
|
|

 , 赵文辉, Zhao Wenhui
, 赵文辉, Zhao Wenhui【目的】通过多视图协同可视化的方式对时序文本挖掘过程进行可视化, 以实现多角度多层面洞察文本数据背后隐藏的规律和信息。【方法】基于文本词向量矩阵, 对多政策主体的政策时序文本, 通过数据清洗、计算TF-IDF值、构建向量空间模型、奇异值分解等文本挖掘技术进行信息提取和可交互的可视化探索分析。【结果】选取2016年1月-2017年8月北京市中关村示范区下属子园区的相关委内信息文本为样本, 采用文本挖掘技术和多视图协同可视化方法, 探索政策文本背后的规律, 验证了本文方法和框架的有效性。【局限】针对大规模文本具体细节单数据点的展示效果不佳, 文本挖掘技术有待进一步提升, 模型数据吞吐量有待基于大数据架构进一步增强。【结论】本文方法和框架能够对时序文本类数据做到充分的挖掘展示, 更好地把握数据背后的信息, 增强政策主体的决策依据。
[Objective] This paper visualizes the text mining process through multi-view collaborative technique, aiming to identify the patterns and insights more effectively. [Methods] Based on the textual word vector matrix, we processed the texts of multi-policy subjects with data cleaning, TF-IDF calculation, vector space model, singular value decomposition and other methods. [Results] We examined effectivenesss of the proposed model with governmental information from Zhongguancun of Beijing during the period of January 2016 to August 2017. [Limitations] The framework could not visualize the single data points of large-scale texts. [Conclusions] Multi-view collaborative visualization is an effective way to interpretate text message.
随着网络的飞速发展, 人们获取信息变得更为简便, 信息数量也越来越多, 但是使用传统的检索和阅读方式从大量复杂信息中获取有用信息变得更为困难。据统计, 当前非结构化数据占数据总量的80%, 并将在2020年之前以44倍的速度迅猛增长。因此如何在有限时间内从大量的文本信息中快速了解信息内容以及信息之间的关系, 成为人们关注和研究的焦点。
政策分析最早起源于上世纪50年代, 由美国学者莱斯威尔和勒恩纳主编的《政策科学: 范围与方法的最近进展》一书中最早提出。本文的研究对象是政策时序文本数据或者时序文本类数据, 主要指特定主体某些关键信息按时间顺序排列的文本记录, 主体可以是单一主体, 也可以是多主体。政策类复杂文本一直都是关于文本信息类问题研究的重要难点, 大多对文本信息通过特征提取、构建向量空间模型并进行相关降维, 最终将处理好的数据进行可视化。对于时序类政策文本, 本文将挖掘过程借助多视图协同可视化技术展现, 选取北京市相关经济政策为样本进行文本挖掘, 一方面试图填补基于模型预测研究中对相关政策领域研究的空白, 并力图建立一套完整可行的时序文本数据基本分析框架, 为该问题提供新的分析角度和技术手段; 另一方面试图从大量文本数据中更好地把握有关经济政策的基本情况, 及其内部隐含主题词的分布和政策内含焦点演变, 通过多层次多角度分析挖掘和对比政策的变迁路径, 为决策者提供有价值的参考信息。
文本是政策类信息最基本的呈现形式。文本可视化主要是为人们理解复杂、异构的文本内容和内在规律时提供新的思路, 实现迅速有效理解[1]。从文本的内容角度可将文本可视化划分为基于词频统计、基于聚类算法和基于语义三类[2]。余红梅等提出依据可视化的对象是着眼于文本内部还是文本与文本之间, 将文本可视化又划分为“文本内可视化”和“文本间可视化”[3]; 唐家渝等提出将时间和其他信息相结合的可视化与其他基于多层信息的可视化, 研究包含时间、空间等属性的文本如何选择可视化手法[4]; 张伟研究具有时间和顺序属性信息的文本, 特别针对于文本内容有序演化特点的网络舆情数据[5]。Lin等采用TF-IDF技术抽取关键词进行可视化[6]。文本可视化发展前进的根本动力是人类理解文本信息的需求, 文档中的文本信息包括三个层级: 词汇、语法和语义[7]。现今文本可视化研究思路大多数是将文本看作一个词汇的集合, 通过词频处理得到文本包含的信息。
近年来, 政策类文本可视化的相关研究在不同的领域发展迅速。王璟等利用CiteSpace软件对WOS收录的2001年-2010年国际体育政策研究相关文献进行共引分析和共词分析[8]; 韩永君应用CiteSpace软件对数据进行文献共引分析和聚类分析[9]; 朱皆笑采用文献统计工具SATI等, 对近年来中国知网收录的教育治理现代化文献进行可视化分析[10]。综上, 已有研究局限在于使用固定几种可视化工具, 没有应用更加灵活的工具, 针对经济类政策文本的研究较少, 多是对于已有文献的综述类分析。
本文基于对政策时序文本价值的基本认识, 在政策时序文本价值挖掘的实现思路上主张将“挖掘目的、挖掘过程、结果展示”三者有机融合, 借助现有文本挖掘技术, 除了提出多政策主体时序文本的基本挖掘和展示设计的系统方案以外, 还通过编程语言Python对方案进行完整实现和验证, 极大地弥补了现有研究的不足。
在信息可视化中, 需要将原始数据通过视图的形式展示给相关用户, 处理相对复杂的数据集时, 只通过一个视图通常无法将数据的信息全面展示出来, 此时需要进行多视图协同可视化, 把握各个不同的角度进行展示, 因此多视图协同展示成为信息可视化的重要手段[11]。
陈谊等通过组合平行坐标、直方图以及矩阵图和散点图的结合, 取得了良好的农药残留数据分析效果[12]; 刘芳采用平行坐标、Treemap以及散点图同时对具有空间和多元性的统计数据进行有效的多角度分析[7]; 胡华全等在构建多视图可视化分析框架SatNetVis的基础上形成卫星时变拓扑视图, 对卫星网络可视化研究做出重要补充[13]; 刘明超等设计多视图协同可视化分析模型, 并在此基础上设计并实现Web环境下的犯罪实用可视分析模型, 可以从微观角度帮助破案人员进一步挖掘隐含信息[14]。
本文通过不同组件的不同功能, 实现相互之间的互补, 对数据进行属性维度、时间维度等多角度展示。在所处理过的数据中, 对部分数据进行数据子集可视化, 得到最终的多视图协同可视化。多个视图跨越了单一视图视觉通量限制的问题, 并通过Python对整个分析过程做一个完备的呈现。
在中国特色社会主义市场经济的大背景下, 结合当今互联网、大数据、人工智能的时代特点, 各行各业政策的制定者需要对经济社会发展中的各类问题以及自身政策特点、政策变迁路径等有清晰明了的认知, 还需要全面快速有效地把握其他相关行业的政策信息; 对于各类政策相关利益主体尤其是市场中的企业, 要谋求生存和发展, 也必须依靠对相关政策信息的有效获取、处理、认知和应用。所以, 各类决策者对于政策信息的形式、内容、载体提出了更高需求。具体地, 决策者对于政策信息的认知需求主要表现在以下方面。
(1) 对政策信息广度和深度的需求;
(2) 对政策信息认知准确度和效率的需求;
(3) 对政策信息载体、形式等的需求。
针对信息类型的划分在整个可视化过程中最为重要, 从政策文本信息类型的角度, 本文认为可以从两个角度进行划分: 基于政策主体和基于信息颗粒度的划分。基于政策主体的划分相对较为具象, 把特定政策发布者的信息归为一个类型, 方便构建可视化方案的理论框架, 比如本文不断提及的“政策主体”概念, 是针对信息类型的划分提出的; 具体面向可视化的方案设计, 基于信息颗粒度的划分显得尤其重要, 出于满足决策者对政策信息基本需求的初衷, 面向政策文本可视化方案的设计目的, 将政策文本的信息类型划分为以下类型: ①多政策主体政策文本序列整体信息; ②不同政策对比信息; ③不同语义对比信息; ④同一政策主体的政策变迁信息; ⑤不同政策主体的政策对比信息; ⑥特定政策详细信息。
基于上述面向可视化设计过程的对政策文本信息类型的基本划分, 本文结合多视图联动可视化技术, 提出政策文本可视化的通用解决方案, 以满足决策者对政策信息认知的基本可视化需求。
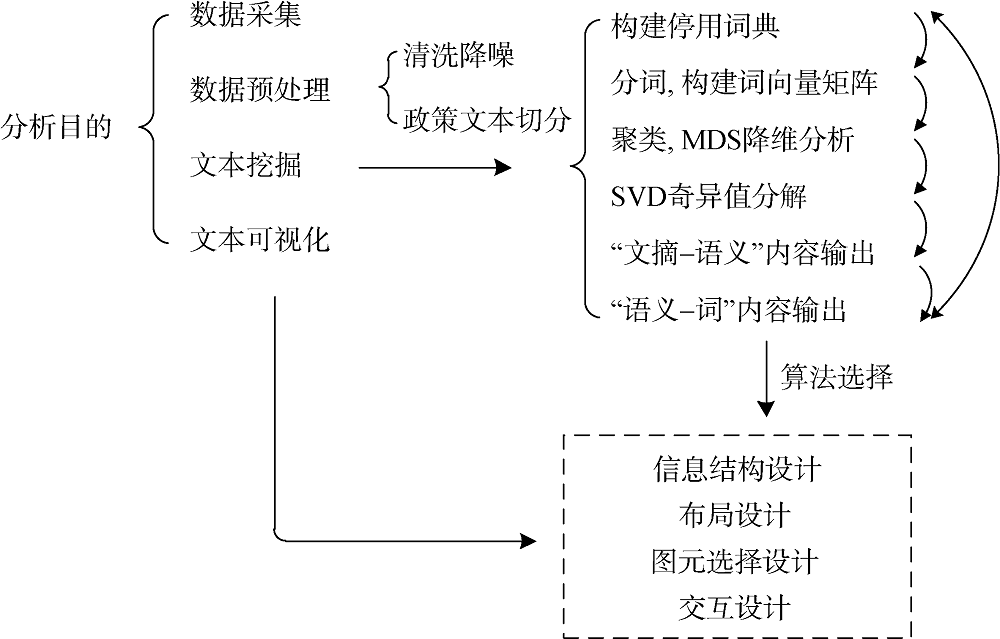
基于对政策时序文本的需求分析, 本文借助数据过滤以及相关TF-IDF词频计算、奇异值矩阵分解和MDS聚类等文本挖掘技术以及多视图协同可视化技术, 系统解决多政策主体时序文本挖掘和展示的问题。“挖掘目的、挖掘过程、结果展示”的有机融合, 指在挖掘过程设计和挖掘结果的展示上, 始终以政策信息的认知需求和可视化需求为指导和依据, 比如针对政策文本认知的广度和深度需求, 在挖掘过程中突出对政策文本进行主题和语义的提取, 才能真正解决认知的深度问题。从可视化的设计上来看, 可视化方案本身就是对于效率、信息载体、信息形式等需求的满足, 而可视化方案的信息结构设计、图元选择、界面布局设计、交互设计等环节是进一步细化和完善对各类需求的实现过程。此外, 在可视化界面信息结构的安排和设计上, 充分考虑信息认知过程的自然习惯, 对于信息认知过程的自然习惯考虑直接体现在数据挖掘流程的设置上, 比如先进行词向量矩阵构建、文本聚类以及MDS降维等整体性信息的挖掘, 再进行深入的语义挖掘过程。本文研究思路如图1所示。
(1) TF-IDF
TF-IDF方法的主要思想是: 一个词条如果在一篇文章中出现的频率(Term Frequency, TF)高, 在其他文章中很少出现, 则认为这一词条具备较强的类别区分能力。该方法在计算某文档集文本中词条频率的同时
也会考虑该词条在全部文档集文本中的出现频率, 认为在文档集中出现率中等词条的权重要高于出现率很高或者很低的词条。文档D中词条的TF-IDF权重计算方法如公式(1)-公式(3)所示[15]。
$t{{f}_{i,j}}=\frac{{{n}_{i,j}}}{\mathop{\sum }_{k}{{n}_{k,j}}}$ (1)
其中, ${{n}_{i,j}}$是词语${{t}_{i}}$在文档
$id{{f}_{i}}=\log \frac{\left| D \right|}{\left| \left\{ d:d\ni {{t}_{i}} \right\} \right|}$ (2)
其中, $\left| D \right|$是语料库中的文档总数, 分母是包含项{Invalid MML}的文件数目。
$tfid{{f}_{i,j}}=t{{f}_{i,j}}\times id{{f}_{i}}$ (3)
(2) MDS降维
输入相似程度矩阵, 在低维空间中找其对应的位置坐标, 通过欧氏距离计算两点间距, 根据距离判断其相似程度。MDS的核心思想为保留数据之间的相似度, 计算方法如公式(4)-公式(8)所示[16]。
设有
$\Delta =\left[ \begin{matrix} {{\sigma }_{11}} & \cdots & {{\sigma }_{\begin{smallmatrix} 1n \\ \end{smallmatrix}}} \\ \vdots & \ddots & \vdots \\ {{\sigma }_{n1}} & \cdots & {{\sigma }_{nn}} \\\end{matrix} \right]$ (4)
其中, ${{\sigma }_{ij}}=\sum\nolimits_{p=1}^{d}{\sqrt{{{\mathrm{(}{{r}_{ip}}-{{r}_{jp}}\mathrm{)}}^{2}}}}$为第
这些向量与原数据距离尽可能接近, 故其评价函数为公式(5)。
min$\sum\nolimits_{i<j}{{{(\left| {{x}_{i}}-{{x}_{j}} \right|-{{\sigma }_{ij}})}^{2}}}$ (5)
对矩阵$\Delta $的双重中心化矩阵进行奇异值分解得到降维后矩阵
$\hat{\Delta }$=-$\frac{1}{2}$
其中
${{\hat{\Delta }}_{ij}}$=-$\frac{1}{2}$(${{\sigma }_{ij}}^{2}$-$\frac{1}{m}\sum\nolimits_{k=1}^{m}{{{\sigma }_{ij}}^{2}+\frac{1}{{{m}^{2}}}}\sum\nolimits_{i=1}^{m}{{{\sigma }_{j\text{l}}}^{2}}+$ $\frac{1}{{{m}^{2}}}\sum\nolimits_{i=1}^{m}{\sum\nolimits_{k=1}^{m}{{{\sigma }_{lk}}^{2}}}$)=${{x}_{i}}\cdot {{x}_{j}}$ (7)
矩阵$\hat{\Delta }$是对称且半正定的, 对矩阵$\hat{\Delta }$进行奇异值分解如公式(8)所示。
$\hat{\Delta }=U\Lambda {{U}^{\text{T}}}=U{{\Lambda }^{\frac{1}{2}}}{{\Lambda }^{\frac{1}{2}}}{{U}^{\text{T}}}$ (8)
其中, $\Lambda $为$\hat{\Delta }$的特征值组成的对角矩阵,
(3) SVD分解
假设
其中,
其中,
为获得矩阵
本文提供政策时序类文本进行全面的整体性可视化分析的解决方案, 该方案的具体使用场景为: 政策路径演进对比分析、竞争对手市场战略分析等有持续性文本信息存在的场合。所使用数据属于按一定格式规范存在的电子文本文档。在数据预处理阶段, 为达到对多政策主体时序文本进行全面的整体性分析的目的, 将数据采集阶段得到的文本信息按照主体进行分类整理, 按主体构建单独的文件夹进行保存, 这一过程中同时完成数据清洗、文本分词、去停用词等相关操作。文本数据作为典型的非结构化数据, 采集完成以后, 往往杂乱无章, 需要从主体的角度具体分析各主体相关信息在采集文本中的分布规律, 然后按照一定规则对文本进行切分, 当前并不存在通用的不对文本信息分布规律做任何要求的将文本信息按主体切分的技术手段; 作为一种系统性的解决方案, 需要对输入文档主体信息分布格式做统一要求, 按照格式要求提供doc源文件数据, 便能得到文本挖掘结果, 否则需要重新实现文本切分等数据预处理阶段。
上述技术实现步骤如下:
(1) 根据文本分析主体和分析信息类型获取, 存储到工程目录下的“委内信息”文件夹下。
(2) 根据主体和文本发布时间切分doc文件内容, 通过正则表达式实现, 将切分后的内容以txt格式保存到对应主体所在的文件夹。
(3) 根据领域知识构建停用词典和自定义词典, 词典内容能达到文本分析目的即可, 将上述切分好的txt文件使用Python中第三方库jieba进行分词处理, 并将结果输出到同一文件夹下, 文件名不变。
文本挖掘阶段是整个方案的核心环节, 对时序类文本分析的完成度以及可视化设计起到决定性作用。文本挖掘过程需要解决两个核心问题: 挖掘内容以及挖掘技术。
(1) 挖掘内容由文本挖掘目的决定, 针对政策时序类文本数据挖掘的基本目的, 在第3节提出6类信息类型作为文本挖掘过程的挖掘内容, 第①、②、③、⑥信息类型主要用来满足多主体政策时序文本形成概览性的认识, 同时不牺牲政策的细节信息。
(2) 挖掘技术的问题, 可以采用有限的文本聚类、文本分类、文本语义提取等技术, 针对概览性认识的目的, 通过对文本聚类和文本语义提取结果进行表达, 再通过可视化技术使得特定类别文本的具体含义能够快速获取, 形成对文本内容的整体把握。针对文本聚类问题, 本文采取基于TF-IDF值的词袋模型基础上的K-means聚类, 为完成对聚类结果在二维平面的可视化表达, 需要对文档基于词袋数据进行MDS降维处理, 文本语义提取方面同样基于词袋模型, 使用经典的SVD算法进行语义提取。第④、⑤信息类型本质上是对文本语义提取结果的深入应用, 主要目的是在语义的抽象层面上快速处理大量文本信息, 是提升文本使用效率的根本解决办法。本节需要解决的核心问题是, 如何在现有挖掘技术基础上完成对政策内容深入挖掘以及政策路径变迁分析。通过充分应用语义提取结果, 对不同政策或者主体之间的文本内容进行语义层面的对比分析来实现, 对信息的可视化表达成为这一环节的关键。
具体实现步骤如下:
①将分词文档内容按照scikit-learn包中tfidf算法输入参数要求读入计算机内存, 运行算法, 得到tf矩阵和tfidf矩阵, 把各文档的词袋结果按源文档名以txt格式保存在相应的tf值和tfidf值文件夹下。
②使用scikit-learn库中的K-means方法对tfidf值文件夹中的文档进行聚类操作, 将聚类结果输出到指定csv文件中, 方便具体查看; 使用MDS算法对上述文档进行降维处理, 并保存结果变量。
③同样基于上述文档, 使用第三方库numpy中的SVD算法进行语义提取运算, 并保存结果变量。
文本可视化设计是对文本挖掘目的体现, 文本可视化设计和文本挖掘过程都由挖掘目的指导, 但文本挖掘更多是满足挖掘目的的大体方向, 而文本可视化设计则是对挖掘目的更详细的呈现。
政策时序类文本需要满足的认知需求是复杂多样的, 致使文本可视化设计的信息类型也复杂多样, 为此本文提出信息结构设计、布局设计、图元选择、交互设计的可视化设计流程和策略。其中, 信息结构设计要解决的问题是对文本挖掘过程产出信息进行有效整理, 需要对每一大类信息内部进行准确的结构设计, 以充分满足政策时序文本挖掘分析的基本需求; 布局设计是在信息结构设计的基础上, 对每一类信息进行界面布局, 一大类信息会采用一个可视化页面来表达, 页面的不同位置放置不同信息类型, 在布局设计的时候, 还需要考虑通过图元和交互表达信息的可能性, 减少界面的冗余性; 图元选择是指在布局设计的基础上, 对界面布局上的每一小类信息, 选择恰当的可视化元素进行表达; 交互设计是对界面布局设计、图元选择的有效补充和增强, 通过交互设计, 可以增强用户的探索欲望, 提升认知效率, 比如对于本文后续将会提到的在整体信息界面加入了解政策文本具体内容的需求, 若没有点击之后更新部分图表内容的交互操作, 通过其他的可视化设计手段无法达到理想效果。以本文样本数据为基础, 提出时序类文本可视化设计架构, 如图2所示。
最左边两列表示政策时序文本可视化过程中的信息结构, 其中第2列就是第3节提出的可视化的信息类型内容, 第1列表示将信息分为“政策文本挖掘的概览信息”和“政策特征信息”两大类。“政策特征信息”是对政策文本内容语义提取结果整合与重组以后得到的信息; 在具体的可视化视图界面中, 信息结构的“政策文本挖掘的概览信息”内容占据一个可视化界面, “政策特征信息”占据另一个可视化界面。第3列表示基于前述挖掘结果对信息结构的可视化信息实现, 第3列内容是对可视化信息内容的具体可视化图元映射, 图与图之间的交互关系, 通过图例中所示对应箭头表达, 基于单图的可视化交互内容。图2中绿色方框表示可视化的数据来源, 都是数据挖掘过程的产出结果。
文本挖掘可视化设计环节中的另一个挑战是文本挖掘结果的可视化工程实现, 一般情况下有两种解决办法: 一个是借助现有可视化工具进行结果的可视化设计, 另一个则是借助编程软件进行定制化程度更高的可视化设计。由于方案一具有自由度低、手动设置环节配置复杂等缺点, 在考虑到方案的统一性、协调性、完美性、使用便捷性等情况下, 采用Python进行可视化开发。在工程实现上, 本文的可视化开发主要借助Python语言中著名的Matplotlib包实现, 由于Matplotlib包中的可视化方式没有交互功能, 因此本文基于Matplotlib包开发交互功能, 比如折线图的Tooltips功能, 可以进行交互选择的菜单, 可以查看数据细节的动态三维散点图等。
本文调用中关村科技园2016年1月-2017年8月的委内信息, 委内信息主要是中关村科技园内各园区关于各类产业政策的实践反馈, 通过相关产业政策发布后企业自身部署后取得的成果反映企业对于相关产业政策的反应速度。例如: 2016年12月7日以“中关村软件园‘双创’工作取得积极成效”为题的文本, 主要介绍的是中关村软件园“双创”工作取得的积极成效, 具体通过企业数目的增加、投资金额的上升、总产值的升高、获奖科研的突破为具体结果突出“双创”政策对园区经济发展的正向拉动作用, 不仅促进企业的聚集和发展, 还有一大批新产品、新技术加速诞生; 2016年12月21日以“海淀区‘四个聚焦’加快推进全国科技创新中心核心区建设”从整个区的发展来看政策的施展情况。委内信息分别从企业层面、园区层面、行政区层面用具体的实践数据说明新政策发布带来的积极作用; 还通过不同产业的进步发展说明情况。
整体信息的可视化是指对文本挖掘结果和文本挖掘样本数据的基本呈现, 以快速形成对文本的全面认识。对整体信息的可视化设计就是要完成对上述内容的信息结构设计、可视化界面设计、可视化图元选择和设计、交互设计。为此, 本文对整体信息的可视化设计主要分为文档和词语基本内容和关系的可视化、基于MDS降维的政策文本聚类信息可视化、对政策文本整体所包含语义信息的可视化、对政策文本语义抽取结果可视化, 以满足第3节提出的前三条信息需求类型。整体可视化具象信息介绍如表1所示。
(1) 文档和词语基本关系的可视化
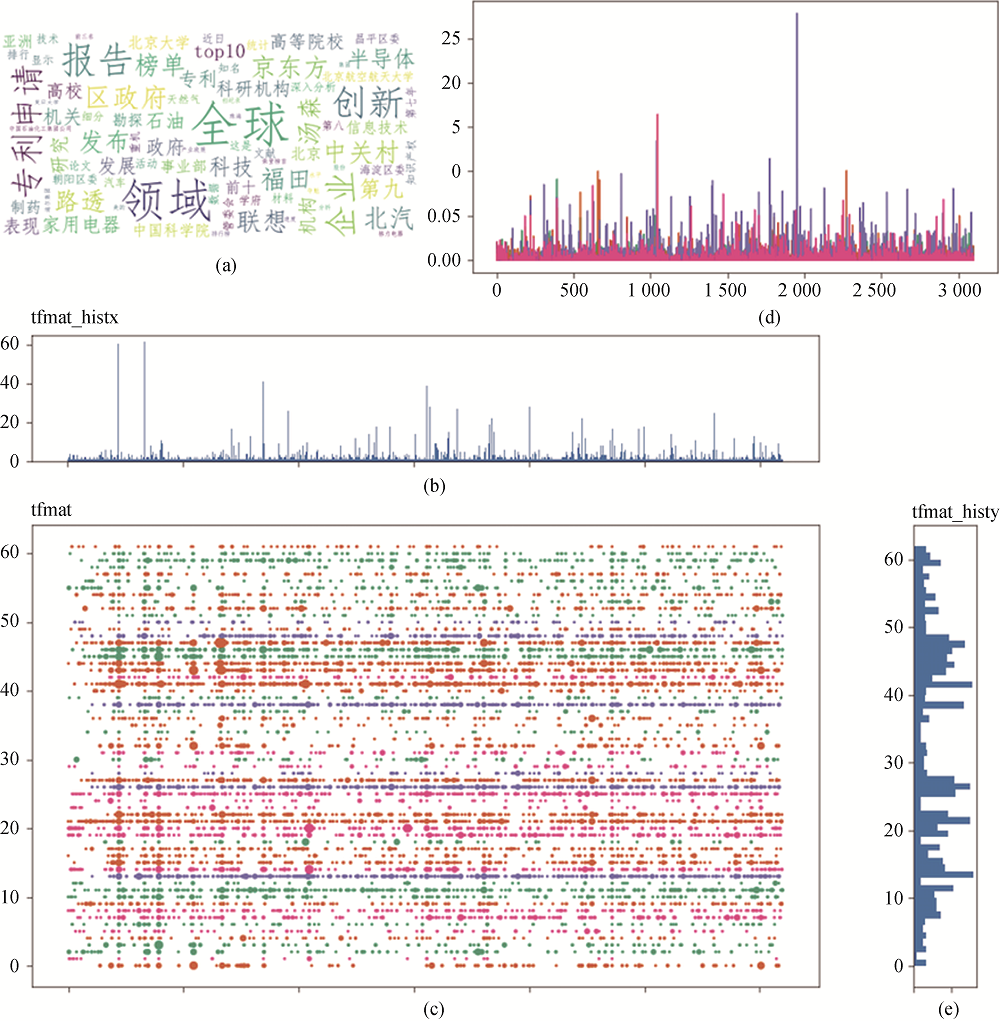
文档和词语基本关系的可视化如图3所示, 主要包括: 词频全文档分布信息(图3(a))、文档的含词量分布信息、各词语在文档中的分布信息、特定文档所包含的词语、各类型文档的区别信息、全部文档的相似性信息。
其中, 在图3(c)中, 气泡颜色表示文档所属的聚类类别, 气泡大小表示文档含词量, 横轴表示TF-IDF算法处理后形成的词语序号, 纵轴同样是经算法处理后形成的文档顺序, 考虑到坐标界面范围的有限性, 所有以词语为坐标轴的可视化图标, 轴的含义均与此处保持一致; 文档聚类中心折线图的颜色也表示聚类类别, 横坐标同样表示词语序号, 纵坐标则对应词汇对于聚类中心文档的信息量(TF-IDF值); 关于词频的相关统计全部基于去停用词以后经过TF-IDF算法得到的“文档-词频”矩阵, 文档聚类则是基于文档词向量矩阵(矩阵值取为特定词在相应文档中的TF-IDF值)运用K-means算法得到, 词云基于分词文档得到。
图3(c)、图3(b)以及图3(e)的搭配使用, 可以快速形成对政策文本的整体认识, 通过图3(b)可以看出, 全部文档中词的整体分布并不平均, 这可以大致说明所研究政策文本的政策具备一定的侧重点或者倾向性, 通过tfmat_histy可以看出各个政策文档的篇幅差异比较大, 对于篇幅较大的政策文档, 一般来说可能比较重要, 通过聚类中心折线图可以看出, 聚类得到的三类文本存在较为显著的差别, 尤其是在部分关键词汇上, 差异表现得更为明显, 一定程度上说明聚类的合理性, 较为合理的聚类为基础可以对文档内容形成整体性的把握, 通过观察相应类别中某一政策文档的词云实现, 比如图3中呈现出来的东城园政策文本, 可以看出政策上对于园区的增长以及高新技术、企业孵化、税收等方面较为关注。
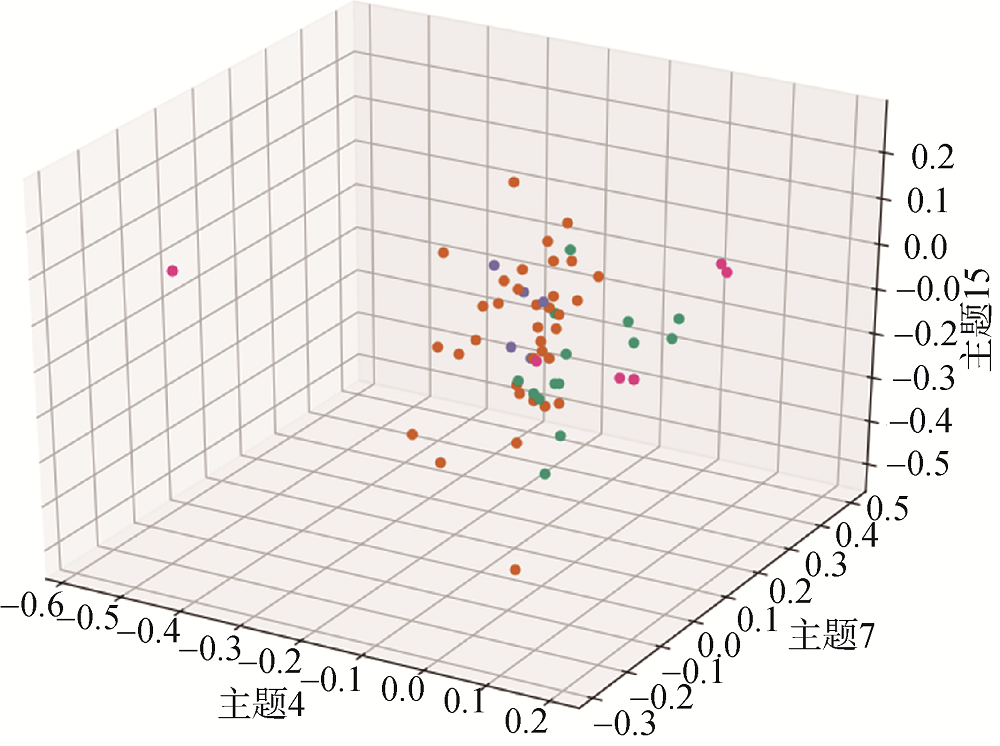
(2) 基于MDS降维的政策文本聚类
MDS降维主要是通过对处理过的词频进行降维, 高维数据解读方法主要是通过图形的改进以及添加相应降维技术对其进行解读, 不同的维度数据通过降维能有效发现数据不同的分布区间以及详细程度。本文选取MDS降维主要是对不同园区的数据进行聚类后的降维处理, 能够将特定政策文本详细信息做基本的可视化, 图形之间添加交互式联动, 左侧散点图与右侧不同区之间的联动交互, 重点结合联动同时呈现。
(3) 政策文本整体所包含的语义信息可视化
通过行奇异值分解, 文本的特征向量变化较小, 保证了匹配结果的准确性; 奇异值的比例不变性, 对于文本进行归一化处理不会从本质改变奇异值的相对大小; 奇异值的旋转不变形, 不但具有正交变换、转移、位移、镜像映射等代数和几何上的不变形, 而且稳定和抗噪效果较好, 应用于文本分类中可靠性较高。
结果呈现: SVD分解过后的S和V两个矩阵热力图, 分别是文章×主题矩阵(以TF-IDF值为基础通过渐变颜色显示重要程度)、主题×语义类以及语义类×特征词三个矩阵。
将前面提及的三种基本可视化方式结合多视图协同技术, 呈现在同一界面, 能够实现不同角度、多种算法的结果同时呈现, 能够同时兼顾其他方面的对于整个文本的解读。
图7为政策类文本信息综合展示的图形, 颜色按照需求分布, 多视图应用的图元为前面依次介绍的图元, 根据不同的数据需求应用不同图元。
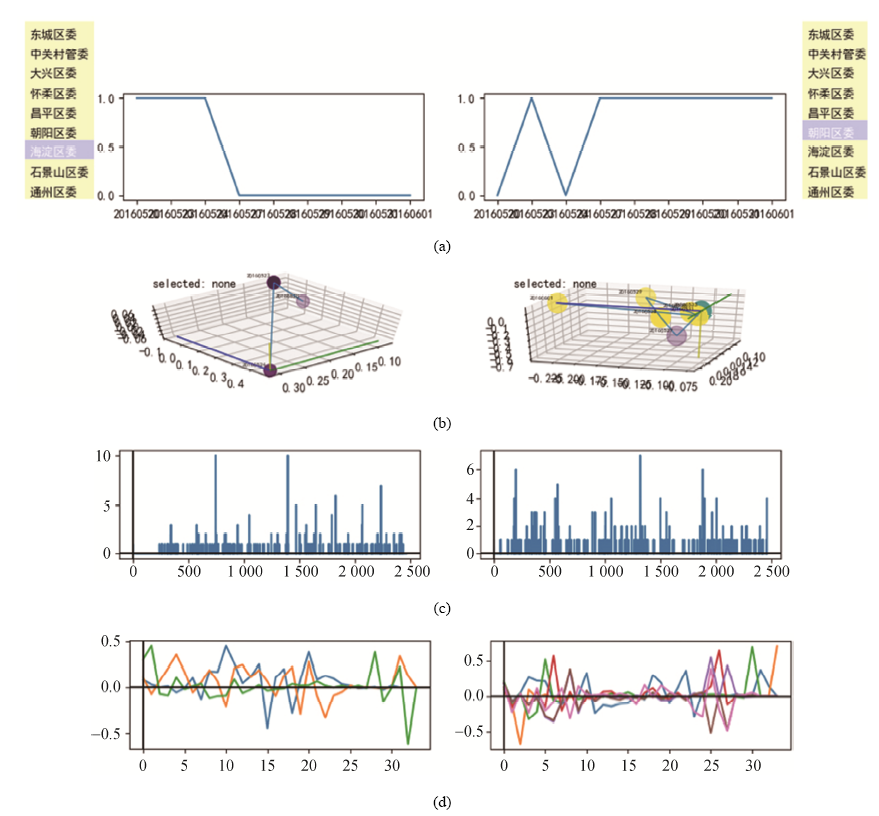
关于文本的探索性分析图, 对数据的容纳性更加强大, 界面本身呈现对称的形状, 可以同时查询两个园区的相关信息, 通过一致的图形进行不同园区政策类文本的对比解读:
(1) 图7(a)表示园区按照不同时间发布政策 的频数, 可通过筛选条选择不同园区, 多视图皆可联动;
(2) 图7(b)表示每个园区政策文档三维散点图, 展示聚类后不同语义的相互联系, 可根据筛选条选择不同园区;
(3) 图7(c)表示不同园区、不同月份发布政策报告的词频柱状图;
(4) 图7(d)表示根据SVD分解的每个园区的主题分布折线图, 根据不同语义类进行不同颜色分类。
根据特定时间区间的中关村政策文档通过多视图协同可视化的实例结果, 通过不同视图的联合展示, 以清楚地看到不同维度的多重信息, 对不同园区政策文本的发布以及词频的计算, 能够对不同园区的文本做出有效的分析。
本文面向时序类文本, 选取中关村示范区相关的委内政策信息作为样本, 基于对政策时序文本价值的基本认识, 在文本挖掘的实现思路上实现了“挖掘目的、挖掘过程、结果展示”三者有机融合, 借助数据过滤、相关文本挖掘技术以及多视图协同可视化技术, 提出多政策主体时序文本挖掘和展示的系统解决方案。本文实现了对时序类文本数据的多视图协同可视化探索性分析, 为时序类文本挖掘、政策分析等领域提供了新的研究思路, 同时填补了政策分析领域、文本挖掘领域一定的研究空白。本文技术思路创新在于以分析过程结合挖掘目的和模型产出结果进行可视化, 这能够把握整个文本挖掘过程中信息流动的重要节点, 丰富文本挖掘的结果。不足之处是整体界面有很大的优化空间, 在对数据的处理方面仍会有更多的选择可以尝试, 未来会结合前端的操作来美化界面的表达。此外, 通过面向过程的多视图协同可视化展示方式, 以符合人类认知节奏的方式设计过程和可视化展示方案, 提高对于过程数据的可理解性, 进一步提升用户对于复杂的时序类文本数据的认知效率。
杨亚楠: 提出研究思路, 整体思路整合, 起草论文;
赵文辉: 设计研究方案, 技术实现;
张健: 论文的大纲设计, 内容规划;
谭珅: 数据校对, 资料整理;
张贝贝: 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 651748094@qq.com。
[1] 杨亚楠, 赵文辉. BaseData.zip. 训练模型所需数据集.
[2] 杨亚楠, 赵文辉. compoud_vis_real_data.py. 模型所需代码.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}