
|
|

 , 温晓洁, Wen Xiaojie
, 温晓洁, Wen Xiaojie【目的】针对面向科技文献的神经机器翻译中存在的词汇表受限问题, 提出优化方法, 进而提升翻译质量。【方法】根据科技词汇构词规律, 结合点互信息, 在保留词汇义素完整的同时, 对神经机器翻译词汇表进行优化, 达到减少未登录词的目的。【结果】选择NTCIR-2010专利语料和自动化计算机领域期刊论文摘要语料进行实验, 将实验结果与普通分词和子词分词对比, 证明该方法的有效性。【局限】仅考虑中文字符的优化。【结论】在中文科技文献领域, 基于科技词汇构词的词汇表优化方法能够提升翻译效果。
[Objective] This paper optimizes the vocabulary of Neural Machine Translation (NMT) in scientific and technical domain for the problem of vocabulary limitation and improves the translation performance. [Methods] Based on the word formation and Point-wise Mutual Information(PMI), the paper proposes a method to optimize the vocabulary while preserving the integrity of the lexical semanteme which reduces the number of unknown words. [Results] The NTCIR-2010 corpus and abstract of journal articles in the domain of automation and computer were selected for experiments. The experimental results were compared with the segmentation method and the sub-word method, and it proved the effectiveness of the method. [Limitations] This paper did not cover the optimization of non-Chinese characters. [Conclusions] The experiments show that in scientific and technical domain, the vocabulary optimization algorithm based on scientific word formation achieves better translation performance.
科技文献(Scientific and Technical Document)是记载科学技术等知识的载体[1]。科学技术的快速发展促生了很多科技文献, 其中不乏大量的外文科技文献。科研人员从其他语言的科技文献中获取信息较为困难, 跨语言成为交流的主要障碍。多数科技文献仍然需要通过人工翻译才能为更多的科技工作者使用, 这种方式效率低、成本高。随着计算机的普及以及相关技术的快速发展, 利用计算机进行语言间转换的方法——机器翻译, 成为突破口。机器翻译能够快速实现语言间的大批量翻译, 随着神经机器翻译的兴起, 其效果也逐步满足实用化需求。
神经机器翻译在近两年得到飞速发展, 已经超越传统的统计机器翻译方法, 取得了更好的翻译效果。与统计机器翻译相比, 神经机器翻译具有更多优势。神经机器翻译模型框架简洁易学习[2], 能够直接从生数据中学习到隐含特征, 并捕获长距离依赖[3], 翻译句比统计机器翻译结果更为连贯、通顺。尽管神经机器翻译优势显著, 但也同样存在着明显的不足, 其中一个主要缺陷是词汇表受限导致的大量未登录词翻译问题。神经机器翻译的训练复杂度和计算复杂度随着词汇表词数的增加而剧增, 由于受硬件配置和计算复杂度的限制, 一般将词汇表的规模设置在3万到8万之间。这会导致很多低频词不在词汇表中, 被当做未登录词, 无法进行准确翻译。当句子中只有几个未登录词时, 翻译效果较好, 但当句子中出现大量未登录词时, 会出现大量的漏译现象。Cho等[4]的实验表明, 随着未登录词数的增加, 翻译性能迅速下降。词汇表受限带来的主要问题包括[5]: 未登录词导致源语言句子语义无法正确表示, 加重翻译结果的歧义现象, 如 “碳丝灯”不在词汇表中, 被<unk>替代输入给编码器; 训练语料中的源语言和目标语言句子结构被破坏, 神经网络参数质量不高; 解码过程中, 模型不能够生成合适的翻译结果, 如“这就是碳丝灯。”翻译结果为“this is <unk>.”。Jean等[6]的实验表明, 未登录词问题对词形丰富的语言影响更大。
面向科技文献的神经机器翻译中, 词汇表受限问题更为严重。一方面, 科技文献中包含大量的专有名词, 不同领域的科技文献包含不同的专有名词, 中文、英文、数字的混用都大大增加了机器翻译中的词汇表规模; 另一方面, 现有的分词工具在科技文献自动分词中会出现较多错误, 这同样会导致词汇表增加。本文针对科技文献神经机器翻译, 总结科技词汇构词规律, 利用科技词汇构词特征, 结合点互信息, 在保留词汇义素完整的同时, 对词汇表进行优化, 成功减少了未登录词比例, 最终达到翻译效果提升的目的。
尽管神经机器翻译取得了不小的进步, 但是在处理更大词汇表时具有局限性。许多学者对神经机器翻译词汇表受限问题进行研究。
针对神经机器翻译中的未登录词和罕见词问题, 有学者用查找字典的方式进行替换。Luong等[7]提出使用位置信息标注目标句子中的未登录词, 以便查询其源句子的对应位置。之后, 使用简单的单词字典查找或实体复制进行替换。然而, 这种方法在翻译科技文献时有一定的局限性, 某些未登录词可能是技术术语的一部分, 但这种方法只专注于解决未登录词, 忽略了词间关系。
Sennrich等[8]借鉴一种数据压缩算法: Byte Pair Encoding[9], 采用子词单元(Sub-word Units)的拆分策略, 利用常见词替换不常见词, 有效缓解神经机器翻译中的集外词和罕见词问题。Luong等[10]提出一种混合字符-词的神经机器翻译模型, 大多数情况下, 模型在词级进行翻译; 当出现未登录词时, 则会启用字符级模型, 在训练难度和复杂度不是很高的情况下, 实现了开放词汇表, 同时解决源语言和目标语言的未登录词问题。Costa-Jussà等[11]将基于字符产生词嵌入的方法应用于神经机器翻译, 可以在一定程度上克服未登录词问题, 但只是在源端使用, 对于目标端, 仍然面临词汇表大小的限制。
上述研究通过将语料库中的单词分割成更小单位的字符解决词汇表受限问题。虽然取得了一定突破, 但在估计更小单位字符时忽略了词的形态学概念, 可能导致词结构中语义和句法信息损失。Ataman等[12]通过开发一种基于语言动机的分割方法克服这个不足, 对于形态丰富的语言, 这种方法可以很好地分割词汇, 在满足神经机器翻译所需词汇表大小的同时, 依然考虑词的形态特性, 在土耳其语到英语的翻译任务中, 实现了更好的翻译准确度。
从简单的未登录词替换到考虑语言知识进行切分, 学者们从很多方面尝试解决神经机器翻译词汇表受限问题, 但是上述研究主要针对通用语料, 针对科技文献的研究较少。与通用语料相比, 科技文献语料词汇结构复杂, 含有大量专业词汇, 加大了科技文献词汇表优化的难度。本文基于科技文献词汇特点进行词汇表优化, 提升中英科技文献翻译效果。
在进行神经机器翻译训练时, 前处理阶段生成源端和目标端的词汇表, 以便用于训练和解码阶段。对于词汇表的生成, 采用的方法是对源端语料进行分词, 然后对分词后的源端词汇进行词频统计, 选取频数比较高的前
(1) 混合字符分词[10]: 保留词汇表中的词, 将未登录词切分为字符。本文通过神经机器翻译系统生成词汇表, 然后将非词汇表中的词切分成字符, 以上处理都是针对中文字符。
(2) 子词切分[8]: 通过比单词更小的单位拆分低频词, 也就是用子词单元对低频词进行表示, 常用的分词工具是BPE。学者进行的都是同源语言之间的实验, 对于中英科技文献之间是否有改善, 还有待于实验验证。
(3) 词级分词方式: 这是进行神经机器翻译实验普遍采用的分词方法, 但是近来有被混合分词、子词分词替代的趋势。因为词级分词会产生很大的词汇表, 形成很多未登录词, 影响翻译效果。由于中文的特殊性质, 新词层出不穷, 无章法可循, 分词工具仍不能达到对中文的完美分词。而且, 科技文献有其自身特点, 术语量比较多, 组成比较复杂, 这对分词又提出挑战。
本文使用的神经机器翻译系统是基于注意力机制的循环神经网络, 对源端句子进行编码形成词向量, 然后根据源端句子词向量, 计算目标句子条件概率, 给出翻译结果[14]。编码器是双向循环神经网络, 读取输入序列
训练语料为NTCIR-2010专利语料①(①http://research.nii.ac.jp/ntcir/ntcir-10/index.html.), 神经机器翻译系统为OpenNMT[15], 普通分词选择Stanford中文分词[16], 英文采用NLTK[17]处理。三种分词粒度为普通分词、混合字符分词、BPE子词分词, 分别在数量为3万和5万的词汇表中进行中英文翻译实验。评价方法为BLEU[18], 由NiuTrans的NiuTrans-dev- merge.pl[19]脚本计算得出。
在词汇表设置为3万时, 从BLEU值来看, BPE分词翻译效果优于普通分词和混合字符分词, 混合字符分词翻译效果优于普通分词。在词汇表设置为5万时, 相对于3万词汇表, 未登录词比例和数量有一定程度的减少, 但是BLEU得分没有明显提高。实验说明, 即使在一定程度上增大词汇表的数量, 也不能显著减少未登录词数量, 提升BLEU值。BPE(3万词汇表)BLEU得分高于BPE(5万词汇表), 但是未登录词数量多于后者。BPE子词分词和混合字符分词(3万词汇表)优于Stanford分词(5万词汇表)的翻译效果, 证明小于词粒度的分词有助于神经机器翻译训练, 提升翻译效果, 为词汇表优化提供了启示。混合字符分词和BPE子词分词有助于面向科技文献的神经机器翻译词汇表压缩, 词汇表数量在相对小的情况下, 取得了较好的效果, 达到大词汇表数量的翻译效果, 实现了压缩词汇表数量的目的。但是在进行子词切分时忽略了词语间的语义关系, 而且BPE子词分词将中文字符与非中文字符联合训练, 对中文字符语义有负面影响。
科技文献包含大量专业词汇, 因其出现频率不高, 在神经机器翻译系统中大多被作为未登录词处理, 这大大影响了科技文献的翻译效果。实际上, 科技词汇具有比较鲜明的特征, 多数科技词汇由相关专业词汇通过分拆、组合等方式形成, 这是本文进行词汇表优化的主要依据。
科技词汇中的三字词、四字词、五字词居多[20]。其中组合词的比例较高, 如“乙酸乙酯”, 由“乙酸”、“乙酯”组合而成。这种由短名词组成的长名词, 可以被拆解成多个短词, 长度越长的词汇, 往往出现的频率越低, 如果能将长词切分为短词, 能够大大减小词汇表的数量。例如“乙酸乙酯”切分为“乙酸”、“乙酯”两个词, 而这两个词本身就已经包含在词汇表中, 那么切分后相当于词汇表减少了一个专业词汇, 而利用神经机器翻译本身的特性, 虽然“乙酸乙酯”在语料中被切分, 但在实际训练过程中, 其结构特征能够被网络记录, 往往并不影响实际的翻译结果。
科技词汇构词复杂, 包含很多数字、英文字母、符号等特殊字符[21], 对其分词造成了很大阻碍。切分后的科技语料, 有很多由中文字符与其他特殊字符组成的词, 或者单纯是特殊字符的词。例如“6-溴-7-羟基-2-苯并噻唑基”, “95℃”, “Biochem.J.270”等。普通分词会有很多中文字符与非中文字符相连的情况, 其中包含正确切分的词汇, 也包含被非中文字符影响导致错误切分的词汇, 如“如图7A”、“咪唑-2-基”等。这种汉字与其他字符组成的混合字符, 经过分词工具进行切分后, 会存在粘连现象, 而且比例较大, 造成词汇表数量巨大, 本文对这类现象进行分割处理, 减少对语义的影响, 不仅利于中文分词, 还有利于中文的后续处理。
随着科学技术的发展, 科技新词也不断涌现。理解科技新词的构词规律对于机器翻译很重要。科技词汇构成主要包含两种形式。
(1) 合成法。合成法是科技新词的主要构词方法, 将两个或者两个以上的旧词组合在一起生成新词。如 “机器翻译”由“机器”、“翻译”组合而成, 在目标端的英文是“machine translation”等。这些合成词可以被用于后续的中文处理, 使用高频短词对低频长词进行表示。
(2) 派生法。派生法主要进行派生构词, 在词根的基础上附加前缀或后缀, 即词缀派生法。在现代汉语的构成中, 有成词语素与非成词语素的区别, 成词语素可单独成词, 非成词语素不可单独成词。非成词语素可以和其他的成词语素构成词, 位置可以是词前或者词后, 这样的非成词语素叫做词缀[22]。如名词后缀“控制器” “存储器” “服务器”中的“器”等。
科技新词的增多, 给分词和机器翻译都带来挑战。科技新词的使用率不是很高, 频数较低, 容易形成未登录词, 加大了神经机器翻译的难度。对于经过合成法、词缀法形成的科技新词, 本文通过词内词将频数比较低的长词进行切分, 利用神经机器翻译中的词向量和网络结构保持其语义相关。
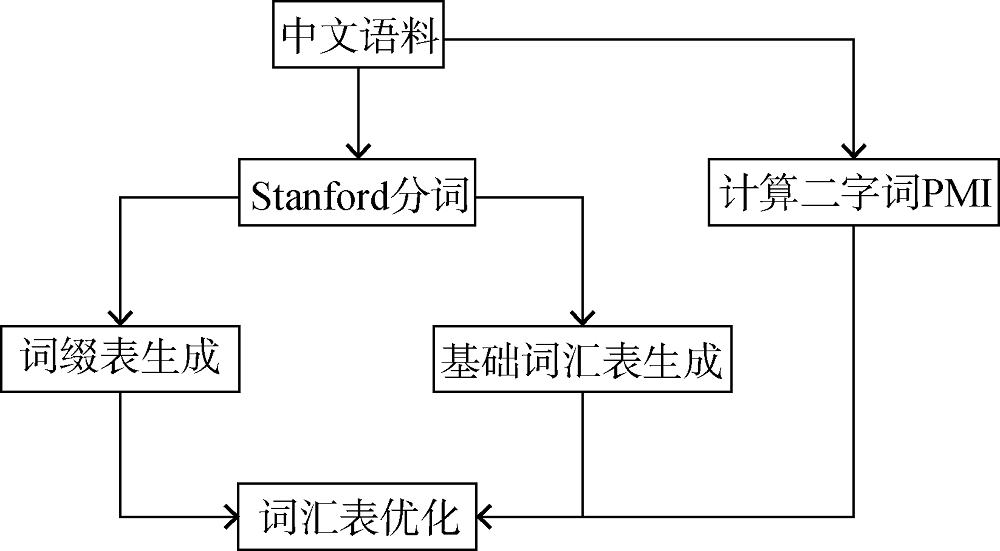
科技词汇大量使用合成法、派生法生成新的专业术语, 而这两种方法使用的基本元素能够保持基本语义不发生变化, 基于这一特性, 本文设计了词汇表优化算法, 共分为基础词汇表生成、词缀表生成、二字词点互信息计算和词汇表优化4个主要部分。
(1) 基础词汇表生成
基础词汇表是进行词汇表优化的基本词汇单元, 用来表示科技文献中较小的能够保持基本语义的单元, 主要用于切分三字词和低频长词。首先统计语料中的二、三字词, 本文根据现代汉语词典和词频选择二、三字词作为基础词汇表。提出两种基础词汇表生成方法, 具体生成方法如下。
①前N词(TOP_N): 选取高频二、三字词作为后续再处理的切分字典。此方法针对单一分词结果, 会有高频分错词的情况, 优点是可以避免混入低频词。神经机器翻译产生的词汇表, 中文词数量在3万左右, 所以将二字词数量定到2万, 三字词定到8 500。
②字典+词频(Dict+Fre): 将语料中的词与现代汉语词典取交集, 如果数量不满足二字词2万、三字词8 500, 再将高频二、三字词添加到分词字典中。可以确保大部分二、三字词是切分正确的词, 后添加的高频词不会被替换成<unk>。字典和频数成为选择二、三字词的影响因素。
(2) 词缀表生成
主要通过统计和过滤来获取科技词汇中的前缀和后缀, 目标是帮助优化含有词缀的三字词。在语料中, 三字词的组成形式可以分为三种: 1+1+1, 2+1, 1+2, 后两种存在大量词缀加二字词的组成情况。统计三字词的首尾词词频, 筛选出高频和位置信息明确的词缀词生成词缀表, 如 “非、不、再”等前缀词, “态、化、率”等后缀词, 可以引导词缀与词的切分。
(3) 二字词点互信息计算
对于没有词缀或者含有前后词缀的三字词, 可以参考点互信息切分。点互信息(Pointwise Mutual Information, PMI)[23]常用于中文分词, 可以判断词之间成词的可能性, 定义如公式(1)所示。
$PMI(x,y)=\log \frac{p(x,y)}{p(x)p(y)}=\log \frac{p(x|y)}{p(x)}=\log \frac{p(y|x)}{p(y)}$(1)
其中,
(4) 词汇表优化
主要针对二字词、三字词和多字词三种情况进行优化。
①二字词: 相关试验[24]证明, 基于字符级的翻译结果与基于词的翻译结果相差不多, 所以对于词长为2的低频词进行切碎处理。
②三字词: 基于科技词汇词缀和点互信息对低频三字词进行前向最大匹配切分。对于未含有词缀的低频三字词, 先判断PMI高低, 再判断两个二字词的词频, 如果其中某个二字词PMI和词频都高, 则此二字词保留, 否则保留高频二字词。
③多字词: 由科技词汇复合词规律指导对低频长词进行双向最大匹配切分, 同时保留相对高频的成语、熟语词。如 “稀土金属元素”在语料中的频次为2, “稀土”的频次是419, “金属”的频次是213 558, “元素”的频次是6 141, 可以在词汇表中保留“稀土”、“金属”、“元素”, 对“稀土金属元素”进行切分, 切分结果为“稀土 金属 元素”, 优化词汇表, 减少词汇表数量, 部分切分情况如表3所示。
实验数据集为NTCIR-2010专利语料和自动化计算机领域期刊论文摘要语料①(①本语料为中图分类TP(自动化、计算机技术)期刊论文中英文摘要自动抽取的双语语料。)。中文采用Stanford分词, 英文采用NLTK处理。表4和表5是神经机器翻译实验结果, 词汇表数量为5万。
Baseline采用Stanford分词, 其实验结果作为基线系统。根据所使用的基本词汇表生成方法不同, 设计两个优化方法实验, TOP_N选取高频二、三字词作为分词字典; Dict+Fre选取字典词与高频词作为分词字典。表4显示, 相对Baseline, TOP_N在BLEU值方面提升2%, 未登录词数量减少了405; Dict+Fre在BLEU值方面提升了1.91%, 未登录词数量减少了302。表5显示, 相对Baseline, TOP_N在BLEU值方面提升0.64%, 未登录词数量减少了70; Dict+Fre在BLEU值方面提升了0.68%, 未登录词数量减少了87。
按照优化算法对词汇表进行处理, 中文词汇缩减到3万以下。实验结果证明两种改进方法都提升了翻译效果, 同时优于BPE子词分词。从测试集中选择的一个样例如表6所示, 在词级分词中, “阴离子交换剂”保留, 属于未登录词, 由<unk>替换输入给编码器, 损失了源词有价值信息; 在改进方法中, “阴离子交换剂”被切分为“阴离子 交换 剂”或者“阴 离子 交换 剂”, 子串属于高频词, 在词汇表中, 保留了源词有价值信息。与基线系统作对比, 改进方法翻译出了未登录词, 提升了翻译效果, 为以后基于科技词汇优化词汇表提供了有效证明。
受神经机器翻译本身的特性限制, 词汇表过小成为影响神经机器翻译质量的重要因素之一。本文将科技词汇构词规律运用到面向科技文献的神经机器翻译的词汇表优化中, 基于词缀、复合词等特征, 参考点互信息将低频词分解为语义完整的高频词, 压缩了词汇表数量, 实现神经机器翻译词汇表优化, 实验结果验证了该方法的有效性。
本文对中文词汇进行处理, 科技文献依然包含数量众多的非中文字符, 英文字母、数字等字符, 同样需要进行处理优化, 在未来工作中将继续探索。
刘清民, 石崇德: 提出研究思路, 设计研究方案;
刘清民: 数据处理, 实验验证, 论文撰写及修改;
石崇德, 姚长青: 方案讨论, 论文修改;
温晓洁, 孙玥莹: 论文修改。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: liuqm2016@istic.ac.cn。
[1] 刘清民, 石崇德. NTICR-2010、自动化计算机期刊论文摘要语料.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |

{kind=link}
{kind=link}