
|
|
庞贝贝, 苟娟琼 , 穆文歆
, 穆文歆
北京交通大学经济管理学院 北京 100044
Pang Beibei, Gou Juanqiong, Mu Wenxin
中图分类号: TP393
通讯作者:
收稿日期: 2018-01-18
修回日期: 2018-02-20
网络出版日期: 2018-06-25
版权声明: 2018 《数据分析与知识发现》编辑部 《数据分析与知识发现》编辑部
基金资助:
展开
摘要
【目的】对高校学生深度辅导这一特定领域知识进行建模, 提出一个支持小规模知识获取和建模的框架。【方法】采用LDA模型识别出文档集合所包含的主题及标识主题的词组; 对“文档-主题”矩阵进行概念层次分析, 获取主题之间的上下位关系; 并将建模结果统一编码为本体的形式存入知识库, 以便进行知识检索。【结果】本研究面向深度辅导具体应用, 引入概念层次分析法, 在LDA建模基础上进一步细化主题知识的粒度, 改善了LDA主题建模结果难以表达主题之间关联关系的难题。【局限】未考虑新的深度辅导文档带来的知识库增量更新问题。【结论】本研究框架能够很好地支持深度辅导领域中诸如学生问题、交流方式、引导技巧等多粒度知识的建模与检索。
关键词:
Abstract
[Objective] This paper proposes a framework for small-scale knowledge acquisition and modeling, aiming to more effectively manage the College Students’ deep mentoring work. [Methods] Firstly, we used the LDA to identify topics of collected documents, as well as the phrases describing the topics. Secondly, we used the concept hierarchy analysis to get the relations among these topics. Finally, we encoded ontology of the modeling results for knowledge retrieval. [Results] This study further refined the granularity of topic knowledge on the basis of LDA modeling, which reduced the difficulty of topic modeling and describe their relationship. [Limitations] We did not examine the expanded knowledge base generated by the new depth mentoring documents. [Conclusions] The proposed framework supports the modeling and retrieval of multi granularity knowledge from deep counseling, such as identifying problems, communication methods, and guiding skills.
Keywords:
高校学生深度辅导主要是指针对困扰学生的具体问题进行个性化辅导, 为每一名学生的健康成长提供有力支持。从2009年开始, 北京市委教育工作委员会提出要把“确保每名学生每年都能得到至少一次有针对性的深度辅导”作为深度辅导工作的一项具体要求。在具体的深度辅导过程中, 辅导员一方面需要通过与学生的谈话快速定位学生的问题所在, 另一方面需要针对问题及时对学生行为进行引导。整个辅导过程对辅导员历史经验的依赖性非常强。对于年轻的辅导员, 这一挑战无疑是巨大的。然而现有关于深度辅导的研究多停留在理论教育层面, 缺乏具体的实践指导。
因此, 本研究希望通过对历史的非结构化深度辅导文档集进行分析, 提取并存储深度辅导谈话内容中涉及的领域知识, 进而以知识检索的方式帮助辅导员降低压力、提升工作效率。在对深度辅导领域知识建模中, 多层谈话主题的获取是该领域知识建模的难点, 具体体现为深度辅导谈话中所涉及的学生问题、交流方式、引导技巧、辅导模式等多粒度知识的建模。
基于此, 针对特定的深度辅导领域知识建模问题, 本研究提出一个支持小规模知识获取和建模的框架, 主要用于从非结构化文本资源中半自动挖掘潜在的知识, 并对获取的潜在知识进行进一步的语义增强知识建模, 建立知识库, 实现知识共享。本研究框架所构建的领域知识模型可描述为: 将一个给定的集合(可以是一个单一的文本, 也可以是多个文本的集合)抽象为多个主题(由特征词集描述主题), 以及这些主题之间的上下位语义关系。最后, 将研究框架所获得的多粒度知识统一编码为本体的形式, 以便进行知识存储、检索以及更新。
主题模型作为一种文本内容的概率生成模型, 通过对人类思维过程的模拟, 找到产生文本的最佳主题和词汇, 是目前最常用的文本主题提取方法。现有的主题模型主要包括: 潜在语义分析(LSA)、概率潜在语义分析(PLSA)和潜在狄利克雷分配(LDA)。
LSA打破了以往基于“词典空间”进行文本表示的思维, 创新性地引入语义维度, 实现了文档在低维隐含语义空间上的表示。但是LSA方法论的基础来源于线性代数, 运算结果在很多维度上为负数[1]。霍夫曼针对LSA的缺陷提出一个构建在可靠的概率统计学基础上的新方法PLSA。但PLSA并没有在文档层提供概率模型, 导致模型中待估参数的数量随语料库的大小呈线性增长, 容易出现过度拟合问题[2]。2003年, Blei等通过引入一个Dirichlet先验分布扩展了PLSA模型, 克服了PLSA参数随着文档集增长而线性增长的不足, 形成当前被广泛应用的产生式概率主题模型LDA[3]。
现有研究中, 利用LDA主题模型进行文档主题知识挖掘的方向共分为两类, 一是利用LDA模型进行主题提取, 识别并关联不同时间片段下的相似主题, 进而实现主题演化趋势分析。杨海霞等[4]借助LDA主题模型, 依照时间戳从文档集合中提取主题并根据不同时间段下主题强度的变化分析主题的演化趋势; 胡吉明等[5]进一步从主题相似度和强度两个方面构建动态LDA模型, 描述主题在内容和强度上随时间变化的趋势; 徐月梅等[6]将LDA与流行学习(ISOMAP非线性降维)相结合, 实现了在低维可视平面上描绘主题在全局时间跨度的演化分析。二是利用LDA模型进行主题提取与主题语义增强, 建模结果多用于知识存储与检索。现有文献中的主题语义增强视角分为: 基本的主题语义类型及语法关系增强, 主题与描述主题的词汇之间进行语义增强两个层面。
(1) 从主题语义类型和语法关系增强视角: 冯佳等[7]通过LDA模型抽取研究主题, 并基于领域本体进行概念映射挖掘主题的语义类型; Rocca等[8]利用LDA模型进行主题抽取、语法关系加强等, 形成SKOS本体以支持知识检索。
(2) 从主题与描述主题的词汇之间进行语义增强视角: 阮光册等[9]利用LDA主题建模结果进行文本降维, 并对降维后的文本主题数据进行关联规则分析, 进一步挖掘文本主题与词汇之间的语义关联; 王红 等[10]借助LDA模型实现领域本体核心概念的相关术语提取, 并基于LDA主题概率分布研究了概念和术语之间的语义关系识别规则的构建方法。
通过对文档主题分析相关文献的综述可知, 现有研究采用LDA方法进行主题提取之后, 多从主题相似性、主题语义类型及语法关系增强、主题与词汇语义关系增强视角进行研究, 缺乏对主题与主题之间层次关系的研究。但是对于特定领域的知识建模而言, 概念层次关系是最重要的知识元素, 在深度辅导领域, 对于特殊学生的潜在问题进行精准定位具有重要意义。因此, 对主题粒度的研究显得尤为重要, 需要基于LDA主题建模结果进一步识别主题与主题之间的概念层次关系。
概念层次关系包含两种类型: 对称关系和非对称关系。对于前者, 由于查询扩展、词表构建等的需要, 研究相对成熟。后者则是目前知识建模研究的重点, 不同领域的学者针对来源数据的特征及知识层次的具体应用提出各种构建方法[11]。概念层次分析研究方法分为三个方向:
(1) 最典型的是层次聚类分析(Hierarchical Clustering Analysis)方法, 该方法使用术语连接规则, 通过层次式架构方式将术语聚类形成若干个具有层次关系的主题簇[12], 但由于多数层次聚类分析算法都具有较高的计算复杂度, 并不适用于大规模数据集[13]。
(2) 形式概念分析FCA(Formal Concept Analysis)方法, 这是一种用于数据分析、知识管理、本体构建等领域的数学方法, 利用对象和属性间的映射关系描述领域的形式化背景, 半自动化识别概念间的层次关系[14]。如: 王昊等[11]将FCA理论应用于医学学科领域, 用于建立中文医学专业术语之间的层次关系。
(3) 基于知识库的方法, 利用现有知识库(维基百科、WordNet)等资源, 对需要分层的术语进行定义, 通过定义术语之间的语义关系来解析术语之间的层次结 构[16]。该方法识别效果好, 但是对知识库的领域依赖性较强[11]。
通过对现有概念层次分析法的综述, 发现主题建模得到的“文档-主题-概率”矩阵可以借助域值设定, 半自动转换为形式概念分析法的输入矩阵, 两种方法结合可实现主题上下位层次关系的半自动识别, 有效分析主题粒度并获取主题之间的潜在语义知识。为此, 本研究结合深度辅导领域知识建模所面临的特定问题, 提出一个支持小规模知识获取和建模的框架, 对深度辅导领域进行主题知识提取。
该方法基于两个模型: 潜在狄利克雷分配(LDA)和形式概念分析法(FCA)。首先, LDA主要用于对非结构化文本资源进行主题建模, 并借助领域知识, 识别文档集合中包含的主题, 以及标识主题的词组。其次, FCA根据LDA输出的“文档-主题-概率”矩阵构建概念网格, 进一步分析主题概念之间的上下位语义关系。最后, 将提取的知识统一编码为本体的形式, 描绘一个语义的多粒度图或网络, 建模结果所包含的节点如下:
(1) 主题: 从更加抽象的角度描述文档;
(2) 词组: 用于描述/标识主题;
(3) 词汇: 从一般抽象角度描述文档与词组。
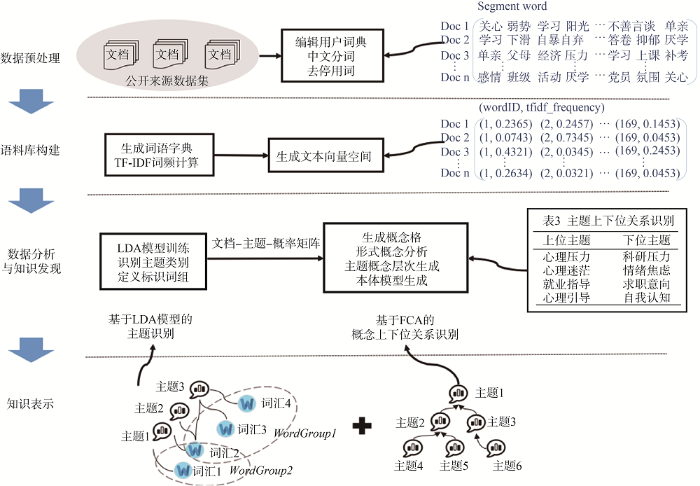
本文的总体研究思路共分为4个部分: 数据预处理、语料库构建、数据分析与知识发现、知识表示, 如图1所示。
(1) 数据预处理: 主要包括编辑用户字典、对数据集进行中文分词、去停用词。
(2) 语料库构建: 由于深度辅导文本中存在大量的诸如“同学”“学生”“大学”之类的词汇, 这类词汇虽然词频高, 但并不能直观反映主题类型, 属于干扰词汇, 因此, 选择TF-IDF词频替代传统的词数统计来 生成文本向量空间, 在一定程度上降低干扰词汇的 影响。
(3) 数据分析与知识发现: 细分为基于LDA模型的主题识别和基于形式概念分析法的概念上下位关系识别, 用于识别主题、主题标识词组以及主题之间的上下位关系。
(4) 知识表示: 主要是将多粒度知识抽取结果进行存储与检索。
为了提取学生深度辅导领域知识, 首先通过网页爬虫软件获取深度辅导文档。并对数据进行适当的预处理。预处理程序包括: 筛除无意义的文档, 去除每篇文档的回车符、图片, 将所有文档整合为一个文档集合, 并对文档集合进行分词操作。为了提升计算机分词准确率, 本研究以人工参与方式建立领域字典表和停用词表:
(1) 领域字典表的目的是为了避免切词工具误将领域专有词汇进行切分。根据领域知识以及实验切词结果, 多次迭代建立字典表, 获得187个深度辅导领域专有名词;
(2) 停用词指切词文档中的符号、语气词、副词、介词、连接词等无用词语, 如“的”、“在”等。根据网上现有资源, 对“哈尔滨工业大学停用词词库”、“四川大学机器学习智能实验室停用词词库”、“百度停用词表”等各种停用词表进行整合去重, 得到比较全面的停用词表, 共2 340个停用词。
在现有的词频表示方法中, TF-IDF(Term Frequency- Inverse Document Frequency)作为一种统计方法, 可以很好地评估一个字词对于一个文档集或语料库中的某份文件的重要程度[16]。故选择TF-IDF词频替代简单的词数统计。
公式(1)表示的是词语ti在文档dj中TF词频, 其中, 分子表示词语ti在文档dj中出现的次数, 分母表示文档dj中所有字词出现的次数之和。
公式(2)表示的是词语ti的逆向文档频率, 其中, $\left| D \right|$指语料库中的文档总数, $\left| \left\{ j:{{t}_{i}}\in {{d}_{j}} \right\} \right|$表示语料库中包含词汇ti的文档总数, 为了避免词语不在语料库中的特殊情况, 分母一般使用$\left| \left\{ j:{{t}_{i}}\in {{d}_{j}} \right\} \right|+1$。
公式(3)用于计算公式(1)和公式(2)的乘积。得到第j篇文档的在整个语料库中的TF-IDF词频。
$tf(i,j)=\sum\limits_{j=1}^{n}{\frac{{{n}_{ij}}}{\sum\nolimits_{k}{{{n}_{kj}}}}}$ (1)
$idf(i)=log\frac{\left| D \right|}{\left| \left\{ j:{{t}_{i}}\in {{d}_{j}} \right\} \right|+1}$ (2)
$tfidf(i,j)=tf(i,j)\times idf(i)$ (3)
通过文本预处理, 获取公开来源数据集的文本向量空间I, 其中$I=({{I}_{1}},{{I}_{2}},{{I}_{3}},\cdots ,{{I}_{n}})$, ${{I}_{j}}=[((t\_i{{d}_{1}},tfid{{f}_{j1}}),$ $(t\_i{{d}_{2}},tfid{{f}_{j2}}),(t\_i{{d}_{3}},tfid{{f}_{j3}}),\cdots ,(t\_i{{d}_{m}},tfid{{f}_{jm}}))]$, $j\in $ $\left\{ 1,2,3,\cdots ,n \right\}$, n表示所收集到的文档总数, m表示文档集合切词得到的词汇数量。
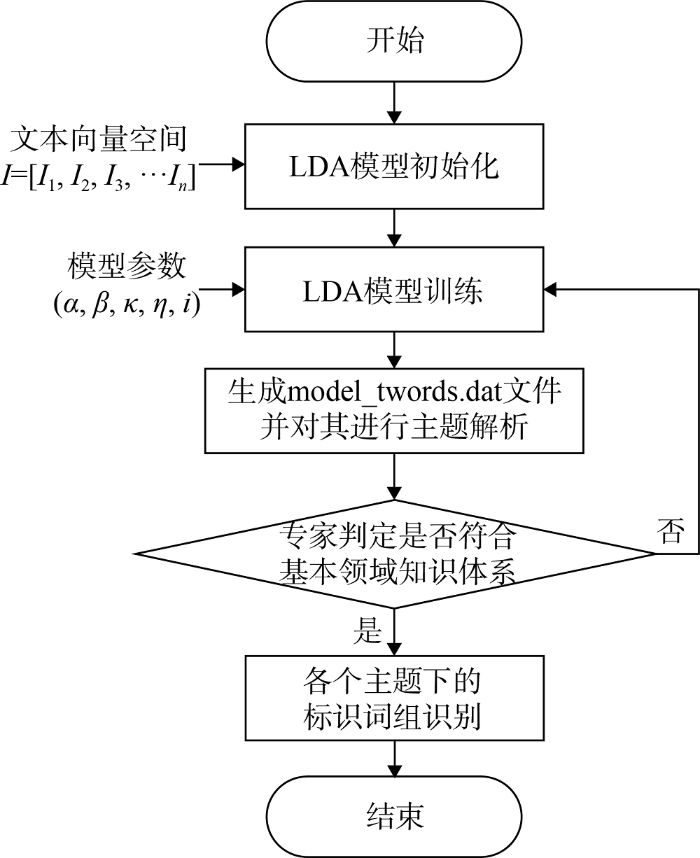
主题和标识词组的抽取是知识库建设的重要环节, 利用LDA的主题推断功能可以获取知识库中的重要主题, 以及标识这些主题的词组。以数据预处理获得的文本向量空间I作为LDA模型的训练文档, 进行基于LDA模型的主题和标识词组识别, 识别算法如图2所示。
(1) LDA模型初始化
在主题模型中, 主题表示一个概念, 表现为一系列相关的字词, 是这些字词的条件概率, 即一篇文章d中的每个词w都是通过“以一定概率选择了某个主题t, 并从这个主题t中以一定概率选择某个词语w”这样一个过程得到。那么如果要生成一篇文档, 它里面每个词语出现的概率如公式(4)所示。
$p(w|d)=\sum\limits_{t}{p(w|t)\times p(t|d)}$ (4)
这个概率公式可以用矩阵表示, 如图3所示。
给定一系列文档, 通过对文档分词、计算各个文档中每个单词的词频就可以得到左边的“文档-词语”矩阵。主题模型通过左边这个矩阵进行训练, 学习出右边两个矩阵[8]。因此, 为了获取“主题-词语”矩阵, 输入文本向量空间I作为LDA模型的训练文档。
(2) 训练LDA模型
LDA模型的训练参数包括: $(\alpha ,\beta ,k,n,i)$, 其中, $\alpha $是一个对称的Dirichlet分布的参数, 值越大意味着越平滑, 一般取值50/k, β一般取值0.01, k表示聚类的主题个数, n表示每个主题下的特征词个数, i表示吉布斯抽样迭代次数, 一般为1 000次。在参数k的估计上, 采用基于密度的自适应最优LDA模型选择方法[17]。但Topic个数确定的准确性很大程度上依赖于先验知识, 因此, 在该方法的基础上, 借助专家挖掘法判定主题建模结果是否符合基本的领域认知体系, 从而确定参数k。
(3) 各个主题下的标识词组识别
LDA主题建模生成model_twords.dat文件, 文件内容可描述为$D(N)=(topicID,word,probability)$, 即每个主题下概率值排名Top N的特征词, 依据特征词的分布, 结合领域知识, 定义主题名, 得到每个主题下稳定的标识词组。
基于FCA的术语层次分析分为两个步骤:
(1) 建立形式化背景[1], 形式化背景可以定义为一个三元组: $F=(O,M,R)$, 其中, O示对象集合, M表示属性集合, R表示对象和属性的映射关系, 本文形式化背景定义为: $F=(Documents,Topics,I)$, 其中, $Documents$表示文档集合, $Topics$表示LDA模型抽取得到的主题。文档和主题的示意关联如表1所示。其中“1”表示文档包含该主题, “0”表示不包含该主题。
表1 高校深度辅导领域的“文档-主题”矩阵
| Topic Document | 心理 压力 | 科研 压力 | 心理 抑郁 | 交友 恋爱 | 生活 作息 | 宿舍 矛盾 |
|---|---|---|---|---|---|---|
| D1 | 1 | 0 | 0 | 0 | 0 | 0 |
| D2 | 1 | 1 | 0 | 0 | 0 | 0 |
| D3 | 1 | 0 | 1 | 0 | 0 | 0 |
| D4 | 0 | 0 | 0 | 1 | 0 | 0 |
| D5 | 0 | 0 | 0 | 0 | 1 | 0 |
| D6 | 0 | 0 | 0 | 0 | 0 | 1 |
| D7 | 1 | 0 | 1 | 0 | 1 | 0 |
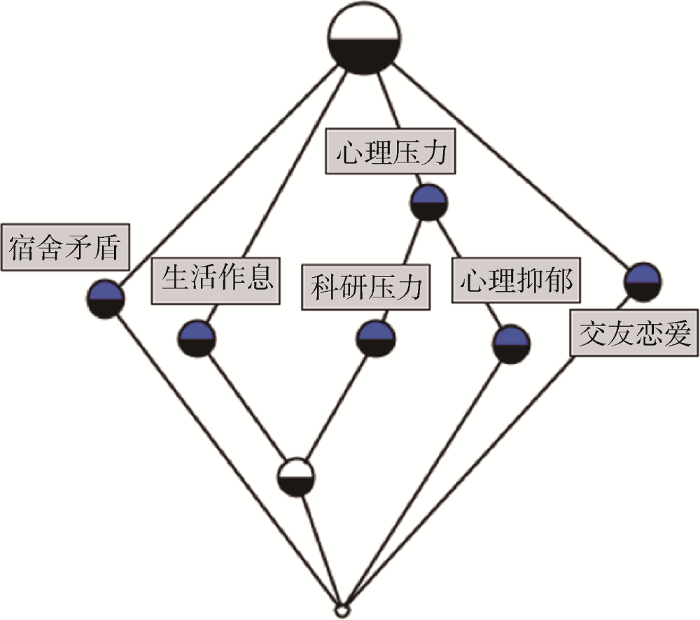
(2) 建立概念格
运用德国达姆斯塔特科技大学开发的形式概念分析工具ConExp构建概念格[18]。ConExp可以利用概念格的形式表示一个有限形式背景的结构, 并用Hasse图表示。Hasse图中圆形节点表示主题概念, 每个主题概念包含两个部分, 上半部分代表属性, 下半部分代表对象。每个概念节点的属性集合是该节点上层所有属性的总和(继承父概念属性), 对象属性是该节点下层所有对象的总和(覆盖子概念外延)。根据表1的“文档-主题”矩阵所建立的概念格如图4所示。基于FCA的概念格构建可以清晰反映出主题之间的上下位关系。在图4中可以看到心理抑郁和科研压力的上层概念均是心理压力。
基于以上建模结果, 利用W3C组织发布的OWL (Ontology Web Language)[19]对主题、词汇、词组以及主题之间的上下位逻辑关联进行语义描述, 从而便于计算机存储和处理。知识表达示意图如图5所示。
数据来源包括百度文库、道客巴巴、博客、知网等, 爬取的关键词包括“辅导员”、“深度辅导”、“大学生”、“谈话”等, 共获得总字数为1 478 969字的深度辅导记录, 存为训练文档集train.dat。
在LDA主题模型中, 结合困惑度判定法和领域专家知识, 设置主题个数T=36, 按照一般经验设置超参数$\alpha $和$\beta $, 其中, $\alpha \text{=}{50}/{\text{T}}\;\text{=}5.56$, $\beta \text{=}0.01$, “文档-主题-概率”矩阵转换为FCA形式化背景的域值设为$\sigma \text{=}2.26$。
按照第4节所述的主题和标识词组抽取方法, 对训练文档集train.dat进行LDA主题建模、参数训练、主题解析、标识词组识别, 最终得到36类主题, 共 1 080个标识词, 之后人工参与解读每类主题的含义, 部分实验结果如表2所示。
表2 LDA主题抽取结果(部分)
| 主题分类 | 标识词组 |
|---|---|
| 心理压力 | 治疗, 情绪, 抑郁症, 顺利, 本科, 导师, 保研, 逃避, 实习, 校方, 入党, 困难生, 考验, 患有, 特殊, 生活, 科研任务, 成功, 希望, 可行, 永远, 想要, 康复, 急于, 负面, 愤怒, 研究生, 生气, 瓦伦达, 暗示, 紧张, 状态, 迷茫 |
| 面谈模式 | 谈话, 学生, 了解, 情况, 交流, 进行, 深入, 沟通, 感受, 主题, 方式, 班主任, 技巧, 融入, 善于, 状况, 及时, 注意, 良好, 面对面, 内容, 课堂, 真实, 平等, 面谈, 安抚, 鞭策, 兼顾 |
| 情感& 工作受挫 | 谈心, 分手, 异常, 情感, 面试, 考试, 条件, 力不从心, 走神, 一味, 关注, 措施, 未来, 事实, 单位, 状态, 参加, 信息, 女孩, 认知, 现状, 拒绝, 倾诉, 运动, 力争, 不足之处, 行为, 不愿, 恋爱, 灌输, 表白, 疗法 |
| 人际沟通 | 心理, 支持, 行为, 过程, 期望, 内心, 接受, 社会, 契约, 自我, 感受, 师生, 信任, 情感, 认同, 人际, 沟通, 经验, 程度, 个体, 防御, 谈心, 态度, 信息, 交往, 接纳, 判断, 性格 |
| 心理引导 | 学生, 辅导员, 问题, 信任, 启发, 朋友, 信息, 协助, 挖掘, 帮助, 关注, 解决, 依靠, 做好, 有效, 心理引导, 案例, 困扰, 及时, 积极, 时间, 解决问题, 方法, 角色, 给予, 班委, 逐一, 希望, 优秀 |
| 就业指导 | 就业, 就业指导, 毕业生, 职业, 过程, 指导, 个性化, 困难, 能力, 专业, 培训, 自我, 职业生涯, 社会, 咨询, 求职, 层面, 分析, 老师, 技术, 原则, 计划, 帮助, 培养, 水平, 探索, 择业, 提高, 实施, 生涯, 工作, 选择, 公务员, 环境, 社会, 备考, 实习 |
| 求职意向 | 求职, 了解, 专业, 行业, 事业单位, 找工作, 方向, 职位, 单位, 目标, 情况, 工作, 意识, 准备, 毕业后, 规划, 企业, 就业, 竞争, 进行, 知识, 方向, 发展, 岗位, 简历, 所学, 月薪, 软件, 决定, 下一步, 成功经验 |
| 宿舍情谊 | 寝室, 舍友, 文明, 作息时间, 告知, 作息, 共识, 文化, 感情, 荣誉感, 三年, 清晰, 一起, 时光, 参加, 心情, 邀请, 欢声笑语, 幸福, 可爱, 过节, 看望, 自豪, 努力奋斗 |
| 家庭关怀 | 孩子, 母亲, 父母, 尊重, 家庭, 家长, 信任, 父亲, 谈心, 得知, 一直, 电话, 女生, 事情, 突然, 相对, 不好, 希望, 照顾, 回去, 决定, 对待, 得到, 修养 |
| 打架斗殴 | 学生, 事件, 事情, 教育, 干部, 处理, 打架, 暗示, 双方, 批评, 沟通, 造成, 积极, 思考, 正确, 避免, 家长, 体谅, 学生会, 建议 |
| 学业警告 | 学业, 大学, 父母, 学习, 成绩, 学校, 一直, 警告, 时间, 课程, 发现, 专业, 退学, 学分, 家里, 挂科, 联系, 学期, 感觉, 比较, 以后, 表现 |
| 双困辅导 | 问题, 学习, 心理, 学生, 家庭, 困难, 经济, 生活, 情况, 帮助, 压力, 产生, 学业, 目标, 双困生, 教育, 学校, 引导, 同学, 建立, 适应, 社会, 导致, 出现, 自我, 能力 |
| 班委交流 | 工作, 班级, 老师, 干部, 鼓励, 交流, 班委, 能力, 时间, 成绩, 沟通, 优秀, 生活, 锻炼, 关系, 学习成绩, 努力, 精力, 负责, 培养, 学期, 其他同学, 学院, 监督, 寻找, 方式, 营造, 转变, 组织, 锻炼, 建议, 长期, 担任, 活动, 参加, 学习, 积极, 实践, 提高 |
将LDA主题建模生成的model_theta.dat文件(文档-主题-概率矩阵)依照预先设定的域值转化为FCA的输入矩阵。利用ConExp概念层次分析工具得到主题间的关联关系。部分结果如图6所示。概念层次分析结果整理后得到如表3所示的主题上下位关系识别结果。由表3可知, 心理压力的下位主题是比赛压力; 辅导模式的下位主题是面谈模式、监督模式; 心理迷茫的下位主题是情感倾诉、情绪焦虑; 情绪焦虑的下位主题是考前焦虑; 就业指导的下位主题是发展规划、毕业去向和求职意向; 毕业去向的下位主题是求职意向; 求职意向的下位主题是企事业单位备考; 人际沟通的下位主题是班委交流; 环境氛围的下位主题是宿舍关系、宿舍情谊、宿舍矛盾; 心理引导的下位主题是自我认知、人格魅力、理想与价值等。其中, “心理迷茫→情绪焦虑→考前焦虑”是典型的三级主题关联, “就业指导→毕业去向→求职意向→企事业单位备考”是典型的四级主题关联。
表3 主题上下位关系识别结果(部分)
| 上位主题 | 下位主题 |
|---|---|
| 心理压力 | 比赛压力 |
| 辅导模式 | 面谈模式, 监督模式 |
| 心理迷茫 | 情感倾诉, 情绪焦虑 |
| 情绪焦虑 | 考前焦虑 |
| 就业指导 | 发展规划, 毕业去向, 求职意向 |
| 毕业去向 | 求职意向 |
| 求职意向 | 企事业单位备考 |
| 人际沟通 | 班委交流 |
| 环境氛围 | 宿舍关系, 宿舍情谊, 宿舍矛盾 |
| 宿舍关系 | 宿舍情谊, 宿舍矛盾 |
| 心理引导 | 自我认知, 人格魅力, 理想与价值 |
根据专家访谈, 确定深度辅导最基本的五大访谈主题: 学习主题、家庭主题、就业主题、心理主题、生活主题, 并初始化知识库。之后根据OWL定义的基本语法和标签, 采用UltraEdit文本编辑工具对LDA主题抽取结果和FCA结果进行OWL编码, 并与初始化知识库中的概念进行关联, 构建深度辅导领域本体。领域本体主要包括4个类: 辅导主题、行为引导、词汇、词组。其中词汇构成词组, 词组描述辅导主题和行为引导, 各类主题之间存在上下位的关联关系, 如图7所示。
在此基础上, 利用斯坦福大学开发的Protégé软 件[20]读取OWL文件, 借助Racer推理机检验本体一致性, 并通过OntoGraf插件进行检索和可视化展示。
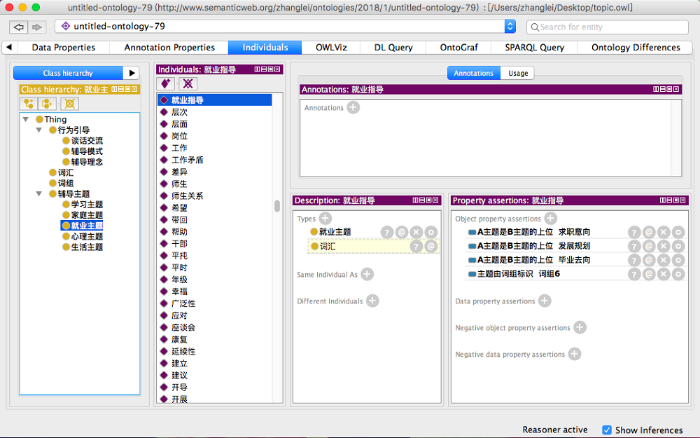
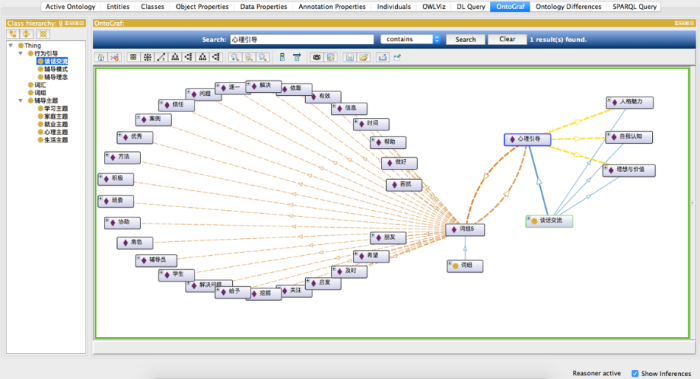
图8展示了深度辅导知识库的类、实例, 每个类都包括特定的实例。其中, 就业指导属于就业主题下的一个实例, 就业指导的下位主题包括发展规划、毕业去向、求职意向。就业指导由词组6标识。图9展示了OntoGraf插件对深度辅导知识库的可视化结果。在搜索框中输入: 心理引导, 即可得到与心理引导相关的领域知识。
由图9可知, 心理引导是心理主题的实例化对象, 自我认知、人格魅力、理想与价值是心理引导的三个下位主题。此外, 检索结果显示词组5用于标识心理引导主题, 并列出了该词组中所包含的全部词汇。辅导员在与学生的沟通谈话中可以通过词检索快速定位学生问题, 也可以通过主题检索查询辅导方法, 对学生的负面情绪、不良行为以及特殊问题进行及时的引导。
为了对高校学生深度辅导这一特定领域的知识进行建模, 本研究提出一个支持小规模知识获取和建模的框架。首先从网络上获取公开来源文档集合, 采用LDA主题建模方法对数据集进行知识提取, 知识的描述粒度分为主题、词组、词汇。其中, 主题用于描述文档, 词组用于标识主题, 词汇构成词组。但是高校深度辅导应用的难点在于如何精确定位学生的问题所在, 故在LDA建模结果的基础上需要进一步分析主题粒度。为此, 对LDA主题建模输出的“文档-主题”矩阵进行层次概念分析, 获取主题之间的上下位关系。上位主题的覆盖范围比下位主题更大, 而下位主题的精确程度要高于上位主题。简言之, 本研究在LDA建模基础上细化了主题知识的粒度, 改善了LDA主题建模结果难以表达主题之间上下位关系的难题。最后, 将以上建模结果统一编码为本体的形式存入知识库, 以便进行知识的检索。本研究的局限在于没有考虑新的深度辅导文档带来的知识库增量更新问题, 未来将会进一步深化研究。
庞贝贝: 数据筛选, 进行实验, 起草论文;
苟娟琼, 穆文歆: 提出研究思路, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 16113125@bjtu.edu.cn。
[1] 庞贝贝. depth tutoring.txt. 深度辅导训练数据集.
[2] 庞贝贝. segment.zip. 切词程序包.
[3] 庞贝贝. LDA.zip. 主题模型程序包.
[4] 庞贝贝. stopwords.txt. 笔者整理的停用词表.
[5] 庞贝贝. dict.txt. 笔者整理的深度辅导领域字典表.
[6] 庞贝贝. model_twords.dat. 基于LDA的主题抽取结果.
[7] 庞贝贝. model_theta.xls. 基于FCA的形式概念分析数据.
[8] 庞贝贝. topic_rdf.owl. 建模结果进行统一OWL编码结果.
| [1] |
基于潜在语义空间维度特性的多层文档聚类 [J].https://doi.org/10.3321/j.issn:1000-0054.2005.09.013 URL [本文引用: 2] 摘要
为实现文档在不同概念层次下的自动聚类,研究了潜在语义空间中维度的统计特性,发现对应大奇异值的维度描述了语义元素间的共性,对应小奇异值的维度描述了语义元素间的特性,呈现出潜在语义空间维度与概念粒度之间隐含的对应关系.基于这种认识,通过采用不同维度来实现文档在不同概念粒度下的聚类,并获得了很好的聚类准确率.另外,在基于潜在语义分析的文档聚类算法中,采用文档自检索矩阵的行向量,代替低维文档向量作为聚类对象,获得了更好的聚类准确率.
Multi-hierarchy Documents Clustering Based on LSA Space Dimensionality Character [J].https://doi.org/10.3321/j.issn:1000-0054.2005.09.013 URL [本文引用: 2] 摘要
为实现文档在不同概念层次下的自动聚类,研究了潜在语义空间中维度的统计特性,发现对应大奇异值的维度描述了语义元素间的共性,对应小奇异值的维度描述了语义元素间的特性,呈现出潜在语义空间维度与概念粒度之间隐含的对应关系.基于这种认识,通过采用不同维度来实现文档在不同概念粒度下的聚类,并获得了很好的聚类准确率.另外,在基于潜在语义分析的文档聚类算法中,采用文档自检索矩阵的行向量,代替低维文档向量作为聚类对象,获得了更好的聚类准确率.
|
| [2] |
Investigating Task Performance of Probabilistic Topic Models: An Empirical Study of PLSA and LDA [J].https://doi.org/10.1007/s10791-010-9141-9 URL [本文引用: 1] 摘要
AbstractProbabilistic topic models have recently attracted much attention because of their successful applications in many text mining tasks such as retrieval, summarization, categorization, and clustering. Although many existing studies have reported promising performance of these topic models, none of the work has systematically investigated the task performance of topic models; as a result, some critical questions that may affect the performance of all applications of topic models are mostly unanswered, particularly how to choose between competing models, how multiple local maxima affect task performance, and how to set parameters in topic models. In this paper, we address these questions by conducting a systematic investigation of two representative probabilistic topic models, probabilistic latent semantic analysis (PLSA) and Latent Dirichlet Allocation (LDA), using three representative text mining tasks, including document clustering, text categorization, and ad-hoc retrieval. The analysis of our experimental results provides deeper understanding of topic models and many useful insights about how to optimize the performance of topic models for these typical tasks. The task-based evaluation framework is generalizable to other topic models in the family of either PLSA or LDA.
|
| [3] |
Latent Dirichlet Allocation [J]. |
| [4] |
基于LDA挖掘计算机科学文献的研究主题 [J].
【目的】运用文本挖掘技术自动从海量科技文献中提取研究主题并探测其研究趋势。【方法】以《中文核心期刊要目总览(2014年版))—"TP自动化技术、计算机技术"栏目前10种期刊刊载的计算机科学类(Computer Science)文献为研究对象,借助LDA主题模型,考虑科技文献的发表时间信息,挖掘出典型话题,并根据主题强度分析主题的演化趋势。【结果】18个研究话题中有7个主题强度上升的主题和6个主题强度下降的主题。【局限】仅分析了国内计算机领域的前10种期刊,期刊范围不够大,也未考虑国外计算机领域的期刊文献。【结论】该方法能够深入挖掘计算机领域期刊文献的话题,帮助从事该领域研究的学者了解主题的演化趋势并寻找新兴研究主题。
Extracting Topics of Computer Science Literature with LDA Model [J].
【目的】运用文本挖掘技术自动从海量科技文献中提取研究主题并探测其研究趋势。【方法】以《中文核心期刊要目总览(2014年版))—"TP自动化技术、计算机技术"栏目前10种期刊刊载的计算机科学类(Computer Science)文献为研究对象,借助LDA主题模型,考虑科技文献的发表时间信息,挖掘出典型话题,并根据主题强度分析主题的演化趋势。【结果】18个研究话题中有7个主题强度上升的主题和6个主题强度下降的主题。【局限】仅分析了国内计算机领域的前10种期刊,期刊范围不够大,也未考虑国外计算机领域的期刊文献。【结论】该方法能够深入挖掘计算机领域期刊文献的话题,帮助从事该领域研究的学者了解主题的演化趋势并寻找新兴研究主题。
|
| [5] |
基于动态LDA主题模型的内容主题挖掘与演化 [J].https://doi.org/10.13266/j.issn.0252-3116.2014.02.023 URL [本文引用: 1] 摘要
指出文本内容主题的挖掘和演化研究对于文本建模和分类及推荐效果提升具有重要作用。从分析基于LDA主题模型的文本内容主题挖掘原理入手,针对当前网络环境下的文本内容特点,构建适用于动态文内容本主题挖掘的LDA模型,并通过改进的Gibbs抽样估计提高主题挖掘的准确性,进而从主题相似度和强度两个方面研究内容主题随时间的演化问题。实验表明,所提方法可行且有效,对后续有关文本语义建模和分类研究等具有重要的实践意义。
Mining and Evolution of Content Topics Based on Dynamic LDA [J].https://doi.org/10.13266/j.issn.0252-3116.2014.02.023 URL [本文引用: 1] 摘要
指出文本内容主题的挖掘和演化研究对于文本建模和分类及推荐效果提升具有重要作用。从分析基于LDA主题模型的文本内容主题挖掘原理入手,针对当前网络环境下的文本内容特点,构建适用于动态文内容本主题挖掘的LDA模型,并通过改进的Gibbs抽样估计提高主题挖掘的准确性,进而从主题相似度和强度两个方面研究内容主题随时间的演化问题。实验表明,所提方法可行且有效,对后续有关文本语义建模和分类研究等具有重要的实践意义。
|
| [6] |
基于流形学习的新闻主题关系构建和演化研究 [J].Analyzing Evolution of News Topics with Manifold Learning [J]. |
| [7] |
基于LDA和本体的科学前沿识别与分析方法研究 [J].Research on the Method of Detecting and Analyzing Scientific Fronts Based on LDA and Ontology [J]. |
| [8] |
A Semantic-grained Perspective of Latent Knowledge Modeling [J].https://doi.org/10.1016/j.inffus.2016.11.003 URL [本文引用: 2] 摘要
In the era of Web 2.0, the knowledge is the de-facto social currency in the global network environment. Knowledge is not an accumulation of data, but a relation-based representation of the information content, which needs to be distilled and arranged in a semantic infrastructure to guarantee interoperability and sharable understanding. In the light of this scenario, the paper introduces a semantically enhanced document retrieval system that describes each retrieved document with an ontological multi-grained network of the extracted conceptualization. The system is based on two well-known latent models: Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA): LSA provides a spatial distribution of the input documents, facilitating their retrieval, thanks to an ontological representation of their relationship network. LDA works instead at deeper level: it drives the ontological structuring of the knowledge inside the individual retrieved documents in terms of words, concepts and topics. The novelty of this approach is a multi-level granulation of the knowledge: from a document matching the query (coarse granularity), to the topics that join documents, until to the words describing a concept into a topic (fine granularity). The final result is a SKOS-based ontology, ad-hoc created for a document corpus; graphically supported for the navigation, it enables the exploration of the concepts at different granularity levels.
|
| [9] |
基于关联规则的文本主题深度挖掘应用研究 [J].
【目的】准确理解文本信息中潜在的知识关联,丰富文本知识挖掘的方法。【方法】将主题模型和关联规则相结合,运用LDA主题模型抽取文本中的主题集合,在实现文本降维的同时,实现文本在语义空间的表达;通过关联规则进一步挖掘文本中主题的语义关联。【结果】设置合理的支持度和置信度阈值,可以有效地挖掘文本中潜在知识的关联,实现对文本的深入"理解"。【局限】数据预处理过程中,用户自定义词典的设计会对实验结果产生一定的影响。【结论】提出一种非结构化文本信息潜在语义关联挖掘的新思路,改善了针对文本信息知识发现的效果。
Mining Document Topics Based on Association Rules [J].
【目的】准确理解文本信息中潜在的知识关联,丰富文本知识挖掘的方法。【方法】将主题模型和关联规则相结合,运用LDA主题模型抽取文本中的主题集合,在实现文本降维的同时,实现文本在语义空间的表达;通过关联规则进一步挖掘文本中主题的语义关联。【结果】设置合理的支持度和置信度阈值,可以有效地挖掘文本中潜在知识的关联,实现对文本的深入"理解"。【局限】数据预处理过程中,用户自定义词典的设计会对实验结果产生一定的影响。【结论】提出一种非结构化文本信息潜在语义关联挖掘的新思路,改善了针对文本信息知识发现的效果。
|
| [10] |
基于LDA的领域本体概念获取方法研究 [J/OL].Research on Domain Ontology Concept Acquisition Method Based on LDA and Application [J/OL]. |
| [11] |
基于形式概念分析的学科术语层次关系构建研究 [J].https://doi.org/10.3772/j.issn.1000-0135.2015.006.007 URL [本文引用: 3] 摘要
本体是领域知识的有效组织和描述,本体学习则是实现本体自动构建的方法体系和技术集合。本文以本体学习理论为指导,提出了一种以文档-术语空间为核心、形式概念分析(FCA)为手段的中文领域本体层次结构自动构建的有效方法,并以"白血病"领域为例,对面向学科资源的医学专业术语层次关联的抽取进行了详细论证,具体包括专业术语的抽取和筛选,术语文档关联的修正等数据清洗过程;文档术语矩阵的建立,领域概念格的自动生成,以及概念格中术语属性的层次关联建立等FCA过程;术语层次关联的自动OWL描述和存储,和领域本体的概念检索和可视化展示过程等。
Study on Construction of Hierarchy Relationship of Subject Terms Based on Formal Concept Analysis [J].https://doi.org/10.3772/j.issn.1000-0135.2015.006.007 URL [本文引用: 3] 摘要
本体是领域知识的有效组织和描述,本体学习则是实现本体自动构建的方法体系和技术集合。本文以本体学习理论为指导,提出了一种以文档-术语空间为核心、形式概念分析(FCA)为手段的中文领域本体层次结构自动构建的有效方法,并以"白血病"领域为例,对面向学科资源的医学专业术语层次关联的抽取进行了详细论证,具体包括专业术语的抽取和筛选,术语文档关联的修正等数据清洗过程;文档术语矩阵的建立,领域概念格的自动生成,以及概念格中术语属性的层次关联建立等FCA过程;术语层次关联的自动OWL描述和存储,和领域本体的概念检索和可视化展示过程等。
|
| [12] |
Learning Ontologies to Improve Text Clustering and Classification [C]// |
| [13] |
聚类分析研究中的若干问题 [J].
<p>聚类分析是重要的数据挖掘方法, 目的是寻找数据集中所包含的簇结构. 以往研究工作中聚类分析的一些<br />基本问题始终是人们关注的重点, 为此在简要回顾具有代表性的研究成果的基础上, 总结了该研究所面临的若干基<br />本问题及解决方法, 以期能够对相关研究提供有益的参考.</p>
Survey on Challenges in Clustering Analysis Research [J].
<p>聚类分析是重要的数据挖掘方法, 目的是寻找数据集中所包含的簇结构. 以往研究工作中聚类分析的一些<br />基本问题始终是人们关注的重点, 为此在简要回顾具有代表性的研究成果的基础上, 总结了该研究所面临的若干基<br />本问题及解决方法, 以期能够对相关研究提供有益的参考.</p>
|
| [14] |
A FCA-Based Ontology Construction for the Design of Class Hierarchy [C] // |
| [15] |
Deriving a Large Scale Taxonomy from Wikipedia [C]//
|
| [16] |
一种结合词项语义信息和TF-IDF方法的文本相似度量方法 [J].https://doi.org/10.3724/SP.J.1016.2011.00856 URL [本文引用: 2] 摘要
传统的文本相似度量方法大多采用TF-IDF方法把文本建模为词频向量,利用余弦相似度量等方法计算文本之间的相似度.这些方法忽略了文本中词项的语义信息.改进的基于语义的文本相似度量方法在传统词频向量中扩充了语义相似的词项,进一步增加了文本表示向量的维度,但不能很好地反映两篇文本之间的相似程度.文中在TF-IDF模型基础上分析文本中重要词汇的语义信息,提出了一种新的文本相似度量方法.该方法首先应用自然语言处理技术对文本进行预处理,然后利用TF-IDF方法寻找文本中具有较高TF-IDF值的重要词项.借助外部词典分析词项之间的语义相似度,结合该文提出的词项相似度加权树以及文本语义相似度定义计算两篇文本之间的相似度.最后利用文本相似度在基准文本数据集合上进行聚类实验.实验结果表明文中提出的方法在基于F-度量值标准上优于TF-IDF以及另一种基于词项语义相似性的方法.
A Text Similarity Measurement Combining Word Semantic Information with TF-IDF Method [J].https://doi.org/10.3724/SP.J.1016.2011.00856 URL [本文引用: 2] 摘要
传统的文本相似度量方法大多采用TF-IDF方法把文本建模为词频向量,利用余弦相似度量等方法计算文本之间的相似度.这些方法忽略了文本中词项的语义信息.改进的基于语义的文本相似度量方法在传统词频向量中扩充了语义相似的词项,进一步增加了文本表示向量的维度,但不能很好地反映两篇文本之间的相似程度.文中在TF-IDF模型基础上分析文本中重要词汇的语义信息,提出了一种新的文本相似度量方法.该方法首先应用自然语言处理技术对文本进行预处理,然后利用TF-IDF方法寻找文本中具有较高TF-IDF值的重要词项.借助外部词典分析词项之间的语义相似度,结合该文提出的词项相似度加权树以及文本语义相似度定义计算两篇文本之间的相似度.最后利用文本相似度在基准文本数据集合上进行聚类实验.实验结果表明文中提出的方法在基于F-度量值标准上优于TF-IDF以及另一种基于词项语义相似性的方法.
|
| [17] |
科技情报分析中LDA主题模型最优主题数确定方法研究 [J].Identifying Optimal Topic Numbers from Sci-Tech Information with LDA Model [J]. |
| [18] |
概念格构建工具ConExp与LatticeMiner的比较研究 [J].Comparative Study on ConExp and LatticeMiner [J]. |
| [19] |
Web Ontology Language: OWL[A]// Handbook on Ontologies [M]. |
| [20] |
Semi-Automatic Terminology Ontology Learning Based on Topic Modeling [J].https://doi.org/10.1016/j.engappai.2017.05.006 URL [本文引用: 1] 摘要
Abstract: Ontologies provide features like a common vocabulary, reusability, machine-readable content, and also allows for semantic search, facilitate agent interaction and ordering & structuring of knowledge for the Semantic Web (Web 3.0) application. However, the challenge in ontology engineering is automatic learning, i.e., the there is still a lack of fully automatic approach from a text corpus or dataset of various topics to form ontology using machine learning techniques. In this paper, two topic modeling algorithms are explored, namely LSI & SVD and Mr.LDA for learning topic ontology. The objective is to determine the statistical relationship between document and terms to build a topic ontology and ontology graph with minimum human intervention. Experimental analysis on building a topic ontology and semantic retrieving corresponding topic ontology for the user's query demonstrating the effectiveness of the proposed approach.
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |
/
| 〈 |
|
〉 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}