




1 引 言
对于机构实体的名称规范方式主要包括制定标准规范名称著录、建设机构名称数据库以及编制机构名称规范文档。其中, 对机构进行层级划分的一个典型实践是万方数据公司开发的“机构多层级词表”, 其通过“用、代、属、分、族”的叙词表编制模型对机构进行分层处理[3]。对机构名称进行自动归类的算法主要包括基于规则的方法、基于统计的方法以及规则和统计相结合的方法[4]。基于规则的方法与特定领域高度相关, 通常要综合考虑机构名称的构词规则、语义上下文和语法特征, 没有良好的可移植性; 基于统计的算法依赖于标注语料和训练模型的质量。随着时间的变化, 新的机构名称不断出现, 机构名称的形式处于不断变化中, 相较之下标注语料具有明显的时滞性; 并且人工标注的语料与领域的相关性强, 不能适应通用性的机构实体命名识别。因此, 不同统计方法相结合以及规则与统计相结合的算法成为主流。
Wikidata是一个开放、协作编辑的知识库, 以条目为中心创建了类的层次结构, 类成员由属性Subclass of以及Instance of进行连接, 这样构建好的类目体系将条目类及其属性组成立体网络, 既实现对条目的明确识别区分, 又将条目之间的关系进行明确揭示, 便于机器实现语义层面理解。Wikidata机构实体数丰富, 更新速度快, 达到1 566 903个, 针对当前机构范畴树的缺乏, 本文旨在以Wikidata为机构数据作为来源, 按照一定的分类原则, 以代表机构实体的条目及相应的类型属性为核心构建一棵通用机构范畴树。通过构建机构层级体系的方式, 将机构实体进行有序集中, 对其类型属性进行系统描述, 对不同机构实体之间的关联关系进行清晰的揭示, 应对机构名称混乱、机构间关系模糊、机构信息资源无序繁琐等问题, 从而提升信息检索查准率和查全率, 提高知识组织和服务水平。然而, 在构建机构范畴树的过程中, 发现Wikidata机构树中有23个实例数目大于10 000的条目, 实例数目过多则将使类目的外延过大, 不能明确地指示及类分资源。为系统化机构名称层级体系, 对这一类型实例进行细分, 使其均衡分布在机构范畴树的各层[5]。
聚类是将物理或抽象对象集合按有关特性的相似程度进行分组的过程, 目的是使同一簇中对象的特性尽可能地相似, 而不同簇对象之间的差异尽可能地增大。在机构范畴树的编制过程中, 自动聚类技术可以辅助实现机构实例的自动抱团及类识别, 有效提高机构范畴树的构建效率。因此, 本文提出一种适用于Wikidata中机构实体的聚类算法, 从而完善机构范畴树的编制, 实现机构实体的有序集中。
2 机构实体的数据特点
2.1 机构类目范畴树的实例分布
Wikidata中的机构名以“Subclass of ”和“Instance of ”两个属性与顶级类“Organization”相关联。通过SPARQL查询对机构类(Organization)进行逐级类目的抽取。将这些抽取的条目按照各自的“Subclass of ”和“Instance of ”属性组织成树形结构, 构建机构类目范畴树。对机构的实例和子类进行统计分析可知, 机构类目范畴树中平均每个子类有203个实例。对比发现, 机构类目范畴树中各类目的实例数量分布很不均匀:
(1) 以Instance of属性与机构类目范畴树的顶级类Organization相连的实例数量高达29 897个;
(2) 包含机构各级子类的4 020个有效条目中, 实例数量为0的条目有1 181个, 占总条目数的29.4%, 其中1 063个无实例的条目处于机构数的最深一层;
(3) 这些实例分布在类目的各个层级, 其中实例分布于最深一层的条目有2 001个, 占49.8%;
(4) 实体的实例分布明显不均, 高达1 000个实例数的条目有134个, 如Business Enterprise的实例数已达110 394个, 具体如表1所示。
表1 机构类目范畴树中拥有不同实例数量条目的分布
| 实例数范围 | 相应条目数 |
|---|---|
| i=0 | 1 181 |
| 0<i≤10 | 1 474 |
| 10<i≤100 | 865 |
| 100<i≤1 000 | 366 |
| 1 000<i≤10 000 | 111 |
| i>10 000 | 23 |
类的实例集合一定程度上可以检验类目的实用程度, 实例数量过多表示类的外延过大, 不能正确类分资源。因此, 对实例进行聚类是十分必要的[3]。
2.2 Wikidata中机构实例的特点
在Wikidata中, 机构实体以基于语义的结构化数据的方式存储。以“Organization”为例, 机构实体的数据结构如图1所示。
图1
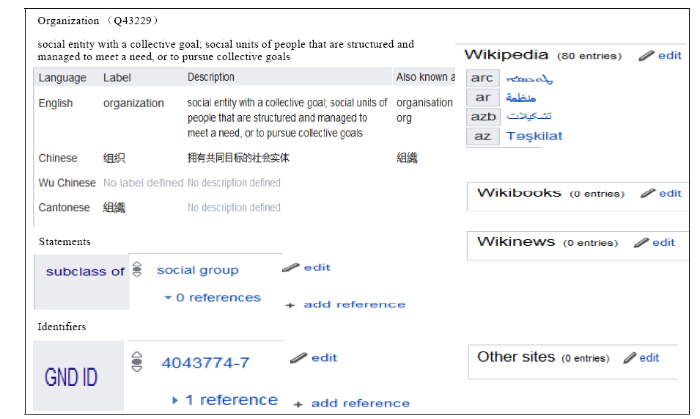
每个机构实体都有一个以“Q”开头的唯一标识符, 以及多语言标签(Labels)、多语言描述(Descriptions)、多语言别名(Aliases)、根据属性来分组的陈述(Statement)或声明(Claims)、与该实体相关的站点链接(Sitelinks)。其中, 多语言标签、描述、别名用来区分同名的条目, 描述换言之就是实体的定义, 对实体的内涵进行限定; 声明包含属性、属性值和限定符; 实体陈述是含有参考文献和排名的声明; 每个声明总是与一个属性相关联, 并且在一个实体陈述中可以有多条声明与同一属性相关联。与实体相关的网站链接将实体链接到Wikidata其他姊妹项目的页面, 如维基百科的相应词条界面。维基百科是一个动态、自由访问和编辑开放网站, 具有质量高、覆盖广、实时演化和半结构化等特点, 以网页形式发布, 每个网页对一个实体进行详细介绍, 页面主要由标题、文本信息、目录结构、信息盒、链接及分类等信息组成[6]。页面开头的第一段(称为摘要)是对机构实体概念的定义和基本描述, 对机构的类型、所属国家、创建时间、机构愿景、机构职能进行高度概括。
利用SPARQL查询语言从数据获取接口中抽取“Organization”的声明数据(语言为英语), 即机构实体拥有的属性以及相应的属性值, 随后, 利用Excel软件进行处理, 剔除无用属性, 得到机构应有的属性共计70个。可以将机构的属性归纳为如下三种:
(1) 机构的类型信息, 包括机构的上位类Subclass of、机构在其他维基项目中所属的分类如Commons Category以及诸如DBpedia等其他本体或知识库中机构的等价类。相应的属性值类型为文本。
(2) 机构的一些外部标识符, 如GND编号、国际标准名称标识符ISNI等, 多达32个。相对应的属性值多为由数字或字母组成的字符串, 如Intel的国际标准名称标识符为“0000 0001 0354 5207”; Intel的Freebase ID为“/m/03s7h”; Intel的Quora Topic ID(一种互动型问答知识库)为“Intel-company”。
(3) 适用于机构类实体的属性, 包括机构的所属国家、总部位置、创办者、成立时间、成立地点、法律形式、产业、所属组织、首席执行官、首席运营官、机构主管、职位、公司决策者、代言人、员工人数、产品、标志图像、宗旨、母语标签、拥有、业务部门、业务地区、可分为、母公司、子公司、分离自、官方网站、官方应用程序28个属性。其中, 员工人数的属性值类型为数值, 其余属性的属性值类型为字符串。
第一类属性提供了丰富的语义关系, 是构建机构范畴树的依据。第二类属性提供了外部标识符, 指向规范控制机构和数据源, 使得不同领域的标识符集中到一起, 促进数据的互联, 使用户获得更丰富的信息。第三类属性则从不同的方面对机构实体自身进行描述。从另一个角度来说, 第三类属性是前述维基百科中摘要的结构化形式。值得一提的是, 由于Wikidata是社区驱动的数据库, 机构实体的数据质量参差不齐, 并不是每个实体都包含上述三类属性。因此, 依据第一类属性组织而成的机构范畴树中, 不包含“Subclass of ”属性的机构实例的类识别就显得尤为重要。
聚类是一种无监督的学习, 适用于事先不知道其类标签的机构实例数据。基于以下假设: 主题相同或类似的不同文档, 往往有大量与主题相关的词汇同时出现。因此聚类算法对表征机构实体的文本(即算法的输入)十分敏感。加之, 机构实体名称通常是一个不超过5个词的短文本, 且机构名称几乎都包含机构性质或类型的特征词, 如大学、学院、研究所等。本研究中, 特征词共现对于机构实体的聚类来说是巨大的噪音。基于此, 选取Wikidata中机构实体的某些文本类型属性值作为机构实体名称的上下文环境, 构成一个语义更加丰富的文本, 从而减少特征词对机构实体聚类的影响。综上, 可以选取机构实体名称、机构实体的描述以及机构实体的第三类属性值表征机构实体。由于机构实体的第三类属性值在内容层面等价于维基百科中机构实体的摘要, 相较之下, 摘要更容易获取和处理, 因此采用摘要代替机构实体的第三类属性值。即, 机构实体表达如公式(1)所示。
其中, Org表示机构实体集, N表示机构实体的名称, D表示机构实体的描述, A表示摘要, 即机构实体集可以看作相同属性下不同属性值的一组记录。
3 机构实体的文本聚类方法
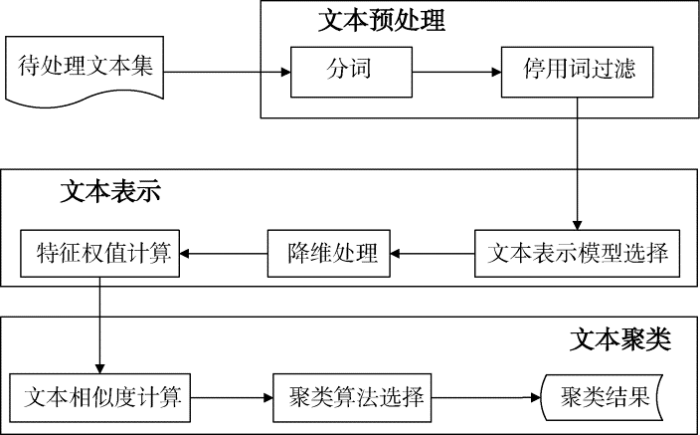
文本聚类是一种无监督的机器学习方法, 处理的数据是以自然语言形式存在的文本集, 由于文本数据的无结构化或半结构化特性, 其缺乏计算机可理解的语义信息, 因此需要将文本转换为能够被计算机处理的结构化形式, 即文本表示。对文本数据进行形式化表示之后, 可以运用聚类算法进行文本聚类分析。文本预处理、文本表示以及聚类分析方法的选择对于最终聚类结果起着关键性作用。文本聚类的操作流程如图2所示。
图2
3.1 文本表示方法的选择
文本表示是对文本数据进行数学建模的过程, 目的是将非结构化或半结构化文本转换为计算机可理解的结构化形式。文本表示通过文本中的特征词进行文本内容表达, 因此也称为文本特征表示, 它不仅需要准确反映文本的语义内容, 而且需要具备对不同主题文本的区分能力。文本表示主要包括文本表示模型选择、文本特征降维和特征加权三个步骤。
主题模型思想利用无监督的主题聚类模型对文本进行聚类。其中, 最具代表性的是Deerwester等提出的潜在语义索引(Latent Semantic Index, LSI)方法, 它是一种基于矩阵模型挖掘文本主题的思想, 不需要确定的语义编码, 仅依赖于上下文中词与词的联系, 并用语义结构表示词与文本, 达到简化文本向量的目 的[7]。使用线性代数对样本中的文本进行分析统计, 提取出词项-文档矩阵中潜在的语义结构, 从“字符匹配”向“概念匹配”转变。
潜在语义分析的关键在于利用奇异值分解(Singular Value Decomposition, SVD)的降维方法对文档的潜在结构(语义结构)进行挖掘。初始空间通过映射后成为的潜在语义空间是对空间向量的维度压缩, 空间向量通过奇异值分解将原来的空间基变换为新的空间基, 也就是将原本以单独词汇作为维度的空间向量转化为新的词汇向量, 新的词汇向量将每一维度视为一个潜在的语义, 成为潜在语义上的一个投影[8]。此方法的优点是可以在较低维的语义空间中进行相关性分析, 挖掘出隐含在文档中的语义相关性, 达到去除噪声和数据压缩等目的。传统的聚类方法比如层次聚类算法对于高维数据的效果是很差的。因为在高维度下距离的度量包含大量随机扰动的结果, 用LSI降维以后那些分量都会被过滤掉, 聚类效果将有所提高。因此, 本文采用潜在语义结构将待聚类的机构实体文档集表示为计算机可处理的形式, 然后用聚类算法对得到的矩阵进行聚类。
3.2 文本聚类算法的选择
常用的聚类算法有很多, 可以分为划分法、层次法、基于密度的方法、基于网格的方法、基于模型的方法。其中, 层次聚类法相对于其他几种聚类算法有如下的优点: 距离和相似度的规则容易定义, 限制少; 不需要预先给定聚类数; 可以发现类的层次关系。这些优势与本研究的目的相适应, 所以采用层次聚类 算法。
层次聚类根据自底向上和自顶向下可以分为两种: 凝聚型层次聚类法和分裂型层次聚类法, 文本聚类通常采用前者, 即开始时每个对象作为一个单独的簇, 根据算法定义的“簇的相似度”相继合并邻近的对象或簇, 直到所有的类合并为一个。本研究中, 初始的机构实体文档-词向量经过潜在语义索引的变换, 空间基发生变换, 但向量之间的夹角没有变化, 与此相适应, 选择余弦相似度作为“簇的相似度”度量标准。算法终止条件为两类合并为一类后, 合并后的类中所有项之间的平均距离最小。
3.3 文本聚类算法的评价指标
对聚类结果的分析和评价是判断一个文本聚类算法优劣的重要依据。常用的文本聚类结果评价方法主要分为两大类:外部聚类有效性和内部聚类有效性。外部聚类有效性要求数据集真实的分类数目和分类情况己知, 将聚类算法产生的结果与“真实”的结果进行比较, 评估其有效性, 常用指标有召回率、准确率等。当数据集真实的分类情况未知时[14], 使用内部聚类有效性评价。这种方法基于聚类的一般性目标进行聚类结果的评价, 即: 聚类结果须满足类簇中相似度较高而类簇间相似度较低的要求。比较典型是轮廓系数[15],该指标综合考虑簇的分离度和紧凑度两种因素, 值在-1和1之间变化, 簇的轮廓系数值越趋近于1, 表明该簇与其他簇中对象相异性越大, 同时表明分类结果越合理。除了作为评估聚类算法性能的指标, 轮廓系数还可以用于聚类数目的判断。本文通过计算待聚类数据集的平均轮廓系数值, 绘制关于聚类簇数与轮廓系数值的曲线图, 从而确定聚类的簇数, 以提高聚类效率。
4 聚类方法的实现与结果分析
4.1 实现流程
实现流程可以分为4个部分: 获取数据、数据预处理、构建潜在语义空间以及机构实体聚类。实现流程如图3所示。
图3
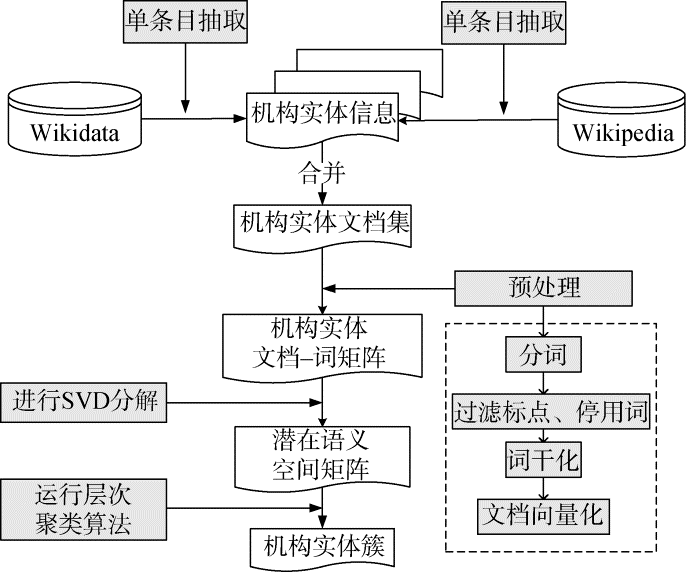
(1) 获取数据
选取机构实体的名称、描述属性以及维基百科中机构实体的首段摘要三个属性值作为表征机构实体的文本描述。利用SPARQL查询并导出Wikidata中机构类下没有“Subclass of ”属性的实例及其相应的属性和属性值, 然后添加Wikipedia中相应的首段描述作为机构实体的附加属性。所有实例及相应的三个属性值构成一个文档集存储, 每一行代表一个机构实例。选取其中500个机构实体作为机构实体数据集, 处理得到的机构实体数据集存储形式如表2所示。其中, Name是机构实体的名称, Description是机构实体的描述属性, Abstract of Wikipedia是机构实体在维基百科中的摘要。
表2 机构实体数据集存储形式示例表
| Name | Description | Abstract of Wikipedia |
|---|---|---|
| Academy of Fine Arts | Art society in India | The Academy of Fine Arts, in Kolkata (formerly Calcutta) is …[16] |
(2) 机构实体文档集的预处理
预处理主要包括分词、过滤无意义词汇、分词结果词干化和构建向量空间模型4个部分, 作为文本聚类的前提, 对聚类效果有重要影响。NLTK是Python语言中用于处理自然语言数据的领先平台, 它提供了超过50个语料库和词汇资源(如WordNet)简单易用的接口, 以及一整套文本处理库用于分词、词干化、标记、解析和语义推理, 在实践中获得广泛应用。本次实验引入NLTK库对文档进行预处理, 得到每个实体对应的词汇集。处理流程如下:
①文档单词小写化同时按照空格分词;
②引入NLTK的Word_tokenize函数, 分离标点符号与单词;
③利用NLTK提供的英文停用词表去除停用词;
④定义一个标点符号列表, 然后过滤这些标点符号;
⑤调用Lancaster Stemmer接口对过滤后的单词进行 分词;
⑥根据经验, 需要去掉词频为1的低频词, 以免对结果产生影响。
为表示文档中蕴含的潜在结构, 需要一种可以进行数学运算的表征文档的方法, 即经过上述处理的词汇集需转换为相应的向量空间模型。Python中的Gensim库提供了一个用于实现主题建模的可扩展的软件框架, 目前有效实现了几种流行的向量空间算法, 包括词袋模型(Bag-of-Word)、TF-IDF、分布式增量潜在语义分析、分布式增量隐含狄利克雷分配或随机预测[12]。构建向量空间模型的代码如下:
##引入gensim
from gensim import corpora, models, similarities
import os
from collections import defaultdict
import logging
logging.basicConfig(format='%(asctime)s : %(levelname) s: %(message)s', level=logging.INFO)
#构建词袋
dictionary = corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
#构建tfidf模型
tfidf = models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
#写入文件
tfoutfile=open("tfoutfile.txt","w")
for doc in corpus_tfidf:
tfoutfile.write(repr(doc))
tfoutfile.write("\n")
tfoutfile.close()
对上述词汇集抽取一个词袋, 即为预处理得到的每个词干分配一个唯一的ID, 该词典定义了处理器知晓的所有单词词表。根据词袋将机构实体文档集转换为一个向量列表, 即每个文档表示为由词典中出现的词及其权重组成的向量。此时, 词项权重采用的是位加权方案, 向量的长度是词典中词项的数量。词袋模型的一个主要特性是它完全忽略文档中所涉及单词出现的顺序, 这也是词袋这一名字的由来。由于词袋模型采用的位加权方案无法反映不同词项与文档之间关系的强弱[17], 为提升权重值对矩阵特征的指示作用, 需要采用TF-IDF加权方式计算词项权重。使用模型作为一个抽象术语, 描述把一个文档表示转换为另一种文档表示的行为。以词袋模型作为输入, 使其转换为“词频-逆文档频率”(Term Frequency - Inverse Document Frequency, TF-IDF)向量空间模型, 该向量空间模型中, 以文档集中每个单词稀缺性的权重替代单词出现的频率计数, 经过转换, 获得文档集的TF-IDF表示模型, 其规模为500×1631。该模型有1 631的维度, 且据统计, 其中只有10 738个非0元素, 需要对这样的高维稀疏矩阵进行降维以去除噪声实现数据压缩。
(3) 构建潜在语义空间模型
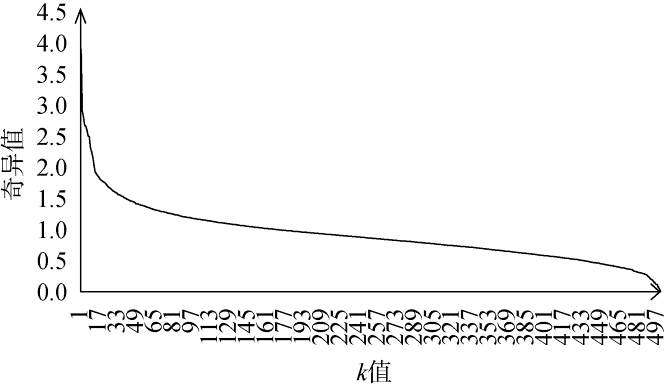
对TF-IDF向量组成的500×1631矩阵进行奇异值分解, 得到左奇异值矩阵u、右奇异值矩阵y和奇异值矩阵S, 为选取合适的截断值k, 对奇异值矩阵S对角线上的奇异值进行分析, 奇异值随k值增加的变化曲线如图4所示。可以看出, 奇异值随k值增大呈递减排列, 且奇异值减小的速度逐渐减小, 到k≈10这个点之后, 奇异值在一个很小的区间内变化, 因此认为k=10进行降维时得到的近似矩阵能够基本代表原始矩阵。
图4
利用Gensim库中的Lsimodel模型转换算法, 将4.1(2)的向量空间模型进行秩(即k)为10的降维处理, 对其进行重构, 得到相应的10维潜在语义空间模型。
(4) 运行层次聚类算法
以潜在语义空间模型作为输入, 计算机构实体间的余弦相似度, 对机构实体数据集中最为相似的两个机构实体进行组合, 并反复迭代这一过程, 两两组合的机构实体构成最底层聚类树; 然后计算组合之间的相似度, 并对相似度最高的机构实体组合进行合并。两个组合机构实体之间的相似度采用“组内平均链接”度量, 即计算两个组合中每个机构实体与其他所有机构实体的距离, 将所有距离的均值作为两个组合之间的距离。重复这个过程, 通过计算和对比, 合并不同组合中的机构实体, 自底向上, 每一步计算结果形成聚类树的一层[18]。
4.2 结果分析与评估
为验证本文所提聚类算法对机构实体聚类的有效性, 从两个方面进行评估: 一方面, 利用平均轮廓系数评估潜在语义索引对机构实体聚类的影响; 另一方面, 通过人工标注实验数据集, 计算准确率以评估聚类算法是否能够实现预期目标。
(1) 潜在语义分析对聚类的影响
为评估潜在语义索引对聚类结果的影响, 对比基于TF-IDF向量的层次聚类和基于潜在语义索引的层次聚类效果。采用平均轮廓系数这一指标进行比较。编写程序计算并绘制不同聚类数目下平均轮廓系数的变化折线图。
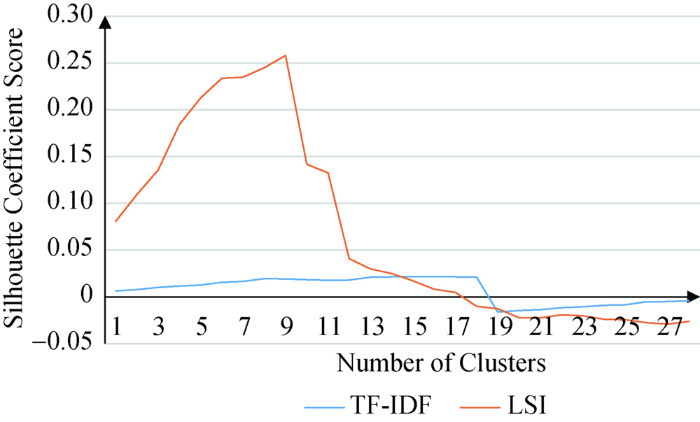
1 631维的TF-IDF向量空间模型, 数据的分布是极其稀疏的, 数据分布的稀疏导致高维空间中任意两个机构实体之间的相似度随着维度的增长而接近于一致, 相似度值往往较低以至于模糊了“类”的界限。由数据维度的增加引发的数据分析问题, 一般统称为“维度灾难”。根据图5可以看出, 聚类数目相同的情况下, 基于潜在语义索引的层次聚类平均轮廓系数要远远大于基于TF-IDF的层次聚类平均轮廓系数。可以认为, 通过潜在语义索引的降维, 可以解决困扰文本聚类问题的“维度灾难”问题, 提高聚类算法性能。
图5
(2) 聚类算法性能的评价
根据平均轮廓系数折线图, 发现聚类数目为2或10时, 平均轮廓系数值相当且达到峰值, 也就是说采用基于潜在语义分析的层次聚类方法时, 聚类数选择2或者10能够达到最好的聚类效果。然而全部数据聚为两类, 数据集仍未得到细分, 不符合预期目标, 因此选择10作为最终聚类的个数。以阈值为0.5对4.1节形成的聚类树进行切分, 得到最终聚类结果如表3所示。
表3 机构实体的聚类结果(示例)
| 类号 | 数量 | 机构 |
|---|---|---|
| 0 | 26 | Animal Aid; Animal Liberation; Animal Defenders International…… |
| 1 | 35 | International Society of Copier Artists; Lithuanian Artists' Association; Artists Union…… |
| 2 | 116 | Air Accident Investigation Bureau of Singapore; Air Accidents Investigation Institute; Airlines Electronic Engineering Committee…… |
| 3 | 76 | Medical Emergency Relief International; Medical Council of India; Center for Medical Progress…… |
| 4 | 55 | Academy of Labor and Social Relations; Academy of Labour Social Relations and Tourism; Academy of Innovation Management…… |
| 5 | 30 | Accreditation Council for Business Schools and Programs; Accreditation Service for International Colleges; Accreditation and Quality Assurance Commission…… |
| 6 | 33 | Financial Stability Board;Financial Stability Forum;Financial and Economic Committee…… |
| 7 | 53 | Women Food and Agriculture Network; Women Involved in Nurturing, Giving, Sharing; Women's Armed Services Integration Act…… |
| 8 | 62 | National Student Film Association; National Student Lobby; Students Offering Support…… |
| 9 | 14 | Accounting Professional & Ethical Standards Board; Accounting Standards Board; Educational Foundation for Women in Accounting…… |
为检验聚类效果是否符合预期目标, 对机构实体数据集进行人工标注。一个机构实体数据集中500个机构实体, 构成124 750个机构实体对, 以人工标注结果作为自动聚类的参照, 这些机构实体对可以分为4种类型, 具体类型和数量如表4所示。
表4 机构实体自动聚类和手工聚类的4种情况
| 手工聚类中 属于同一类 | 自动聚类中 属于同一类 | 标识 | 数量(个) |
|---|---|---|---|
| 是 | 是 | TP | 15 096 |
| 否 | 否 | TN | 99 612 |
| 否 | 是 | FP | 3 634 |
| 是 | 否 | FN | 6 408 |
采用Alahakoon等[19]提出的方法定义准确率P, 该指标综合考虑聚类算法的积极准确率和消极准确率, 其计算方法如公式(2)所示。
经过计算, 基于潜在语义索引的层次聚类算法准确率达87.3%, 其中积极准确率为80.6%, 消极准确率为94.0%, 消极准确率高于积极准确率, 表明实验采用的算法在正确区分不同类机构实体方面的性能更佳。
为进一步验证潜在语义索引算法在机构实体聚类中的性能, 在相同实验环境下, 采用另一种主题模型——隐含狄利克雷分布(Latent Dirichlet Allocation, LDA)作为文本表示方法, 采用层次聚类法作为聚类方法, 实现机构实体的聚类。结果显示, 同等条件下, 基于隐含狄利克雷分布的层次聚类算法准确率为50.5%, 其中积极准确率为15.1%, 而消极准确率却高达85.9%。即, 基于隐含狄利克雷分布的层次聚类算法不能有效地识别同类机构实体。两算法相比之下, 基于潜在语义索引的层次聚类算法在识别同类机构实体和区分非同类机构实体方面具有明显的优越性。
当然, 基于潜在语义索引的层次聚类算法也有一些不足之处, 一方面, 潜在语义模型将每个词语映射为多维空间中的一个点, 可以高效地解决同义词问题, 却忽略了一词多义的情况, 同时奇异值分解存在计算复杂度高的问题, 在数据量增大的情况下对内存的要求也相应地增加。另一方面, 为保证聚类的效率, 层次方法通常是单向的, 即不对己经划分的决策回溯, 一旦成功划分簇, 该簇就不再被其他划分所考虑。基于此, 关于机构实体聚类算法的研究还有很大提升空间。
5 结 语
将维基百科中机构实体的摘要作为机构实例的上下文环境, 一方面丰富了机构实体的语义环境, 可以提高机构实体聚类的准确率; 另一方面可以减小机构实体名称中特征词共现对聚类的影响。以Wikidata中随机抽取的500个机构实例为数据源进行实验, 表明基于潜在语义索引的层次聚类方法在机构实体聚类方面是有效且可行的。分别以TF-IDF向量空间模型和潜在语义空间模型作为实验输入, 实验结果表明潜在语义索引有利于解决“维度灾难”问题, 提高聚类算法的性能。潜在语义索引无法表示一词多义的情况和层次聚类算法的单向性问题, 将作为后续改进算法的研究方向。
作者贡献声明
贾君枝: 提出研究思路, 设计研究框架, 论文修改、审阅及定稿;
叶壮壮: 收集、整理与分析资料, 执行与实施研究过程, 撰写 论文。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: 1092041743@qq.com。
[1] 叶壮壮. org-instances.csv. 实验数据集.
[2] 叶壮壮. 实例数量.xlsx. Wikidata机构类目范畴树中不同类的实例数量表.
[3] 叶壮壮. 奇异值分解.xlsx. 随k值增加奇异值的变化情况.
[4] 叶壮壮. 聚类结果.xlsx. 机构聚类结果.
[5] 叶壮壮. 轮廓系数.txt. 轮廓系数的计算和比较代码.
[6] 叶壮壮. 基于潜在语义索引的Wikidata机构实体聚类.txt. 基于潜在语义索引的机构实体聚类代码.
[7] 叶壮壮. 使用组内平均联接进行聚类的树状图.png. 使用组内平均联接进行聚类的树状图.
参考文献
科研实体唯一标识系统研究
[J].
Research on Identification Systems of Scientific Research Entity
[J].
中文机构名称规范库建设的实践与分析——以“中科院机构名称规范库”建设为例
[J].
The Practice and Analysis of the Construction of Chinese Institution Name Library ——“Institution Name Authority of Chinese Academy of Science” as Example
[J].
机构多层级词表的编制及在文献计量评价与科研绩效管理中的应用
[J].
The Compilation of Multi-Echelon Thesaurus of Organization Names and Its Application in the Document Measurement and Evaluation and in the Management of Achievements in Scientific Researches
[J].
一种基于词频统计的组织机构名识别方法
[J].
Organization Name Recognition Based on Word Frequency Statistics
[J].
基于Wikidata的机构类目范畴树构建与优化
[J].
Construction and Optimization of Organizational Category Tree Based on Wikidata
[J].
基于维基百科的语义Web搜索技术研究
[D].
Semantic Web Search Technology Based on Wikipedia
[D].
Indexing by Latent Semantic Analysis
[J].
基于向量空间的文本聚类方法与实现
[D].
Design and Implementation of Text Clustering Based on Vector Space Model
[D].
基于层次搜索的潜在语义索引方法研究
[J].
Latent Semantic Indexing Based on Level Search Scheme
[J].
一种支持轨迹大数据潜在语义相关性挖掘的谱聚类方法
[J].
DOI:10.3969/j.issn.0372-2112.2015.05.019
URL
Magsci
[本文引用: 1]

<p>针对交通管理优化和轨迹大数据挖掘的实际应用需求,本文提出了一种支持交通轨迹大数据潜在语义相关性挖掘的交通路网谱聚类方法(TSSC).首先研究了交通轨迹数据的向量空间建模方法,其次通过随机投影法快速提取大规模轨迹数据矩阵的特征信息并构建其低维语义子空间,然后基于语义子空间挖掘轨迹数据的潜在语义相关特性,在此基础上通过谱聚类方法实现了交通路网的快速聚类.通过本文提出的方法对总里程1400多万公里的实际交通轨迹数据进行实验分析表明,本方法可根据交通轨迹大数据的潜在语义相关性对交通路网进行快速的谱聚类处理,从而在复杂的交通路网间快速挖掘其潜在特性,为交通规划及其管理优化提供决策支持信息,同时也为时空大数据的聚类挖掘提供了一种新的解决方案.</p>
A Spectral Clustering Method for Big Trajectory Data Mining with Latent Semantic Correlation
[J].
DOI:10.3969/j.issn.0372-2112.2015.05.019
URL
Magsci
[本文引用: 1]
<p>针对交通管理优化和轨迹大数据挖掘的实际应用需求,本文提出了一种支持交通轨迹大数据潜在语义相关性挖掘的交通路网谱聚类方法(TSSC).首先研究了交通轨迹数据的向量空间建模方法,其次通过随机投影法快速提取大规模轨迹数据矩阵的特征信息并构建其低维语义子空间,然后基于语义子空间挖掘轨迹数据的潜在语义相关特性,在此基础上通过谱聚类方法实现了交通路网的快速聚类.通过本文提出的方法对总里程1400多万公里的实际交通轨迹数据进行实验分析表明,本方法可根据交通轨迹大数据的潜在语义相关性对交通路网进行快速的谱聚类处理,从而在复杂的交通路网间快速挖掘其潜在特性,为交通规划及其管理优化提供决策支持信息,同时也为时空大数据的聚类挖掘提供了一种新的解决方案.</p>
Fast Supervised Dimensionality Reduction Algorithm with Applications to Document Categorization & Retrieval
[C]//
Random Projection in Dimensionality Reduction: Applications to Image and Text Data
[C]//
基于并行计算的概率潜在语义分析算法研究
[J].
Research on Probability Latent Semantic Analysis Algorithm Based on Parallel Computing
[J].
高维数据的聚类方法研究与应用
[D].
Research on Clustering Methods for High Dimensional Data and Their Applications
[D].
Clustering Categorical Data Using Silhouette Coefficient as a Relocating Measure
[C]//
Software Framework for Topic Modelling with Large Corpora
[C]//
层次聚类的方法及应用
[J].
Hierarchical Clustering Method and Application
[J].
Dynamic Self-Organizing Maps with Controlled Growth for Knowledge Discovery
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}