1 引 言
Web2.0时代, 以社交网站、微博、博客、论坛为代表的社交媒体成为互联网世界中最大的信息产生与交换渠道[1 ] , 同时也为谣言的生成与传播构筑了温床。社会学家将谣言定义为: 没有相应事实基础, 却被捏造出来并通过一定手段推动传播的言论[2 ] 。相较于社会谣言, 网络中的谣言常常以吸引流量或制造恐慌为目的, 因而往往带有较大的煽动性与恶意性, 成为破坏网络空间秩序与环境的毒瘤, 对社会生活造成极大的负面影响[3 ] 。因此对网络谣言进行有效 鉴别, 具有较为紧迫的社会意义、经济意义与现实 意义。
目前国内外针对网络谣言的检测主要依赖于一些公司或公益性组织建立的辟谣平台, 其中国际包括Snopes.com、FactCheck.org、UrbanLegends.about. com、Emergent等网站, 国内主要有中国互联网联合辟谣平台(http://www.piyao.org.cn/,中央网信办)、微博辟谣(https://weibo.com/weibopiyao, 新浪微博)等渠道。这些渠道通过调查溯源等手工方式对网络谣言进行检测, 在取得较高准确度的同时也需要很大的时间开销, 尤其是当面对海量的网络消息时, 人工鉴谣就显得力不从心。因此, 网络谣言的自动检测也是谣言分析的热点问题之一。Twitter是全球范围内具有深远影响力与代表性的社交媒体, 以Twitter为对象开展网络谣言的自动检测研究对于网络谣言的治理具有广泛借鉴性。
2 文献综述
网络谣言的自动检测最早开始于Twitter, 众多学者从识别谣言的要素入手, 构造相关特征实现对网络谣言的检测。Castillo等[4 ] 归纳了来自4个方面的要素以识别谣言, 分别是文本特征、用户特征、传播特征和话题特征, 在此基础上总结出15项关键特征并利用决策树算法J48实现对谣言的检测。Ma等[5 ] 考虑谣言演变的时间特征, 使用动态时间序列模型对谣言进行检测。Zhao等[6 ] 通过构建线索词等特征实现了谣言的早期预测。祖坤琳等[7 ] 则关注微博的评论消息, 将微博评论的情感倾向性加入模型, 实现了谣言的有效检测。这些方法虽然取得一定效果, 但是大多依赖于手工构造特征, 也属于谣言识别要素的浅层提取, 因而无法进一步提升准确率。
近年, 很多学者尝试使用深度学习模型自动构造深层特征实现谣言检测。Ma等[8 ] 尝试使用RNN及其衍生模型对谣言事件进行检测, 抽取相关的Tweet组成谣言事件, 然后通过词嵌入提取谣言事件的特征, 最后借助RNN网络实现对谣言事件的检测, 实验证明了RNN在谣言检测领域的有效性。Chen等[9 ] 在此基础上, 加入注意力机制, 实现对Tweet特征的深层抽取, 取得了较好效果。深度学习模型的构建依赖于大量标注数据, 而网络谣言的数据获取一直是谣言检测领域的一大难题, 因此数据标注问题成为基于深度学习模型进行谣言检测的最大瓶颈。一些学者尝试避开数据的标注, 借助无监督学习的思想进行网络谣言检测。Zhang等[10 ] 提出一种无监督的谣言检测方式, 借助于多层自编码器获取谣言的文本编码规则, 实现对谣言的有效检测。Chen等[11 ] 在自编码器的前端加入多层RNN网络, 进一步提升了模型的效果。无监督学习的方法虽然避开了数据标注的问题, 但是模型的不稳定性会带来较大局限。
无论使用传统模型还是深度学习模型, 通过对文本信息、用户信息、传播信息的加工可有效识别网络谣言[12 ] , 借助深度网络自动构建特征进一步提升了谣言检测的准确性与稳定性。然而网络谣言涉及众多领域, 比如经济类谣言、社会类谣言、政治类谣言等。不同领域具有不同的特征, 但现有的谣言检测研究缺乏对领域的关注, 常用统一的检测模型应对各个领域的谣言。这样的方法忽视了领域差异对谣言检测的影响, 导致识别准确率低。针对网络谣言的分领域问题, 也可以利用已有方法进行识别, 但有些领域数据量较少会导致识别结果不佳。本文将这一问题视为领域数据标注不足的问题, 利用迁移学习的思想来探寻其中的解决方案。
3 问题分析
3.1 网络谣言的领域差异
Twitter仿照传统媒体的分类标准, 根据来源与内容将平台内的消息划分为不同领域, 如社会类、军事类、娱乐类等① (①https://twitter.com/search?q=#ThisHappened.), 从而使具有不同偏好的用户方便地获取自己喜欢的信息。从新闻学角度出发, 不同领域的信息具有不同的描述对象、描述技巧和描述词汇, 这一点也反映在社交媒体的文本中。
网络谣言的产生往往从真实事件出发, 对事实进行篡改、夸张与嫁接, 因而网络谣言也会涉及不同的领域, 具有不同的语言特征。如娱乐类的谣言往往充斥着“私生子”、“隐婚”、“潜规则”等字眼, 而生活类的谣言则与健康、日常饮食、养生等话题相关。从计算语义学的角度看, 这些领域的差异可以被理解为不同领域的信息具有不同数据分布, 因此不同领域的谣言检测方法也不尽相同。
传统的网络谣言检测方法使用机器学习算法建模时, 常常将具有不同数据分布的各个领域信息作为一个整体去构建分类器, 这样建立的分类器往往缺乏领域针对性, 导致某些领域的网络谣言不能被很好地鉴别。因而需要针对各个领域分别构建分类器, 从而捕捉特定领域的关键特征, 实现精细化检测, 也可以有效避免来自领域高频词的误导。比如食品类谣言中经常出现的“致癌”、“癌症”、“细菌”等词, 在医学领域则作为正常词出现。
事实上网络谣言在各领域的分布是极不平均的。以国外辟谣网站Snopes② (②https://www.snopes.com/archive/.)为例, 2018年第三季度披露的网络谣言共676条, 其中政治类占比最大, 约28%; 新闻类占22%, 排第二; 娱乐类和商业类分别占13%和11%, 排第三和第四; 其他多达18个细分类别均不到10%。这种不平衡性使谣言识别可能在某些领域准确性较高, 而另外的领域则效果不佳, 这也为分领域的谣言检测提出了挑战。
因此, 本文提出一种跨领域的谣言检测模型, 将利用具有丰富标注数据的领域谣言构建的分类模型迁移到含有少量数据或缺少标注数据的领域中, 解决领域间数据或标注不平衡的问题。
3.2 跨领域谣言检测模型
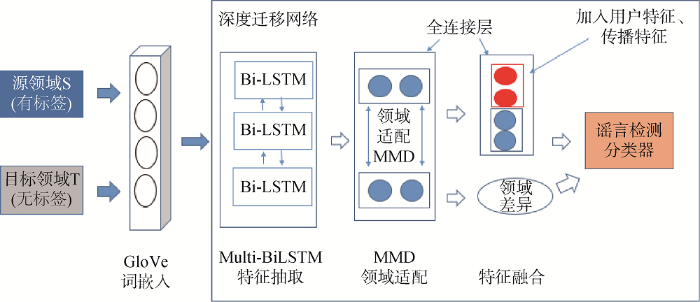
本文的建模场景针对谣言在某些领域(目标领域T)存在数据量少且缺少标注的问题, 借助标注数据丰富的领域(源领域S)数据通过迁移学习, 提高目标领域的检测效果。借鉴文献[4 ], 结合谣言的文本特征、用户特征、传播特征构建深度迁移谣言检测模型, 如图1 所示。因为用户特征与传播特征不受领域影响, 因此先对文本特征进行跨领域迁移, 在网络训练时再引入用户特征与传播特征。
图1
整个流程可分为词嵌入处理、特征抽取、领域适配、特征融合、预测分类等步骤。具体而言, 模型通过预先训练GloVe词向量实现对输入文本的向量化; 将两个领域的文本向量经过同一个多层双向LSTM网络[13 ] , 完成对文本特征深度提取(特征抽取); 然后将经过特征抽取过的两个领域数据输入全连接层, 这时会计算两个领域数据分布的差异; 最后将输出向量与对应的用户特征向量及传播特征向量进行拼接, 并送入Softmax层进行预测训练。
考虑极端情况下的领域迁移: 即源领域存在标注数据集SE , 目标领域存在无标注数据集TE , yi 表示类别变量, 定义$SE=\{(S{{E}_{1}},{{y}_{1}})\ldots (S{{E}_{i}},{{y}_{i}})\ldots (S{{E}_{n}},{{y}_{n}})\}$, $TE=\{T{{E}_{1}}\ldots T{{E}_{i}}\ldots T{{E}_{m}}\}$。
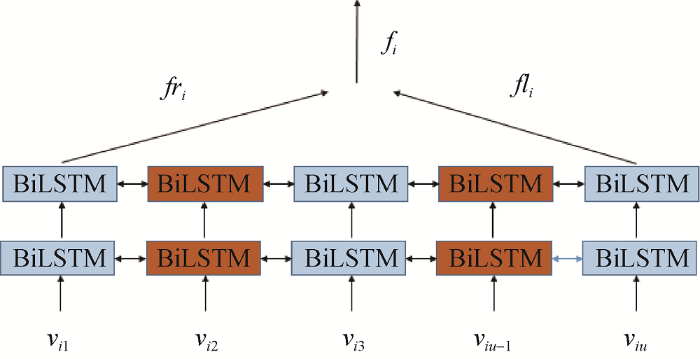
特征抽取通过深度网络实现对谣言文本特征的表示, 使用Multi-BiLSTM网络作为特征抽取的网络结构。这是因为, 一方面文本数据具有天然的序列化特征, LSTM能保留文本的位置信息; 另一方面, 一般社交媒体信息属于典型的短文本, LSTM加入了门控机制, 能有效解决短文本中上下文信息少、语义不明确等问题。
根据Ma等[8 ] 的研究, RNN网络能够在网络谣言检测任务中有效对文本特征进行抽取, 在此基础上通过对比实验证明了使用复杂RNN衍生结构与增加网络层数可显著提升特征抽取效果, 继而提升谣言检测效果。借鉴Ma等[8 ] 的研究成果, 本文选择双层双向LSTM网络(Multi-BiLSTM)作为特征抽取层, 其中双向机制保证了每一个词都在充分考虑上下文的条件下获得语义[14 ] , 这样双层网络保证了文本特征被深度抽取, 其结构如图2 所示。
图2
定义源领域S 与目标领域T 经过特征抽取输出的结果分别为$Sf=\{S{{f}_{1}}\ldots S{{f}_{i}}\ldots S{{f}_{m}}\}$与$Tf=$$\{T{{f}_{1}}\ldots T{{f}_{i}}\ldots T{{f}_{m}}\}$。
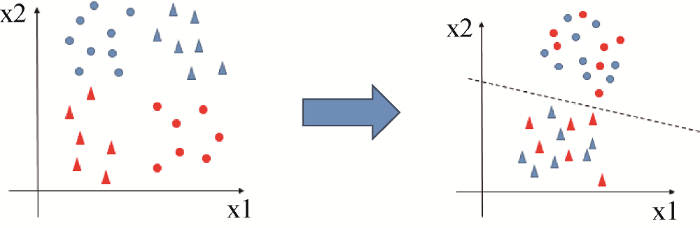
领域适配旨在减小领域间的数据分布差异[15 ] , 使两个领域数据分布趋同, 如图3 所示, 蓝色表示源领域S , 红色表示目标领域T , 圆点表示谣言, 三角表示非谣言数据, 在跨领域构建谣言检测模型时, 源领域S 与目标领域T 具有不同的数据分布(左图), 因而不能直接使用源领域S 帮助目标领域T 构建谣言检测。利用基于特征的迁移学习技术进行领域适配, 即通过特征变换使得源领域与目标领域数据分布趋于相似(右图), 继而目标领域可以借助源领域的标签信息进行训练建模, 这一过程也称为文本的特征对齐(Feature Alignment)。
图3
最大均值差异(Maximum Mean Discrepancy, MMD)方法是由Borgwardt等[16 ] 提出的判断两类样本是否同属于一个总体分布的指标, 最初用于双样本检测中。因为MMD统计量的大小表示两个数据分布之间的距离, 很多学者利用这一点将MMD应用在迁移学习领域[17 ,18 ,19 ] 。本文基于此将MMD方法应用到网络谣言检测的领域适配中, 在Multi-BiLSTM层后添加领域适配层, 计算源领域S 与目标领域T 间的距离, 并将其计入整个深度迁移网络的损失函数。借助于特征抽取层Multi-BiLSTM网络良好的特征变换能力[20 ] , 在训练过程中可以不断减小源领域S 与目标领域T 的分布差异, 从而实现领域的适配。
设领域适配层权值为${{w}_{a}}$,偏置量为${{b}_{a}}$,$\text{ }\!\!\sigma\!\!\text{ }(\cdot )$为sigmod函数, 则领域适配层的输出分别如公式(1)和公式(2) 所示。
(1) $S{{a}_{i}}=\sigma ({{w}_{a}}\cdot S{{f}_{i}}+{{b}_{a}})$
(2) $T{{a}_{i}}=\sigma ({{w}_{a}}\cdot T{{f}_{i}}+{{b}_{a}})$
同时计算基于MMD的领域分布距离并计入最终的误差函数。
设源领域数据$Sa=\{S{{a}_{1}}\ldots S{{a}_{i}}\ldots S{{a}_{n}}\}$服从p 分布, 目标领域数据$Ta=\{T{{a}_{1}}\ldots T{{a}_{i}}\ldots T{{a}_{n}}\}$服从q 分布。在一个再生核希尔伯特空间(Reproducing Kernel Hilbert Space, RKHS) H 中存在映射函数$\phi (\cdot ):\text{X}\to H$表示从原始空间到希尔伯特空间的一个映射[16 ] , 则源领域与目标领域的MMD距离如公式(3)所示。
(3) $MMD(Sa,Ta)={{\left\| {{E}_{p}}[\phi (Sa)]-{{E}_{q}}[\phi (Ta)] \right\|}_{H}}$
其中, H 是完备的内积空间, 进一步描述为L 2范式和内积形式如公式(4)、公式(5)所示, 其中${{\mu }_{p}},{{\mu }_{q}}$表示p ,q 分布的总体分布[16 ] 。
(4) $MM{{D}^{2}}(Sa,Ta)=||<{{\mu }_{p}}-{{\mu }_{q}},\phi (\cdot ){{>}_{H}}|{{|}^{2}}$
(5) $\begin{align} & MM{{D}^{2}}(Sa,Ta)=E[\phi (Sa)\phi (S\text{\hat{a}})]\text{+}E[\phi (Ta)\phi (T\text{\hat{a}})]- \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \mathrm{2}E[\phi (Ta)\phi (Sa)] \\ \end{align}$
存在再生核$k(x,y)=\phi (x)\phi (y)$, 所以存在MMD的估计量如公式(6)所示[16 ] 。
(6) $\begin{align} & MM{{D}^{2}}(Sa,Ta)=[\frac{1}{{{n}^{2}}}\sum\limits_{i,j\mathrm{=}1}^{n}{k(S{{a}_{i}},S{{a}_{j}})}+ \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{1}{{{m}^{2}}}\sum\limits_{i,j\mathrm{=}1}^{m}{k(T{{a}_{i}},T{{a}_{j}})}- \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \frac{2}{mn}\sum\limits_{i,j=1}^{n,m}{k(S{{a}_{i}},T{{a}_{j}})}] \\ \end{align}$
仿照SVM的核方法, 在实际计算中核函数k (x , y )可选择高斯核、线性核等。本文选用高斯核, 如公式(7)所示。
(7) $k(x,\text{y})=\exp (-\frac{{{\left\| x-y \right\|}^{2}}}{2{{\sigma }^{2}}})$
至此基于MMD计算的领域距离已经计算完成。如果将其作为误差项直接计入损失函数, 则使用SGD求优时的时间复杂度为$o({{n}^{2}})$, 这样会大大降低迁移效率。采用Gretton等[21 ] 提出的线性无偏估计量作为最终领域距离, 可以使计算的时间复杂度由$o({{n}^{2}})$降为$o(n)$。
定义函数$q({{d}_{i}})$如公式(8)所示, 进而可以计算MMD的值如公式(9)所示[21 ] 。
(8) $\begin{align} & q({{d}_{i}})\triangleq k(S{{a}_{2i}}_{-1},S{{a}_{2i}})+k(T{{a}_{2i-1}},T{{a}_{2i}})- \\ & \ \ \ \ \ \ \ \ \ \ \ k(S{{a}_{2i}}_{-1},T{{a}_{2i}})-k(T{{a}_{2i-1}},S{{a}_{2i}}) \\ \end{align}$
(9) $MM{{D}^{2}}(Sa,Ta)\triangleq \frac{2}{n}\sum\limits_{i=1}^{n/2}{q({{d}_{i}})}$
至此, 公式(9)将作为误差函数将计入总体迁移网络的总体误差。
特征融合是将不同角度的特征结合, 为分类提供更多可依据的信息。网络谣言的检测除了使用文本特征, 也可以利用其他特征。如从用户角度出发, 造谣者作为非正常用户常常具有粉丝少、关注多、注册地不明确、缺少认证等特点。从传播角度出发, 谣言在传播中蛊惑性较强, 具有较多的转发数、较少的评论数等。这两类特征并不随文本领域的不同而产生差别, 因此本文设计特征融合层, 在结合Castillo等[4 ] 、祖坤琳等[7 ] 、Zhang等[10 ] 研究成果的基础上, 选择8项用户特征、5项传播特征与输出的文本特征向量拼接, 形成完整的特征向量, 最终送入Softmax层生成预测类别。用户特征与传播特征如表1 和表2 所示。
设特征融合层权值为${{w}_{m}}$, 偏置量为${{b}_{m}}$, $S{{u}_{i}}$为第i 个用户的用户特征, $S{{p}_{i}}$为第i 个用户的传播特征。源领域S 数据特征融合层输出为$S{{m}_{i}}$, 类别预测变量为${{\hat{y}}_{i}}$, 则有网络结构如公式(10)和公式(11)所示。
(10) $S{{m}_{i}}=\sigma ({{w}_{m}}\cdot [S{{a}_{i}},S{{u}_{i}},S{{p}_{i}}]+{{b}_{m}})$
(11) ${{\hat{y}}_{i}}=Softmax(S{{m}_{i}})$
本文提出的深度迁移网络类似于多任务学习的形式, 一方面通过学习源领域与目标领域的数据分布差异实现领域适配, 另一方面学习了源领域的标签信息, 反映在目标函数上就是整个网络的损失函数由两部分组成, 分别是代表领域差距的MMD统计量与反映源领域标签信息的$\sum\limits_{i=1}^{n}{L\text{oss(}{{y}_{i}}\mathrm{,}{{{\hat{y}}}_{i}}\text{)}}$, 因此整个迁移网络的损失函数可表示如公式(12)所示, 其中K 为迁移常数。
(12) $\begin{align} & Global\_Loss(S,T)= \\ & \ \ \ \ \ \ \ \sum\limits_{i=1}^{n}{Loss({{y}_{i}},{{{\hat{y}}}_{i}}})+K\cdot MM{{D}^{2}}(Sa,Ta) \\ \end{align}$
4 实验与分析
4.1 数据采集与预处理
本实验在Twitter数据集上进行。数据一部分来自文献[8 ]公开的Twitter数据集, 其中包含498条谣言事件(对内容相似Twitter的总结文本)与494条非谣言事件, 以及这些事件后对应的Twitter文本。从中选择5个领域(Politics、News、Business、Food、History)的谣言文本, 从每个领域人工抽取10个关键词组成查询项, 将这些查询项通过Twitter官方的API进行检索, 得到包含10 314条Twitter的数据集, 其明细如表3 所示。
原始的Tweet数据包含较多信息, 通过文本提取获取到Tweet的正文部分, 作为实验的原始输入。同时提取其中的用户信息与传播信息, 经过归一化处理后在模型后半部分进行特征融合。实验采用交叉验证的方式, 实验结果图表展示了相关指标的均值。
使用GloVe(Global Vectors for Word Representation)实现对Tweet文本的词嵌入建模。GloVe是Pennington等[22 ] 提出的一种无监督词嵌入技术。相较于Word2Vec模型, GloVe通过加入全局的共现矩阵(Co-occurrence Matrix)信息, 有效解决了过于依赖局部信息、多义词处理乏力等问题, 适合Twitter这类短文本[23 ] 。
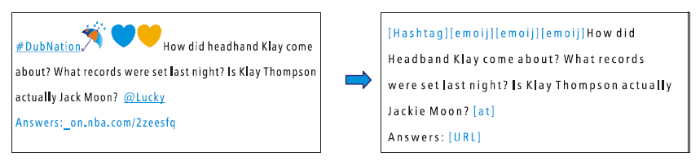
选择Stanford自然语言处理小组公开的Twitter文本集① (①https://nlp.stanford.edu/projects/glove/.)作为词库(本文选择其中的2 000万条构建词库), 在此基础上训练GloVe词向量。常见的Twitter文本一般由文字、符号、表情、@、hashtag(标签)、链接等元素构成, 传统的文本预处理方式会直接删除其他元素只保留文字元素。但Castillo等[4 ] 的研究表明符号、表情、@、hashtag(标签)、链接等元素可作为有效识别谣言的要素, 并在模型中加入这些元素的统计量实现了较好的预测效果。本文在此基础上, 使用特定标签对Twitter文本中的特殊元素进行替换, 并训练得到对应标签的词向量, 有效保留了这些元素的位置信息与数量信息。具体处理如图4 所示。
图4
4.2 迁移常数的选择
选择从Politics到Business与News到Food的迁移场景, 不同迁移场景最佳迁移常数不同, 但是迁移常数一般在1附近取得最佳迁移效果, 不同迁移常数下F1值的变化如图5 所示。说明在误差函数中, 领域损失项与标签损失项同样重要, 这从另一个角度也印证了领域适配的重要性。P、B、N、F分别表示Politics, Business, News, Food等领域。
图5
4.3 迁移有效性度量
迁移有效性度量迁移前后目标领域谣言检测 模型的准确率变化。实验选定Politics与News领 域为源领域, Food、History与Business为目标领域, 设计6组迁移实验(目标领域的标签信息仅用作测试集, 在训练时不带入模型)。选择的模型分别是:
①深度迁移网络(1D1A)。即本文的方法, D代表领域, A代表迁移, 1D1A代表既划分了谣言的领域又实现了迁移学习。
②不划分领域(0D0A)。将所有领域当作一个整体, 不考虑领域差异的影响, 因而也不存在领域适配和迁移。
③分领域但未做领域适配(1D0A)。即分领域构建谣言检测模型, 但对于无标注的目标领域T, 直接应用源领域数据得到的检测模型。源领域训练时网络结构不变, 数据输入只有源领域数据, 误差函数也删除了MMD损失项。
①深度迁移网络有效性。划分领域又做迁移学习(1D1A)的结果相较于另外两种不做迁移的建模思路准确率平均提升10.6%(0D0A)与8.1%(1D0A), 召回率平均提升10.9%(0D0A)与9.0%(1D0A), F1值平均提升10.3%(0D0A)与8.5%(1D0A)。这说明深度迁移网络通过加入领域适配层有效利用源领 域数据的标签信息, 减小了领域分布的差异, 有效提升检测效果。
②领域间数据分布差异明显, 分领域进行谣言检测更加精细化。1D0A忽略了领域间的数据分布差异, 直接将源领域的分类器应用于目标领域。其各项指标平均比深度迁移网络低8.5%左右, 这说明领域间确实存在数据分布差异, 分领域的建模方式具有更高准确性。
③数据在领域上的不平衡会降低数据贫瘠领域的准确度。0D0A遵循传统的建模思想将所有领域看作一个整体进行建模。相较于分领域的深度迁移网络, 其在谣言检测的准确率上平均低10.6%。这种准确度降低主要来自于数据集的不平衡, 数据越丰富效果越显著。
④分布越相近领域, 迁移效果越好。从传播学角度, Business作为目标领域与源领域Politics和News有更相近的数据分布, 因而经过迁移后, 谣言检测的准确率平均提高约10.0%。而从Politics到Food的迁移任务中, 谣言检测准确率仅提升6.1%左右, 这也符合人的直观认识。
将迁移学习的结果与已有方法从有标签数据和无标签数据两个方面展开对比。有标注为监督学习方法, 使用目标领域的标签信息构建谣言检测模型, 分类器为支持向量机SVM和线性回归LR。另一方面, 更常见的情况是目标领域往往缺少标注数据, 这就需要无监督的方式进行谣言检测。采用文献[10 ,11 ]提出的无监督模型作为对比实验, 其中文献[10 ]的方法定义为Multi-AN, 文献[11 ]的方法定义为RNN+AN。实验结果如表5 所示。
在有监督学习方面, SVM在三个领域的准确率平均比深度迁移网络高2.7%左右, 比LR则平均高1.3%, 这说明准确率差别并不显著, 迁移学习已经非常接近有监督学习的检测效果。而且在不同的目标领域表现较为稳定, 说明深度迁移网络的领域适配机制使得源领域标签信息可以被目标领域使用。由于实际应用中目标领域往往不具备充足的标注数据, 人工标注数据意味着巨大的时间成本与人工代价, 深度迁移网络就可以在无标注的数据集上得到谣言检测模型, 且准确率与在有标注数据集学习到的模型十分接近。
在无监督学习方面, 从表5 的实验结果来看, 文献[11 ]提出的RNN+AN模型是无监督方法中效果最好的, 以RNN+AN的模型为对比分别分析本文方法在三个领域内的迁移效果。在Food领域, 以Politics为源领域的迁移方法F1值与RNN+AN方法的F1值持平, 但以News为源领域的迁移方法在F1指标上却比对比方法高出5.2%, 这说明在Food领域内本文方法总体优于无监督方法; 在History领域, 两组迁移任务在F1值上的表现略低于RNN+AN的无监督方法(分别低0.1%与0.4%), 但是在Recall指标上均高于无监督方法, 这说明更多的潜在谣言被找到, 这一点在谣言的检测中显得更加重要; 在Business领域, 本文方法在F1值上比RNN+AN方法分别高出7.0%与6.6%。综合来看, 本文方法优于无监督的谣言检测方法。无监督方法是解决谣言数据无标注问题的一种思路, 其放弃了对标签信息的使用, 只选择微博数据的自身特征进行谣言检测, 因而检测效果有待进一步提升。本文方法在面对大量无标注数据时, 借助深度迁移网络, 有效利用源领域的标签信息, 因而在实验结果上优于无监督方法。
5 结 语
本文针对不同领域网络谣言的识别问题, 尝试对网络谣言实现分领域的有效检测。提出一种基于深度迁移网络的跨领域谣言检测模型, 在源领域拥有标注数据、目标领域是无标注数据的情况下, 通过双层双向LSTM网络实现对文本特征的深度提取, 在领域适配层计算源领域与目标领域MMD作为领域误差并送入全局误差, 与用户特征及传播特征相融合, 使用Softmax进行分类。实验在Twitter数据集上展开, 结果证明深度迁移网络能够有效迁移源领域标注数据, 帮助目标领域构建谣言检测模型, 显著提升目标领域谣言的检测准确率。
本文模型在面对不同领域的迁移任务时表现存在一定差别, 在进行迁移任务之前不能明确选择最优的源领域, 原因在于并未深入探讨领域分布差异对领域迁移任务的影响, 这将是下一步的工作重点, 以提升跨领域迁移的可扩展性与可控性。另一方面, 本文模型假定微博属于某一单一领域, 实际生活中很多网络谣言难以划分到某一个领域, 常常会同时属于社会、生活、经济等多个领域, 这一点广泛地存在于中文微博谣言。因此本文模型面对中文微博谣言时尚有一定的局限性, 也没有在中文微博上进行相关实验, 未来需要利用多标签学习技术进行深入分析, 探索适应中文数据的跨领域迁移方法。另外, 进一步的研究还包括如何提升深度迁移网络训练效率、改进本方法在监督学习上的表现等。
作者贡献声明
刘勘: 提出研究思路, 制定研究方案, 论文撰写、修改及最终版本修订;
杜好宸: 采集和分析数据, 进行实验, 撰写论文。
支撑数据
支撑数据由作者自存储, E-mail: dududuhc@163.com。
[1] 杜好宸. data.zip. Twitter谣言的训练集和测试集数据.
[2] 杜好宸. Tweet_word_embedding_200d.csv. 使用GloVe算法预训练的Tweet词向量.
[3] 杜好宸. result.rar. 文中实验数据及图表数据.
参考文献
View Option
[1]
曹博林 . 社交媒体: 概念、发展历程、特征与未来——兼谈当下对社交媒体认识的模糊之处
[J]. 湖南广播电视大学学报 , 2011 (3 ):65 -69 .
[本文引用: 1]
( Cao Bolin . Social Media: Definition, History of Development, Features and Future—The Ambiguous Cognition of Social Media
[J]. Journal of Hunan Radio & Television University , 2011 (3 ):65 -69 .)
[本文引用: 1]
[2]
雷霞 . 谣言: 概念演变与发展
[J]. 新闻与传播研究 , 2016 (9 ):113 -118 .
[本文引用: 1]
( Lei Xia . Rumor: Concept Evolution and Development
[J]. Journalism & Communication , 2016 (9 ):113 -118 .)
[本文引用: 1]
[3]
Fanti G Kairouz P Oh S , et al . Hiding the Rumor Source
[J]. IEEE Transactions on Information Theory , 2017 ,63 (10 ):6679 -6713 .
[本文引用: 1]
[4]
Castillo C Mendoza M Poblete B . Information Credibility on Twitter
[C]// Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India. 2011 : 675 -684 .
[本文引用: 4]
[5]
Ma J Gao W Wei Z , et al . Detect Rumors Using Time Series of Social Context Information on Microblogging Websites
[C]// Proceedings of the 24th ACM International Conference on Information and Knowledge Management, Melbourne, Australia. ACM , 2015 : 1751 -1754 .
[本文引用: 1]
[6]
Zhao Z Resnick P Mei Q . Enquiring Minds: Early Detection of Rumors in Social Media from Enquiry Posts
[C]// Proceedings of the 24th International Conference on World Wide Web, Florence, Italy. ACM , 2015 : 1395 -1405 .
[本文引用: 1]
[7]
祖坤琳 , 赵铭伟 , 郭凯 , 等 . 新浪微博谣言检测研究
[J]. 中文信息学报 , 2017 ,31 (3 ):198 -204 .
[本文引用: 2]
( Zu Kunlin Zhao Mingwei Guo Kai , et al . Research on the Detection of Rumor on Sina Weibo
[J]. Journal of Chinese Information Processing , 2017 ,31 (3 ):198 -204 .)
[本文引用: 2]
[8]
Ma J Gao W Mitra P , et al . Detecting Rumors from Microblogs with Recurrent Neural Networks
[C]// Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, USA. 2016 : 3818 -3824 .
[本文引用: 4]
[9]
Chen T Li X Yin H , et al . Call Attention to Rumors: Deep Attention Based Recurrent Neural Networks for Early Rumor Detection
[C]// Proceedings of the 2018 Pacific-Asia Conference on Knowledge Discovery and Data Mining. 2018 : 40 -52 .
[本文引用: 1]
[10]
Zhang Y Chen W Yeo C K , et al . Detecting Rumors on Online Social Networks Using Multi-Layer Autoencoder
[C]// Proceedings of the 2017 IEEE Technology & Engineering Management Conference. IEEE , 2017 : 437 -441 .
[本文引用: 4]
[11]
Chen W Zhang Y Yeo C K , et al . Unsupervised Rumor Detection Based on Users’ Behaviors Using Neural Networks
[J]. Pattern Recognition Letters , 2018 ,105 :226 -233 .
[本文引用: 4]
[12]
刘雅辉 , 靳小龙 , 沈华伟 , 等 . 社交媒体中的谣言识别研究综述
[J]. 计算机学报 , 2018 ,41 (7 ):1536 -1558 .
[本文引用: 1]
( Liu Yahui Jin Xiaolong Shen Huawei , et al . A Survey on Rumor Identification over Social Media
[J]. Chinese Journal of Computers , 2018 ,41 (7 ):1536 -1558 .)
[本文引用: 1]
[13]
Zhou J Xu W . End-to-End Learning of Semantic Role Labeling Using Recurrent Neural Networks
[C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. 2015 : 1127 -1137 .
[本文引用: 1]
[14]
Chen T Xu R He Y , et al . Improving Sentiment Analysis via Sentence Type Classification Using BiLSTM-CRF and CNN
[J]. Expert Systems with Applications , 2017 ,72 :221 -230 .
[本文引用: 1]
[15]
Blitzer J McDonald R Pereira F . Domain Adaptation with Structural Correspondence Learning
[C]// Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing, Sydney, Australia. ACM , 2006 : 120 -128 .
[本文引用: 1]
[16]
Borgwardt K M Gretton A Rasch M J , et al . Integrating Structured Biological Data by Kernel Maximum Mean Discrepancy
[J]. Bioinformatics , 2006 ,22 (14 ):e49 -e57 .
[本文引用: 4]
[17]
Ghifary M Kleijn W B Zhang M . Domain Adaptive Neural Networks for Object Recognition
[C]// Proceedings of the 13th Pacific Rim International Conference on Artificial Intelligence. 2014 : 898 -904 .
[本文引用: 1]
[18]
Tzeng E Hoffman J Zhang N , et al . Deep Domain Confusion: Maximizing for Domain Invariance
[OL]. arXiv Preprint, arXiv: 1412. 3474.
[本文引用: 1]
[19]
Long M Cao Y Wang J , et al . Learning Transferable Features with Deep Adaptation Networks
[C]// Proceedings of the 32nd International Conference on Machine Learning, Lille, France. 2015 : 97 -105 .
[本文引用: 1]
[20]
Mou L Meng Z Yan R , et al . How Transferable are Neural Networks in NLP Applications?
[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, USA. 2016 : 479 -489 .
[本文引用: 1]
[21]
Gretton A Sriperumbudur B Sejdinovic D , et al . Optimal Kernel Choice for Large-Scale Two-Sample Tests
[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, USA. 2012 : 1205 -1213 .
[本文引用: 2]
[22]
Pennington J Socher R Manning C D . GloVe: Global Vectors for Word Representation
[C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar. 2014 : 1532 -1543 .
[本文引用: 1]
[23]
Wu K Yang S Zhu K Q . False Rumors Detection on Sina Weibo by Propagation Structures
[C]// Proceedings of the 31st International Conference on Data Engineering, Seoul, South Korea. IEEE , 2015 : 651 -662 .
[本文引用: 1]
社交媒体: 概念、发展历程、特征与未来——兼谈当下对社交媒体认识的模糊之处
1
2011
... Web2.0时代, 以社交网站、微博、博客、论坛为代表的社交媒体成为互联网世界中最大的信息产生与交换渠道[1 ] , 同时也为谣言的生成与传播构筑了温床.社会学家将谣言定义为: 没有相应事实基础, 却被捏造出来并通过一定手段推动传播的言论[2 ] .相较于社会谣言, 网络中的谣言常常以吸引流量或制造恐慌为目的, 因而往往带有较大的煽动性与恶意性, 成为破坏网络空间秩序与环境的毒瘤, 对社会生活造成极大的负面影响[3 ] .因此对网络谣言进行有效 鉴别, 具有较为紧迫的社会意义、经济意义与现实 意义. ...
社交媒体: 概念、发展历程、特征与未来——兼谈当下对社交媒体认识的模糊之处
1
2011
... Web2.0时代, 以社交网站、微博、博客、论坛为代表的社交媒体成为互联网世界中最大的信息产生与交换渠道[1 ] , 同时也为谣言的生成与传播构筑了温床.社会学家将谣言定义为: 没有相应事实基础, 却被捏造出来并通过一定手段推动传播的言论[2 ] .相较于社会谣言, 网络中的谣言常常以吸引流量或制造恐慌为目的, 因而往往带有较大的煽动性与恶意性, 成为破坏网络空间秩序与环境的毒瘤, 对社会生活造成极大的负面影响[3 ] .因此对网络谣言进行有效 鉴别, 具有较为紧迫的社会意义、经济意义与现实 意义. ...
谣言: 概念演变与发展
1
2016
... Web2.0时代, 以社交网站、微博、博客、论坛为代表的社交媒体成为互联网世界中最大的信息产生与交换渠道[1 ] , 同时也为谣言的生成与传播构筑了温床.社会学家将谣言定义为: 没有相应事实基础, 却被捏造出来并通过一定手段推动传播的言论[2 ] .相较于社会谣言, 网络中的谣言常常以吸引流量或制造恐慌为目的, 因而往往带有较大的煽动性与恶意性, 成为破坏网络空间秩序与环境的毒瘤, 对社会生活造成极大的负面影响[3 ] .因此对网络谣言进行有效 鉴别, 具有较为紧迫的社会意义、经济意义与现实 意义. ...
谣言: 概念演变与发展
1
2016
... Web2.0时代, 以社交网站、微博、博客、论坛为代表的社交媒体成为互联网世界中最大的信息产生与交换渠道[1 ] , 同时也为谣言的生成与传播构筑了温床.社会学家将谣言定义为: 没有相应事实基础, 却被捏造出来并通过一定手段推动传播的言论[2 ] .相较于社会谣言, 网络中的谣言常常以吸引流量或制造恐慌为目的, 因而往往带有较大的煽动性与恶意性, 成为破坏网络空间秩序与环境的毒瘤, 对社会生活造成极大的负面影响[3 ] .因此对网络谣言进行有效 鉴别, 具有较为紧迫的社会意义、经济意义与现实 意义. ...
Hiding the Rumor Source
1
2017
... Web2.0时代, 以社交网站、微博、博客、论坛为代表的社交媒体成为互联网世界中最大的信息产生与交换渠道[1 ] , 同时也为谣言的生成与传播构筑了温床.社会学家将谣言定义为: 没有相应事实基础, 却被捏造出来并通过一定手段推动传播的言论[2 ] .相较于社会谣言, 网络中的谣言常常以吸引流量或制造恐慌为目的, 因而往往带有较大的煽动性与恶意性, 成为破坏网络空间秩序与环境的毒瘤, 对社会生活造成极大的负面影响[3 ] .因此对网络谣言进行有效 鉴别, 具有较为紧迫的社会意义、经济意义与现实 意义. ...
Information Credibility on Twitter
4
2011
... 网络谣言的自动检测最早开始于Twitter, 众多学者从识别谣言的要素入手, 构造相关特征实现对网络谣言的检测.Castillo等[4 ] 归纳了来自4个方面的要素以识别谣言, 分别是文本特征、用户特征、传播特征和话题特征, 在此基础上总结出15项关键特征并利用决策树算法J48实现对谣言的检测.Ma等[5 ] 考虑谣言演变的时间特征, 使用动态时间序列模型对谣言进行检测.Zhao等[6 ] 通过构建线索词等特征实现了谣言的早期预测.祖坤琳等[7 ] 则关注微博的评论消息, 将微博评论的情感倾向性加入模型, 实现了谣言的有效检测.这些方法虽然取得一定效果, 但是大多依赖于手工构造特征, 也属于谣言识别要素的浅层提取, 因而无法进一步提升准确率. ...
... 本文的建模场景针对谣言在某些领域(目标领域T)存在数据量少且缺少标注的问题, 借助标注数据丰富的领域(源领域S)数据通过迁移学习, 提高目标领域的检测效果.借鉴文献[4 ], 结合谣言的文本特征、用户特征、传播特征构建深度迁移谣言检测模型, 如图1 所示.因为用户特征与传播特征不受领域影响, 因此先对文本特征进行跨领域迁移, 在网络训练时再引入用户特征与传播特征. ...
... 特征融合是将不同角度的特征结合, 为分类提供更多可依据的信息.网络谣言的检测除了使用文本特征, 也可以利用其他特征.如从用户角度出发, 造谣者作为非正常用户常常具有粉丝少、关注多、注册地不明确、缺少认证等特点.从传播角度出发, 谣言在传播中蛊惑性较强, 具有较多的转发数、较少的评论数等.这两类特征并不随文本领域的不同而产生差别, 因此本文设计特征融合层, 在结合Castillo等[4 ] 、祖坤琳等[7 ] 、Zhang等[10 ] 研究成果的基础上, 选择8项用户特征、5项传播特征与输出的文本特征向量拼接, 形成完整的特征向量, 最终送入Softmax层生成预测类别.用户特征与传播特征如表1 和表2 所示. ...
... 选择Stanford自然语言处理小组公开的Twitter文本集① (①https://nlp.stanford.edu/projects/glove/.)作为词库(本文选择其中的2 000万条构建词库), 在此基础上训练GloVe词向量.常见的Twitter文本一般由文字、符号、表情、@、hashtag(标签)、链接等元素构成, 传统的文本预处理方式会直接删除其他元素只保留文字元素.但Castillo等[4 ] 的研究表明符号、表情、@、hashtag(标签)、链接等元素可作为有效识别谣言的要素, 并在模型中加入这些元素的统计量实现了较好的预测效果.本文在此基础上, 使用特定标签对Twitter文本中的特殊元素进行替换, 并训练得到对应标签的词向量, 有效保留了这些元素的位置信息与数量信息.具体处理如图4 所示. ...
Detect Rumors Using Time Series of Social Context Information on Microblogging Websites
1
2015
... 网络谣言的自动检测最早开始于Twitter, 众多学者从识别谣言的要素入手, 构造相关特征实现对网络谣言的检测.Castillo等[4 ] 归纳了来自4个方面的要素以识别谣言, 分别是文本特征、用户特征、传播特征和话题特征, 在此基础上总结出15项关键特征并利用决策树算法J48实现对谣言的检测.Ma等[5 ] 考虑谣言演变的时间特征, 使用动态时间序列模型对谣言进行检测.Zhao等[6 ] 通过构建线索词等特征实现了谣言的早期预测.祖坤琳等[7 ] 则关注微博的评论消息, 将微博评论的情感倾向性加入模型, 实现了谣言的有效检测.这些方法虽然取得一定效果, 但是大多依赖于手工构造特征, 也属于谣言识别要素的浅层提取, 因而无法进一步提升准确率. ...
Enquiring Minds: Early Detection of Rumors in Social Media from Enquiry Posts
1
2015
... 网络谣言的自动检测最早开始于Twitter, 众多学者从识别谣言的要素入手, 构造相关特征实现对网络谣言的检测.Castillo等[4 ] 归纳了来自4个方面的要素以识别谣言, 分别是文本特征、用户特征、传播特征和话题特征, 在此基础上总结出15项关键特征并利用决策树算法J48实现对谣言的检测.Ma等[5 ] 考虑谣言演变的时间特征, 使用动态时间序列模型对谣言进行检测.Zhao等[6 ] 通过构建线索词等特征实现了谣言的早期预测.祖坤琳等[7 ] 则关注微博的评论消息, 将微博评论的情感倾向性加入模型, 实现了谣言的有效检测.这些方法虽然取得一定效果, 但是大多依赖于手工构造特征, 也属于谣言识别要素的浅层提取, 因而无法进一步提升准确率. ...
新浪微博谣言检测研究
2
2017
... 网络谣言的自动检测最早开始于Twitter, 众多学者从识别谣言的要素入手, 构造相关特征实现对网络谣言的检测.Castillo等[4 ] 归纳了来自4个方面的要素以识别谣言, 分别是文本特征、用户特征、传播特征和话题特征, 在此基础上总结出15项关键特征并利用决策树算法J48实现对谣言的检测.Ma等[5 ] 考虑谣言演变的时间特征, 使用动态时间序列模型对谣言进行检测.Zhao等[6 ] 通过构建线索词等特征实现了谣言的早期预测.祖坤琳等[7 ] 则关注微博的评论消息, 将微博评论的情感倾向性加入模型, 实现了谣言的有效检测.这些方法虽然取得一定效果, 但是大多依赖于手工构造特征, 也属于谣言识别要素的浅层提取, 因而无法进一步提升准确率. ...
... 特征融合是将不同角度的特征结合, 为分类提供更多可依据的信息.网络谣言的检测除了使用文本特征, 也可以利用其他特征.如从用户角度出发, 造谣者作为非正常用户常常具有粉丝少、关注多、注册地不明确、缺少认证等特点.从传播角度出发, 谣言在传播中蛊惑性较强, 具有较多的转发数、较少的评论数等.这两类特征并不随文本领域的不同而产生差别, 因此本文设计特征融合层, 在结合Castillo等[4 ] 、祖坤琳等[7 ] 、Zhang等[10 ] 研究成果的基础上, 选择8项用户特征、5项传播特征与输出的文本特征向量拼接, 形成完整的特征向量, 最终送入Softmax层生成预测类别.用户特征与传播特征如表1 和表2 所示. ...
新浪微博谣言检测研究
2
2017
... 网络谣言的自动检测最早开始于Twitter, 众多学者从识别谣言的要素入手, 构造相关特征实现对网络谣言的检测.Castillo等[4 ] 归纳了来自4个方面的要素以识别谣言, 分别是文本特征、用户特征、传播特征和话题特征, 在此基础上总结出15项关键特征并利用决策树算法J48实现对谣言的检测.Ma等[5 ] 考虑谣言演变的时间特征, 使用动态时间序列模型对谣言进行检测.Zhao等[6 ] 通过构建线索词等特征实现了谣言的早期预测.祖坤琳等[7 ] 则关注微博的评论消息, 将微博评论的情感倾向性加入模型, 实现了谣言的有效检测.这些方法虽然取得一定效果, 但是大多依赖于手工构造特征, 也属于谣言识别要素的浅层提取, 因而无法进一步提升准确率. ...
... 特征融合是将不同角度的特征结合, 为分类提供更多可依据的信息.网络谣言的检测除了使用文本特征, 也可以利用其他特征.如从用户角度出发, 造谣者作为非正常用户常常具有粉丝少、关注多、注册地不明确、缺少认证等特点.从传播角度出发, 谣言在传播中蛊惑性较强, 具有较多的转发数、较少的评论数等.这两类特征并不随文本领域的不同而产生差别, 因此本文设计特征融合层, 在结合Castillo等[4 ] 、祖坤琳等[7 ] 、Zhang等[10 ] 研究成果的基础上, 选择8项用户特征、5项传播特征与输出的文本特征向量拼接, 形成完整的特征向量, 最终送入Softmax层生成预测类别.用户特征与传播特征如表1 和表2 所示. ...
Detecting Rumors from Microblogs with Recurrent Neural Networks
4
2016
... 近年, 很多学者尝试使用深度学习模型自动构造深层特征实现谣言检测.Ma等[8 ] 尝试使用RNN及其衍生模型对谣言事件进行检测, 抽取相关的Tweet组成谣言事件, 然后通过词嵌入提取谣言事件的特征, 最后借助RNN网络实现对谣言事件的检测, 实验证明了RNN在谣言检测领域的有效性.Chen等[9 ] 在此基础上, 加入注意力机制, 实现对Tweet特征的深层抽取, 取得了较好效果.深度学习模型的构建依赖于大量标注数据, 而网络谣言的数据获取一直是谣言检测领域的一大难题, 因此数据标注问题成为基于深度学习模型进行谣言检测的最大瓶颈.一些学者尝试避开数据的标注, 借助无监督学习的思想进行网络谣言检测.Zhang等[10 ] 提出一种无监督的谣言检测方式, 借助于多层自编码器获取谣言的文本编码规则, 实现对谣言的有效检测.Chen等[11 ] 在自编码器的前端加入多层RNN网络, 进一步提升了模型的效果.无监督学习的方法虽然避开了数据标注的问题, 但是模型的不稳定性会带来较大局限. ...
... 根据Ma等[8 ] 的研究, RNN网络能够在网络谣言检测任务中有效对文本特征进行抽取, 在此基础上通过对比实验证明了使用复杂RNN衍生结构与增加网络层数可显著提升特征抽取效果, 继而提升谣言检测效果.借鉴Ma等[8 ] 的研究成果, 本文选择双层双向LSTM网络(Multi-BiLSTM)作为特征抽取层, 其中双向机制保证了每一个词都在充分考虑上下文的条件下获得语义[14 ] , 这样双层网络保证了文本特征被深度抽取, 其结构如图2 所示. ...
... [8 ]的研究成果, 本文选择双层双向LSTM网络(Multi-BiLSTM)作为特征抽取层, 其中双向机制保证了每一个词都在充分考虑上下文的条件下获得语义[14 ] , 这样双层网络保证了文本特征被深度抽取, 其结构如图2 所示. ...
... 本实验在Twitter数据集上进行.数据一部分来自文献[8 ]公开的Twitter数据集, 其中包含498条谣言事件(对内容相似Twitter的总结文本)与494条非谣言事件, 以及这些事件后对应的Twitter文本.从中选择5个领域(Politics、News、Business、Food、History)的谣言文本, 从每个领域人工抽取10个关键词组成查询项, 将这些查询项通过Twitter官方的API进行检索, 得到包含10 314条Twitter的数据集, 其明细如表3 所示. ...
Call Attention to Rumors: Deep Attention Based Recurrent Neural Networks for Early Rumor Detection
1
2018
... 近年, 很多学者尝试使用深度学习模型自动构造深层特征实现谣言检测.Ma等[8 ] 尝试使用RNN及其衍生模型对谣言事件进行检测, 抽取相关的Tweet组成谣言事件, 然后通过词嵌入提取谣言事件的特征, 最后借助RNN网络实现对谣言事件的检测, 实验证明了RNN在谣言检测领域的有效性.Chen等[9 ] 在此基础上, 加入注意力机制, 实现对Tweet特征的深层抽取, 取得了较好效果.深度学习模型的构建依赖于大量标注数据, 而网络谣言的数据获取一直是谣言检测领域的一大难题, 因此数据标注问题成为基于深度学习模型进行谣言检测的最大瓶颈.一些学者尝试避开数据的标注, 借助无监督学习的思想进行网络谣言检测.Zhang等[10 ] 提出一种无监督的谣言检测方式, 借助于多层自编码器获取谣言的文本编码规则, 实现对谣言的有效检测.Chen等[11 ] 在自编码器的前端加入多层RNN网络, 进一步提升了模型的效果.无监督学习的方法虽然避开了数据标注的问题, 但是模型的不稳定性会带来较大局限. ...
Detecting Rumors on Online Social Networks Using Multi-Layer Autoencoder
4
2017
... 近年, 很多学者尝试使用深度学习模型自动构造深层特征实现谣言检测.Ma等[8 ] 尝试使用RNN及其衍生模型对谣言事件进行检测, 抽取相关的Tweet组成谣言事件, 然后通过词嵌入提取谣言事件的特征, 最后借助RNN网络实现对谣言事件的检测, 实验证明了RNN在谣言检测领域的有效性.Chen等[9 ] 在此基础上, 加入注意力机制, 实现对Tweet特征的深层抽取, 取得了较好效果.深度学习模型的构建依赖于大量标注数据, 而网络谣言的数据获取一直是谣言检测领域的一大难题, 因此数据标注问题成为基于深度学习模型进行谣言检测的最大瓶颈.一些学者尝试避开数据的标注, 借助无监督学习的思想进行网络谣言检测.Zhang等[10 ] 提出一种无监督的谣言检测方式, 借助于多层自编码器获取谣言的文本编码规则, 实现对谣言的有效检测.Chen等[11 ] 在自编码器的前端加入多层RNN网络, 进一步提升了模型的效果.无监督学习的方法虽然避开了数据标注的问题, 但是模型的不稳定性会带来较大局限. ...
... 特征融合是将不同角度的特征结合, 为分类提供更多可依据的信息.网络谣言的检测除了使用文本特征, 也可以利用其他特征.如从用户角度出发, 造谣者作为非正常用户常常具有粉丝少、关注多、注册地不明确、缺少认证等特点.从传播角度出发, 谣言在传播中蛊惑性较强, 具有较多的转发数、较少的评论数等.这两类特征并不随文本领域的不同而产生差别, 因此本文设计特征融合层, 在结合Castillo等[4 ] 、祖坤琳等[7 ] 、Zhang等[10 ] 研究成果的基础上, 选择8项用户特征、5项传播特征与输出的文本特征向量拼接, 形成完整的特征向量, 最终送入Softmax层生成预测类别.用户特征与传播特征如表1 和表2 所示. ...
... 将迁移学习的结果与已有方法从有标签数据和无标签数据两个方面展开对比.有标注为监督学习方法, 使用目标领域的标签信息构建谣言检测模型, 分类器为支持向量机SVM和线性回归LR.另一方面, 更常见的情况是目标领域往往缺少标注数据, 这就需要无监督的方式进行谣言检测.采用文献[10 ,11 ]提出的无监督模型作为对比实验, 其中文献[10 ]的方法定义为Multi-AN, 文献[11 ]的方法定义为RNN+AN.实验结果如表5 所示. ...
... ]提出的无监督模型作为对比实验, 其中文献[10 ]的方法定义为Multi-AN, 文献[11 ]的方法定义为RNN+AN.实验结果如表5 所示. ...
Unsupervised Rumor Detection Based on Users’ Behaviors Using Neural Networks
4
2018
... 近年, 很多学者尝试使用深度学习模型自动构造深层特征实现谣言检测.Ma等[8 ] 尝试使用RNN及其衍生模型对谣言事件进行检测, 抽取相关的Tweet组成谣言事件, 然后通过词嵌入提取谣言事件的特征, 最后借助RNN网络实现对谣言事件的检测, 实验证明了RNN在谣言检测领域的有效性.Chen等[9 ] 在此基础上, 加入注意力机制, 实现对Tweet特征的深层抽取, 取得了较好效果.深度学习模型的构建依赖于大量标注数据, 而网络谣言的数据获取一直是谣言检测领域的一大难题, 因此数据标注问题成为基于深度学习模型进行谣言检测的最大瓶颈.一些学者尝试避开数据的标注, 借助无监督学习的思想进行网络谣言检测.Zhang等[10 ] 提出一种无监督的谣言检测方式, 借助于多层自编码器获取谣言的文本编码规则, 实现对谣言的有效检测.Chen等[11 ] 在自编码器的前端加入多层RNN网络, 进一步提升了模型的效果.无监督学习的方法虽然避开了数据标注的问题, 但是模型的不稳定性会带来较大局限. ...
... 将迁移学习的结果与已有方法从有标签数据和无标签数据两个方面展开对比.有标注为监督学习方法, 使用目标领域的标签信息构建谣言检测模型, 分类器为支持向量机SVM和线性回归LR.另一方面, 更常见的情况是目标领域往往缺少标注数据, 这就需要无监督的方式进行谣言检测.采用文献[10 ,11 ]提出的无监督模型作为对比实验, 其中文献[10 ]的方法定义为Multi-AN, 文献[11 ]的方法定义为RNN+AN.实验结果如表5 所示. ...
... ]的方法定义为Multi-AN, 文献[11 ]的方法定义为RNN+AN.实验结果如表5 所示. ...
... 在无监督学习方面, 从表5 的实验结果来看, 文献[11 ]提出的RNN+AN模型是无监督方法中效果最好的, 以RNN+AN的模型为对比分别分析本文方法在三个领域内的迁移效果.在Food领域, 以Politics为源领域的迁移方法F1值与RNN+AN方法的F1值持平, 但以News为源领域的迁移方法在F1指标上却比对比方法高出5.2%, 这说明在Food领域内本文方法总体优于无监督方法; 在History领域, 两组迁移任务在F1值上的表现略低于RNN+AN的无监督方法(分别低0.1%与0.4%), 但是在Recall指标上均高于无监督方法, 这说明更多的潜在谣言被找到, 这一点在谣言的检测中显得更加重要; 在Business领域, 本文方法在F1值上比RNN+AN方法分别高出7.0%与6.6%.综合来看, 本文方法优于无监督的谣言检测方法.无监督方法是解决谣言数据无标注问题的一种思路, 其放弃了对标签信息的使用, 只选择微博数据的自身特征进行谣言检测, 因而检测效果有待进一步提升.本文方法在面对大量无标注数据时, 借助深度迁移网络, 有效利用源领域的标签信息, 因而在实验结果上优于无监督方法. ...
社交媒体中的谣言识别研究综述
1
2018
... 无论使用传统模型还是深度学习模型, 通过对文本信息、用户信息、传播信息的加工可有效识别网络谣言[12 ] , 借助深度网络自动构建特征进一步提升了谣言检测的准确性与稳定性.然而网络谣言涉及众多领域, 比如经济类谣言、社会类谣言、政治类谣言等.不同领域具有不同的特征, 但现有的谣言检测研究缺乏对领域的关注, 常用统一的检测模型应对各个领域的谣言.这样的方法忽视了领域差异对谣言检测的影响, 导致识别准确率低.针对网络谣言的分领域问题, 也可以利用已有方法进行识别, 但有些领域数据量较少会导致识别结果不佳.本文将这一问题视为领域数据标注不足的问题, 利用迁移学习的思想来探寻其中的解决方案. ...
社交媒体中的谣言识别研究综述
1
2018
... 无论使用传统模型还是深度学习模型, 通过对文本信息、用户信息、传播信息的加工可有效识别网络谣言[12 ] , 借助深度网络自动构建特征进一步提升了谣言检测的准确性与稳定性.然而网络谣言涉及众多领域, 比如经济类谣言、社会类谣言、政治类谣言等.不同领域具有不同的特征, 但现有的谣言检测研究缺乏对领域的关注, 常用统一的检测模型应对各个领域的谣言.这样的方法忽视了领域差异对谣言检测的影响, 导致识别准确率低.针对网络谣言的分领域问题, 也可以利用已有方法进行识别, 但有些领域数据量较少会导致识别结果不佳.本文将这一问题视为领域数据标注不足的问题, 利用迁移学习的思想来探寻其中的解决方案. ...
End-to-End Learning of Semantic Role Labeling Using Recurrent Neural Networks
1
2015
... 整个流程可分为词嵌入处理、特征抽取、领域适配、特征融合、预测分类等步骤.具体而言, 模型通过预先训练GloVe词向量实现对输入文本的向量化; 将两个领域的文本向量经过同一个多层双向LSTM网络[13 ] , 完成对文本特征深度提取(特征抽取); 然后将经过特征抽取过的两个领域数据输入全连接层, 这时会计算两个领域数据分布的差异; 最后将输出向量与对应的用户特征向量及传播特征向量进行拼接, 并送入Softmax层进行预测训练. ...
Improving Sentiment Analysis via Sentence Type Classification Using BiLSTM-CRF and CNN
1
2017
... 根据Ma等[8 ] 的研究, RNN网络能够在网络谣言检测任务中有效对文本特征进行抽取, 在此基础上通过对比实验证明了使用复杂RNN衍生结构与增加网络层数可显著提升特征抽取效果, 继而提升谣言检测效果.借鉴Ma等[8 ] 的研究成果, 本文选择双层双向LSTM网络(Multi-BiLSTM)作为特征抽取层, 其中双向机制保证了每一个词都在充分考虑上下文的条件下获得语义[14 ] , 这样双层网络保证了文本特征被深度抽取, 其结构如图2 所示. ...
Domain Adaptation with Structural Correspondence Learning
1
2006
... 领域适配旨在减小领域间的数据分布差异[15 ] , 使两个领域数据分布趋同, 如图3 所示, 蓝色表示源领域S , 红色表示目标领域T , 圆点表示谣言, 三角表示非谣言数据, 在跨领域构建谣言检测模型时, 源领域S 与目标领域T 具有不同的数据分布(左图), 因而不能直接使用源领域S 帮助目标领域T 构建谣言检测.利用基于特征的迁移学习技术进行领域适配, 即通过特征变换使得源领域与目标领域数据分布趋于相似(右图), 继而目标领域可以借助源领域的标签信息进行训练建模, 这一过程也称为文本的特征对齐(Feature Alignment). ...
Integrating Structured Biological Data by Kernel Maximum Mean Discrepancy
4
2006
... 最大均值差异(Maximum Mean Discrepancy, MMD)方法是由Borgwardt等[16 ] 提出的判断两类样本是否同属于一个总体分布的指标, 最初用于双样本检测中.因为MMD统计量的大小表示两个数据分布之间的距离, 很多学者利用这一点将MMD应用在迁移学习领域[17 ,18 ,19 ] .本文基于此将MMD方法应用到网络谣言检测的领域适配中, 在Multi-BiLSTM层后添加领域适配层, 计算源领域S 与目标领域T 间的距离, 并将其计入整个深度迁移网络的损失函数.借助于特征抽取层Multi-BiLSTM网络良好的特征变换能力[20 ] , 在训练过程中可以不断减小源领域S 与目标领域T 的分布差异, 从而实现领域的适配. ...
... 设源领域数据$Sa=\{S{{a}_{1}}\ldots S{{a}_{i}}\ldots S{{a}_{n}}\}$服从p 分布, 目标领域数据$Ta=\{T{{a}_{1}}\ldots T{{a}_{i}}\ldots T{{a}_{n}}\}$服从q 分布.在一个再生核希尔伯特空间(Reproducing Kernel Hilbert Space, RKHS) H 中存在映射函数$\phi (\cdot ):\text{X}\to H$表示从原始空间到希尔伯特空间的一个映射[16 ] , 则源领域与目标领域的MMD距离如公式(3)所示. ...
... 其中, H 是完备的内积空间, 进一步描述为L 2范式和内积形式如公式(4)、公式(5)所示, 其中${{\mu }_{p}},{{\mu }_{q}}$表示p ,q 分布的总体分布[16 ] . ...
... 存在再生核$k(x,y)=\phi (x)\phi (y)$, 所以存在MMD的估计量如公式(6)所示[16 ] . ...
Domain Adaptive Neural Networks for Object Recognition
1
2014
... 最大均值差异(Maximum Mean Discrepancy, MMD)方法是由Borgwardt等[16 ] 提出的判断两类样本是否同属于一个总体分布的指标, 最初用于双样本检测中.因为MMD统计量的大小表示两个数据分布之间的距离, 很多学者利用这一点将MMD应用在迁移学习领域[17 ,18 ,19 ] .本文基于此将MMD方法应用到网络谣言检测的领域适配中, 在Multi-BiLSTM层后添加领域适配层, 计算源领域S 与目标领域T 间的距离, 并将其计入整个深度迁移网络的损失函数.借助于特征抽取层Multi-BiLSTM网络良好的特征变换能力[20 ] , 在训练过程中可以不断减小源领域S 与目标领域T 的分布差异, 从而实现领域的适配. ...
Deep Domain Confusion: Maximizing for Domain Invariance
1
... 最大均值差异(Maximum Mean Discrepancy, MMD)方法是由Borgwardt等[16 ] 提出的判断两类样本是否同属于一个总体分布的指标, 最初用于双样本检测中.因为MMD统计量的大小表示两个数据分布之间的距离, 很多学者利用这一点将MMD应用在迁移学习领域[17 ,18 ,19 ] .本文基于此将MMD方法应用到网络谣言检测的领域适配中, 在Multi-BiLSTM层后添加领域适配层, 计算源领域S 与目标领域T 间的距离, 并将其计入整个深度迁移网络的损失函数.借助于特征抽取层Multi-BiLSTM网络良好的特征变换能力[20 ] , 在训练过程中可以不断减小源领域S 与目标领域T 的分布差异, 从而实现领域的适配. ...
Learning Transferable Features with Deep Adaptation Networks
1
2015
... 最大均值差异(Maximum Mean Discrepancy, MMD)方法是由Borgwardt等[16 ] 提出的判断两类样本是否同属于一个总体分布的指标, 最初用于双样本检测中.因为MMD统计量的大小表示两个数据分布之间的距离, 很多学者利用这一点将MMD应用在迁移学习领域[17 ,18 ,19 ] .本文基于此将MMD方法应用到网络谣言检测的领域适配中, 在Multi-BiLSTM层后添加领域适配层, 计算源领域S 与目标领域T 间的距离, 并将其计入整个深度迁移网络的损失函数.借助于特征抽取层Multi-BiLSTM网络良好的特征变换能力[20 ] , 在训练过程中可以不断减小源领域S 与目标领域T 的分布差异, 从而实现领域的适配. ...
How Transferable are Neural Networks in NLP Applications?
1
2016
... 最大均值差异(Maximum Mean Discrepancy, MMD)方法是由Borgwardt等[16 ] 提出的判断两类样本是否同属于一个总体分布的指标, 最初用于双样本检测中.因为MMD统计量的大小表示两个数据分布之间的距离, 很多学者利用这一点将MMD应用在迁移学习领域[17 ,18 ,19 ] .本文基于此将MMD方法应用到网络谣言检测的领域适配中, 在Multi-BiLSTM层后添加领域适配层, 计算源领域S 与目标领域T 间的距离, 并将其计入整个深度迁移网络的损失函数.借助于特征抽取层Multi-BiLSTM网络良好的特征变换能力[20 ] , 在训练过程中可以不断减小源领域S 与目标领域T 的分布差异, 从而实现领域的适配. ...
Optimal Kernel Choice for Large-Scale Two-Sample Tests
2
2012
... 至此基于MMD计算的领域距离已经计算完成.如果将其作为误差项直接计入损失函数, 则使用SGD求优时的时间复杂度为$o({{n}^{2}})$, 这样会大大降低迁移效率.采用Gretton等[21 ] 提出的线性无偏估计量作为最终领域距离, 可以使计算的时间复杂度由$o({{n}^{2}})$降为$o(n)$. ...
... 定义函数$q({{d}_{i}})$如公式(8)所示, 进而可以计算MMD的值如公式(9)所示[21 ] . ...
GloVe: Global Vectors for Word Representation
1
2014
... 使用GloVe(Global Vectors for Word Representation)实现对Tweet文本的词嵌入建模.GloVe是Pennington等[22 ] 提出的一种无监督词嵌入技术.相较于Word2Vec模型, GloVe通过加入全局的共现矩阵(Co-occurrence Matrix)信息, 有效解决了过于依赖局部信息、多义词处理乏力等问题, 适合Twitter这类短文本[23 ] . ...
False Rumors Detection on Sina Weibo by Propagation Structures
1
2015
... 使用GloVe(Global Vectors for Word Representation)实现对Tweet文本的词嵌入建模.GloVe是Pennington等[22 ] 提出的一种无监督词嵌入技术.相较于Word2Vec模型, GloVe通过加入全局的共现矩阵(Co-occurrence Matrix)信息, 有效解决了过于依赖局部信息、多义词处理乏力等问题, 适合Twitter这类短文本[23 ] . ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}