




1 引 言
随着互联网的快速发展, 网络文本信息呈爆炸式增长, 关键词作为文档内容信息表征的最小单元, 能够简明地表述文档内容的主旨信息, 成为人们快速掌握文档内容的主要工具。关键词最早应用于新闻报道、文献检索等领域, 以便人们高效检索和管理文档。传统的论文库和新闻库中的关键词一般由专家对文档进行标注产生; 面对高速发展的网络文本, 人工标注如此海量的信息已经变得不现实。社会迫切需要通过计算机实现文本关键词自动标注, 关键词自动抽取技术逐渐成为自然语言处理和信息检索的热点研究问题。目前, 关键词自动抽取技术广泛应用于搜索引擎、新闻服务等领域, 是实现信息检索、文本摘要生成、文本分类、文本聚类以及推荐系统等任务的基础。
关键词自动抽取主要包括三个步骤:
(1) 文本预处理, 对文本进行分词、词性标注和去停用词等;
(2) 候选关键词的选择, 经统计[1], 关键词一般为名词、动词及形容词, 针对英文语料一般选择形容词和名词或名词形容词词组作为候选关键词, 而对于中文语料多数选择名词和动词作为候选关键词, 其他无实质性意义的词语几乎不作为关键词;
(3) 确定关键词, 使用算法对候选关键词进行权重计算, 按照权重大小排序, 最终选择TopN的候选关键词作为文档关键词。
候选关键词的选取一般按照词性进行判断, 较为简单, 而从候选关键词中确定关键词成为关键步骤。关键词自动抽取有多种方法, 其中, TextRank算法[2]应用较为广泛, 抽取效果较好。
以TextRank为代表的图方法只考虑文档词与词之间的语义信息, 图中节点的重要性以均匀的方式进行传递, 未考虑文档的主题信息; 因此, 以TextRank为代表的图方法在进行关键词提取时会出现主题覆盖性偏差的问题, 导致多数关键词可能集中在一个大主题下, 而未涉及其他主题。基于以上问题, 本文在TextRank图模型的基础之上, 使用LDA(Latent Dirichlet Allocation)[3]对文本集建模, 引入文档的隐含主题信息, 利用多文档的主题分布和词分布, 计算词语在主题上的区分度作为节点在图中的权重, 将原始图中词语的重要性权重转换为非均匀传递; 同时, 考虑每个词语在不同主题下的重要性可能不同, 计算每个词语在不同主题下的重要性, 并将其设置为词语在图中的随机跳转概率, 改变原始节点等概率的情况。最后对重新构建的转移矩阵进行词图迭代, 对节点进行排序, 选取TopN个关键词作为文档关键词, 实现较好的关键词抽取效果。
2 相关工作
根据是否需要标注语料, 关键词抽取一般可以分为有监督的关键词抽取和无监督的关键词抽取。赵京胜等[1]探讨关键词抽取的内涵和理论基础, 并对这两类关键词抽取技术和研究现状做了较为全面的总结, 同时预测了关键词抽取所面临的问题和研究趋势。在有监督关键词抽取方面, Turney[4]设计了结合专业领域知识的GenEx分类算法, 将词性信息作为特征, 关键词抽取效果优于传统的决策树分类算法, 并且该类算法可以推广至多个领域。Frank等[5]基于朴素贝叶斯方法实现了关键词自动抽取系统KEA, 实验表明, 当使用该系统结合特定领域的信息时, 提取的关键词质量显著提高。有监督的关键词抽取虽然已经在某些领域取得较好的成果, 但应用范围具有局限性并且需要大量人工标注语料库, 而面对互联网产生的大量网页新闻、微博语料, 对文本语料进行人工标注往往成本较高, 耗时耗力。因此无监督关键词抽取方法成为近年关键词抽取的研究热点。无监督关键词抽取的方法可以归为三类: 基于统计方法的关键词抽取、基于主题的关键词抽取及基于图模型的关键词抽取。
(1) 基于统计方法的关键词抽取, 以TF-IDF及其改进方法为代表的统计方法应用较为广泛。钱爱兵等[6]结合新闻网页的特征, 考虑候选关键词的位置、词长以及词性信息, 对TF-IDF进行综合加权, 最终形成新的关键词顺序。杨凯艳[7]发现在计算IDF时高度依赖词语频数, 而忽略其在文本集上的分布情况, 提出结合信息增益和离散度量化词语在文本集上的分布; 将多类词语统计特征进行融合代替原始的词频TF特征, 改善原始类内信息不足的问题。基于统计方法的关键词抽取优点在于简单快速, 结果较符合实际情况, 但传统的TF-IDF算法以词频为主要特征衡量词语重要性, 不够全面, 无法反映词汇的语义信息, 不能覆盖文档的各个主题信息。
(2) 基于主题的关键词抽取, 利用主题模型对文档关键词进行抽取, 文档中词语的主题特征越明显, 其代表的主题表征力越强。利用主题特征抽取文档关键词, 一般有两种方法: 假设一个词语只能代表一个主题, 选取每个主题下概率最高的TopN个词作为该主题的关键词; 假设能够代表主题的词语一般主题区分度较大, 在某个主题下权重较高, 在其他主题下出现的频率较低, 每个词代表其最能代表的一个主题。朱德泽等[8]提出一种基于文档隐含主题的关键词抽取算法TFITF, 根据主题模型计算词汇对主题的TFITF权重, 进而产生词汇对文档的权重, 利用共现信息进行排序, 最后使用主题相似性排除相似关键词组。丁卓冶[9]假设微博的词语分为背景词和主题词, 设计针对此类短文本的面向主题的翻译模型, 其关键词提取效果优于一些经典关键词提取方法。基于主题的关键词抽取方法, 使用大规模文档集学习文本的隐含主题, 所得关键词能够涵盖文本的主要主题, 但忽略了单文本词与词之间的结构信息。
(3) TextRank算法将传统的网页排序算法PageRank应用于文本领域, 将文本中不同粒度的文字单元作为网络图中的节点, 利用滑动窗口机制, 将单元之间的共现关系作为图模型的边, 通过随机游走进行迭代计算节点权重。由于其效果优于传统的TF-IDF, 并且复杂度低, 所以被广泛应用。考虑到原始TextRank算法将节点权重设置均匀传递, 而在关键词抽取时, 每个词语在文本中出现的位置和频次不同, 其所能表征的文本内涵也就不同。夏天[10]将词语的位置信息和频度信息引入TextRank算法中, 构建新的非均匀转移矩阵, 提取关键词的效果优于原始TextRank算法。单文本进行关键词抽取信息受限, 文献[11]考虑融入外部语义信息, 将维基百科以词向量的形式进行聚类, 并认为词语到簇心的距离越远越能反映区别于质心的其他语义信息。除此之外, Bougouin等[12]在构建网络图时将相似词聚集成簇, 将簇作为网络图中的节点, 构建全连通网络, 对簇进行排序, 得到权重较高的簇, 实验验证选择簇中最先在文本中出现的词作为关键词效果最好。
由于单一的方法不能同时综合文本的统计特征和语义信息, 很多学者考虑到方法融合。顾益军等[13]将单一文档的结构信息和文档主题信息进行融合, 在转移矩阵中加入主题影响力, 但仍保持PageRank均匀随机跳转假设, 较理想化。刘啸剑等[14]通过主题模型计算词与词及词与文档之间的相关性, 将两类相关性作为图模型中边的权重和跳转概率, 并将短语作为图中的节点, 最后结合词语的长度信息和位置信息得到每个节点的权重。而Liu等[15]提出TopicalPageRank, 将原始的PageRank分解成在不同主题上带有偏好的PageRank, 改变了原始随机游走策略。该方法对每个主题进行词语权重计算, 计算复杂度较高。与上述结合方式不同, 本文综合两方面因素: 一方面将词语在主题层次的主题相关性作为词语的非均匀跳转概率; 另一方面还考虑图中词语在随机跳转时的偏好问题, 加权文档主题分布和主题词分布作为词语在文档中的重要度, 设为图模型中节点的随机跳转概率, 充分利用文本的主题信息以及词语的共现关系。
3 构建基于文档主题结构和词图迭代的关键词抽取方法
基于文本主题词分布的TextRank关键词抽取方法是一个无监督算法, 不需要预先标注大量语料, 将文档预处理后筛选出的名词和动词作为节点, 通过滑动窗口构建共现词图, 通过LDA主题模型得到主题-词分布, 利用主题-词分布计算出词语在主题上的分布, 进而得到节点的权重, 根据文档的主题分布以及主题上的词分布加权求出每个词在文档主要主题下的分布概率作为图模型的跳转概率, 进而改变随机游走的特点。
3.1 节点权重和随机跳转概率计算
图1
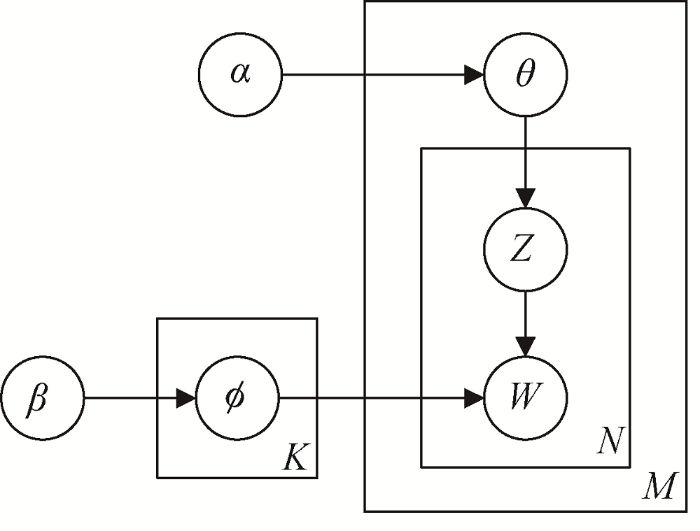
LDA中, 文档-主题概率和主题-词概率均服从狄利克雷分布, 文档中的词语无序, 该模型为标准的词袋模型。假设文档集中包含M个文档, 总词汇量为V, 隐含主题数为K, 要生成一篇由n个词组成的文档, 首先从文档-主题分布${{\theta }_{m}}\tilde{\ }Dir(\alpha )$中抽取一个主题, 其中$m=\left\{ 1,2,\cdots ,M \right\}$, $\alpha $为$\theta$的超参数; 然后从该主题对应的词分布${{\phi }_{k}}\tilde{\ }Dir(\beta )$中抽取一个词, 其中$k=\left\{ 1,2,\cdots ,K \right\}$, $\beta $为$\phi $的超参数。重复此过程n次, 即可得到含有n个词的文档。
LDA的概率模型如公式(1)所示。
通过LDA, 可以得到文档在主题上的概率分布以及主题在词语上的概率分布, 如公式(2)和公式(3)所示。
其中, ${{n}_{m,k}}$表示文档m中的词语被赋给主题k的次数, ${{n}_{w,k}}$表示词w被赋给主题k的次数; $K$和$V$分别代表主题数量和总词汇量; $\alpha $和$\beta $分别为文档-主题分布和主题-词分布的超参数。根据公式(2)和公式(3), 可以得到词语的权重和词语在文档主题下的分布概率, 在计算词语权重时, 将原始主题-词矩阵转化为词语在主题上的分布向量${{W}_{c}}=[{{W}_{c,1}},{{W}_{c,2}},\ldots ,{{W}_{c,i}},\ldots ,{{W}_{c,k}}]$, ${{W}_{c,i}}$代表词语$c$在主题$i$上的概率分布, 其公式如公式(4)所示。本文认为词语在主题上的分布越均匀, 则这个词语是宽泛词的概率越大, 这类词语通常没有实质性意义, 不能够作为区分文档内容的关键词, 故将向量${{W}_{uniform}}=[1/K,1/K,\ldots ,1/K]$设为噪音向量。使用KL距离公式计算词$c$的主题分布向量${{W}_{c}}$到噪音向量${{W}_{uniform}}$的距离作为节点权重, KL距离如公式(5)所示; 距离越大说明该词语在主题上分布越不均匀, 则该词语在某个主题上具有代表性。
另外, 本文将一篇文章看作若干主题的混合分布, 一个词语若在此文档中出现概率较高的一个或者几个主题中出现的概率也比较高, 认为该词语对于此文档比较重要, 成为关键词的几率也较大。该词语在文档中重要主题下的概率分布如公式(6)所示, 将主题分布概率和对应主题下的词语概率分布进行加权求和, 作为TextRank图模型中的随机跳转概率。原始TextRank的随机跳转概率假设每个词语以等概率$\frac{1}{\left| V \right|}$随机跳转到其他节点, 没有任何偏好。而实际上, 该部分也能够设为非均匀分布, 假设某些节点这部分概率较大, 最终TextRank值将更加偏向于这些节点。
3.2 基于文档主题结构的TextRank图模型构建
TextRank的基本思想是, 一个节点的重要性取决于链入节点的数量和质量, 链入节点数量越多, 链入节点权重越高, 此节点的权重也就越高。一篇文档可以根据词语之间的共现关系构建一个词图, 文档中的词语作为词图中的节点, 词语之间的邻接关系作为词图的边, 词图可以为有向图也可以是无向图。节点的得分为$G=(V,E)$, V表示节点集, E表示边集; TextRank词图计算公式如公式(7)所示。$in({{v}_{i}})$表示${{v}_{i}}$的入度, 即指向该节点的集合, $out({{v}_{i}})$表示${{v}_{i}}$的出度, $\lambda $为阻尼系数, 代表节点有$1-\lambda $的概率随机跳转到其他节点, 一般设为0.85。
与原始算法不同, 本文将原始节点之间的均匀传递转换为根据词语的主题分布距离计算的非均匀传递, 此步骤按照词语的泛化性对词语进行重要性标注, 从而过滤宽泛词, 提升关键词在文档中的排序; 节点在图中的随机跳转概率被转换为词语通过主题隐含层在文档中表现的重要性, 将词语隐含的主题信息加入到词语的跳转概率中, 以提高主题的覆盖率, 将词语在不同主题中的重要性进行区分, 最终加权测量词语的主题影响力。文献[1]指出词图是否有向对关键词抽取结果影响不大, 本文采用有向图: 在窗口滑动过程中, 由第一个词分别依次指向后面的词语, 直至滑动窗口滑至文档结束。最终TextRank词图的计算公式如公式(8)所示。
其中, $P({{v}_{i}})$为公式(6)所述的主题影响力权重, 即词语在文档中重要主题下的概率分布。$D({{v}_{i}})$代表节点${{v}_{i}}$的权重即其到噪音向量的距离。根据公式(8)进行词图迭代, 计算出每个候选词语的得分, 最终选取得分TopN的候选词语作为文档关键词。
4 实 验
4.1 实验数据来源及预处理
由于目前缺少权威的面向中文关键词抽取的公开数据集, 为保证测试数据的真实性和实验结果的可重复性, 本文对文献[11]提供的Python爬虫代码进行改进后, 定向爬取南方周末网站的1 683篇新闻文章作为实验语料, 文章内容包括体育、娱乐、政治、社会等主题。经人工排查, 去除过短无效文章、重复文章以及个别抓取格式有误的文章, 最终用于实验的文章数是1 559篇。抓取内容包括文章标题、正文以及网页明确标记的关键词标签, 并将该标签作为文章对应的标准关键词, 方便实验结果对比。该数据集中平均每篇文档大概包含2 400-2 700个字符, 3-5个关键词。
获取原始语料后, 需要对语料进行预处理。
(1) 针对文本中的“(某某记者)”, “(如图X所示)”和“网页链接”等大量出现但无法反映语义信息的文本, 使用正则表达式将其去除。
(2) 对文档集进行分词, 使用NLPIR-ICTCLAS 2016分词系统。
至此, 处理后的数据将作为LDA模型的输入语料。在词图构建使用滑动窗口对候选关键词进行共现展示时, 候选词的选取往往有两种方式, 一种是过滤文档中的停用词等没有实质意义的词语; 另一种则是考虑文档中的每一个词, 不做任何词性的过滤。这里选择第一种方式, 虽然停用词的存在可以提供距离信息, 更好地判断两个词语之间的共现性, 但是这类词语不具备关键词的特性也无需计算相似度, 距离的影响较小, 可以忽略。所以, 结合中文语料特性, 仅选取可能为关键词词性的词语作为候选关键词, 最终使用文档中非单个字符的名词和动词作为候选关键词。
4.2 模型评价指标
使用准确率(Precision, P)、召回率(Recall, R)以及F1-Measure作为关键词抽取效果的评价标准, 计算每篇文档的准确率、召回率和F1-Measure, 然后对所有文档的这三个值求平均, 即得到改进后算法在此新闻数据集上的效果。这三类评估方法没有考虑关键词的排序问题, 故假设算法抽取的指定TopN词语中如包含正确的关键词即算作关键词自动抽取成功, 不考虑TopN中的词语顺序问题。令A表示测试数据集中文章本身所提供的关键词集合, B表示使用算法抽取出来的关键词集合, 准确率、召回率和F1-Measure的计算方法如公式(9)-公式(11)所示。
4.3 设置模型参数
LDA模型和TextRank算法中包含的一些参数, 如主题数K、滑动窗口$\omega $以及阻尼因子$\lambda $等, 均会对关键词抽取的效果产生影响, 因此, 需要对这些参数进行调整, 使得算法能够达到最优效果。除了需要调整的参数外, 其他参数根据经验分别设置为$\alpha =$50.0/K、$\beta $=0.01、主题模型迭代次数为1 000次。分别针对主题数、滑动窗口大小以及阻尼系数进行实验, 找到算法表现最优时对应的参数值。
(1) 主题数量K
图2
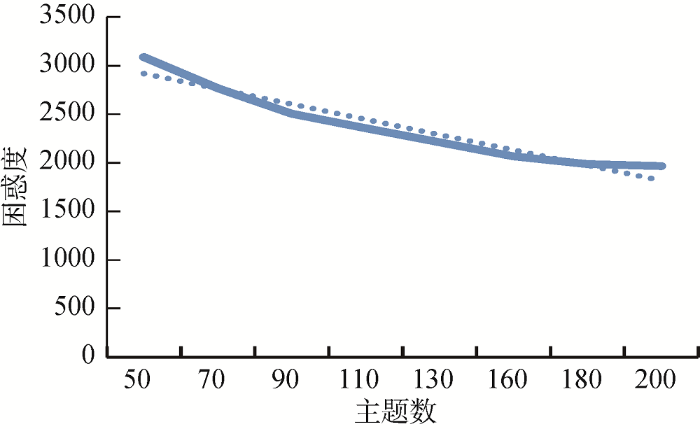
图3
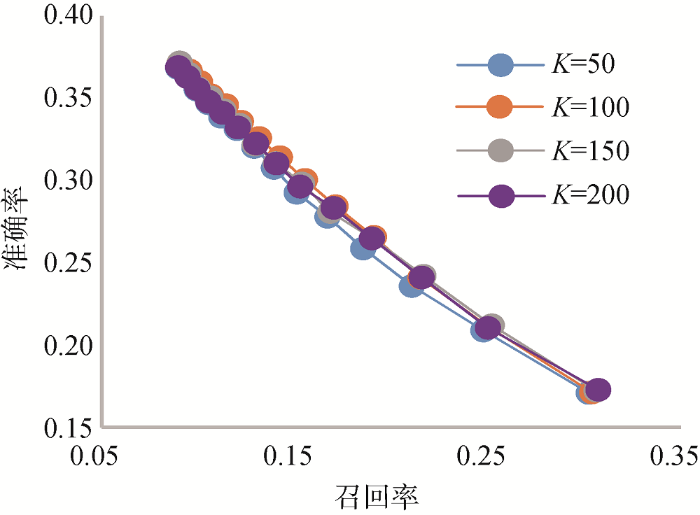
当关键词抽取个数为3, 主题数量分别取50、100、150、200时, 关键词抽取的准确率、召回率以及F1-Measure如表1所示。当主题数为50时, 模型困惑度较高, LDA建模效果不够明显导致主题信息较混乱, 关键词抽取效果较差; 当主题数为100、150和200时, 模型困惑度虽然呈递减模式, 但总体差距不大, 所以关键词抽取效果相差不明显。当主题数为150时, 准确率、召回率略高于其他K值, 所以本文最终设定K=150进行实验。
表1 LDA主题个数K对数据集的影响
| K | P | R | F1 |
|---|---|---|---|
| 50 | 0.248 | 0.209 | 0.224 |
| 100 | 0.251 | 0.211 | 0.226 |
| 150 | 0.252 | 0.212 | 0.228 |
| 200 | 0.250 | 0.211 | 0.226 |
(2) 滑动窗口$\omega $
滑动窗口的大小决定网络的连通性, 通过调整滑动窗口的大小可以改变网络所表示文档结构信息的多少。文献[13]将网络设置为全连通状态, 而大部分网络为半连通网络; 文献[14]认为滑动窗口在[2,10]区间效果较好, 针对较长文本, 滑动窗口应该适当变大, 尽可能多地获取文本结构信息。根据词图中节点的个数, 本文分别将$\omega $设置为3、5、7、9进行实验, 结果如图4所示。当关键词抽取个数为2-5时, 无论$\omega $取值如何, F1-Measure值都比较高。这与训练语料的特性相关, 本文所选取语料标准结果集的关键词一般也是3-5个。滑动窗口设为3时, 关键词效果较好, 但随着抽取关键词个数的增加, 滑动窗口大小对关键词抽取效果的影响越来越小, 因此当所需抽取的关键词个数较多时, 滑动窗口的大小对抽取效果影响不大, 这也验证了部分文献中选择全连通网络结构的合理性。
图4

(3) 阻尼系数$\lambda $
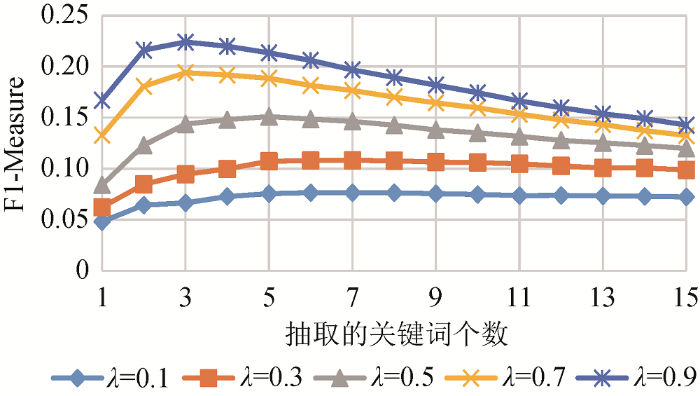
在传统的PageRank中, 阻尼系数用来调整每个网页随机跳转到其他网页的概率; 由于本文算法与原始算法有所不同, 不能再采用默认阻尼系数, 所以需要通过调整阻尼系数, 以达到最优实验结果。分别取阻尼系数为0.1、0.3、0.5、0.7、0.9, 在每个阻尼系数下分别抽取1-15个关键词, 最终得到F1-Measure变化趋势如图5所示。可以看出, 阻尼系数的改变对本算法影响较为显著, 在抽取关键词个数相同的情况下, 随着阻尼系数的增加, 抽取效果逐渐变好。本算法中将阻尼系数$\lambda $设置为0.7-0.9之间效果较好。
图5
4.4 实验结果分析
表2 不同算法准确率、召回率和F值结果
| TopN | TF-IDF | TextRank | LDA | 文献[13]方法 | 文献[14]方法 | 本文算法 | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | P | R | F1 | ||
| 3 | 0.213 | 0.182 | 0.196 | 0.231 | 0.194 | 0.211 | 0.243 | 0.203 | 0.221 | 0.245 | 0.206 | 0.224 | 0.248 | 0.211 | 0.228 | 0.278 | 0.239 | 0.257 | |
| 5 | 0.163 | 0.23 | 0.191 | 0.175 | 0.244 | 0.204 | 0.191 | 0.256 | 0.219 | 0.203 | 0.256 | 0.226 | 0.213 | 0.282 | 0.243 | 0.216 | 0.289 | 0.247 | |
| 7 | 0.135 | 0.264 | 0.179 | 0.141 | 0.274 | 0.186 | 0.162 | 0.289 | 0.208 | 0.169 | 0.293 | 0.214 | 0.183 | 0.325 | 0.234 | 0.181 | 0.323 | 0.232 | |
| 9 | 0.116 | 0.291 | 0.166 | 0.12 | 0.299 | 0.171 | 0.135 | 0.318 | 0.190 | 0.145 | 0.324 | 0.200 | 0.162 | 0.357 | 0.223 | 0.159 | 0.351 | 0.219 | |
| 15 | 0.083 | 0.343 | 0.134 | 0.083 | 0.344 | 0.134 | 0.102 | 0.362 | 0.159 | 0.106 | 0.375 | 0.165 | 0.124 | 0.411 | 0.191 | 0.119 | 0.399 | 0.183 | |
当TopN取3时, 本文算法的关键词抽取准确率最高, 随着抽取关键词个数的增加, 召回率增大, 准确率不断下降; 对比TF-IDF和LDA两种传统方法, 本文算法的准确率、召回率和F1-Measure均有较好的表现。TF-IDF算法只考虑词语的统计特征, 关键词的提取主要还是由词汇出现的频率决定, 没有考虑文档的结构信息; 本实验所选取的语料涵盖多个方面的新闻文章, 不属于同一类型的文章; 所以TF-IDF算法无法综合考虑特征词汇在文档集合类间和类内的分布情况, 因此在这三种算法中效果最差。以TextRank为代表的图方法认为一个词语的重要性由链入它的词语的重要性和数量决定, 考虑文档中词与词之间的共现语义关系, 属于对文档结构的一种建模, 所以效果会相对优于TF-IDF; 但TextRank的思想仍然倾向于选择文档中出现频率较高的词语, 而文档关键词往往和文档之间存在一定的词汇差异现象。对于LDA主题模型, 结合了多文档的外部主题信息, 在抽取关键词时考虑主题的覆盖性, 所以抽取效果优于TF-IDF和TextRank。本文算法将隐含主题模型和基于随机游走的图方法相结合, 具有较好的主题覆盖性, 同时考虑文档的内部结构信息, 所以抽取准确率高于其他传统方法。本文方法与文献[13]和文献[14]方法类似, 均为主题模型和TextRank相结合方式, 故也做对比, 实验结果显示, 本文方法与文献[14]的方法效果优于仅利用主题向量加权的调整节点权重的文献[13]的方法。加入词语长度信息和位置信息的文献[14]方法在提取关键词大于7时, 表现略优于本文算法, 所以词语的位置信息及其他信息也是笔者下一步需要考虑的因素。
利用TextRank和本文算法对随机选取的5篇文章进行关键词抽取结果分析, 选取前5个词展示, 如表3所示。可以看出TextRank对于部分主题较为分散的文档, 往往主题覆盖性较低, 偏向于高频词; 抽取的关键词相比于本文算法的关键词较为靠后, 对于文档含义的表达也有所欠缺。例如: 对于文档1, 从本文算法抽取的关键词可以看出, 该新闻是关于“郭有明副省长涉嫌违纪”事件, 而TextRank算法抽取结果只能得到关于“郭有明”的某个情况。文档2关键词抽取结果所展示两个方法效果相差较小, 根据关键词抽取结果均能看出该文档是描述“幼儿园装修导致甲醛超标, 致使幼儿皮肤过敏, 出现咳嗽症状。”而从文档3抽取结果能够看出TextRank所抽关键词有重复现象, 如公司和有限公司, 只出现两个关键人物名称, 没有抽取事件内容; 本文算法中的“非法经营”和“并处”能够点明事件主旨, 文档3表达“和丁羽心、刘志军相关的公司非法经营被处罚”。文档4关键词抽取结果所展示两个方法效果相近, 大致为“治疗宫颈癌的HPV疫苗经过临床实验, 可供人类接种。”文档5中, TextRank出现宽泛词“报道”并且排序较靠前, 本文算法抽取结果较能准确表达主题“衡阳市人大代表涉嫌破坏选举事件被立案”。综上, 本文算法在无监督关键词抽取方面效果明显优于其他方法。
表3 TextRank与本文算法抽取关键词结果对比
| 文档编号 | 抽取方法 | 关键词 | ||||
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 1 | TextRank | 宜昌 | 郭有明 | 部门 | 透露 | 知情人 |
| 本文算法 | 郭有明 | 副省长 | 报道 | 涉嫌 | 违纪违法 | |
| 2 | TextRank | 幼儿 | 装修 | 幼儿园 | 咳嗽 | 皮肤 |
| 本文算法 | 幼儿园 | 甲醛 | 装修 | 咳嗽 | 过敏 | |
| 3 | TextRank | 公司 | 丁羽心 | 人民币, | 刘志军 | 有限公司 |
| 本文算法 | 丁羽心 | 刘志军 | 并处 | 有限公司, | 非法经营 | |
| 4 | TextRank | HPV疫苗 | 宫颈癌 | 接种 | 默沙东 | 试验 |
| 本文算法 | HPV疫苗 | 宫颈癌 | 临床试验 | 中国 | 上市 | |
| 5 | TextRank | 报道 | 衡阳市 | 破坏选举 | 衡阳 | 人大代表 |
| 本文算法 | 破坏选举 | 衡阳 | 人大代表 | 涉嫌 | 立案 | |
5 结 语
针对仅使用文档内部结构信息进行关键词抽取(TF-IDF和TextRank)和仅利用主题模型进行关键词抽取存在的问题, 本文提出一种综合主题信息和文档结构信息的关键词抽取方法。该方法是一种带有主题权重的随机游走模型, 通过主题词分布重置节点权重, 加权主题词分布和文档主题分布作为随机跳转概率, 构建新的转移矩阵; 通过迭代计算出候选关键词权重, 选取前N个得分较高的候选关键词作为文档关键词。实验结果表明, 该方法能够充分利用两类结构信息, 有效地抽取关键词, 准确率、召回率和F1-Measure均显著高于其他同类算法。
尽管如此, 通用的无监督关键词抽取算法准确率、召回率还普遍较低, 未来研究将考虑充分利用语料内外的语义信息, 借助外部语义特征, 如利用维基百科等扩充文本内容, 进一步提升关键词抽取效果。
作者贡献声明
孙明珠: 提出研究思路和实验方案, 进行实验, 论文撰写与修订;
马静: 扩展研究思路, 论文审阅与修订;
钱玲飞: 论文审阅与修订。
利益冲突声明
所有作者声明不存在利益冲突关系。
支撑数据
支撑数据由作者自存储, E-mail: majing5525@126.com。
[1] 孙明珠, 马静, 钱玲飞. article.xml. 新闻原始语料.
[2] 孙明珠, 马静, 钱玲飞. graph_weight_word.zip. 词图、节点权重及跳转概率信息.
[3] 孙明珠, 马静, 钱玲飞. keyword extract.zip. 程序源码.
参考文献
自动关键词抽取研究综述
[J].
Review of Research in Automatic Keyword Extraction
[J].
TextRank: Bringing Order into Texts
[C]//
Latent Dirichlet Allocation
[J].
Learning Algorithms for Keyphrase Extraction
[J].
Domain-Specific Keyphrase Extraction
[C]//
基于改进TF-IDF的中文网页关键词抽取——以新闻网页为例
[J].
Chinese Webpage Keyword Extraction Based on Improved TF-IDF—Taking News Webpage as an Example
[J].
基于改进的TFIDF关键词自动提取算法研究
[D].
Research on Automatic Keyword Extraction Algorithm Based on Improved TFIDF
[D].
一种基于LDA模型的关键词抽取方法
[J].
A LDA-Based Approach to Keyphrase Extraction
[J].
面向主题的关键词抽取方法研究
[D].
Research on Keyword Extraction Methods for Topics
[D].
词语位置加权TextRank的关键词抽取研究
[J].
Study on Keyword Extraction Using Word Position Weighted TextRank
[J].
词向量聚类加权TextRank的关键词抽取
[J].
Extracting Keywords with Modified TextRank Model
[J].
TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction
[C]//
融合LDA与TextRank的关键词抽取研究
[J].
Study on Keyword Extraction with LDA and TextRank Combination
[J].
基于图和LDA主题模型的关键词抽取算法
[J].
Graph Based Keyphrase Extraction Using LDA Topic Model
[J].
Automatic Keyphrase Extraction via Topic Decomposition
[C]//

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}