




1 引 言
近年, 网络的飞速发展引发了数据量的爆炸式增长。数据中蕴含着无穷的价值, 同时也引发了严重的“信息过载”问题。推荐系统是一种帮助用户快速发现有用信息的工具, 正逐步成为解决信息过载问题的主要发展方向。和搜索引擎不同的是, 推荐系统不需要用户提供明确的需求, 而是通过分析用户的历史行为给用户的兴趣建模, 从而主动向用户推荐能够满足其兴趣和需求的信息。
协同过滤算法是应用最广泛、同时也是发展比较成熟的一种推荐算法。其基本思想是根据用户的浏览记录、购买记录、评分记录或者主页的标注标签等历史信息, 向用户主动推荐信息或预测用户的兴趣偏好, 以实现个性化推荐。电商网站亚马逊的个性化推荐系统有着“推荐系统之王”的美誉, 其核心就是协同过滤算法。然而现有的协同过滤算法只考虑用户或物品之间的相似程度, 忽略了用户的评分是多重因素的结果, 可能是用户习惯于打出高分, 也有可能是用户对质量较好的物品做出的客观评价。现有协同过滤不能体现这些影响因素, 从而导致系统推荐的物品偏离了用户的真实喜好。因此, 如何在海量数据中有效发现用户的兴趣喜好成为推荐系统中一个重要的研究领域。
2 文献回顾
推荐算法是整个推荐系统中最核心和关键的部分, 在很大程度上决定了推荐系统性能的优劣。传统的推荐方法主要包括基于协同过滤的推荐方法、基于内容的推荐方法和混合推荐方法。其中协同过滤以其模型通用性强、不需要太多对应数据领域的专业知识、算法实现简单、推荐效果理想等优点成为工业界应用最为广泛的推荐算法[1]。
然而, 现实应用环境中, 用户评分数据极其稀疏, 用户间的共同评分数量极少, 这种方法得到的用户间相似性的可靠性和准确性都难以保证。此外, 用户对物品的评分是多重因素的结果。用户可能并不是真正感兴趣, 只是对质量好的物品做出客观评价。用户打分还有可能受到当前推荐系统的影响[6]。
针对上述问题, 研究人员提出多种改进方法优化近邻的选择以提高推荐准确度。具体到方法而言, 主要分为以下几类:
上述文献虽然从不同角度提升了推荐的准确度, 但仍存在某些问题。首先, 在计算用户间相似性时没有考虑目标用户的影响, 认为每个共同项目的评分有相同的贡献度, 且不随目标项目而动态变化, 导致针对不同项目计算出目标与其他用户间的相似性结果保持不变。其次, 忽略了邻居用户对目标用户的推荐贡献能力, 导致近邻集合中与目标用户相似性较高但对其推荐能力较差的伪近邻比例增高, 导致推荐质量下降[14]。
用户对一个物品的评分是多种因素的结果, 并不一定代表用户对物品真正感兴趣, 很有可能是对质量较高的物品做出的客观评价, 亦或是用户习惯了给出高分, 只有遇到质量较差的物品才给出低分。现有文献中, 鲜有从这个角度入手。有学者利用物品质量和用户评分偏好计算用户评分趋势和电影流行度趋势, 并利用决策函数预测用户评分[15]。该算法改进了协同过滤中存在的扩展问题, 然而却简单地用平均分作为物品质量的评分依据。此外, 评分预测被简单地视作趋势的走向, 导致推荐精度下降。
针对上述问题, 本文在已有研究基础上利用物品的质量对已有评分矩阵进行修正, 改进了查找与目标用户兴趣相似的最近邻集合的准确度。
3 物品质量分析
3.1 HITS算法
在HITS算法[19]中, 每个网络节点被赋予两个属性: Hub属性和Authority属性。同时, 网络节点被分为两种: Hub节点和Authority节点。Hub是中心的意思, 所以Hub节点指那些包含很多指向Authority节点链接的节点, 比如国内的一些门户网站; Authority节点则指那些包含有实质性内容的节点。HITS算法的目的是当用户查询时, 返回给用户高质量的Authority节点。
利用用户和电影构建二部图结构, 其中的链接关系如图1所示。使用HITS算法进行迭代计算, 在权值稳定后迭代完成, 算法返回已经按权值排好序的Authority集, 即用户所观看的电影项目集合, 因为这些电影代表了能够满足用户观看情况的高质量电影集合。
图1
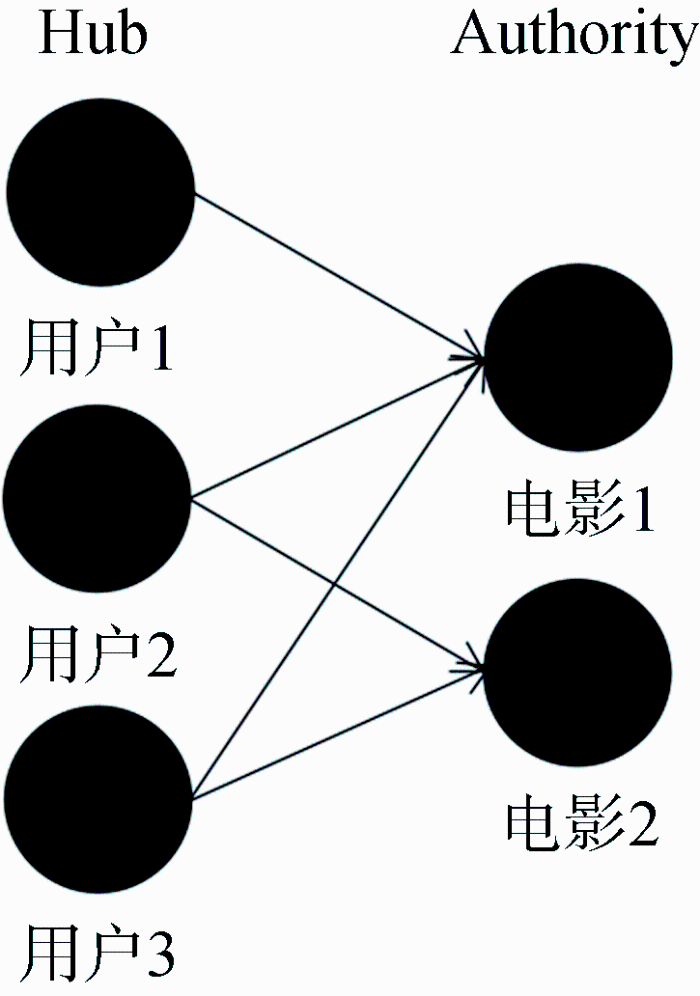
使用HITS算法作为物品质量分析方法存在一些问题:
(1) 由于要进行大量迭代计算, 导致算法性能极其低下;
(2) HITS从机制上很容易被作弊者操纵;
(3) 新的物品由于评分较少, 迭代计算后其权值很小, 对新事物不太友好。
3.2 基于贝叶斯估计的物品质量评估
考虑如下两种情况: 电影A: 1条评分, 平均分5分; 电影B: 50条评分, 平均分为4.5分。直观上人们认为电影B的质量要优于电影A的质量, 这里需要去测度这两个电影的质量。
思路一: 设定阈值K, 利用评分数量高于K的部分计算平均分以评估电影的质量, 低于K的则暂时丢弃。然而这种方法存在以下问题: 如何去选定阈值K; 如果只有一个评分数大于K, 并且它的评分很低, 此时可能得出与事实相左的结论。
思路二: 基于贝叶斯估计的物品质量评估。贝叶斯估计既考虑到没有足够的数据通过均值进行估计, 又包含了其他观测值的所有数据。贝叶斯估计允许不直接计算有限数量的估计值, 而是计算出已知值的概率分布, 然后利用这个概率分布获取估计值。这个方法也是当前IMDB[20]用来计算其Top250电影的方法, 如公式(1)所示。
其中, R表示电影的平均分, V表示电影的观看频次, M表示要进入榜单的最少观看频次, X表示整个榜单的平均观看次数。对公式(1)稍作改动, 得到公式(2)。
其中, m代表评分值的先验, C代表对先验的置信度, N表示电影观看的频次。
设定m=3、C=5, 则电影A和电影B的评分分别是: ${{r}_{A}}=\frac{5\times 3+5\times 1}{5+1}=3.3$; ${{r}_{B}}=\frac{5\times 3+4.5\times 50}{5+50}=4.36$
可见电影B的质量比电影A的质量好, 符合最初的设想。
4 用户评分修正
考虑以下两种情况: 用户A对电影的评分是3、3、5, 用户B对相同电影的评分为5、5、5, 用户A和用户B对同一部电影的5分代表的意义不同。用户A对电影的5分可能代表他非常喜欢这部电影, 而用户B可能只是习惯于打高分。并且对一部高质量的电影, 用户也很少会打出低评分, 这会影响发掘用户的兴趣特征, 因此需要对现有评分矩阵进行修正, 利用修正后的评分反应用户对电影真实的兴趣。
用户对一部电影的评分是多重因素下的结果, 可以通过从用户原来的评分中剔除电影质量的贡献度, 得到用户对电影的兴趣度。定义公式修正用户对电影的评分, 称为兴趣度, 如公式(3)所示。
兴趣度表示用户的评分和电影质量之间的差值, 可以为正值或负值。正值表明用户倾向于评分高于电影质量, 表明用户对电影感兴趣的程度。基于物品质量和用户评分修正的协同过滤算法如下所示。
算法1 基于物品质量和用户评分修正的协同过滤算法
输入: 完整的训练集用户评分矩阵
输出: 测试集用户的预测评分
过程:
①利用公式(2)计算训练集中每部电影i的电影质量;
②利用公式(3)计算训练集中每个用户u的评分兴趣度并输出兴趣度矩阵;
③将兴趣度矩阵计算皮尔逊系数并得到候选用户u的Top-N近邻;
④利用基于用户的协同过滤计算目标用户的预测评分。
5 实验说明
本文采用的数据集是明尼苏达大学GroupLens小组发布的最新MovieLens Latest数据集, 包含270 000个用户对45 000部电影的26 000 000条评分记录, 评分范围为1-5, 在数据集中随机划分80%作为训练集、20%作为测试集。
5.1 电影质量
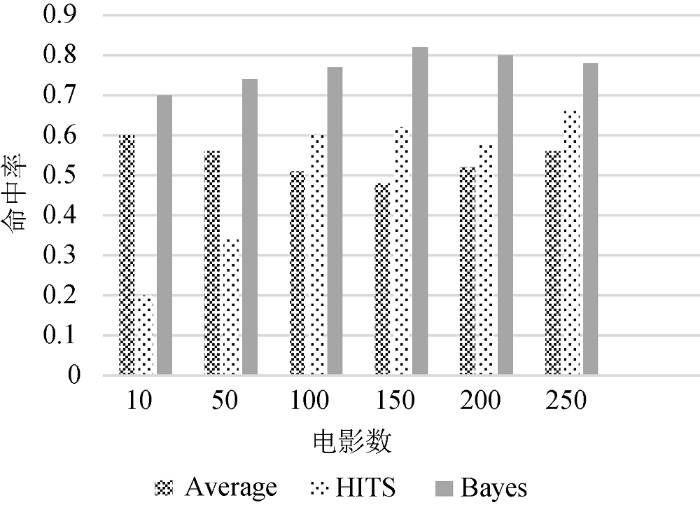
对数据集分别使用平均分、HITS算法、贝叶斯估计方法得到排名前10的电影与从IMDB官网获取的Top250进行对比, 如表1所示。
表1 Item质量实验对比
| Average | HITS | Bayes | IMDB |
|---|---|---|---|
| Planet Earth | Forrest Gump | The Shawshank Redemption | The Shawshank Redemption |
| The Shawshank Redemption | Pulp Fiction | The Godfather | The Godfather |
| The Usual Suspects | The Matrix | The Usual Suspects | The Godfather: Part II |
| Schindler’s List | The Shawshank Redemption | The Godfather: Part II | The Dark Knight |
| The Godfather: Part II | The Silence of the Lambs | Schindler’s List | 12 Angry Men |
| 12 Angry Men | Jurassic Park | Seven Samurai | Schindler’s List |
| Fight Club | Star Wars: Episode IV | Fight Club | The Lord of the Rings: The Return of the King |
| Pulp Fiction | Star Wars: Episode V | 12 Angry Men | Pulp Fiction |
| Planet Earth | Terminator 2: Judgment Day | Spirited Away | Il buono, il brutto, il cattivo |
| Human Planet | Braveheart | Pulp Fiction | Fight Club |
以IMDB Top250电影作为基准, 定义命中率为电影数量在IMDB Top250中的比率, 如公式(4)所示。
图2
5.2 针对评分修正的实验结果
图3
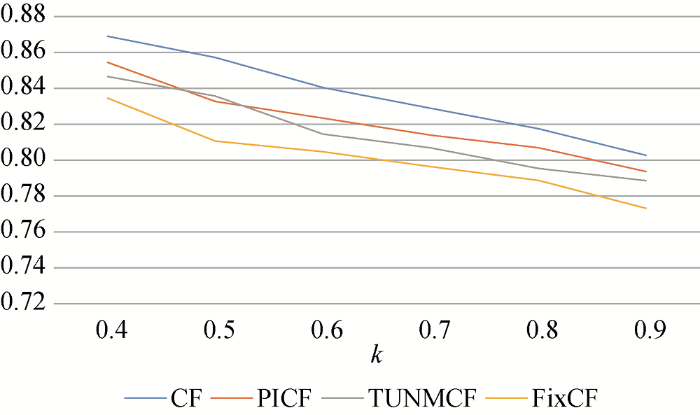
从图3可以看出, 随着用户间相似度k的增大, 无论是传统的协同过滤方法还是改进后的协同过滤方法, MAE值都在变小, 推荐精度都在提升。而本文算法FixCF相较之下有更好的精度, 这表明用户评分修正的方法确实可以进一步提高推荐质量。
6 结 语
本文在总结用户评分受物品质量和用户倾向性影响的基础上, 提出基于物品质量和用户评分修正的协同过滤推荐算法以提高推荐质量, 初步实现了预期的设计目标。该方法还存在需要进一步研究和改进之处, 主要有以下几点:
(1) 用户的评分偏好信息需要改进, 因为用户的评分偏好信息对推荐评分的预测有重大影响;
(2) 用户的兴趣度算法改进, 可以增加影响因子来修正物品质量对用户评分影响的大小;
(3) 用户的兴趣会随着时间而变化, 将时间信息纳入到计算之中。
作者贡献声明
焦富森, 李树青: 提出研究思路, 采集分析数据, 起草及修改 论文;
焦富森: 进行实验。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: jiaorocks@gmail.com。
[1] 焦富森. ml-latest. ratings.csv. 实验数据集.
参考文献
互联网推荐系统比较研究
[J].
Comparison Study of Internet Recommendation System
[J].
基于项目评分预测的协同过滤推荐算法
[J].
A Collaborative Filtering Recommendation Algorithm Based on Item Rating Prediction
[J].
Amazon.com Recommendations: Item-to-Item Collaborative Filtering
[J].
协同过滤推荐算法综述
[J].
Survey of Collaborative Filtering Algorithms
[J].
An Entropy-Based Neighbor Selection Approach for Collaborative Filtering
[J].
Is Seeing Believing?: How Recommender System Interfaces Affect Users’ Opinions
[C]//
基于评分矩阵填充与用户兴趣的协同过滤推荐算法
[J].
DOI:10.3969/j.issn.1000-3428.2016.01.007
Magsci
[本文引用: 2]

针对传统协同过滤推荐算法评分矩阵稀疏和推荐精度不高的问题,提出一种改进的协同过滤推荐算法。通过用户属性偏好和项目流行度计算用户对项目的偏好度,结合用户平均评分对评分矩阵中未评分项目进行填充。考虑到用户兴趣随时间的变化,将基于时间的兴趣度权重函数和偏好度引入到项目相似度计算和推荐过程中,确定项目最近邻集合,从而实现最优推荐。实验结果表明,与传统协同过滤推荐算法相比,该算法较准确地反映了用户的兴趣变化趋势,并且在有效解决评分矩阵稀疏问题的同时提高了推荐准确率。
Collaborative Filtering Recommendation Algorithm Based on Score Matrix Filling and User Interest
[J].
DOI:10.3969/j.issn.1000-3428.2016.01.007
Magsci
[本文引用: 2]
针对传统协同过滤推荐算法评分矩阵稀疏和推荐精度不高的问题,提出一种改进的协同过滤推荐算法。通过用户属性偏好和项目流行度计算用户对项目的偏好度,结合用户平均评分对评分矩阵中未评分项目进行填充。考虑到用户兴趣随时间的变化,将基于时间的兴趣度权重函数和偏好度引入到项目相似度计算和推荐过程中,确定项目最近邻集合,从而实现最优推荐。实验结果表明,与传统协同过滤推荐算法相比,该算法较准确地反映了用户的兴趣变化趋势,并且在有效解决评分矩阵稀疏问题的同时提高了推荐准确率。
基于评分矩阵预填充的协同过滤算法
[J].
DOI:10.3969/j.issn.1000-3428.2013.01.037
Magsci
[本文引用: 1]
随着用户和项目数量的增长,用户-项目评分矩阵变得极其稀疏,导致基于相似度计算的推荐算法精度降低。为此,提出一种基于加权Jaccard系数的综合项目相似度度量方法,使用项目综合相似度对评分矩阵进行预填充。实验结果表明,在用户-项目评分矩阵极其稀疏的情况下,该算法能产生比传统算法更精确的推荐结果。
Collaborative Filtering Algorithm Based on Rating Matrix Pre-filling
[J].
DOI:10.3969/j.issn.1000-3428.2013.01.037
Magsci
[本文引用: 1]
随着用户和项目数量的增长,用户-项目评分矩阵变得极其稀疏,导致基于相似度计算的推荐算法精度降低。为此,提出一种基于加权Jaccard系数的综合项目相似度度量方法,使用项目综合相似度对评分矩阵进行预填充。实验结果表明,在用户-项目评分矩阵极其稀疏的情况下,该算法能产生比传统算法更精确的推荐结果。
基于离散量和用户兴趣贴近度的协同过滤推荐算法
[J].针对传统协同过滤算法在计算用户相似度过程中,由于数据稀疏性导致的无法计算、失真、虚高等问题,提出一种融合离散量和兴趣贴近度的相似度度量方法。收集用户对项目的评分数据,从全信息量角度进行分析,通过引入离散量相关理论进行用户评分向量间的相似度计算,对评分相似的用户进行初步筛选,利用用户兴趣贴近度对相似度结果进行进一步加权处理,得到融合用户兴趣偏好信息的相似度结果,以此为基础,采用协同过滤算法进行个性化推荐。实验结果表明,该算法可有效提高信息推荐系统的推荐质量,在数据极端稀疏的情况下也能保持较好的性能。
Collaborative Filtering Recommendation Algorithm Based on Discrete Quantity and User Interests Approach Degree
[J].针对传统协同过滤算法在计算用户相似度过程中,由于数据稀疏性导致的无法计算、失真、虚高等问题,提出一种融合离散量和兴趣贴近度的相似度度量方法。收集用户对项目的评分数据,从全信息量角度进行分析,通过引入离散量相关理论进行用户评分向量间的相似度计算,对评分相似的用户进行初步筛选,利用用户兴趣贴近度对相似度结果进行进一步加权处理,得到融合用户兴趣偏好信息的相似度结果,以此为基础,采用协同过滤算法进行个性化推荐。实验结果表明,该算法可有效提高信息推荐系统的推荐质量,在数据极端稀疏的情况下也能保持较好的性能。
基于目标用户近邻修正的协同过滤算法
[J].
DOI:10.16451/j.cnki.issn1003-6059.201509005
Magsci
[本文引用: 2]
在基于用户的协同过滤算法中,用户评分倾向性和评分矩阵的稀疏性致使难以准确可靠地搜寻目标用户的近邻.基于此,文中提出基于目标用户近邻修正的协同过滤算法.首先定义积极评分和消极评分两类用户群体,选择从目标用户评分倾向性一致的用户群体中寻找其近邻.然后对与目标用户共同评分项数量少而相似度可能高的近邻进行修正,为目标用户寻找更准确的近邻集合.实验表明,文中算法在一定程度上能有效提高推荐质量.
Target User’s Neighbors Modification Based Collaborative Filtering
[J].
DOI:10.16451/j.cnki.issn1003-6059.201509005
Magsci
[本文引用: 2]
在基于用户的协同过滤算法中,用户评分倾向性和评分矩阵的稀疏性致使难以准确可靠地搜寻目标用户的近邻.基于此,文中提出基于目标用户近邻修正的协同过滤算法.首先定义积极评分和消极评分两类用户群体,选择从目标用户评分倾向性一致的用户群体中寻找其近邻.然后对与目标用户共同评分项数量少而相似度可能高的近邻进行修正,为目标用户寻找更准确的近邻集合.实验表明,文中算法在一定程度上能有效提高推荐质量.
Utilizing Various Sparsity Measures for Enhancing Accuracy of Collaborative Recommender Systems Based on Local and Global Similarities
[J].
An Effective Threshold-Based Neighbor Selection in Collaborative Filtering
[C]//
基于双重邻居选取策略的协同过滤推荐算法
[J].协同过滤是电子商务推荐系统中应用最成功的推荐技术之一,但是传统的协同过滤推荐算法存在推荐精度低和抗攻击能力差的缺陷.针对这些问题,提出了一种基于双重邻居选取策略的协同过滤推荐算法.首先基于用户相似度计算的结果,动态选取目标用户的兴趣相似用户集.然后提出了一种用户信任计算模型,根据用户的评分信息,计算得到目标用户对兴趣相似用户的信任度,并以此作为选取可信邻居用户的依据.最后,利用双重邻居选取策略,完成对目标用户的推荐.实验结果表明该算法不仅提高了系统推荐精度,而且具有较强的抗攻击能力.
A Collaborative Filtering Recommendation Algorithm Based on Double Neighbor Choosing Strategy
[J].协同过滤是电子商务推荐系统中应用最成功的推荐技术之一,但是传统的协同过滤推荐算法存在推荐精度低和抗攻击能力差的缺陷.针对这些问题,提出了一种基于双重邻居选取策略的协同过滤推荐算法.首先基于用户相似度计算的结果,动态选取目标用户的兴趣相似用户集.然后提出了一种用户信任计算模型,根据用户的评分信息,计算得到目标用户对兴趣相似用户的信任度,并以此作为选取可信邻居用户的依据.最后,利用双重邻居选取策略,完成对目标用户的推荐.实验结果表明该算法不仅提高了系统推荐精度,而且具有较强的抗攻击能力.
基于熵优化近邻选择的协同过滤推荐算法
[J].
Collaborative Filtering Recommendation Algorithm Based on Entropy Optimization Nearest-neighbor Selection
[J].
Recommendation Algorithm Based on Item Quality and User Rating Preferences
[J].
The PageRank Citation Ranking: Bringing Order to the Web[R]
Using Bayesian Networks to Infer Product Rankings from User Needs
[C]//
基于用户偏好与商品属性情感匹配的图书个性化推荐研究
[J].
Personalized Book Recommendation Based on User Preferences and Commodity Features
[J].
Authoritative Sources in a Hyperlinked Environment
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}