泛应用到其他评价中。
俞立平: 负责全文的构思、自然权重消除的算法设计, 论文撰写, 修订;
宋夏云: 基础数据的处理, 文献综述;
王作功: 数据分析与处理。
所有作者声明不存在利益冲突关系。
支撑数据见期刊网络版http://www.infotech.ac.cn。
[1] 俞立平, 宋夏云, 王作功. JCR 2016 Mathematics.xls. 论文相关数据.
| [1] |
Introducing the Current Contribution Index for Characterizing the Recent,Relevant Impact of Journals [J].https://doi.org/10.1007/s11192-009-0427-x URL [本文引用: 1] 摘要
The Garfield (Impact) Factor characterizes the measure of the up to date specific contribution of scientific journals to the total impact of the journals in a special field. A new indicator (Current Contribution Index, CCI) was introduced in order to characterize the relative contribution of journals to recent, relevant knowledge of a corresponding field. The CC Index relates the number of citations received by a journal in a given year to the total number of citations obtained by all journals of the corresponding field in that year. Mean Garfield Factors and mean Current Contribution Indexes were calculated for some fields and several journals. No significant correlation was found between the Garfield Factor (GF) and Current Contribution Index (CCI) of journals. The ratios of the GF to CCI referring to the corresponding top 10, 20 or 50 per cent of the journals ranked by decreasing GF and CCI, strongly differ by field.
|
| [2] |
Citation Statistics: A Report from the International Mathematical Union (IMU) in Cooperation with the International Council of Industrial and Applied Mathematics (ICIAM) and the Institute of Mathematical Statistics (IMS) [J].https://doi.org/10.1214/09-STS285 URL [本文引用: 1] |
| [3] |
The Skewness of Science [J]. |
| [4] |
科技评价中不同客观评价方法权重的比较研究 [J].https://doi.org/10.3969/j.issn.1000-7695.2009.08.047 URL [本文引用: 3] 摘要
为了比较不同客观评价方法指标权重赋值的特点,以中国科学技术信 息研究所CSTPC数据库中的医学科技期刊为例,首先应用客观评价方法进行评价,然后通过回归分析或排序选择模型估算出部分非直接赋权的客观评价法的权 重,最后再比较不同客观评价方法权重的特点.结果发现,不同客观评价方法对相同指标的重要性认识相差较大,因此单纯采用客观评价法进行评价结果是不可靠 的.客观赋权法指标权重结果可以用来修正主观赋权法,同时可以适当消除主观赋权评价时专家的意见分歧.
Comparative Research on Weight of Different Objective Evaluation Methods in Scientific and Technological Evaluation [J].https://doi.org/10.3969/j.issn.1000-7695.2009.08.047 URL [本文引用: 3] 摘要
为了比较不同客观评价方法指标权重赋值的特点,以中国科学技术信 息研究所CSTPC数据库中的医学科技期刊为例,首先应用客观评价方法进行评价,然后通过回归分析或排序选择模型估算出部分非直接赋权的客观评价法的权 重,最后再比较不同客观评价方法权重的特点.结果发现,不同客观评价方法对相同指标的重要性认识相差较大,因此单纯采用客观评价法进行评价结果是不可靠 的.客观赋权法指标权重结果可以用来修正主观赋权法,同时可以适当消除主观赋权评价时专家的意见分歧.
|
| [5] |
主成分与因子分析在期刊评价中的改进研究 [J].https://doi.org/10.3969/j.issn.1002-1965.2014.12.018 URL [本文引用: 3] 摘要
分析了主成分分析和因子分析在期刊评价中的误区,并提出了优化方法。研究表明,无论是主成分分析还是因子分析,其隐含的假设是评价指标必须服从正态分布,在期刊评价指标普遍呈幂律分布的情况下,采用主成分分析和因子分析要慎重,应将评价指标取对数后再进行评价。采用主成分和因子分析即使评价方法相同,不同评价也不具有可比性。主成分或因子分析采用方差贡献率作为权重值得商榷,应结合专家打分来赋予权重。
The Misunderstandings and Optimization of Principal Component and Factor Analysis in Journal Evaluation [J].https://doi.org/10.3969/j.issn.1002-1965.2014.12.018 URL [本文引用: 3] 摘要
分析了主成分分析和因子分析在期刊评价中的误区,并提出了优化方法。研究表明,无论是主成分分析还是因子分析,其隐含的假设是评价指标必须服从正态分布,在期刊评价指标普遍呈幂律分布的情况下,采用主成分分析和因子分析要慎重,应将评价指标取对数后再进行评价。采用主成分和因子分析即使评价方法相同,不同评价也不具有可比性。主成分或因子分析采用方差贡献率作为权重值得商榷,应结合专家打分来赋予权重。
|
| [6] |
群组评价中指标最优权重设计 [J].https://doi.org/10.3969/j.issn.1002-4565.2011.08.015 URL [本文引用: 1] 摘要
在群组评价中,对指标权重的设计常常存在较大的争议.本文通过借鉴回归的优化思想,证明了当存在m个评价主体分别对n个指标的赋权信息时,使得评价主体间差异最小化的最优权重为这m个权重向量的算术平均值;当不存在评价主体对n个指标的赋权信息时,对这些指标赋予同样的权重,是使得潜在的评价主体之间在最大可能分歧情形时评价差异最小化的近似最优赋权方法.
Optimal Weighting Design of Indicators in Group Evaluation [J].https://doi.org/10.3969/j.issn.1002-4565.2011.08.015 URL [本文引用: 1] 摘要
在群组评价中,对指标权重的设计常常存在较大的争议.本文通过借鉴回归的优化思想,证明了当存在m个评价主体分别对n个指标的赋权信息时,使得评价主体间差异最小化的最优权重为这m个权重向量的算术平均值;当不存在评价主体对n个指标的赋权信息时,对这些指标赋予同样的权重,是使得潜在的评价主体之间在最大可能分歧情形时评价差异最小化的近似最优赋权方法.
|
| [7] |
客观评价法中的数据差异赋权有效性及实证 [J].https://doi.org/10.13546/j.cnki.tjyjc.2015.21.021 URL [本文引用: 1] 摘要
针对综合评价方法中的数据差距赋权法是否具有有效性,文章专门设计一个验证用例,对客观赋权法中的"熵权法"、"拉开档次法"和"均方差法"进行实证研究.结果发现:这三种方法与主观赋权法相比在权重、总分和排名上都有偏差,故与主观赋权评价法相矛盾.产生这种矛盾的原因是数据差异赋权.事实上,数据差异大小不能反映指标的重要程度的高低,因此,数据差异的客观赋权法缺乏理论根据,是一种存在瑕疵的、有效性不稳定的方法.
Validity and Demonstration of Data Discrepancy Empowerment in Objective Evaluation Method [J].https://doi.org/10.13546/j.cnki.tjyjc.2015.21.021 URL [本文引用: 1] 摘要
针对综合评价方法中的数据差距赋权法是否具有有效性,文章专门设计一个验证用例,对客观赋权法中的"熵权法"、"拉开档次法"和"均方差法"进行实证研究.结果发现:这三种方法与主观赋权法相比在权重、总分和排名上都有偏差,故与主观赋权评价法相矛盾.产生这种矛盾的原因是数据差异赋权.事实上,数据差异大小不能反映指标的重要程度的高低,因此,数据差异的客观赋权法缺乏理论根据,是一种存在瑕疵的、有效性不稳定的方法.
|
| [8] |
混合多属性决策问题中的权重研究 [J].Research on the Weight of Hybrid Multiple Attribute Decision-making Problem [J]. |
| [9] |
模糊综合评价中权重与评价原则的重新确定 [J].
文章针对当前模糊综合评价中指标权重确定及评价对象的归类原则两个方面存在的不足进行分析,并以新思路重新设计了指标权重的确定方法及评价对象的归类原则,通过实例计算及结果分析进一步验证了设计的合理性。
Redetermination of Weight and Evaluation Principle in Fuzzy Comprehensive Evaluation [J].
文章针对当前模糊综合评价中指标权重确定及评价对象的归类原则两个方面存在的不足进行分析,并以新思路重新设计了指标权重的确定方法及评价对象的归类原则,通过实例计算及结果分析进一步验证了设计的合理性。
|
| [10] |
Constructing Summary Indices of Quality of Life: A Model for the Effect of Heterogeneous Importance Weights [J].https://doi.org/10.1177/0049124106292354 URL [本文引用: 1] 摘要
The authors consider how to construct summary indices (e.g., quality-of-life [QOL] indices) for a social unit that will be endorsed by a majority of its citizens. They assume that many social indicators are available to describe the social unit, but individuals disagree about the relative weights to be assigned to each social indicator. The summary index that maximizes agreement among citizens can then be derived, along with conditions under which an index will be endorsed by a majority in the social unit. The authors show that intuition greatly underestimates the extent of agreement among individuals, and it is often possible to construct a QOL index that most citizens agree with (at least in direction). In particular, they show that the equal-weighting strategy is privileged in that it minimizes disagreement among all possible individuals' weights. They demonstrate these propositions by calculating real QOL indices for two surveys of citizens' actual importance weights.
|
| [11] |
Prospect Theory: An Analysis of Decision Under Risk [J].https://doi.org/10.2307/1914185 URL [本文引用: 1] |
| [12] |
SMART and SMARTER: Improved Simple Methods for Multiattribute Utility Measurement [J].https://doi.org/10.1006/obhd.1994.1087 URL [本文引用: 1] 摘要
This paper presents two approximate methods for multiattribute utility measurement, SMARTS and SMARTER, each based on an elicitation procedure for weights. Both correct an error in SMART, originally proposed by Edwards in 1977, and in addition SMARTER is simpler to use. SMARTS uses linear approximations to single-dimension utility functions, an additive aggregation model, and swing weights. The paper proposes tests for the usability of these approximations. SMARTER, based on a formally justifiable weighting procedure developed by Barron and Barrett, uses the same procedures as SMARTS except that it omits the second of two elicitation steps in swing weights, substituting calculations based on ranks. It can be shown to perform about 98% as well as SMARTS does, without requiring any difficult judgments from elicitees.
|
| [13] |
粗糙集理论在情报分析指标权重确定中的应用 [J].Application of Rough Set Theory in Determining the Weight of Information Analysis Index [J]. |
| [14] |
基于粗集理论的属性权重确定方法 [J].https://doi.org/10.3321/j.issn:1003-207X.2002.05.020 URL [本文引用: 1] 摘要
Attribute weight is usually ascertained by decision maker’s experience knowledge According to calculation method of attribute importance degree in rough sets,the paper put forward the method of ascertaining attribute weight which combined weight given by decision maker with attribute importance degree ascertained by rough sets,that is the method of ascertaining attribute weight based on rough sets The method realized unity between subjective experience knowledge and objective situation,thus it can acquire much more ideal result.
The Method of Ascertaining Attribute Weight Based on Rough Sets Theory [J].https://doi.org/10.3321/j.issn:1003-207X.2002.05.020 URL [本文引用: 1] 摘要
Attribute weight is usually ascertained by decision maker’s experience knowledge According to calculation method of attribute importance degree in rough sets,the paper put forward the method of ascertaining attribute weight which combined weight given by decision maker with attribute importance degree ascertained by rough sets,that is the method of ascertaining attribute weight based on rough sets The method realized unity between subjective experience knowledge and objective situation,thus it can acquire much more ideal result.
|
| [15] |
多资源均衡的权重优选法 [J].https://doi.org/10.3969/j.issn.1004-6062.2002.03.022 URL [本文引用: 1] 摘要
本文针对网络计划技术中多资源均衡所存在的问题,提出了多资源均衡的一种有效方法--权重优选法,叙述了该方法的基本原理和优化步骤,并通过算例验证了这一方法的有效性.
The Weight Optimal Choice Method of Multi-Resource Leveling [J].https://doi.org/10.3969/j.issn.1004-6062.2002.03.022 URL [本文引用: 1] 摘要
本文针对网络计划技术中多资源均衡所存在的问题,提出了多资源均衡的一种有效方法--权重优选法,叙述了该方法的基本原理和优化步骤,并通过算例验证了这一方法的有效性.
|
| [16] |
基于信息粒度的属性权重确定方法 [J].Attribute Weight Determination Method Based on Information Granularity [J]. |
| [17] |
基于聚类的多属性群决策专家权重确定方法 [J].https://doi.org/10.3969/j.issn.1007-3221.2014.06.011 URL [本文引用: 1] 摘要
对于多属性群决策中专家权重确定的问题,本文提出了基于聚类的专家权重确定方法,将专家权重分为类别间权重和类别内权重,对专家聚类步骤和类别间权重的计算方法进行了改进。通过专家给出的判断矩阵构建相容度矩阵,利用系统聚类原理,对相容度矩阵进行聚类,得到最大相容度谱系图。通过最大相容度间的距离和给定阈值的比较,对专家进行恰当分类,从而避免了根据现有研究步骤只能将专家分为两类的不足。此外,在确定类别间权重时,除继续对类容量较大的类赋予较大的类别间权重系数外,还引入专家判断矩阵的属性权重一致性来反映类别间的差异,从而有效避免了当某几类专家中含有相等数目专家时,赋予这几类专家相同类别间权重系数的问题。所提方法结构清晰、计算简便,并使得专家权重计算结果更为合理准确。最后运用一个算例对比验证了该方法的可行性和有效性。
A Method for Determining the Experts’ Weights of Multi-Attribute Group Decision-Making Based on Clustering Analysis [J].https://doi.org/10.3969/j.issn.1007-3221.2014.06.011 URL [本文引用: 1] 摘要
对于多属性群决策中专家权重确定的问题,本文提出了基于聚类的专家权重确定方法,将专家权重分为类别间权重和类别内权重,对专家聚类步骤和类别间权重的计算方法进行了改进。通过专家给出的判断矩阵构建相容度矩阵,利用系统聚类原理,对相容度矩阵进行聚类,得到最大相容度谱系图。通过最大相容度间的距离和给定阈值的比较,对专家进行恰当分类,从而避免了根据现有研究步骤只能将专家分为两类的不足。此外,在确定类别间权重时,除继续对类容量较大的类赋予较大的类别间权重系数外,还引入专家判断矩阵的属性权重一致性来反映类别间的差异,从而有效避免了当某几类专家中含有相等数目专家时,赋予这几类专家相同类别间权重系数的问题。所提方法结构清晰、计算简便,并使得专家权重计算结果更为合理准确。最后运用一个算例对比验证了该方法的可行性和有效性。
|
| [18] |
基于路径系数权重的科技成果奖励评价模型 [J].Evaluation Model of Scientific and Technological Achievements Based on the Weight of Path Coefficient [J]. |
| [19] |
众里取大规则下由频率确定属性权重的方法 [J].Method of Frequency Determining the Attribute Weights Based on the Take-the-Biggest- of-All Rule [J]. |
| [20] |
基于序数信息的属性权重确定方法 [J].https://doi.org/10.13546/j.cnki.tjyjc.2015.13.020 URL [本文引用: 1] 摘要
目前很多方法均是通过构造判断矩阵确定属性权重,但对属性两两比较打分往往比较困难,并且经常含有过多的主观性。文章提出了一个确定权重的客观方法,该方法的思路是:对于多个决策者而言,每个决策者均按属性重要程度给出排列,根据排列信息得到一个综合判断矩阵,之后确定指标权重。这个方法的特点是无需决策者构造判断矩阵,因此避免赋值的主观性;通过概率的视角定义了权重赋值,能够判定权重差异是否具有显著性。
Research on Attribute Weight Determination Method Based on Ordinal Information [J].https://doi.org/10.13546/j.cnki.tjyjc.2015.13.020 URL [本文引用: 1] 摘要
目前很多方法均是通过构造判断矩阵确定属性权重,但对属性两两比较打分往往比较困难,并且经常含有过多的主观性。文章提出了一个确定权重的客观方法,该方法的思路是:对于多个决策者而言,每个决策者均按属性重要程度给出排列,根据排列信息得到一个综合判断矩阵,之后确定指标权重。这个方法的特点是无需决策者构造判断矩阵,因此避免赋值的主观性;通过概率的视角定义了权重赋值,能够判定权重差异是否具有显著性。
|
| [21] |
平衡计分卡指标权重前后不一致现象研究 [J].A Study of Inconsistency of Initial Weight with Result Weight in Balanced Scorecard [J]. |
| [22] |
期刊评价中TOPSIS的漏洞研究——权重单调性 [J].https://doi.org/10.3969/j.issn.1002-1965.2014.11.024 URL [本文引用: 1] 摘要
首先提出非线性评价法权重单调性问题,即在多属性评价中,在其他 指标权重不变的情况下,其中一个指标权重增加,那么评价结果也必须增加,并设计出采用传统回归和岭回归计算模拟权重进而对权重的单调性进行检验的方法。基 于JCR2012物理学期刊数据,以总被引频次和影响因子为例对TOPSIS评价方法的研究表明:TOPSIS评价法权重并不具有正向单调性,只能用于等 权重评价,加权TOPSIS法存在漏洞。研究方法也可广泛用于非线性评价方法的权重单调性检验。
Study on TOPSIS’s Vulnerability in Journal Evaluation - Weights Monotony [J].https://doi.org/10.3969/j.issn.1002-1965.2014.11.024 URL [本文引用: 1] 摘要
首先提出非线性评价法权重单调性问题,即在多属性评价中,在其他 指标权重不变的情况下,其中一个指标权重增加,那么评价结果也必须增加,并设计出采用传统回归和岭回归计算模拟权重进而对权重的单调性进行检验的方法。基 于JCR2012物理学期刊数据,以总被引频次和影响因子为例对TOPSIS评价方法的研究表明:TOPSIS评价法权重并不具有正向单调性,只能用于等 权重评价,加权TOPSIS法存在漏洞。研究方法也可广泛用于非线性评价方法的权重单调性检验。
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}