
|
|

 , 段华, Duan Hua
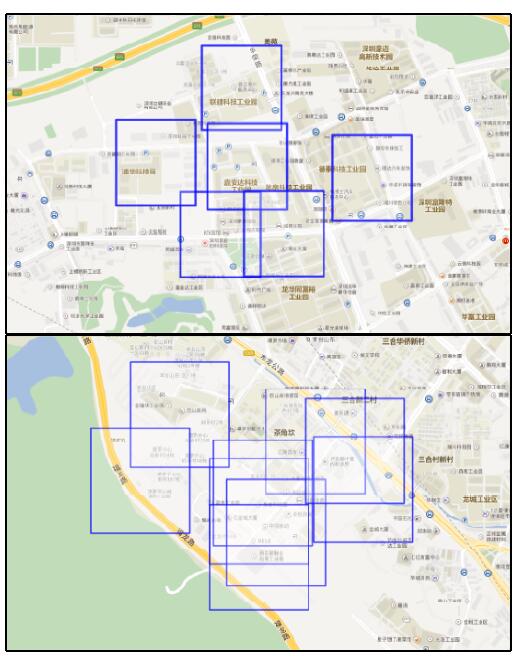
, 段华, Duan Hua【目的】发现重要位置, 为用户行为轨迹特征和规律的研究提供良好数据支撑。【方法】提出融合用户表示方法的重要位置预测模型, 提出基于Word2Vec的用户行为轨迹的向量化表示方法; 基于用户向量相似度构建用户关系网络, 提取访问位置上的核心用户; 通过核心用户的访问行为进行重要位置预测。【结果】实验结果表明, 基于本文方法过滤后的核心用户对重要位置进行标注, 比直接标注的正确率提升7%。在地图上显示标注区域, 能够有效发现对应的住宅区和商业区。【局限】本文方法只能够识别居住地和工作地, 更加细粒度的标注有待进一步实现。【结论】本文所提基于用户表示学习的核心用户过滤方法, 对重要位置的标注具有重要意义, 同时为研究用户的轨迹行为特征和规律提供了更为科学的决策支持。
[Objective] This paper tries to discover the important locations of users, aiming to provide good data support for user behavior studies. [Methods] We presented a model for predicting important locations based on user representation. First, we proposed a vectorized representation method to predict user behaviors based on Word2Vec. Then, we constructed a user relationship network based on the similarity of user vectors to extract core users. Finally, we predicted the important locations by the behaviors of core users. [Results] The precison of important locations classifiction was 7% higher than those of the exisitng methods. Moreover, the residential and commercial areas were shown in the labeled map. [Limitations] Our method can only identify residential and business areas. [Conclusions] The proposed method could effectively find important locations and provide more supports to study user behaviors.
随着移动应用技术和空间数据采集技术的发展, 用户空间移动行为轨迹数据的获取和分析成为数据挖掘研究中的热门方向之一。轨迹数据能够有效反映人类的行为活动, 在海量用户行为轨迹数据的背后, 隐含着丰富的用户行为规律信息和重要位置属性特征, 通过对这些信息进行深入挖掘和利用, 不仅能够发现个体用户的日常行为规律和群体用户的共性行为特征, 还可以掌握用户在重要位置下独有的行为特征。因此, 用户行为轨迹的分析与挖掘对用户位置预测、轨迹用户推荐和位置推荐等具有重要意义。
在众多有关用户行为轨迹的研究中, 如何发现轨迹中的重要位置一直是学者关注的重点。然而, 在用于记录用户行为轨迹的手机数据中, 由于存在数据噪声大、数据分布密度不均、用户结构复杂、数据准确性低、数据中存在基站跳变现象等问题, 导致用户手机轨迹数据存在质量不高的缺点[1]。在海量低质的手机轨迹数据上进行用户行为及位置特征的研究也就相对较少。已有研究[2]首先对海量低质手机轨迹数据进行预处理, 而后从用户人群行为规律角度、统计分析角度对重要位置进行推理和发现。该方法只侧重低质手机轨迹数据的处理, 没有考虑用户人群的属性特征, 缺少对人群数据的过滤与甄别, 导致重要位置识别效果较差。随着手机轨迹行为数据研究的逐渐深入, 一些研究者在对手机轨迹数据进行分析过程中发现, 重要位置上的核心用户行为是影响和反映该位置特征的关键[3]。
因此, 本文以表示学习理论为指导, 提出用户表示模型对重要位置核心用户进行过滤和甄别。具体工作包括: 对低质手机轨迹数据进行数据预处理, 引入Word2Vec理论和社交网络分析理论对不同位置上的用户群体进行核心用户过滤; 提取能够体现该位置特征的用户群体, 基于用户群体中核心用户的行为特征对位置进行识别标注。实验结果表明本文方法能够有效提高位置识别的准确率和召回率, 同时为后续空间轨迹分析与挖掘提供了重要的理论依据。
随着移动互联网的广泛推广, 移动轨迹数据的分析与挖掘能够更好地刻画现实世界, 因此有关面向位置的服务(Location-Based Service, LBS)的轨迹数据分析与挖掘受到学者广泛关注, 重要位置发现是轨迹数据分析与挖掘的关键问题之一。
重要位置[2]指人们在日常生活中的主要活动地点, 比如工作地和居住地。由于用户在重要位置的停留情况、连接次数与时间密切相关, 如用户在居住地的时间主要集中在夜间, 而在工作地的时间往往在工作日的白天, 因此挖掘某一重要位置, 需要给出用户出现在该重要位置的时间范围。随着基于位置服务技术的发展, 积累了大量用户移动空间轨迹数据。重要位置发现成为用户轨迹数据挖掘的重要研究方向之一, 也是用户空间行为刻画研究的基础。
早期重要位置发现方法主要从统计分析的角度进行研究, 文献[4]将目标区域进行栅格化处理, 而后将基站位置映射到栅格中, 统计用户在每个栅格的出现次数, 将次数最多的栅格看作包含重要位置的栅格, 使用栅格的中心点或在该栅格出现位置的平均值作为用户重要位置所在地。随着数据挖掘技术的发展, 出现了基于聚类分析进行用户重要位置发现的研究, 文献[2]直接对用户连接过的基站位置点进行聚类, 并将聚类中心作为用户重要位置。文献[1]则提出先聚类再过滤的改进方案, 考虑用户在各簇中的停留时间和次数, 从而筛选出潜在合理的簇。文献[5]基于用户社交媒体的签到数据进行用户空间行为分析与挖掘, 然而, 社交媒体的签到数据虽然位置精度高, 但是覆盖用户规模较小、人群窄, 而且还存在数据稀疏性问题。文献[6]基于用户刷卡记录数据分析居住地和工作地, 其覆盖人群仍不够广泛, 所获结果精度不够高。文 献[7-9]则基于手机轨迹数据, 进行重要位置发现和空间行为分析的研究。由于访问重要位置的用户行为复杂、数据质量差等问题, 导致统计分析和传统聚类方法识别重要位置的效果差。因此, 需要先对访问位置的用户进行过滤, 再基于过滤后的核心用户对重要位置进行识别。
表示学习又称表征学习(Representation Learning), 利用机器学习技术自动获取每一个实体或者关系的向量化表达, 旨在将研究对象的语义信息表示为稠密的低维实值向量, 是准确描述刻画研究对象的有效方法之一。表示学习是将研究对象用低维向量进行表示, 然后利用深度学习模型进行分析的一类研究方法。从最初自然语言处理领域的Word2Vec[10]到现在的Sentence2Vec[11]、Doc2Vec[12]、Topic2Vec[13], 再到社交网络领域的Node2Vec[14]、Poi2Vec[15]等。向量的表示方法不仅能够体现对象之间的量化关系, 还能够实现向量之间的运算操作。因此, 本文以表示学习的理论和方法为基础, 探索解决访问重要位置的用户行为复杂导致的重要位置识别效果差的问题。提出基于用户行为表示的核心用户过滤模型, 从而提高重要位置的识别效果。
轨迹数据有极大的研究价值, 但是针对手机轨迹数据存在数据准确性低、数据分布密度不均、数据噪声大、数据中存在基站跳变现象等问题, 本文首先给出基于低质手机轨迹数据的用户行为轨迹形式化数据提取方法。
定义1 用户行为轨迹集合(The Set of User Information Trajectory, $\mathrm{SUIT}$): $SUIT(u)=$$\{Ui{{t}_{1}},$$Ui{{t}_{2}},$ $Ui{{t}_{3}},\cdots ,Ui{{t}_{n}}\}$,
通过对手机轨迹数据的观察与分析, 发现手机轨迹数据中多个位置记录表示的是用户同一个活动区域, 如果直接采用用户的时空轨迹$SUIT(u)$作为输入序列进行计算, 将会造成序列过长、质量不高且输出效果差等问题, 因此, 提出活动区域集合的定义, 用于描述轨迹中多个位置相近点的合并, 从而实现轨迹位置数据的二次处理, 提高用户移动轨迹数据的质量。
定义2 活动区域集合(The Set of Region, SR): $SR=\{S{{r}_{1}},S{{r}_{2}},S{{r}_{3}},\cdots ,S{{r}_{n}}\}$, $S{{r}_{i}}$表示用户活动区域多个位置的融合, $S{{r}_{i}}=\{lo{{c}_{1}},lo{{c}_{2}},\cdots ,lo{{c}_{m}}\}$, 其中$lo{{c}_{k}}$表示用户访问的位置记录。
基于活动区域, 对用户的轨迹数据进行转换定义, 形成以活动区域为基本单元的用户时空轨迹序列。
定义3 用户时空轨迹序列集合(The Set of Trajectory Sequence, STS): $STS(u)=\{T{{S}_{1}},T{{S}_{2}},T{{S}_{3}},\cdots T{{S}_{n}}\}$,
本文提出基于K-means的活动区域提取两步方法, 实现由用户行为轨迹到用户时空轨迹序列集合的转换, 具体实现算法如下:
输入: 用户行为轨迹集合$SUIT$
输出: 时空轨迹序列集合
①: 离异点过滤: 基于用户访问位置的时间, 对用户位置进行分析, 过滤掉与其他连续访问位置距离过大的噪声离异位置。生成$SUI{{T}^{'}}$
②: 基于用户轨迹的活动区域构建: 设定距离阈值$d$
③: 对用户访问序列进行判断:
④: for each $Ui{{t}_{i}}$和$Ui{{t}_{i+1}}$:
⑤: $lo{{c}_{new}}$: if $\left| (Ui{{t}_{i+1}}\to loc)-(Ui{{t}_{i}}\to loc) \right|\le d$:
⑥: 更新$lo{{c}_{new}}=((Ui{{t}_{i+1}}\to loc)+$$(Ui{{t}_{i}}\to loc))/2$
⑦: 更新轨迹信息: $Ui{{t}_{i}}=<uid,lo{{c}_{new}},t>$
$Ui{{t}_{i+1}}=<uid,lo{{c}_{new}},t>$
⑧: else 位置信息不更新
⑨: 位置更新: 从位置集合角度, 对所有用户访问的 所有位置集合, 本文采用K-means聚类算法进行位置的二次合并;
⑩: 基于聚类类标更新位置信息。
经过位置数据的区域性转换形成用户时空轨迹序列集合, 能够有效提高低质量手机轨迹数据的准确性, 为下一步用户行为的表示提供了准确度高、结构化强的轨迹数据集合。
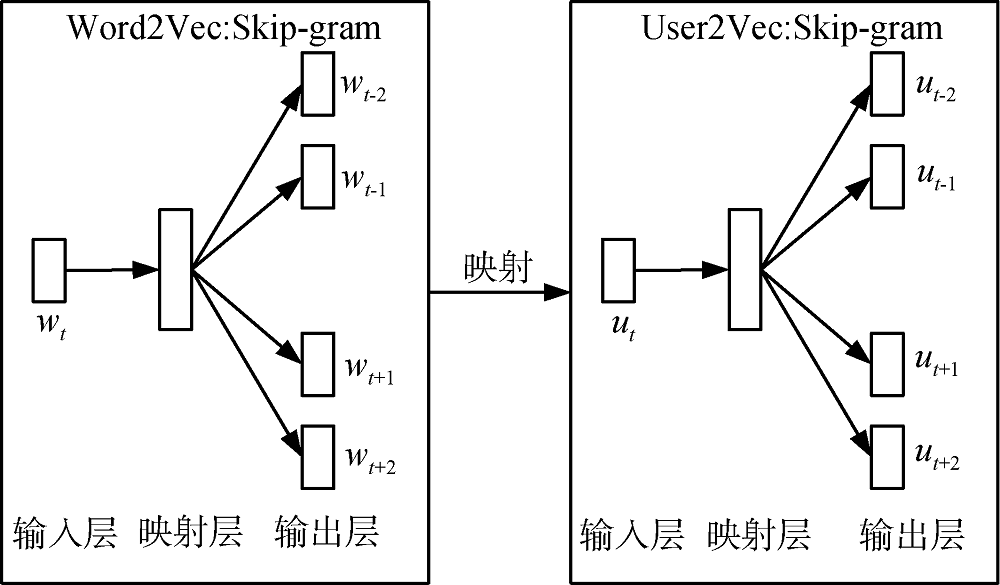
表示学习是利用机器学习技术自动获取每一个实体或者关系的向量化表达, 旨在将研究对象的语义信息表示为稠密的低维实值向量, 是准确描述刻画研究对象的有效方法之一。本文基于Word2Vec模型思想[9],提出User2Vec模型, 该模型首先基于用户的时空轨迹数据构建用户时空轨迹的文本表示, 而后引入Word2Vec模型计算用户实体的向量表示, 并基于用户之间的向量相似度进行核心用户提取。
根据定义3中的STS用户时空轨迹集合, 构建活动区域下的用户访问序列, 而后将用户映射为单词, 将活动区域下的用户访问序列映射为句子, 从而构建用户时空轨迹的文本表示。
定义4 活动区域下的用户访问序列(The Sequence of Users, SoU): $SoU(S{{r}_{m}})=$$\{T{{S}_{i}}\left| S{{r}_{p}}=S{{r}_{m}} \right.$$\And \And {{u}_{i}}\in $ $U\And \And T{{S}_{i}}$$\in STS({{u}_{i}})\}$, 其中,
根据用户访问同一个活动区域的用户访问序列, 计算用户之间访问的时间间隔, 当时间间隔小于阈值
定义5 用户轨迹序列文本(User of Sequence Text,
UST):$UST=\{{{u}_{1}},{{u}_{2}},\cdots {{u}_{i}},{{u}_{j}},\cdots |$$T{{S}_{i}}\in SoU(S{{r}_{m}})\And \And T{{S}_{j}}\in $$SoU(S{{r}_{m}})\And \And \left| T{{S}_{j}}.{{t}_{q}}-T{{S}_{i}}.{{t}_{q}} \right|<th\}$, 其中
以所有用户的
输入: 所有用户的时空轨迹集合
输出: 用户轨迹序列文档
①: 针对每个用户的时空轨迹集合
②: 以
③: 设置时间阈值
④: 提取用户轨迹序列文本, 形成用户轨迹序列文档
本文引入Word2Vec模型对用户的时空行为进行向量化建模, Word2Vec是Google于2012年实现的开源语言建模工具[10], 在自然语言处理领域得到广泛关注。它包含两种训练词向量的模型, 分别是连续词袋模型(Continuous Bag-of-Word, CBOW)和 Skip- Gram 模型, 两种模型都以神经网络作为分类算法, 包含输入层、映射层和输出层, 以文本集作为输入, 通过训练输出每个词的词向量。CBOW模型根据上下文预测当前词的概率, 而Skip-Gram模型则是基于当前词, 预测上下文的情况。对于词向量的训练过程, Word2Vec提供了Hierachical Softmax(HS)和Negative Sampling(NS)两种策略。本文将空间用户映射为Word2Vec模型中的词, 将
通过训练, 模型的输出结果为
${{U}_{mn}}=\left[ \begin{align} & {{x}_{11}},\,{{x}_{12}},\cdot \cdot \cdot ,\,\ {{x}_{1j}},\cdot \cdot \cdot ,{{x}_{1n}} \\ & {{x}_{21}},\,{{x}_{22}},\cdot \cdot \cdot ,\ {{x}_{2j}},\cdot \cdot \cdot ,{{x}_{2n}} \\ & {{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}_{{}}...... \\ & {{x}_{i1}},\,{{x}_{i2}},\,\cdot \cdot \cdot ,\ \,{{x}_{ij}},\ \cdot \cdot \cdot ,\ {{x}_{in}} \\ & {{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}_{{}}...... \\ & {{x}_{m1}},{{x}_{m2}},\cdot \cdot \cdot ,{{x}_{mi}},\cdot \cdot \cdot ,{{x}_{mn}} \\ \end{align} \right]$ (1)
其中, ${{x}_{i1}},{{x}_{i2}},\cdots ,{{x}_{in}}$为用户
网络结构能够有效表示用户之间的行为关系, 网络结构的度量也能够直观地体现节点重要程度。本文基于用户空间行为特征的向量进行用户关系计算, 采用余弦相似度进行度量, 构建相同活动区域下的用户行为关系网络。
定义6 $Sim({{u}_{i}},{{u}_{j}})$表示节点
$\begin{align} & Sim({{u}_{i}},{{u}_{j}})=\cos (\alpha )=\frac{\overrightarrow{{{u}_{i}}}\cdot \overrightarrow{{{u}_{j}}}}{\left| \overrightarrow{{{u}_{i}}} \right|\cdot \left| \overrightarrow{{{u}_{j}}} \right|}= \\ & {{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}{{_{{}}}_{{}}}\frac{{{x}_{i1}}{{x}_{j1}}+{{x}_{i2}}{{x}_{j2}}+{{x}_{i3}}{{x}_{j3}}+\cdots +{{x}_{in}}{{x}_{jn}}}{\sqrt{x_{i1}^{2}+x_{i2}^{2}+\cdots x_{in}^{2}}+\sqrt{x_{j1}^{2}+x_{j2}^{2}+\cdots x_{jn}^{2}}} \\ \end{align}$ (2)
以活动区域为基本单元, 构建活动区域下用户访问网络
定义7 基于活动区域的用户网络集合$G(S{{r}_{p}})=$ $\{V(S{{r}_{p}}),E,W\}$。其中,
根据网络分析和图论[16,17]中节点重要性度量指标的定义, 中心性(Centrality)是判定网络中节点重要性的量化指标。采用网络结构中的度中心性作为衡量节点在网络中重要程度的标准, 对每个活动区域的网络进行度中心性计算, 并取Top-N个度中心性较高的节点作为核心节点, 用于识别活动区域的特征。具体实施算法如下。
输入: 用户间的相似度$Sim({{u}_{i}},{{u}_{j}})$
输出: 活动区域核心节点
①: 基于$Sim({{u}_{i}},{{u}_{j}})$计算每个活动区域下用户之间的相似度;
②: 基于用户之间的相似度和设定的阈值$\theta $, 构建每个活动区域下的网络结构$G(S{{r}_{p}})$。本文采用相似度的均值作为阈值;
③: 计算每个活动区域网络$G(S{{r}_{p}})$的网络结构特征, 计算网络的度中心性, 并排序;
④: 取每个活动区域下的Top-N节点作为活动区域属性分析的核心节点输出。
用户的属性以及访问时间对识别重要位置有重要影响, 文献[1]提出将工作日与周末的7PM至7AM定义为“Home”时间; 工作日的7AM至5PM定义为“Work”时间。因此, 本文结合以上描述, 基于人们日 常生活规律以对数据的统计分析, 给出访问时间范围的设定规则。
①连接时间范围$TR=\{t|t\ge 8:00\And \And t<12:00\}$,
有工作时间倾向的连接时间范围;
②连接时间范围$TR=\{t|t\ge 12:00\And \And t<14:00\}$,
有就餐时间倾向的连接时间范围;
③连接时间范围$TR=\{t|t\ge 14:00\And \And t<17:00\}$,
有工作时间倾向的连接时间范围;
④连接时间范围$TR=\{t|t\ge 17:00\And \And t<20:00\}$,
有就餐时间倾向的连接时间范围;
⑤连接时间范围$TR=\{t|t\ge 20:00\And \And t<08:00\}$,
有居住地时间倾向的连接时间范围。
基于以上规则, 计算用户在规则时间范围内, 核心用户的连接次数、停留时间、连接频率等属性的值, 形成以活动区域为基本单元的区域特征属性二维表。
本文对重要位置的预测主要包括两类: 居住地和工作地, 基于用户行为生成的区域特征属性数据的特征, 采用基于支持向量机的分类预测模型进行关键位置预测。支持向量机基于结构风险最小原理, 为控制泛化能力, 需要控制两个因素, 即经验风险和置信范围值。支持向量机以训练误差作为优化问题的约束条件, 以置信范围最小化作为优化问题, 最终化为解决一个线性约束的凸二次规划求解问题, 所以支持向量机的解具有唯一性, 也是全局最优的。因此本文基于支持向量机构建分类预测模型能够有效优化最终预测的准确性。实验证明支持向量机的分类模型效果要优于其他分类模型。
使用某手机运营商提供的手机IP连接日志数据进行方法的验证。通过预处理后, 实验数据包括大约654万条轨迹序列数据, 涵盖大约135万个位置, 分布在深圳、广州、东莞等多个城市。对135万个位置进行活动区域处理, 共标注11 171个重要的活动区域作为识别和预测区域。其中包括4 525个居住地和6 646个工作地。
基于对数据的统计分析和相关文献提供的方法, 对涉及的参数进行设定和优化, 具体参数设定如表1所示。
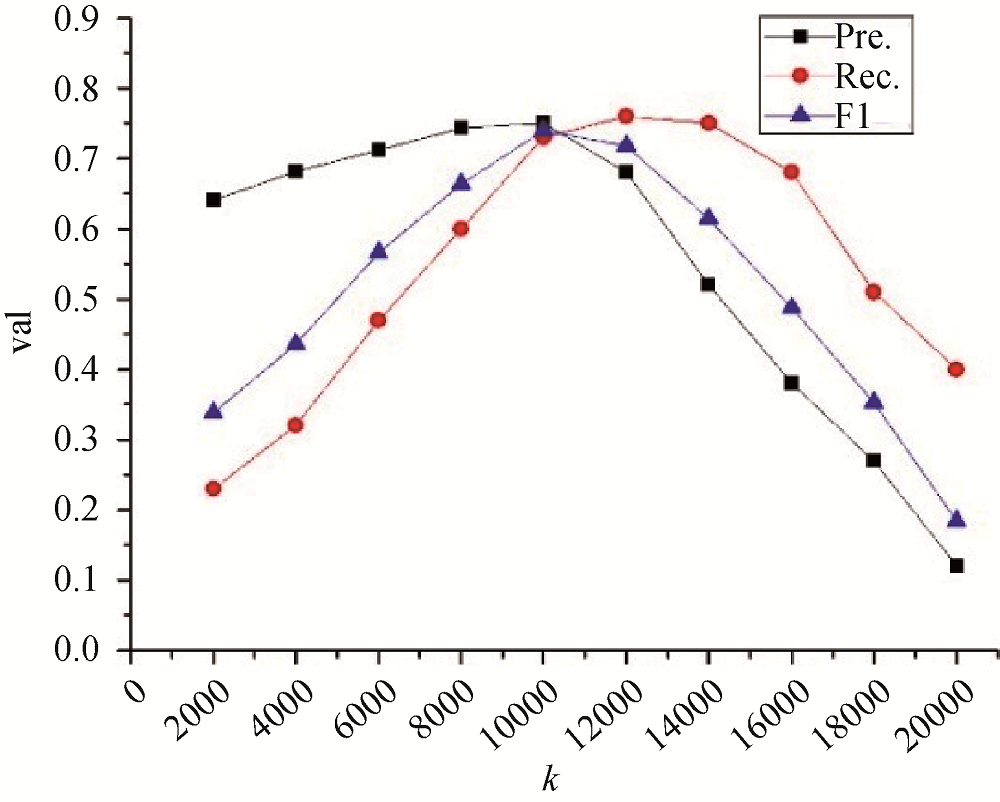
为验证活动区域提取过程中聚类个数
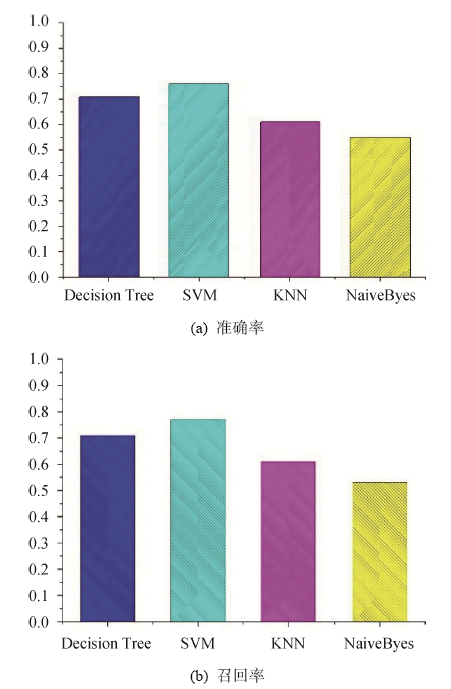
另外, 本文验证了不同分类预测模型对重要位置预测结果的影响, 采用SVM预测模型与DecisionTree、KNN和NaiveBayes等4种分类算法分别进行实验, 其评价指标为准确率、召回率, 如图3所示。
由实验结果可知, SVM分类模型在本文给出的输入数据中的准确率、召回率是最好的。
最后, 验证了核心用户对实验结果的影响, 分别进行对比实验:
(1) 本文提出的核心用户提取方法(Embedding UserBased);
(2) 未过滤的全部用户的方法(AllUserBased);
(3) 对重要位置的随机预测的方法(Based Line)。
本文选择SVM模型进行分类实验。实验结果如图4所示。实验结果表明, 使用本文基于用户向量的表示学习方法, 对访问用户进行过滤, 而后用于对重要位置的识别能够有效提高预测结果的准确率和召回率。由ROC曲线比较可知, 本文提出的用户向量表示过滤核心用户用于重要位置识别正确率能够提高近7%。同时, 也证明了重要位置的属性特征是由访问该位置的核心用户决定的。本文方法能够有效过滤掉与该位置关联相对较少且不能反映该位置特征的用户行为数据。
本文对低质量手机数据进行深入分析和理解之后, 针对数据质量差的问题, 基于聚类算法对用户位置进行活动区域映射; 引入表示学习理论, 应用Word2Vec模型构建User2Vec模型, 对用户访问行为进行向量表示, 并在此基础上, 应用网络结构分析, 提取活动区域网络下的核心用户; 最后, 基于核心用户的活动属性, 采用基于支持向量机的分类预测模型进行重要位置的识别和预测。通过实验分析, 发现利用经过核心用户筛选之后的数据进行重要位置的识别效果, 要优于直接进行重要位置识别。本研究能够对未知位置进行发现和识别, 并在此基础上研究用户的出行规律。然而, 本研究只是初步分析了特征比较明显的居住地和工作地, 有待进一步实现更多特征区域的识别, 以及表示学习在活动区域上的应用等。
曾庆田: 提出研究思路, 设计研究方案, 修改论文;
戴明弟: 实验数据预处理、实验的设计与实现, 论文初稿撰写, 修改论文;
李超: 实验结果分析, 论文框架设定, 论文修改;
段华, 赵中英: 研究方案的设计与讨论, 修改论文。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: 1008lichao@163.com。
[1] 李超, 戴明弟. 原始数据_手机轨迹数据.zip. 原始数据.
[2] 李超, 戴明弟. 实验过程数据.zip. 实验中间数据.
[3] 李超, 戴明弟. 实验结果数据.zip. 实验结果数据.

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}