
|
|


【目的】实现对大规模法律文本中法律术语的自动识别, 促进法律大数据的结构化进程。【方法】将条件随机场模型作为主动学习算法的分类器, 在经过K-means聚类后的语料库中, 按照分层抽样的方式抽取用于启动主动学习算法的初始样本, 将熵值作为主动学习的样例选择依据, 迭代地进行主动学习的学习过程及样例选择过程, 直到模型的调和均值F值趋于稳定时停止迭代, 输出最终的法律术语自动识别模型——AL-CRF模型。【结果】在中文裁判文书上的命名实体识别实验表明, 通过少量且高质的样本训练的AL-CRF模型对于法律术语的识别准确率和召回率可达90%以上, 且相较于等标注工作量训练的CRF模型F值提高4.85%。【局限】K-means聚类方法对噪声和离群点较为敏感, 可能会影响模型的识别效果。【结论】结合主动学习的条件随机场模型能在保证识别质量的情况下, 减少低质量样本的标注工作量。
[Objective] This paper tries to identify legal terminologies automatically from the large-scale legal texts, aiming to structuralize legal big data. [Methods] We used the Conditional Random Field model as the classifier of the Active Learning algorithm, and then identify legal terms. Once the corpus was clustered by K-means, we extracted the initial list used to initiate the Active Learning algorithm with stratified sampling. Entropy was used as the basis of sample selection for Active Learning. The learning and sample selection process of active learning were carried out iteratively until the harmonic mean F value of the model was stabilized. Finally, the legal domain entity recognition model (AL-CRF) was generated. [Results] We ran the proposed model with Chinese judgment documents and found the precision and recall rates of AL-CRF model reached more than 90%, and its F value was 4.85% higher than that of the CRF model with equal labeling workload training. [Limitations] K-means clustering method is sensitive to noise and outliers, which may affect performance of the model. [Conclusions] The conditional random fields combined with active learning could reduce the workload with low-quality samples and ensure the recognition quality.
大数据与人工智能技术的兴起, 对各行各业产生了深远影响。在法律领域, 新兴技术的发展助推了裁判结果预测、法律文书自动起草、辅助办案、类案检索等智慧应用的实现。与此同时, 国外在法律领域开展了许多深入的大数据研究, 诞生了警务预测[1]、保释风险分析[2]、诉讼结果预测[3]等多角度的实践成果。而在国内, 依托大数据技术所开展的法律领域研究形成的实践应用相对较少, 应用的主体和角度也较为有限[4], 究其原因是国内现有法律数据的结构化程度不足[5], 无法为这些应用的建设提供优质的法律大数据资源。由于法律数据处理的专业性较强, 仅通过人工标注的方式难以满足法律大数据的结构化要求, 只有借助人工智能等技术自动识别法律大数据中的法律术语才能提高法律大数据的结构化效率, 进而促进中国法律智慧应用的落地实践。
自动识别法律术语即对文本中的罪名、刑罚、法律概念、法律原则和法律条文等具有特定法律含义的法律用语进行命名实体识别(Named Entity Recognition, NER), 属于词法分析中未登录词识别的范畴[6]。图书情报、计算机等学科的研究人员对命名实体识别问题进行了广泛研究, 提出多种有监督及无监督式的识别方法[7]。对于法律领域而言, 由于缺乏统一的法律用词、标准的领域本体和专业的叙词表等资源, 使得无监督的识别方法难以有效应用[5]。而对于有监督的识别方法, 则需要大量已标注的训练数据作为支撑, 但囿于法律文本标注专业性强及耗费人力物力较多的情况, 难以大规模实施。因此, 如何在保证命名实体识别精度的前提下通过较少的样本标注工作来构建监督式模型, 成为当前法律术语自动抽取过程中亟待解决的问题。
基于此, 本文将主动学习算法与条件随机场模型(Conditional Random Field, CRF)结合, 利用主动学习的样例选择过程选择高质量训练样本, 再通过主动学习的学习过程不断优化CRF模型的精度, 最终减少了低质量样本标注的工作量。本研究可以依托少量的样本标注工作训练出识别效果良好的法律术语识别模型, 更适用于实际的法律大数据结构化处理环境。
命名实体识别在第6届消息理解会议(MUC-6)中被规定为信息抽取的一个重要子任务[8], 识别方法通常分为三类: 基于规则和词典的方法、基于统计的方法和两者混合的方法。早期的命名实体识别主要采用基于规则和词典的方法, 这种方法需要领域专家或语言学家制定规则, 但规则编制过程往往难以涵盖所有语言现象且建设周期较长, 同时该方法的可移植性不强[9]。基于统计的方法即根据已标注的语料训练概率模型完成命名实体识别的过程, 主要包括隐马尔科夫模型(HMM)[10,11]、最大熵模型(ME)[12,13]、支持向量机模型(SVM)[14,15]和条件随机场模型(CRF)[16,17]等, 这类方法可移植性较好, 建设周期较短, 但是对特征选取要求较高且对于已标注语料库依赖较大。混合方式则是将规则与统计模型结合, 综合两种方法的优势, 利用规则知识提前对目标文本进行过滤处理, 减少统计方法的状态搜索空间。近年来, 也出现了将深度学习与规则或统计模型结合的混合方法[18]。除了识别方法的发展, 命名实体识别的对象也从最初的人名、地名、时间等通用实体发展为识别文本中有特殊含义的词或短语, 如疾病名称、基因组序列等领域实体。由于不同领域的文本特征、实体特征均存在较大差异, 不同领域的命名实体识别方法难以直接迁移, 需根据领域数据特征, 选择合适的命名实体识别方法。如孙娟娟等[19]提出针对渔业领域标准文件进行渔业领域术语识别的深度学习识别方法; Wei等[20]提出基于双向递归神经网络的命名实体识别模型, 用于识别医学文献中的疾病名称。
具体到中文法律文本的命名实体识别, 目前的研究可以分为两类: 一类是识别法律文本中的通用实体, 即人名、地名、机构名等实体的识别。如王礼敏[21]提出基于多任务表示学习的法律文书命名实体识别方法, 将命名实体识别任务分割成多个子任务, 不同的辅助子任务分别将通过共享学习得到的辅助表示加入到主任务中, 从而提高主任务的识别效果。周晓辉[22]使用多个串联的HMM 模型, 对文本进行由浅至深层次的实体识别, 将低层 HMM 模型的输出作为高层 HMM 模型的输入, 利用搜索引擎识别并消解同义命名实体, 从而完成法律文本的命名实体识别过程。这些研究从法律文本的文本特征出发, 识别法律文本中的通用实体, 然而除通用实体外, 法律文本中更多的是具有法律意义的法律术语, 如“原告”、“被告”等法律概念和《中华人民共和国婚姻法》等法律条文, 对于法律文本的另一类命名实体识别研究即识别其中的法律术语, 这类研究目前相对较少。张琳等[23]统计法律实体的内外部特征, 将CRF模型应用到罪名、刑罚等法律术语的识别上, 取得了较好的识别效果。徐建忠等[24]则针对法律文本中的非连续实体, 提出一种基于超图的非连续法律实体识别方法, 在对非连续法律实体的识别上, 该模型的识别效果较CRF模型有一定提升。当前CRF模型及基于超图的识别模型虽然在一定程度上解决了对法律文本中关键法律信息的识别问题, 但对人工标注数据的依赖使得现有模型难以适用于法律大数据的处理。
综上所述, 法律领域的命名实体识别已有一定的研究成果, 目前的模型虽然在仿真实验中表现较好, 但需要人工预先标注大量法律文本, 在实际的法律大数据环境下难以实施。因此, 本文将主动学习应用于法律术语的自动识别中, 将CRF模型作为主动学习的分类器暨法律术语识别模型, 利用主动学习算法选择高质量样本进行人工标注, 在不降低CRF模型识别效率的前提下, 减少训练样本数量, 降低人工标注低质量样本的工作量, 从而促进法律大数据的结构化进程。
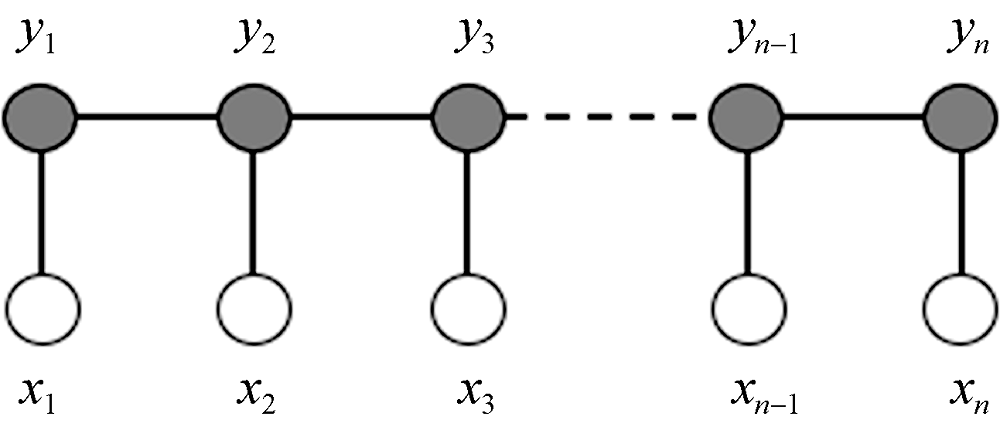
CRF模型是在给定随机变量
CRF模型的任务是通过训练得到的模型参数预测语料标注组合
$\begin{align} & P\text{(}y\text{ }\!\!|\!\!\text{ }x\text{)}=\frac{1}{Z(x)}\exp (\sum\limits_{i,k}{{{\lambda }_{k}}{{t}_{k}}({{y}_{t-1}},{{y}_{i}},x,i)+} \\ & {{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}_{{}}\sum\limits_{i,l}{{{\mu }_{l}}{{s}_{l}}({{y}_{i}},x,i))} \\ \end{align}$ (1)
观测集$X$为对文本语料进行分词和特征自动标注后的序列集, $Y$为观测集$X$对应的标注类型。在特征模型构建中使用5词位标注集P={B, I, E, S, O}, 其中B表示实体起始词, E表示实体结束词, 实体中除了起始词和结束词外其余部分都标记为I, S表示单字词实体, O表示实体之外的词语。
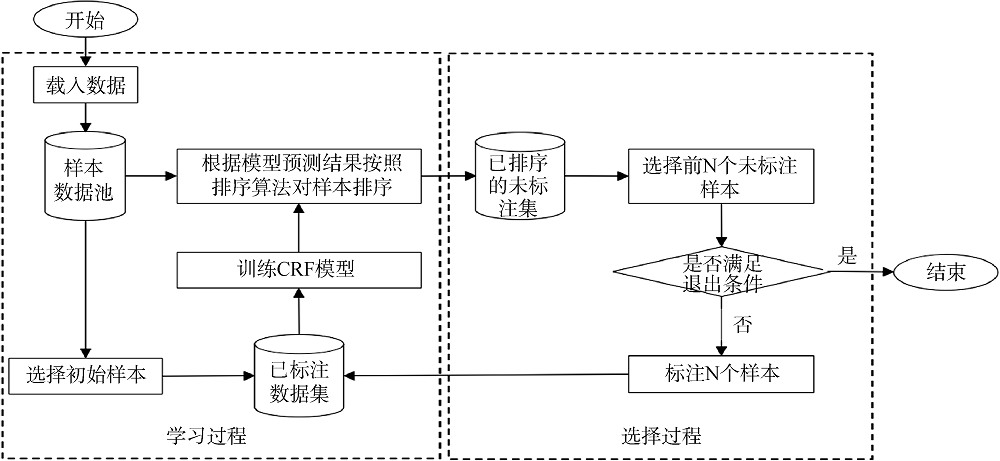
本文主动学习算法过程如图2所示。利用特定策略选出初始训练集并进行人工标注, 训练初始的条件随机场模型。选择过程根据当前训练的模型信息, 按照一定排序规则对未标注样本进行排序, 选择其中的前N个样本进行人工标注; 学习过程将标注后的样本加入训练集, 重新训练识别模型。主动学习的学习过程和选择过程迭代进行, 直到满足退出条件时停止迭代。可以看出, 在主动学习的算法过程中需要解决三个重点问题, 分别为如何构造初始训练集、采取何种样例选择策略以及如何设置迭代退出条件。
初始训练集用于训练主动学习算法中的基准分类器, 因此, 选择代表性好的初始训练集能训练出识别效果良好的基准分类器, 进而减少模型迭代次数, 加快模型收敛过程。基本的初始训练集构造方法即随机抽样方法, 但由于初始训练集规模有限, 此方法选择的样本很难具有代表性。而由于聚类方法能将具有相似特征的样本进行聚合, 因此基于聚类结果进行分层抽样更能选择出具有代表性的样例。
在主动学习中, 按照获取样例方式的不同可将样例选择策略分为两种: 流式样例选择策略和池式样例选择策略。流式样例选择策略的学习过程需要处理所有未标记样例, 样例的查询成本较高。此外, 由于其需要提前预设样例标注条件, 故不具备良好的适用性[25]; 而池式策略则是每次从当前样例池中选择贡献度最高的样例, 降低了样例的查询成本, 因此, 其应用更为广泛。
主动学习是一个通过迭代选取价值量高的样例进行模型训练, 从而不断提高分类器效率的过程。虽然迭代次数的增加一定程度上可以提高分类器效率, 但是会增加样例选择和样例标注的工作量, 其训练过程力求达到样例标注代价与分类器性能之间的均衡。因此, 通常情况下, 主动学习算法会在模型效率达到预设精度或者样例数量达到阈值时终止迭代。
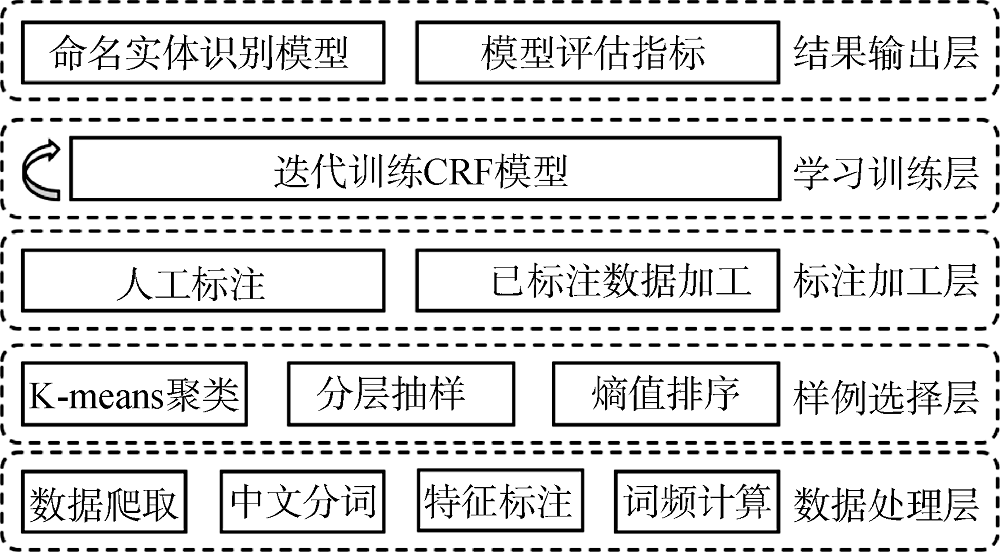
本文所提AL-CRF模型以主动学习为基本框架, 以CRF模型为主动学习的基础分类器, 其算法框架如图3所示。
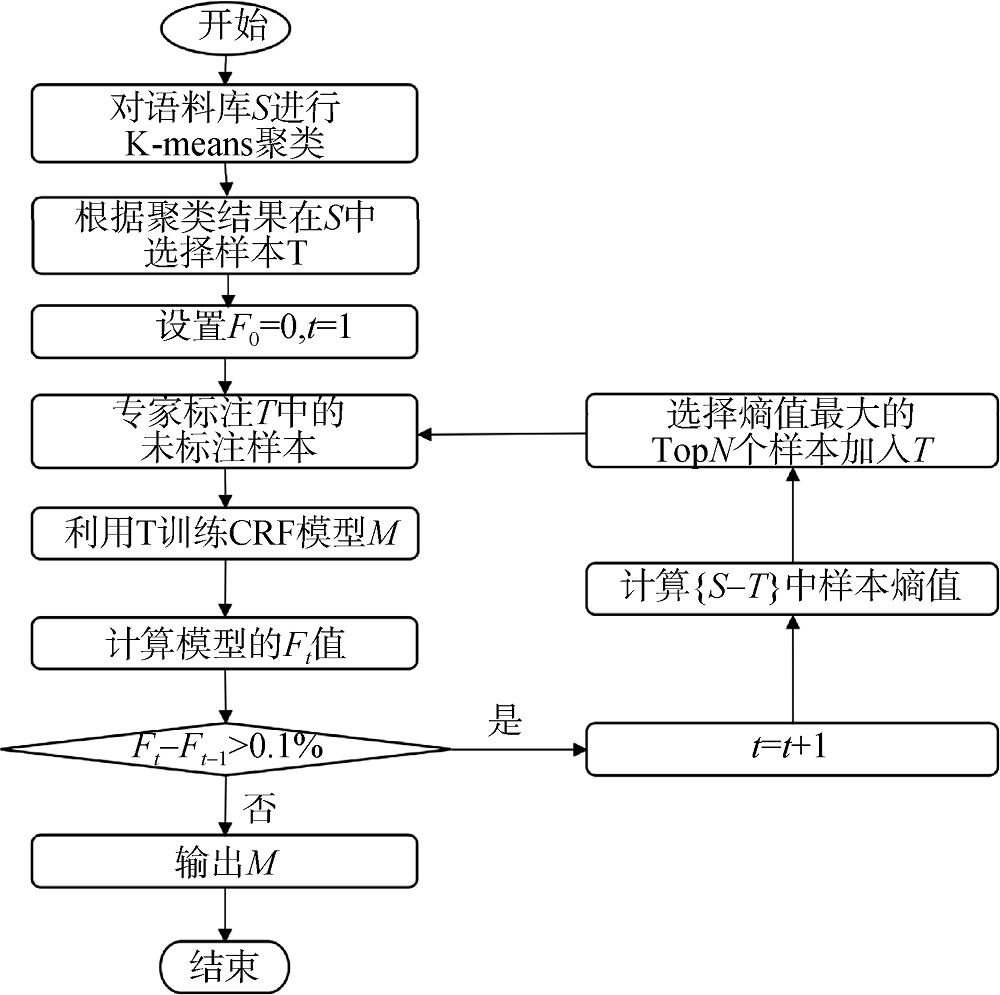
(1) 为构造更具代表性的初始训练集, AL-CRF模型利用TF-IDF特征权重将文本数据进行向量化表示后, 采用K-means算法进行聚类, 并对聚类后的数据进行分层抽样, 其算法过程可描述为:
①载入语料库后进行TF-IDF计算, 并进行归一化处理后得到数据集X;
②从数据集X中任意选择K个样本数据作为聚类中心C;
③分别计算X中其余样本到C的欧式距离, 根据距离将X中的其余样本归分到距其最近的聚类中;
④所有样本划分完成后, 分别计算每个聚类样本的均值m, 将其代替原来的聚类中心点, 更新K个聚类中心;
⑤与前一次的聚类中心相比较, 如果没发生变化则终止, 否则转到步骤②;
⑥输出最终聚类结果;
⑦根据聚类结果进行分层抽样, 输出初始样本集。
(2) AL-CRF模型选择基于池的样例选择策略, 并基于不确定性标准, 将信息熵作为评价样例价值的度量。信息熵是用来衡量信息量大小的度量单位, 信息熵越大则样例所含信息量越大, 表明分类器最不能确定其所属类别。在迭代过程中, 模型通过现有分类器对剩余样例的标注序列进行预测, 从而得到样例的熵值序列, 将样例的熵值序列之和即样例中每一个词语的熵值之和作为该样例的熵值, 选择熵值较大的样例加入待人工标注序列中。熵值计算方法如公式(2)-公式(4)所示。
$H({{x}_{j}})=-\sum\nolimits_{i}{p({{y}_{i}}|{{x}_{j}})\mathrm{log}p({{y}_{i}}|{{x}_{j}})}$ (2)
$H\text{(}{{s}_{t}}\text{)}=\sum\nolimits_{j}{H({{x}_{j}})}$ (3)
$H\text{(}{{d}_{k}}\text{)}=\sum\nolimits_{t}{H({{s}_{t}})}$ (4)
其中, $H({{x}_{j}})$表示词语${{x}_{j}}$的熵值, $p({{y}_{i}}|{{x}_{j}})$表示在给定词语${{x}_{j}}$情况下, 其标签为${{y}_{i}}$的可能性。$H\text{(}{{s}_{t}}\text{)}$表示句子${{s}_{t}}$的熵值, $H\text{(}{{d}_{k}}\text{)}$表示文本${{d}_{k}}$的熵值。
(3) 在终止条件设置中, 为控制训练过程样例的选择和标注代价, AL-CRF模型设置F值变化率不大于0.1%为主动学习的迭代终止条件, 即${{F}_{t}}-{{F}_{t-1}}\le 0.1\text{ }\!\!%\!\!\text{ }$, 其中${{F}_{t}}$表示第
综上, AL-CRF模型的算法流程如图4所示。
裁判文书是人民法院在审理案件过程中或审理结束后, 根据事实和法律所作出的具有约束力的决定[26], 是一种典型的法律文本。本文将裁判文书作为研究对象, 从“中国裁判文书网”中抓取裁判文书61 515份, 经过清除重复、空白以及无内容数据后, 得到59 788份有效数据的文书库, 包括一审文书52 995份, 二审文书 5 632份, 再审文书325份, 刑罚变更37份, 其他类别799份。为使模型更具适用性, 采用分层抽样的方式从59 788份中抽取1 000份裁判文书数据作为实验语料。
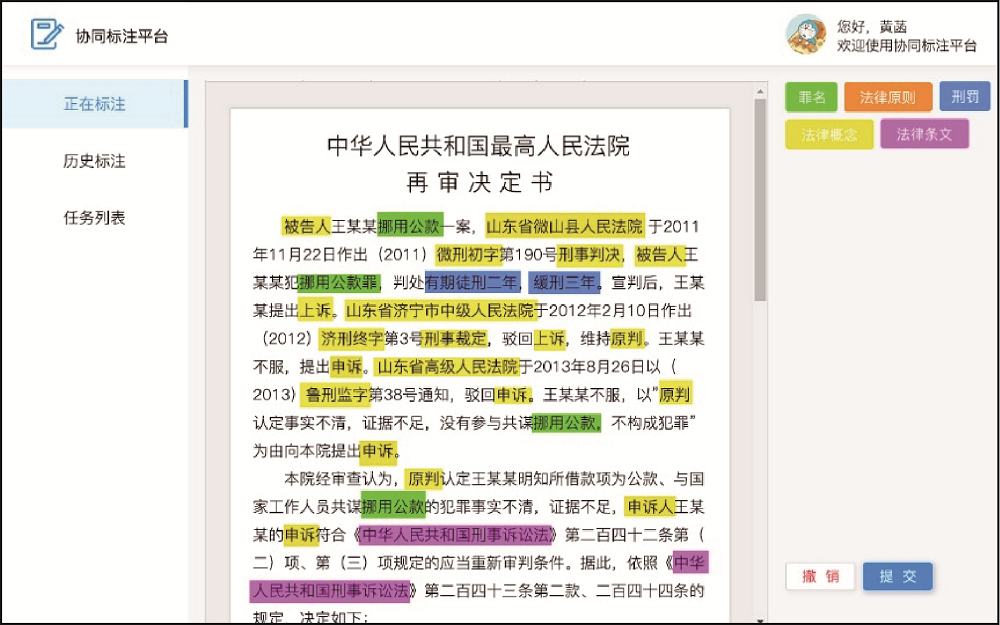
为保证标注数据的质量, 本文设计了在线标注平台, 专家通过该平台对裁判文书中的法律术语进行标注, 标注界面如图5所示。通过图6所示的标注流程, 保证每条文本均经过两人的标注, 避免一人标注时的错标、漏标等问题。在1 000份法律文书中, 标注的法律实体共73 217个, 包括罪名、刑罚、法律原则、法律概念及法律条文5种类别, 其分布情况如表1所示。
由于中文本身不存在分隔符, 因此中文分词是进行后续数据分析的基础。为提高分词准确性, 本文用从百度百科中获取罪名、法律机构、法律常用词构造法律领域的专业词典, 将其导入NLPIR分词工具, 对裁判文书文本进行中文分词。
在CRF模型的构建过程中, 结合法律领域实体的内外部特征, 定义分词序列、词性、词长、是否左边界词、是否右边界词5种特征如表2左侧所示。完成对语料库的人工标注后, 采用程序自动标注的方式, 通过5词位标注集的方法对已标注语料进行自动化处理, 处理后的语料格式如表2右侧所示。
(1) 评价指标
依据命名实体识别模型常用指标体系, 选择准确率P(Precision)、召回率R(Recall)、F值(F-measure) 作为评测指标, 计算方法如公式(5)-公式(7)所示。
$P=\frac{A}{A+W}\times 100\text{ }\!\!%\!\!\text{ }$ (5)
$R=\frac{A}{A+U}\times 100\text{ }\!\!%\!\!\text{ }$ (6)
$F=\frac{2\times P\times R}{p+R}\times 100\text{ }\!\!%\!\!\text{ }$ (7)
其中,
(2) 聚类数量选择
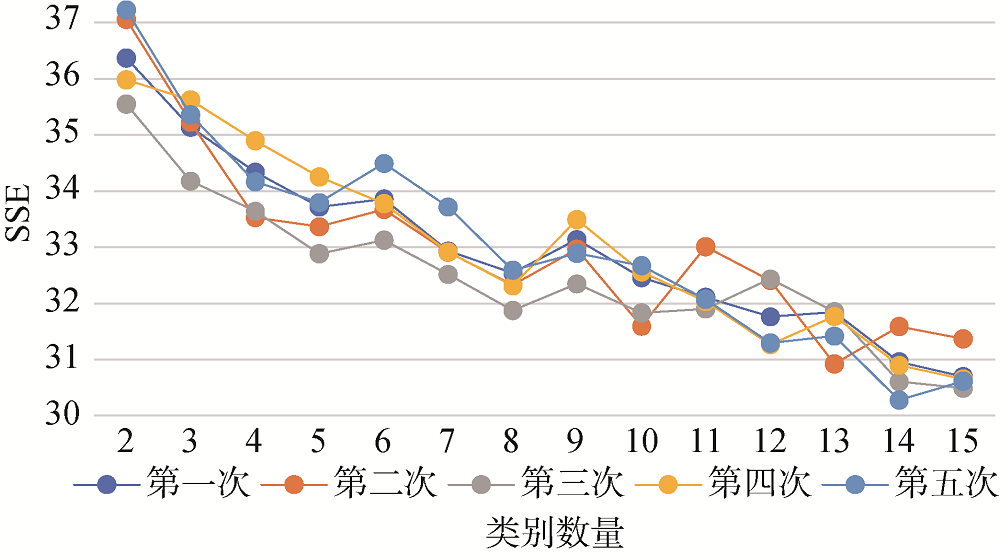
在初始样本选择过程中, 首先采用K-means算法对训练语料进行文本聚类, 根据聚类结果选择初始样本。为确定K-means聚类的聚类数量, 采用5折交叉验证的方式, 按照4:1的比例划分训练集和测试集, 进行5轮实验。每轮实验都包括聚类数量从2-15的14次聚类实验, 实验结束后, 计算每次实验的误差平方和 (Sum of the Squared Errors, SSE), 通过手肘法进行聚类数量选择。K-means聚类实验SSE值分布如图7所示, 根据手肘法的一般原则, 聚类数量为5和8时, SSE取较低值。
为进一步确定聚类数量, 根据这两种聚类结果选择初始样本集, 训练初始识别模型, 并利用同一测试集对模型效果进行检验, 5轮实验的平均识别效果如表3所示。
通过分析表3结果可知, 按照分层抽样的方式从聚类后的语料库中选取初始训练集能在一定程度上提高初始模型的准确率和召回率。当聚类数量为8时, 模型的识别效果最好, 因此选择聚类数量为8。
(3) CRF模型与AL-CRF模型的识别结果对比
分别利用AL-CRF模型与CRF模型在1 000份裁判文书上进行法律术语识别实验。采用10折交叉验证的方式, 将文书分为10等份, 按9:1的比例划分训练集和测试集, 共进行10轮实验。在AL-CRF识别实验中, 采用K-means聚类算法将训练集聚为8类, 根据聚类结果, 按照分层抽样的方式从中选择100份初始样本, 进行模型训练; 迭代地将未选择语料中熵值最高的50份样本加入训练集, 重新训练模型, 直到模型调和均值F的增长率小于0.1%时结束迭代; 最后用测试集评测模型的效果。而在CRF识别实验中, 直接采用随机抽样的方式从训练集中抽取与AL-CRF模型等量的样本数据进行模型训练, 并用同一测试集对模型效果进行评测。10轮对比实验的识别效果如表4所示。
通过表4可知, 在法律术语的自动抽取实验中, AL-CRF模型的迭代次数约为9, 即通过550份经由两轮专家标注的法律文书数据训练后, AL-CRF模型取得了较好的识别效果, 准确率、召回率都达到90%以上, 且相较于等标注工作量训练的CRF模型F值提高4.85%。具体到法律领域的5类实体, 模型识别效果如表5所示。
从法律领域各类实体的识别效果来看, AL-CRF的识别结果较CRF模型均有一定提升, 其中法律概念实体的提升效果最为明显。在这5类实体中, 法律原则实体的识别效果最差。通过对原始数据进行分析发现, 法律原则实体中含有大量长实体, 对长实体的识别错误是这类实体识别效果不佳的原因之一。识别效果最好的是罪名类实体, 这是因为本文预先构建了包含罪名的法律领域词典, 并将其导入NLPIR分词工具中, 使得罪名实体成为分词结果中的单个词语, 而在CRF模型的特征构建中, 词语本身是本文构建的特征之一, 从而准确地识别罪名实体。
自动识别中文法律文本中的法律术语是法律大数据结构化处理的基础。本文根据法律领域的数据特征, 应用主动学习算法, 将条件随机场模型作为主动学习的分类器, 采用基于K-means聚类的分层抽样方法构造主动学习算法的初始训练集, 利用基于信息熵的样例选择策略进行迭代过程中的样例选择, 设置基于F值变化率的迭代终止条件, 构建了法律术语识别模型——AL-CRF。实验表明, 将AL-CRF模型用于识别中文裁判文书中的法律术语时, 其调和均值可达到90%以上; 更重要的是, 通过主动学习算法减少了CRF模型训练过程中需要的训练样本数量, 降低了法律文本预先标注的工作量, 适用于法律大数据的命名实体识别, 为法律大数据的结构化处理和进一步分析挖掘奠定了基础。
本文研究存在一些不足, 例如采用的K-means聚类方法对数据噪声和离群点较为敏感, 可能导致初始训练集中存在部分离群数据, 进而影响模型的整体识别精度。因此, 改进AL-CRF模型, 优化其存在的一些不足是本文下一步的主要工作; 同时, 对于法律文本的其他结构化处理过程如实体属性识别、实体间关系提取等也将成为本文的未来研究方向。
黄菡: 设计研究方案, 设计并进行实验, 论文起草及修改;
王宏宇: 提出研究思路, 数据采集及预处理, 论文修改;
王晓光: 设计研究方案, 论文最终版本修订。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: hh@zuel.edu.cn。
[1] 黄菡. the Chinese judgments documents.txt. 原始裁判文书数据.
[2] 黄菡. dictionary.txt. 罪名词典.
[3] 黄菡. documents_clusters.zip. K-means聚类结果.
[4] 黄菡. Documents_annotated.zip. 文书命名实体识别结果.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}