
|
|


【目的】从科技查新候选检索结果中自动筛选与查新点语义相近的文献(期刊论文、专利)。【方法】设计基于Bi-GRU-ATT的深度多任务层次分类模型, 利用国际专利分类表(IPC)类别及专利数据, 训练多个不同层次分类模型, 利用少量论文数据进行Fine-tuning, 使之适用于论文和专利两种类别数据, 依照先父后子的次序识别查新点及候选记录的语义类别, 从而判定二者间的语义匹配度。【结果】在E21B专利分类下的两级分类模型中, 准确率分别达到82.37%和73.55%, 优于其他基准模型; 在使用真实查新点实验数据的语义匹配实验中, 语义匹配的精度达到88.13%, 比基准检索模型(TF-IDF)提高15.16%。【局限】仅在少量类别中开展训练, 还没有扩展到IPC所有分类中。【结论】初步实验表明该方法能够在一定程度上提升查新点语义匹配效果。
[Objective] This paper tries to identify semantics similar to the novelty points from preliminary searching results, aiming to retrieve needed journal articles or patents automatically. [Methods] First, we designed a deep multi-task hierarchical classification model based on Bi-GRU-ATT. Then, we trained several different hierarchical classification models using International Patent Classification Table (IPC) categories and patents. Third, we used a small amount of paper data to fine-tune the model for papers and patents. Finally, we compared the semantic categories of new points and candidate records to collect the matching ones. [Results] With two-level classification of patents under IPC (E21B), the new model’s precisions were 82.37% and 73.55% respectively, which were better than the benchmark models. For real novelty search points data, the precision of semantic matching was 88.13%, which was 15.16% higher than that of TF-IDF. [Limitations] Only examined our model with a small amount of IPC categories . [Conclusions] The proposed method improves the semantic matching of novelty search points.
查新点是科技查新中的关键内容, 是一种由申请人提炼、在所研究领域具有新颖性, 但有待科学查证的研究要点。在自动科技查新系统中, 从大量检索结果集中自动筛选与查新点语义相符的文献内容(期刊论文、专利等)是处理流程中的关键环节, 能在很大程度上减轻查新员的工作强度, 使其从繁琐的人工逐一比较、判别过程中解脱出来。
查新点的检索结果筛选问题可以归结为语义检索中文本段与文本段间的语义匹配问题。目前, 自动科技查新的研究还处于起步阶段, 大多停留在生成检索词阶段[1,2], 鲜见涉及到语义层面的相关研究。但语义检索领域已有大量类似研究成果, 从方法上看, 文本段间的语义匹配主要有三种思路: 将文本向量化后利用词向量计算文本段之间的语义距离, 如WMD相似 度[3]; 抽取文本段中的主要语义成分, 如SAO语义结构; 识别文本段所属知识类别, 如领域知识分类、知识图谱等。第一种适合于较短的文本, 第二种准确性还达不到应用要求, 而文本分类的方法应用广泛, 从效果上看, 神经网络深度学习模型大多要优于传统的机器学习模型, 如SVM、CRF等, 这主要归结于深度学习模型能够更好地捕捉词及句子在统计学上的语义特征。
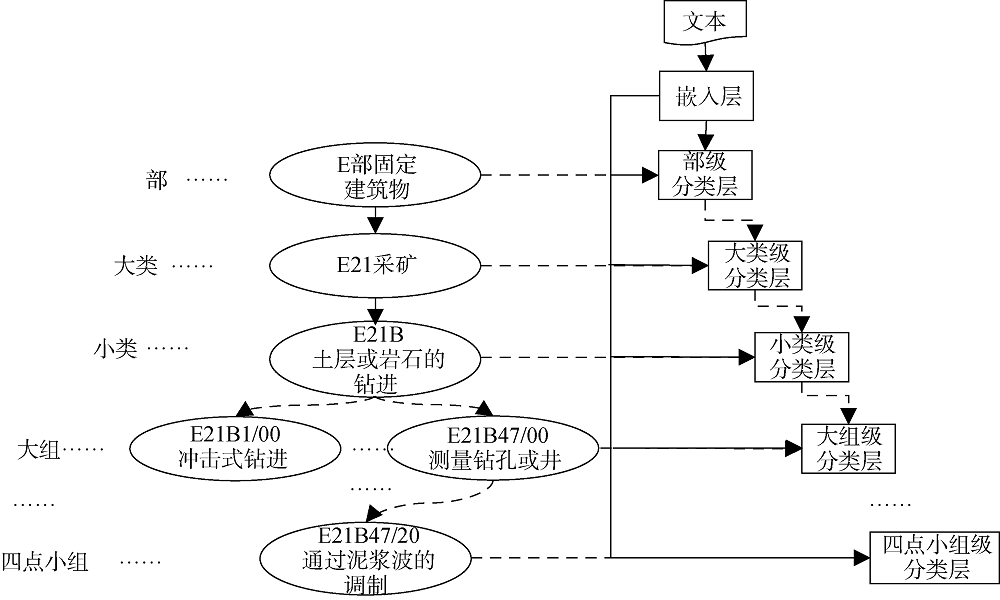
在科技查新中, 国际专利分类表(International Patent Classification, IPC)是判断专利所属类别的重要手段, 按照技术主题设立类目, 整个技术领域分为8个不同等级: 部、大类、小类、大组、一点小组、二点小组、三点小组、四点小组。对于查新点的语义识别问题, 如果能正确识别出各文本段在IPC中所属类别, 则可以通过该分类表的树状层级关系计算各节点间的语义距离, 从而获取文本段间的语义距离, 进而解决文本段语义匹配问题。
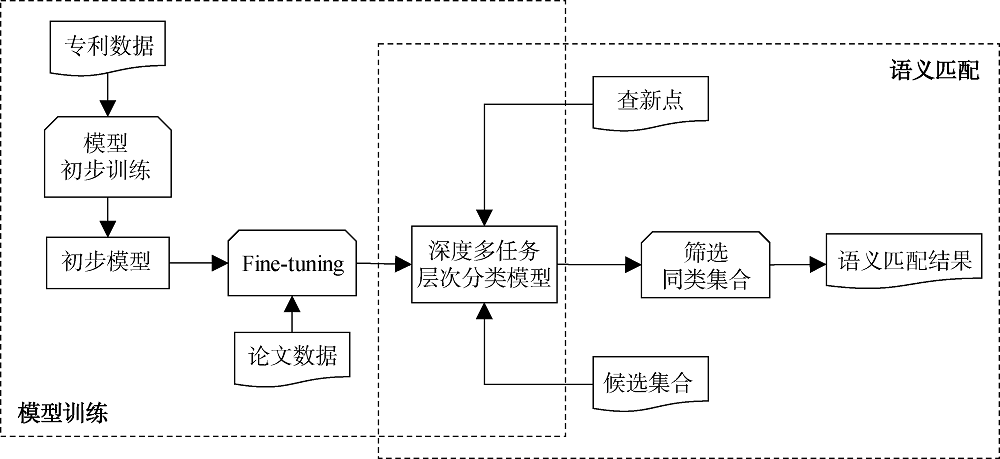
按照这一思路, 本文设计了一种深度多任务层次分类模型(Bi-GRU-ATT), 利用国际专利分类表类别及专利数据, 训练多个不同层次分类模型, 利用少量论文数据进行Fine-tuning, 使之适用于论文和专利两种类别数据, 依照先父后子的次序识别查新点及候选记录的语义类别, 利用分类表树状层级关系计算各节点间的语义距离, 从而判定两个文本段在语义上是否匹配。
科技查新中的查新点通常为一段描述文本, 当前有关查新点语义匹配方面的研究不多, 但在语义检索、自然语言处理等领域有许多有关文本间的语义匹配方面的研究。
(1) 文本向量之间的语义距离能够衡量匹配关系。Kusner等[4]借助词向量构建文本矩阵, 以文本矩阵之间相互转化所需代价描述文本段的语义距离。这种方法计算复杂度高, 因此在处理长文本时效率较低; 而且直接使用词向量构建的文本矩阵没有考虑不同匹配任务之间的差异, 所以适用的任务范围有限。一些学者通过训练神经网络获取表示指定关系的文本语义向量。最早可追溯到Huang等[5]提出的深度结构化语义模型(Deep Structured Semantic Models, DSSM), 使用n-gram方法将文本转化为One-Hot形式输入深层神经网络中, 然后以使相互匹配的文本段所对应向量之间的余弦距离不断缩小为目的训练模型, 最终获得适配具体任务的文本语义向量。
(2) 一些研究抽取文本段中的主要语义成分, 以主要成分之间的匹配关系表示文本段之间的匹配关系。如李欣等[6]基于SAO(Subject-Action-Object)结构使用相似度算法对专利文本进行聚类, 实现相似技术专利之间的语义匹配。但是SAO结构的识别本身存在较大误差, 因此需要大量人力对抽取的SAO结构数据进行清洗; 此外, 该文章计算相似度的主要依据是WordNet, 无法囊括新兴概念, 因此导致涉及这些概念的相似度计算也存在误差。在此基础上, 何喜军等[7]构建技术领域本体以提高SAO结构抽取的精度, 同时引入词向量提高语义相似度计算的准确性, 但是这种方法仍然没有解决人工成本过高的问题, 难以投入实际应用中。
(3) 识别文本段所属的知识类别, 并寻找属于同类别的文本段是进行语义匹配的另一种途径, 这种方法将语义匹配问题转换为文本分类问题。文本分类问题的相关研究由来已久。Joulin等[8]提出fastText模型将文本词向量序列进行平均池化后连接Softmax层输出类别。由于模型结构简单, 所以训练速度非常快; 但是直接进行平均池化的做法导致网络完全丢失了词序信息。在此基础上, Kim[9]使用完整的卷积神经网络结构对文本进行分类, 该模型能够保存词序中的关键信息, 分类效果有所提升; 但卷积神经网络中卷积窗口大小的约束使得模型无法对长序列信息进行完整分析。Li等[10]使用双向LSTM建模解决分类问题, LSTM的门限机制避免了长时信息的丢失。Pappas等[11]在LSTM的基础上引入注意力机制(Attention), 使模型更好地进行文本表征, 进一步提高模型的性能。
整体匹配流程可分为训练阶段与测试阶段。在训练阶段主要解决的问题是得到具有识别文献多层次类别能力的模型。对于专利数据, 目前已有国际专利分类表对其进行标准合理的分类, 能够较好地描述数据之间的语义关联性。IPC分类体系将技术按不同粒度分为8个层次类别。
本文基于深度多任务学习构建层次分类模型拟合该分类体系。再使用少量论文数据进行Fine-tuning, 使模型可用于专利和文献两种数据。在测试阶段, 分别计算查新点和候选文献数据的语义类别, 通过检验与查新点同属一个类别的文献数据是否与查新点相关验证模型的有效性。
查新点语义匹配的整体框架如图1所示。
本文构建的深度多任务层次分类模型包括两部分, 一部分是针对不同粒度分类任务的分类器组成的多任务结构, 该结构下每个分类器均对应IPC分类体系中的一个节点, 父节点分类器生成的中间向量与文本嵌入表示拼接后作为子分类器的输入进行下一层的类别判断, 该结构用于强化父子分类器之间的联系; 另一部分是所有分类器共享的预测结构, 该预测结构是一个使用预训练字向量构建的嵌入层, 用于提取先验知识。其中用到的预训练字符向量降低了文本表示规模, 避免文本矩阵过于稀疏从而导致梯度消失的问题, 同时经过预训练的字符向量极大程度上保留了原本的语义信息。没有采用词向量[13]是因为查新文本中会频繁出现没有被词向量收录的新颖术语, 使用字符向量增强了鲁棒性。具体结构和对应关系如图2所示。
分类时, 文本首先进入嵌入层转换为矩阵形式, 然后流入部级分类层判断其所属大类。再按图2中右侧分类结构中的虚线路径所示进行细粒度类别的判断, 直到获得IPC最细粒度的类别。
深度多任务层次分类模型中的分类器使用基于Attention的双向GRU模型(Bi-GRU-ATT模型)。选择Bi-GRU-ATT模型是因为双向RNN系列结构保存了充足的上下文信息, 同时Cho等[14]通过研究表明, GRU单元结构避免了传统RNN丢失信息的问题, 且训练难度较LSTM更低, 相比之下更适用于数据量适中的任务; 而Raffel等[15]通过研究表明, 引入Attention机制能够使模型更容易挖掘到用于分类的关键特征。
综上所述, 节点分类模型的结构如图3所示。
上述模型是使用专利数据训练所得, 由于专利数据与论文数据的行文方式存在一定差异, 因此该模型还需要进一步处理以使其能够准确处理论文数据。Fine-tuning是使用少量新数据对已有模型在结构或参数上进行少量调整以适应新数据的一种迁移学习方法。Howard等[16]通过实验证明了在文本分类任务中使用极少量数据进行Fine-tuning的有效性。本文使用少量论文数据, 在不修改模型结构的前提下, 以较低的学习率对适用于专利数据的深度多任务层次分类模型进行Fine-tuning, 使模型获得对论文数据进行分类的能力。
本文实验分为两部分: 第一部分用于验证深度多任务层次分类模型的性能, 第二部分参照真实查新点数据, 利用层次分类模型寻找与查新点含有语义匹配关系的文献数据。为限制模型复杂度, 本次实验只在小类-大组-一点小组这三个维度上进行。实验环境如表1所示。
选取国际专利分类表下小类“E21B”中约44 351条专利与150篇文献数据进行分类实验, 然后以与“E21B47/00”密切相关的真实查新点数据作为样例进行实际的查新匹配实验。
小类“E21B”中的数据多与“土层或岩石的钻进”相关。选择该类别是因为该类别下的数据量可观, 且其下存在大组能有效进行更细粒度的类别划分。在专利数据方面, 选取大组中的7个类别作为树模型父节点的类别标签, 该层次中每个类别约有5 000条数据; 以及一点小组中“E21B47/00”下的三个类别作为子节点的类别标签, 该子层次中每个类别约有2 000条数据。而对用于Fine-tuning的文献数据, 人工标注出一点小组下每个类别各30条数据。实验前均匀且随机取出各类别下十分之一的数据作为测试集合; 剩余数据同样均匀且随机地分为10份, 每次随机取9份用于训练, 剩余一份用于验证。
在训练前需要保证每个类别的训练样本数量大致相同。对于样本类别分布不均的节点, 需要对样本量较少的类别进行数据增广。将该类别文本中的词进行随机调换, 作为新样本加入。
此外, 模型中使用的字符向量为Polyghot利用Word2Embedding训练的64维字符向量, 其中含有汉字1.2万个, 英文7.8万个以及其他字符9 000个, 训练该字符级向量的数据来源为Wikipedia。
(1) 分类实验结果
在实验中, 设定深度多任务层次分类模型中每个分类器中的隐含层神经元数为128, 学习率为10-3, 输入文本的截断长度为400, 神经元Dropout保留比率为0.7, Batch-Size为32, 模型迭代最大次数为30次, 输出的类别数取决于各个节点下的子类别数目。
实验除采用本文所述方法外, 还使用CNN、LSTM、Bi-LSTM-ATT、Bi-GRU作为分类器结构展开实验比对结果。所得结果如表2所示。
从实验结果可以看出, 各个模型所得效果相近。CNN和LSTM两个基础模型结果相对较差, CNN效果相比LSTM要好的原因可能是LSTM对于数据量过于敏感。使用双向序列模型的效果要略高于CNN和LSTM, 原因是双向模型在训练过程中既考虑上文也考虑下文。在引入Attention后, 模型的精度有进一步提升, 可见Attention在提取特征方面起到非常重要的作用。总体上, Bi-LSTM-ATT与Bi-GRU-ATT的效果最佳。之所以Bi-GRU-ATT效果略好, 其原因可能是供训练的数据量无法让Bi-LSTM-ATT发挥最佳性能。
之后进行针对文献数据的Fine-tuning。在调整过程中, 使用的学习率为10-5, 迭代轮数为5, 调整前后的对比实验结果如表3所示。
由表3可知, 直接使用专利层次分类模型对文献数据进行分类时, 准确率没有大幅下降, 可能是因为同类别的专利数据和文献数据知识点相互重合, 而模型对这些知识点的识别较好。在使用少量文献数据进行Fine-tuning后, 模型对文献数据的分类性能得到一定增强, 证明Fine-tuning取得了较好的效果。
(2) 查新匹配实验结果与分析
本实验从真实的查新报告中选取与“E21B47/00”密切相关的查新点数据, 利用查新报告中提供的检索式在数据库中进行检索, 使用本文提出的语义匹配模型与传统的TD-IDF算法筛选与查新点含有密切语义关系的数据, 并与人工筛选结果进行比对。部分实验结果如表4所示。
深度多任务层次分类模型与基准模型的精度对比如表5所示。
从表5中可知, 本文模型相比于基准模型大大提高了语义匹配的性能; 此外, 层次分类模型在进行真实的查新匹配时效果要远优于分类任务, 原因在于真实查新报告中提供的优质检索式起到一定程度的筛选作用。
为从科技查新检索结果集中筛选出与查新点语义相近的文献, 本文利用国际专利分类表的层次结构, 参考父子节点层次类别间的继承关系, 通过Fine-tuning等手段, 构建以Bi-GRU-ATT为分类器的深度多任务层次分类模型, 通过计算查新点与备选检索结果所属类别判断计算二者在语义层面上是否存在匹配关系。初步实验表明, 该方法比目前几种常用的分类模型在准确率上有提升。在使用真实查新单进行的实验中, 该方法在查新点语义匹配中的精度明显高出基准TF-IDF模型。
由于仅使用IPC中的少量层次类别进行实验, 没有覆盖IPC所有分类节点及层次, 因此在泛化能力和适用性等方面还有待进一步研究和实验。
姚俊良: 设计并实施技术方案和技术路线, 采集、清洗数据, 开展实验并进行结果分析, 论文起草及最终版本修订;
乐小虬: 提出论文研究方向和主要研究思路, 优化研究方案及技术路线的设计, 撰写第1小节, 进行论文修改。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: lexq@mail.las.ac.cn。
[1] 姚俊良, 乐小虬. sci-tech_semantic_classification_result.txt. 专利与文献分类测试结果.
[2] 姚俊良, 乐小虬. sci-tech_semantic_match_result.txt. 查新实验结果.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}