
|
|

 , 周俊艺, Zhou Junyi
, 周俊艺, Zhou Junyi【目的】尝试在图书评论主题抽取中引入自然语言语义信息。【方法】将常识知识库的全局语义信息应用到图书评论主题词发现和主题聚类任务中, 自动抽取评论中的显性主题词和隐性主题词。【结果】实验结果表明: 与双向传播算法相比, 基于知识库方法抽取结果的句覆盖率高出30.8%, 主题词汇多样性高出0.36%。以此为基础绘制主题词共词聚类图谱, 结合知识网络中的节点中心度呈现各个类簇中的关键主题词。【局限】由于目前没有成熟的图书评论领域知识库, 本文主题挖掘过程未引入领域知识, 还未达到最理想效果。【结论】基于知识库方法有助于提高图书评论主题抽取的句子覆盖率和主题词汇多样性。
[Objective] This paper tries to extract topics from book reviews with the help of natural language semantics. [Methods] We proposed a method to retrieve the explicit and implicit topic keywords with the global semantic information from common sense knowledge base. [Results] The sentence coverage rate with the knowledge base method and the lexical diversity of the proposed method were 30.8% and 0.36% higher than those of the Double-Propagation algorithm. Then, based on the extracted topic words, we created a cluster map to identify the topic keywords identified by the nodes cluster centrality. [Limitations] There is no domain knowledge base in the field of book reviews. [Conclusions] The proposed method based on Knowledge Base improves the sentence coverage and lexical diversity of topics extracted from book reviews.
图书评论是了解用户对图书内容、形式与意义观点的主要途径。目前互联网已经成为图书零售的重要渠道, 互联网上发表的图书评论是消费者面对种类繁多的图书商品做出购买决策的重要参考, 同时这些图书评论也为作者、出版商提供了收集和分析读者观点的有效渠道, 能够为图书出版和宣传提供科学依据。
主题分析是情报检索的重要环节, 图书评论主题抽取的研究目标是从图书评论中挖掘被评价的具体对象, 属于细粒度观点挖掘。图书评论主题抽取问题中, 自然语言语义的复杂性一直是难点。本文尝试将常识知识库的全局语义信息应用到图书评论主题词发现和主题聚类任务中, 自动抽取典籍英译图书评论中的显性主题词和隐性主题词, 并以此为基础绘制主题词共词聚类图谱呈现关键主题词。
评论主题词抽取任务可以分为显性主题词抽取和隐性主题词抽取, 显性主题词在评论文本中以名词或名词短语等形式显性出现; 隐性主题词通常字面表征不明确或者没有直接的书面表述形式, 是需要通过深入的概念分析才能挖掘出来的主题概念或复杂概念的组合, 隐性主题词的分析与提炼建立在显性主题词基础上[1]。面向文献检索领域, 隐性主题词具有隐含性、相对性、模糊性和依附性, 不同文献情报机构基于不同角度、知识结构基础和词表参照系统, 揭示的隐性主题词有所不同, 隐性主题词与显性主题词的相关程度难以准确衡量[1]。
显性主题词抽取方法主要有无监督的基于规则方法、聚类方法, 以及有监督方法。基于规则的方法难点在于规则模板的建立需要领域专家的参与, 例如Hu等[2,3]利用关联规则挖掘频繁项集作为产品特征, 局限是非频繁主题词的识别率低; Qiu等[4]利用句法依存关系建立双向传播算法抽取模版, 在中等规模语料集上的效果较好。Poria等[5]利用依存关系、WordNet和SenticNet常识知识库检测评论主题词, 在公开数据集上取得很好的效果。聚类方法的可移植性有限, 如Su等[6]利用中文概念词典等多源知识, 提出COP-Kmean聚类和相互强化规则挖掘产品特征和观点词间的映射, 但难以用来解决其他问题。
图书评论主题相对分散[13], 现有研究局限于少量图书的评论数据或主观分析方法, 如Sohail等[14,15]将图书评论主题分为7类, 收集20个用户对计算机图书评论的主观反馈进行验证, 局限在于主题类别是主观设置而并非从评论文本中抽取; 陈晓美[16]基于LDA主题模型提出评论观点识别和判定方法, 利用《卡尔威特的教育》一书的评论文本进行验证, 实验方法未得到广泛验证。可见, 当前亟需面向大样本数据的图书评论主题自动抽取方法。
综上, 商品评论的显性主题词自动抽取技术已经比较成熟, 尤其随着深度学习算法和高维表示模型的利用, 显性主题词的自动抽取准确率提升明显; 但隐性主题词的抽取自动化程度不高, 需要领域专家的参与; 领域知识库的建立有助于将领域专家的知识建模, 但目前领域知识库资源少、建设成本高, 而且需要随着语料的变化不断更新。由此, 本文尝试在图书评论主题词抽取中突破主观分析和小样本数据的局限, 引入常识知识库自动抽取显性主题词和隐性主题词, 并形成主题词聚类图谱呈现关键主题词。
自然语言语义的复杂性是主题抽取中待解决的问题。自然语言文本中的同义词、近义词、同词异形、同词异义等语义信息只有在上下文中才有意义, 本文利用外部常识知识库对图书评论语料进行全局语义映射, 提出从评论文本中同时抽取显性主题词和隐性主题词的无监督方法。
自然语言中的概念可以表达为多种形式, 受限于知识库规模, 语料中的词汇无法全部映射到知识库的概念上。因此, 基于常识库主题词挖掘的关键问题是如何表示这部分非概念词汇。
AffectNet是一个多学科的常识和情感知识库[17], 其中每个概念表示为矩阵中的一行。Rajagopal等[18]利用AffectNet知识库, 采用相似性检测将知识库中未包含的非概念词映射到知识库中的相似概念词。两个概念之间的相似度通过行向量间的点积来量化, 点积值越大, 概念相似度越高。为避免点积计算的维度灾难, 使用截断的奇异值分解法, 设AffectNet矩阵的低阶近似矩阵为$\tilde{A}=US{{V}^{*}}$, 其中
$\begin{align} & \underset{\tilde{A}|rank(\tilde{A})=k}{\mathop{\min }}\,|A-\tilde{A}|\ =\underset{\tilde{A}|rank(\tilde{A})=k}{\mathop{\min }}\,|\sum{-{{U}^{*}}\tilde{A}V}| \\ & \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ =\underset{\tilde{A}|rank(\tilde{A})=k}{\mathop{\min }}\,|\sum{-S}| \\ \end{align}$ (1)
本文进行图书评论主题抽取的总体思路是: 从图书销售网站爬取用户原始评论语料, 通过词性标注、词干处理得到评论的概念列表全集; 构建浅层语法和深层语义相结合的评论主题词发现模式, 运用常识知识库将高维评论文本映射到低维主题词空间, 揭示概念之间及概念属性之间的句法相似度和语义相似度, 通过概念属性匹配和常识库多标度矩阵概念向量夹角度量获取主题词表, 多维度分析挖掘隐含的评论主题词; 为进一步理清主题词的知识关联, 运用共词聚类挖掘主题相近的主题词子类, 通过共词聚类图谱的度数中心度评价主题词在知识网络中的影响力, 进而获取关键主题词。
基于知识库的评论主题抽取系统架构如图1所示。从要素上看, 系统包含预处理模块、主题词抽取模块和主题聚类模块。对于给定的图书评论主题词抽取任务, 先从相关网站上获取评论语料形成原始评论数据, 对评论语料进行分句处理; 对于分句后的评论文本, 执行句法分析截断为语句块; 再对语句块进行词干化处理, 通过词性标注分析获取句子的概念列表全集。
(1) 主题词抽取
①检测句法相似度, 对于概念列表中的每一个名词短语语块, 分别抽取语块中的句法元素及其在知识库中匹配概念的属性, 组成名词短语语块的相关属性集合。两两比较这些属性集合, 判断两个名词短语构成的概念是否存在共同元素, 如果发现共同元素则认为两个名词短语相似, 记录在知识库中匹配的概念集合中。
②检测语义相似度, 对于概念列表中的每一个名词短语语块, 在知识库中搜寻语义相似的概念, 语义上相似的概念在语义空间上也表现为相似。此处通过AffectNet计算语义相似度, AffectNet矩阵中的行表示自然语言中的概念, 列表示不同的常识特征值。基于公式(1)中的多维标度矩阵中概念向量间夹角计算语义相似度。
③组合句法相似度检测和语义相似度检测的结果, 找出候选词在AffectNet中句法和语义均相似的概念, 添加到主题词列表。这些主题词既包含显性主题词, 也包含隐性主题词。
④重复步骤①-步骤③, 直至所有语料处理完毕。
(2) 主题聚类
图书评论的观点信息通常按照主题相互聚集, 聚集程度高的词汇一般是具有代表性的主题词。传统的共词聚类存在同义词、近义词辨识和词语歧义问题, 共现关系不能有效表现关键词间的语义相关性, 人工调整或加权处理也很难保证其共现关系的真实性[19,20]。胡昌平等[21]和Wang等[22]研究发现, 对词语进行语义化处理可以改善共词分析效果。
在主题聚类模块中, 将主题词抽取模块中基于常识知识库映射的全局语义信息作为共词聚类的输入, 采用加权模块参数化聚类算法, 将主题词之间的共词网络简化为若干概念相对独立的主题聚类类团, 使得同一类团内主题相似性最大, 不同类团间主题相似性最小, 从而直观地表示主题词间联系的密切程度, 进一步对读者共同关注的具体图书属性进行概括分类。
加权模块参数化聚类算法[23]的优点是效率高, 适合处理大规模数据, 能够保持同一领域多个映射之间的一致性。具体实现方法如下[24]: 设
${{S}_{ij}}=\frac{2m{{c}_{ij}}}{{{c}_{i}}{{c}_{j}}}$ (2)
聚类的具体任务是为每一个节点
$V({{x}_{1}},\cdot \cdot \cdot ,{{x}_{n}})=\sum\limits_{i<j}{{{s}_{ij}}}{{d}_{ij}}^{2}-\sum\limits_{i<j}{{{d}_{ij}}}$ (3)
其中, 第一项代表节点间的吸引力, 关联度高的节点互相吸引, 节点间关联越强吸引力就越强; 第二项代表排斥力, 关联度低的节点互相排斥。
${{d}_{ij}}=\left\| {{x}_{i}}-{{x}_{j}} \right\|=\sqrt{\sum\limits_{k=1}^{p}{{{({{x}_{ik}}-{{x}_{jk}})}^{2}}}}$ (4)
${{d}_{ij}}=\left\{ \begin{align} & 0\ \ \ \ \ \ \ {{x}_{i}}={{x}_{j}} \\ & 1/\gamma \ \ \ {{x}_{i}}\ne {{x}_{j}} \\ \end{align} \right.$ (5)
公式(5)中, 分辨参数
$\overset{\scriptscriptstyle\frown}{V}({{x}_{1}},\cdot \cdot \cdot ,{{x}_{n}})=\frac{1}{2m}\sum\limits_{i<j}{\delta ({{x}_{i}},{{x}_{j}}){{w}_{ij}}\left( {{c}_{ij}}-\gamma \frac{{{c}_{i}}{{c}_{j}}}{2m} \right)}$ (6)
$\delta \text{(}{{x}_{i}}\text{, }{{x}_{j}}\text{)}=\left\{ \begin{align} & \ 1\ \ \ \ \ \ {{x}_{i}}={{x}_{j}} \\ & \ 0\ \ \ \ \ \ {{x}_{i}}\ne {{x}_{j}} \\ \end{align} \right.$ (7)
其中, 权重
${{w}_{ij}}=\frac{2m}{{{c}_{i}}{{c}_{j}}}$ (8)
为验证本文基于知识库的图书评论主题抽取方法的有效性, 从主题词抽取和主题聚类两个方面进行实验, 实验过程包括图书评论文本数据采集和预处理、基于常识知识库的主题词抽取、主题词共词矩阵生成和基于共词矩阵的主题聚类。
典籍英译图书是中国文化走出去的重要途径, 相关评论是判断译本是否得到读者肯定的重要线索。本文从亚马逊网站采集典籍英译图书评论数最多的《孙子兵法》、《西游记》、《三国演义》、《红楼梦》和《论语》5本原著共17个英译本的读者评论, 共计 3 967条图书评论, 经过分句预处理得到由16 830句评论文本构成的语料库, 总字符数133万, 平均每句评论的文本长度为76字符。每本书籍的评论文本数、句子数、字符数、平均句子长度和译本版本数如表1所示。
对语料分句, 以句子为单位进行概念主题词抽取, 采用改进的Stanford词性标注工具[25]将输入的句子拆分为分句和语句块; 采用Lancaster Stemming Algorithm[26]词干化每个语句块; 使用Concept Parser在线分析器[27]进行逐句的主题词抽取, 通过定义概念词的词性标注搭配规则、句法相似检测和语义相似检测, 找出候选词在常识知识库AffectNet中相似度最大的概念, 获取概念词列表作为主题词, 通常表现为复合词。
基于知识库主题词抽取结果与Qiu等[4]提出的双向传播算法的对照结果如表2所示。从表2的句子层面观察, 基于知识库的主题词抽取的信息比双向传播抽取的信息更丰富, 抽取信息的统计结果如表3所示, 双向传播算法只有67.3%的句子返回抽取结果, 本文提出的基于知识库方法有98.1%的句子返回主题词抽取结果, 从语料中更多的句子中抽取了信息。从抽取信息的质量来看, 双向传播返回总词次也称为型符(Token)60 597个, 不重复计算的类符(Type)4 061个; 基于知识库方法返回总词次175 889个, 不重复计算的类符7 224个, 基于知识库方法返回的型符、类符数量均比双向传播方法多。词汇多样性是反映词汇信息丰富程度的测量维度, 为避免语篇长度对测量信度的影响, 采用Uber Index量化主题词抽取结果的词汇多样性, 计算方法如公式(9)所示。
$Uber\text{ }index=\frac{{{(\log Tokens)}^{2}}}{(\log Tokens-\log Types)}$ (9)
从表3可以看出, 基于知识库方法抽取结果的词汇多样性高于双向传播抽取方法, 虽然基于知识库抽取的复合主题词中重复出现大量的虚词, 如功能词of和介词to、in、with等, 这些词重复次数会使得词汇多样性降低; 而双向传播抽取的是特征词-特征词对、观点词-特征词对、特征词-观点词对和观点词-观点词对, 抽取结果主要包含名词、形容词等有实际意义的实词。综合考虑以上因素, 基于知识库主题词抽取方法的效果更好。
分别统计5本图书评论的主题词频, 保留主题词列表中有名词释义的词汇, 根据自定义的停用词表筛选去除停用词形成主题词表, 停用词表包含语料中的非实体词条(目录词条、类别词条、书名词条、作者姓名和书中人物姓名, 如book、work、read、daiyu、sunzi等)。截取每本典籍的词频最高的20个主题词, 如表4所示, 在三本以上典籍抽取结果中出现的高频主题词汇加粗显示。
可以看出, 5本典籍英译评论者有很多共同关注的主题词, 如translation是5本典籍英译作品均被评论者使用的高频主题词, chinese、classic、reader、time、version出现在4本典籍英译评论者高频使用的主题词列表中, character、edition、end、language、life、original、page、volume出现三次, 表明相关话题被海外读者高度关注。
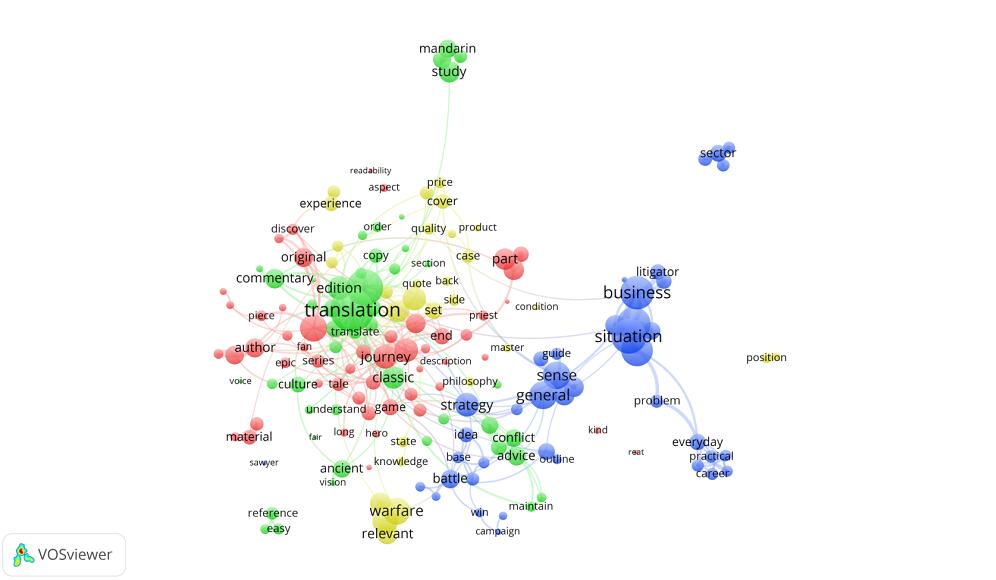
评论者共同关注的主题是本文另一个研究目标, 对主题词的聚类分析可以从冗杂的网络评论信息中抽取描述实体的概括性信息, 有助于对评论观点进行汇总分析。使用VOSviewer[28]实现主题词共词聚类, 为改进传统共词分析对于词汇语义关系表现的不足, 以常识知识库抽取的主题词表作为共词聚类的输入, 取词频20以上、句共现频率100以上的167个共现主题词, VOSviewer聚类模型吸引力参数取1, 排斥力参数取-1, 聚类分辨率参数取25, 最小类簇20, 标准化参数为“Linlog/Modularity”, 迭代次数300次。
聚类结果如图2所示, 其中不同圆圈代表主题词节点, 圆圈越大表明主题词出现频率越高, 距离越邻近表明主题词共现频率越高。主题词被分为4个聚类, 其中类1包含51个主题词, 类2包含46个主题词、类3包含41个主题词、类4包含29个主题词。
共词强度是社会网络分析中节点关键程度评价的重要标准, 主要指标是度数中心度。度数中心度越高, 说明该节点在知识网络中影响力越大, 越可能成为关键主题词[29]。采用知识网络中的度数中心度衡量每个类簇中的节点关键程度, 通过UCINET6.0软件分析得到按类簇度数中心度排序的主题词如表5所示。类1包含的关键主题词主要有: history、journey、character、part、interesting、plot、child、hero等, 主要与书中人物和情节相关; 类2包含的主题词主要有: translation、version、edition、classic、study、commentary、advice、rating、mandarin、English、translate、translator等, 对译本翻译风格、版本的关注比较集中; 类3包括situation、business、nature、deal、strategy、battle、fight、politics等, 主要与书中的主题内容相关; 类4包含的主题词主要有page、volume、cover、note、review、side、quality、price、error、paper等与书籍质量相关的词汇。综上, 典籍英译海外读者主要关注的问题可以概括为书中人物情节、翻译风格、主题内容和质量价格这4类。
本文利用常识知识库的全局语义信息, 提出基于常识知识库的无监督评论主题词抽取方法, 以亚马逊网站上17个版本典籍英译图书的评论为数据源进行研究, 自动抽取评论中的显性主题词和隐性主题词, 并以此为基础绘制主题词共词聚类图谱, 通过可视化的相似度映射技术和加权的模块参数化聚类算法呈现海外读者共同高度关注的主题类簇, 发现典籍英译海外评论者主要关注的4个主题类簇, 结合知识网络中的节点中心度呈现各个类簇中的关键主题词。研究结果表明基于知识库方法抽取的结果句子覆盖面更广、主题词汇多样性更丰富。
由于目前没有成熟的图书评论领域知识库, 本文主题挖掘过程尚未引入领域知识, 还未达到最理想效果。未来研究计划是建立图书评论领域知识库, 并在更大规模评论语料上测试, 进一步提高主题抽取的准确率。
祁瑞华: 提出研究思路, 设计研究方案, 进行实验, 论文起草及最终版本修订;
周俊艺: 采集、分析数据, 进行实验;
郭旭, 刘彩虹: 清洗和分析数据, 进行实验。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: rhqi@dlufl.edu.cn。
[1] 祁瑞华, 郭旭. 图书评论. csv. 典籍英译图书评论数据集.
[2] 祁瑞华, 郭旭. 概念词列表. csv. 基于知识库的概念词抽取结果.
| [1] |
[本文引用:3]
|
| [2] |
[本文引用:1]
|
| [3] |
[本文引用:1]
|
| [4] |
[本文引用:3]
|
| [5] |
[本文引用:2]
|
| [6] |
[本文引用:1]
|
| [7] |
[本文引用:1]
|
| [8] |
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
[本文引用:1]
|
| [11] |
[本文引用:1]
|
| [12] |
[本文引用:1]
|
| [13] |
[本文引用:1]
|
| [14] |
[本文引用:1]
|
| [15] |
[本文引用:1]
|
| [16] |
[本文引用:1]
|
| [17] |
[本文引用:1]
|
| [18] |
[本文引用:3]
|
| [19] |
[本文引用:1]
|
| [20] |
[本文引用:1]
|
| [21] |
[本文引用:1]
|
| [22] |
[本文引用:1]
|
| [23] |
[本文引用:1]
|
| [24] |
[本文引用:5]
|
| [25] |
[本文引用:1]
|
| [26] |
[本文引用:1]
|
| [27] |
URL
[本文引用:1]
|
| [28] |
[本文引用:1]
|
| [29] |
[本文引用:1]
|
| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |



{kind=link}
{kind=link}
{kind=link}
{kind=link}