
|
|

 , 张婷婷
, Zhang Tingting
, 张婷婷
, Zhang Tingting
【目的】针对大众性问答社区答案质量参差不齐的现状, 对答案质量排序方法进行探讨。【方法】依据信息接受模型, 从感知价值角度构建答案质量排序初始指标体系; 采用K-Medoids聚类算法对初始指标进行离散化, 同时利用粗糙集理论对初始指标进行约简并赋予权值, 进而修正指标体系; 运用加权灰色关联分析计算答案的加权灰色关联度, 以产生排序结果。【结果】针对“知乎”6类话题下6个问题的2 297条相关数据进行实验分析, 排序靠前的答案通常采用图文结合的表达方式、答案所含信息量高, 且回答者社区参与度较高, 从而答案的质量较高。【局限】数据规模需要扩大, 对排序方法的评价还可以优化。【结论】73名“知乎”用户对原始排序与本研究排序进行满意度评价, 结果表明本文方法具有优越性。
[Objective] This paper proposes a new method to rank the quality of answers from a popular Q&A community in China. [Methods] First, based on the information acceptance model, we established initial quality indicators for the answer’s perceived values. Then, we discretized these indicators with the K-Medoids clustering algorithm. Third, we reduced and weighted the indictors with the help of rough set theory. Finally, we generated the formal rankings with the weighted grey correlation analysis. [Results] We evaluated the proposed method with 2 297 answers for six different types of questions from the Q&A website of “Zhihu”. We found that the answers ranked higher generally included textual message with images. These answers were also more informative than others and involved active members of the Q&A community. [Limitations] The size of our dataset needs to be expanded, and the evaluation method of the proposed model could be optimized. [Conclusions] The proposed method is an effective way to rank the quality of answers from the Q&A community.
大众性问答社区作为一种综合类的生产型知识源, 已经成为用户快速获取知识的重要来源之一。然而, 大众性问答社区的答案由用户创造生成, 而用户却并不一定是某个领域的专家, 因此答案质量参差不齐, 从而引发“知识泛滥”、“知识过载”等问题。科学的知识组织有利于用户快速获取优质答案、减轻认知负担, 从而增加用户黏性。由此, 作为大众性问答社区知识组织的重要方式之一, 答案质量排序便成为实践领域和研究领域共同关注的重要问题。例如, 作为国内知名的大众性问答社区, “知乎”引入“投票机制”, 通过答案的点赞数和反对数结合威尔逊得分算法对答案质量进行排序, 取得了一定效果[1]。但是, 大众性问答社区的社交属性会造成“投票机制”失灵。当用户回答了某个问题时, 其关注者很有可能为其回答点赞。回答者的关注人数越多, 答案所收到的点赞数越多。同时, 当用户遇到与自身观点相异的回答或许也不会吝惜自己手中的反对票。因此, 仅依据点赞数和反对数进行答案质量排序存在一定局限性。此外, 通过梳理国内外相关文献, 已有研究在答案质量评价因素、答案质量评价方法、实验研究对象选择等方面均存在一定优化空间。由此, 本文在“知乎”社区已有答案质量排序方法和国内外相关研究成果的基础上, 提出一种新的答案质量排序方法, 以期对大众性问答社区知识组织研究进行有益补充。
从研究现状来看, 答案质量排序方法主要有三种类型。
(1) 人工方法, 即依据答案质量评价因素, 通过人工方式进行评分。例如, Fichman从准确性、完整性、可证实性等三个方面采用人工打分的方式分析Askville、WikiAnswers、Wikipedia Reference Desk、Yahoo!Answers等4个问答社区的答案质量[2]; Shah等雇佣了5个工作人员, 按照Zhu等提出的13维度质量评估模型(包括相关性、信息量、完整性等)[3]对Yahoo! Answers的答案质量进行评估[4]。
(2) 语义模型方法, 即通过构建主题模型、语言模型[5], 挖掘问答内容中隐含的主题及其概率分布, 发现问题和答案之间的语义关系, 从而实现答案质量排序。例如, Yang等以Stack Overflow为实验研究对象, 利用TEM(Topic Expertise Model), 引入用户之间的链接关系, 得到用户的兴趣分布和专业程度, 进而通过答案主题相似性和用户权威度对候选答案进行排序[6]; 刘瑜等在此基础上进一步提出RTEM (Related Topic Expertise Model)[7]; 张成等利用概率潜在语义分析(Probabilistic Latent Semantic Analysis, PLSA)模型表达用户兴趣分别, 进而依据答案和问题之间的主题匹配度对Yahoo! Answers中的答案进行排序[8]; Guo等利用LDA-DF主题模型发现问题和答案的主题分布、用户的潜在主题兴趣, 然后将这些结果融入到已有答案质量排序方法中以提高Yahoo! Answers的答案质量排序效果[9]; 来社安等通过计算答案和问题中语言“单位”之间的相似度和对应的权值, 引入HITS算法模型对权值进行调整, 提出一种基于相似度的答案质量评价方法, 并以百度知道为例进行实验分析[10]。
(3) 分类模型方法, 即利用支持向量机、决策树、逻辑回归、随机森林等方法对答案质量评价因素进行实验分析[11], 以产生答案质量分类模型。例如, Ginsca等通过分析Stack Overflow中用户特征(如年龄、自我描述、个性肖像等), 利用支持向量机构建分类器筛选出高质量答案[12]; 孔维泽等综合考虑基于时序的特征、基于问题粒度的特征、基于百度知道特性的用户特征和经典的文本、链接特征, 采用支持向量机构建答案质量分类模型[13]; 姜雯等提取Yahoo! Answers中答案的文本特征、用户特征、时序特征等, 并提出附加情感标注的回答特征, 利用决策树实现了信息质量自动化分类预测[14]; John等以Yahoo! Answers为实验研究对象, 利用逻辑回归构建包含社会特征、文本特征以及内容评价特征为指标的质量分类框架[15]; 李晨等通过提取百度知道中答案文本与非文本特征, 利用逻辑回归构建答案质量分类器[16]。
国内外学者围绕问答社区答案质量评价问题已经展开了积极探索, 并取得了一定进展, 但是还存在一定拓展空间。
(1) 从答案质量评价因素来看, 人工方法主要利用答案质量评价因素, 语义模型方法主要关注答案特征维度指标, 分类模型方法中部分学者仅考虑回答者维度指标或答案维度指标, 还有部分学者综合利用回答者维度和答案维度的相关指标。考虑到用户利用问答社区获取知识是为了解决其现实问题, 所以在分析答案质量评价因素时应该以用户对于答案解决其现实问题的感知价值为核心。依据信息接受模型的基本结论[17]: 影响用户感知价值的因素为信息质量和信息源可靠性。前者对应答案特征维度, 后者对应回答者特征维度。所以, 答案质量评价因素应该综合考虑答案和回答者两个角度。此外, 在分析评价因素时, 并没有充分考虑各种指标对于答案质量评价的重要程度, 从而影响排序方法的精确度。
(2) 从答案质量评价方法来看, 人工方法主观性较强, 效率较低; 语义模型方法比较适用于内容丰富的文本, 而问答社区中很多问答内容属于短文本; 分类模型方法将答案质量高低视为二分类问题, 从而影响了分类模型的适用性。
(3) 从实验研究对象选择来看, Yahoo! Answers等国外问答社区是实验研究数据的重要来源, 国内百度知道也有部分学者研究, 而国内较为知名的其他问答社区相对较少。显然, 不仅国内外问答社区之间存在明显差异, 而且国内不同问答社区也有各自的重要特性, 因此, 不同的问答社区会对答案质量评价有着特定的要求。
针对以上不足, 本研究选择国内知名大众性问答社区“知乎”为研究对象, 从答案特征和回答者特征两个维度提炼影响答案质量排序的初始指标体系, 并利用粗糙集理论客观分析初始指标的重要程度, 同时通过知识约简的方法剔除冗余属性以进一步修正指标体系, 最后利用加权灰色关联分析对答案质量进行排序。
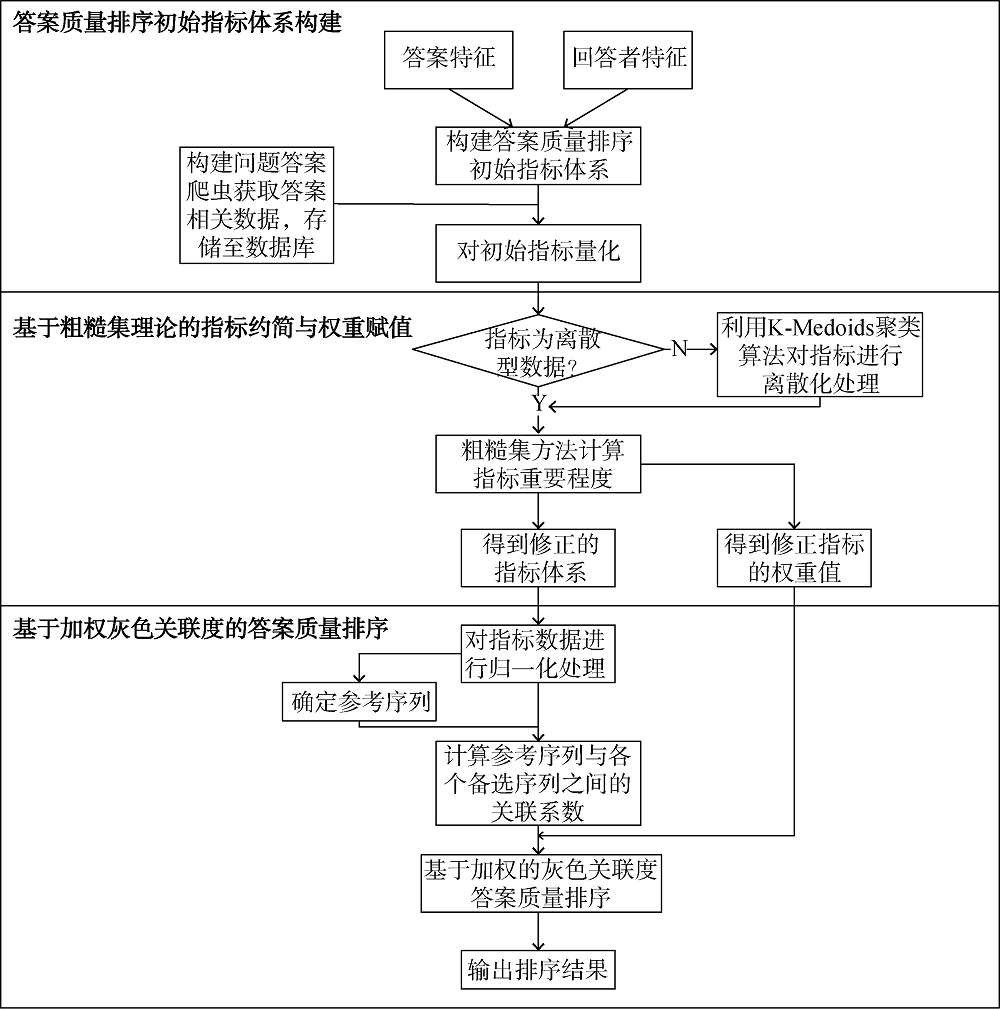
答案质量排序方法的基本流程如图1所示, 主要包括三个模块: 答案质量排序初始指标体系构建、基于粗糙集理论的指标约简与权重赋值、基于加权灰色关联度的答案质量排序。
依据信息接受模型, 本研究从感知价值角度综合考虑答案特征、回答者特征, 选取14个指标形成答案质量排序初始指标体系, 具体如表1所示。
粗糙集理论的权重确定方法优点是可以在不需要任何先验信息的情况下完成权值计算, 且粗糙集理论提供的知识约简可以在保留关键信息的前提下对大量数据进行挖掘得到知识的最小表达[21]。依据粗糙集理论, 在对指标赋权值之前, 需要对数据进行离散化处理。连续数据离散化应尽可能满足两点: 连续属性离散化后的空间维数应尽可能小, 连续属性值离散化处理丢失的信息应尽量少[22]。
(1) 数据离散化
连续数据离散化算法很多, 如等宽区间法、等频区间法、聚类法、信息熵法等。结合“知乎”社区特点以及各种方法的优势, 本研究采用基于K-Medoids算法的数据离散方法[23], 使用的聚类评价指标是DB指数(Davies-Bouldin Index)[24]。需要指出的是, 本研究对连续属性是逐一进行离散化的, 而且对每个指标进行探索性聚类分析。通过计算每个指标不同
(2) 粗糙集定权
完成数据离散化处理之后, 根据波兰数学家Pawlak提出的粗糙集理论对指标进行约简和赋值[25]。假设初始指标体系由
根据粗糙集理论中属性重要性的概念, 定义指标
${{\omega }_{r}}=\frac{\left| po{{s}_{P}}(Q) \right|-\left| po{{s}_{P-\left\{ r \right\}}}(Q) \right|}{\left| U \right|}$ (1)
其中,
指标r的权重系数计算方法如公式(2)[26]所示。
${{\lambda }_{r}}=\frac{{{\omega }_{r}}}{\mathop{\sum }_{i\in P}{{\omega }_{i}}}$ (2)
灰色关联分析法[27]其原理是将各个答案的属性值与选定的理想值进行对比, 即利用加权的方法测量两个向量的相似度, 和理想答案相似度越高的答案将排序在前, 具体步骤如下:
(1) 对决策信息进行规范化处理。由于各个指标的量纲和数量级不同, 因此在数据分析之前, 需要对数据进行规范化处理。指标主要分为效益型、成本型以及固定型指标。其中, 效益型指标值越大越好, 成本型指标值越小越好, 固定型指标维持某一个数值最好。故对效益型、成本型以及固定型指标原始数据处理如公式(3)-公式(5)[28]所示, 将决策的评价矩阵$A={{({{\alpha }_{ij}})}_{m\times n}}$标准化为属性值具有相同指向的决策信息矩阵$R={{({{r}_{ij}})}_{m\times n}}$。
对于效益型指标的属性值, 有:
${{r}_{ij}}=\frac{{{\alpha }_{ij}}-\underset{i}{\mathop{\min }}\,{{\alpha }_{ij}}}{\underset{i}{\mathop{\max }}\,{{\alpha }_{ij}}-\underset{i}{\mathop{\min }}\,{{\alpha }_{ij}}}$ (3)
对于成本型指标的属性值, 有:
${{r}_{ij}}=\frac{\underset{i}{\mathop{\max }}\,{{\alpha }_{ij}}-{{\alpha }_{ij}}}{\underset{i}{\mathop{\max }}\,{{\alpha }_{ij}}-\underset{i}{\mathop{\min }}\,{{\alpha }_{ij}}}$ (4)
对于固定型指标的属性值, 有:
${{r}_{ij}}=1-\frac{\left| {{r}_{ij}}-r \right|}{\underset{i}{\mathop{\max }}\,\underset{i}{\mathop{\max }}\,\left\{ \left| {{r}_{ij}}-r \right| \right\}}$ (5)
其中,
(2) 确定参考序列。确定理想方案数列的原则是在各个指标下选择最优的方案, 以此为参考标准, 其决策信息组合成为理想方案数列。具体而言, 选取答案质量排序指标的最优值作为参考序列${{R}_{o}}=\left\{ {{r}_{o1}},{{r}_{o2}},\cdot \cdot \cdot ,{{r}_{on}} \right\}$, 其中
(3) 计算各个备选方案的决策信息数列与最优方案的数列距离${{\Delta }_{ij}}$, 如公式(6)[27]所示。
${{\Delta }_{ij}}=d{{({{r}_{oj}},{{r}_{ij}})}_{{}}}i=1,2,\cdot \cdot \cdot ,m\mathrm{;}j=1,2,\cdot \cdot \cdot ,n$ (6)
(4) 计算两数列距离的最大值$({{\Delta }_{\max }})$和最小值$({{\Delta }_{\min }})$如公式(7)-公式(8)[27]所示。
${{\Delta }_{\max }}=\underset{i,j}{\mathop{\max }}\,{{\Delta }_{ij}}$ (7)
${{\Delta }_{\min }}=\underset{i,j}{\mathop{\min }}\,{{\Delta }_{ij}}$ (8)
(5) 计算理想方案的决策信息数列与各个备选方案数列之间的关联系数, 如公式(9)[27]所示, 即形成两数列的关联系数矩阵${{({{\xi }_{ij}})}_{m\times n}}$。
${{\xi }_{ij}}=\frac{{{\Delta }_{\min }}+\rho {{\Delta }_{\max }}}{{{\Delta }_{ij}}+\rho {{\Delta }_{\max }}}$ (9)
其中, $\rho \in \left[ 0,1 \right]$表示加权灰色关联分析的分辨系数, 通常$\rho =0.5$。
(6) 计算理想方案的决策信息数列与各个备选方案数列之间的关联程度
${{r}_{i}}=\underset{i=1}{\overset{n}{\mathop \sum }}\,{{\xi }_{ij}}{{\lambda }_{j}}$ (10)
(7) 根据加权灰色关联度大小进行排序, 从而实现答案质量排序。
选取“知乎”社区的法律、互联网、健康、教育、经济学、历史6个话题, 并在每个话题下随机选择1个问题, 共6个问题及其答案构成本文的研究数据。爬取这6个问题下的2 297条回答及其相关信息。每条记录包括答案内容、答案发布时间、回答者昵称、回答者所获点赞数、回答者所获感谢数、回答者被收藏数、回答者回答问题数、回答者粉丝数、回答所对应的题目、问题发布时间、答案在“知乎”问题下的排名等内容。由于有的用户账号被知乎社区停用, 因此无法获取其个人信息, 故删除此种无效数据。实验数据如表2所示。对数据进行清洗, 按照上文方法对指标分别进行量化。
考虑到“知乎”社区中问答页面每次只显示20条答案, 因此选取每个问题的前20条答案进行重排序。对某个问题下的所有答案进行离散化处理。以互联网问题为例, 根据K-Medoids聚类结果和评价指标确定指标的聚类
对6个问题数据进行离散化处理, 不同问题下指标数据分布所需离散类别统计结果如表4所示。
根据公式(1)、公式(2)计算各项指标的权重, 6个问题下不同指标的权重值如表5所示。6个问题下的答案所获点赞数、回答者粉丝数、回答者所获点赞数、回答者所获感谢数以及回答者所获收藏数等5个指标的权重系数基本为0, 说明其为冗余指标, 可以删除。此外, 不同问题下的指标受其问题类型、问题答案量、回答者等因素影响, 相同指标的权重值有所不相同, 但在平均权重值上下小范围波动。由此, 可以判断不同“知乎”问题下答案质量排序指标的重要程度具有一定共性, 所以本研究以不同问题下指标权重均值表示所构建指标的一般权重。修正后的9个指标按照平均权重大小排序为: 答案情感值、答案时效性、回答者回答问题数、答案长度、答案信息熵、答案评论数、是否包含图片、答案中心度、是否包含外部链接。
利用加权灰色关联分析依次计算同一问题下前20条答案中每个答案与参考序列的关联度。以互联网问题为例, 参考序列为$Y=\{1,1,1051,5,4715,9.07,$ $20.82,0.33,3783\}$, 第一条答案序列${{X}_{1}}=\{0,0,451,22,$, $403,6.85,10.33,0.09,19\}$利用公式(3)至公式(5)对比较序列
${{{X}'}_{1}}=\{0.0,0.0,0.427,0.020,0.080,0.617,0.429,0.273,0.001\}$
${Y}'=\{1.0,1.0,1.000,1.000,1.000,1.000,1.000,1.000,1.000\}$
利用公式(9)计算各个点之间的关联度:
${{\gamma }_{1}}=\{0.333,0.333,0.467,0.962,0.352,0.536,0.451,0.458,0.334\text{ }\!\!\}\!\!\text{ }$, 最后利用公式(10), 根据平均指标权重$\overline{\lambda }=\{0.063,$ $0.031,\text{ }0.066,\text{ }0.208,\text{ }0.087,$$0.075,\text{ }0.059,\text{ }0.225,\text{ }0.142\}$, 求得互联网问题下第一条答案与参考序列
以QQ、微信、邮件等方式向具有“知乎”使用经验的用户发送调查问卷。调查问卷包括6个问题下本研究排序和知乎排序结果以及用户满意度评价表。评价表需要被调查者根据回答的相关性、回答的信息量、回答的说服力、回答的有用性等4个方面对排序结果分别给出分值(0-10)。分值越高表示用户的满意度越高。共发放问卷107份, 回收有效问卷73份。73名被调查者对“知乎”社区原始排序结果和本文排序结果的满意度评价均值如表6所示。统计结果表明, 本文排序结果在4个方面均优于“知乎”原有排序结果, 从而表明本文方法的优越性。
本研究以“知乎”为例, 从感知价值角度综合考虑答案特征和回答者特征构建答案质量排序初始指标体系, 利用粗糙集理论客观分析答案质量排序初始指标的重要程度, 同时通过知识约简剔除冗余属性以进一步修正指标体系, 最后利用加权灰色关联分析进行答案质量排序。实验结果表明, 在本研究中排序靠前的答案, 一般图文结合便于用户理解, 答案所含信息量高, 且回答者社区参与度较高, 更符合用户的信息需求。然而, 本文的研究也存在一定缺陷。相比于“知乎”海量的问答数据, 仅以6个话题下各随机选取了1个问题的2 297条相关数据进行实验分析, 数据规模略显不足, 需要在今后的研究中进一步扩大实验数据规模。此外, 排序方法评价主要依据用户的主观满意度调查, 缺少与不同排序模型(如SVMRank)的客观比较, 这将是今后研究的重点。
易明: 提出研究思路, 设计研究方案, 论文最终版本修订;
张婷婷: 数据采集与清洗, 进行实验, 起草论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 708966821@qq.com。
[1] 张婷婷. Dataset.csv. 知乎问答数据.
[2] 张婷婷. Resut.csv. 评价结果数据.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |

{kind=link}
{kind=link}