1 引 言
伴随着Web 3.0与移动互联网的蓬勃发展, 互联网用户整体上对社交网络服务依存度较高。对于用户而言, 社交网络好友推荐服务可以有效地解决社交网络信息过载问题, 同时帮助用户拓展社交关系, 促进社交网络上基于共同兴趣、高度相似的虚拟社区的形成。对于SNS平台商而言, 社交网络好友推荐服务能够帮助用户拓展社交圈, 增强相似用户间高质量的沟通交流, 从而增加用户粘着度和留存率。
在海量信息中, 用户很难筛选出自己真正感兴趣的好友, 从而有效地建立社交关系。同时, 在好友推荐研究过程中, 冷启动和数据稀疏性问题没有得到很好的解决, 社交网络中存在的信任关系也没有被很好的利用。本文综合利用用户信息和社交网络拓扑结构信息, 深度挖掘用户间交互行为变化所反映的动态信任关系, 最终为社交用户做出更有效的好友推荐。
2 研究背景
国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐。基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法。基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响。社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友。许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣。Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习。汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐。混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐。在推荐领域, 数据稀疏性问题普遍存在。好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度。传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路。
在传统的电商推荐领域, 解决稀疏问题的方法主要有数据填充、矩阵分解技术和社会化网络推荐等。数据填充法利用模型预测数据, 与实际情况存在差距, 随着数据的增多, 数据填充的不准确性会逐渐累积, 也会对协同过滤的最后评分值产生影响, 以至推荐结果不准确[6 ] 。此外, 学者们还尝试借鉴一些更专业的数据处理方法解决稀疏性带来的不良影响。Sarwar等[7 ] 最早提出矩阵分解模型, 并将其与用户推荐系统结合, 但是在数学处理上步骤复杂, 计算量庞大。张彦龙[8 ] 提出一种将协同过滤算法和社会网络分析相结合的相似度计算方法, 缓解了由于项目评分矩阵稀疏造成相似度计算结果准确率低的问题。
(1) 将用户在社交平台和电商购物平台的评分信息相结合。但由于国内很多大型电商平台和社交平台定位都比较专一, 电商平台的社交性不高, 评分系统不完善, 且不同平台存在着兼容性和迁徙性差 等问题, 这种方法会导致推荐结果可信度差, 准确度不高。
(2) 利用聚类算法对系统中所有用户数据做预先处理, 使得最有可能成为好友的用户处于同一簇内, 降低用户数据稀疏性, 同时缩小推荐时的搜索范围[9 ] 。
(3) 借助用户间拓扑社交信息(转、赞、评、@)等, 模仿构造出一个User-User的评分矩阵。
考虑到人与人之间主观的信任关系很大程度上影响他们的交友决策, 学者们也不断提出一些新的信任评估方法以准确评估社交网络中节点之间的信任关系。在2004年, Massa等[10 ] 叙述了基于信任的推荐模型的基本思想, 以用户间的信任度替代相似度, 这种方法虽然能获得很高的召回率, 但是准确率比较低。Beth等[11 ] 提出在多条信任传播路径上选出一条最可信的路径作为推荐路径, 并计算该路径上的信任值作为用户间的间接信任度。但不足之处在于没有具体阐明可靠路径的选择依据。信任的动态性是信任评估和可信赖性预测的最大挑战[12 ] 。在1994年, Marsh[13 ] 就结合地位、重要程度、风险、能力等影响因素来计算信任度, 但受限于计算过程中的数据获取, 该计算模型一直没能充分展示出优势。
通过分析国内外研究现状, 笔者发现目前传统电商领域的推荐技术相对较成熟, 但社交网络上好友推荐因其推荐对象的特殊性和社交网络关系的引入, 虽可以借鉴传统电商领域推荐的相关技术方法, 但研究思路还存在不同。社交网络中存在大量用户社交行为和用户原创内容(User Generated Content, UGC), 这些数据可以用来更准确地推断用户偏好。在前人工作的基础上, 本文结合社交网络拓扑信息和用户信息, 在网络拓扑结构分析中深度挖掘用户间交互行为所反映的信任强度和动态的信任关系, 提出一种新的融合用户信息和动态信任关系的好友推荐方法。
3 研究框架与方法
图1
图1
基于用户聚类与动态交互信任关系的好友推荐方法研究框架
(1) 第一阶段主要是基于用户的性别、年龄和关键词属性为所有用户进行特征向量建模。
(2) 第二阶段进行基于改进的K-Prototypes算法的用户聚类。使用用户的历史交友性别偏好代替原始样本的性别属性值, 衡量样本和原型之间的距离。聚类可以预先将最有可能成为好友的用户聚为一个簇, 降低簇类信任关系的稀疏度。
(3) 在第三阶段进行初始状态下拓扑网络信任度的计算。在各个簇类, 借鉴微博社交网络上相邻用户间信任值度量模型, 同时考虑网络用户间的全局信任关系和点对点交互关系, 其中, 全局信任度由用户的粉丝数量、博文质量和粉丝关注比来衡量; 交互信任度由用户间转发、评论及@关系来衡量。
(4) 为刻画社交网络中信任关系的动态特征: 自适应性和时间衰减性, 在第四阶段引入三个动态信任调节因子: 信任奖励因子、信任惩罚因子和时间衰减因子。距离评估时间点间隔越短的交互行为影响越大, 并在时间窗格中对频繁互动的
(5) 在第五阶段融合全局信任度和动态的交互信任度, 计算得到动态综合信任度, 并基于此为目标用户推荐综合信任度最高的Top-N用户, 完成推荐。
4 研究过程
基于社交网络图的社交行为和关注行为为用户进行好友推荐, 是社交网络好友推荐的一种常用技术, 在个性化好友推荐服务中得到广泛应用。但是随着社交网络注册用户的爆炸性增长, 传统的推荐算法受制于整个网络中社交互动行为的高稀疏性, 严重影响了结果的准确率和可扩展性。因此本文基于用户信息进行建模, 将最有可能成为好友的用户先聚为一类, 在基于用户信息划分得到的簇类内, 从用户间拓扑网络信任关系入手, 综合全局信任关系和交互信任关系进行邻居查找并产生Top-N好友推荐列表。为进一步提升推荐效果, 在衡量用户间交互信任关系的时候, 深度挖掘用户交互行为变化所反映的动态交互信任关系, 创新性地引入三个动态信任调节因子以更好地刻画交互信任关系的动态性: 自适应性和时间衰减性, 完成更精确的好友推荐。
4.1 用户信息特征向量建模
为将更可能成为好友的用户通过预先聚类的方法聚为一簇, 方便用户之间进行交流协作, 需要基于用户信息进行特征向量建模。社交网络的好友关系通常是基于共同兴趣建立起来的, 而决定用户兴趣的因素往往可以归结为维数相对较少的一些要素, 如性别、年龄等[14 ] , 另外, 用户以往博文、转发和评论中频繁出现的关键词, 直观地反映了用户的兴趣所在, 可以在预测模型中表示用户特征, 因此用户可以表示为一组由不同要素构成的向量。
对于每一个用户u , 将用户历史发表、评论、转发过的文本进行抽取, 利用网络全用户文本内容所有的保留词构建一个词向量: ${{V}_{u}}=\{\{{{t}_{1}},{{w}_{1}}\},\{{{t}_{2}},{{w}_{2}}\},\cdots \}$, 其中, ${{t}_{i}}$是关键词, ${{w}_{i}}$是每个关键词对应的权重, 权重采用信息检索领域著名的TF-IDF公式[15 ] 进行计算, 如公式(1)所示。
(1) ${{w}_{i}}=TF({{t}_{i}})\times IDF({{t}_{i}})=\frac{fre{{q}_{iu}}}{fre{{q}_{u}}}\times \lg \frac{N}{{{n}_{i}}}$
其中, $fre{{q}_{iu}}$表示用户u 使用关键词ti 的频率, $fre{{q}_{u}}$代表用户u 使用过的所有单词的频率。$fre{{q}_{iu}}=0$时表示用户u 没有使用过关键词ti 。关键词ti 的逆文本词频$IDF({{t}_{i}})=\lg \frac{N}{{{n}_{i}}}$, N 表示用户总数, ni 为使用过关键词ti 的用户数。为消除量纲对聚类结果的影响, 对用户年龄使用极大-极小法做归一化, 如公式(2)所示。
(2) $y=\frac{x-\text{Min}(X)}{\mathrm{Max}(X)-\mathrm{Min}(X)}$
其中, x, y 分别表示转化前、后的值, $\mathrm{Min}(X)$、$Max(X)$分别表示样本中对应属性的最小值和最大值。
除年龄之外, 性别也是影响用户兴趣和交友的重要因素, 相比而言, 女性更关注美妆、时尚、母婴, 而男性则更关注电竞、球赛等。在微博上基于兴趣的网络社交中, 有共同关注点的用户更易成为好友。可分别用1(男性)、2(女性)和0(未知)对用户性别进行标识。这样, 每个用户可抽象为用年龄、性别和若干个关键词的属性值所表示的向量, 其中年龄和关键词权重均为数值型变量, 而性别为分类变量。用户特征向量矩阵如表1 所示。
4.2 基于改进K-Prototypes的用户聚类研究
本文基于K-Prototypes的混合属性聚类改进算法, 主要是为了提高聚类结果的准确性和可解释性, 针对K-Modes算法中的海明公式进行改进。
在改进的K-Prototypes算法中, 数值属性之间的相异度采用欧式距离表示, 样本${{X}_{i}}$和原型${{V}_{l}}$数值属性距离的计算如公式(3)所示, 其中${{x}_{iz}}$是第i 个对象${{X}_{i}}$的第z 维属性值, ${{V}_{lz}}$是第l 个对象${{V}_{l}}$的第z 维属性值。
(3) ${{d}_{1}}({{X}_{i}},{{V}_{l}})={{\sum\nolimits_{z=1}^{p}{\left\| {{x}_{iz}}-{{v}_{lz}} \right\|}}^{2}}$
在进行分类属性的距离衡量时, 根据TF-IDF公式, 定义用户历史交友性别偏好计算公式, 如公式(4)所示。
(4) $gd\text{ }\!\!\_\!\!\text{ }pre=\frac{{{n}_{i}}(gd)}{{{n}_{i}}}\times \lg (\frac{N}{N(gd)})$
其中, ${{n}_{i}}(gd)$表示该用户历史好友中性别为gd 的人数, ${{n}_{i}}$表示该用户的好友总数, $N$代表所有用户数, $N(gd)$是所有用户中性别为gd 的用户人数。
基于以上定义, 可以用样本历史交友性别偏好来衡量分类属性的相异度。使用用户历史交友偏好代表程度最高的性别值作为该对象新的分类属性值进行存储, 如公式(5)-公式(7)所示。
(5) $\delta ({{x}_{i(p+1)}},{{v}_{j(p+1)}})=\left\{ \begin{matrix} 1\ \ {{x}_{i(p+1)}}\ne {{v}_{j(p+1)}} \\ 0\ \ {{x}_{i(p+1)}}={{v}_{j(p+1)}} \\\end{matrix} \right.$
(6) ${{x}_{i(p+1)}}={{v}_{i(p+1)}}=gd\_pre$
(7) $\begin{matrix} & gd\text{ }\!\!\_\!\!\text{ }pre\in \\ & \left\{ \begin{matrix} & \underset{gd\in G}{\mathop{\max }}\,(\frac{{{n}_{i}}(gd)}{{{n}_{i}}}\times \lg (\frac{N}{N(gd)})), \\ & G\in \{0\text{(}unknown),1(male),2(female)\text{ }\!\!\}\!\!\text{ } \\ \end{matrix} \right\} \\ \end{matrix}$
由于只包含一个分类属性, 故改进的K-Prototypes算法中, 样本${{X}_{i}}$和原型${{V}_{l}}$的距离$d({{X}_{i}},{{V}_{l}})$定义如公式(8)所示, 其中, $\gamma $是分类属性的权重, 用来平衡不同类型的数据。
(8) $d({{X}_{i}},{{V}_{j}})=\sum\nolimits_{k=1}^{p}{{{\left\| {{x}_{ik}}-{{v}_{jk}} \right\|}^{2}}+\gamma \times \delta ({{x}_{i(p+1)}},{{v}_{j(p+1)}})}$
该算法的核心思想是每次迭代过程计算样本${{X}_{i}}\mathrm{(}i=1,\ 2,\ \cdot \cdot \cdot ,\ n\mathrm{)}$到各聚类集合$C=\{{{C}_{1}}\mathrm{,}\ {{C}_{2}}\mathrm{,}\ \cdot \cdot \cdot ,\ {{C}_{k}}\}$的距离, 选择最小距离, 将样本划分到该聚类簇中, 更新聚类集中原型变量, 包括数值属性平均值和分类属性值计数器两部分, 每次迭代后分类属性用基于频率的方法更新模式以使聚类代价函数$E(X,V)$达到最小, 函数定义如公式(9)所示。
(9) $E(X,V)=\sum\nolimits_{j=1}^{k}{\sum\nolimits_{i=1}^{n}{{{u}_{ij}}d({{X}_{i}},{{V}_{j}})}}$
$\left\{ \begin{matrix} & {{u}_{ij}}\in \left\{ 0,1 \right\}\ \ \ \ \ \ \ \ \ \ \ \ 1\le i\le n,1\le j\le k \\ & \sum\nolimits_{j=1}^{k}{{{u}_{ij}}=1\ \ \ \ \ \ \ \ \ 1\le i\le n} \\ & 0<\sum\nolimits_{i=1}^{n}{{{u}_{ij}}<n\ \ \ \ 1\le j\le k} \\ \end{matrix} \right.$
其中, ${{V}_{j}}$表示第$j$类的类原型, ${{u}_{ij}}$表示观测变量${{X}_{i}}$对聚类中心${{V}_{j}}$的隶属度, ${{u}_{ij}}$在经典数学领域取0或1二值, 当${{u}_{ij}}$为1时, 表示样本${{X}_{i}}$在类${{C}_{j}}$中, ${{u}_{ij}}$为0则表示${{X}_{i}}$不属于类${{C}_{j}}$。$d({{X}_{i}},{{V}_{j}})$表示${{X}_{i}}$与${{V}_{j}}$之间的距离。
基于改进K-Prototypes的用户聚类步骤如下。
①根据用户${{X}_{i}}$历史交友的性别数据, 利用公式(4)计算每个用户的交友性别偏好作为用户的分类属性值;
②给定聚类个数$k$, 任意选择$k$个样本作为初始原型$V=\{{{V}_{1}},\ {{V}_{2}},\ \cdots ,\ {{V}_{k}}\}$, 并设定分类属性权重值γ ;
③对于每个样本${{X}_{i}}\mathrm{(}i=1,\ 2,\ \cdots ,\ n\mathrm{)}$, 根据公式(5)-公式(8)计算其到各聚类原型的距离$d({{X}_{i}},{{V}_{j}})$, 根据距离最小原则, 每当有新的样本加入簇类时, 重新计算所有数值属性的均值, 并更新分类(交友性别偏好)属性值的计数器;
④根据簇内样本的数值型变量均值和分类属性中出现概率最高的属性值来重新计算该簇的原型;
⑤根据代价函数公式(9), 求每次迭代的目标函数值;
⑥重复步骤③-步骤⑤, 直到聚类结果趋于稳定, 前后两次迭代代价函数的变化值小于给定阈值。
通过改进K-Prototypes算法对推荐系统的用户进行预先聚类, 将性别、年龄、关键词属性维度相似的用户划分到相同簇中, 在减小邻居用户搜寻空间、有效降低计算量和复杂度的同时, 也能在一定程度上缓解数据稀疏性问题。
4.3 初始状态下拓扑网络信任度的计算
将社交网络中相邻用户间的关系划分为全局关系和交互关系, 全局关系用来表示用户在整个网络中的信誉值和影响力, 交互关系点对点地反映用户之间的互动行为。对应的信任则划分为全局信任度和交互信任度。其中, 对于全局信任度的计算, 使用用户的粉丝数量、博文质量和粉丝关注比这三个指标; 对于交互信任度的计算, 按照微博社交网络上特有的几种互动方式(@、转发、评论)进行分类, 并创新性地引入动态调节因子, 提出一种新的基于动态交互信任关系的社交网络好友推荐方法。
对于全局信任度的衡量, 借鉴尹光宇[16 ] 的研究方 法, 为提高指标的适用性, 在个别因素的权重比例上做了调整。
粉丝数量: NF (u )表示用户u 拥有的粉丝总数, NF (u )客观地反映了其他用户对该用户的认可度。
博文质量: TQ (u )代表用户u 历史发布的博文质量, 用来衡量一个人在社交网络中作为信息产生者或信息传播者所产生的内容的受欢迎程度。越多的人对该用户发表的微博进行评论和转发, 说明其在社交网络中越受欢迎, 该用户的信誉值也相对越高。因此, 一个用户的博文历史被转发次数越多, 代表这个人可以生产或传播越高质量的信息, 这一用户在全局关系中影响力越大。用两个参数对转发和评论行为进行权重调节。博文质量的计算方法如公式(10)所示。
(10) $TQ(u)=\frac{\varphi \times {{n}_{c}}+\psi \times {{n}_{f}}}{{{n}_{u}}}$
其中, $\varphi +\psi =1$, 且$0<\varphi <\psi <1$。${{n}_{u}}$表示用户u 历史发表的博文总数量, ${{n}_{c}}$表示博文被评论次数, ${{n}_{f}}$代表博文被转发次数。
粉丝关注比: R (u )表示用户u 的粉丝数和其关注的人数之比, 简称粉丝关注比, 用来衡量一个用户在社交网络中的社会地位。粉丝关注比的计算方法如公式(11)所示。
(11) $R(u)=\frac{fa(u)}{fo(u)}$
其中, $fa(u)$表示用户u 所拥有的粉丝数量, 相应地, $fo(u)$则表示用户u 关注列表中的人数。
用户在微博社交网络中的全局信任度TR 由粉丝数量、博文质量和粉丝关注比这三个因素来综合考量, 定义如公式(12)所示。
(12) $\begin{matrix} & TR=\alpha \times \frac{NF(u)-\mathrm{MIN}(NF)}{\mathrm{MAX}(NF)-\mathrm{MIN}(NF)}+ \\ & \ \ \ \ \ \ \ \beta \times \frac{TQ(u)-\mathrm{MIN}(TQ)}{\mathrm{MAX(}TQ\mathrm{)}-\mathrm{MIN(}TQ\mathrm{)}}+ \\ & \ \ \ \ \ \ \ \gamma \times \frac{R(u)-\mathrm{MIN}(R)}{\mathrm{MAX}(R)-MIN(R)} \\ \end{matrix}$
其中, $\alpha +\beta +\gamma =1$, 且$0\le \alpha ,\ \beta ,\ \gamma \le 1$。MAX(NF )、 MIN(NF )分别表示所有用户最大粉丝数量和最小粉丝数量, MAX(TQ )、 MIN(TQ )分别表示所有用户博文质量最大值和最小值, MAX(R )、 MIN(R )表示所有用户粉丝关注比最大值和最小值。为排除量纲的影响, 使用最大最小值归一法, 将每个因素对应的值映射到0和1区间。
不同于全局信任关系, 交互信任度是点对点的, 每个用户因交互对象的不同而有不同的交互信任度, 这有助于对用户进行个性化的好友推荐。微博社交网络中提供了@、评论、转发等多种交互方式, 且这些交互方式都是有向的, 可以很好地契合信任的非对称性特征。用户u 和用户v 之间的交互信任度计算方法如公式(13)所示。
(13) $\begin{matrix} & IR(u,\ v)=\lambda \times \frac{uv}{uALL}+\mu \times \frac{u评论v}{u评论ALL}+ \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \nu \times \frac{u转发v}{u转发ALL} \\ \end{matrix}$
其中, $\lambda $、$\mu $和$\nu $为相对权重, $\lambda +\mu +\nu =1$, 且$0\le \lambda ,\ \mu ,\ \nu \le 1$。“$uv$”表示用户u 使用“@”与用户v 的交互次数, “$uALL$”表示用户u 在初始状态下使用“@”与网络中所有用户的交互次数。同理, “$u评论v$”和“$u评论ALL$”, “$u转发v$”和“$u转发ALL$”分别代表用户u 使用评论或者转发的方式与用户v 或全体用户的交互次数。权重的分配是一个关键问题, 在实际使用中可以根据社交网络中各用户不同的使用习惯, 灵活地调整权重$\lambda $、$\mu $和$\nu $。在本实验中, 由于不便获取每个个体对这三种交互方式的使用习惯, 因此为$\lambda $、$\mu $和$\nu $赋予多数人认同的经验值。
4.4 动态信任因子调节下的交互信任度计算
如果一个人和另一个人之间存在很强的信任关系, 他们之间的交互行为应该是你来我往的, 并且相比于其他人而言, 此两个用户之间的交互频率明显高出许多, 对于长期的高频交互行为应在衡量交互信任度值时予以奖励。交互信任度的动态性变化表现在两个方面: 一是自适应性, 即信任随着交互正反馈行为缓慢增加, 随着交互负反馈行为而迅速衰减; 二是时间衰减性, 即对时间间隔越久的交互行为施加越大程度的衰减。本文创新性地引入三个动态信任调节因子: 时间衰减因子、信任奖励因子和信任惩罚因子来更新交互信任度值。
一个用户的时间和精力是有限的, 其在社交网络所有的行为也是有限的, 所以一个人更愿意这有限的交互行为对象都是自己非常信任的人。据此, 定义在${{t}_{i}}$时刻用户之间交互反馈得分${{S}_{i}}$: 用户u 和用户v 之间的交互行为在该时刻用户u 的所有交互行为中所占的比例, 用来衡量用户对历史交互体验的反馈。计算方法如公式(14)所示。
(14) ${{S}_{i}}=\frac{{{E}_{uv}}}{\mathop{\sum }_{l=1}^{n}{{E}_{u{{x}_{l}}}}}$
其中, ${{E}_{u{{x}_{l}}}}$代表在${{t}_{i}}$时刻用户u 和${{x}_{l}}$所有形式的交互行为, 计算方法如公式(15)所示。
(15) ${{E}_{u{{x}_{l}}}}=\lambda \times (u{{x}_{l}})+\mu \times (u评论{{x}_{l}})+\nu \times (u转发{{x}_{l}})$
根据对交互的正反馈和负反馈的描述, 可以得到: 若${{t}_{i}}$时刻的交互反馈得分${{S}_{i}}$不低于${{t}_{i-1}}$时刻, 即${{S}_{i}}-{{S}_{i-1}}\ge 0$, 则为交互的正反馈, 反之, ${{S}_{i}}-{{S}_{i-1}}<0$为负反馈。引入信任奖励因子(Reward Factor)${{\tau }^{r}}$和信任惩罚因子(Punishment Factor)${{\tau }^{p}}$, 对正反馈进行奖励, 对负反馈进行惩罚。两种因子的定义如公式(16)和公式(17)所示。
(16) ${{\tau }^{r}}=2\times \left| {{\sigma }_{i}} \right|\times {{S}_{i}}\times c_{i}^{r}$
(17) ${{\tau }^{p}}={{S}_{i}}\times {{2}^{\left| {{\sigma }_{i}} \right|\times c_{i}^{p}}}$
参考前一个时间窗格的反馈情况, 如果连续的两个时间窗格均为非负反馈, 则$c_{i}^{r}=c_{i}^{r}+1$, 如果连续两个时间窗格均为负反馈, 那么$c_{i}^{p}=c_{i}^{p}+1$。这里还需说明, $c_{i}^{r}$和$c_{i}^{p}$的初值均为1。${{\sigma }_{i}}$代表连续两个时间窗格交互反馈得分变化的斜率, ${{S}_{i}}$是第i 个时间窗格用户u 对用户v 的交互反馈得分。
将时间轴划分为若干个长度为${{t}_{0}}$的时间窗, 交互信任值每经过${{t}_{0}}$时间间隔便更新一次。若用户u 和对象v 在第i -1个时间窗格${{t}_{i-1}}$时刻的交互信任值为$I{{R}_{i-1}}$, 那么在信任奖励因子和信任惩罚因子调节下的${{t}_{i}}$时刻的交互信任度值计算方法如公式(18)所示。
(18) $I{{R}_{i}}=\left\{ \begin{matrix} I{{R}_{i-1}}+{{\tau }^{r}}{{S}_{i}}-{{S}_{i-1}}\ge 0 \\ I{{R}_{i-1}}-{{\tau }^{p}}{{S}_{i}}-{{S}_{i-1}}<0 \\\end{matrix} \right.$
${{\tau }^{p}}\gg {{\tau }^{r}}$, 由此看出, 奖励是线性增加的, 而惩罚是指数下降的, 连续的负反馈之下, 信任值迅速衰减, 可以很好地在推荐时剔除网络中的恶意攻击和虚假伪装用户。经过信任奖励因子和信任惩罚因子调节后的交互信任度值能体现当前时刻用户之间的信任关系。
越近发生的行为对于信任值的影响越大, 为更好地体现节点当前的行为特点, 优先选取距离当前时间最近的交互行为作为交互信任度值度量的凭证, 引入时间衰减因子$\delta $来遗忘过时的历史行为记录。
在同样大小的时间窗格下, 交互信任度每经过${{t}_{0}}$时间间隔便衰减一次。在信任奖励因子和信任惩罚因子调节的基础上, 经过时间衰减因子动态调整后的ti 时刻交互信任值$I{{R}_{i}}'$定义如公式(19)所示。
(19) $I{{R}_{i}}'=I{{R}_{i}}\times \delta$
其中, $\delta $为时间衰减因子, 距离交互信任度的评估时间间隔时间越久, 中间经过的时间窗格越多, 衰减幅度就应该越大。需要评估对象u 对目标节点v 的交互信任度时间为t , 且$t>{{t}_{i}}$, 衰减因子$\delta $定义如公式(20)所示。
(20) $\delta ={{e}^{-c\left| \frac{t-{{t}_{i}}}{{{t}_{0}}} \right|}}$
其中, $\left| \frac{t-{{t}_{i}}}{{{t}_{0}}} \right|$为对象从第i 个时间窗格${{t}_{i}}$时刻到评估时刻t 之间经过的时间窗格数; c 是衰减系数, 通过目标节点自身情况主观设定: c 的值越大, 时间衰减因子的值越小, 反之, 则时间衰减因子的值越大。$\delta $是一个$[0,1]$内的数值, 越靠近1, 对交互信任度的衰减程度就越小。引入时间衰减因子后, 信任模型能够充分体现出时间因素对交互信任度计算的影响, 及时调整以契合实际情况, 提高准确性。
将目标节点加入在线社交网络的时间${{t}_{s}}$和对节点间交互信任关系的评估时间t 分别作为时间轴的起始点, 划分为若干个长度为${{t}_{0}}$的时间窗, 交互信任度值每过${{t}_{0}}$更新一次。人为划分的用户交互时间节点示例如图2 所示。
图2
在每个时间窗格内的具体更新过程描述如下: 根据交互反馈情况的正负, 结合信任奖励因子${{\tau }^{r}}$和信任惩罚因子${{\tau }^{r}}$, 使用公式(18)调节交互信任度以体现交互信任关系的自适应动态性; 然后对其结果使用时间衰减因子进行调节, 对距离评估时间越长的交互信任度值施加越大的衰减效果。最终得到t 时刻由动态信任因子调节下的动态交互信任度$I{{R}_{i}}'$。
4.5 基于动态综合信任度的好友推荐
在拓扑社交网络中, 一个节点对另一个节点的信任, 一方面取决于这个对象在网络全局的信誉情况, 另一方面受两个节点之间点对点的历史交互体验的影响。融合全局信任度和经过动态信任因子调节的交互信任度, 计算最终的动态综合信任度(Dynamic Comprehensive Trust, DCT), 如公式(21)所示。
(21) $DCT=\eta \cdot TR+(1-\eta )\cdot IR'$
其中, $\eta $是引入的全局信任度和动态交互信任度的调和参数, $0\le \eta \le 1$。如果$\eta >0.5$, 表明在用户做好友选择的过程中, 对象的全局信任度更为重要; 如果$\eta <0.5$, 表明比起对象在全局的信任而言, 用户更注重和对象点对点交互所产生的信任。$\eta $的最终取值在训练集上通过实验调试得到。
在各个簇内, 按照动态综合信任度的高低进行 排序, 将排名前N的用户组成推荐列表呈现给目标 用户。
5 实验测试与分析
5.1 实验数据集
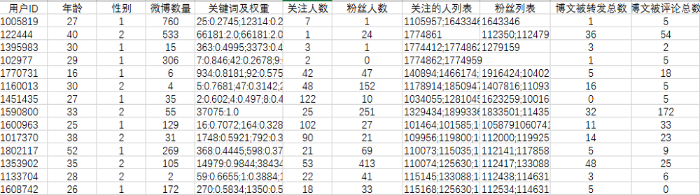
本实验使用腾讯微博提供的KDD CUP 2012比赛的真实数据集。该数据集规模庞大, 内容信息全面, 可以用来验证本文方法。数据集总共包含7个TXT文档, 本文用到其中5个文档: user_profile.txt、user_action.txt、user_sns.txt、user_key_word.txt和rec_log_ train.txt。从用户信息表中随机抽取5万条数据, 并筛选去除年龄小于5岁和大于67岁(笔者认为处于此年龄段的人群不具备社交网络的使用能力或使用习惯)、关注和被关注关系同时为空、关键词为乱码的数据, 最终得到34 731条数据。为防止过拟合以及方便后续对相关参数的调节, 从实验数据集中分割出2/3(23 154)作为训练数据, 1/3(11 577)作为测试数据, 测试集中隐藏用户的好友关系。最终部分样本数据展示如图3 所示。
图3
5.2 实验环境
本实验的硬件环境: CPU: Intel Core i5 3230M; 内存: 12GB; 硬盘: 700GB SSD。软件环境: 操作系统: Windows 8.1; 编程语言: Python 3.6; 数据库: SQL Server2012; 流程图: Visio 2016; 统计图表绘制工具: Matplotlib库; 社交网络可视化工具: Gephi 0.9.2。
5.3 评价指标
因为聚类过程是无监督的算法, 事先并不知道样本的正确分类, 并且也不存在这样的严格分类, 所以只能将“类内高聚合、类间低耦合”的原则作为指导思想, 采用聚类结果的平均畸变程度(Average Distortion, AD)衡量聚类结果的好坏。平均畸变程度计算的是每一个类各点到聚类中心的平均距离, 若类内部的成员彼此间越紧凑则类的畸变程度越小, 反之, 若类内部的成员彼此间越分散则类的畸变程度越大。AD指标的计算方法如公式(22)-公式(23)所示。
(22) $\overline{A{{D}_{l}}}=\frac{1}{{{\text{ }\!\!\Omega\!\!\text{ }}_{i}}}\sum\nolimits_{{{x}_{i}}\in {{\text{ }\!\!\Omega\!\!\text{ }}_{i}}}{\left\| {{x}_{i}}-{{w}_{i}} \right\|}$
(23) $AD=\frac{1}{K}\sum\nolimits_{k=1}^{K}{\overline{A{{D}_{l}}}}$
其中, 第i 个簇内共有${{n}_{i}}$个成员组成对象集合${{\mathrm{ }\!\!\Omega\!\!\text{ }}_{i}}$, ${{w}_{i}}$为该簇的聚类中心, $\left\| {{x}_{i}}-{{w}_{i}} \right\|$代表该类内每一个点到距离中心的距离, $\overline{A{{D}_{l}}}$代表第i 个簇的平均畸变程度, 整个网络最终被划分K 个簇, AD 值衡量了各个簇类平均畸变程度的均值。
Top-N推荐中常用的评价指标有准确率(Precision)、召回率(Recall)以及综合准确率和召回率的F1-Measure。
准确率定义是在为目标用户推荐的列表中, 正确推荐并被接受的用户所占的比例。召回率与准确率定义类似, 是正确推荐的好友数与系统中用户的好友数量的比例。准确率、召回率和$F1-Measure$定义如公式(24)-公式(26)所示。
(24) $Precision=\frac{\mathop{\sum }_{u}(R(u)\bigcap T(u))}{R(u)}$
(25) $Recall=\frac{\mathop{\sum }_{u}(R(u)\bigcap T(u))}{T(u)}$
(26) $F1-Measure=\frac{2\times Precision\times Recall}{Precision+Recall}$
其中, $R(u)$表示推荐系统给用户u 推荐的好友集合, $T(u)$表示在系统中用户u 感兴趣的好友集合。
5.4 参数确定
在本研究中, 分类型属性只有性别一维, 而数值型属性有年龄和关键词, 且关键词是一个高维变量, 因此他们的权重比不会超过1:2, 令$\gamma $=1/3。
对于聚类类别的选取, 使用“肘部法则”确定最佳k 值。随着k 值的增大, 每个类别包含的样本数会减少, 于是样本离其原型的距离势必会更近, 平均畸变程度呈下降趋势。但是, 伴随着k 值继续增大, 平均畸变程度的改善效果会不断减小, 因此, 对平均畸变程度改善效果最明显的k 值为最佳分类数。
(3) 全局信任度三个指标的权重系数$\alpha $、$\beta $和$\gamma $粉丝数量、博文质量和粉丝关注比三个指标共 同衡量用户的全局信任度, 因此为它们赋予相同的权值[16 ] , 即: $\alpha =\beta =\gamma =1/3$。
(4) 初始交互信任度和交互反馈得分计算公式中的权重系数$\lambda $、$\mu $和$\nu $
由于不便获取每个个体对这三种交互方式的使用习惯, 因此为$\lambda $、$\mu $和$\nu $赋予多数人认同的经验值, 一般地, 用户选择@行为与另一对象进行交互, 代表对目标更为信任, 令$\lambda =0.4$, $\mu =\nu =0.3$。
抽取的原始数据总共包含48天的用户行为, 在全样本中, 用户使用@、评论和转发行为与其他用户进行交互的次数在间隔时间为2天时, 平均变化率为1.22%, 4天时平均变化率达2.85%, 6天时平均变化率为3.34%。在权衡准确性和算法性能后, 令时间窗格${{t}_{0}}=4$, 在整个监测周期中将交互信任度更新6次。
时间衰减系数取值通常是一个大于1且小于10的整数, 在本实验中取c =3。
(7) 动态综合信任度计算中权重$\eta $的分配
用户之间动态综合信任度的计算由全局信任度和动态的交互信任度两部分构成, 平衡因子$\eta $用来调节这两部分权重, 取值范围为[0, 1]。当$\eta $取0时, 根据用户之间的交互信任度为每位用户生成个性化推荐列表; 当$\eta $取1时, 只根据用户在全局拥有的唯一信任度产生推荐, 且对不同用户的推荐结果相同。具体取值将由后续在训练集上的实验结果调试确定。
5.5 实验结果与分析
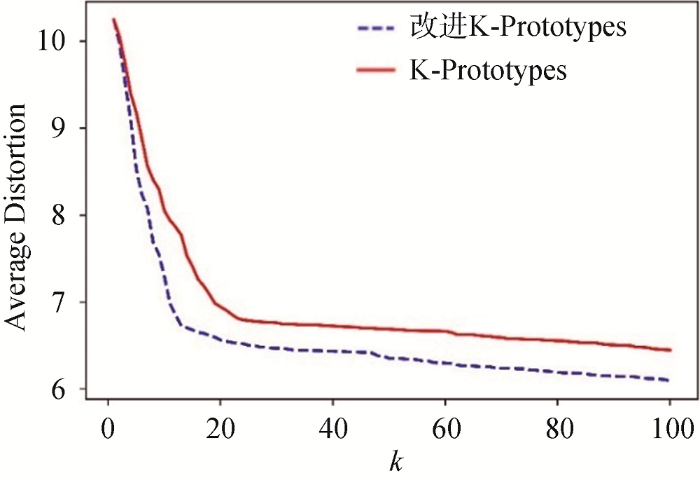
为对比改进的K-Prototypes算法与传统的K-Prototypes算法在聚类结果上的表现, 根据平均畸变程度AD这一指标, 使用改进的K-Prototypes算法和传统的K-Prototypes算法计算[1,100]各个k 值下对应的平均畸变程度AD, 结果如图4 所示。
图4
可以看出, 使用改进的K-Prototypes在各个k 值下计算得到的AD值均低于传统的K-Prototypes算法, 这就证明聚类得到的各个类更加紧密, 聚类效果更好。
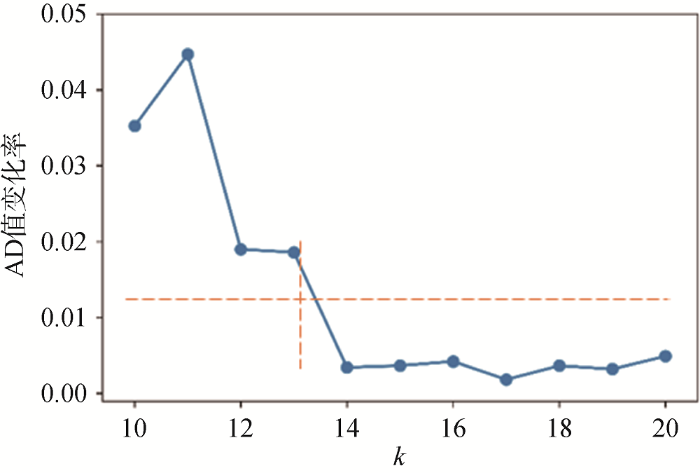
另外, 对于k 值的选择, 笔者尽量选择让AD值更小的k 值, 但这里不使用最小AD对应的k 值, 这是因为随着聚类类别的增加, AD值势必降低, 直至各为一类, 但这样显然失去了聚类的意义。选择“肘部法则”确定最佳分类数k , 即选择畸变程度改善效果下降幅度最大的位置对应的k 值(肘部)。笔者观察到在图4 中改进的K-Prototypes算法对应的蓝色虚线部分, “肘部”k 对应的数值应该在10-20之间, 为更精确地确定最佳分类数k , 进一步计算k 取10-20时对应的AD值变化斜率, 结果如图5 所示。
图5
从图5 中可以看出, k =13之前AD值变化斜率高于0.01, 而在k =13之后AD值变化的斜率明显低于0.01, 因此确定k =13为最佳分类簇数。最终, 基于改进的K-Prototypes算法将所有用户聚为13类。
在评估本文的方法之前, 需要首先通过实验确定调节全局信任度和交互信任度权重的参数$\eta $的大小。当$\eta $调整到一个适当的值时, 本文的方法在推荐结果的性能指标总体表现优良。以为用户推荐6人为准, 调整$\eta $从0到1每次增加0.1, 对应推荐结果的平均准确率、召回率和F1值绘制如图6 所示。通过图6 可以看出, $\eta $在区间[0.2, 0.4]有最优准确率; $\eta $在区间[0.3, 0.5]有最优召回率; 综合指标F1-Measure的最高值也在$\eta \in $[0.3, 0.5]时。综合来看, $\eta $取0.4时有最佳推荐结果。
图6
为更好地评价本文方法的推荐质量, 在腾讯微博数据上将本文算法与传统的基于共同好友比例为用户推荐好友的好友(Friend-of-a-Friend, FOAF)方法、在整个网络中融合拓扑社交关系和内容进行好友推荐(SNS+Content)的方法进行比较。社交网络在进行好友推荐时都不会一次推荐较多的用户[17 ] , 多数在10个以内, 因此在本文实验中为用户生成的推荐列表分别包含Top-2, Top-4, Top-6, Top-8, Top-10和Top-12这6种情况。本文方法和FOAF、SNS+Content在推荐准确率、召回率和F1-Measure上的变化曲线如图7 所示。
图7
图7
三种方法准确率、召回率、F1-Measure对比
①当推荐用户较少时, 三种方法的F1值随推荐数量增加而增加, 并且增速放缓逐渐趋于平稳;
②本文方法和SNS+Content方法的F1值明显优于FOAF方法, 这说明综合考虑社交网络和内容信息能够取得更好的推荐效果;
③综合准确率和F1值来看, 在推荐人数较多时, 本文方法在推荐性能的曲线上呈现下降趋势。这是由于本文方法为降低网络稀疏性, 预先将最有可能成为好友的用户聚类成簇, 并且在各个簇内进行推荐。当推荐数量比较少时, 可以准确且高效地将簇内信任对象进行推荐, 而当用户需要进一步扩展好友圈时, 可能不局限于本文预先基于用户信息所划分的簇类, 因此本文算法在推荐数量较多时性能下降, 准确率和F1值略低于在整个网络上进行大范围搜索的推荐方法。由于社交网络为了避免一次推荐较多好友而让用户产生选择疲劳, 通常一次推荐的好友数一般不超过10人, 可以看出, 本文方法生成的Top-9好友列表, 在准确率和F1值指标上均有优越的表现, 这说明在用户所属的簇或者说“好友候选集”上进行推荐是有意义的, 用户倾向于与同处一个“好友候选集”里的用户成为朋友。
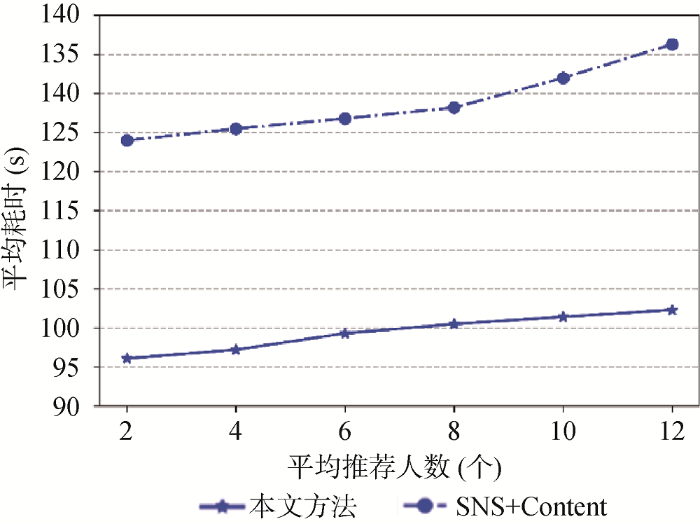
在不考虑前期基于用户信息发现相似簇耗时的情况下, 本文方法与融合社交网络信息和内容信息的推荐方法随推荐好友个数的增加所耗时的变化情况如图8 所示。可以看出: 在为一个特定用户推荐N个好友的情况下, 本文方法要比SNS+Content推荐方法消耗的时间更少。
图8
6 结 语
本文结合社交网络拓扑信息和用户信息, 在网络拓扑结构分析中深度挖掘用户间交互行为所反映的信任强度和动态的信任关系, 提出一种基于用户聚类与动态交互信任关系的好友推荐方法。利用公开数据集对本文方法进行比对验证, 基于性别、年龄和关键词信息进行用户建模, 使用改进的K-Prototypes聚类算法的分类型变量距离衡量公式, 实验结果表明改进的K-Prototypes得到的各个簇类更加紧密, 聚类效果更好; 且经过聚类后各个簇类的网络稀疏度和平均稀疏度优于整个网络的稀疏度。从全局信任度和交互信任度这两个维度计算能反映用户间信任强度的综合信任度。在时间窗格内动态调节用户间的交互信任度, 为目标用户推荐动态综合信任度最高的Top-N用户。在进行交互信任度的更新时首先引入三个动态信任调节因子: 信任奖励因子、信任惩罚因子和时间衰减因子, 综合调节时间窗格内的用户间的动态综合信任度。并依据此为目标用户产生Top-N推荐列表。
尽管本文在传统的社交网络好友推荐方法基础上进行了一些改进研究, 但仍然存在不足之处, 未来可以从以下方面继续开展工作:
(1) 基于观点挖掘和情感分析的用户信任度衡量方法。本文主要基于用户在拓扑网络中的一系列交互行为计算他们之间的信任度, 考虑到在线社会网络环境下的海量用户生成内容中包含丰富的用户评论观点和情感信息, 对这些文本语料的挖掘有助于从中发现用户之间更深层次基于观点和情感倾向一致的信任。未来笔者拟采用观点挖掘和情感分析方法研究基于内容文本挖掘的用户信任度衡量方法。
(2) 社交网络中群体信任关系的研究。本文提出的信任衡量模型暂未考虑到一对多、多对多的群体信任关系。人在社交网络中存在强烈的群体归属感, 交友的判断和选择也会受所属群体中其他成员的影响, 因此对群体信任的研究是一个非常有价值的课题。
作者贡献声明
高慧颖: 提供研究思路, 设计研究方案, 论文最终版本修订;
支撑数据
支撑数据由作者自存储, E-mail: huiying@bit.edu.cn。
[1] 魏甜. example_submission_1column_noheader.csv. 范例.
[2] 魏甜. track1.zip. 实验数据.
参考文献
View Option
[1]
Adamic L A Adar E . Friends and Neighbors on the Web
[J]. Social Networks , 2003 ,25 (3 ):211 -230 .
[本文引用: 1]
[2]
Colace F De Santo M Greco L , et al . A Collaborative User-Centered Framework for Recommending Items in Online Social Networks
[J]. Computers in Human Behavior , 2015 ,51 :694 -704 .
[本文引用: 1]
[3]
许超逸 , 李德玉 , 王素格 . 基于博文及网络结构信息的好友推荐方法
[J]. 计算机工程与应用 , 2016 ,52 (1 ):55 -60 .
Magsci
[本文引用: 1]
由于人们在书写用户属性信息时随意性和虚假性,使得在进行用户兴趣建模时用户属性无法得到有效利用。针对该问题,提出了一种基于兴趣偏好和网络结构的混合好友推荐方法。采用LDA主题模型对用户微博进行建模,从中挖掘用户兴趣,并依据同质性原理利用好友兴趣偏好对目标用户兴趣偏好进行修正。同时,采用一种新颖的基于网络结构的预测指标度量用户间的亲密程度。实验结果表明,与仅利用网络结构的推荐效果相比,加入用户兴趣后的模型在准确率及AUC指标上有显著提升,同时也可提高部分博文主题不明确用户的兴趣挖掘效果。
( Xu Chaoyi Li Deyu Wang Suge . Friend Recommendation Method Based on Micro-blogs and Network Structural Information
[J]. Computer Engineering and Applications , 2016 ,52 (1 ):55 -60 .)
Magsci
[本文引用: 1]
由于人们在书写用户属性信息时随意性和虚假性,使得在进行用户兴趣建模时用户属性无法得到有效利用。针对该问题,提出了一种基于兴趣偏好和网络结构的混合好友推荐方法。采用LDA主题模型对用户微博进行建模,从中挖掘用户兴趣,并依据同质性原理利用好友兴趣偏好对目标用户兴趣偏好进行修正。同时,采用一种新颖的基于网络结构的预测指标度量用户间的亲密程度。实验结果表明,与仅利用网络结构的推荐效果相比,加入用户兴趣后的模型在准确率及AUC指标上有显著提升,同时也可提高部分博文主题不明确用户的兴趣挖掘效果。
[4]
Makrehchi M . Social Link Recommendation by Learning Hidden Topics
[C]// Proceedings of the 5th ACM Conference on Recommender Systems. ACM , 2011 : 189 -196 .
[本文引用: 1]
[5]
汤颖 , 钟南江 , 范菁 . 一种结合用户评分信息的改进好友推荐算法
[J]. 计算机科学 , 2016 ,43 (9 ):111 -115 .
[本文引用: 1]
( Tang Ying Zhong Nanjiang Fan Jing . Improved Friends Recommendation Algorithm Combining with User Rating Information
[J]. Computer Science , 2016 ,43 (9 ):111 -115 .)
[本文引用: 1]
[6]
马宏伟 , 张光卫 , 李鹏 . 协同过滤推荐算法综述
[J]. 小型微型计算机系统 , 2009 ,30 (7 ):1282 -1288 .
[本文引用: 1]
( Ma Hongwei Zhang Guangwei Li Peng . Survey of Collaborative Filtering Algorithms
[J]. Journal of Chinese Computer Systems , 2009 ,30 (7 ):1282 -1288 .)
[本文引用: 1]
[7]
Sarwar B Karypis G Konstan J , et al . Application of Dimensionality Reduction in Recommender Systems—A Case Study
[C]// Proceedings of the 6th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2000 .
[本文引用: 1]
[8]
张彦龙 . 结合社会网络分析的协同过滤算法改进研究
[D]. 广州: 华南理工大学 , 2014 .
[本文引用: 1]
( Zhang Yanlong . Research on Improved Collaborative Filtering Algorithm with Combination of Social Network Analysis
[D]. Guangzhou: South China University of Technology , 2014 .)
[本文引用: 1]
[9]
何静 , 潘善亮 , 韩露 . 基于双边兴趣的社交网好友推荐方法研究
[J]. 计算机工程与应用 , 2015 ,51 (6 ):108 -113 .
Magsci
[本文引用: 1]
随着社交网的广泛流行,用户的数量也急剧增加,针对社交网络用户难以在海量用户环境中快速发现其可能感兴趣的潜在好友的问题,各种推荐算法应运而生,协同过滤算法便是其中最为成功的思想。然而目前的协同过滤算法普遍存在数据稀疏性和推荐精度低等问题,为此提出一种基于动态K-means聚类双边兴趣协同过滤好友推荐算法。该算法结合动态K-means算法对用户进行聚类以降低稀疏性,同时提出相似度可信值的概念调整相似度计算方法以提高相似度精度;利用调整后的相似度分别从用户的吸引与偏好两方面计算近邻用户集,综合考虑这两方面近邻对当前用户的择友影响来生成推荐列表。实验证明,相较于基于用户的协同过滤算法,该算法能有效提高系统的推荐精度与效率。
( He Jing Pan Shanliang Han Lu . Recommendation Algorithm of SNS Friends Based on Bilateral Interest
[J]. Computer Engineering and Applications , 2015 ,51 (6 ):108 -113 .)
Magsci
[本文引用: 1]
随着社交网的广泛流行,用户的数量也急剧增加,针对社交网络用户难以在海量用户环境中快速发现其可能感兴趣的潜在好友的问题,各种推荐算法应运而生,协同过滤算法便是其中最为成功的思想。然而目前的协同过滤算法普遍存在数据稀疏性和推荐精度低等问题,为此提出一种基于动态K-means聚类双边兴趣协同过滤好友推荐算法。该算法结合动态K-means算法对用户进行聚类以降低稀疏性,同时提出相似度可信值的概念调整相似度计算方法以提高相似度精度;利用调整后的相似度分别从用户的吸引与偏好两方面计算近邻用户集,综合考虑这两方面近邻对当前用户的择友影响来生成推荐列表。实验证明,相较于基于用户的协同过滤算法,该算法能有效提高系统的推荐精度与效率。
[10]
Massa P Avesani P . Trust-Aware Collaborative Filtering for Recommender Systems
[C]// Proceedings of the OTM Confederated International Conferences. 2004 : 492 -508 .
[本文引用: 1]
[11]
Beth T Borcherding M Klein B . Valuation of Trust in Open Networks
[C]// Proceedings of the 3rd European Symposium on Research in Computer Security. 1994 : 1 -18 .
[本文引用: 1]
[12]
Chang E Thomson P Dillon T , et al . The Fuzzy and Dynamic Nature of Trust
[C]// Proceedings of the 2005 International Conference on Trust, Privacy, and Security in Digital Business. 2005 : 161 -174 .
[本文引用: 1]
[13]
Marsh S P . Formalising Trust as a Computational Concept
[D]. Stirling: University of Stirling , 1994 .
[本文引用: 1]
[14]
蒋江涛 . 社交网络中基于地理位置特征的社团发现方法研究与实现
[D]. 北京: 北京航空航天大学 , 2014 .
[本文引用: 1]
( Jiang Jiangtao . Reasearch and Implementation of Community Detection Based on Geographical Feature for Social Networks
[D]. Beijing: Beihang University , 2014 .)
[本文引用: 1]
[15]
黄亮 , 杜永萍 . 基于信任关系的潜在好友推荐方法
[J]. 山东大学学报: 理学版 , 2013 ,48 (11 ):73 -79 .
[本文引用: 1]
( Huang Liang Du Yongping . The Method of Latent Friend Recommendation Based on the Trust Relations
[J]. Journal of Shandong University: Natural Science , 2013 ,48 (11 ):73 -79 .)
[本文引用: 1]
[16]
尹光宇 . 社交网络中用户间信任度量模型研究
[D]. 合肥: 中国科学技术大学 , 2013 .
[本文引用: 2]
( Yin Guangyu . Researches on Measurement Model for Trust Between Users in Social Networks
[D]. Hefei: University of Science and Technology of China , 2013 .)
[本文引用: 2]
[17]
张婷婷 . 基于社区发现的好友推荐方法研究
[D]. 沈阳: 辽宁大学 , 2016 .
[本文引用: 1]
( Zhang Tingting . Research on Friend Recommendation Based on Community Detection
[D]. Shenyang: Liaoning University , 2016 .)
[本文引用: 1]
Friends and Neighbors on the Web
1
2003
... 国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐.基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法.基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响.社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友.许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣.Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习.汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐.混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐.在推荐领域, 数据稀疏性问题普遍存在.好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度.传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路. ...
A Collaborative User-Centered Framework for Recommending Items in Online Social Networks
1
2015
... 国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐.基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法.基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响.社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友.许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣.Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习.汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐.混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐.在推荐领域, 数据稀疏性问题普遍存在.好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度.传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路. ...
基于博文及网络结构信息的好友推荐方法
1
2016
... 国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐.基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法.基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响.社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友.许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣.Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习.汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐.混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐.在推荐领域, 数据稀疏性问题普遍存在.好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度.传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路. ...
基于博文及网络结构信息的好友推荐方法
1
2016
... 国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐.基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法.基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响.社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友.许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣.Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习.汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐.混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐.在推荐领域, 数据稀疏性问题普遍存在.好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度.传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路. ...
Social Link Recommendation by Learning Hidden Topics
1
2011
... 国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐.基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法.基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响.社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友.许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣.Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习.汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐.混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐.在推荐领域, 数据稀疏性问题普遍存在.好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度.传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路. ...
一种结合用户评分信息的改进好友推荐算法
1
2016
... 国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐.基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法.基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响.社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友.许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣.Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习.汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐.混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐.在推荐领域, 数据稀疏性问题普遍存在.好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度.传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路. ...
一种结合用户评分信息的改进好友推荐算法
1
2016
... 国内外学者对于好友推荐的相关研究依据研究方法不同大致可以分为三类: 一是基于社交网络中的好友关系拓扑图进行推荐; 二是基于用户的信息进行推荐; 三是是综合利用用户信息和拓扑网络关系进行好友推荐.基于社交网络关系拓扑图模型进行好友推荐不需要考虑用户的信息, 将用户抽象为网络中的一个节点, 是社会化推荐中被广泛研究的方法.基于拓扑结构的传统推荐方法建立在“两个相同节点的邻居节点越多就越相似”的假设上, Adamic等[1 ] 在此基础进行改进, 根据节点的度为不同节点分配不同权重值, 以平衡节点的邻居节点数量带来的影响.社交网络中存在着海量用户信息可有效挖掘用户的潜在好友, Colace等[2 ] 基于用户浏览情况与发表日志高频词, 通过分析用户行为、偏好等发掘潜在好友.许超逸等[3 ] 用潜在狄利克雷分布主题模型从博文中挖掘用户兴趣.Makrehchi[4 ] 利用LDA主题模型对社交网络中节点属性信息进行学习.汤颖等[5 ] 则在用户社交网络拓扑结构相似度的基础上, 考虑基于对象评分的用户兴趣相似度, 最后结合拓扑相似度和兴趣相似度对目标用户进行好友推荐.混合的推荐方式虽然有多种组合, 但是在实际应用中并不一定都能实现理想的推荐.在推荐领域, 数据稀疏性问题普遍存在.好友推荐的数据矩阵稀疏主要来源于两个方面, 一是社交网络注册用户日益庞大, 用户间的共同好友少、互动频率低; 二是可获取的用户的数据信息有限, 如用户的历史浏览记录、兴趣标签、搜索关键词, 所以如何处理数据稀疏问题将会直接影响推荐系统的准确度.传统的电商推荐应用最广的技术是协同过滤, 虽然电商与好友推荐的稀疏矩阵具体涵指不全相同, 但传统电商领域较成熟的稀疏矩阵解决方法仍可为解决好友推荐的稀疏性问题提供思路. ...
协同过滤推荐算法综述
1
2009
... 在传统的电商推荐领域, 解决稀疏问题的方法主要有数据填充、矩阵分解技术和社会化网络推荐等.数据填充法利用模型预测数据, 与实际情况存在差距, 随着数据的增多, 数据填充的不准确性会逐渐累积, 也会对协同过滤的最后评分值产生影响, 以至推荐结果不准确[6 ] .此外, 学者们还尝试借鉴一些更专业的数据处理方法解决稀疏性带来的不良影响.Sarwar等[7 ] 最早提出矩阵分解模型, 并将其与用户推荐系统结合, 但是在数学处理上步骤复杂, 计算量庞大.张彦龙[8 ] 提出一种将协同过滤算法和社会网络分析相结合的相似度计算方法, 缓解了由于项目评分矩阵稀疏造成相似度计算结果准确率低的问题. ...
协同过滤推荐算法综述
1
2009
... 在传统的电商推荐领域, 解决稀疏问题的方法主要有数据填充、矩阵分解技术和社会化网络推荐等.数据填充法利用模型预测数据, 与实际情况存在差距, 随着数据的增多, 数据填充的不准确性会逐渐累积, 也会对协同过滤的最后评分值产生影响, 以至推荐结果不准确[6 ] .此外, 学者们还尝试借鉴一些更专业的数据处理方法解决稀疏性带来的不良影响.Sarwar等[7 ] 最早提出矩阵分解模型, 并将其与用户推荐系统结合, 但是在数学处理上步骤复杂, 计算量庞大.张彦龙[8 ] 提出一种将协同过滤算法和社会网络分析相结合的相似度计算方法, 缓解了由于项目评分矩阵稀疏造成相似度计算结果准确率低的问题. ...
Application of Dimensionality Reduction in Recommender Systems—A Case Study
1
2000
... 在传统的电商推荐领域, 解决稀疏问题的方法主要有数据填充、矩阵分解技术和社会化网络推荐等.数据填充法利用模型预测数据, 与实际情况存在差距, 随着数据的增多, 数据填充的不准确性会逐渐累积, 也会对协同过滤的最后评分值产生影响, 以至推荐结果不准确[6 ] .此外, 学者们还尝试借鉴一些更专业的数据处理方法解决稀疏性带来的不良影响.Sarwar等[7 ] 最早提出矩阵分解模型, 并将其与用户推荐系统结合, 但是在数学处理上步骤复杂, 计算量庞大.张彦龙[8 ] 提出一种将协同过滤算法和社会网络分析相结合的相似度计算方法, 缓解了由于项目评分矩阵稀疏造成相似度计算结果准确率低的问题. ...
结合社会网络分析的协同过滤算法改进研究
1
2014
... 在传统的电商推荐领域, 解决稀疏问题的方法主要有数据填充、矩阵分解技术和社会化网络推荐等.数据填充法利用模型预测数据, 与实际情况存在差距, 随着数据的增多, 数据填充的不准确性会逐渐累积, 也会对协同过滤的最后评分值产生影响, 以至推荐结果不准确[6 ] .此外, 学者们还尝试借鉴一些更专业的数据处理方法解决稀疏性带来的不良影响.Sarwar等[7 ] 最早提出矩阵分解模型, 并将其与用户推荐系统结合, 但是在数学处理上步骤复杂, 计算量庞大.张彦龙[8 ] 提出一种将协同过滤算法和社会网络分析相结合的相似度计算方法, 缓解了由于项目评分矩阵稀疏造成相似度计算结果准确率低的问题. ...
结合社会网络分析的协同过滤算法改进研究
1
2014
... 在传统的电商推荐领域, 解决稀疏问题的方法主要有数据填充、矩阵分解技术和社会化网络推荐等.数据填充法利用模型预测数据, 与实际情况存在差距, 随着数据的增多, 数据填充的不准确性会逐渐累积, 也会对协同过滤的最后评分值产生影响, 以至推荐结果不准确[6 ] .此外, 学者们还尝试借鉴一些更专业的数据处理方法解决稀疏性带来的不良影响.Sarwar等[7 ] 最早提出矩阵分解模型, 并将其与用户推荐系统结合, 但是在数学处理上步骤复杂, 计算量庞大.张彦龙[8 ] 提出一种将协同过滤算法和社会网络分析相结合的相似度计算方法, 缓解了由于项目评分矩阵稀疏造成相似度计算结果准确率低的问题. ...
基于双边兴趣的社交网好友推荐方法研究
1
2015
... (2) 利用聚类算法对系统中所有用户数据做预先处理, 使得最有可能成为好友的用户处于同一簇内, 降低用户数据稀疏性, 同时缩小推荐时的搜索范围[9 ] . ...
基于双边兴趣的社交网好友推荐方法研究
1
2015
... (2) 利用聚类算法对系统中所有用户数据做预先处理, 使得最有可能成为好友的用户处于同一簇内, 降低用户数据稀疏性, 同时缩小推荐时的搜索范围[9 ] . ...
Trust-Aware Collaborative Filtering for Recommender Systems
1
2004
... 考虑到人与人之间主观的信任关系很大程度上影响他们的交友决策, 学者们也不断提出一些新的信任评估方法以准确评估社交网络中节点之间的信任关系.在2004年, Massa等[10 ] 叙述了基于信任的推荐模型的基本思想, 以用户间的信任度替代相似度, 这种方法虽然能获得很高的召回率, 但是准确率比较低.Beth等[11 ] 提出在多条信任传播路径上选出一条最可信的路径作为推荐路径, 并计算该路径上的信任值作为用户间的间接信任度.但不足之处在于没有具体阐明可靠路径的选择依据.信任的动态性是信任评估和可信赖性预测的最大挑战[12 ] .在1994年, Marsh[13 ] 就结合地位、重要程度、风险、能力等影响因素来计算信任度, 但受限于计算过程中的数据获取, 该计算模型一直没能充分展示出优势. ...
Valuation of Trust in Open Networks
1
1994
... 考虑到人与人之间主观的信任关系很大程度上影响他们的交友决策, 学者们也不断提出一些新的信任评估方法以准确评估社交网络中节点之间的信任关系.在2004年, Massa等[10 ] 叙述了基于信任的推荐模型的基本思想, 以用户间的信任度替代相似度, 这种方法虽然能获得很高的召回率, 但是准确率比较低.Beth等[11 ] 提出在多条信任传播路径上选出一条最可信的路径作为推荐路径, 并计算该路径上的信任值作为用户间的间接信任度.但不足之处在于没有具体阐明可靠路径的选择依据.信任的动态性是信任评估和可信赖性预测的最大挑战[12 ] .在1994年, Marsh[13 ] 就结合地位、重要程度、风险、能力等影响因素来计算信任度, 但受限于计算过程中的数据获取, 该计算模型一直没能充分展示出优势. ...
The Fuzzy and Dynamic Nature of Trust
1
2005
... 考虑到人与人之间主观的信任关系很大程度上影响他们的交友决策, 学者们也不断提出一些新的信任评估方法以准确评估社交网络中节点之间的信任关系.在2004年, Massa等[10 ] 叙述了基于信任的推荐模型的基本思想, 以用户间的信任度替代相似度, 这种方法虽然能获得很高的召回率, 但是准确率比较低.Beth等[11 ] 提出在多条信任传播路径上选出一条最可信的路径作为推荐路径, 并计算该路径上的信任值作为用户间的间接信任度.但不足之处在于没有具体阐明可靠路径的选择依据.信任的动态性是信任评估和可信赖性预测的最大挑战[12 ] .在1994年, Marsh[13 ] 就结合地位、重要程度、风险、能力等影响因素来计算信任度, 但受限于计算过程中的数据获取, 该计算模型一直没能充分展示出优势. ...
Formalising Trust as a Computational Concept
1
1994
... 考虑到人与人之间主观的信任关系很大程度上影响他们的交友决策, 学者们也不断提出一些新的信任评估方法以准确评估社交网络中节点之间的信任关系.在2004年, Massa等[10 ] 叙述了基于信任的推荐模型的基本思想, 以用户间的信任度替代相似度, 这种方法虽然能获得很高的召回率, 但是准确率比较低.Beth等[11 ] 提出在多条信任传播路径上选出一条最可信的路径作为推荐路径, 并计算该路径上的信任值作为用户间的间接信任度.但不足之处在于没有具体阐明可靠路径的选择依据.信任的动态性是信任评估和可信赖性预测的最大挑战[12 ] .在1994年, Marsh[13 ] 就结合地位、重要程度、风险、能力等影响因素来计算信任度, 但受限于计算过程中的数据获取, 该计算模型一直没能充分展示出优势. ...
社交网络中基于地理位置特征的社团发现方法研究与实现
1
2014
... 为将更可能成为好友的用户通过预先聚类的方法聚为一簇, 方便用户之间进行交流协作, 需要基于用户信息进行特征向量建模.社交网络的好友关系通常是基于共同兴趣建立起来的, 而决定用户兴趣的因素往往可以归结为维数相对较少的一些要素, 如性别、年龄等[14 ] , 另外, 用户以往博文、转发和评论中频繁出现的关键词, 直观地反映了用户的兴趣所在, 可以在预测模型中表示用户特征, 因此用户可以表示为一组由不同要素构成的向量. ...
社交网络中基于地理位置特征的社团发现方法研究与实现
1
2014
... 为将更可能成为好友的用户通过预先聚类的方法聚为一簇, 方便用户之间进行交流协作, 需要基于用户信息进行特征向量建模.社交网络的好友关系通常是基于共同兴趣建立起来的, 而决定用户兴趣的因素往往可以归结为维数相对较少的一些要素, 如性别、年龄等[14 ] , 另外, 用户以往博文、转发和评论中频繁出现的关键词, 直观地反映了用户的兴趣所在, 可以在预测模型中表示用户特征, 因此用户可以表示为一组由不同要素构成的向量. ...
基于信任关系的潜在好友推荐方法
1
2013
... 对于每一个用户u , 将用户历史发表、评论、转发过的文本进行抽取, 利用网络全用户文本内容所有的保留词构建一个词向量: ${{V}_{u}}=\{\{{{t}_{1}},{{w}_{1}}\},\{{{t}_{2}},{{w}_{2}}\},\cdots \}$, 其中, ${{t}_{i}}$是关键词, ${{w}_{i}}$是每个关键词对应的权重, 权重采用信息检索领域著名的TF-IDF公式[15 ] 进行计算, 如公式(1)所示. ...
基于信任关系的潜在好友推荐方法
1
2013
... 对于每一个用户u , 将用户历史发表、评论、转发过的文本进行抽取, 利用网络全用户文本内容所有的保留词构建一个词向量: ${{V}_{u}}=\{\{{{t}_{1}},{{w}_{1}}\},\{{{t}_{2}},{{w}_{2}}\},\cdots \}$, 其中, ${{t}_{i}}$是关键词, ${{w}_{i}}$是每个关键词对应的权重, 权重采用信息检索领域著名的TF-IDF公式[15 ] 进行计算, 如公式(1)所示. ...
社交网络中用户间信任度量模型研究
2
2013
... 对于全局信任度的衡量, 借鉴尹光宇[16 ] 的研究方 法, 为提高指标的适用性, 在个别因素的权重比例上做了调整. ...
... (3) 全局信任度三个指标的权重系数$\alpha $、$\beta $和$\gamma $粉丝数量、博文质量和粉丝关注比三个指标共 同衡量用户的全局信任度, 因此为它们赋予相同的权值[16 ] , 即: $\alpha =\beta =\gamma =1/3$. ...
社交网络中用户间信任度量模型研究
2
2013
... 对于全局信任度的衡量, 借鉴尹光宇[16 ] 的研究方 法, 为提高指标的适用性, 在个别因素的权重比例上做了调整. ...
... (3) 全局信任度三个指标的权重系数$\alpha $、$\beta $和$\gamma $粉丝数量、博文质量和粉丝关注比三个指标共 同衡量用户的全局信任度, 因此为它们赋予相同的权值[16 ] , 即: $\alpha =\beta =\gamma =1/3$. ...
基于社区发现的好友推荐方法研究
1
2016
... 为更好地评价本文方法的推荐质量, 在腾讯微博数据上将本文算法与传统的基于共同好友比例为用户推荐好友的好友(Friend-of-a-Friend, FOAF)方法、在整个网络中融合拓扑社交关系和内容进行好友推荐(SNS+Content)的方法进行比较.社交网络在进行好友推荐时都不会一次推荐较多的用户[17 ] , 多数在10个以内, 因此在本文实验中为用户生成的推荐列表分别包含Top-2, Top-4, Top-6, Top-8, Top-10和Top-12这6种情况.本文方法和FOAF、SNS+Content在推荐准确率、召回率和F1-Measure上的变化曲线如图7 所示. ...
基于社区发现的好友推荐方法研究
1
2016
... 为更好地评价本文方法的推荐质量, 在腾讯微博数据上将本文算法与传统的基于共同好友比例为用户推荐好友的好友(Friend-of-a-Friend, FOAF)方法、在整个网络中融合拓扑社交关系和内容进行好友推荐(SNS+Content)的方法进行比较.社交网络在进行好友推荐时都不会一次推荐较多的用户[17 ] , 多数在10个以内, 因此在本文实验中为用户生成的推荐列表分别包含Top-2, Top-4, Top-6, Top-8, Top-10和Top-12这6种情况.本文方法和FOAF、SNS+Content在推荐准确率、召回率和F1-Measure上的变化曲线如图7 所示. ...












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}