
|
|

 , 李斌, Li Bin
, 李斌, Li Bin【目的】在数字人文这一背景下, 为更加深入和精准地从古代典籍中挖掘相应的知识, 通过实验对比分析, 探究不同词性标记集在典籍实体抽取上的差异性。【方法】基于已完成人工校验和机器自动标注的《左传》与《国语》构成的训练和测试语料, 以南京师范大学先秦词性标记集为主、以北京大学、中国科学院计算技术研究所和教育部词性标记集为辅, 共形成三种不同大小的新标记集, 通过条件随机场以及添加特征模板比较这三种词性标记集合在同一语料上进行实体抽取结果的差异性。【结果】在先秦典籍《左传》和《国语》上对不同大小的三种词性标记集开展对比实验, 三种模型各自进行实体抽取的F值分别达到82.53%、83.42%和84.07%。【局限】特征选取有待进一步改善, 训练结果还有提升空间。【结论】本文研究结果有助于先秦古文献命名实体的抽取, 所构建的词性标记集合适用于古汉语词性标注工作。
[Objective] In the context of digital humanities, in order to excavate the corresponding knowledge from the Pre-Qin literature more deeply and accurately, for different parts of the set of lexicon in the class of entity extraction model on the differences in the study. [Methods] Based on the training and testing corpora consisting of “Zuo Zhuan” and “Guo Yu” which have been manually labeled by the machine, three tagging sets of different sizes are formed, with the Pre-Qin part-of-speech tagging set of Nanjing normal university as the main part, supplemented by the part-of-speech tagging sets of Peking University, the Institute of Computing Technology of Chinese Academy of Sciences and the Ministry of Education. The differences between the results of the entity extraction on the same corpus were compared by using the conditional random field and the feature templates. [Results] Comparative experiments were carried out on three part-of-speech tagging sets of different sizes in the Pre-Qin classics “Zuo Zhuan” and “Guo Yu”. The F values of the three models were 82.53%, 83.42% and 84.07%, respectively. [Limitations] Feature selection needs further improvement, and training results can be improved. [Conclusions] The result is helpful for the extraction of the named entities in the ancient literature of the Pre-Qin period. The set of part-of-speech tags constructed is suitable for the part-of-speech tagging of ancient Chinese.
从20世纪50年代起, 自然语言处理就伴随着图灵机的提出而成为学者的关注对象。自然语言处理的研究范围主要包括: 机器翻译、自动分词、词性标注、语法解析、名词实体识别以及实体关系识别等。随着计算机技术的快速发展, 中文信息处理得到长足发展, 其中现代汉语文本信息处理已经取得丰富的成果[1,2], 但针对古代汉语文本信息处理的研究则相对较少。
古文信息处理研究相对滞后主要有三方面原因[3]。
(1) 古汉语文本的信息化程度较低。虽然国家已设立重大项目将古籍资料转换成电子版, 但仍有大量古籍没有完成数字化, 很多疑难汉字甚至都没有对应的计算机编码。
(2) 当前的社会生活中古汉语使用率低。在互联网时代, 很少有人在生活和工作中需要使用古汉语, 古文信息处理研究所能带来的商业价值较低, 因此缺乏吸引力。
(3) 古汉语研究与信息处理技术缺乏有机结合。大部分古汉语语言学家在信息技术方面有所欠缺, 另一方面从事古文信息处理的计算机工作者则亟需古汉语语言学家提供大量的语料库以及语言学角度下的知识和方法。
词性标注是自然语言处理的重要内容之一, 也是其他信息处理技术的基础。在各种自然语言处理过程中, 均有词性标注阶段。词性标注的正确率直接影响到后续的分析处理结果。因此, 词性标注一直是自然语言处理的重要内容。
在古汉语文本处理方面, 蒋建洪等结合基于词典分词法和基于统计分词法的优点, 将MMSEG分词算法和互信息算法应用于分词处理过程中, 得到的分词模型能够较好地解决分词速度和效率问题[4]。王嘉灵以《汉书》为语料, 对比三大类词表在分词上的效果, 发现注疏词表和专名词表是最优的分词词表组合[5]。石民等采用基于CRF的分词标注一体化方法, 与两步方法相比, 分词、标注性能均有明显提高, 开放测试的F值分别达到94.60%和89.65%[6]。留金腾等以《淮南子》为文本, 采用自动分词与词性标注并结合人工校正的方法构建语料库, 其中自动分词和标注过程使用领域适应方法优化标注模型, 在分词和词性标注上均显著提升了标注性能[7]。钱智勇等利用隐马尔可夫模型对《楚辞》进行自动分词标注实验, 通过比较分词后的标注词性概率, 取最大概率作为最后的分词和词性标注结果, 并在其中使用全切分和加值平滑算法。经过实验调整分词标注程序模块和参数, 最终得到一个分词标注辅助软件[8]。姜维等针对词性标注主要面临的兼类词消歧以及未知词标注的难题, 引入条件随机域建立词性标注模型, 易于融合新的特征, 并能解决标注偏置的问题, 此外还引入长距离特征有效地标注复杂兼类词, 以及应用后缀词与命名实体识别等方法提高未知词的标注精度[9]。张颖杰等采用《汉语大词典2.0》作为知识来源, 将其词条释义作为义类, 每个义项的例句作为训练语料, 使用基于支持向量机(Support Vector Machine, SVM)的半指导方法对《左传》进行全文词义标注, 提高古汉语语义标注的正确率[10]。
在命名实体抽取方面, 根据机器学习方法的不同, 可以分为无监督及有监督方法。有监督方法主要通过挖掘能表征命名实体的有用特征来提高抽取效果, 但是对于不同的数据集往往需要训练不同的参数。有监督方法中, 代表性的工作有Turney提出的GenEx[11]以及Frank等的KEA系统[12]。无监督方法一般利用文档词本身的统计信息实现命名实体的抽取, 适用范围广。无监督方法中目前的主流方法可归纳为三种: 基于TF-IDF统计特征的关键词抽取、基于主题模型的关键词抽取和基于词图模型的关键词抽取方法。其中词图模型又以TextRank算法为典型代表[13]。牛萍等针对候选词的选取, 提出一种连续单字未登录词识别和多词短语识别的方法, 改进TF-IDF公式, 将识别准确率提高了5%左右[14]。徐文海等提出一种基于向量空间模型和TF-IDF方法的中文关键词抽取算法, 用TF-IDF方法对文献空间中的每个词进行权重计算, 然后根据计算结果抽取关键词, 该算法对中文科技文献的关键词自动抽取成效显著[15]。李鹏等为提高网页关键词抽取质量, 提出利用社会化标签(Tag)进行关键词抽取的框架, 并给出一种具体的实现方法Tag-TextRank, 实验表明Tag-TextRank在各项评价指标上均优于经典的抽取方法TextRank[16]。谢玮等设计基于TextRank图算法思想的论文推荐系统, 通过加入词与词之间的影响力计算以及多文档集中逆文档频率IDF, 并基于余弦向量值对抽取出的关键词进行相似度匹配, 实现论文的推荐[17]。蒲梅等以新闻事件要素分析为基础, 利用TextRank算法对事件句构建关系图模型, 引入位置关系、句子相似度和关键词覆盖率三个影响因子, 提出一种新的新闻事件主题句提取算法, 其效果优于基于TF-IDF和Title的关键事件主题句抽取方法[18]。宁建飞等将Word2Vec与TextRank有效融合, 对TextRank算法进行改进, 文档集中的词关系有助于修正单文档内部的词关系, 提升单文档的关键词抽取准确性[19]。夏天基于TextRank基本思想, 构建候选关键词图, 计算词语之间的影响力概率转移矩阵, 通过迭代法实现候选关键词分值计算, 结果表明, 对词语未知加权的TextRank方法优于传统TextRank方法和基于LDA主题模型的关键词抽取方法[20]。魏赟等提出一种综合TF-IDF、TextRank、统计学知识抽取关键短语和利用候选关键短语逆文档频率排序的方法, 相比于经典TextRank模型, 该模型准确率、召回率和F值分别提高了2%、4.5%和3.4%[21]。
目前比较权威的词性标记集有南京师范大学先秦汉语词类标注基本集、北京大学汉语文本词性标记集、中国科学院计算技术研究所(简称“中科院计算所”)汉语词性标记集以及教育部出版的现代汉语词类标记规范。鉴于不同标记集对于典籍实体抽取结果有不同的影响, 本文以南京师范大学先秦汉语词类标注基本集为主, 通过其他版本词性标记集对其进行补充或合并, 形成不同大小的新的词性标记集。采用条件随机场模型对不同词性标记集标注后的语料进行实体抽取实验, 探究不同词性标记集合在典籍实体抽取上的差异性, 以找出性能较好的词性标记集。
具有语义知识特征的词性在整个古文信息处理过程中起着承上启下的重要作用。对于词来说, 词性让词汇具备不同的语义知识; 对于实体来说, 词性不仅是实体的重要构成部分而且决定了实体语义构成的基本模式。因此一个适合于古文信息处理的词性标记集在一定程度上对整个古文信息处理具有直接而重要的影响。鉴于此, 基于已有词性标记集, 针对古汉语文本特征, 本文制订古汉语词性标记集并通过具体实验验证。在制定这一标记集的过程中主要遵循如下原则。
(1) 严格遵循古汉语的语言规律和特征。虽然现代汉语是古汉语的延续, 但古汉语有其自身的特点和特征, 比如在动词上, 古汉语就有区别于现代汉语的活用动词, 对于这一类动词要单独成类。
(2) 全面贯彻句法功能一致的原则。结合词性这一概念的内涵与外延, 在制定古文词性标记集合过程中, 严格贯彻各类词性在句法功能上要一致的原则, 在这一原则下, 古文典籍中的数词和量词应该是一类词, 而不应该分成两个词类。
(3) 系统兼顾语义独立和完整。词性最为突出的一个特性就是有独立的语义内涵, 比如动词和名词在语义上就有极大的差异, 因此在制定古汉语词性标记集合的过程中, 除了考虑句法功能的相同性, 也要系统考虑语义的独立性。比如名词中的方位名词, 虽然在句法功能上与一般名词相同, 但在语义上有其独特之处, 因此对于这一类词汇应当设立一个词类。
在上述原则和规范的基础上, 本文以南京师范大学先秦汉语词类标注基本集为主, 以北京大学、中科院计算所和教育部词性标记集为辅, 共形成三种不同大小的新标记集。为检验所制定词性标记集的科学性与合理性, 通过实体识别任务对三个词性标记集进行验证。
南京师范大学先秦汉语词类标注基本集中共包含普通名词(n)、人名(nr)、地名(ns)、方位名词(f)、时间名词(t)、动词(v)、使动用法(sv)、意动用法(yv)、为动用法(wv)、形容词(a)、数词(m)、量词(q)、代词(r)、介词(p)、连词(c)、助词(u)、副词(d)、语气词(y)、拟声词(s)、兼词(j)、标点(w)这21种词性。标记集1根据北京大学、中科院计算所和教育部对动词的分类, 将南京师范大学先秦标记集中的使动用法(sv)、意动用法(yv)、为动用法(wv)合并为一类, 并称为古代动词, 用符号gv表示。
标记集2和标记集3都是在标记集1的基础上再次对部分词性进行修改产生的。古汉语中需要识别的命名实体主要包括人名、地名、时间名词这三类, 借鉴教育部的词类标记规范中对名词的定义, 且方位名词在语料中所占比例较少, 将方位名词(f)归入普通名词(n)形成标记集2, 名词大类下就分为普通名词、人名、地名和时间名词。又根据中科院计算所汉语词性标记集中对数量词的界定, 在标记集1的基础上将南京师范大学标记集中的数词(m)和量词(q)合并为数量词, 形成标记集3, 实验所用语料《左传》中数词(m)共1 298个, 量词(q)共100个, 《国语》中数词(m)共957个, 量词(q)共38个, 因此将二者合并为数量词后用数量较多的符号m表示。
各标记集下的词性分类情况如表1所示, 其中标记集1共包含19种词性, 标记集2和标记集3都包含18种词性, 后续实验均以此三种标记集为基础展开。
(1) 语料简介
《左传》是春秋末年鲁国的左丘明为《春秋》做注解的一部史书, 与《公羊传》、《谷梁传》合称“春秋三传”。是中国第一部叙事详细的编年体史书, 共35卷, 记述范围从公元前722年(鲁隐公元年)至公元前468年(鲁哀公二十七年), 也是儒家经典之一, 且为十三经中篇幅最长的。篇幅约23万字, 是先秦传世文献中单本字最多的文献, 非常适合用来作为机器学习的对象, 服务于先秦其他文献的自动标注。《国语》又名《春秋外传》, 是中国最早的一部国别体著作。记录范围上起周穆王十二年(公元前990年)西征犬戎(约公元前947年), 下至智伯被灭(公元前453年), 包括各国贵族间朝聘、宴飨、讽谏、辩说、应对之辞以及部分历史事件与传说。
南京师范大学语言科技研究所构建了目前国内最大规模的先秦典籍人工语料库, 共包括25种比较重要和可靠的先秦传世文献, 达到了分词和词性标注的级别。本文选取先秦语料库中的《左传》语料进行实体内外部特征统计, 并按照条件随机场的要求形成特征模板, 对《左传》语料进行特征学习, 从中建立古汉语实体抽取模型。最后, 在经过人工校验和机器自动标注的《国语》上进行古汉语实体抽取实验。根据MUC(Message Understanding Conference)的定义, 命名实体有人名、地名、机构名、日期、时间、百分数、货币这7类[22], 再结合南京师范大学版词性标记集中的词性分类, 本文将要抽取的实体定为人名、地名和时间名词三类, 在标记集中分别用“nr”、“ns”和“t”表示。
《左传》和《国语》中出现的实体数量如表2所示。《左传》中人名、地名、时间名词分别占实体总数的56.78%、33.31%、9.91%; 《国语》中人名、地名、时间名词分别占实体总数的60.74%、29.78%、9.48%, 可以看出人名在两者中都占绝大多数, 其次是地名, 最少的是时间名词。
(2) 特征统计
实体的长度分布情况不仅决定条件随机场模型的词位数量, 还决定模型的序列跨度。基于《左传》和《国语》的实体进行长度统计如表3所示, 结果表明两种语料中人名实体都是长度为2的出现频次最高, 其次是长度为1或3的, 长度为4或5的基本很少; 地名实体都是长度为1的出现频次最高, 其次是长度为2的, 长度为3或4或5的基本上是个例; 而时间名词在《左传》中长度为2的频次最高, 主要是“己丑”“甲午”“八月”“二年”这类两字词的时间名词, 《国语》中长度为1的频次最高, 主要是“今”“昔”“古”这类单字时间名词。
实体词左右高频邻接词的词性分布具体情况如表4所示。可以看出, 左边界词中动词占绝大多数, 而右边界词则主要集中在虚词上, 从训练特征的选取上考虑, 虚词在实体自动抽取过程中起到非常重要的节点作用, 本文将以“p、c、d、u”为词性标记的词性作为一个特征添加到实体抽取条件随机场训练的模板中, 并统一标注为“Y”, 不属于这几类词性的标注为“N”。
基于实体内外部特征的统计情况以及本文探究不同词性标记集合在典籍实体抽取上差异性的目的, 语料标注样例如表5所示。
(1) CRFs模型概述
条件随机场模型(Conditional Random Fields, CRFs)是Lafferty等在最大熵模型和隐马尔可夫模型的基础上提出的一种无向图学习模型, 是一种用于标注和切分有序数据的条件概率模型[23]。给定一组数据序列随机变量X, CRFs根据标注结果序列的随机变量Y给出条件概率分布P(Y|X), 通过训练以使条件概率P(Y|X)最大。CRFs最简单的形式是线性CRFs, 其中各节点间可以形成线性结构。线性CRFs对应一个有限的状态机, 适用于线性数据序列的标注。本文默认使用的CRFs为线性CRFs。
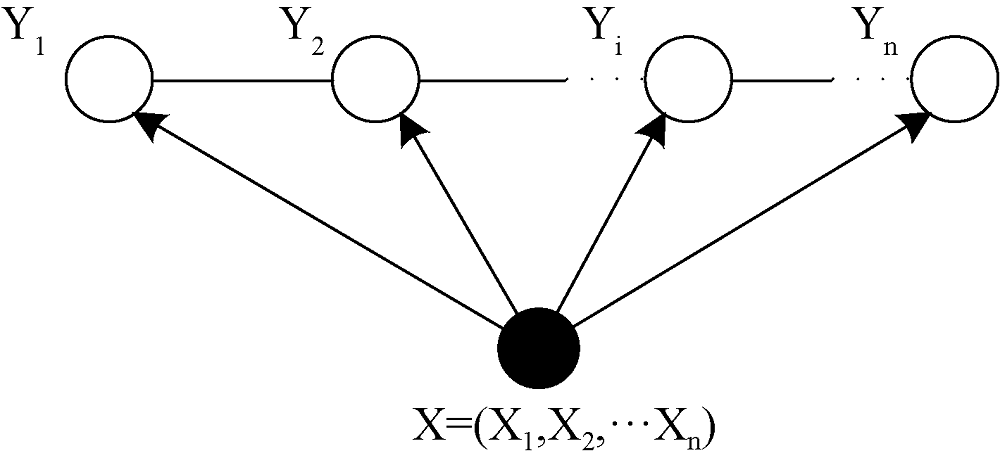
无向图模型亦称为马尔可夫随机场或马尔可夫网络, 由Pearl提出[24]。无向图G(V,E)表示概率分布, 其中V是节点, 表示随机变量; E是边, 表示随机变量之间的依赖关系。设v∈V是无向图G中的任意一个节点, W是与v有边连接的所有节点, 随机变量Yv对应于v, 随机变量YW对应于W。若由随机变量Y构成一个可以用G(V,E)表示的马尔可夫随机场, 即$\text{P}({{Y}_{\text{v}}}|X,{{Y}_{\text{W}}},W\ne v)=P({{Y}_{\text{v}}}|X,{{Y}_{\text{W}}},W\sim v)$, 对任意节点v成立, 则条件概率分布P(Y|X)为条件随机场。其中, W~v表示图G中与节点v有边连接的所有节点W, W≠v表示节点v以外的所有节点。Yv和YW为节点。
若$\text{P(}{{\text{Y}}_{\text{i}}}\text{ }\!\!|\!\!\text{ X,}{{\text{Y}}_{\text{1}}}\text{,}\cdot \cdot \cdot \text{,}{{\text{Y}}_{\text{i-1}}}\text{,}{{\text{Y}}_{\text{i+1}}}\text{,}\cdot \cdot \cdot \text{,}{{\text{Y}}_{\text{n}}}\text{)=P(}{{\text{Y}}_{\text{i}}}\text{ }\!\!|\!\!\text{ X,}{{\text{Y}}_{\text{i-1}}}\text{,}{{\text{Y}}_{\text{i+1}}}\text{)}$, 则P(Y|X)为条件随机场(线性链条件随机场), 如图1所示。
(2) CRFs模型的优点
条件随机场在应用中具有两个优点。一是对观测值不存在严格的独立性假设, 观测值的所有属性都可以为决策任意顶点上状态变量的取值提供依据。二是建立整个标记序列的联合概率, 这样不仅能够避免如最大熵、隐马尔可夫模型的标记偏置问题, 同时通过对所有特征进行全局归一化处理, 得到表达特征在全局条件下的重要程度, 使模型充分利用特征信息。鉴于此, 本文运用CRFs模型, 结合古汉语词汇的语言学规则构建特征模板, 探究CRFs模型在古汉语词性标注中的应用。
(3) 特征模板
如何针对词性标注为CRFs模型选择合适的特征模板, 是CRFs模型在词性标注中能否发挥作用的关键。特征模板指针对条件随机场模型的训练过程结合所需要识别序列单位的长度、前后字(词)、语音、相关搭配以及作为字词组合的概率等信息集合[25]。
特征模板可以根据是否需要结合特征知识分为简单特征模板和组合特征模板等。古代汉语文本词性标注主要涉及到的特征是词, 其中又以单字词为主。本文使用的简单特征模板如表6所示。简单特征模板作为Baseline, 之后的特征知识模板在此基础上产生。
(1) 模型构建
命名实体抽取的流程主要由训练和测试两部分组成。训练模块主要是在条件随机场的基础上, 使用所确定的自身特征并进一步添加特征模板, 在训练语料上得到知识抽取模型参数, 主要是特征的权重。测试模块是基于训练部分的特征权重值在测试语料上抽取命名实体的过程。基于测试部分抽取的命名实体, 结合相应评价指标, 从而确定不同标记集对实体抽取的影响。具体的模型构建流程如图2所示。
(2) 评价指标
命名实体抽取的评价指标采用精确率P(Precision)、召回率R(Recall)和调和平均值(F-Score)。精确率和召回率计算如公式(1)和公式(2)所示。
$P=\frac{正确抽取的实体}{正确抽取的实体+错误抽取的实体}\times 100%$ (1)
$R=\frac{正确抽取的实体}{正确抽取的实体+没有抽取的实体}\times 100%$ (2)
在用精确率和召回率评价命名实体抽取性能的过程中, 提高召回率时, 精确率会下降, 反之亦然。在这种情况下, 采用
$F=\frac{(\beta^{2}+1)\times{P}\times{R}}{(\beta^{2}\times{P})+R}=\frac{2\times{P}\times{R}}{P+R}(\beta=1)$ (3)
基于条件随机场, 通过自身模板和添加特征模板, 选取经过标注的语料进行训练和测试, 从而确定不同标记集对实体抽取的影响。将《左传》作为训练语料, 结合所选取的词性、词长以及虚词特征, 通过条件随机场得到三种不同标记集下的实体抽取模型, 再将模型应用到《国语》命名实体抽取上进行验证。三种标记集的具体测试结果如表7所示。
在词性、词长、虚词组合特征的基础上, 针对命名实体抽取的任务, 从基于条件随机场的抽取模型和调和平均值上可以看出, 标记集3的实体抽取模型效果最好, F值为84.07%。
对不同标记集下命名实体错误识别的统计如表8所示。可以看出, 人名与地名互标错的情况较多, 这主要源于《左传》和《国语》中的姓氏多取自爵位、官职、封邑等, 造成识别困难。人名实体中没有被识别出来的主要是长度为1、3、4以及部分长度为2的不常见人名, 如“辛”“衛武公”“閼伯”“竇犨”。地名实体中没有被识别出来的主要是长度为2以及长度为1的不常见地名, 如“會稽”“曲沃”“謝”。
本文在古代汉语文本词性标记集和实体抽取领域进行了探索。基于条件随机场模型, 通过观察词性、词长、虚词等特征, 使用《左传》作为训练语料, 得到三种不同词性标记集的实体抽取模型并在《国语》上进行验证, 从实验结果可以看出利用标记集3构建的实体抽取模型实验效果最好, F值为84.07%。
本文主要研究局限在于实验特征选取有待进一步改善, 训练结果还有提升空间, 下一步工作将会根据古汉语的具体特征对词性标记集进行增加或修改部分词性, 从先秦语料库中挖掘更多的特征知识添加到命名实体抽取的特征模板中, 进一步提高实体抽取的精确率和召回率。
王东波: 提供研究思路, 设计研究方案;
李斌: 提供数据支撑;
袁悦: 进行实验, 起草论文;
黄水清, 王东波: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail:db.wang@njau.edu.cn。
[1] 袁悦, 王东波, 黄水清, 李斌. Ancient Chinese.mdb. 《左传》和《国语》文本数据.
[2] 袁悦, 王东波, 黄水清, 李斌. result.txt. 基于条件随机场的命名实体抽取结果.
[3] 袁悦, 王东波, 黄水清, 李斌. Template. 命名实体抽取特征模板.
| [1] |
[本文引用:1]
|
| [2] |
[本文引用:1]
|
| [3] |
[本文引用:1]
|
| [4] |
[本文引用:1]
|
| [5] |
[本文引用:1]
|
| [6] |
该文探索了古代汉语,特别是先秦文献的词切分及词性标注。首先对《左传》文本进行了词汇处理(分词和词性标注)和考察分析,然后采用条件随机场模型(CRF),进行自动分词、词性标注、分词标注一体化的对比实验。结果表明,一体化分词比单独分词的准确率和召回率均有明显提高,开放测试的F值达到了94.60%;一体化词性标注的F值达到了89.65%,比传统的先分词后标注的“两步走”方法有明显提高。该项研究可以服务于古代汉语词汇研究和语料库建设,以弥补人工标注的不足。
Magsci
[本文引用:1]
|
| [7] |
该文介绍了以《淮南子》为文本的上古汉语分词及词性标注语料库及其构建过程。该文采取了自动分词与词性标注并结合人工校正的方法构建该语料库,其中自动过程使用领域适应方法优化标注模型,在分词和词性标注上均显著提升了标注性能。分析了上古汉语的词汇特点,并以此为基础描述了一些显式的词汇形态特征,将其运用于我们的自动分词及词性标注中,特别对词性标注系统带来了有效帮助。总结并分析了自动分词和词性标注中出现的错误,最后描述了整个语料库的词汇和词性分布特点。提出的方法在《淮南子》的标注过程中得到了验证,为日后扩展到其他古汉语资源提供了参考。同时,基于该文工作得到的《淮南子》语料库也为日后的古汉语研究提供了有益的资源。
Magsci
[本文引用:1]
|
| [8] |
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
近几年的中文分词研究中,基于条件随机场(CRF)模型的中文分词方法得到了广泛的关注。但是这种分词方法在处理歧义切分方面存在一定的问题。CRF虽然可以消除大部分原有的分词歧义,却会带来更多新的错误切分。该文尝试找到一种简单的、基于“固结词串”实例的机器学习方法解决分词歧义问题。实验结果表明,该方法可以简单有效的解决原有的分词歧义问题,并且不会产生更多新的歧义切分。
Magsci
[本文引用:1]
|
| [11] |
|
| [12] |
[本文引用:1]
|
| [13] |
[本文引用:1]
|
| [14] |
关键词的抽取广泛应用于自然语言处理过程中.对于中文关键词抽取,分词结果及候选词的选取严重影响后期的抽取结果.针对候选词的选取,提出一种连续单字未登录词识别和多词短语识别的方法来进行候选词选择,可以较好的识别出频率大于1的未登录词,且不依赖于语料库规模和领域.并且,在传统的TFIDF基础上,结合位置特征和长度特征的情况下,考虑兼类词的不同词性问题,提出改进的TFIDF计算公式,进行关键词抽取.通过比较实验,证明了候选词对关键词抽取的影响,与TFIDF进行比较实验,改进的TFIDF的准确率提高了5%左右.
Magsci
[本文引用:1]
|
| [15] |
[本文引用:1]
|
| [16] |
关键词抽取是从文本中抽取代表性关键词的过程,在文本处理领域中具有重要的应用价值.利用一种近年来受到广泛关注的新的信息源——社会化标签(tag)——来提高网页关键词抽取的质量.通过对Tag数据进行统计分析,发现用户往往对多个在话题上相关的网页使用同样的标签词,一个特定的文档可以通过其标注信息找到相关文档.在此基础上,提出了利用Tag进行关键词抽取的框架,并给出了一种具体的实现方法Tag-TextRank.该方法在TextRank基础上,通过目标文档中的每个Tag引入相关文档来估计词项图的边权重并计算得到词项的重要度,最后将不同Tag下的词项权重计算结果进行融合.在公开语料上的实验表明,Tag-TextRank在各项评价指标上均优于经典的关键词抽取方法TextRank,并具有很好的推广性.
|
| [17] |
针对传统审稿方式所存在的问题,设计了基于TextRank图算法思想的论文推荐系统,以实现论文审稿分配过程的自动化。系统通过加入词与词之间的影响力计算以及多文档集中逆文档频率IDF,实现关键词抽取部分,并使用基于余弦向量值的计算对抽取出的关键词向量进行相似度匹配,最后计算审稿人在各研究领域的影响力,实现论文的推荐。采用了综合考察准确率、召回率的F值作为评测指标,验证了该方法的有效性。在实际使用环境中,该系统具有较高的准确性与可靠性。
|
| [18] |
[本文引用:1]
|
| [19] |
[本文引用:1]
|
| [20] |
[本文引用:1]
|
| [21] |
[本文引用:1]
|
| [22] |
[本文引用:1]
|
| [23] |
[本文引用:1]
|
| [24] |
[本文引用:1]
|
| [25] |
[本文引用:1]
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |


{kind=link}
{kind=link}
{kind=link}
{kind=link}