
|
|

 , 祝忠明, Zhu Zhongming
, 祝忠明, Zhu Zhongming【目的】实现对机构知识库作者名消歧的高度自动化处理, 并在适当的时机提供人工介入机制。【方法】分析机构知识库作者名消歧的特殊性与消歧特征项, 依此构建机构知识库作者名通用消歧框架并实践部署。【结果】该框架在实际应用中取得良好的成效, 准确率达到99%以上。【局限】对缺失单位信息的作者名未进行处理; 作者别名与机构别名可能存在例外情况。【结论】该框架能够有效地解决机构知识库作者名消歧的难题, 在此基础上可构建更多的精准增值服务。
[Objective] This paper tries to automatically finish the disambiguation of author names in institutional repositories, and then provide human intervention mechanism at the right time. [Methods] First, we analyzed the unqiue features of the author name disambiguation. Then, we constructed a general disambiguation framework for the institutional repository. [Results] Our framework achieved good results in practice with more than 99% of precision. [Limitations] We did not examine the author names without affiliation addresses, and there may be exceptions in the alias of authors and institutions. [Conclusions] This framework could effectively disambiguate author names in institutional repositories, which helps us provide more value-added services.
作者名消歧是图书馆界长期面临的一个难题, 机构知识库(Institutional Repository, IR)的内容建设也存在此问题。IR通常会汇集不同来源的知识产出数据, 由于作者署名的多样性, 同一科研人员发表在不同期刊或被不同数据库收录的文章其作者姓名样式具有多样性。根据中国科学院IR建设的经验, 普通三个字中文姓名的常见英文别名样式不下十几种。因此, IR中通常很难将本属于同一作者的文章归并到该科研人员名下。在检索发现某一科研人员成果, 或进行机构知识资产审计分析时, 都需要明确每一篇产出具体对应的科研人员。如果不能很好地解决作者名消歧问题, 将不利于IR作品的统计分析, 也不利于作品的传播交流。
IR中的人名自动消歧, 总体上是属于自然语言处理中的命名实体识别(Named Entity Recognition, NER)中的人名消歧问题。传统的人名消歧研究主要是面向Web人名检索、人名知识库构建、基于全文的人名识别等领域, 而IR中的作者名消歧具有特殊性:
(1) 一般的人名消歧只需要区分不同的人名实体, 而IR中收录的都是本机构产出, 所以人名消歧后的实体都是机构成员。
(2) IR中的知识产出有相对规范的结构化元数据, 如题名、作者、关键词、出版物名称等。
(3) 由于科学交流的严谨性, IR中的人名消歧的准确度要求比较高, 如果自动消歧存在误差, 必须有人工介入纠正处理的机制。
由于以上特殊性, IR中的作者名消歧也不同于一般的人名消歧。
与IR作者名消歧有关的研究已有很多。无论是哪种方式的作者名消歧, 有一个共同点是都要为消歧后的作者分配一个唯一标识符(Name Identifier)。标识符的来源有两种, 一种是复用已有的被广为使用的第三方标识符, 如Scopus Author ID、Researcher ID、ORCID等, 另一种是IR为自己机构科研人员创建内部的唯一标识符。前者比较有代表性的是DSapce为元数据规范控制使用的Authority Control机制, 对作者元数据字段集成ORCID进行唯一标识[1,2]。
传统的IR作者名消歧一般由人工完成。例如, 在提交者或管理员进行作品提交或编辑时手动指定本机构作者对应的系统用户。CSpace[3]之前的处理方式是: 首先, 在用户注册时根据模板自动生成用户的几十种别名, 在作品提交时将当前作品中的作者名称与系统别名库中的用户进行匹配, 当匹配到一个或多个用户时向这些作者发送认领通知邮件, 用户收到邮件后登录系统进行确认[4]。类似的解决方案还有: 陈嘉勇等[5]提出基于文献实体关系分层模型的IR作者认领模式, 但这类方式大部分工作仍需要人工参与, 自动化程度不高。因此, IR作者名自动消歧研究的目标是尽可能地提高机器处理的自动化程度与准确度。
还有一些关于作者名自动消歧的算法研究。例如, Han等[6]使用的朴素贝叶斯和支持向量机方法, Treeratpituk等[7]使用的随机森林分类法选取文献相关特征项进行人名消歧。Fan等[8]提出基于作者合著图的人名识别GHOST框架。Song等[9]使用文献主题概率分布进行人名消歧。张雄等[10]通过个人信息特征和文献话题等特征, 采用多特征的融合方法充分挖掘与实体相关联的信息, 实现人名消歧。肖晶等[11]提出模糊匹配消歧算法。此类作者名消歧算法的共同之处是选取若干特征项, 将特征项的值作为输入参数, 使用某一种或几种算法对作者名进行聚类归并, 从而达到人名消歧的效果。这些算法主要面向文献资源库, 对于IR中的人名消歧来说, 由于IR作者名消歧的特殊性, 仅依靠消歧算法并不能一劳永逸地解决IR的作者歧义问题。一种比较好的方案是在消歧框架的适当环节加入相关的消歧算法, 从而提高消歧的效率与准确度。
要实现对IR作者名的自动消歧, 首先需要分析IR中的哪些数据项可用于作者名消歧。总体来说, IR中收录的知识产出数据特征项有限, 除了全文, 一般产出数据仅包含为数不多的题名、作者、发表期刊等元数据。以下是本消歧框架中可以用于IR作者名消歧的特征项。
(1) 作者唯一标识符
在发表自己的学术成果时, 有些期刊或出版商会要求作者填写Email或ORCID等个人唯一标识信息。有些数据库商或第三方系统也会提供处理过的作者唯一标识, 例如: Scoups收录的知识产出数据中可能会包含作者的Scopus Author ID, WOS收录的产出数据有些包含作者的Researcher ID等。
(2) 作者单位
IR收录的产出数据基本都是本机构科研人员的产出, 消歧的主要目标之一是为了统计本机构科研人员的发文情况, 因此IR的作者名消歧一般只针对本机构作者, 对外单位的合著者是不需要消歧的。公开发表的学术作品中一般都会有作者的单位信息, 可依此判断作品中的作者是否属于本机构。同作者姓名类似, 作者在发表文章时填写的单位信息会有多种格式, 例如, 以下几个作者单位对应的知识产出都属于“上海科技大学”。
ShanghaitechUniv, Shanghai 200031, Peoples R China
Shanghaitech University, Shanghai; 200031, China
上海科技大学创业与管理学院
(3) 作者别名
科研人员在不同时期发表文章时填写的作者名样式可能不一, 不同期刊或出版商对作者名样式的要求也可能不一。尤其是中文姓名的作者发表外文文章时, 其对应的外文姓名往往有很多种样式。例如, 姓和名的前后顺序, 是否使用全拼, 以及姓名存在的各种变种等。以中文姓名“杜九霖”为例, 其对应的英文别名包括但不限于以下几种:
Du JiuLin/JiuLin Du/Du JL/JL Du/Du, jiulin/Jiulin D/Du
Jiulin/Du Jiu-lin/Du J.L./Du J.-L./Jiulin Du/Jiu-lin Du/Du,
JiuLin/Du, Jiulin/Du, JL/Du, Jiu-lin/Du, J.L./Du, J.-L.
(4) 合著者
学术成果得以发表很多时候是整个科学家团队集体的智力结晶, 若一个科研人员与另一个科研人员有过合作, 那么以后他们很有可能会再次合作。因此, 一个科研人员的多篇产出中若有同名合著者, 则该合著者往往对应同一人。利用该特征, 不管机构作者的合著者是否是本机构成员, 也不管该合著者的作者名是否已消歧都可用于当前作者的名称消歧。
(5) 研究主题
在机构内如果多个科研人员的某一别名相同, 其研究主题往往是不同的。利用该特征可以对一篇产出的主题分别与同别名科研人员研究主题进行对比, 确定到底属于哪个科研人员。知识产出的主题可从作品的标题、摘要、关键词、主题词、学科分类、全文等数据项中提取。
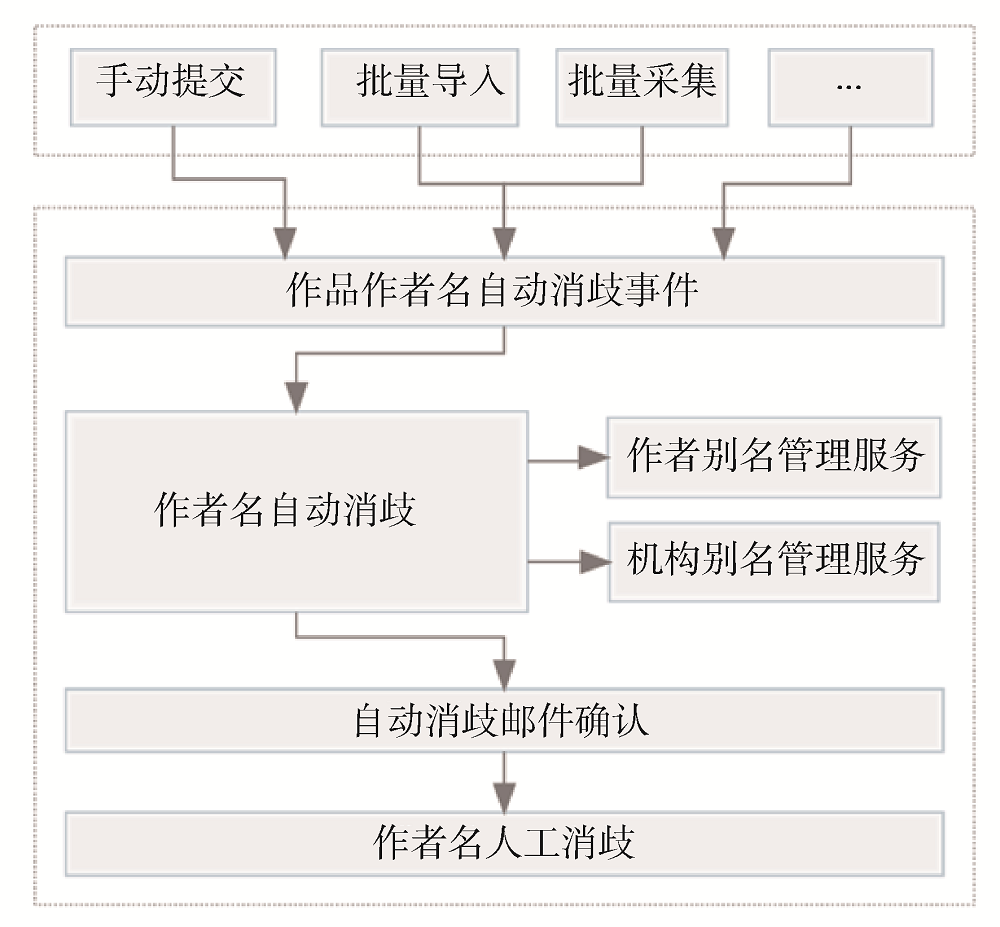
IR作者名自动消歧框架总体设计如图1所示。
IR中知识产出的存缴往往有多种途径, 包括: 科研人员或图书馆员手动提交、系统管理员批量导入或通过OAI等接口从第三方系统中同步等。为了支持不同途径提交的数据, 以及作品的作者等元数据项发生变化时能及时重新执行作者名自动消歧操作, 系统使用事件触发的机制调用作者名消歧服务。不管数据是以哪种方式进入系统的, 在提交成功后都会触发作品的作者名自动消歧事件。
自动消歧事件触发后, 会调用作者名自动消歧模块, 利用作者别名管理服务与机构别名管理服务完成作者名的自动消歧。其中, 作者别名管理服务模块主要是在用户注册的时候生成用户所有可能形式的别名, 在执行作者名自动消歧时根据当前作者别名返回其同别名的所有科研人员; 机构别名管理服务主要提供机构名称规范管理功能, 支持IR管理员预先定义本机构的规范中英文名称及其各种别名, 同时在作者名消歧时根据每一作者的单位信息判断是否为本机构作者。
自动消歧操作执行完成之后, 对于消歧失败或错误的消歧, 系统提供人工消歧功能, 由科研人员或系统管理员进行人工消歧或消歧纠正。
为保证消歧过程的可控性与准确性, 笔者对作者名的消歧定义以下5种状态:
(1) 未消歧或机器消歧不成功: 尚未进行消歧操作或虽然执行了消歧操作但不成功, 即没有找到作者名对应的系统科研人员用户;
(2) 机器消歧成功: 在作者名自动消歧过程中, 机器能够以比较高的可信度直接确定某一作者名对应系统中的某一科研人员用户;
(3) 机器消歧待确认: 在作者名自动消歧过程中, 自动消歧算法发现某一作者名可能对应一个或多个同别名用户, 且可信度都不高, 需要人工进一步确认;
(4) 科研人员手动消歧成功: 当前作者名消歧最终是通过科研人员手动方式实现的;
(5) 管理员手动消歧成功: 当前作者名消歧最终是通过管理员手动方式实现的。
以上第(2)、(3)种状态都是机器有自动消歧结果的, 对于这种处理结果, 系统会向相关用户发送确认邮件, 如果自动消歧结果不准确, 用户可进一步人工校正。最后两种是对前三种处理结果的补充, 由人工消歧模块实现, 该模块主要是针对消歧不成功的情况或对机器消歧进行人工干预。
作者名消歧相关数据表结构如图2所示。
其中, eperson表保存科研人员信息, 如科研人员的姓名、Email、系统登录密码等; author表保存作者姓名、Email、ORCID等信息; item表保存作品的核心元数据; organization表保存作者单位信息; organization_standard表与organization_alias表保存机构中英文规范名称与别名。作者名消歧的核心表是author2eperson表, 主要用于存储作者名消歧的结果——作品、科研人员、作者三者之间的关联关系以及消歧状态。
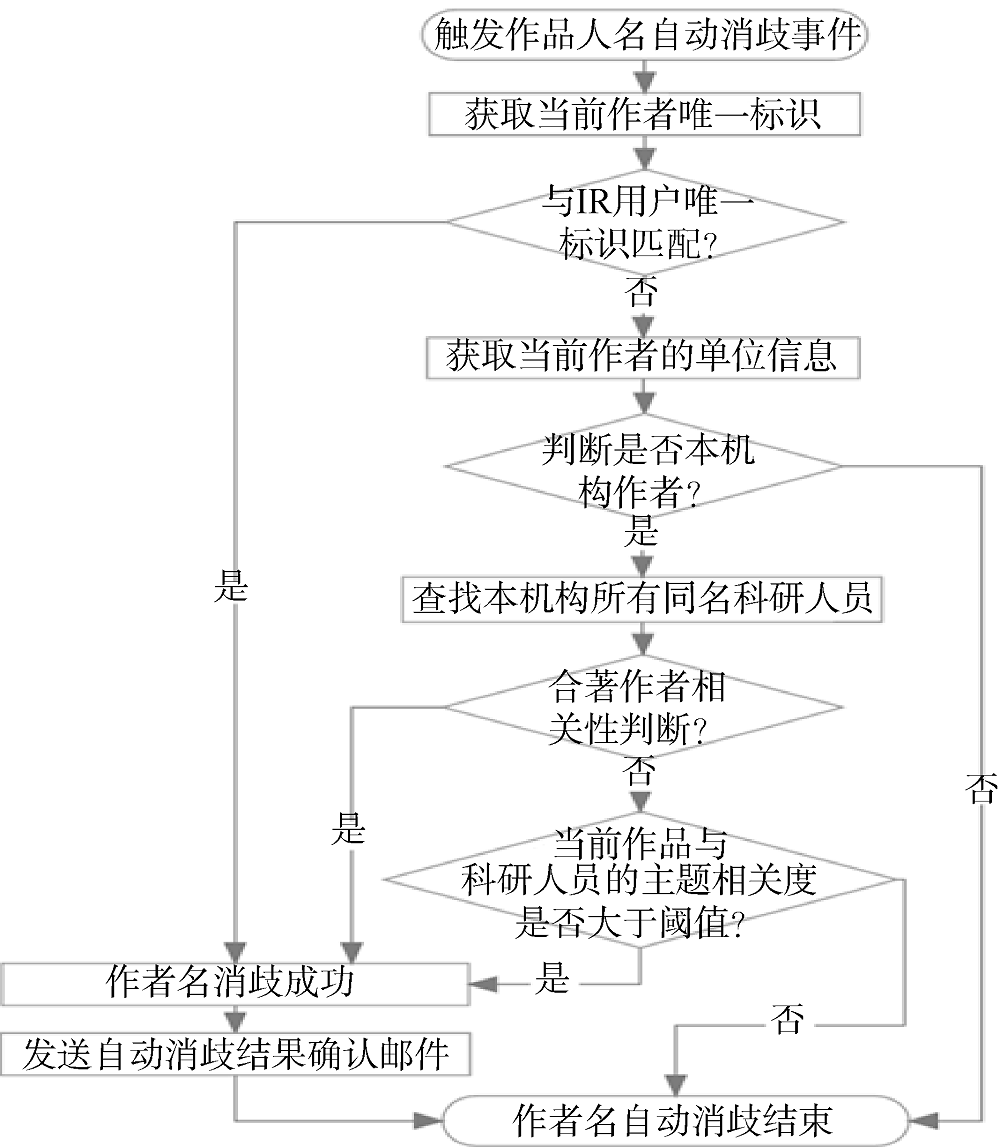
IR作者名消歧框架的核心是自动消歧模块。该模块在对某一个作品的作者名进行消歧时, 会循环读取当前作品的每个作者, 对于作品原始数据中没有作者唯一标识的, 除非判断该作者属于本机构才执行消歧操作, 否则认为该作者不是本机构科研人员且不执行消歧操作。对某一作者名的消歧一般处理流程如图3所示。
消歧过程主要包括以下几个步骤:
(1) 根据作者唯一标识消歧
判断作品元数据中是否有此作者对应的唯一标识信息, 如Email、ORCID、ResearcherID等, 如果有则将该唯一标识与系统中所有用户的唯一标识进行对比, 若匹配成功, 即判断该作品是该用户的产出, 并将消歧结果写入author2eperson表, 标记该条作者名消歧状态为“机器消歧成功”。如果作品元数据中当前作者名没有唯一标识信息则转入步骤(2)。
(2) 判断是否为本机构作者
读取作品中当前作者对应的单位信息, 作者单位信息一般有一条或者多条, 一般来说作者单位信息是由国家、城市、街道、单位别名、邮编等项组成的字符串。自动消歧模块通过机构别名管理服务判断这些作者单位信息中是否包含本机构的规范名称或别名, 如果有则确认当前作者属于本机构且需要进行消歧; 否则, 表示当前作者不属于本机构, 直接退出消歧处理流程。
(3) 获取本机构同别名科研人员
如果步骤(2)判断当前作者属于本机构, 这一步会通过作者别名管理服务, 获取当前作者名在本系统中所有同别名的科研人员。由于作者别名的多样性, 通过别名找到的科研人员可能会有多个, 这就需要通过作品的合著者与研究主题等方式进一步判断当前作者到底对应哪个科研人员。
(4) 通过合著作者消歧
一般情况下, 若某一待消歧作者名出现在两篇作品中, 且两篇作品中有一个相同的合著作者, 那这两篇文章出现的待消歧作者一般对应同一科研人员。对于作品的某一作者名, 如果在系统中找到两个或以上同别名科研人员, 利用该原则, 从系统中获取每个科研人员已消歧作品的合著作者名, 将其与当前作品的合著作者对比, 可利用如下公式判断哪个同别名科研人员曾与当前作品的合著者合作过。
其中,
(5) 通过研究主题消歧
使用研究主题消歧, 先获取每个同别名科研人员已消歧作品集合, 使用Jaccard相似系数计算当前作品与科研人员已消歧作品研究主题的相关度。如果与某一科研人员的相关度大于阈值且比其他同别名科研人员的相关度更高, 则认为当前作者名与该科研人员对应, 将其消歧状态标记为“机器消歧成功”; 否则, 将所有的同别名科研人员标记为“机器消歧待确认”。
(6) 发送自动消歧处理结果确认邮件
考虑到机器处理可能存在的错误, 对于自动消歧处理后无论是标记为“机器消歧成功”还是“机器消歧待确认”, 系统都会向相关用户发送邮件通知, “机器消歧成功”的科研人员如果发现自动消歧有误可手动纠正, “机器消歧待确认”的科研人员可以手动确认当前作品是否属于自己。
通过以上步骤可实现对作者名的自动消歧。由于原始录入的作品元数据质量不一, 有些作品的作者项缺失单位信息, 或者自动消歧不成功, 或者自动消歧结果有误, 这时候都需要人工介入处理。
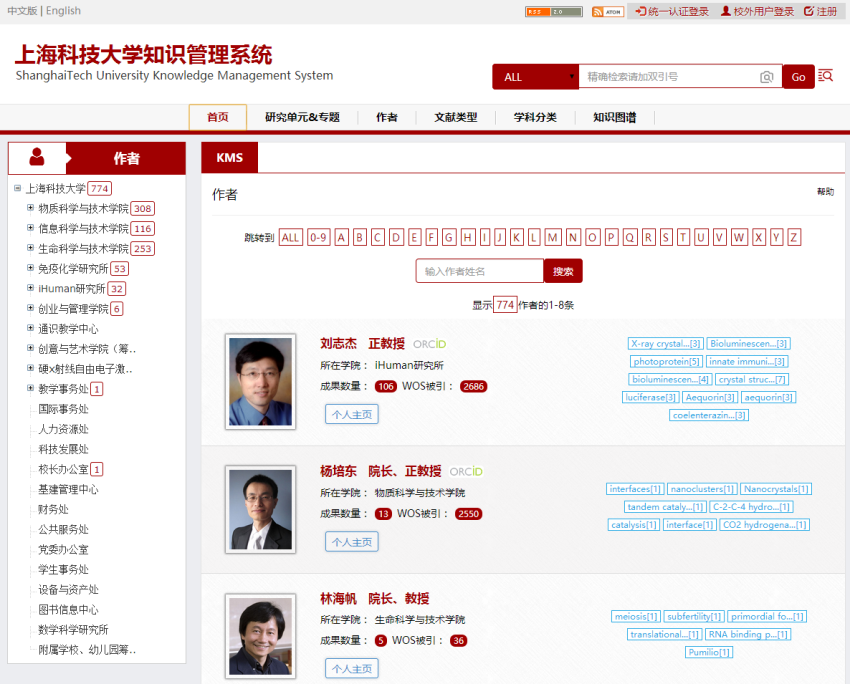
对于科研人员, 收到消歧确认邮件通知后, 可进入系统浏览个人已消歧与待消歧作品列表, 且支持科研人员对待消歧或已消歧作品进行手动消歧, 之后将其消歧状态标记为“科研人员手动消歧成功”。对于管理员, 系统提供了详细的消歧审计与管理功能, 管理员可按作品或消歧后的科研人员查看系统所有作品作者名的消歧进度、状态, 支持向科研人员批量发送消歧通知邮件, 以及对消歧结果进行手动修改, 如图4所示。
修改后系统会将该作者名的消歧状态标记为“管理员手动消歧成功”。机器最大程度实现自动处理的基础上, 在适当的环节加入人工干预机制, 既保证了IR作者名消歧的效率, 也保证了质量。
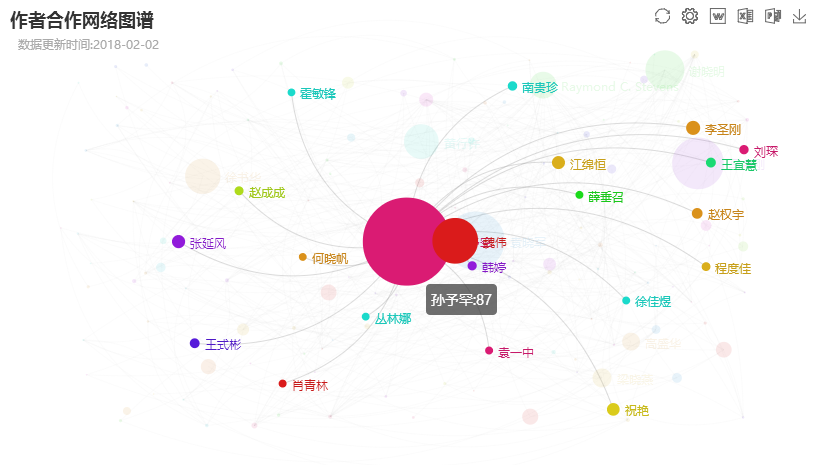
该作者名消歧框架已在机构知识库软件CSpace中实践应用, 如中国科学院一些研究所IR以及上海科技大学知识管理系统(ShanghaiTech University Knowledge Management System, STU-KMS)[12]等。以STU-KMS为例, 截至2018年2月2日, 收录的作品共1 698条, 使用该消歧框架对属于本机构的作者名消歧后得到共774个作者实体, 目前这些实体中99%以上都是由机器自动处理的结果, 其余主要是由于作者别名管理模块对国外作者英文别名的支持不完善造成自动消歧失败, 最后由管理员执行手动消歧。消歧后的作者实体列表如图5所示。作者消歧之后, 可在此基础上构建一些精准、可靠的增值服务, 例如机构科研人员合著网络图谱, 如图6所示。
通过图6可看出机构科研人员的成果量, 科研人员之间的合作关系, 以及机构的核心研究队团等信息。此外, 类似的服务还有基于已消歧作者名的科研人员成果检索、个人主页科研成果列表展示、机构科研成果多维度统计分析等。
由于IR作者名消歧的特殊性, 传统的消歧方案要么主要依靠人工完成, 要么只偏重于机器自动消歧的算法研究, 缺少自动消歧统一处理框架。在实际应用中, IR作者名消歧一方面要尽可能地提高自动化程度与效率, 另一方面在消歧过程中须提供人工介入机制, 使整个消歧过程可控。依此, 本文提出一种通用的IR作者名消歧处理框架。该框架既支持高度自动化的作者名消歧, 也针对机器消歧可能存在的不准确性, 支持用户对消歧结果进行确认。此外, 针对机器消歧不成功的情况提供了科研人员与管理员手动消歧功能以补充自动消歧的不足。
经实践检验, 该作者名消歧处理框架在实际应用中取得了良好的成效, 较之CSpace以前的所有作者名消歧都需要人工确认, 该方案可以实现自动化处理。但有以下方面仍需进一步优化: 目前的方法必须要求作者与作者单位信息间建立关联关系, 否则自动消歧时会不做任何处理; 主题相关度算法中可以加入更多的特征项, 例如标题、摘要、项目等数据, 或通过全文文本挖掘提取主题信息从而提高消歧的准确度; 作者别名、机构别名例外情况的处理。通过不断完善改进, 进一步提高IR作者名消歧自动化程度, 以及自动处理的召回率与准确率等, 从而更好地支持在此基础上构建IR的增值服务。
张旺强: 总体框架设计与核心功能编程实现, 论文撰写;
祝忠明: 确定研究方案, 论文修订;
李雅梅: 参与框架设计与完善;
卢利农: 负责框架有效性检验并提供统计数据;
刘巍: 框架前期调研与部分设计工作。
所有作者声明不存在利益冲突关系。
支撑数据由作者自存储, E-mail: zhangwq@llas.ac.cn。
[1] 李雅梅, 张旺强. 作者名未消歧STU-KMS作品列表. xls.
[2] 李雅梅, 张旺强. 作者名已消歧STU-KMS作品列表. xls.
| [1] |
URL
[本文引用:1]
|
| [2] |
URL
[本文引用:1]
|
| [3] |
URL
[本文引用:1]
|
| [4] |
[本文引用:1]
|
| [5] |
[本文引用:1]
|
| [6] |
[本文引用:1]
|
| [7] |
[本文引用:1]
|
| [8] |
[本文引用:1]
|
| [9] |
[本文引用:1]
|
| [10] |
[本文引用:1]
|
| [11] |
[本文引用:1]
|
| [12] |
URL
[本文引用:1]
|

| 版权所有 © 2015 《数据分析与知识发现》编辑部 地址:北京市海淀区中关村北四环西路33号 邮编:100190 电话/传真:(010)82626611-6626,82624938 E-mail:jishu@mail.las.ac.cn |



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}