
|
|

 , 刘东苏
, Liu Dongsu
, 刘东苏
, Liu Dongsu
【目的】构建一种微博话题演化方法, 正确把握话题发展趋势, 提高网络舆情预警能力。【方法】使用Skip-gram模型在文本集上训练得到词向量模型, 将每一时间片的微博文本输入BTM得到候选主题, 在主题维上构造候选主题词向量; 利用K-means算法对主题词向量聚类, 得到融合后的主题, 进而建立文本集在时间片上的话题演化路径。【结果】实验结果表明, 本文方法话题抽取F值为75%, 对比主题模型提高约10%, 证明本方法的可行性。【局限】话题演化的衡量标准不一致, 没有对比多种话题演化方法。【结论】本文方法能有效抽取各阶段话题, 为网络舆情分析提供有效途径。
[Objective] This paper aims to correctly grasp the topic development trend by constructing a microblog topic evolution method, and it is of great significance for public sentiment warning. [Methods] Firstly, the Ship-gram model is used to train the word vector model on the text set. Input the text of each time slice into the BTM to get the candidate theme. In BTM thematic dimension, the theme word vector is constructed. Secondly, k-means algorithm is used to cluster the theme word vector to get the fused theme. And the topic evolution of the text set on time slice is established. [Results] The experimental results show that the F value of this method is 75%, which is about 10% higher than that of the topic model. This proves the feasibility of the proposed method. [Limitations] There is no definite measuring standard for topic evolution, and there is no comparison between various methods of topic evolution. [Conclusions] The proposed method can effectively extract topics at all stages and provide an effective way for network public opinion analysis.
互联网及其引发的信息革命, 极大地影响着人们的生产生活方式。近年来自媒体和社会化网络消除了公众言论的障碍, 网络言论自由, 观点表达复杂多元已成为网络舆论的新特征。网络舆论的传播呈现非线性的散播路径, 使得舆论话题在扩散过程中具备反复波动的特点, 特别是热点话题在长期的演化过程中会呈现多个高峰, 其内容焦点很可能随着时间的推移发生动态迁移, 出现阶段性变化的特点[1]。及时准确地发现舆论话题焦点的转移, 动态跟踪话题的演变趋势, 深入分析话题的现状和特点, 可以更完整地描述网络舆情动态演化路径, 帮助大众更清晰准确地把握热点事件的来龙去脉, 也是网络舆情引导服务的重要内容, 对于构建良好的网络舆论生态环境具有重要意义。
微博是一个可以分享信息、获取热点话题的社交平台。当用户发微博时, 经常用较短的文字来表达自己的观点或分享新事物。同时社交媒体可以在没有任何结构或组织的文本中传播信息, 使得传统的结构化表达方式在很大程度上被社交媒体无结构、无关联的表达所取代。微博传播的无限性、开放性、共享性, 使网络空间充斥着一系列非理性言论。任何突发因素都可能引发公众的“舆论海啸”。因此, 研究公众对公共事件的讨论、跟踪热点事件的进展是非常重要的。
与话题演化相关的工作包括话题发现与跟踪技术。随着研究的深入, 一方面, 采用主题模型模拟文章的生成过程, 将高维主题分布平稳以后的样本作为语料中文档的主题分布, 以此得到文本话题, 这成为话题分析的主要方法。赵爱华等[2]提出基于LDA的新闻话题子话题划分方法; 徐佳俊等[3]利用LDA模型挖掘论坛中的热点话题, 并分析话题的演化路径; 王亚民等[4]利用BTM模型对微博文本进行建模以适应微博短文本的特征, 从而挖掘微博的热点话题。另一方面, 研究人员将时间信息引入LDA模型, 研究话题随时间的动态迁移, 如Topic over Time (ToT)模型[5]、动态话题模型[6](Dynamic Topic Model, DTM)。齐亚双等[7]利用DTM模型分析学科领域研究方向和发展演化情况; Alsumait等[8]提出在线LDA (OLDA)模型; 胡艳丽等[9]提出基于OLDA的话题演化方法和内容演化。基于LDA主题模型利用主题-词分布和文档-主题分布进行计算, 而短文本受到稀疏模式问题的困扰, 有限的上下文使主题模型很难识别出短文档中模糊词的含义。唐晓波等[10]对LDA进行扩展, 并将文本按时间划分, 使其适合中文微博处理; 史庆伟等[11]提出针对微博文本的词对主题演化模型, 扩充短文本的特征。
以上方法均属于“文本”粒度层面的文本表示。近年, 基于“词”粒度层面的文本表示也取得了一定进展, 词向量的基本思想是通过训练语料充分挖掘词语之间丰富的语义信息。李帅彬等[12]通过定义文本词向量模型得到文本的词向量表示来发现微博热点话题; 张佳明等[13]利用词向量引入的语义信息, 有效提高微博事件追踪的性能。
词向量是一种用数学化的形式表示词语, 将词语用一个向量表征。最简单的词向量方式是One-Hot编码, 即用一个很长的向量表示一个词。但是这种表示有两个缺点: 容易遭受维度灾难; 不能很好地描述词与词之间的相似性。Hinton[14]提出Distributed Representation的概念, 可以克服One-Hot编码的缺点。2013年, Google团队发布Word2Vec工具, 其主要包含连续Bag-of-Word模型和Skip-gram模型。Word2vec自提出以来, 在自然语言处理任务中得到了广泛应用。
综上, 本文采用BTM主题模型从微博中获取候选话题, 利用Word2Vec构造候选主题的主题词向量; 通过对候选主题词向量进行聚类将候选主题融合从而得到更为准确的微博话题, 同时对主题微博进行标记, 可以更好地描述话题内容; 最后根据结果计算相邻时间片话题之间的相似度, 完成话题演化分析。
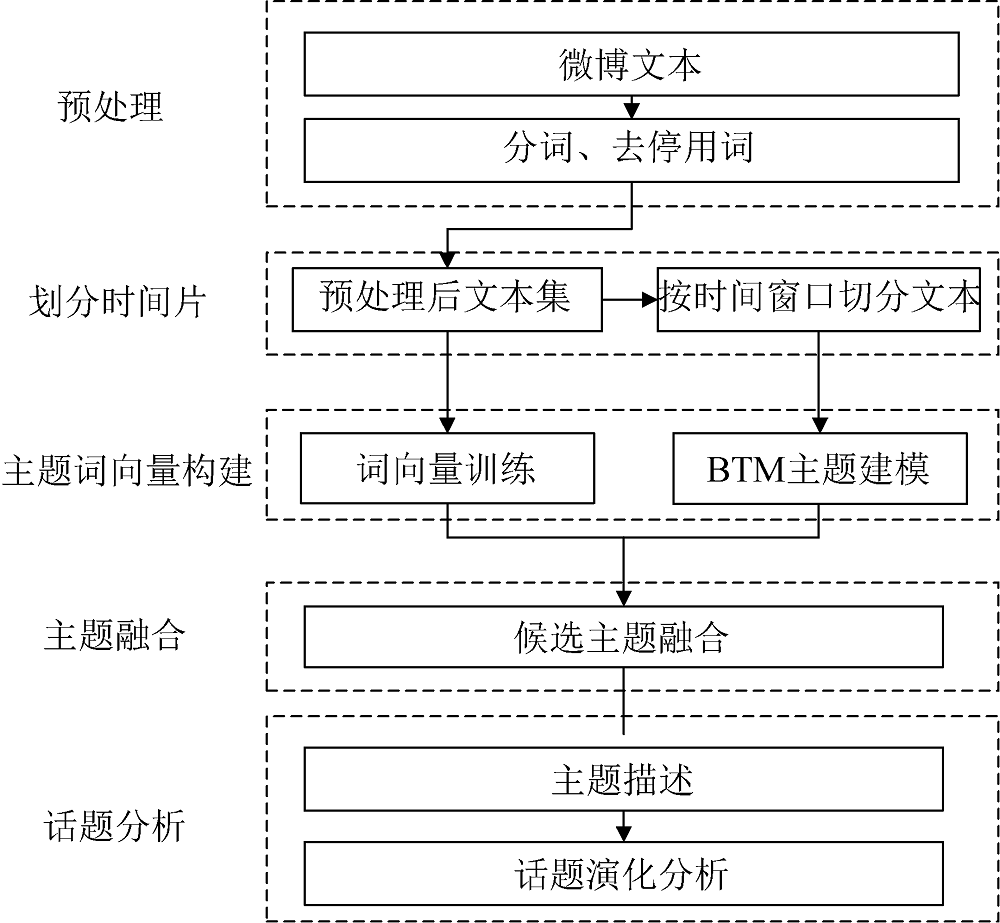
根据微博发布的时间按照指定时间粒度将其划分到不同的时间片中, 分别在每个时间片上运用BTM模型获取主题。总体研究框架包括: 划分时间片、每一时间片的主题提取、主题分析。对不同时间片的微博语料进行主题建模, 挖掘候选话题; 构建候选话题的主题词向量, 对主题词向量进行聚类, 完成主题融合, 从而得到准确的微博话题, 同时计算每个微博对话题的贡献度, 根据贡献度较高的微博进行主题描述; 最后计算主题相似度, 完成话题演化分析。具体研究框架如图1所示。
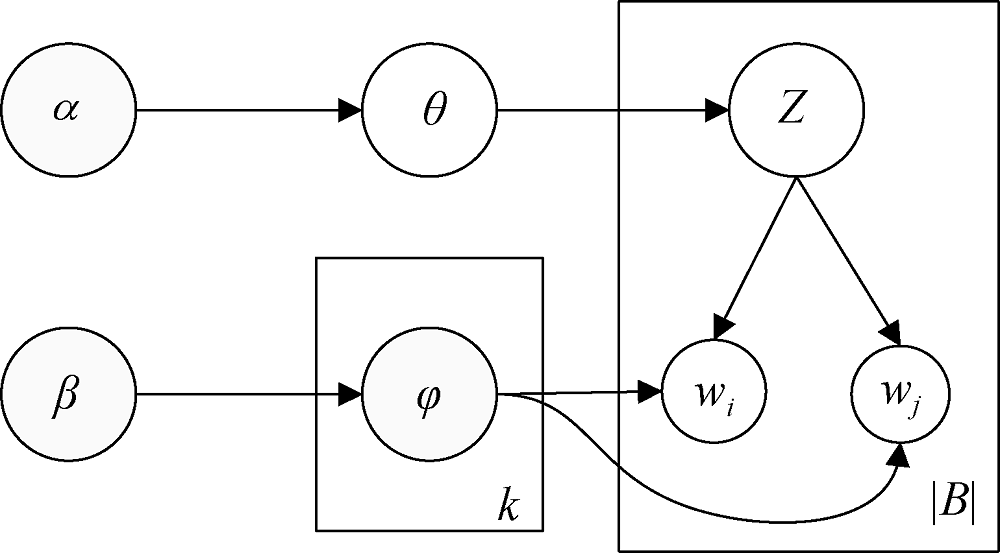
(1) BTM主题建模
BTM主题模型[15]主要是针对短文本建模的主题模式。其关键思想是在整个语料库中使用丰富的全局词共现模式来增强主题学习, 以解决单一文档中的稀疏性问题。具体地说, 是将整个语料库看成一个混合的主题, 其中每个词对都是独立于特定主题的。词对属于某一主题的概率由词对中每个词属于该主题的概率相乘得到。假设$\alpha$和
①对语料采样一个主题分布$\theta \tilde{\ }Dir(\alpha )$;
②对每个主题
③对每个双词
BTM模型如图2所示, 模型中的参数选择根据经验进行设置, 取$\alpha ={}^{50}/{}_{k}$, $\beta =0.01$, 迭代次数为1 000, BTM模型主题数
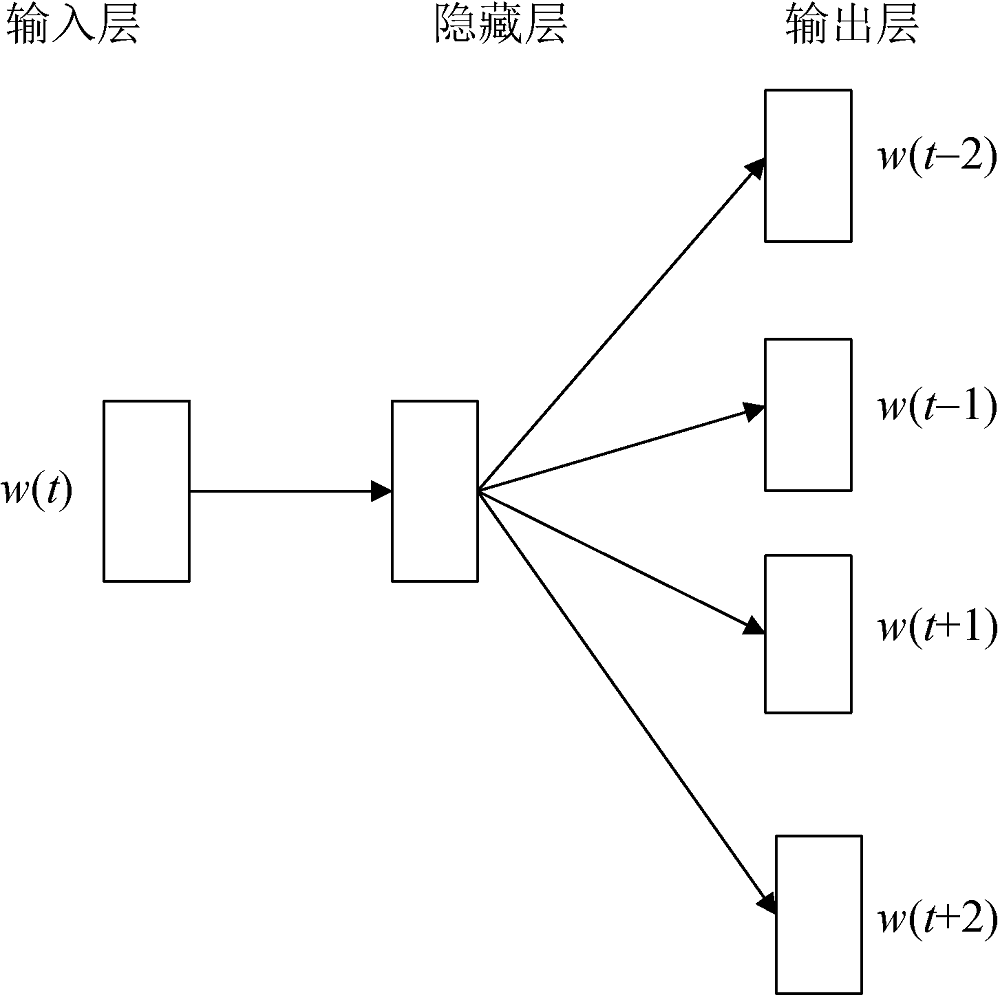
(2) 主题词向量的构建
使用Skip-gram模型训练整个语料库, 得到相应词汇的词向量; 将BTM得到的每一时间片的候选主题词表示为主题词向量, 主题词向量利用语料库中丰富的语义信息评估词语的相似性。
Skip-gram模型依靠给定输入词
(3) 主题融合
利用词向量和K-means聚类对候选主题进行融合, 保存训练好的词向量, 然后统计BTM得到的候选主题, 得到词表
算法1 基于词向量的话题融合算法
输入: 词向量, 候选主题
输出: 融合后的主题集
①初始化Word2Vec的参数, 将数据集输入到模型中, 训练得到词向量的模型;
②利用BTM模型对不同时间片的文本建模, 得到候选主题; 根据每个主题的“主题-词”概率分布, 抽取每个潜在主题下概率最大的前
③将词表
④将
⑤根据聚类结果获得每个类簇的关键词, 得到融合后的主题集
(4) 主题描述
关键词对话题描述的程度不够, 因此选择具有代表性的微博对每一话题进行扩充, 即选择对话题内容覆盖度较高的微博作为该话题的主题微博, 从而更好地描述主题。主题微博利用文献[19]的计算方法, 依据微博中包含主题关键字的比例来选择, 微博对于主题贡献度的计算方法如公式(1)所示。
$Coverage(M)={{\max }_{0\le k\le topic}}\frac{n}{N}$ (1)
其中,
在新浪微博数据集上进行实验, 证明引入词向量的微博话题聚类的有效性。
采用集搜客爬虫工具[20], 在新浪微博平台上抓取数据, 采集包括“勒索病毒”、“科技”、“旅游”、“人工智能”、“财经”等10类话题, 去掉文本中的链接、@其他用户的信息, 初步清洗去重后得到17 071条数据。
采用Python中的Jieba分词[21]对去重后的文本进行分词。对数据进行清洗、分词、去除停用词等预处理后共得到16 089条有效数据。将预处理过的微博文本按照其发布时间划分到6个时间片中; 将所有微博语料输入到主题模型中提取微博话题; 最后通过计算相邻时间片的主题相似度分析微博的话题演化。
对第一时间片的语料进行词频统计分析, 根据词表人工标注不同话题下的话题词, 形成标准的话题集。评估聚类结果时, 主要对话题词抽取结果的召回率R、准确率P和F值进行评估。
(1) 主题融合
在候选主题融合时, 首先在每个时间片内运用BTM模型获取候选话题, 其参数设置如下:
对第一时间片的话题提取对比实验结果如表2所示。
可以看出基于词向量的话题抽取方法的准确率、召回率与F值均高于两种对比方法, 其准确率稍高于BTM, 但是召回率明显优于BTM方法, 因为词向量是基于大量语料库训练得到的, 能更好地适应语料的变化。而基于OLDA模型的准确率与召回率均低于其他两种方法, 分析原因在于OLDA模型是在LDA模型的基础上改进得到的, 而微博短文本由于数据稀疏, 话题相关词汇出现的频率很低, 导致OLDA模型不如BTM模型的效果理想。
(2) 主题描述
通过本文模型得到不同话题的话题词, 例如, 第一个时间片中Topic 1.1的主题特征词分别为“病毒”、
“中”、“勒索病毒”、“文件”、“比特币”、“电脑”、“高校”、“同学”、“毕业设计”、“老师”, 根据公式(1)选择每一话题的主题微博, 结合主题微博对应的文本内容与主题特征词结合进行主题描述, 将Topic 1.1描述为“国内高校电脑中比特币勒索病毒”。部分时间片的主题关键词和主题微博总结如表3所示, 根据关键词和主题微博完成主题描述。
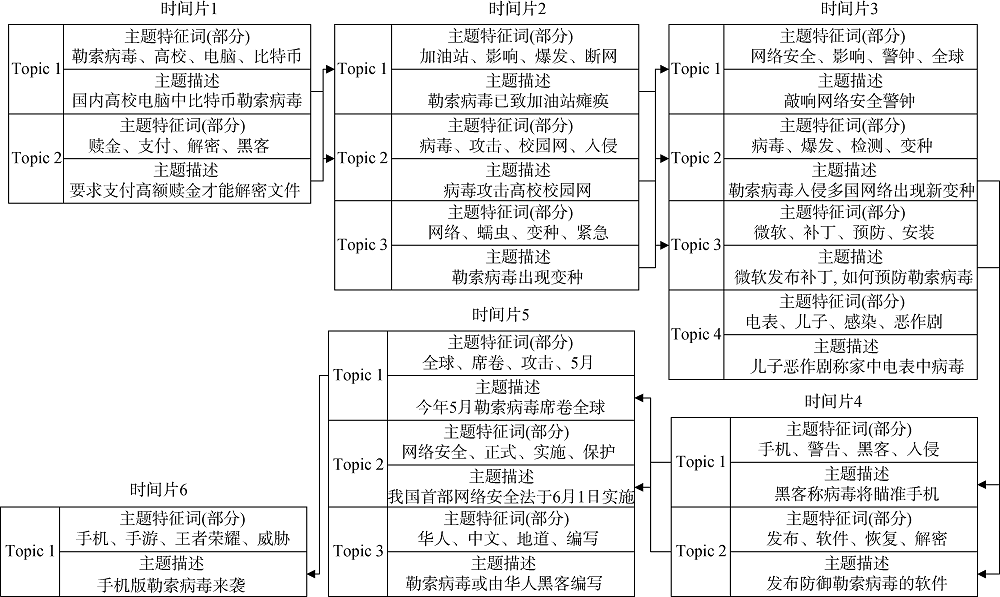
以新浪微博“勒索病毒”话题为例, 选取主题之间相似度阈值为0.5, 确定相邻时间片主题之间的演化关系, 从主题内容方面进行演化分析, 包括 主题的新生、合并、孤立和消亡等情况, 结果如图4所示。
通过计算主题词向量间的相似度得到不同主题间的相似度, 在余弦相似度的基础上引入词语对应的词向量, 将文本向量的每一项从词语转变成该词语的词向量, 计算方法如公式(2)所示。
$\begin{align} & sim({{D}_{1}},{{D}_{2}})= \\ & \frac{\sum\nolimits_{k=1}^{n}{(wk({{D}_{1}})\times {{v}_{1k}})\times (wk({{D}_{2}})\times {{v}_{2k}})}}{\sqrt{{{\sum\nolimits_{k=1}^{n}{(wk({{D}_{1}})\times {{v}_{1k}}\times {{v}_{2k}})}}^{2}}\times \sum\nolimits_{k=1}^{n}{{{(wk({{D}_{2}})\times {{v}_{1k}}\times {{v}_{2k}})}^{2}}}}} \\ \end{align}$ (2)
其中,
由图4可知, 在话题刚出现时, 人们的关注点主要是“勒索病毒”的入侵和支付高额赎金; 当话题发展到第3个时间片时, 有新话题的出现, 即儿子恶作剧称家中电表中病毒, 由于该事件在下一时间段中并未出现相关子话题, 可以判断该话题为孤立的子话题; 而当话题发展到第5个时间片时, 主要关注点在网络安全的讨论上, 其次出现关于勒索病毒来源的讨论; 在第6个时间片, 手机版勒索病毒的来袭则是第4个时间片黑客称病毒将瞄准手机这一子话题的延续。
传统的主题模型在进行话题演化分析时, 存在话题数不确定的问题。本文首先根据微博发布的时间将其划分到不同的时间片中, 同时利用大规模语料训练得到词向量, 通过对候选主题词向量聚类抽取不同时间片的话题词, 再次结合主题微博完成各时间片的主题描述, 最终形成话题演化分析, 并以新浪微博平台数据为例进行分析。结果表明,该方法能利用词向量充分挖掘词语间的语义关系, 提高话题间的区分度。但本文依旧存在一个普遍的问题, 即不能给出话题演化的衡量标准。因此后续研究将以更广泛复杂的突发事件语料进行测试及探索更合理的话题演化分析和评价方法, 同时结合情感分析更加细化话题的主题与情感变化。
张佩瑶: 设计实验, 实验数据采集、预处理和实验结果分析, 论文撰写;
刘东苏: 提出研究思路, 设计研究方案, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 970223903@qq.com。
[1] 张佩瑶, 刘东苏. 源数据.rar. 抓取自新浪微博的数据.
[2] 张佩瑶, 刘东苏. 6个时间片_txt. 由中文分词数据预处理后得到的文件.
[3] 张佩瑶, 刘东苏. sjj训练语料. txt. 利用Word2Vector训练词向量.
| [1] |
[本文引用:1]
|
| [2] |
针对目前网络热点新闻话题中存在的难以区分一个话题下的多个子话题现象,提出一种基于LDA模型的子话题划分方法.首先应用LDA模型对新闻文档进行建模,采用贝叶斯标准方法确定最优主题个数,使LDA模型拟合文档性能达到最佳;其次针对子话题间文本相似度较高的特点,引入主题特征词相关性分析,采用改进的KL距离公式,计算新闻文档之间相似度,有效区分了文档内容相似但话题重点不同的报道;最后通过single-pass增量聚类算法进行文档聚类,实现子话题划分.实验验证了改进后的相似度计算方法的有效性,实验结果表明该方法能够有效地提高热点新闻话题子话题划分的准确率.
<br>
Magsci
[本文引用:1]
|
| [3] |
语义歧义增加了生物事件触发词检测的难度,为了解决语义歧义带来的困难,提高生物事件触发词检测的性能,该文提出了一种基于丰富特征和组合不同类型学习器的混合模型。该方法通过组合支持向量机(SVM)分类器和随机森林(Random Forest)分类器,利用丰富的特征进行触发词检测,从而为每一个待检测词分配一个事件类型,达到检测触发词的目的。实验是在BioNLP2009共享任务提供的数据集上进行的,实验结果表明该方法有效可行。<br>
|
| [4] |
[本文引用:2]
|
| [5] |
[本文引用:1]
|
| [6] |
[本文引用:1]
|
| [7] |
[本文引用:1]
|
| [8] |
[本文引用:1]
|
| [9] |
[本文引用:2]
|
| [10] |
[本文引用:1]
|
| [11] |
[本文引用:1]
|
| [12] |
[本文引用:1]
|
| [13] |
微博文本长度短,且网络新词层出不穷,使得传统方法在微博事件追踪中效果不够理想。针对该问题,提出一种基于词向量的微博事件追踪方法。词向量不仅可以计算词语之间的语义相似度,而且能够提高微博间语义相似度计算的准确率。该方法首先使用Skip-gram模型在大规模数据集上训练得到词向量;然后通过提取关键词建立初始事件和微博表示模型;最后利用词向量计算微博和初始事件之间的语义相似度,并依据设定阈值进行判决,完成事件追踪。实验结果表明,相比传统方法,该方法能够充分利用词向量引入的语义信息,有效提高微博事件追踪的性能。
Magsci
[本文引用:1]
|
| [14] |
[本文引用:1]
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
URL
[本文引用:1]
|
| [18] |
URL
[本文引用:1]
|
| [19] |
[本文引用:1]
|
| [20] |
URL
[本文引用:1]
|
| [21] |
URL
[本文引用:1]
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}