
|
|
叶光辉 , 胡婧岚
, 胡婧岚
Ye Guanghui, Hu Jinglan
中图分类号: G350
通讯作者:
收稿日期: 2017-12-22
修回日期: 2018-01-15
网络出版日期: 2018-06-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】揭示标签网络中节点链路的形成机理, 对社交博客标签的增长态势和连接模式进行分析。【方法】借助统计分析和网络分析指出标签增长模式; 在标签度分布分析的基础上, 细化统计标签连接的类型及对应的数量, 总结新加入标签的连接规律; 定义度度相关性指标, 验证标签连接服从优先连接模式的概率。【结果】发现标签最符合线性增长模式, 标签度分布呈现出单峰居中, 左侧震荡, 右侧平缓的态势, 不符合幂律分布。【局限】未能结合用户标记行为说明其对标签网络连接模式形成的影响。【结论】无论是“新标签-旧标签”还是“旧标签-旧标签”均不完全服从优先连接模式。
关键词:
Abstract
[Objective] This study reveals the forming mechanism of network nodes, aiming to examine the growth trend and attachment mode of social blog tags. [Methods] Firstly, we proposed the model of tag growth with the help of statistics and network analysis. Then, we established the categories of tag links and corresponding numbers, as well as summarized the connection rules of newly added tags. Finally, we defined the indicators of degree dependency and examined the probability of tag connection following preferential attachment modes. [Results] The tag growth showed the linear growth pattern and the distribution of tags had one single peak center, the shock left side and the gentle right side, which did not meet the power-law distribution. [Limitations] We did not explain the impacts of users’ tagging behaviors on the network connections. [Conclusions] Neither the “new tag-old tag” nor the “old tag-old tag” models are not fully compliant with the preferential attachment mode.
Keywords:
在线社交博客已经成为信息交流、资源推荐、情感分析、主题监测的重要媒介和语料库。如果将在线社交博客看成是社交媒介环境下融合多维语义元素的元网络,则媒介体现了其网络特性, 可采用线性三元组来表达网络节点的关系属性, 三元组涵盖两个节点及其语义关系或语义强度。直观地讲, 在线社交博客三元组包括的逻辑关系都属于前者, 三元组两端节点类型不一致, 比如评论关系关联的两端节点类型为用户和评论, 标注关系关联的两端节点类型为用户和标签。然而这种二模关系形成的三元组无法进行更深层次的量化分析, 需要进行二次媒介转化(第一次以社交平台本身为媒介, 第二次以社交平台中的某一语义元素为媒介), 将二模关系形成的三元组转换为一模关系形成三元组, 本文所研究的社会化标签网络生成需要经历上述模的转换过程, 由此可见针对社交博客标签的系统研究都非直观的统计分析, 还需要结合语义分析和网络分析的方法和工具。同时也正是因为社交用户、话题及标签之间多重性关系的差异以及标签及话题之间的聚合关联关系, 标签网络的增长态势及连接模式不一定与社交用户、话题所对应的分析结果相一致, 有待进一步深入挖掘。
语料库则体现了在线社交博客的语义特征, 标签、评论、话题等节点都可理解为短文本, 这些文本资源是进行语义分析的重要依据, 但目前短文本分析依然存在不少问题, 尤其是以往长文本分析方法在上述短文本分析中的适用性、短文本句法结构的不完整和语言特色等, 相较而言, 标签是最为轻量级的语义片段, 同时也是这些语义片段中结构化程度最高的语料, 因此以标签为节点, 构建标签网络进行各类主题分析的研究不一而足, 但这些研究往往关注既有标签网络的结构特征分析, 缺乏针对标签网络的动态演化分析, 更缺乏利用实际社会网络语料对标签连接模式进行细化分析。标签网络的动态演化分析可有效发掘在线社交博客的关键节点、链路以及节点角色的迁移过程, 标签连接模式分析则揭示了这些关键节点和链路的形成机制, 通过这两部分分析有助于突破现有研究瓶颈, 从微观结构视角揭示标签网络宏观结构特征涌现的 机理。
目前社交博客标签研究已成为在线社会网络研究的热点话题, 不同领域学者研究视角存在一定差异, 主要分为:
(1) 利用自然语言处理手段处理标签问题: 标签是大众分类法的产物, 受控程度较低, 层级结构未被清晰揭示, 用户使用标签进行话题标记规范程度不高, 因而会出现异词同义、一词多义、上下文语境等自然语言处理问题, 这些问题对标签组织、标签网络分析、标签应用分析的准确性都造成了较大影响, 因此计算机领域研究者类比半结构化文本处理方式, 对标签集合进行清洗去重[1]、可信度评估[2]、层级关系构建[3]、情感分析[4,5]、聚类分类[6,7]等研究工作。
(2) 采用网络科学方法进行标签分析: 网络科学改变了基于数据库、关联规则的标签分析策略, 试图通过社会网络和复杂网络的分析指标、模型、算法等来发掘在线社交网络的热点话题、热点人物及网络结构。在线社交网络可理解成以多维语义元素为节点, 不同语义元素相互关联形成的元网络[8], 在此概念模型基础之上, 鉴于标签、话题、用户间的多重性关系, 通过主题发掘[9]、社团发现[10]、链路预测[11]、协同过滤[12]等方法深化揭示出节点的网络特征、整体或局部网络特征, 进而为用户兴趣建模[13,14]、内容推荐[15]、知识发现与推送[16,17]等应用的实现提供参考路径。
(3) 采用传播学、心理学理论与方法进行标签分析: 在线社交网络为用户提供了交流的信息空间, 用户因话题而聚集在一起, 而话题是社会化舆情产生、发酵、传播的重要载体。为加强舆情监控, 实现对网络舆情信息流的截断和引导, 传播学和心理学领域对标签传播[18]、信息扩散[19]、舆情分析[20]、行为分析与挖掘[21]、基于标签的用户人格预测[22]等主题开展了深入研究。
(4) 采用文献学理论与方法进行标签分布分析: 社交媒介的发展正改变着传统科学文献交流的范式, 揭示科学文献交流过程的重要经验法则是否适用于标签分布分析?为此相关研究开展了一系列验证分析和应用分析。验证分析主要说明传统经验法则在网络环境的适用性; 在验证分析基础之上, 应用分析主要说明上述定律在资源发现等实际应用中的关键作用[23]。
综上分析可知, 社交博客标签研究是多学科交叉融合的主题领域, 各学科研究边界模糊, 而且研究之间存在相互支撑, 共同形成了标签研究的全貌, 图情领域显然更关注第二部分和第四部分的研究工作, 但目前该部分研究更偏向标签网络宏观结构的揭示, 对标签网络增长态势与连接模式研究较少, 已有研究更偏重通过模型构建和分析解决标签增长过程中的传递和扩散问题, 采用仿真分析来验证标签间连接的模式。受限于社交网络标签数据获取的难度, 较少通过真实数据揭示标签网络增长态势和连接模式, 为此本文以MetaFilter①(①http://www.metafilter.com/。MetaFilter是美国著名的社交博客网站, 成立于1999年, 其由AskMeFi、Music、Job等多个主题版块组成, 每天有大量的用户在上面发帖、评论等。)开源数据为标签来源, 采用统计分析和网络分析相结合的方式对标签增长态势和连接模式进行细化分析。
社交博客标签是社交网络中轻量级的语义片段, 表达与揭示了与之关联的社交用户和社交话题的主题特征, 类同于文献题录信息中的关键词, 但标签受控程度较低, 用户表达和使用相对自由。标签和社交用户、社交话题语义关系的多重性为多对多, 数学上可表示为三元组关系数据, 模态为二模, 并非本文所观测的社会化标签形式, 需要将这种二模形式转换为标签与标签直接连接的一模形式。转换后的形式是资源关联、语义分析、用户推荐、主题侦测、信息过滤、情感分析等社交网络增值服务衍生的基础, 也是提升用户体验、凝聚主题的重要途径。为深入了解标签在上述服务中的价值, 首先需要了解标签增长态势。
社交媒介运行任何时刻产生的动作都被记录到日志文件, 借助这些文件, 可以统计出每个年度标签的数量, 甚至可以统计出每个月份、每天、每个微小时间间隔的数据。与之对应, 标签增量也都可以计算出来, 如美国知名社交博客网站MetaFilter Music版块, 2006年至今发布日志数据的非重复标签数量, 如表1所示, 统计口径为年。
表1 2006年至今MetaFilter非重复标签数量统计结果
| 时刻 | 年份 | 非重复标签数量(个) |
|---|---|---|
| 0 | 2006 | 2 057 |
| 1 | 2007 | 2 686 |
| 2 | 2008 | 4 069 |
| 3 | 2009 | 5 488 |
| 4 | 2010 | 6 967 |
| 5 | 2011 | 7 779 |
| 6 | 2012 | 8 397 |
| 7 | 2013 | 8 838 |
| 8 | 2014 | 9 145 |
| 9 | 2015 | 9 465 |
| 10 | 2016 | 9 737 |
通过表1获取的标签数量时间序列, 可获取标签数量随时间变化的趋势, 粗略预测标签的增长态势。已知传统文献增长规律包括多种理解模式, 其中指数增长、逻辑增长和线性增长为其中最为重要的三类模式[24], 也是其他增长模式的基础。类比文献增长规律, 本文进行标签增长态势分析。
选用统计分析软件SPSS预设的曲线拟合模型进行标签增长拟合。因为标签数量有一个初始值, 即设定2006年为初始年份, 此时对应的t为0, 则标签数量在t=0时候需要一个常量, 则排除幂律曲线、S曲线、对数曲线和倒数曲线。剩余曲线模型拟合度R2大于0.9的为三次曲线(R2为0.992)、二次曲线(R2为0.991)和线性曲线(R2为0.926), 但无论是三次曲线还是二次曲线都不适用于进行标签趋势, 因为标签数量随时间增加而增加, 只是增加的速度可能在不同时间段存在差别, 但肯定不会出现下降。由式(1)和式(2)可知, 式(1)描述标签数量从t∈(0, 9.3525)为递增, 之后开始不断下降, 不符合实际情形; 同理, 式(2)描述标签数量从t∈(0, 10.298)为递增函数, 之后开始不断下降。排除这两类曲线拟合, 可发现线性模型既具有良好的拟合效果, 还具有符合现实标签增长的实际情形, 其拟合方程如式(3)。
Y=1733.909+1359.127t-20.839t2-3.694t3 (1)
Y=1600.930+1570.416t-76.247t2 (2)
Y=2744.636+807.945t (3)
随着标签网络的不断增加, 截止第n年与截止第n+1年标签网络中标签的点度中心度可能会存在差异, 利用标签网络的配对t检验可以验证这种差异的存在。整个过程包括如下步骤:
(1) 生成网络分析所需要的三元组数据, 每一组数据有标签1、标签2以及标签之间的共现次数。
(2) 以t=0时刻标签为初始集合, 计算t=1, 2, ···, n初始标签的点度中心度。选取相同分析对象, 观察在整体标签容量不断增长的情形下, 新标签关系的创建或强化对初始标签点度中心度的影响。
(3) 汇总多个时刻初始标签点度中心度数据, 进行若干组配对t检验。注意配对t检验不仅要求不同时刻样本容量要一致, 还要求配对样本的相关性检验, 只有相关性检验结果显著, 才能进行后续差异性分析。以2013年-2016年MetaFilter数据为配对t检验样本, 最终分析结果如表2所示。
表2 2013年-2016年样本配对检验结果
| 配对样本 | 样本数 | 相关 系数 | 相关 显著度p1 | t | t检验 显著度p2 |
|---|---|---|---|---|---|
| 对1-2013&2014 | 988 | 0.926 | 0.000 | -19.410 | 0.000 |
| 对2-2014&2015 | 988 | 0.961 | 0.000 | -16.516 | 0.000 |
| 对3-2015&2016 | 988 | 0.976 | 0.000 | -13.982 | 0.000 |
通过表2分析可知, 相邻年份对应标签相关系数均大于0.9, p值在显著度为95%水平下均小于0.05, 符合配对t检验的要求。之后进行的配对t检验p值也小于0.05, 根据t检验预设的假设(H0: 相邻年份初始标签组成网络无差异; H1: 相邻年份初始标签组成网络有差异), 则H0不成立, H1成立。这一结论说明新标签的加入或新连接关系的建立、强化对初始标签中心性具有显著影响。
(4) 衡量步骤(3)中标签影响程度, 则需要细化分析标签的增长规律, 直观地可用标签增量进行评估。在标签网络年度增长的过程中, 初始集合中标签的中心度会随着新标签连接、旧标签连接或强化(旧标签之前可能存在联系或没有联系, 如果没有则是连接, 有则是强化)而发生变化, 选择任意两个相邻阶段进行分析, 这种变化可能存在两种情况: 不变和变大。不变表示在标签增长过程没有新标签与之建立连接, 也没有旧标签与之建立连接; 变大表示在标签增长过程中存在上述两种情形。考虑这个增长过程, 则标签增长呈现出更为多样的规律, 同样以2013年-2016年数据为样本, 标签中心度变化情况统计结果如表3所示。
结合表3分析, 发现在标签累计增长不同时刻, 标签度之间存在很强的正相关(见表4), 也就是说前一个观察窗口度值越大则后面标签度值也越大, 但是标签度增长比例与度值存在一定弱的负相关(见表5), 如2013年度值与2014年度值、2015年度值和2016年度值均存在显著的正相关, 但与标签度增长比例第一阶段、第二阶段、第三阶段和全阶段存在弱负相关, 这说明初始时刻标签度值越大, 后面增长时刻标签度值也越大, 但度值增长比例在下降。
表4 各年度标签度相关性分析
| 2013 | 2014 | 2015 | 2016 | ||
|---|---|---|---|---|---|
| 2013 | Pearson 相关性 | 1 | 0.926** | 0.843** | 0.777** |
| 显著性(双侧) | 0.000 | 0.000 | 0.000 | ||
| 2014 | Pearson 相关性 | 0.926** | 1 | 0.961** | 0.913** |
| 显著性(双侧) | 0.000 | 0.000 | 0.000 | ||
| 2015 | Pearson 相关性 | 0.843** | 0.961** | 1 | 0.976** |
| 显著性(双侧) | 0.000 | 0.000 | 0.000 | ||
| 2016 | Pearson 相关性 | 0.777** | 0.913** | .976** | 1 |
| 显著性(双侧) | 0.000 | 0.000 | .000 | ||
表5 标签度与标签增长相关性分析
| 年度 | 标签增长阶段 | Pearson相关性 | 显著性(双侧) |
|---|---|---|---|
| 2013 | (Ⅰ) | -0.094** | 0.003 |
| 2014 | (Ⅱ) | -0.100** | 0.002 |
| 2015 | (Ⅲ) | -0.049 | 0.124 |
| 2016 | (Ⅰ-Ⅲ) | -0.146** | 0.000 |
已知标签网络不同时刻节点度增长存在差异, 这种差异主要源于标签间连接模式的不同, 已有的连接模式包括优先连接和均匀连接。优先连接(Preferential Attachment)也被称为Yule过程[25], 1925年最早用于解释物种进化过程中出现的幂律现象, 1999年又被用于分析Web结构中链接的分布规律, 较少用于分析社交博客标签网络结构。本文优先连接模式可能存在两种形式: 一是新加入标签具有较高的概率与度值较高标签连接, 二是新生成标签关系倾向进一步强化已有标签间的强联系, 因而会造成一种“马太效应”现象。幂律分布是优先连接的表现形式, 该连接模式下形成的标签网络具有小世界特征, 标签网络本身具有随机鲁棒性和蓄意攻击条件下的脆弱性。但优先连接也存在不足和不适用的应用场景, 符合优先连接模式的现象也不可避免地存在宽尾和杂乱点, 很多学者对此进行修正, 提出TPA、APA等模型, 同时也发现均匀连接(Uniform Attachment)现象的存在。本文均匀连接则意味着新标签对关系的建立或强化不受标签既有度值的影响, 具有完全随机性[26], 随机图理论是均匀连接的理论基础, 连接的出现是独立的概率事件, 节点度分布服从泊松分布。需要注意的是, 均匀连接作为优先连接的补充, 只存在于特定的现象中, 优先连接在整个连接分布中依然占据主导地位, 多数情况下二者共同存在。了解标签网络可能存在的连接模式后, 接下来采用实际标签语料进行验证分析。
统计MetaFilter平台2013年-2016年标签数据, 生成标签网络, 并统计标签网络中连接度值的最大值和最小值。以2013年为例, 社交用户共使用119个标签进行标注, 基于共现关系形成的标签网络中mefimusicchallenge的度值最大为956; VelvetUnderground等11个标签度值最小为2; 同理, 也可以获取之后三年标签度的最大值和最小值, 通过极值运算可初步判定标签度分布的离散程度。为了更加精细化地描述出标签度分布规律, 笔者进一步统计度值为K的标签节点出现的概率P(K), 其计算方式等价于K值标签数量与标签总数的比值, 绘制以K为x值, P(K)为y值的坐标图, 2013年度分布曲线如图1所示。
以2013年为参照系, 对比之后三年的度分布曲线, 可以观察到类似的度分布特点, 主要表现为:
(1) 整体上讲, 各年度度分布曲线都有一个典型的峰值, 峰值相对居中, 峰值左右两侧较为平缓, 但左侧在一定范围内呈现出较大的波动性, 右侧近乎形成一条水平线, 集中着对应年份度值最大但数量最少的标签, 因此可以明显看出, 从2013年到2016年标签度分布均不服从幂律, 拟合分析结果也进一步验证了这一推断: 2013年标签度分布虽最符合幂律分布, 但拟合度R2只有0.441, 后续三年标签度分布规律则更为不明确。
(2) 横向对比分析, 笔者发现各年份峰值: 2013(334,0.1164)、2014(410, 0.1043)、2015(434,0.0992)和2016(436,0.0962), 水平方向不断显著向后推移, 垂直方向在缓慢下降, 这一方面说明随着时间的推移, 新标签关系的建立或强化对上一阶段处于峰值中的标签具有显著影响; 另一方面也说明新标签关系的建立或强化也具有一定的随机性, 实现连接的概率大小与既有标签度值不一定具有正向相关关系。综合两部分标签度分布分析可知, 标签连接可能混合了优先连接和均匀连接两种模式, 而要深入探析标签间关系, 则要进行标签关系建立或强化的分类研究。
以2013年标签网络为基准, 统计2014年-2016年累计增长标签网络中新连接关系的类型, 如图2-图4所示, 以及对应类型的数量, 统计结果如表6所示。
表6 标签连接关系类型及特征统计
| 标签关系 时间 | 新标签-新标签 | 新标签-旧标签 | 旧标签-旧标签 |
|---|---|---|---|
| 2013-2014 | 4 611 | 17 616 | 31 060 |
| 2013-2015 | 3 372 | 18 140 | 59 821 |
| 2013-2016 | 4 038 | 21 213 | 88 045 |
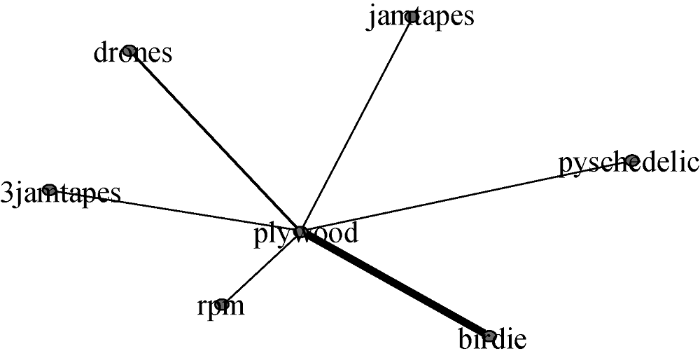
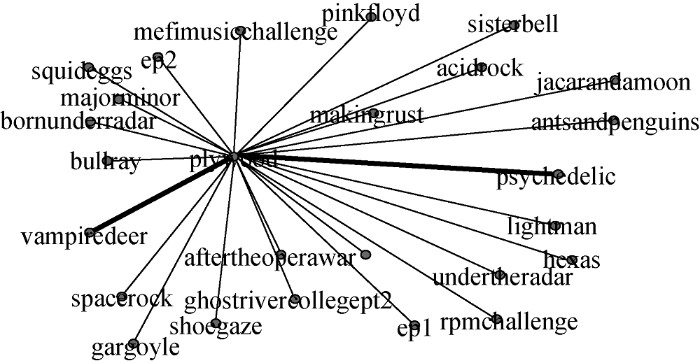
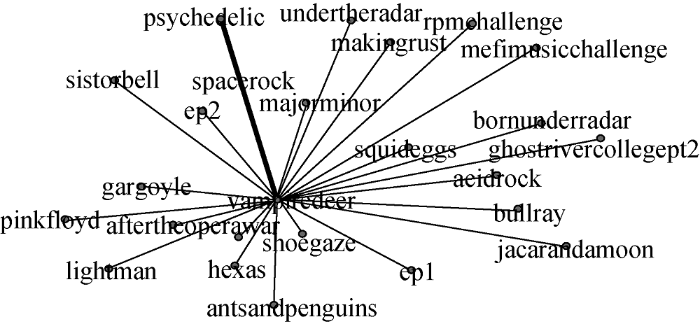
表6中新标签-新标签关系表示由待分析年份新出现的标签建立起的关系, 例如图2中plywood即为2016年新出现标签, 该标签当年共与drones等6个标签建立联系, 其中与标签birdie最为紧密, 共标记话题117次; 新标签-旧标签指待分析年份新出现的标签与待分析年份之前出现的标签之间建立起的关系, 例如图3中plywood共与acidrock等25个旧标签建立联系, 其中与标签vampiredeer联系最为紧密, 共标记话题 1 107次; 旧标签-旧标签关系指待分析年份之前出现标签之间建立或强化的关系形式, 例如图4旧标签vampiredeer共与24个旧标签建立或强化连接关系, 其中与标签psychedelic最为紧密, 共标记话题14 637次。
经计算可得2014年新增标签562个, 2015年新增标签506个, 2016年新增标签402个, 结合表6统计结果, 可得出以下推断:
(1) 通过新增标签数目可推算出理论上新标签间连接的最大关系数, 以2014年为例, 该数值为562×561/2= 157 641, 实际连接数为4 611, 则新标签间连接概率为0.029, 同理可算出截至2015年和2016年新标签间的连接概率。由表7得出新标签间平均连接概率为0.035, 新标签与旧标签平均连接概率为0.965, 这说明每一个新增标签存在极大可能与旧标签建立连接。
表7 标签连接概率分析
| 标签连接概率 时间 | 新标签-新 标签 | 新标签-旧标签 | 旧标签-旧标签 | |
|---|---|---|---|---|
| 建立 | 强化 | |||
| 2013-2014 | 0.029 | 0.971 | 0.153 | 0.847 |
| 2013-2015 | 0.026 | 0.974 | 0.481 | 0.519 |
| 2013-2016 | 0.050 | 0.950 | 0.321 | 0.679 |
| 均值 | 0.035 | 0.965 | 0.318 | 0.682 |
(2) 新标签对标签网络的影响表现为新标签间连接关系的建立, 但受限于新标签规模, 新标签对整个标签网络形成的影响不及旧标签, 旧标签间不仅涵盖了关系的建立, 还包括关系的强化。通过表7可推断出旧标签间连接和强化的概率, 以2014年为例, 2013年旧标签和旧标签连接数为26 307, 2014年该连接数变为31 060, 则旧标签连接概率为(31060-26307)/ 31060=0.153, 旧标签强化概率为26307/31060=0.847, 综合分析得出平均连接的概率为0.318, 旧标签间平均强化连接的概率为0.682, 这两个数值表明在旧标签网络形成中均匀连接和优先连接模式可能都在起作用, 旧标签以小概率建立与其他旧标签的联系, 以大概率强化已经建立好的连接关系。
由4.2节分析可知, 新标签极大概率和旧标签进行连接, 但是否服从优先连接模式还需进一步验证, 为此笔者定义了度度相关性(Degree Correlation)指标来描述网络连接模式。
(1) 以新标签-旧标签为例说明度度相关性: 如果新标签整体倾向于和度大的节点链接, 则网络形成服从优先连接模式; 反之, 则网络形成不服从优先连接模式。以4.1节中峰值点为度值大小分界点, 计算出度值不小于峰值度值节点数目与度值小于峰值节点数目的比例, 比例越大说明连接模式越倾向于优先连接, 比例越小说明连接模式越不倾向优先连接, 比例越靠近1说明连接模式越倾向于混合模式。
(2) 以旧标签-旧标签为例说明度度相关性: 同样以峰值点为度值大小分界点, 差别在于新标签-旧标签只考虑连接右端, 则旧标签-旧标签要同时考虑连接左右两端, 如果两端度值均不小于峰值点度值, 则表明旧标签间具有度度正相关, 服从优先连接模式; 反之则表明旧标签间具有度度负相关, 不服从优先连接模式。
通过表8分析可知:
表8 标签连接模式分析
标签连接模式 时间 | 新标签-旧标签 | 旧标签-旧标签 | ||
|---|---|---|---|---|
| 优先连接 | 非优先 连接 | 优先连接 | 非优先 连接 | |
| 2013-2014 | 7 439 | 10 120 | 14 294 | 38 993 |
| 2013-2015 | 5 730 | 12 354 | 21 758 | 59 575 |
| 2013-2016 | 6 233 | 14 856 | 25 582 | 87 714 |
| 均值 | 6 467 | 12 443 | 20 545 | 62 094 |
(1) 新标签平均优先连接数6 467, 非优先连接数为12 443, 两者比例为0.520, 再结合4.2节推论, 可知新标签以96.5%概率与旧标签建立联系, 且这种联系只有34.2%服从优先连接模式, 65.8%不服从优先连接模式, 因此可以说新标签间连接基本不服从优先连接模式, 新标签与旧标签连接也不服从优先连接模式, 反而非优先连接模式占据主导地位。
(2) 旧标签与旧标签之间经统计呈现度度正相关的平均比例为24.9%, 度度负相关的平均比例为75.1%, 因此可以说旧标签间连接也不完全服从优先连接模式, 反而非优先连接模式占据主导地位。上述两组分析结果进一步验证了4.1节对标签度分布规律的判断, 同时细化探析了4.2节标签之间连接或强化关系形成的内在机理。
上述分析结论与常规研究得出的分析结论存在一定差异, 核心体现在标签度分析规律判定上, 常规研究认定标签度分布符合幂律, 新标签对连接主要遵循优先连接模式。但上述分析却不完全遵循这一模式, 对照研究综述和整个分析过程, 主要原因在于标签网络构建依据客观语料, 但标签标注却是用户主观行为, 用户标注的随意性及用户本身的知识存量、理解能力都会对标注标签产生一定影响, 本文研究试图从网络科学视角解读标签网络增长态势和连接模式, 没有从心理学、传播学角度对用户标注行为及其对研究主题的影响进行强化分析。目前综合网络科学与行为科学的分析尚存在权重分配、融合分析算法设计等方面的问题, 也是后续研究亟待扩展的内容。
网络增长的微观机制导致了在线社会网络宏观结构的涌现, 揭示该过程对于理解在线社会网络的演化至关重要。当社交网络中一个新主题产生时, 新主题包括的标签可能是新标签, 也可能是旧标签, 由此形成的标签关系包括新标签-新标签、新标签-旧标签和旧标签-旧标签。本文以社交网络MetaFilter标签数据为分析对象, 从社交网络标签关系增长角度出发, 分析标签网络的增长态势和连接模式。增长态势部分重点描绘了标签网络增长的拟合曲线, 结合t检验和相关性分析, 说明了标签网络增长过程中的节点特征: 在前一个时间观察窗口度值越大的标签, 在后一个时间观察窗口度值也越大, 但是度值增长比例却较小, 这说明标签网络增长服从特定的连接模式。
为探究社交网络标签连接模式, 笔者在解析标签连接可能存在的连接模式的基础之上, 首先分析了标签度分布规律, 指出社交网络标签度分布并不服从幂律, 呈现出单峰居中, 左侧震荡, 右侧平缓的分布态势; 然后细化统计标签连接的类型及对应的数量后, 归纳出“新标签以极大概率与旧标签建立联系, 旧标签以小概率建立与其他旧标签的联系, 以大概率强化已经建立好的连接关系”的结论; 最后定义度度相关性指标解析标签服从优先连接模式的概率, 验证分析得出无论是“新标签-旧标签”还是“旧标签-旧标签”均不完全服从优先连接模式。
综合两部分分析, 发现社交网络标签增长并不服从之前多数研究所认定的优先连接模式, 反而呈现出更为复杂的增长规律, 非优先连接模式在标签关系连接或强化过程中可能占据着主导地位。这主要源于之前在线社交网络标签增长分析更强调通过数学建模、仿真分析等手段获取观察结果, 因为社交网站对于自己数据的保密政策使得研究者很难获取带有时间标记的演化网络的数据, 因此长久以来难以通过真实数据揭示标签网络增长态势和连接机制。仿真分析与采用真实标签网络分析尚存在一定差距, 同时模型分析虽然简化了现实问题分析的复杂程度, 但模型设置参数或变量不一定完全和真实分析的影响因素存在一一映射。鉴于社交媒介环境下异质网络语义元素之间的关联性, 后续研究中, 笔者将从用户视角分析用户标 记行为对社交网络标签网络增长和连接模式形成的 影响。
叶光辉: 提出研究思路及命题, 资料收集, 论文撰写及文字校对;
胡婧岚, 徐健: 数据搜集, 数据分析;
夏立新: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 3879-4081@163.com。
[1] 叶光辉, 胡婧岚, 徐健, 夏立新. MetaFilter music section 2006-2016 tag数据.sql. MetaFilter音乐版块2006年-2016年数据.
| [1] |
社交网络图像垃圾标签去除研究 [D].Research on Filtering Tag Spam of Social Network Images [D]. |
| [2] |
社会标注可信度评价方法研究 [D].Research on Method of Evaluating Confidence of Social Annotations [D]. |
| [3] |
基于用户自描述标签的层次分类体系构建方法 [J].Taxonomy Construction Based on User Self-describing Tags [J]. |
| [4] |
一种基于句法分析的情感标签抽取方法 [J].https://doi.org/10.13266/j.issn.0252-3116.2014.14.002 URL [本文引用: 1] 摘要
指出情感标签由评价对象和情感词组成,包含评论的关键要素,能清楚地表达评价者的观点意见。提出一种针对产品网络评论的情感标签抽取模型,利用依存句法分析设计情感标签抽取算法,通过情感极性计算对抽取出的情感标签进行过滤。通过放宽的抽取规则与情感极性过滤相结合,以提高情感标签的召回率,实现潜在评价对象的抽取。最后用网络抓取的产品评论语料作为测试数据集对模型进行测试,获得较高的抽取准确率和召回率,并对模型中存在的问题进行总结,作为模型改善的指导。
A Sentiment Label Extraction Method Based on Dependency Parsing [J].https://doi.org/10.13266/j.issn.0252-3116.2014.14.002 URL [本文引用: 1] 摘要
指出情感标签由评价对象和情感词组成,包含评论的关键要素,能清楚地表达评价者的观点意见。提出一种针对产品网络评论的情感标签抽取模型,利用依存句法分析设计情感标签抽取算法,通过情感极性计算对抽取出的情感标签进行过滤。通过放宽的抽取规则与情感极性过滤相结合,以提高情感标签的召回率,实现潜在评价对象的抽取。最后用网络抓取的产品评论语料作为测试数据集对模型进行测试,获得较高的抽取准确率和召回率,并对模型中存在的问题进行总结,作为模型改善的指导。
|
| [5] |
基于社会标签的图像情感分类标注研究 [J].https://doi.org/10.13266/j.issn.0252-3116.2016.21.014 URL [本文引用: 1] 摘要
[目的 /意义]提出利用社会标签自动分类图片情感类型的方法,服务基于情感特征的图像检索与利用。[方法/过程]以Flickr图片为例,利用PMI算法对Word Net-Affect词表进行预处理形成典型情感词表;结合Ekman提出的6类基本情感类型,利用标签对图片情感类型进行标注;并且,通过实验对分类标注效果进行验证;最后,讨论图片特点、标注意图、非情感标签数量对分类标注效果的影响。[结果 /结论]研究发现,一幅图片的非情感标签与情感标签在表现图片整体情感类型的倾向性上具有较高一致性;结合PMI算法,利用预处理后的典型情感词表标注图片的结果优于未处理的Word Net-Affect词表;并且,分类标注效果与人工标注结果也具有较好的一致性,其中,快乐类(Happy)和忧伤类(Sad)图片的分类标注一致性最高,惊讶类(Surprise)的分类标注一致性最低;分析发现,仅通过标签标注图片情感类型的过程中,分类标注效果与图片情感的典型性、单一性以及图片发布方和欣赏者意图、动机的差异、图片的非情感标签个数都有关系。
Research on Image Emotional Annotations Based on Social Tags [J].https://doi.org/10.13266/j.issn.0252-3116.2016.21.014 URL [本文引用: 1] 摘要
[目的 /意义]提出利用社会标签自动分类图片情感类型的方法,服务基于情感特征的图像检索与利用。[方法/过程]以Flickr图片为例,利用PMI算法对Word Net-Affect词表进行预处理形成典型情感词表;结合Ekman提出的6类基本情感类型,利用标签对图片情感类型进行标注;并且,通过实验对分类标注效果进行验证;最后,讨论图片特点、标注意图、非情感标签数量对分类标注效果的影响。[结果 /结论]研究发现,一幅图片的非情感标签与情感标签在表现图片整体情感类型的倾向性上具有较高一致性;结合PMI算法,利用预处理后的典型情感词表标注图片的结果优于未处理的Word Net-Affect词表;并且,分类标注效果与人工标注结果也具有较好的一致性,其中,快乐类(Happy)和忧伤类(Sad)图片的分类标注一致性最高,惊讶类(Surprise)的分类标注一致性最低;分析发现,仅通过标签标注图片情感类型的过程中,分类标注效果与图片情感的典型性、单一性以及图片发布方和欣赏者意图、动机的差异、图片的非情感标签个数都有关系。
|
| [6] |
一种子空间聚类算法在多标签文本分类中应用 [J].https://doi.org/10.3969/j.issn.1000-386x.2014.08.072 URL [本文引用: 1] 摘要
随着社交网络的兴起,文本数据不断增加,这使得自动化文本分类技术成为研究的热点。单个文本可能同时带有多个类别标签,该特点直接导致传统的二分类或多类别分类技术在多标签文本数据上性能不佳。针对这一不足,提出一种基于半监督杂质的子空间聚类分析算法SCA(subspace clustering analysis),该算法分析在多标签环境下每一对分类和标签之间存在的潜在相关性。并设计一种对分类文本数据更有效的多标签分类器。最后,实验对两个多标签文本集进行分析,结果表明该算法优于当前采用的其他文本分类方法。
Applying a Subspace Clustering Algorithm in Multi-Label Text Classification [J].https://doi.org/10.3969/j.issn.1000-386x.2014.08.072 URL [本文引用: 1] 摘要
随着社交网络的兴起,文本数据不断增加,这使得自动化文本分类技术成为研究的热点。单个文本可能同时带有多个类别标签,该特点直接导致传统的二分类或多类别分类技术在多标签文本数据上性能不佳。针对这一不足,提出一种基于半监督杂质的子空间聚类分析算法SCA(subspace clustering analysis),该算法分析在多标签环境下每一对分类和标签之间存在的潜在相关性。并设计一种对分类文本数据更有效的多标签分类器。最后,实验对两个多标签文本集进行分析,结果表明该算法优于当前采用的其他文本分类方法。
|
| [7] |
新浪微博用户领域分类标签的结构和互动研究 [J].https://doi.org/10.3969/j.issn.1002-1965.2014.04.022 URL [本文引用: 1] 摘要
使用社会网络分析方法,以新浪微博用户互惠关系为研究基础,通过实证分析新浪微博用户领域分类标签的密度,研究微博用户领域分类标签结构;打破原来用户所处微博用户领域分类标签格局,依据用户互惠关系对其进行重新分组,探讨在微博空间中各领域标签的互动情况。密度分析结果表明新浪微博对娱乐、传媒、健康、军事、房产分类标签影响较大,对汽车和公益分类标签影响相对较小;通过凝聚子群分析发现5组高密度凝聚子群,每组凝聚子群包含的分类标签互动程度高,影响程度大,从而能为舆论的监控和引导以及预测领域信息对其他领域影响关系提供理论依据。
Structure and Interaction: The User Category Tags on the Sina Microblog [J].https://doi.org/10.3969/j.issn.1002-1965.2014.04.022 URL [本文引用: 1] 摘要
使用社会网络分析方法,以新浪微博用户互惠关系为研究基础,通过实证分析新浪微博用户领域分类标签的密度,研究微博用户领域分类标签结构;打破原来用户所处微博用户领域分类标签格局,依据用户互惠关系对其进行重新分组,探讨在微博空间中各领域标签的互动情况。密度分析结果表明新浪微博对娱乐、传媒、健康、军事、房产分类标签影响较大,对汽车和公益分类标签影响相对较小;通过凝聚子群分析发现5组高密度凝聚子群,每组凝聚子群包含的分类标签互动程度高,影响程度大,从而能为舆论的监控和引导以及预测领域信息对其他领域影响关系提供理论依据。
|
| [8] |
社会语义网络结构分析——以MetaFilter为例 [J].https://doi.org/10.16353/j.cnki.1000-7490.2015.12.012 URL [本文引用: 1] 摘要
为充分利用社交网络资源,以MetaFilter为数据源,分析社会语义网络结构。通过面向对象方法,指出社会语义网络是融合多维语义关系的元网络;以post title为语料,揭示tag分布符合幂律,并参照Cite ULike,探讨用户标注行为及主题的演化;统计主流版块的comment、favorite及category数据,透视用户标注主题及方式;围绕整体网络、多维语义关系网络,借助相应指标量化网络结构特征和用户角色。用户角色识别不能单纯依靠网络分析,尚需结合语义分析。QA是社会语义网络中最活跃的语义关系,但知识复用率较低,且基于实际问答关系的用户连通性不足。
Structure Analysis on Semantic Social Network Based on MetaFilter [J].https://doi.org/10.16353/j.cnki.1000-7490.2015.12.012 URL [本文引用: 1] 摘要
为充分利用社交网络资源,以MetaFilter为数据源,分析社会语义网络结构。通过面向对象方法,指出社会语义网络是融合多维语义关系的元网络;以post title为语料,揭示tag分布符合幂律,并参照Cite ULike,探讨用户标注行为及主题的演化;统计主流版块的comment、favorite及category数据,透视用户标注主题及方式;围绕整体网络、多维语义关系网络,借助相应指标量化网络结构特征和用户角色。用户角色识别不能单纯依靠网络分析,尚需结合语义分析。QA是社会语义网络中最活跃的语义关系,但知识复用率较低,且基于实际问答关系的用户连通性不足。
|
| [9] |
Topic Sense Induction from Social Tags Based on Non-negative Matrix Factorization [J].https://doi.org/10.1016/j.ins.2014.04.048 URL [本文引用: 1] 摘要
Social tagging, also noted as collaborative tagging or folksonomy, is an important way for users themselves to describe resources on the Web. The tags that the web users adopt to describe the resources are called social tags, and they have been widely used and studied. However, for the absence of a central controlled vocabulary, the semantics of the social tags are ambiguous due to constant changes of either the users interests or the informal definitions, which makes it hard to directly make use of these social tags in the web applications. In this paper, we propose a non-negative matrix factorization (NMF) based method to automatically induce topic senses from social tags, which can then be used for the tag disambiguation. A novel automatic evaluation method is also proposed to evaluate our method. The experiment results show that the proposed topic sense induction method can help to provide precise resources search and recommendation, which is one of the key functionalities in social tagging systems.
|
| [10] |
Automatic Clustering of Social Tag Using Community Detection [J].https://doi.org/10.12785/amis/070235 URL [本文引用: 1] 摘要
Automatically clustering social tags into semantic communities would greatly boost the ability of Web services search engines to retrieve the most relevant ones at the same time improve the accuracy of tag-based service recommendation. In this paper, we first investigate the different collaborative intention between co-occurring tags in Seekda as well as their dynamical aspects. Inspired by the relationships between co-occurring tags, we designed the social tag network. By analyzing the networks constructed, we show that the social tag network have scale free properties. In order to identify densely connected semantic communities, we then introduce a novel graph-based clustering algorithm for weighted networks based on the concept of edge betweenness with high enough intensity. Finally, experimental results on real world datasets show that our algorithm can effectively discovers the semantic communities and the resulting tag communities correspond to meaningful topic domains.
|
| [11] |
Social Link Prediction in Online Social Tagging Systems [J].https://doi.org/10.1145/2516891 URL [本文引用: 1] 摘要
Social networks have become a popular medium for people to communicate and distribute ideas, content, news, and advertisements. Social content annotation has naturally emerged as a method of categorization and filtering of online information. The unrestricted vocabulary users choose from to annotate content has often lead to an explosion of the size of space in which search is performed. In this article, we propose latent topic models as a principled way of reducing the dimensionality of such data and capturing the dynamics of collaborative annotation process. We propose three generative processes to model latent user tastes with respect to resources they annotate with metadata. We show that latent user interests combined with social clues from the immediate neighborhood of users can significantly improve social link prediction in the online music social media site Last.fm. Most link prediction methods suffer from the high class imbalance problem, resulting in low precision and/or recall. In contrast, our proposed classification schemes for social link recommendation achieve high precision and recall with respect to not only the dominant class (nonexistence of a link), but also with respect to sparse positive instances, which are the most vital in social tie prediction.
|
| [12] |
Enhancing Tag-based Collaborative Filtering via Integrated Social Networking Information [C]// |
| [13] |
基于社会化标签网络的细粒度用户兴趣建模 [J].Fine-grained User Preference Modeling Based on Tag Networks [J]. |
| [14] |
Mining Users’ Interest Graph in Social Networks with Topic Based Tag Propagation [C]// |
| [15] |
基于社会网络分析的社会化标签网络分析与个性化信息服务研究 [J].Social Labeling Network Analysis and Personalized Information Service Research Based on Social Network Analysis [J]. |
| [16] |
社会化标签系统中基于社会网络的知识推送网络演化研究 [J].
利用网络分析方法,本文将社会化标签系统中基于社会网络的知识推送网络构造方法描述为六个步骤。借鉴演化理论,将基于社会网络的知识推送网络演化动力归纳为内生动力和外生动力。移植生物进化论的相关理论,提出多重动力机制作用下基于社会网络的知识推送网络演化周期性模型:每个周期的起点就是新一轮社会网络的构建,每个周期内部的演化过程分为选择阶段、遗传阶段、变异阶段。依托原型系统搜集不同时间点的相关数据,利用网络结构计量方法对基于潜在社会网络的知识传播网络演化过程进行实证分析,印证上述理论研究成果。图8。表9。参考文献13。
Evolution of Knowledge Push Network Based on Social Network in Social Tagging System [J].
利用网络分析方法,本文将社会化标签系统中基于社会网络的知识推送网络构造方法描述为六个步骤。借鉴演化理论,将基于社会网络的知识推送网络演化动力归纳为内生动力和外生动力。移植生物进化论的相关理论,提出多重动力机制作用下基于社会网络的知识推送网络演化周期性模型:每个周期的起点就是新一轮社会网络的构建,每个周期内部的演化过程分为选择阶段、遗传阶段、变异阶段。依托原型系统搜集不同时间点的相关数据,利用网络结构计量方法对基于潜在社会网络的知识传播网络演化过程进行实证分析,印证上述理论研究成果。图8。表9。参考文献13。
|
| [17] |
Combining Tag Correlation and User Social Relation for Microblog Recommendation [J].https://doi.org/10.1016/j.ins.2016.12.047 URL [本文引用: 1] 摘要
With the development of social networking applications, microblog has turned to be an indispensable online communication network in our daily life. For microblog users, recommending high quality information is a demanding service. Some microblog services encourage users to annotate themselves with tags, which are used to describe their interests or attributes. However, few users are willing to create tags and available tags are not fully exploited for microblog recommendation. Besides, following/follower relationship in microblog is asymmetric, which can be used not only for communicating with friends or acquaintances but also for getting information on particular subjects. So far, there is no microblog recommendation algorithm which employs all the above mentioned information. This paper aims to investigate a joint framework to combine tag correlation and user social relation for microblog recommendation. Our approach identifies users鈥 interests via their personal tags and social relations. More specifically, a user tag retrieval strategy is established to add tags for users without or with few tags, and the user-tag matrix is then built and user-tag weights are then obtained. In order to solve the problem of sparsity of the matrix, both inner and outer correlation between tags are investigated to update the user-tag matrix. Considering the significance of user social relation for microblog recommendation, a user鈥搖ser social relation similarity matrix is constructed. Moreover, an iterative updating scheme is developed to get the final tag-user matrix for computing the similarities between microblogs and users. We illustrate the capability of our algorithm by making experiments on real microblog datasets. Experimental results show that the algorithm is effective for microblog recommendation.
|
| [18] |
社会语义网社区发现标签传递算法研究 [J].Study on Label Propagation Based Community Detection Algorithm for Social Semantic Network [J]. |
| [19] |
在线社会网络中信息扩散研究 [D].Research of Information Diffusion in Online Social Networks [D]. |
| [20] |
舆情热点事件中“标签式传播”现象研究——以“二代”现象为例 [D].Study on Label Communication Phenomenon in the Hot Events of Public Opinion——Take “Sencond Genenration Phenomenon” as an Example [D]. |
| [21] |
知识共享视角下的大众标注行为研究——基于标签的实证分析 [J].Study on the Behaviour of Social Tagging from the Aspect of Knowledge Sharing: An Empirical Analysis Based on Tags [J]. |
| [22] |
基于信息增益与语义特征的多标签社交网络用户人格预测 [J].https://doi.org/10.13413/j.cnki.jdxblxb.2016.03.28 URL [本文引用: 1] 摘要
针对社交网络用户人格预测问题,提出一种结合信息增益与语义特征提炼用户文本信息,并采用多标签分类算法进行综合预测的方法。先基于信息增益提取文本词特征,包括情感词、词性和时态等,进行特征选择与加权;对于语义特征,将文本内容映射为本体概念并计算语义相关度;然后以基于词的特征和语义特征的共同影响为依据,运用多标签分类算法执行人格预测过程,从不同角度处理文本信息,并充分考虑了类标签间的相关性。实验结果验证了该方法的有效性。
Multi-labeled Social Networks Users Personality Prediction Based on Information Gain and Semantic Features [J].https://doi.org/10.13413/j.cnki.jdxblxb.2016.03.28 URL [本文引用: 1] 摘要
针对社交网络用户人格预测问题,提出一种结合信息增益与语义特征提炼用户文本信息,并采用多标签分类算法进行综合预测的方法。先基于信息增益提取文本词特征,包括情感词、词性和时态等,进行特征选择与加权;对于语义特征,将文本内容映射为本体概念并计算语义相关度;然后以基于词的特征和语义特征的共同影响为依据,运用多标签分类算法执行人格预测过程,从不同角度处理文本信息,并充分考虑了类标签间的相关性。实验结果验证了该方法的有效性。
|
| [23] |
社交博客标签分布的布拉德福定律验证分析 [J].Bradford’s Law Confirmatory Analysis of Social Blog Tag Distribution [J]. |
| [24] |
|
| [25] |
A Mathematical Theory of Evolution, Based on the Conclusions of Dr. J. C. Willis, F. R. S [J].https://doi.org/10.1098/rstb.1925.0002 URL [本文引用: 1] |
| [26] |
链接分布机制评述——优先连接和均匀连接 [J].https://doi.org/10.3969/j.issn.1002-1965.2010.10.038 URL [本文引用: 1] 摘要
评述了Web中链接的分布机制——优先连接与均匀连接。大型链接网络中,可用二者结合的混合机制对链接分布现象进行解释。整体而言,链接分布呈幂律分布,可用优先连接机制进行解释,但对于特定的网页集合,需用均匀连接机制进行解释。链接网络中,存在人为操纵的链接现象,如"交换链接"、"购买链接"等,两种机制均无法解释。引文网络与链接网络相似,本文提出可将链接分布机制移植到引文分布的研究中。
Review on the Mechanism of Link Degree Distribution——Preferential Attachment and Uniform Attachment [J].https://doi.org/10.3969/j.issn.1002-1965.2010.10.038 URL [本文引用: 1] 摘要
评述了Web中链接的分布机制——优先连接与均匀连接。大型链接网络中,可用二者结合的混合机制对链接分布现象进行解释。整体而言,链接分布呈幂律分布,可用优先连接机制进行解释,但对于特定的网页集合,需用均匀连接机制进行解释。链接网络中,存在人为操纵的链接现象,如"交换链接"、"购买链接"等,两种机制均无法解释。引文网络与链接网络相似,本文提出可将链接分布机制移植到引文分布的研究中。
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}