




1 引 言
句子是完整表述知识内容的最基本单元[4], 其功能识别是科技文本细粒度知识抽取、挖掘和利用的基础。句子功能识别技术实质上是一个文本分类问题, 这就要求有充足的类别标注数据作为训练集。例如, 在引文句的引用意图识别上, 已有研究多以人工标注数据为语料库开展训练, 时间成本和标注效率难以保障[5]。结构化摘要中包含研究目的、方法、结果、局限和结论等功能句, 可作为现成的训练数据, 但其数量较少, 在一定程度上不足以支撑相关模型的有效训练。此外, 将基于结构化摘要学习到的分类模型迁移到其他句子功能识别时, 必然存在泛化能力受限的问题。以普通摘要功能句识别为例, 结构化摘要与其具有一定相似性, 但普通摘要的非规范化撰写导致其行文与结构化摘要存在差异。因此, 如何降低标注成本并提升领域的泛化能力是需要解决的关键问题。
本文将主动学习的思想[6]应用于科技文献句子功能识别中。鉴于科技文本语句功能识别的应用场景至少包括普通摘要、引文句、特定章节中语句乃至全文句子, 而目前又很少有研究围绕上述问题展开, 本文以普通摘要语句功能识别为场景展开研究。根据量化的结果分析实验效果, 探究主动学习在相近任务场景下提升基本分类模型泛化能力的可行性, 同时为后续开展更多场景下科技文本语句功能识别工作提供借鉴。
2 相关研究
2.1 短文本分类
短文本分类的具体流程上与传统文本分类相同, 但短文本存在严重的特征稀疏性问题, 通常需要依据外部资源或内部语义关联对其进行扩展[7]。Fan等提出挖掘文本中词语共现关系以构建特征共现集合, 从而对短文本的特征进行扩展[8]。Kim等以维基百科为工具构建扩展词表, 以辅助短文本分类[9]。Chen等通过将短文本的TF-IDF特征与LDA多粒度主题分布特征进行拼接, 达到对短文本扩展的目的[10]。Dai等提出基于AP算法聚类对短文本进行扩展[11]。此外, 伴随神经网络的兴起, 循环神经网络、卷积神经网络等也在短文本分类任务上取得显著成果[12]。吴鹏等利用Bi-LSTM模型从海量短文本中判别网民的负面情感, 取得显著效果[13]。王东波等基于Bi-LSTM模型展开先秦典籍问句自动分类研究, 调和平均值达94.78%[14]。王盛玉等基于词注意力卷积神经网络模型展开文本情感分类研究, 较传统机器学习方法准确率提升2%[15]。
2.2 科技文献句子功能识别
在摘要句功能类型识别方面, McKnight等以MedLine论文摘要为数据源, 标注背景介绍、研究方法、实验结果以及研究结论4种功能句标签, 分别在线性分类器和SVM分类器下进行实验, 发现SVM效果更好[21]。华秀丽等以2010年ACL 200篇长文的摘要为研究对象, 将其划分为背景知识、论文主题、研究方法和实验结果4种功能, 提出一种两阶段的细粒度摘要功能句识别方法, 实验结果证明此方法可取得较好的效果[22]。王东波等以情报学领域期刊中的结构化摘要为研究对象, 对比4种分类模型在句子功能识别中的性能, 发现SVM效果优于长短期记忆网络, 而LSTM-CRF和RNN-CRF的效果又优于SVM[23]。
3 基于主动学习的普通摘要句子功能识别流程
传统的基于训练语料所进行的监督学习, 是从标记的训练数据中推断出一个有分类功能的机器学习模型, 其中, 准确找寻类别数据集间的决策边界十分重要。但在标注语料有限和涉及领域泛化的情况下, 决策边界的判别效果有待商榷。鉴于此, 待考虑的解决方案有三类:
图1
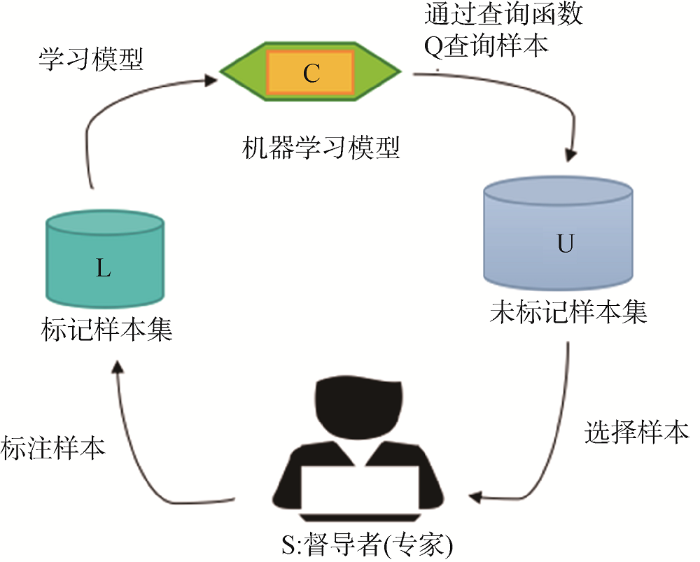
主动学习方案在少量标注语料情况下, 通过筛选源领域中最有价值的样本进行标记, 既可降低人工标注成本, 又可提高已标注语料的领域泛化能力[28]。因此, 本文采用主动学习策略开展实验探索。
结合已有相关研究和主动学习思想, 本文提出基于主动学习的科技论文句子功能识别方法, 以普通摘要语句功能识别为场景, 具体流程如图2所示。
图2
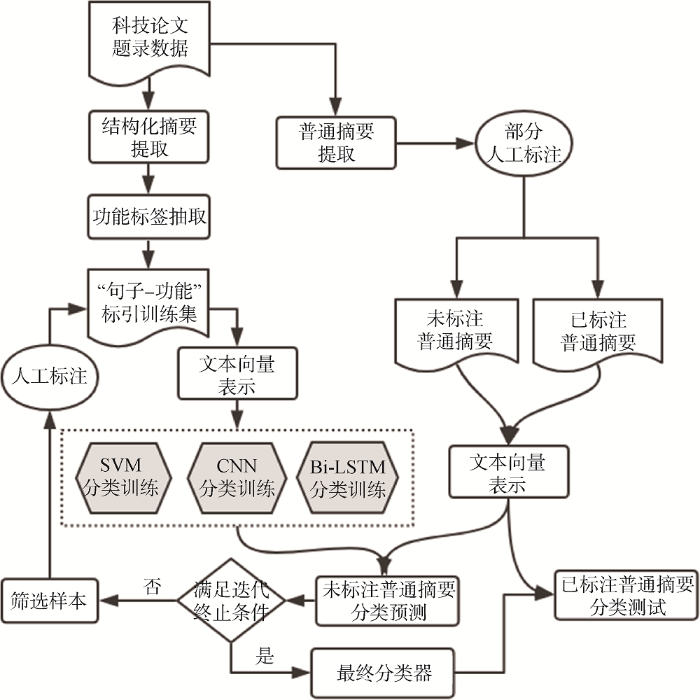
(1) 从科技论文题录数据获取结构化摘要和普通摘要, 随机选择少量普通摘要句子进行人工标注作为最终测试集。剩余大量普通摘要作为未标注语料;
(2) 以结构化摘要为初始训练集训练出初始分类器, 进而对未标注语料进行句子功能类别预测;
(3) 根据主动学习策略筛选出需要人工标注的样本补充到上一次训练集中, 再次进行训练以优化分类器;
(4) 不断迭代步骤(3), 直到满足迭代终止条件得到最终分类器;
(5) 利用测试集评估该分类器在完全普通摘要句子下的分类效果。
鉴于实验中数据处理方法、分类训练各环节的技术方案选择与具体实验场景相关, 涉及到的技术方案细节将在实验部分进行讨论, 以便结合实际效果进行技术方案选择。
4 实 验
选用图书情报领域相关期刊为数据源, 以普通摘要语句功能识别为场景, 进行基于主动学习的科技论文语句功能识别实验。
4.1 数据处理
(1) 数据收集
从图书情报领域CSSCI收录期刊中人工筛选采用结构化摘要的期刊, 包括《图书情报工作》、《情报理论与实践》、《情报杂志》、《情报科学》、《图书馆学研究》、《现代图书情报技术》(2017年更名为《数据分析与知识发现》)及《图书馆论坛》。从上述期刊论文题录中导出结构化摘要作为初始训练语料, 截至2017年11月中旬共2 952条。此外, 从图书情报领域CSSCI收录期刊中获取普通摘要共64 868篇, 随机取800条作为测试语料, 其余64 068条作为未标注语料。
(2) 结构化标签提取及功能句类别确定
结构化摘要中功能标签均以“[]”或“【】”形式标注, 因此利用正则匹配共抽取14种结构化标签, 对应功能归类如表1所示。鉴于“局限”、“应用背景”和“文献范围”三种类型出现次数过少, 本次实验不作考虑。最终, 将待识别的句子功能类型确定为“目的/意义”、“方法/过程”和“结果/结论”三种。
表1 摘要结构化标签抽取与功能归类
| 功能类型 | 结构化摘要标签 | ||||
|---|---|---|---|---|---|
| 目的/意义 | 目的/意义 | 目的 | |||
| 方法/过程 | 方法/过程 | 过程/方法 | 方法/内容 | 方法 | 过程 |
| 结果/结论 | 结论/结果 | 结果/结论 | 结果 | 结论 | |
| 局限 | 局限 | ||||
| 应用背景 | 应用背景 | ||||
| 文献范围 | 文献范围 | ||||
(3) 训练集和测试集的构造依据表1, 可从2 952条结构化摘要中抽取出11 606条已归类句子。按照十折交叉验证方法, 取其中9份为训练集, 1份为验证集。随机选取800条普通摘要分句, 人工对各句标注“目的/意义”、“方法/过程”和“结果/结论”功能标签, 共得到1 451句有类别句子, 作为最终测试集。同时, 按照相同方式对其余64 068条普通摘要进行分句, 共得到81 204条子句, 作为未标注语料。
4.2 技术方案
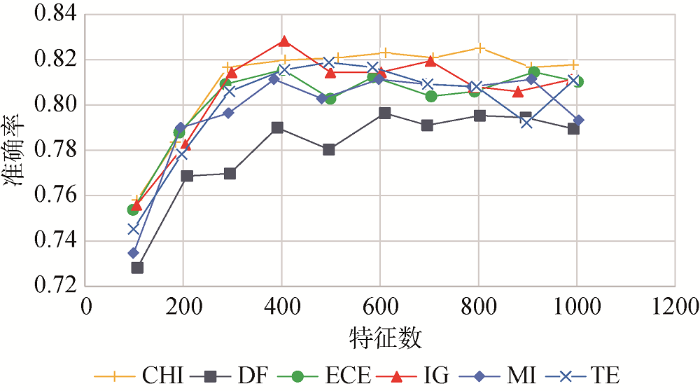
(1) 支持向量机分类方案由于SVM分类仍是传统的机器学习流程, 故需要进行文本预处理、特征权重计算以及特征选择等操作。①文本预处理采用Jieba分词工具进行分词。在去停用词环节, 考虑到与传统短文本分类中基于语义选择特征词不同, 句子功能识别是基于语用的分类, 其特征词更多侧重于类似“首先”、“表明”等非概念性的连词、动词, 这些词在传统文本分类中多作为停用词被去除。因此, 仅在数字、标点基础上人工添加例如“的”、“了”、“是”等对分类无贡献的单字词, 以构成最终停用词表。②特征权重计算句子的向量化采用词袋模型, 为确定词语的加权方案, 笔者对布尔权重、词语频次、TF-IDF方案进行尝试, 发现布尔权重在结构化摘要功能句识别中效果最好, 因此后续实验中以布尔逻辑方案标识词语权重。此外, 有研究指出, 句子位置对判别摘要句功能类别有一定价值[30]。因此, 将句子位置信息作为句子向量化表示的一个重要维度, 计算方式为摘要句的出现位置与所在摘要总句子数的比值。③特征选择方法确定句子功能的特征词选择是后续分类的基础。在实践中, 不仅需要采用有效的特征选择方法, 还要确定合适的特征词数。常用的特征选择方法包括卡方检验(CHI)、文本频度(DF)、期望交叉熵(ECE)、信息增益(IG)、互信息(MI)、特征熵(TE)等[31]。为确定特征选择算法和特征词数, 以“RBF”内核SVM为分类器, 超参数“C”设为1.0, 通过Scikit-learn实现, 在结构化摘要语料上比较这6种主流特征提取算法, 对每种特征选择方法进行10次实验且每次设定不同特征词数量(100-1000之间)。在不考虑句子位置信息时, 各算法在不同特征词数下的分类整体准确率如图3所示, 可知信息增益方法在特征词数为405时分类准确率最高。因此, 后续实验采用信息增益作为特征选择方法, 特征词数为405。最终各类别选择的部分特征词示例如表2所示。
图3
(2) 神经网络分类方案
此阶段以文本中的字为基本单元, 针对大量普通摘要进行词嵌入向量表示学习。通过Python调用Gensim实现Word2Vec算法[32], 选择Skip-gram模型并设定窗口为5, 将摘要句中的字表示为100维的向量。
实验中, 分类模型采用CNN和Bi-LSTM两种, 通过Keras库实现。以词嵌入向量表示的文本观测序列为主输入, 通过Embedding层将其嵌入模型, 然后接入CNN或Bi-LSTM层用于挖掘文本中的深层特征信息, 继而以前文所得句子位置信息为辅助输入, 最终经两层隐藏层输出句子以One-Hot形式表示的功能标签。
(3) 主动学习优化方案
主动学习研究的关键问题是向专家提供标注数据的筛选过程。
由于普通摘要句子功能识别的本质是短文本分类问题, 分类算法通过结构化摘要句训练分类器, 继而对普通摘要测试集进行功能类别判定, 输出结果为句子属于“目的/意义”、“方法/过程”和“结果/结论”类别的概率, 根据概率最大原理判定其类别。因此, 笔者认为其中最大的两种类别概率相差越小, 对于分类器判定功能类别越模糊, 而这正是分类器需要完善之处, 即主动学习中需要引入专家标注的数据。
因此, 待标注数据的筛选过程聚焦于分类器对无标签普通摘要句的预测结果, 如果三个分类器判定某一句的分类概率中最大及次大的差值小于0.05, 则将其作为筛选结果由专家标注其正确的功能类别, 如果不属于以上功能类别则将其过滤。同时, 主动学习每次迭代标注200句功能句, 造成训练集增量式增加, 重新训练分类器并基于测试集检测其泛化能力。迭代上述过程, 直到分类器性能不再提升或满足一定条件停止。实验中, 句子功能识别效果评价指标采用准确率(Precision)、召回率(Recall)以及F1值。
4.3 实验结果及分析
实验分为三组: 实验(1)针对结构化摘要语句进行十折交叉验证, 探究利用结构化摘要是否可抽取出对语句功能识别有重要贡献的特征集, 结合句子位置信息效果; 实验(2)利用基于结构化摘要训练的分类器, 进行普通摘要语句功能识别测试, 探究基于结构化摘要训练的分类器迁移到非规范化撰写的普通摘要语句功能识别的可行性; 实验(3)使用本文基于主动学习的方法对普通摘要语句功能进行识别, 探究加入主动学习优化方案效果提升情况。
(1) 结构化摘要句子功能训练十折交叉验证结果分析
表3 结构化摘要句子功能训练十折交叉验证结果(%)
| 序号 | SVM | CNN | Bi-LSTM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| 1 | 91.66 | 91.12 | 91.39 | 92.75 | 92.45 | 92.60 | 91.93 | 92.07 | 92.00 |
| 2 | 91.80 | 91.62 | 91.71 | 92.56 | 92.51 | 92.53 | 93.01 | 93.20 | 93.10 |
| 3 | 91.21 | 91.12 | 91.16 | 92.73 | 92.60 | 92.66 | 93.12 | 93.07 | 93.09 |
| 4 | 90.96 | 90.77 | 90.86 | 89.50 | 91.41 | 90.44 | 93.68 | 93.48 | 93.58 |
| 5 | 92.39 | 92.21 | 92.29 | 92.54 | 92.52 | 92.53 | 94.35 | 94.19 | 94.27 |
| 6 | 91.19 | 91.05 | 91.11 | 90.30 | 90.36 | 90.32 | 93.35 | 93.38 | 93.36 |
| 7 | 90.10 | 90.62 | 90.35 | 93.23 | 93.18 | 93.20 | 93.81 | 93.97 | 93.89 |
| 8 | 91.87 | 90.68 | 91.27 | 93.41 | 93.21 | 93.31 | 93.23 | 93.52 | 93.37 |
| 9 | 91.39 | 91.36 | 91.37 | 92.11 | 91.12 | 92.11 | 92.23 | 92.13 | 92.18 |
| 10 | 89.88 | 89.91 | 89.89 | 91.01 | 91.11 | 91.06 | 91.68 | 91.48 | 91.58 |
| 均值 | 91.24 | 91.05 | 91.14 | 92.01 | 92.05 | 92.03 | 93.04 | 93.05 | 93.04 |
(注: 在多分类任务上, 最终的宏P、R、F1结果数值相近。后续表4、表5相同。)
(2) 普通摘要功能句识别测试结果分析
利用从结构化摘要语料上训练所得的三个初始分类器, 开展普通摘要功能句识别测试, 结果如表4所示。从总体来看, 三种分类器性能相近, 在三种评价指标上均达81%以上, 因此, 利用结构化摘要训练的分类器迁移到非规范化撰写的普通摘要语句功能识别上具有一定可行性。但远未达到在结构化摘要验证集上91%-93%的效果, 表明初始分类器的应用场景迁移到普通摘要这一新任务上时, 其泛化性能具有一定提升空间。
(3) 基于主动学习的普通摘要功能句识别测试结果分析
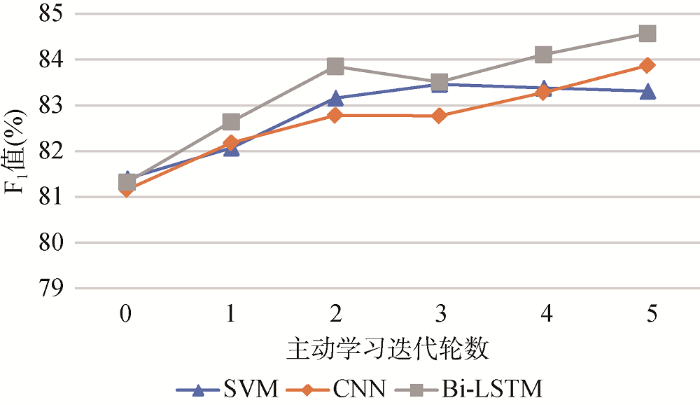
经过5轮迭代, 每轮人工对查询函数给出的200个样本进行标注后, 基于主动学习的普通摘要功能句识别测试结果如表5所示。可知, 三个分类器性能较实验(2)在准确率、召回率和F1值上每轮均有一定程度提升, Bi-LSTM效果最佳, 在准确率、召回率以及F1值上分别提升3.25%、3.24%、3.25%。此外, 各分类器不同迭代次数下的主动学习性能结果如图4所示。可知, 随着主动学习迭代批次的增加, 尽管在中间某次效果趋于稳定甚至略微下降, 但从整体趋势来看, 分类器的性能呈稳步提升。同时, 可观察到, 第一次迭代时折线变化趋势最大, 说明首次使用主动学习时三个分类器的识别效果优化最为明显, 可进一步证明加入主动学习的效用。总之, 本文基于主动学习的方案迁移应用到普通摘要语句功能识别上具有可行性。
表5 基于主动学习的普通摘要功能句识别测试结果(%)
| 迭代轮数 | SVM | CNN | Bi-LSTM | ||||||
|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | |
| 1 | 82.94 | 81.21 | 82.07 | 81.80 | 82.57 | 82.18 | 83.07 | 82.22 | 82.64 |
| 2 | 83.14 | 83.18 | 83.16 | 82.87 | 82.70 | 82.78 | 83.90 | 83.80 | 83.85 |
| 3 | 83.46 | 83.46 | 83.46 | 82.85 | 82.70 | 82.77 | 83.70 | 83.32 | 83.51 |
| 4 | 83.37 | 83.39 | 83.38 | 83.38 | 83.18 | 83.28 | 84.29 | 83.94 | 84.11 |
| 5 | 83.31 | 83.32 | 83.31 | 83.94 | 83.80 | 83.87 | 84.65 | 84.49 | 84.57 |
图4
此外, 鉴于此仅为探究性实验, 目前仅做了5次迭代。尽管总体来讲分类器性能稳步提升, 但可预想随着主动学习迭代次数的增加, 识别效果将趋于稳定甚至略有下降, 原因如下:
(1) 训练语料和测试语料的差异性。本次实验训练语料最初为结构化摘要句子, 测试语料为非规范化撰写的普通摘要句子, 由于语料的天然差异性(例如, 对错分结果进行统计发现, 与结构化摘要不同, 普通摘要由于没有规范化的约束, 文章的目的、方法、结果等不同功能的句子不一定以句号分割, 容易出现多类别句子。), 测试结果达到一定极值将不再提升, 且永远不会优于验证结果;
(2) 数据噪声的累积。迭代初期, 分类器由于学习到主动学习提供的对分类有价值的信息, 性能稳步提升。但迭代中后期, 由于有用的信息已经学习接近完全, 主动学习中逐渐增加的文本噪声将会对分类器性能产生不好的影响, 从而导致分类效果略微下降。因此, 在实际应用中, 主动学习中合理的迭代次数及每次迭代中增量的设置值得后续进一步基于大规模语料展开实验及应用研究。
5 结 语
在面临新任务场景时, 包括深度学习在内的机器学习技术通常严重依赖于人工标注语料。现实中, 一些新的任务往往与已有任务具有部分相似性, 因而在一定程度上可以共享已有的标注语料。主动学习可以发现学习任务中人工标注收益最大的样本, 因此可以用于在共享已有任务中标注语料的前提下, 找出决定新老任务差异的样本提请人工标注。
本文针对科技论文句子功能识别问题, 在充分利用现成结构化摘要语料的基础上, 引入主动学习思想, 以突破文本分类依赖大量人工标注语料的瓶颈问题。以普通摘要语句功能识别为任务场景进行实验, 结果表明, 该方法能够使普通摘要语句功能识别效果得到明显提升, 说明在解决相似任务场景中语料缺失的问题, 主动学习策略具有可行性。因而该方法可迁移应用于其他更多非规范化场景(如引文、全文)的句子功能识别任务。
本文的研究主要侧重于识别摘要中的功能句。实质上, 句子功能识别在科技文献全文本分析中有更广泛的应用。例如, 对引文句的功能识别将有助于判断引用动机并测度引用贡献; 对不同段落中句子功能的识别将有助于定位科技文献研究内容的分布; 对全文中句子功能的识别有助于实现细粒度知识抽取和聚合利用。未来笔者将在这些方面开展进一步研究。
作者贡献声明
陈果: 提出研究思路, 论文修改定稿;
许天祥: 开展实验, 撰写论文。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: delphi1987@qq.com。
[1] 陈果, 许天祥. StructuredAbstract.txt. 结构化摘要数据集.
[2] 陈果, 许天祥. GeneralAbstract.txt. 普通摘要数据集.
参考文献
学术文本的结构功能识别——功能框架及基于章节标题的识别
[J].
The Structure Function of Academic Text and Its Classification
[J].
基于单句粒度的微博主题挖掘研究
[J].
Research of Micro-Blog Topics Mining Based on Sentence Granularity
[J].
如何撰写科技论文英文信息型摘要
[J].
How to Write English Informative Abstract in Paper for Special Science and Technology
[J].
句子级知识抽取在情报学中的应用分析
[J].
An Analysis of the Application of Sentence-Level Knowledge Extraction in Information Science
[J].
引文文本分类与实现方法研究综述
[J].
A Review of Citation Context Classifications and Implementation Methods
[J].
主动学习算法综述
[J].主动学习算法作为构造有效训练集的方法,其目标是通过迭代抽样,寻找有利于提升分类效果的样本,进而减少分类训练集的大小,在有限的时间和资源的前提下,提高分类算法的效率。主动学习已成为模式识别、机器学习和数据挖掘领域的研究热点问题。介绍了主动学习的基本思想,一些最新研究成果及其算法分析,并提出和分析了有待进一步研究的问题。
Survey on Active Learning Algorithms
[J].主动学习算法作为构造有效训练集的方法,其目标是通过迭代抽样,寻找有利于提升分类效果的样本,进而减少分类训练集的大小,在有限的时间和资源的前提下,提高分类算法的效率。主动学习已成为模式识别、机器学习和数据挖掘领域的研究热点问题。介绍了主动学习的基本思想,一些最新研究成果及其算法分析,并提出和分析了有待进一步研究的问题。
利用《知网》和领域关键词集扩展方法的短文本分类研究
[J].
Short-text Classification Based on HowNet and Domain Keyword Set Extension
[J].
Utilizing High-quality Feature Extension Mode to Classify Chinese Short-text
[J].
Language Independent Semantic Kernels for Short-Text Classification
[J].
Short Text Classification Improved by Learning Multi-Granularity Topics
[C]//
Crest: Cluster-based Representation Enrichment for Short Text Classification
[C]//
Recent Trends in Deep Learning Based Natural Language Processing
[J].
基于双向长短期记忆模型的网民负面情感分类研究
[J].
Negative Emotions of Online Users’ Analysis Based on Bidirectional Long Short-Term Memory
[J].
基于深度学习的先秦典籍问句自动分类研究
[J].
Deep Learning-Based Classification of Pre-Qin Classics Questions
[J].
基于词注意力卷积神经网络模型的情感分析研究
[J].
Word Attention-based Convolutional Neural Networks for Sentiment Analysis
[J].
Automatic Classification of Citation Function
[C]//
Ensemble-style Self-training on Citation Classification
[C]//
Summarizing Scientific Articles: Experiments with Relevance and Rhetorical Status
[J].
Coherent Citation-Based Summarization of Scientific Papers
[C]//
基于引文上下文的学术文献摘要方法研究
[D].
Citation-Context Based Academic Literature Summarization Method
[D].
Categorization of Sentence Types in Medical Abstracts
[J].
细粒度科技论文摘要句子分类方法
[J].
DOI:10.3969/j.issn.1000-3428.2012.14.041
Magsci
[本文引用: 1]

以科技论文摘要句子为研究对象,提出一种两阶段的细粒度句子分类方法,通过结合摘要内各个句子的位置、关键词和上下文信息,选择部分易于分辨语境类型的句子,将其作为种子样本训练获得分类模型。利用机器学习的方法对摘要句子的背景知识、论文主题、研究方法和实验结果进行自动分类。实验结果表明,该方法中的F度量值比其他细粒度分类方法平均高3%~5%。
Fine-grained Classification Method for Abstract Sentence of Scientific Paper
[J].
DOI:10.3969/j.issn.1000-3428.2012.14.041
Magsci
[本文引用: 1]
以科技论文摘要句子为研究对象,提出一种两阶段的细粒度句子分类方法,通过结合摘要内各个句子的位置、关键词和上下文信息,选择部分易于分辨语境类型的句子,将其作为种子样本训练获得分类模型。利用机器学习的方法对摘要句子的背景知识、论文主题、研究方法和实验结果进行自动分类。实验结果表明,该方法中的F度量值比其他细粒度分类方法平均高3%~5%。
面向摘要结构功能划分的模型性能比较研究
[J].
A Comparative Study of Model Performances Facing Abstract Structure Function
[J].
An Incremental Self-Trained Ensemble Algorithm
[C]//
理论术语抽取的深度学习模型及自训练算法研究
[J].
A Deep Learning Model and Self-Training Algorithm for Theoretical Terms Extraction
[J].
A Survey on Transfer Learning
[J].
基于迁移学习微博情绪分类研究——以H7N9微博为例
[J].
Microblog Emotion Classification Based on Transfer Learning——A Case Study of Microblogs About H7N9
[J].
Active Learning with Statistical Models
[J].
A Sentence Classification System for Multi Biomedical Literature Summarization
[C]//
文本分类中的特征降维方法综述
[J].
Literature Review of Feature Dimension Reduction in Text Categorization
[J].
Distributed Representations of Words and Phrases and Their Compositionality
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}