
|
|

 , 贺兴时, He Xingshi
, 贺兴时, He Xingshi【目的】将深度信念网络应用于中文文本情感分类, 系统研究深度信念网络在文本情感分类任务中的参数选择与性能分析。【方法】以中文电子商务网站评论数据为研究对象, 提取一元词、二元词、词性、简单依存关系、情感得分和三元组依存关系特征作为深度信念网络的输入, 通过设置不同网络深度、不同输入维数的网络结构计算分类准确率。【结果】实验结果表明, 三元组依存关系特征作为深度信念网络的输入分类效果更好, 而网络层数对分类准确率的影响不大。【局限】尚未在其他深度学习模型上进行实验验证。【结论】深度学习在文本情感分类任务中性能良好, 验证了深度学习对复杂任务有很强的学习能力, 但其模型选择和参数设置尚需要进一步的研究。
[Objective] This paper focused on Chinese text sentiment classification based on deep belief network, especially the parameter selection and performance analysis of the network. [Methods] Chinese e-commercial reviews are as the object of the study, the unigram, bigram, POS, simple dependency label, sentiment score and triple dependency features are extracted and used as the input of deep belief network by setting different layers and different input numbers to compute the accuracy of sentiment classification. [Results] The results demonstrate that the triple dependency features as the input got better classification performance than the other features, but the number of hidden layers doesn’t have an effect on the classification accuracy. [Limitations] The methods aren’t conducted and verified on other deep learning models. [Conclusions] Deep learning has a good performance for sentiment analysis, but how to set up parameters still need to be further considered.
随着互联网的普及, 网络内容的数量以前所未有的速度增长, 而表达看法、意见、建议等的主观性文本, 如科技评论、产品评论、体育评论、时事评论、影视评论、新闻评论、军事评论、音乐评论、股票评论等也大量出现。这些主观信息是针对特定对象而发表的观点、态度、意见、立场等, 有强烈的个人情感色彩。文本情感分类是针对主观性文本进行自动分析和处理归纳的技术。通过该技术可以发现消费者对于产品的喜好、监管人们的情感变化或舆论趋势, 辅助消费者进行购买决策、为生产商改善商品提供依据、辅助政府进行舆情监管等。
文本情感分类技术是对非结构化文本数据进行处理的过程, 对句子语义的理解有较高要求。鉴于深度学习有很强的特征学习能力, 本文将深度信念网络(Deep Belief Network, DBN)应用于文本情感分类任务中, 研究深度信念网络在文本情感分类中的作用。提取一元词、二元词、词性、简单依存关系、情感得分和三元组依存关系特征及其组合特征作为深度信念网络的输入, 采用中文电子商务网站评论数据作为研究对象, 对不同特征输入、不同网络结构情况下的深度信念网络分类性能进行分析。
目前用于文本情感分类研究的主流方法是机器学习, 主要针对文本情感分类任务的特征表示和分类模型。用于文本表示的特征类别有一元词(Unigram)、多元词(N-Grams)、词性(Part-of-Speech, POS)、词的关系特征、基于规则的特征、结合情感词典的特征、社交网络特征和表示词语间修饰关系的依存句法关系特征等[1,2,3]。
在分类模型方面, 传统分类模型如支持向量机、朴素贝叶斯、最大熵模型等也取得了不错效果, 但仅针对于结构简单的数据, 对复杂函数的表示能力有限[4]。在这种情况下, 深度学习因其深层非线性网络结构可以对各种复杂问题进行特征表示而表现出更强的优势。深度信念网络作为深度学习的一种, 在特征表示上效果显著, 被广泛应用于手写体识别[5]、图像识别[6]以及语音识别[7]等领域。在文本情感分析中, Zhou等将深度信念网络用于亚马逊的4种不同语言的评论中, 研究跨语言情感分类, 实验结果证实了所提方法比以前的研究更加有效[8]。Mikolv等将深度信念网络与词向量结合用于韩语文章的政治检测, 分类准确率有了很大提升[9]。文献[10]将深度信念网络与特征选择结合, 提出DBNFS算法, 用于5种不同的数据集中, 实验结果验证了DBNFS的准确率高于已有研究。
以上研究选取的语言都是非中文语言。在中文文本情感分类中, 深度信念网络还没有被系统研究过。本文将深度信念网络用于中文文本情感分类, 研究不同特征集、输入节点和隐层层数对文本情感分类结果的影响。
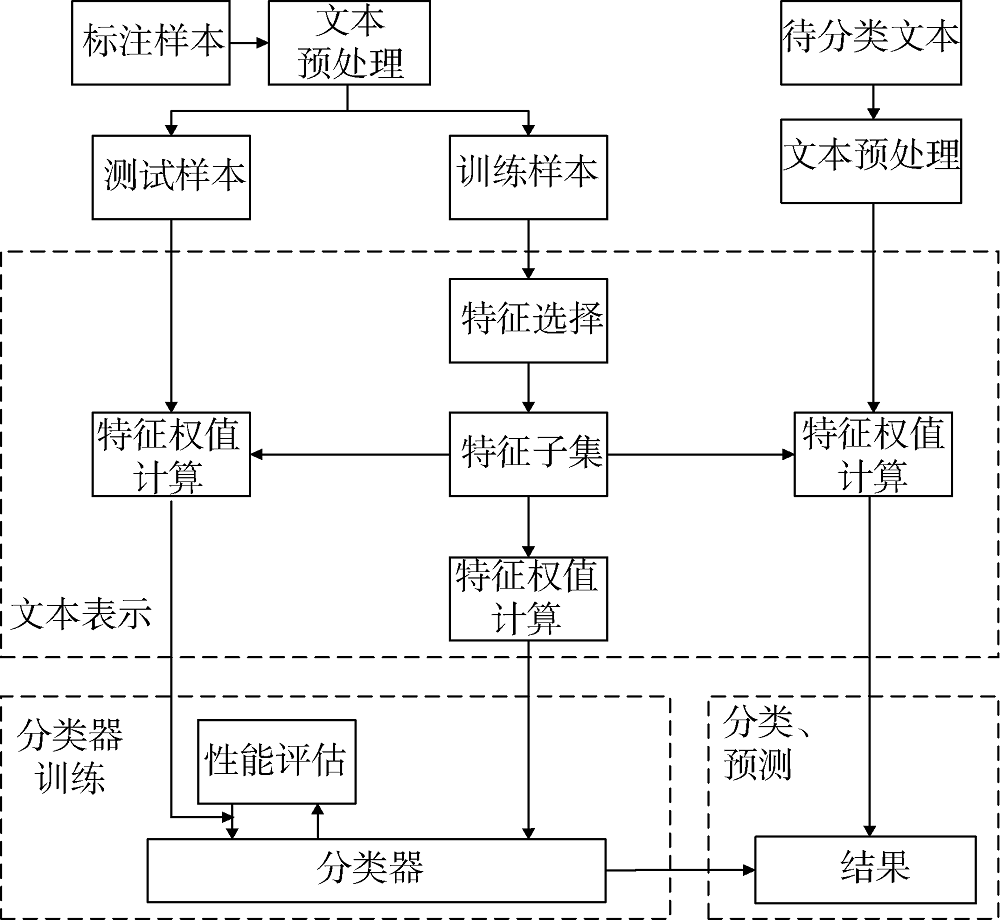
文本情感分类的研究对象是隐含有情感表达的主观性文本, 是一类特殊的文本分类任务。基于机器学习的文本情感分类流程主要分为三个阶段: 文本表示、分类器训练和分类与预测, 如图1所示。文本经过分词、去停用词等预处理后, 在文本表示阶段被表示为由特征项构成的向量空间模型。向量空间模型的构成要经过特征构建、维数约减、特征权值计算三个步骤。在分类器训练中, 向量空间模型作为分类算法的输入。通过样本训练, 分类器不断进行参数调整, 直到测试样本的实际误差与预测误差达到设定范围为止。分类器训练完毕, 则可用于其他数据(如实时数据)的分类与预测。
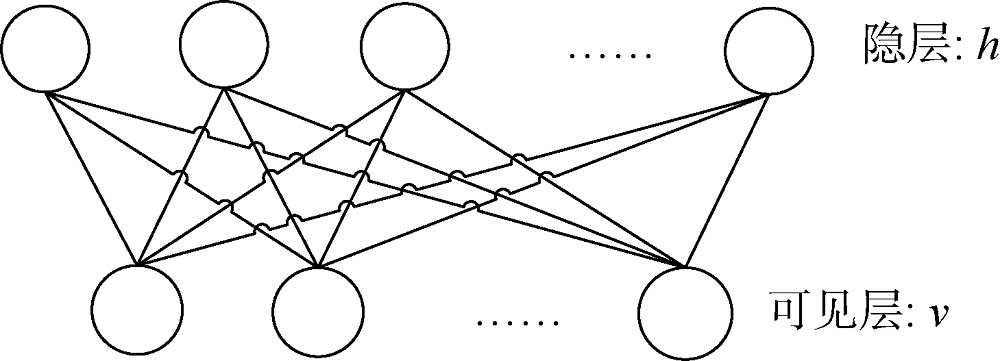
作为深度学习的一种, 深度信念网络[11]是一个概率生成模型。与传统判别模型的神经网络相对, 生成模型是建立一个观察数据与标签之间的联合分布, 对概率
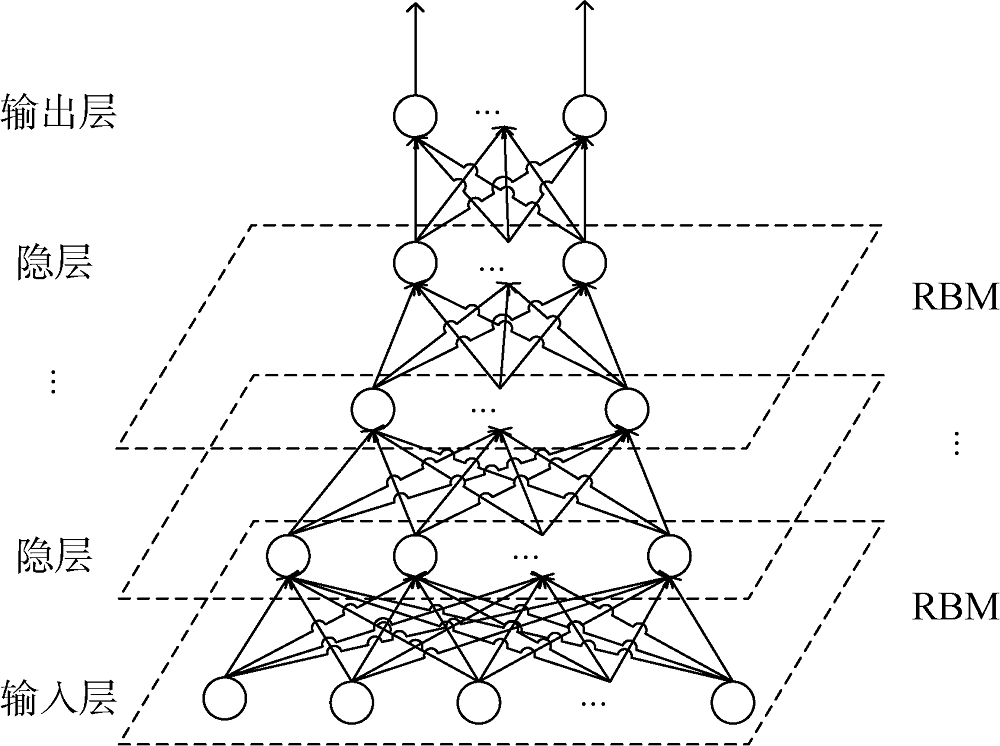
深度信念网络由一个输入层(可见层)、多个隐层和一个输出层组成, 结构如图2所示。
深度信念网络的训练过程包括非监督的特征学习部分和有监督的网络微调部分。其中特征学习部分由一系列的限制波尔兹曼机(Restricted Boltzmann Machine, RBM)串联而成[12]。上一层限制波尔兹曼机的输出成为下一层限制波尔兹曼机的输入。当所有的限制波尔兹曼机学习完成后, 则预训练完成。在网络最后加上输出层, 此输出层也为分类层。将预训练完成的网络结构展开, 输入有标签的样本数据, 通过后向传播(Back Propagation, BP)算法对整个网络进行微调。限制波尔兹曼机预训练的过程相当于为多层BP网络预先学习网络权值和阈值, 有效避免BP网络易陷入局部最优、网络不收敛的缺陷。而BP算法极强的自学习、自组织能力得以充分利用。
限制波尔兹曼机是一种能量模型, 给定一个有
$E(v,h\left| \theta \right.)=-\sum\limits_{i=1}^{n}{{{a}_{i}}{{v}_{i}}-\sum\limits_{j=1}^{n}{{{b}_{j}}{{h}_{j}}-}}\sum\limits_{i=1}^{m}{\sum\limits_{j=1}^{n}{{{v}_{i}}}}{{W}_{ij}}{{h}_{j}}$ (1)
其中, $\theta =\{{{W}_{ij}},{{a}_{i}},{{b}_{j}}\}$为限制波尔兹曼机的实数参数。
根据限制波尔兹曼机结构可知: 当给定可见层的状态时, 隐层节点的激活状态之间是条件独立的。那么, 第
$P({{h}_{j}}=1|v,\theta )=\sigma \left( {{b}_{j}}+\sum\limits_{i}{{{v}_{i}}{{W}_{ij}}} \right)$ (2)
其中, $\sigma (x)=\frac{1}{1+\exp (-x)}$为Sigmoid激活函数。
同理, 当给定隐层节点的激活状态时, 各可见层节点的激活状态之间也是条件独立的, 即第
$P({{v}_{i}}=1|h,\theta )=\sigma \left( {{a}_{i}}+\sum\limits_{j}{{{W}_{ij}}{{h}_{j}}} \right)$ (3)
对限制波尔兹曼机进行训练, 目的是得到合适的
${{\theta }^{*}}=\underset{\theta }{\mathop{\arg max}}\,\mathcal{L}\left( \theta \right)=\underset{\theta }{\mathop{\arg \max }}\,\sum\limits_{t=1}^{T}{\log P({{v}^{(t)}}|\theta )}$ (4)
其中, $P({{v}^{(t)}}|\theta )$为似然函数, 它是(
$P(v,h|\theta )=\frac{{{e}^{-E(v,h|\theta )}}}{Z(\theta )},Z(\theta )=\sum\limits_{v,h}{{{e}^{-E(v,h|\theta )}}}$ (5)
其中,
为训练限制玻尔兹曼机, Hinton提出一个快速学习算法, 称作对比散度(Contrastive Divergence, CD)算法[13]。对比散度算法用训练数据初始化可见层, 根据公式(2)计算隐层节点激活状态; 再根据公式(3)用获得的隐层数值计算可见层节点激活状态, 得到输入的重构模型。利用重构误差调整限制波尔兹曼机参数, 使重构误差尽可能减小。根据对比散度算法, 权值更新公式如公式(6)所示。
$\Delta {{w}_{ij}}=\eta (<{{v}_{i}}{{h}_{j}}{{>}_{data}}-<{{v}_{i}}{{h}_{j}}{{>}_{model}})$ (6)
其中, <·>
当整个限制波尔兹曼机训练完毕后, 将网络进行全连接, 并将得到的权值用于初始化网络。同时, 分类层将加于网络之上对整个网络进行微调。微调部分是有监督的学习过程, 用BP算法对网络权重进行调整。
重构误差是以输入数据作为初始状态
$\begin{align} & error=0 \\ & for t=1,2,\cdot \cdot \cdot ,T \\ & error=error+\parallel {{V}^{\left( t \right)}}-{{V}^{0\left( t \right)}}\parallel \\ & end \\ \end{align}$ (7)
BP算法通过误差而不断修正网络的权值和阈值[15]。BP算法具体计算步骤如下:
假设包含一层隐层的神经网络有
BP算法需要通过修改权值
${{\Delta }_{p}}{{w}_{ji}}=\eta {{\delta }_{pj}}{{o}_{pj}}$ (8)
其中, 输出层${{\delta }_{pj}}=({{\hat{y}}_{pj}}-{{y}_{pj}}){{{f}'}_{j}}(Ne{{t}_{pj}})$, 隐层${{\delta }_{pj}}={{{f}'}_{j}}(Ne{{t}_{pj}})\sum\limits_{k=1}^{M}{{{\delta }_{pk}}{{w}_{kj}}}$, 参数
本文数据集采用数据堂提供的情感分析语料, 其中包括酒店评论数据、图书评论数据和笔记本电脑评论数据, 分别来自携程旅游网、当当网和京东网。
三个原始数据集中均包含已经标注过的正向文本和负向文本, 且以段落的形式存在。本研究目的是分析句子级别的文本情感倾向, 故对原有数据做相应处理。
(1) 对文档数据进行断句处理。以“\n”和中英文的问号“?”“?”、句号“。”“.”和分号“;”“;”为断句标识对所有文档进行断句。在断句基础上, 去除重复句。
(2) 对断句后的新文本重新进行正负向标注。原始文本段落层次上的正负倾向并不等同于每个句子的正负倾向。在原有段落标注基础上, 删除表示中立或者无法确定正负向的句子。此步骤由一人完成后再由另一人检验, 对存在争议的句子进行讨论后确定其倾向, 删除无法确定的句子, 确保文本正负向标注准确。
(3) 对三个数据集进行随机抽取。本文研究平衡数据的文本情感分类, 对酒店评论数据抽取句子4 000条, 包括2 000条正向评论和2 000条负向评论; 对图书评论抽取句子2 000条, 包括1 000条正向评论和1 000条负向评论; 对笔记本电脑评论抽取句子1 000条, 包括500条正向评论和500条负向评论。
借鉴文献综述与分析, 选取一元词、二元词、词性、简单依存关系、情感得分和三元组依存关系, 考察特征及其组合对电子商务网站评论文本情感分析结果的影响。其中, 简单依存关系对应于三元组依存关系, 用依存标签标识。
构造一元词、二元词、词性、简单依存关系、情感得分、三元组依存关系特征表示方法, 总共得到各特征维数如表1所示。
深度信念网络直接作用的文本情感分类任务主要由三部分组成: 文本预处理、文本特征选择和深度神经网络学习, 如图2所示。
(1) 将预处理过的评论文本转化为文本特征向量空间, 按照文本特征表示的三个步骤(特征构建、特征维数约减和特征权重计算)进行构建。采用信息增益得分进行维数约减; 权重计算采用布尔权重法即“0”、“1”表示法。
(2) 将不同维数的文本特征表示作为深度信念网络的输入, 深度信念网络中的限制波尔兹曼机使用对比散度快速学习算法, 按照公式(6)进行计算。计算测试样本的结果极性分类准确率。限制波尔兹曼机每个隐层的重构误差按照公式(7)计算。
采用分类准确率作为评价指标, 指标数值越大, 则文本情感分类的结果越准确。每个特征集的维数分别取信息增益得分靠前的1 000, 2 000, 4 000, 6 000, 8 000, 10 000, 12 000, 14 000项作为网络输入。
深度信念网络的网络结构和参数设置对文本情感分类结果有很大影响。为比较不同网络层数对分类准确率的影响, 设置深度信念网络隐层层数分别为2、3、5层。不同网络层数与其对应的隐层节点数如表2所示。
以X代表输入节点, 2层层数的网络结构为X-600-300, 表示第一隐层节点数为600, 第二隐层节点数为300。依此类推, 3层隐层网络结构的隐层节点数依次为600、300和100; 5层隐层网络结构的隐层节点数依次为2 000、1000、500、200和100, 此网络结构只针对特征维数4 000以上的数据集。由于本实验目的为预测评论文本的极性, 只有一个值, 故输出节点个数为1。
深度信念网络训练过程中的参数设置如下: 限制波尔兹曼机的动量为0.9, 学习速率为0.01, 微调部分的激活函数为Sigmoid函数, 学习速率为0.9, 动量为0.5。BP算法进行微调的迭代次数为50, 其他为深度学习工具箱默认参数。
采用浅层网络包含1层隐层的BP网络作为对比实验, 网络结构为X-600。网络迭代次数为50, 其他参数为深度学习工具箱默认参数。
所有实验均在一台惠普LV2011的台式计算机上完成, 其基本的软硬件配置为: Intel(R) Core(TM) i5-2400 CPU @3.10 GHz; 8.00GB RAM; Windows 7 旗舰版64位操作系统; Matlab R2014a。
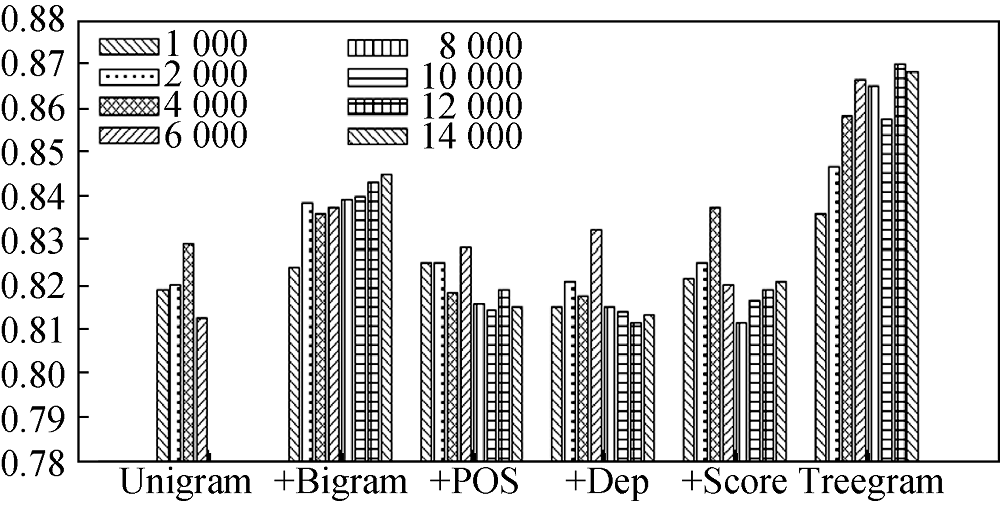
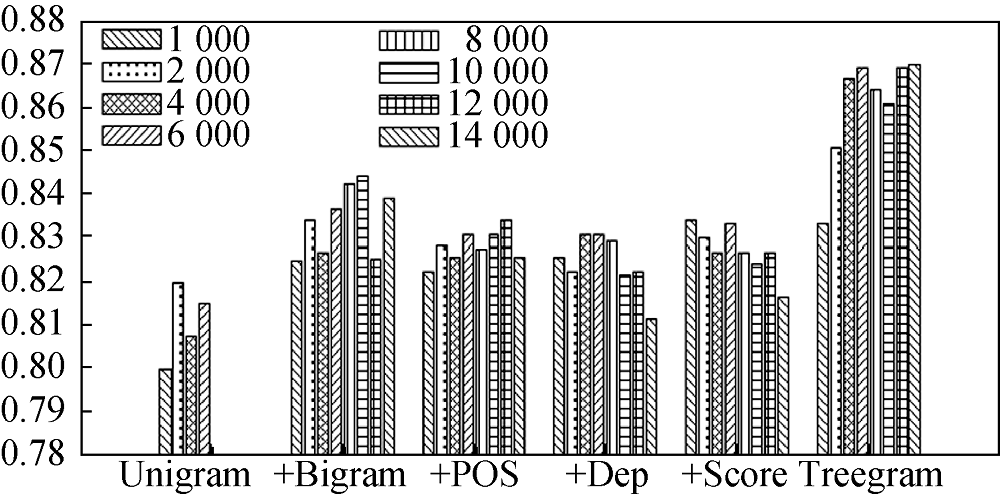
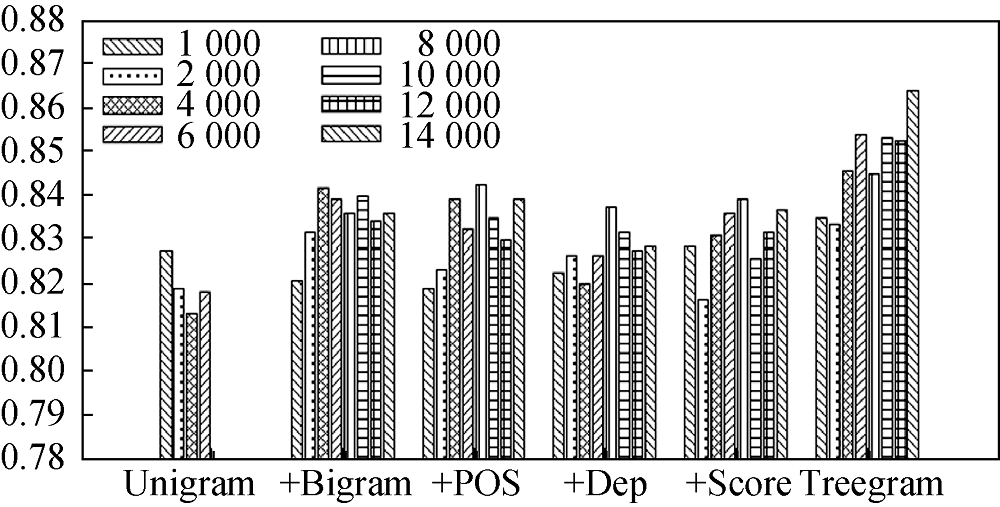
(1) 不同类别特征集对分类准确率的影响
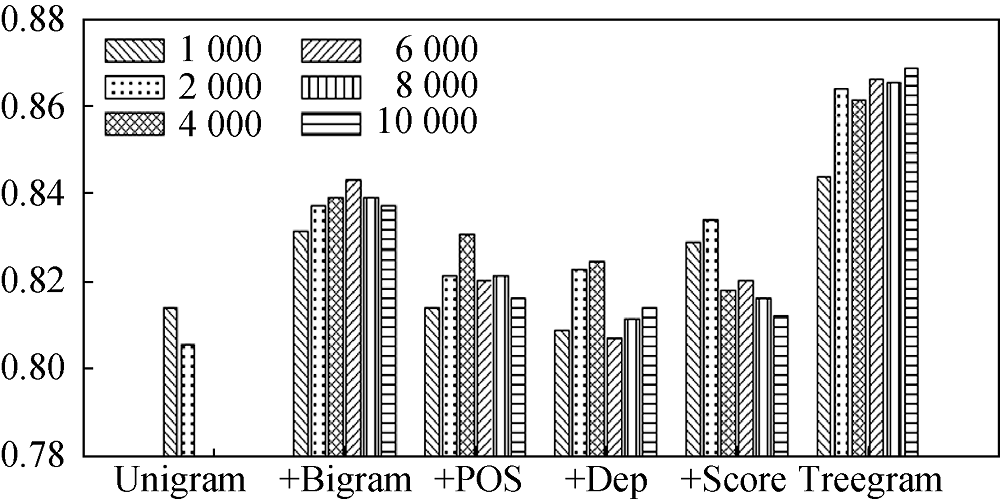
将6种类别特征集(Unigram、+Bigram、+POS、+Dep、+Score、Treegram)分别用于4种不同网络结构: DBN:X-2000-1000-500-200-100、DBN:X-600-300-100、DBN:X-600-300、BP:X-600。对应网络结构中不同类别特征集下的分类准确率如图5-图8所示。
通过对图5-图8中不同特征集得到的结果进行分析, 计算不同特征集平均分类准确率的大小, 得出结论: 无论是多个隐层的深度信念网络还是一个隐层的BP网络, 三元组依存关系特征都取得了较高的分类准确率, 一元词和二元词的组合特征效果其次, 效果最差的特征表示是仅用一元词特征。考虑到深度学习的特征学习能力, 这进一步说明三元组依存关系特征中蕴含丰富的文本信息, 在文本情感分类特征表示中优势明显。
(2) 特征维数对分类准确率的影响
为分析特征维数对分类准确率的影响, 将各网络结构中在相同输入维数下的不同类别特征得到的准确率的平均值进行比较, 结果如表7所示。
表7中, 最高分类准确率与输入维数并没有呈现明显的规律性。因此得出结论: 网络维数对分类准确率的影响不大, 但网络运行时间随着输入节点的增多而增长。在选择输入节点个数时, 应在保证分类准确率的情况下, 适当地选择较小的特征维数。
(3) 网络层数对网络性能的影响
网络层数与网络性能之间的关系通过网络训练过程中得到的重构误差进行分析。
表4、表5、表6中, 第一层重构误差与输入节点有关, 输入节点多则第一层重构误差大。大多数深度信念网络的重构误差随着网络层数的增加而减少, 但在5层深度信念网络中, 第4层重构误差比第3层大。对5层深度信念网络出现的例外进行分析发现, 并不是网络隐层层数越多, 分类准确率就越高。网络层数的增加会导致运行时间的增长。因此, 在设置网络结构时应视具体情况而定。
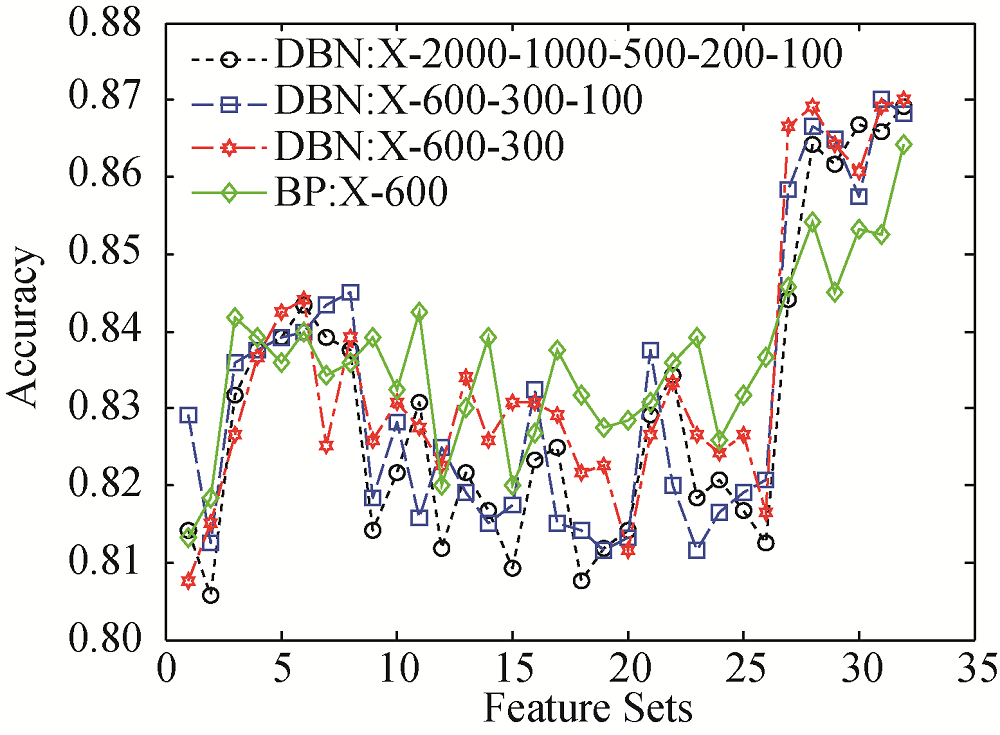
(4) 深度信念网络与BP网络的分析
①准确率分析
将不同层数的深度信念网络结构与BP网络的分类准确率进行比较, 比较不同输入节点上的准确率大小。选择4 000维数以上特征的分类结果, 共有32个数值, 结果如图9所示。
图9中深度信念网络结构分类准确率在各输入节点上趋势基本一致。BP网络中三元组依存关系特征的分类准确率(图9中28-32节点对应分类准确率)明显低于深度信念网络。鉴于依存关系特征的复杂性, 说明BP网络在复杂特征下的学习能力不及深度信念网络。
②收敛性分析
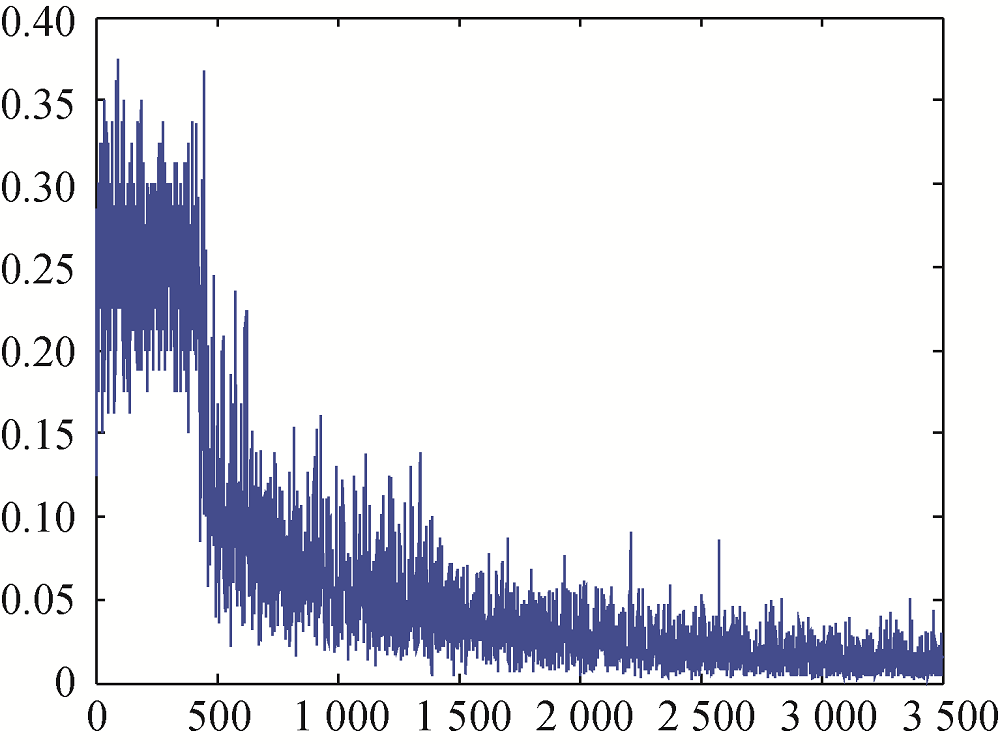
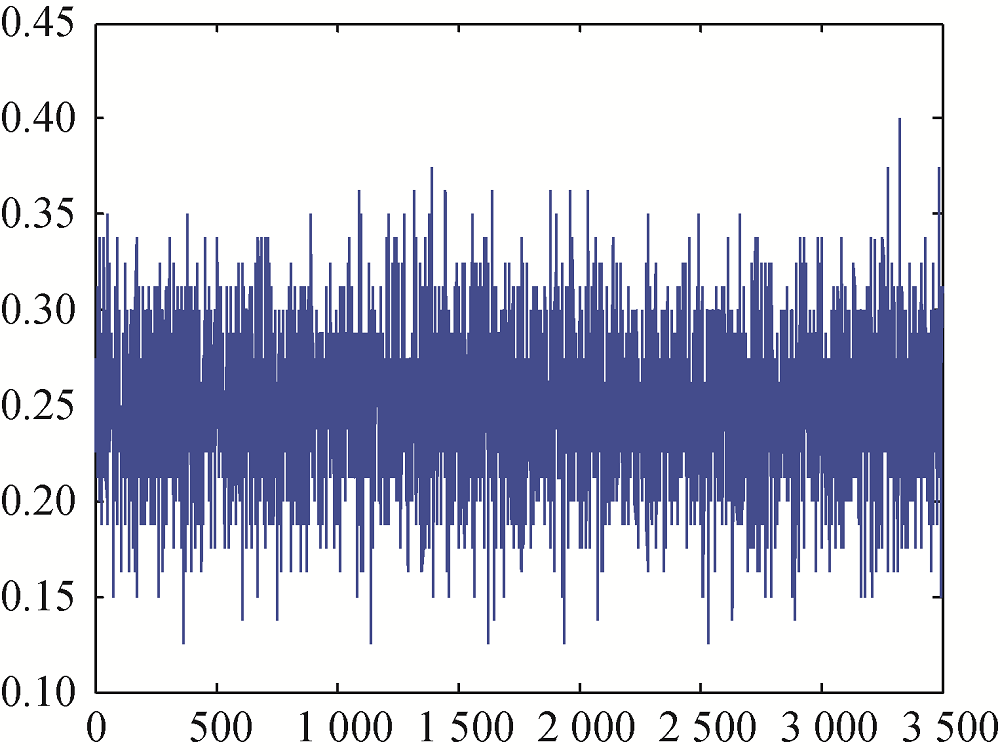
在训练过程中, 由于BP网络权重分配的随机性, 易陷入局部极小, 导致计算不收敛。在本次实验中, BP:X-600没有收敛的比例达4.5%。BP网络收敛与不收敛两种状态的分类准确率误差如图10和图11所示。
(5) 与其他相关研究的比较
在分类准确率上, 与其他相关研究进行比较, 文献[9]将深度信念网络与词向量特征进行结合, 用于韩语政治文章的检测, 准确率为81.8%。本文将依存关系特征与深度信念网络结合, 用于中文的文本情感分类, 准确率为86.2%。分类准确率除了受所用特征影响, 还与网络结构的设置、语料相关。要得到具体影响分类准确率的因素, 还需要进行更多设置相同控制变量的实验。
通过上述对数据结果的分析比较, 得出结论:
(1) 各特征及特征组合用于深度信念网络进行文本情感分类任务时, 三元组依存关系特征分类准确率最高, 其次是一元词和二元词的组合特征。证明了三元组依存关系特征在文本情感分类任务中用于文本表示的优势。
(2) 在设置深度信念网络的网络层数时, 并不是网络层数越多, 分类准确率越高, 要根据具体情况并结合网络训练时间而定。
另外, 本文实验对象为中文电子商务网站评论数据, 较西方语言在文字处理上更为复杂, 在语言特点上有明显不同, 且深度学习在中文情感分类研究中较少。深度学习用于中文文本情感分类中的网络结构及参数还需要进一步研究。
深度信念网络在文本情感分析领域的应用目前还没有系统的研究。本文选取一元词、二元词、词性、简单依存关系、情感得分和三元组依存关系特征用于深度信念网络, 通过设置不同特征集、不同网络深度、不同学习算法研究特征及其组合对电子商务网站评论文本情感分析结果的影响, 研究不同特征集对分类准确率的影响、同一特征集不同维数对分类准确率的影响、网络深度对分类准确率的影响、深度信念网络与BP网络对分类准确率的影响这4方面的问题。实验结果表明, 三元组依存关系特征表示方法在大多数网络结构中有较好的结果, 分类准确率并不会随深度信念网络层数的增多而增加, 网络层数的设定要根据具体情况并结合网络训练时间而定。
本文通过深度信念网络在文本情感分析中的过程研究与性能分析, 验证了深度学习对复杂任务有很强的学习能力, 为深度信念网络进行情感分类任务时的参数选择和模型设置提供了参考。其他深度学习模型的实验还没有得到实现和比较分析, 这是下一步研究方向。
张庆庆: 设计研究方案, 执行实验, 撰写论文;
贺兴时: 提出研究思路;
王慧敏: 实验结果分析;
蒙胜军: 论文修改和修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: suiyue2959@163.com。
[1] 张庆庆. hotel4000.xls. 酒店评论数据.
[2] 张庆庆. book2000.xls. 图书评论数据.
[3] 张庆庆. notebook1000.xls. 笔记本电脑评论数据.
[4] 张庆庆. Features.java. 三元组依存关系特征抽取程序.
[5] 张庆庆. DBNlearning.m.深度信念网络训练程序.
[6] 张庆庆. BPnet.m. BP网络训练程序.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}