




1 引 言
学术论文作为科研成果的具体表现形式之一, 具有很高的研究价值。早期针对论文的被引用情况进行研究, 并用于衡量论文、研究者以及期刊、机构的学术价值[1,2]。而简单的定量研究对科研人员的研究起到的辅助作用越来越小, 他们将目光转向论文内容[3,4,5], 一方面, 学术论文全文资源比以往更加容易获取, 另一方面, 自然语言处理和机器学习方法与技术的不断发展, 使得针对学术论文全文内容的分析、挖掘与深度利用逐渐成为可能。近年来, 学术论文中一种特殊的句子——创新研究评价句, 引起学术界的关注。创新研究评价句(简称为评价句)是指学术论文中学者对前人科研成果进行评价的句子, 如“价值链由Michael E. Porter教授于1985年在其著作《竞争优势》一书中首次提出”, 该句指出“价值链”这个概念最早由Michael E. Porter提出。评价句能够对众多科研成果进行浓缩, 取其精华的部分, 帮助学者快速了解领域发展情况, 并且评价句代表学术界对这些成果的认可度。因此, 评价句的发现为目前解决学术评价问题提供了一个重要的思路[6]。
当前评价句的主要研究者是冯长根教授, 他认为评论句提供了一种“自然而然”的科研成果评价方法, 并根据评价句提出了两个学术评价指标[7]。冯教授通过向大众募集的方式获取评论句, 虽然保证了准确性但需要耗费大量时间和人力, 同时依赖于大众的配合, 并且受限于所收集的数据, 可能造成评价句获取的主观性与不全面问题。
学术论文的评价本质是对其学术价值的评价, 具体体现为创新性的测度[8]。为更加全面地获取创新研究评价句, 本文尝试依据学术论文全文自动抽取的方法解决该问题。具体而言, 以图书情报档案学科为例, 采用学术期刊论文全文作为实验数据, 通过能表征创新研究评价的标志词自动地从学术论文全文中抽取评价句, 并分别从评价句标志词、类型和所在位置等角度分析评价句的分布情况。基于学术论文全文评价句的抽取与分析, 构建评价句知识库, 为学者调研相关研究、撰写综述提供帮助, 为评价科研成果提供新的思路。
2 相关研究
2.1 信息抽取方法概述
信息抽取的基本方法可以分为基于规则的方法和基于统计的方法。
基于规则的方法存在编制规则过程较复杂、对规则构建者的要求高以及难以移植到其他领域等问题。基于统计的方法可以在一定程度上克服这些问题。基于统计的方法主要通过统计分析或机器学习方法, 在语料库上自动抽取相关信息。通常, 基于统计的方法需要一定规模的标注语料。Heffernan等通过Word2Vec训练深度学习分布模型计算语义相似度, 设置目标词为问题及问题的相近词, 并结合句法分析识别科学文本中的问题陈述[11]。Small等直接提取含有“发现”一词的引用句, 通过人工筛选得到匹配发现词的成功率为46%, 通过岭回归分类器训练引用句得到准确率为94%[12]。基于统计的方法建立在标注语料的基础上, 语料的获取及加工需要耗费一定的人力与物力。
2.2 学术实体抽取概述
表1 信息抽取对象介绍[13]
| 抽取对象 | 含义 |
|---|---|
| 命名实体识别 | 从众多信息中识别所需要的命名实体, 是信息抽取中最基本的任务 |
| 多语言实体识别 | 是在命名实体识别基础上的延伸, 可扩展至多种语言 |
| 模板元素抽取 | 将实体与其属性一同抽取出来, 形成实体对象 |
| 参照信息抽取 | 实现将不同地方的统一实体进行连接 |
| 模板关系抽取 | 进一步完善模板元素抽取, 补充各元素之间的关系 |
| 情节模板信息抽取 | 将时间、组织、人物或其他实体连接起来, 形成完整的事件 |
徐文海等基于向量空间模型和TFIDF方法, 从中文科技文献中自动抽取关键词[14]。Castro-Sánchez等通过分析以动词为核心的语句模式, 抽取论文中的学术定义[15]。温有奎等构建学术成果创新点的本体模型, 根据各个模板之间的语义关系动态挖掘学术创新点[16]。Helen等提出一种以章节类型为特征的提取实验技术论文中反问句的方法, 有助于更好地总结全文和实现自动文摘[17]。杨波等通过抽取科技论文中生物信息学家应用科学软件的情况进一步探讨软件与论文的关系[18]。索传军等提出使用认知计算进行学术论文评价的方法, 通过构建知识元数据模型抽取创新性和结论性的句子, 补充已有评价方法和知识体系等, 利用机器学习训练认知系统[8]。
创新研究评价句中包含大量的学术实体, 目前还缺少关于创新评价句自动抽取的研究。因此, 本文以图书情报档案学科为例, 尝试从学术论文全文中自动抽取评价句。
3 研究方法
基于全文的评价句抽取流程如图1所示。
图1
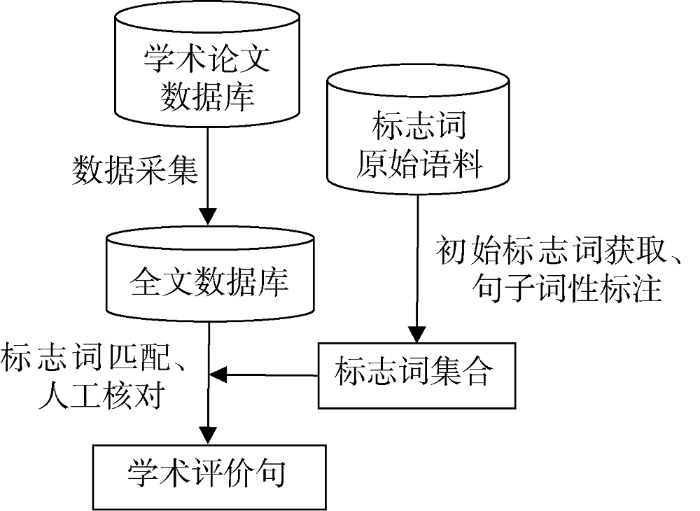
本文依据“开创”、“始于”、“首创”等能表征创新性评价的词语(简称为标志词)抽取创新研究评价句。具体思路为: 观察标志词原始语料, 获取初始的评价句标志词; 对标志词原始语料进行词性标注, 抽取与标志词搭配的动词, 得到最终的标志词集合; 依据标志词集合从学术论文全文数据库中自动抽取评价句。
3.1 学术论文全文数据概述
CNKI涵盖目前绝大部分中文期刊, 并且以HTML全文形式展示的论文比率逐渐增加。本文选择CNKI中图书情报档案领域的CSSCI来源期刊论文作为实验数据, 采集有HTML全文的期刊论文全文。数据采集时间为2017年10月, 当时并未公布新版CSSCI来源数据期刊, 因此使用了2014年-2016年版。最终采集的论文在各期刊分布情况如表2所示。
表2 含HTML全文的学术论文期刊分布情况
| 期刊名称 | 总数(篇) |
|---|---|
| 大学图书馆学报 | 259 |
| 档案学通讯 | 360 |
| 档案学研究 | 461 |
| 国家图书馆学刊 | 18 |
| 情报科学 | 948 |
| 情报理论与实践 | 1 182 |
| 情报杂志 | 1 244 |
| 情报资料工作 | 105 |
| 图书馆 | 973 |
| 图书馆工作与研究 | 1 262 |
| 图书馆建设 | 843 |
| 图书馆论坛 | 948 |
| 图书馆学研究 | 1 626 |
| 图书馆杂志 | 805 |
| 图书情报工作 | 2 266 |
| 图书情报知识 | 345 |
| 图书与情报 | 527 |
| 现代图书情报技术 | 459 |
| 中国图书馆学报 | 298 |
| 合计 | 14 929 |
(注: 由于采集数据时《情报学报》并未被CNKI收录, 所以缺失该期刊数据。)
由于文献中掺杂着一些类似于“会议介绍”、“期刊投稿要求”等与研究无关的短文, 对这些短文一一排除。通过筛选整理后剩余13 600篇学术论文。
3.2 标志词获取
从包含创新评价研究标志词的原始语料(简称标志词原始语料)中获取标志词。该语料为北京理工大学冯长根教授在其网站①(①http://www.wuma.com.cn/.)发布的学术评论句语料。在2018年1月采集该语料, 其中共包括1 026条记录, 每条记录包含机构、评价句、评价句出处和引用文献等4个部分, 样例如表3所示。
表3 学术评价句样例
| 机构 | 评价句 | 出处 | 引用文献 |
|---|---|---|---|
| 北京大学 | QuEChERS方法是一种快速便捷的前处理 方法, 由Anastassiades等在2003年首次 提出该方法由提取和净化两个主要步骤组 成, 主要用于果蔬中农药的检测。 | 木合他拜尔, 严华, 徐姗, 冯楠, 郝杰, 朱尘琪, 郭爽, 张朝晖, 韩 南银. 色谱, 2015, 33(11): 1199-1204. | Anastassiades M, Lehotay S J, Stajinbaher D, et al. J. AOAC Int, 2003, 86(2): 412. |
| 北京工业 大学 | 东南大学的郝英立等人最先在2005年指 出在结霜临界状态时冰粒的大小及其在冷 表面上的分布具有分形特征。 | 刘耀民, 刘中良, 黄玲艳, 孙 俊芳. 中国科学: 技术科学, 2009, 3911: 1864-1869. | Hao Y L, Jose I, Yong X T. Experimental study of initial state of frost formation on flat surface. J Southeast Uni, 2005, 35(1): 149-153 |
| 华东理工 大学 | 另外, Shi课题组于2009年第一次成功实 现了NiCl2(PCy3)2催化下芳基氰化物与反 应性较差的芳基硼酸酯或烯基硼酸酯的 Suzuki-Miyaura偶联反应。 | 寇学振, 范佳骏, 童晓峰, 沈 增明. 有机化学, 2013, 33(7): 1407-1422. | Yu D G, Yu M, Guan B T, Li B J, Zheng Y, Wu Z H, Shi Z. Carbon-carbon formation via Ni-catalyzed Suzuki-Miyaura coupling through C-CN bond cleavage of aryl nitrile[J]. J. Org. Lett. 2009, 11(48): 3374-3377. |
标志词原始语料中包含被评文献的作者、被评文献的出现年份、创新性研究的标志性词汇等信息。笔者逐一浏览标志词原始语料的记录, 获得标志词, 并根据标志词的出现形式对其进行分类: 第一类标志词(记为A)为“首创”、“开创”等单个词语; 第二类标志词为词语的组合形式(记为B), 如“首次······提出”、“最早······提出”(将组合中首创性提示词汇记为B1, 与其搭配的动词记为B2)。
由于标志词原始语料不可能收录所有的标志词, 因此, 进一步扩充标志词集合。对从标志词原始语料中获取的标志词进行同义词扩展, 最终确定标志词集合。
3.3 评价句抽取
根据标志词集合, 从13 600篇图书情报档案领域的学术论文中抽取评价句。利用ICTCLAS分词系统① (①http://ictclas.nlpir.org/.)对学术论文全文进行中文分词, 将标志词集 合中标志词与分词结果进行匹配, 对于匹配到A 类或B类标志词的句子, 将其保存到评价句数据 库中。
通过标志词匹配得到的句子不一定是评价句, 因此还需要进行人工审核过滤。本文设定的过滤 标准为: 若句子中没有提及科研人员或科研成果, 或者没有对其具有首创性的评价, 则判定为非评价句。
4 结果分析
4.1 评价句抽取结果分析
表4 评价句的标志词(频次排序前10位)
| 标志词 | 频次(比率) | 例句 |
|---|---|---|
| 首次······提出 | 588(17.4%) | “被引速度作为有效的文献计量学工具由A. Schubert等人于1986年首次提出” |
| 最早······提出 | 485(14.4%) | “协同概念最早是由德国物理学家赫尔曼·哈肯提出并形成系统性理论” |
| 开创 | 163(4.8%) | “香农(Shannon)从通信角度引入熵的概念开创了信息度量先河掀起了信息度量研究序幕” |
| 早在······提出 | 125(3.7%) | “T. Berners-Lee早在2006年便提出了关联数据的概念” |
| 创始人 | 117(3.5%) | “斯科特(Peter J. Scott)因此成为公认的文件系列系统创始人和文件连续体理论的先驱” |
| 首先······提出 | 113(3.3%) | “信息素养首先于1974年由美国信息产业协会主席PaulZurkow Ski提出” |
| 始于 | 100(3.0%) | “国外的政府信息资源规划研究始于20世纪80年代早期的马钱德、霍顿的信息资源管理阶段性理论” |
| 源于 | 87(2.6%) | “社会分类概念源于Barth” |
| 追溯到 | 87(2.6%) | “消费者决策过程研究最早可追溯到1967年P.Kotler提出的消费者购买决策黑箱理论” |
| 最早······研究 | 61(1.8%) | “最早对作者文献耦合方法进行实证研究的是Zhao Dangzhi” |
表5 非评价句的标志词(频次排序前10位)
| 标志词 | 频次(比率) | 例句 |
|---|---|---|
| 源于 | 3 965(24.1%) | “碎片化信息大多源于微媒体” |
| 第一个 | 1 210(7.4%) | “选择关键词构建共词矩阵是共词分析中的第一个关键步骤” |
| 始于 | 1 081(6.6%) | “佛山市智能图书馆建设始于2011年” |
| 开创 | 816(5.0%) | “移动电子商务开创了产品与服务新的模式” |
| 追溯到 | 297(1.8%) | “修谱者往往愿意将自己的祖先追溯到某个名人” |
| 最早······出现 | 225(1.4%) | “Twitter作为最早出现的微博, 发展相对成熟, 是学术界微博研究者的主要研究对象” |
| 首创 | 214(1.3%) | “统计表明,美国的技术创新有78%为其首创” |
| 首先······分析 | 213(1.3%) | “本研究首先对三种活动类型的特征进行调查分析, 包括普及性和价值性两个方面” |
| 创始人 | 202(1.2%) | “Twitter创始人之一埃文·威廉姆斯曾表示, 微博的真正价值不是粉丝数而是转发量” |
| 首次······出现 | 112(0.7%) | “重要的内容首次出现的位置通常在标题中” |
4.2 评价句类型分析
表6 评价句类型分类说明
| 评价句类型 | 分类依据 | 例句 |
|---|---|---|
| 概念理论类 | 由科研人员命名或定义某个概念或理论 | “价值链由Michael E.Porter教授于1985年在其著作《竞争优势》一书中首次提出” |
| 观点发现类 | 学者通过理论或实践研究提出的想法或发现, 且普遍具有一定长度 | “引文分析法也存在缺陷, 早在1987年, King J就曾撰文指出同被引法的不足” |
| 模型方法类 | 在研究过程中使用的方法 | “TAM模型最早是由Davis在理性行为理论(Theory of Reasoned Action, TRA)的基础上提出” |
| 派别领域类 | 开创了某个学派或是最先在某个领域进行研究 | “《文献计量学》一书奠定了邱均平教授作为国内文献计量学奠基人之一的学术地位” |
| 系统软件类 | 研究成果为开发的系统或者软件 | “汉构是国际上最早基于HPSG理论、面向深层语言处理的中型汉语语法系统之一” |
| 实践应用类 | 需要通过动手实践得到 | “曼彻斯特大学的教授们首次提取出石墨烯···” |
对3 376条评价句的类型分类结果进行统计, 结果如图3所示。图书情报档案领域论文对创新研究的评价, 以概念理论类的评价句为主, 模型方法类与观点发现类也占有不小的比例, 实践应用类与系统软件类较少。
图3

将评价句类型按照期刊分组, 结果如图4所示。其中, 《国家图书馆学刊》论文数量较少, 各类型占比情况与其他期刊相差较大。《情报资料工作》的论文评价句主要以概念理论类为主;《现代图书情报 技术》的论文对创新研究评价时, 以模型方法类为主;《中国图书馆学报》的论文中评价句类型较为 均衡。
图4

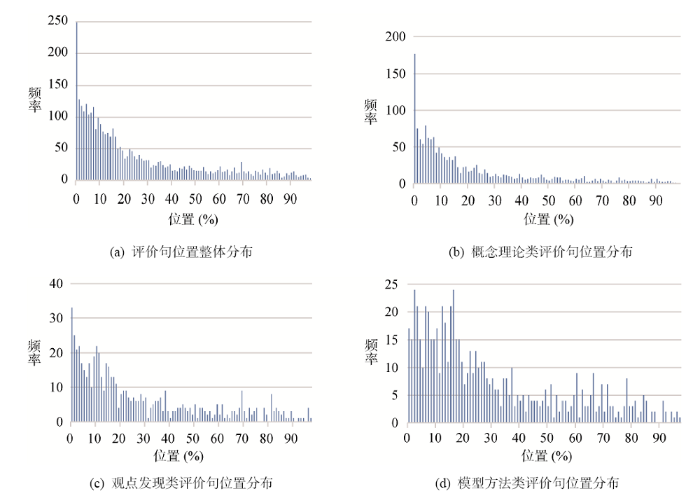
4.3 评价句位置分析
在学术论文中, 不同位置的引用往往具有不同的动机和功能[4]。依据评价句在学术论文中相对位置, 进行评价句的位置分布分析。将论文正文的字数记作length, 评价句位置计算如公式(1)所示。
其中, Locationi指评价句i在全文的位置, lengthj是文章j的全文总字数, lengthbeforei∈j表示文章j中评价句i前的总字数。
图5
5 结 语
本文提出基于学术论文全文的创新研究评价句抽取方法。从标志词原始语料得到初始标志词, 对标志词原始语料进行词性标注, 抽取与标志词搭配的动词, 得到最终的标志词集合。依据标志词集合从学术论文全文中自动抽取评价句, 并对结果进行人工核对, 最终得到评价句, 并从评价句类型与位置两个角度对抽取结果进行分析。研究发现, 图书情报档案领域的学术论文中, 评价句主要以评价概念理论相关的研究为主, 且主要出现在论文正文靠前的位置。
本文研究仍然存在一些不足之处。在数据方面, 仅采集HTML格式的论文全文, 数据范围有待进一步扩大; 仅考察图书情报档案领域的评价句抽取结果, 其他领域的评价句抽取结果有待考察; 基于标志词抽取评价句的方法, 正确率还需要进一步提高, 未来将尝试使用机器学习模型改进评价抽取方法。
作者贡献声明
章成志: 数据采集, 提出论文研究思路, 起草与修改论文;
李铮: 实施实验过程, 进行数据分析, 起草论文。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: 849161192@qq.com。
[1] 章成志, 李铮. data.txt. 学术论文全文数据.
[2] 章成志, 李铮. result.xls. 用于分析的评价句表(含人工标注与计算结果).
[3] 章成志, 李铮. 评价句标志词表.txt. 用于初步识别评价句.
参考文献
Citation Analysis as a Tool in Journal Evaluation
[J].
An Index to Quantify an Individual’s Scientific Research Output
[J].
Content-based Citation Analysis: The Next Generation of Citation Analysis
[J].
全文引文分析方法与应用
[D].
Full-Text Citation Analysis and Applications
[D].
基于引文内容分析的高被引论文主题识别研究
[J].
基于被引次数的引文分析无法直接揭示论文的研究内容,利用关键词或从标题、摘要和全文中抽取的主题词很难客观反映论文的被引原因。本文以碳纳米管纤维研究领域的高被引论文为研究对象进行引文内容抽取和主题识别,经人工判读验证:基于引文内容分析的高被引论文识别的核心主题能够较好地揭示高被引论文的被引原因(引用动机),而且与论文的研究内容相符合;与基于全文、基于标题和摘要的主题识别相比,在引文内容分析基础上识别的主题具有更好的主题代表性,能够有效揭示被引文献的研究内容,是对原文相关信息的重要补充。本文的实验表明基于引文内容分析的高被引论文主题识别是可行而且有效的。图4。表4。参考文献31。
Topic Identification of Highly Cited Papers Based on Citation Content Analysis
[J].基于被引次数的引文分析无法直接揭示论文的研究内容,利用关键词或从标题、摘要和全文中抽取的主题词很难客观反映论文的被引原因。本文以碳纳米管纤维研究领域的高被引论文为研究对象进行引文内容抽取和主题识别,经人工判读验证:基于引文内容分析的高被引论文识别的核心主题能够较好地揭示高被引论文的被引原因(引用动机),而且与论文的研究内容相符合;与基于全文、基于标题和摘要的主题识别相比,在引文内容分析基础上识别的主题具有更好的主题代表性,能够有效揭示被引文献的研究内容,是对原文相关信息的重要补充。本文的实验表明基于引文内容分析的高被引论文主题识别是可行而且有效的。图4。表4。参考文献31。
一种自然而然的科技成果评价方法值得国家推广
[J].
A Natural Evaluation Method of Scientific and Technological Achievements is Worthy of National Promotion
[J].
用学术影响力评价学术论文——兼论关于学术传承效应和长期引用的两个新指标
[J].
Evaluation of Academic Papers with Academic Influence——Proposing Two New Indicators of Academic Inheritance Effect and Long-term Citation
[J].
认知计算——单篇学术论文评价的新视角
[J].
Cognitive Computing: A New Perspective for Evaluating the Individual Academic Paper
[J].
Method Mention Extraction from Scientific Research Papers
[C]//
领域内中文科技文献中新发现语言描述特征分析
[J].
Linguistic Features of New Findings in Chinese Scientific Papers
[J].
Identifying Problem Statements in Scientific Text
[C]//
Discovering Discoveries: Identifying Biomedical Discoveries Using Citation Contexts
[J].
信息抽取方法综述
[J].
A Summary of Information Sampling Method
[J].
一种基于TFIDF方法的中文关键词抽取算法
[J].
A Chinese Keyword Extraction Algorithm Based on TFIDF Method
[J].
Analysis of Definitions of Verbs in an Explanatory Dictionary for Automatic Extraction of Actants Based on Detection of Patterns
[C]//
碎片化科研创新点动态挖掘研究
[J].
Dynamic Mining of Fragmented Scientific Research Innovation Points
[J].
Extraction and Classification of Rhetorical Sentences of Experimental Technical Paper Based on Section Class
[C]//
生物信息学文献中的科学软件利用行为研究
[J].
Research on Using Behavior of Scientific Software in Bioinformatics Literature
[J].
Chance-Corrected Measures for 2 × 2 Tables That Coincide with Weighted Kappa
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}