1 引言
互联网的快速发展促进了学习资源和在线教育平台的大量涌现,然而海量的资源以及学习途径也导致信息过载(Information Overload)[1 ] 困境的出现。因此,研究高度自动化的个性化学习推荐模型,为学习者针对特定课程或领域推荐适合其自身学习情况的学习方案[2 ] ,成为当前教育领域的研究热点之一。
个性化推荐算法(Personalized Recommendation Algorithm)[3 ] 是个性化学习推荐模型的核心支撑,包括基于协同过滤的推荐算法、基于内容的推荐算法和混合推荐算法等。其中基于用户的协同过滤(User-based Collaborative Filtering)算法[4 ] 以用户为中心,较为适用于个性化学习推荐领域。相似度计算是协同过滤算法的关键步骤。传统的相似度计算方法(如余弦相似度、修正的余弦相似度和皮尔逊相似度[5 ] 等)在应用于计算学习者之间的学习情况相似度时,会忽略与学习者有关的知识点掌握程度、知识点平均分以及测试题目难度差异等重要因素,影响计算准确度,使得对学习者的知识点预测得分出现偏差,进而影响最终的推荐效果。
因此,对协同过滤算法进行针对性改进,将其适配于个性化学习推荐领域,建立一种更适用于学习情况的个性化学习推荐模型(Personalized Learning Recommendation Model)[6 ] 具有重要的现实意义。
2 相关研究
近年来,基于网络学习的个性化学习推荐系统对于学习者的重要性逐渐显现[2 ] 。与一般的资源推荐算法不同,在面向学习资源的个性化推荐算法研究中,除了从学习者的兴趣点出发外,还需要考虑与学习者本身相关的个体特征因素。
2.1 学习推荐模型研究现状
在国内外学者对个性化学习推荐领域的研究中,有以下两方面值得关注:
(1)一些学者结合学习者学习情况等相关因素对传统的协同过滤算法做出改进,以期取得更好的学习推荐效果。Bobadilla等[7 ] 提出一种学习推荐算法New-cosine,该算法对每个学习者推荐的重要程度进行加权,提升学习成绩更好的学习者的推荐权重。Dwivedi等[8 ] 构建一个信任感知网络学习推荐系统TRCF-LS-KL,该系统结合学习者的学习风格、知识水平和不同学习者的信任度等方面对协同过滤算法进行改进。Bourkoukou等[9 ] 提出一种基于改进协同过滤算法和顺序模式挖掘的学习模型CF-SPM,该模型融合学习者的学习对象得分、学习时间和频率等以改进协同过滤算法,进而预测其他学习对象的得分,最后运用SPM算法对学习内容排序后进行推荐。Segal等[10 ] 提出联合协同过滤和社会选择理论的个性化学习推荐模型Edurank,通过协同过滤计算得到待推荐学生的相似学生集合,并根据相似学生集合在不同学习内容的答题情况,对学习内容进行难度排序,最后向学生推荐排序后的学习内容。
上述模型在实践中获得了不错的学习推荐效果,但仍然存在对学习者的学习情况相关因素挖掘不够充分和准确的共性问题,影响了学习情况相似度计算的准确性以及最终的推荐效果。因此,如何客观地挖掘和表征学习情况及其他相关因素,提高相似度计算结果的精确度,进而构建推荐效果更优的协同过滤模型,是值得进一步研究的方向。
(2)基于知识地图的学习推荐方法。这类学习资源推荐模式以知识地图为支撑,基于课程内容之间的内在联系进行学习资源推荐。Zheng等[11 ] 构建一个以知识地图为中心的学习系统Yotta,根据课程的知识结构特点及其逻辑关系创建知识地图,建立学习资源与知识单元的联系,根据学习者在不同知识单元中的学习情况推荐合适的学习资源。Wang等[12 ] 提出一个基于知识地图的知识共享社区模型,该模型通过结合学习系统特性,基于知识地图引导学习者在社区中共享知识内容。李士平等[13 ] 提出使用颜色标记知识点及其之间的关系类型、协同共建资源、自动生成学习路径等促进自我导向学习的策略,论证了知识地图在自我导向学习中起到的积极促进作用。柯立秋[14 ] 提出一种基于知识地图的学习资源融合系统,该系统从知识元关联关系出发,结合学习资源相关标准,建立知识元与学习资源间的关联。
上述基于知识地图的学习推荐模型存在一个明显缺陷:由于不具备对学习情况的预测功能,只能局限于在已有测试数据的学习范畴内进行知识点推荐,不能对其余知识点进行预测性推荐。该缺陷恰好可以通过协同过滤算法进行弥补,将知识地图融合运用于协同过滤学习推荐算法中,发展出一种具备高拓展性和准确度的学习推荐模型。
2.2 归纳与对比
基于研究现状,笔者归纳各种效果较为明显的基于改进协同过滤算法的主流推荐算法模型如表1 所示。
由上述研究成果可知,忽略学习者在学习过程中展现的各种学习情况属性以及知识点之间的内在联系会明显地影响学习推荐模型的效果。因此,本文提出一种融合知识地图、度中心性以及协同过滤算法的个性化学习推荐模型(Learning Situation Based Personalized Learning Recommendation Model, LS-PLRM)。在LS-PLRM中,一方面引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法,在此基础上构造一种基于学习情况的协同过滤算法;另一方面通过挖掘课程知识点之间的内在联系,构建课程知识地图。
与上述其他模型相比,本文提出的LS-PLRM注重合理体现学习者学习情况的关键因素,更准确地获得学习情况相似度的计算结果,进而实现对协同过滤算法的改进;同时通过构建引入知识点度中心性的课程知识地图,并基于此进行知识点的个性化推荐,可以帮助学习者更好地掌握知识脉络,减少学习者在学习过程中的认知负担,提升学习效率。
3 知识地图及知识点的度中心性
由知识模块及知识点构建而成的知识地图可以令学习者在学习过程中更加清晰地了解某一课程或者领域的知识体系结构,而知识点的度中心性可作为在知识地图中优先推荐的相对重要知识点的依据。
3.1 课程知识地图模型
知识地图(Knowledge Map)[16 ] 是一个有向无环图,是一种知识编码方法[17 ] ,展示和解释了“关于知识的知识”[18 ] 。本文将知识地图应用于具体课程,分析课程领域内章、节、知识点间的内在逻辑关系,构建网络化的知识结构图。
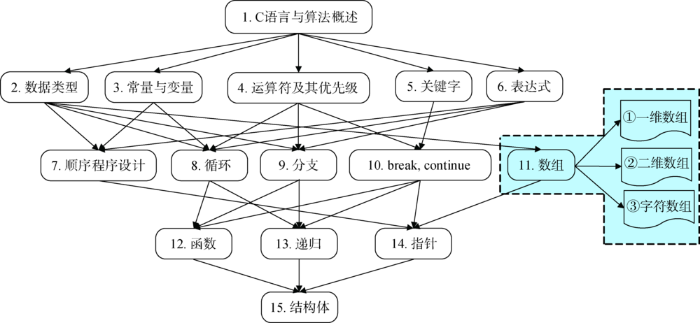
以《C语言程序设计》课程为例,构造其课程知识地图如图1 所示。该课程知识地图包含两大类节点:知识模块和知识点,其中知识模块是一个或多个密切相关的知识点集合。图1 中序号1-15的节点为知识模块。另外,以知识模块“11.数组”为例,列举了隶属于该模块的①-③知识点(见虚线框部分)。其他知识模块也包含数量不等的知识点,由于篇幅所限而不再详细列出。
图1
图1
《C语言程序设计》课程知识地图
Fig.1
Knowledge Map of C Programming
3.2 知识点的度中心性
度中心性(Degree Centrality)用于描述节点在网络结构中的重要程度。一个节点的邻居数目越多,其重要程度就越高[19 ] 。应用于学习推荐领域,度中心性可以衡量一个知识点在课程知识地图的重要程度:度中心性大的知识点一般处于课程知识地图的中心;而度中心性小的知识点一般处于课程知识地图的边缘位置。在知识地图中,知识点隶属于知识模块,为简化计算,可将隶属于同一知识模块的所有知识点的重要程度看作是相同的,因此它们的度中心性也相同。基于同样假设,可将知识点的度中心性等同于所在知识模块的度中心性。某知识模块 m i C D ( m i )
(1) C D ( m i ) = ∑ j z ij h - 1 , i ≠ j
其中, z ij m i m j h 为知识模块数量的总和。
4 基于学习情况的协同过滤算法
本文提出一种适配于个性化学习推荐的协同过滤算法(Collaborative Filtering with Learning Proficiency, Average Score and Topic Differences, PAD-CF),引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法;运用K近邻算法,筛选出相似度最高的TOP-N个学生作为邻居集合;通过该邻居集合计算学生的知识点预测得分,以此作为推荐结果的重要依据之一。
4.1 基于学习情况的相似度计算方法
本文提出一种基于学习情况的相似度计算方法,对传统的Pearson相似度公式进行改进,使其适配于个性化学习推荐领域。不同学生相似度的计算,实质上是计算不同学生在某门课程上学习情况相关因素的相似性。
为体现不同学生在某门课程的掌握程度,引入知识点掌握程度相似性因子(Proficiency Factor,p ),不同学生对知识点的掌握程度相似性越高,表明学生在学习情况上越接近。为描述不同学生对某门课程的总体掌握程度,引入平均分相似性因子(Average Score Factor,a ),不同学生在知识点平均分上相似性越高,表明学生在学习情况上越接近。另外,用于考查同一个知识点的不同题目不可避免地存在难度上的差异,当抽取这些题目进行组卷时,会导致同一个知识点在不同试卷中所表现出的难度系数存在差别,因此引入知识点难度系数修正因子(Difference Factor,d )。
本文提出的三个因子相互关联,并且构成了对学生学习情况的整体表征。p 和a 是从学生对课程的学习情况出发,总体把握学生之间对课程掌握程度的相似性,用于挖掘学生学习课程的学习情况特性。另外,不同试题产生的知识点难度系数差异会影响计算p 和a 的准确度,最终影响学生之间相似度计算的准确性,因此需引入知识点难度系数修正因子d ,以限制知识点难度系数差异带来的影响。
基于上述三个因子形成一种基于学习情况的相似度计算方法,从学习者的学习情况和认知水平出发,同时考虑课程特性并通过修正因子降低知识点难度系数差异。该方法能较为充分和准确地计算学习情况的相似度,进而提升知识点得分预测的准确性。
假设考查学生 s i s j S 1 S 2 Si m pad ( s i , s j ) s i s j
(2) Si m pad ( s i , s j ) = p s i , s j × a s i , s j × ∑ x ∈ X r ' s i , x - r ' s i ¯ r s j , x - r s j ¯ ∑ x ∈ X r ' s i , x - r ' s i ¯ 2 ∑ x ∈ X r s j , x - r s j ¯ 2 x ∈ X = Z 1 ⋂ Z 2
其中, r ' s i , x r ' s i ¯
(3) r ' s i , x = d S 1 , S 2 × r s i , x
(4) r ' s i ¯ = d S 1 , S 2 × r s i ¯
其中, p s i , s j a s i , s j d S 1 , S 2 Z 1 Z 2 s i s j X s i s j r s i , x r s i ¯ s i x 上的得分和在 X r ' s i , x r ' s i ¯ s i d S 1 , S 2 x 上的得分和在 X r s j , x r s j ¯ s j x 上的得分和在 X
在学习某门课程时,不同学生对于各个知识点会有不同的掌握程度。知识点掌握程度相似性因子p 用于描述学生 s i s j
(5) p s i , s j = | X s i , s j p | + | X s i , s j np | | Z 1 ⋂ Z 2 |
其中, | X s i , s j p | s i s j | X s i , s j np | s i s j | Z 1 ⋂ Z 2 | s i s j
p s i , s j s i s j
从考试成绩的角度,学生对于某门课程的学习情况还可以由知识点的平均分来表征,如果两个学生在某门课程的知识点平均分越接近,则他们学习情况的相似程度就越高,由此引入平均分相似性因子a 。某两位学生 s i s j a s i , s j
(6) a s i , s j = r f - r s i , all ¯ - r s j , all ¯
其中, r f r s i , all ¯ r s j , all ¯ s i s j
r s i , all ¯ - r s j , all ¯ s i s j a s i , s j
用于考查同一个知识点的不同题目存在难度上的差异。当抽取这些题目进行组卷时,会导致某知识点在不同试卷中所表现出的难度系数有差异。引入知识点难度系数修正因子d 可以减小该差异,学生 s i s j S 1 S 2 S 1 S 2
(7) d S 1 , S 2 = r S 1 , x ¯ r S 2 , x ¯ x ∈ X = Z 1 ⋂ Z 2
其中, X S 1 S 2 r S 1 , x ¯ r S 2 , x ¯ S 1 S 2 x 的平均得分。
4.2 基于K近邻算法的知识点得分预测
K近邻(K-Nearest Neighbor)算法的基本思想[20 ] 是:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)样本中的大多数属于某一个类别,则推断该样本也属于这个类别。
对于某一学生 s i ∈ S 1 s i S 2 s i W W ⊆ S 2 W s i y 上的分数 Fs ( s i , y )
(8) Fs ( s i , y ) = r s i ¯ + ∑ s j ∈ W Si m pad ( s i , s j ) ( r s j , y - r s j ¯ ) ∑ s j ∈ W Si m pad ( s i , s j ) y ∈ Y = Z 1 - Z 1 ⋂ Z 2
其中, Si m pad ( s i , s j ) s i s j ∈ W Y s i r s j , y s j y
5 融合知识地图、度中心性与协同过滤的个性化学习推荐模型
5.1 个性化学习推荐模型的构建
在个性化学习推荐模型LS-PLRM中,基于知识点的度中心性,运用协同过滤算法PAD-CF计算知识点推荐度,将其标注于知识地图的知识点中,最终形成学习者的个性化学习方案。
个性化学习方案以课程知识地图作为载体。知识地图中的知识点对应唯一的推荐度。推荐度越高的知识点,越应当引起学习者的重视。推荐度由知识点的度中心性与学习者在知识点的失分分值计算得到,其中度中心性高的知识点表示该知识点在知识网络中的重要程度高;而失分分值高的知识点表明学习者对该知识点的掌握程度较低。
对于某学生 s i x 所属知识模块 m j C D ( m j ) [ r f - r s i , x ] x 的推荐度,如公式(9)所示。
(9) Rec ( s i , x , m j ) = w 1 C D ( m j ) + w 2 [ r f - r s i , x ] x ∈ X = Z 1 ⋂ Z 2
同理,对于未测知识点y ,其所属知识模块 m k C D ( m k ) [ r f - Fs ( s i , y ) ]
(10) Rec ( s i , y , m k ) = w 1 C D ( m k ) + w 2 [ r f - Fs ( s i , y ) ] y ∈ Y = Z 1 - Z 1 ⋂ Z 2
其中, w 1 x 或y 所属知识模块度中心性的权重因子; w 2
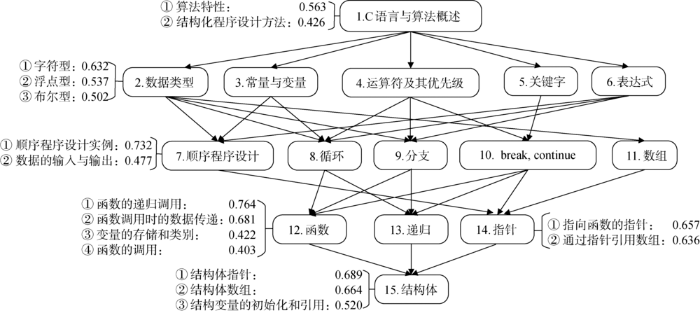
将推荐度标注于知识地图的知识点中,可形成学习者的个性化学习方案。方案所推荐的知识点均为学习者尚未掌握的知识点。以某同学为例,LS-PLRM为其生成的《C语言程序设计》课程的个性化学习方案(局部)如图2 所示(由于篇幅所限,仅列举出6个知识模块的知识点推荐度)。
图2
图2
个性化学习方案示例
Fig.2
Example of Personalized Learning Scheme
5.2 个性化学习推荐模型实施流程
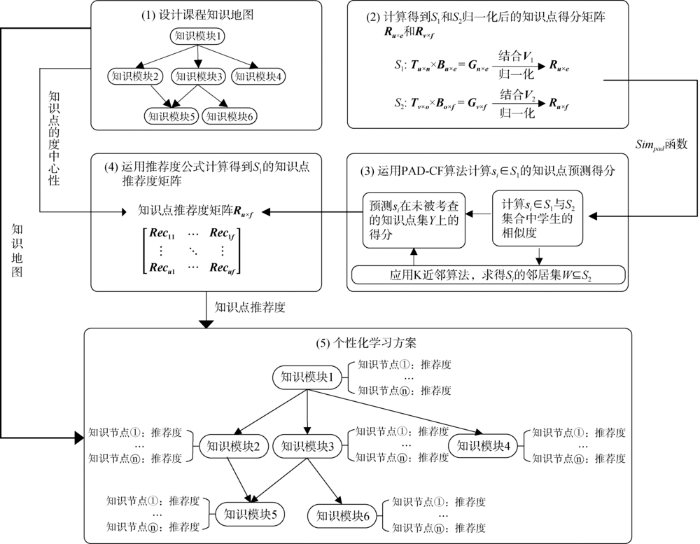
基于课程知识地图、度中心性以及基于学习情况的协同过滤算法,构造LS-PLRM推荐模型的实施框架,其实施流程如图3 所示。
图3
图3
LS-PLRM的实施框架
Fig.3
Framework of LS-PLRM
(1)建立课程知识地图,并计算所有知识模块的度中心性,进而得到所有知识点的度中心性。
(2)设有学生集合 S 1 S 2 u 和v ;用于考查 S 1 S 2 Q 1 Q 2 n 和o ; Q 1 Q 2 Z 1 Z 2 e 和f , Z 1 Z 2 V 1 = { α 1 , α 2 , ⋯ , α e } V 2 = { β 1 , β 2 , ⋯ , β f } B n × e B o × f S 1 S 2 T u × n T v × o G u × e G v × f R u × e R v × f
①据学生的试卷得分情况,分别获取 S 1 S 2 T u × n T v × o
②结合 B n × e B o × f G u × e = T u × n × B n × e G v × f = T v × o × B o × f
③对 G u × e G v × f g ij ∈ G u × e r ij = g ij / α j r ij ∈ R u × e α j ∈ V 1 g ij R u × e G v × f V 2 R v × f
(3)运用PAD-CF算法计算某一学生 s i ∈ S 1 y Fs ( s i , y )
(4)对于 s i
(5)将各个知识点的推荐度标注于课程知识地图中,得到一个以课程知识地图形式呈现的个性化学习方案。学习者可以结合自身学习该课程的需求,按照知识模块层级、知识模块顺序以及各个知识点推荐度的高低对该门课程进行针对性学习。
6 实验及结果分析
(1)实验一:将个性化学习推荐模型LS-PLRM与其他推荐模型进行有效性方面的对比验证;
(2)实验二:基于实验一将个性化学习推荐模型应用于实际的学习者群体,运用分组对比策略,与其他推荐模型作实际应用效果的对比验证。
6.1 实验数据采集
为验证个性化学习推荐模型的有效性,采集三组数据集:dataset_one、dataset_two和dataset_three,均来自广东某高校学生的期末考试数据以及两次测验的实际数据。
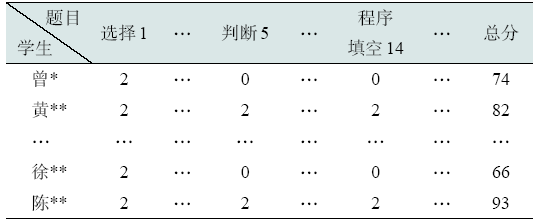
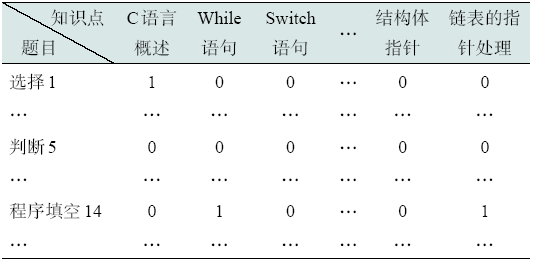
采集自往届学生《C语言程序设计》期末考试成绩,共包含1 430位学生的考试得分,所用试卷共有题目50道,涉及知识点59个。dataset_one用于验证PAD-CF协同过滤算法的有效性,为应用于其中学生学习情况相似度的计算,需要按各道题目得分分别处理。采集到学生的题目得分矩阵,如表2 所示。
通过分析试卷中题目所考查的知识点,得到题目-知识点关联矩阵如表3 所示(其中1代表该题目考查了该知识点,0代表未考查)。
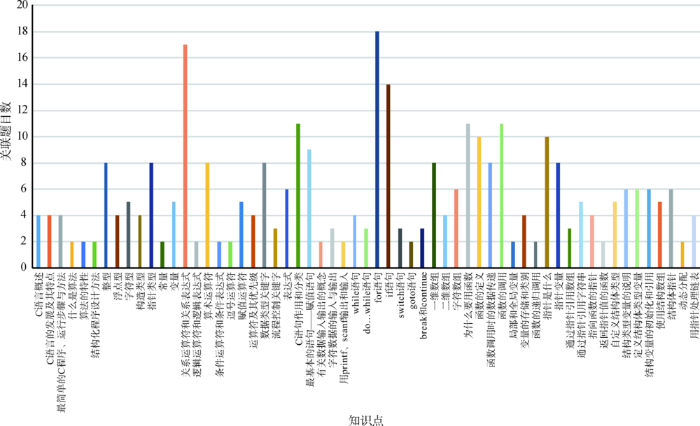
作为期末考试,试卷中涵盖了绝大部分知识点,各知识点所关联的题目数量如图4 所示。
图4
图4
dataset_one中各知识点所关联的题目数量
Fig.4
Question Quantity Associated with Knowledge Points in dataset_one
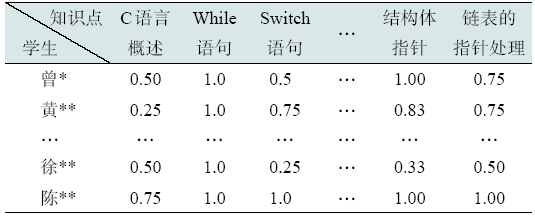
结合题目得分矩阵和题目-知识点关联矩阵,计算得到学生在各个知识点上的得分矩阵,然后对知识点得分进行归一化处理,得到归一化后的知识点得分矩阵如表4 所示,由此构成dataset_one。
(2) dataset_two和dataset_three
dataset_two和dataset_three采集自参与本实验学生的两次对比测试的题目得分,用于验证个性化学习推荐模型的实用性。
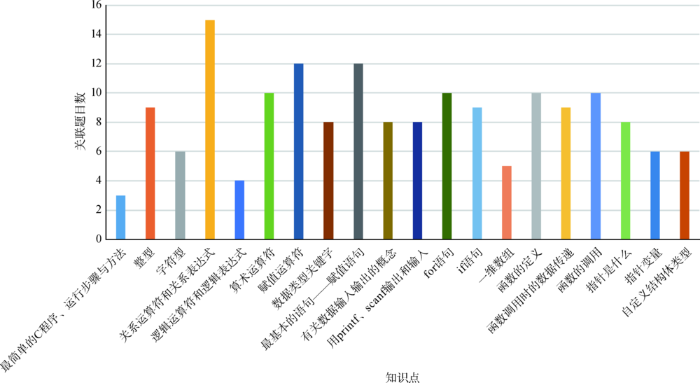
其中dataset_two采集自这些学生第一次测试的题目得分。dataset_two中共包含153位学生的测验得分,所用试卷共有44道题目,涉及20个知识点。同样需要按各道题目得分分别处理(过程参考dataset_one),获得归一化后的知识点得分矩阵,由此构成dataset_two。各知识点所关联的题目数量如图5 所示。
图5
图5
dataset_two中各知识点所关联的题目数量
Fig.5
Question Quantity Associated with Knowledge Point in dataset_two
dataset_three采集自上述学生第二次测试的题目得分。
6.2 实验评价指标
分别通过准确率(precision)、召回率(recall)和F值评价推荐知识点的准确性,通过平均绝对误差(MAE)[21 ] 衡量知识点预测得分与实际得分的接近程度。各指标的计算方法如公式(11)-公式(14)所示。
(11) precision = CorrectRec TotalRec
(12) recall = CorrectRec TotalNotPro
(13) F = 2 × precision × recall precision + recall
(14) MAE = ∑ l=1 N | l i - l i ̑ | N
其中, CorrectRec TotalRec TotalNotPro l i i l i ̑ i
另外,通过得分提升率(GrowthRate)衡量各组学生使用不同推荐模型的效果,如公式(15)所示。
(15) Growt h Rate = ImprovedScore FirstTextScore
其中,ImprovedScore 是增长的分数,FirstTextScore 是第一次测试的分数。
6.3 实验对比及分析
在实验中,将LS-PLRM与Pearson-CF、CF-SPM和Edurank等模型进行对比。选择这些模型进行对比的原因是:Pearson-CF是经典的协同过滤算法,其应用面较广;CF-SPM和Edurank是近年新提出的学习推荐模型,在方法上具有较高的创新性,并且已在实验中取得了较好的推荐效果。
(1) 实验一:验证个性化学习推荐模型的理论有效性
本实验使用dataset_one数据集,该数据集采集自学生期末考试的题目得分,题目具有较强的代表性,适合作为验证不同协同过滤算法有效性的数据集。从dataset_one中抽取90%作为训练集(包含1 287位学生数据);另外10%作为验证集(包含143位学生数据)。
对于《C语言程序设计》,实验表明 w 1 w 2 w 1 w 2
各推荐模型在指标值precision、recall和F值上的实验结果如表5 所示。可以看出,LS-PLRM的实验结果优于其余三种推荐模型,表明LS-PLRM模型能够更加准确地为学生推荐知识点。
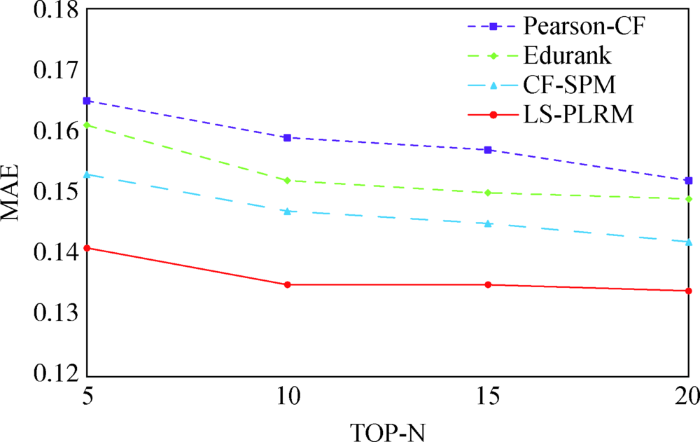
MAE反映知识点预测得分的准确性,MAE值越低,说明该协同过滤算法能够更加准确地预测知识点得分。由于知识点得分进行了归一化处理,各算法模型的MAE值较低,如图6 所示,可以发现LS-PLRM模型比Pearson-CF、Edurank、CF-SPM在MAE值上分别降低11.84%、10.07%、5.63%,知识点预测得分与实际得分的接近程度更高,因此预测的知识点得分更为准确。
图6
图6
各种推荐模型的MAE指标值对比
Fig.6
MAE Values of Recommendation Models
(2) 实验二:验证个性化学习推荐模型的实际有效性
参与本实验的学生共有153名,大致均分为4个小组验证个性化学习推荐模型的有效性。本实验分为两次测试,在第一次测试之后,学生根据不同推荐模型学习两周,然后进行第二次测试。各组的人数及采用的推荐模型如表6 所示。
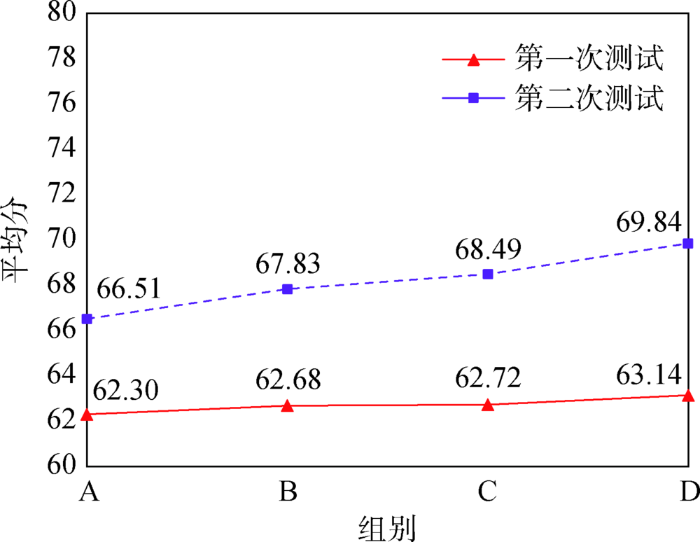
各组学生在两次测试中的平均分如图7 所示,可以看出,A、B、C和D组在第二次测试中的平均分比第一次分别提升4.21、5.15、5.77和6.70,得分提升率分别为6.76%、8.22%、9.20%和10.61%。因此,LS-PLRM模型相比其他推荐模型的有更好的应用效果。
图7
图7
两次测试中的平均分对比
Fig.7
Average Scores in Two Tests
为进一步分析4组学生经过不同推荐模型学习之后的差异性,采用数据分析工具SPSS对第二次测试作特别适用于小样本规模的T检验分析[22 ] 。由于实验需要,各组人数需保持一致,因此在B组随机减少一名学生。分组样本统计如表7 所示,分组成对样本检验如表8 所示。可知各组应用不同模型进行学习之后,D组较其他组的测试得分均值更高,表明LS-PLRM的推荐效果更佳;标准差和均值的标准误差更低,表明经过LS-PLRM学习的学生群体成绩更加均衡,分离度较小。
结合表8 的t 值和sig.(2-tailed)值可以进一步发现,D组与A、B、C相比,sig.(2-tailed)值均小于0.05,表明D组学生的分数与其他各组有显著性差异,使用LS-PLRM进行学习的D组学生取得更好的提升效果,也体现了LS-PLRM在个性化学习推荐领域的有效性。
7 结语
本文构建一种基于学习情况协同过滤算法的个性化学习推荐模型LS-PLRM。在LS-PLRM中,提出一种应用三个学习情况因子以改进相似度计算的PAD-CF协同过滤算法,同时结合知识地图与知识点度中心性进行知识点推荐度的计算与标注,最终生成个性化学习方案。实验结果表明,相比于其他推荐模型,LS-PLRM的推荐知识点准确性更高,证明了LS-PLRM的有效性;同时在实际应用中,学生根据LS-PLRM生成的个性化学习方案学习之后,整体的学习效果有明显提升。
在LS-PLRM模型中,对学习情况影响因素的挖掘尚不够充分;另外,在知识地图的构建过程中,对知识点内在关联的考虑也未够细致。在未来研究中,将考虑更加丰富的学习情况影响因素,进一步提升预测知识点得分的准确性;并构建更为完善的知识地图,以达到更好的推荐效果。
作者贡献声明
陈思兆:设计研究方案,技术实现,进行实验,论文起草;
支撑数据
支撑数据由作者自存储,E-mail: sizhao_chen@163.com。
[1] 陈思兆,李小妹. dataset_one.xlsx. 1430位学生期末成绩及归一化后知识点得分.
[2] 陈思兆,李小妹. dataset_two.xlsx. 153位学生第一次测试的成绩.
[3] 陈思兆,李小妹. dataset_three.xlsx. 153位学生第二次测试的成绩.
[4] 陈思兆,李小妹. knowledgePointsNumber.xlsx. 题目关联知识点数量.
[5] 陈思兆,李小妹. incidenceMatrix.xlsx. 题目-知识点关联矩阵表.
[6] 陈思兆,李小妹. examination.rar. 第一次&第二次测试试卷及答案.
[7] 陈思兆,李小妹. recommend.xlsx. 模型生成153位学生的推荐结果(包括推荐知识点及对应推荐度).
参考文献
View Option
[1]
Tarus J K Niu Z Mustafa G . Knowledge-based Recommendation: A Review of Ontology-based Recommender Systems for E-learning
[J]. Artificial Intelligence Review , 2018 ,50 :21 -48 .
[本文引用: 1]
[2]
Lu J . A Personalized E-Learning Material Recommender System
[C]// Proceedings of the 2nd International Conference on Information Technology for Application (ICITA 2004), Sydney, Australia. 2004 : 374 -379 .
[本文引用: 2]
[3]
杨晋吉 , 胡波 , 王欣明 , 等 . 一种知识图谱的排序学习个性化推荐算法
[J]. 小型微型计算机系统 , 2018 ,39 (11 ):2419 -2423 .
[本文引用: 1]
( Yang Jinji Hu Bo Wang Xinming , et al . Personalized Recommendation Algorithm for Learning to Rank by Knowledge Graph
[J]. Journal of Chinese Computer Systems , 2018 ,39 (11 ):2419 -2423 .)
[本文引用: 1]
[4]
Zhao Z D Shang M S . User-based Collaborative-Filtering Recommendation Algorithms on Hadoop
[C]// Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand. 2010 : 478 -481 .
[本文引用: 1]
[5]
李容 , 李明奇 , 郭文强 . 基于改进相似度的协同过滤算法研究
[J]. 计算机科学 , 2016 ,43 (12 ):206 -208, 240 .
[本文引用: 1]
( Li Rong Li Mingqi Guo Wenqiang . Research on Collaborative Filtering Algorithm with Improved Similarity
[J]. Computer Science , 2016 ,43 (12 ):206 -208, 240 .)
[本文引用: 1]
[6]
韩建华 , 姜强 , 赵蔚 , 等 . 智能导学环境下个性化学习模型及应用效能评价
[J]. 电化教育研究 , 2016 ,37 (7 ):66 -73 .
[本文引用: 1]
( Han Jianhua Jiang Qiang Zhao Wei , et al . A Model of Personalized Learning in Intelligent Tutoring Environment and Its Evaluation
[J]. E-education Research , 2016 ,37 (7 ):66 -73 .)
[本文引用: 1]
[7]
Bobadilla J Serradilla F Hernando A . Collaborative Filtering Adapted to Recommender Systems of E-learning
[J]. Knowledge-Based Systems , 2009 ,22 (4 ):261 -265 .
[本文引用: 2]
[8]
Dwivedi P Bharadwaj K K . Effective Trust-aware E-learning Recommender System Based on Learning Styles and Knowledge Levels
[J]. Journal of Educational Technology & Society , 2013 ,16 (4 ):201 -216 .
[本文引用: 2]
[9]
Bourkoukou O EI Bachari E EI Adnani M . A Recommender Model in E-learning Environment
[J]. Arabian Journal for Science and Engineering , 2017 ,42 :607 -617 .
[本文引用: 2]
[10]
Segal A Gal K Shani G , et al . A Difficulty Ranking Approach to Personalization in E-learning
[J]. International Journal of Human-Computer Studies , 2019 ,130 :261 -272 .
[本文引用: 2]
[11]
Zheng Q H Qian Y N Liu J . Yotta: A Knowledge Map Centric E-Learning System
[C]// Proceedings of the 7th International Conference on e-Business Engineering (ICEBE), Shanghai, China. 2010 : 42 -49 .
[本文引用: 1]
[12]
Wang M H Huang C F Yang T Y . Acceptance of Knowledge Map Systems: An Empirical Examination of System Characteristics and Knowledge Map Systems Self-efficacy
[J]. Asia Pacific Management Review , 2012 ,17 (3 ):263 -280 .
[本文引用: 1]
[13]
李士平 , 赵蔚 , 刘红霞 , 等 . 基于知识地图的自我导向学习设计与实证研究
[J]. 电化教育研究 , 2016 ,37 (5 ):74 -81 .
[本文引用: 1]
( Li Shiping Zhao Wei Liu Hongxia , et al . The Design and Empirical Research of Knowledge-Map Based Self-Directed Learning
[J]. E-education Research , 2016 ,37 (5 ):74 -81 .)
[本文引用: 1]
[14]
柯立秋 . 基于知识地图的学习资源融合系统设计与实现
[D]. 武汉: 华中师范大学 , 2018 .
[本文引用: 1]
( Ke Liqiu . Design and Implementation of Learning Resource Fusion System Based on Knowledge Map
[D]. Wuhan: Central China Normal University , 2018 .)
[本文引用: 1]
[15]
马宏伟 , 张光卫 , 李鹏 . 协同过滤推荐算法综述
[J]. 小型微型计算机系统 , 2009 ,30 (7 ):1282 -1288 .
[本文引用: 1]
( Ma Hongwei Zhang Guangwei Li Peng . Survey of Collaborative Filtering Algorithms
[J]. Journal of Chinese Computer Systems , 2009 ,30 (7 ):1282 -1288 .)
[本文引用: 1]
[16]
Zins C . Knowledge Map of Information Science
[J]. Journal of the American Society for Information Science and Technology , 2007 ,58 (4 ):526 -535 .
[本文引用: 1]
[17]
叶伟巍 . 知识学习与技术创新
[J]. 高等工程教育研究 , 2016 (5 ):74 -79 .
[本文引用: 1]
( Ye Weiwei . Research on Knowledge Gaining and Technological Innovation
[J]. Research in Higher Education of Engineering , 2016 (5 ):74 -79 .)
[本文引用: 1]
[18]
李松林 . 知识教学的突破: 从知识到知识的知识
[J]. 教育科学研究 , 2016 (1 ):60 -64 .
[本文引用: 1]
( Li Songlin . The Breakthrough of Knowledge Teaching: From Knowledge to Knowledge
[J]. Educational Science Research , 2016 (1 ):60 -64 .)
[本文引用: 1]
[19]
Borgatti S P Everett M G . A Graph-theoretic Perspective on Centrality
[J]. Social Networks , 2006 ,28 (4 ):466 -484 .
[本文引用: 1]
[20]
Dong W Moses C Li K . Efficient K-Nearest Neighbor Graph Construction for Generic Similarity Measures
[C]// Proceedings of the 20th International Conference on World Wide Web, Hyderabad, India. 2011 .
[本文引用: 1]
[21]
Klašnja-Milićević A Vesin B Ivanović M , et al . E-Learning Personalization Based on Hybrid Recommendation Strategy and Learning Style Identification
[J]. Computers & Education , 2011 ,56 (3 ):885 -899 .
[本文引用: 1]
[22]
de Winter J C F . Using the Student’s T-test with Extremely Small Sample Sizes
[J]. Practical Assessment, Research, and Evaluation , 2013 ,18 : Article No. 10.
[本文引用: 1]
Knowledge-based Recommendation: A Review of Ontology-based Recommender Systems for E-learning
1
2018
... 互联网的快速发展促进了学习资源和在线教育平台的大量涌现,然而海量的资源以及学习途径也导致信息过载(Information Overload)[1 ] 困境的出现.因此,研究高度自动化的个性化学习推荐模型,为学习者针对特定课程或领域推荐适合其自身学习情况的学习方案[2 ] ,成为当前教育领域的研究热点之一. ...
A Personalized E-Learning Material Recommender System
2
2004
... 互联网的快速发展促进了学习资源和在线教育平台的大量涌现,然而海量的资源以及学习途径也导致信息过载(Information Overload)[1 ] 困境的出现.因此,研究高度自动化的个性化学习推荐模型,为学习者针对特定课程或领域推荐适合其自身学习情况的学习方案[2 ] ,成为当前教育领域的研究热点之一. ...
... 近年来,基于网络学习的个性化学习推荐系统对于学习者的重要性逐渐显现[2 ] .与一般的资源推荐算法不同,在面向学习资源的个性化推荐算法研究中,除了从学习者的兴趣点出发外,还需要考虑与学习者本身相关的个体特征因素. ...
一种知识图谱的排序学习个性化推荐算法
1
2018
... 个性化推荐算法(Personalized Recommendation Algorithm)[3 ] 是个性化学习推荐模型的核心支撑,包括基于协同过滤的推荐算法、基于内容的推荐算法和混合推荐算法等.其中基于用户的协同过滤(User-based Collaborative Filtering)算法[4 ] 以用户为中心,较为适用于个性化学习推荐领域.相似度计算是协同过滤算法的关键步骤.传统的相似度计算方法(如余弦相似度、修正的余弦相似度和皮尔逊相似度[5 ] 等)在应用于计算学习者之间的学习情况相似度时,会忽略与学习者有关的知识点掌握程度、知识点平均分以及测试题目难度差异等重要因素,影响计算准确度,使得对学习者的知识点预测得分出现偏差,进而影响最终的推荐效果. ...
一种知识图谱的排序学习个性化推荐算法
1
2018
... 个性化推荐算法(Personalized Recommendation Algorithm)[3 ] 是个性化学习推荐模型的核心支撑,包括基于协同过滤的推荐算法、基于内容的推荐算法和混合推荐算法等.其中基于用户的协同过滤(User-based Collaborative Filtering)算法[4 ] 以用户为中心,较为适用于个性化学习推荐领域.相似度计算是协同过滤算法的关键步骤.传统的相似度计算方法(如余弦相似度、修正的余弦相似度和皮尔逊相似度[5 ] 等)在应用于计算学习者之间的学习情况相似度时,会忽略与学习者有关的知识点掌握程度、知识点平均分以及测试题目难度差异等重要因素,影响计算准确度,使得对学习者的知识点预测得分出现偏差,进而影响最终的推荐效果. ...
User-based Collaborative-Filtering Recommendation Algorithms on Hadoop
1
2010
... 个性化推荐算法(Personalized Recommendation Algorithm)[3 ] 是个性化学习推荐模型的核心支撑,包括基于协同过滤的推荐算法、基于内容的推荐算法和混合推荐算法等.其中基于用户的协同过滤(User-based Collaborative Filtering)算法[4 ] 以用户为中心,较为适用于个性化学习推荐领域.相似度计算是协同过滤算法的关键步骤.传统的相似度计算方法(如余弦相似度、修正的余弦相似度和皮尔逊相似度[5 ] 等)在应用于计算学习者之间的学习情况相似度时,会忽略与学习者有关的知识点掌握程度、知识点平均分以及测试题目难度差异等重要因素,影响计算准确度,使得对学习者的知识点预测得分出现偏差,进而影响最终的推荐效果. ...
基于改进相似度的协同过滤算法研究
1
2016
... 个性化推荐算法(Personalized Recommendation Algorithm)[3 ] 是个性化学习推荐模型的核心支撑,包括基于协同过滤的推荐算法、基于内容的推荐算法和混合推荐算法等.其中基于用户的协同过滤(User-based Collaborative Filtering)算法[4 ] 以用户为中心,较为适用于个性化学习推荐领域.相似度计算是协同过滤算法的关键步骤.传统的相似度计算方法(如余弦相似度、修正的余弦相似度和皮尔逊相似度[5 ] 等)在应用于计算学习者之间的学习情况相似度时,会忽略与学习者有关的知识点掌握程度、知识点平均分以及测试题目难度差异等重要因素,影响计算准确度,使得对学习者的知识点预测得分出现偏差,进而影响最终的推荐效果. ...
基于改进相似度的协同过滤算法研究
1
2016
... 个性化推荐算法(Personalized Recommendation Algorithm)[3 ] 是个性化学习推荐模型的核心支撑,包括基于协同过滤的推荐算法、基于内容的推荐算法和混合推荐算法等.其中基于用户的协同过滤(User-based Collaborative Filtering)算法[4 ] 以用户为中心,较为适用于个性化学习推荐领域.相似度计算是协同过滤算法的关键步骤.传统的相似度计算方法(如余弦相似度、修正的余弦相似度和皮尔逊相似度[5 ] 等)在应用于计算学习者之间的学习情况相似度时,会忽略与学习者有关的知识点掌握程度、知识点平均分以及测试题目难度差异等重要因素,影响计算准确度,使得对学习者的知识点预测得分出现偏差,进而影响最终的推荐效果. ...
智能导学环境下个性化学习模型及应用效能评价
1
2016
... 因此,对协同过滤算法进行针对性改进,将其适配于个性化学习推荐领域,建立一种更适用于学习情况的个性化学习推荐模型(Personalized Learning Recommendation Model)[6 ] 具有重要的现实意义. ...
智能导学环境下个性化学习模型及应用效能评价
1
2016
... 因此,对协同过滤算法进行针对性改进,将其适配于个性化学习推荐领域,建立一种更适用于学习情况的个性化学习推荐模型(Personalized Learning Recommendation Model)[6 ] 具有重要的现实意义. ...
Collaborative Filtering Adapted to Recommender Systems of E-learning
2
2009
... (1)一些学者结合学习者学习情况等相关因素对传统的协同过滤算法做出改进,以期取得更好的学习推荐效果.Bobadilla等[7 ] 提出一种学习推荐算法New-cosine,该算法对每个学习者推荐的重要程度进行加权,提升学习成绩更好的学习者的推荐权重.Dwivedi等[8 ] 构建一个信任感知网络学习推荐系统TRCF-LS-KL,该系统结合学习者的学习风格、知识水平和不同学习者的信任度等方面对协同过滤算法进行改进.Bourkoukou等[9 ] 提出一种基于改进协同过滤算法和顺序模式挖掘的学习模型CF-SPM,该模型融合学习者的学习对象得分、学习时间和频率等以改进协同过滤算法,进而预测其他学习对象的得分,最后运用SPM算法对学习内容排序后进行推荐.Segal等[10 ] 提出联合协同过滤和社会选择理论的个性化学习推荐模型Edurank,通过协同过滤计算得到待推荐学生的相似学生集合,并根据相似学生集合在不同学习内容的答题情况,对学习内容进行难度排序,最后向学生推荐排序后的学习内容. ...
... Introduction of Classical Recommendation Model
Table 1 算法模型 优势 不足 Pearson-CF[15 ] 是经典的协同过滤算法,结合学习者的共同知识点平均分,使得相似度的计算更具客观性. 由于忽略了体现学习者学习情况的各种因素,导致相似度计算结果准确度欠佳. New-cosine[7 ] 引入权重方程,提升了学习成绩较好学习者的推荐权重,进而改进协同过滤算法. 学习者的学习情况各异,仅以成绩较好的学习者作为推荐标准,缺乏个性化,影响推荐效果. TRCF-LS-KL[8 ] 结合学习者学习风格、知识水平及信任模式对协同过滤算法进行改进. 仅通过问卷调查手段确定学习风格相对片面;由学习者指定被信任人的信任模式具有较大主观性. CF-SPM[9 ] 融合学习者的学习情况(学习对象得分)以及学习风格(学习某对象的时间、频率)改进协同过滤算法. 仅以学习时间和频率等个体差异较大的因素计算学习者的相似度时,存在较大偏差,客观性不足. Edurank[10 ] 联合协同过滤和社会选择理论,结合学习者以及相似学习群体的学习情况和认知水平改进协同过滤算法. 缺乏对学习者自身学习情况和学习风格等方面信息的挖掘,与个性化学习情况的结合程度较低.
由上述研究成果可知,忽略学习者在学习过程中展现的各种学习情况属性以及知识点之间的内在联系会明显地影响学习推荐模型的效果.因此,本文提出一种融合知识地图、度中心性以及协同过滤算法的个性化学习推荐模型(Learning Situation Based Personalized Learning Recommendation Model, LS-PLRM).在LS-PLRM中,一方面引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法,在此基础上构造一种基于学习情况的协同过滤算法;另一方面通过挖掘课程知识点之间的内在联系,构建课程知识地图. ...
Effective Trust-aware E-learning Recommender System Based on Learning Styles and Knowledge Levels
2
2013
... (1)一些学者结合学习者学习情况等相关因素对传统的协同过滤算法做出改进,以期取得更好的学习推荐效果.Bobadilla等[7 ] 提出一种学习推荐算法New-cosine,该算法对每个学习者推荐的重要程度进行加权,提升学习成绩更好的学习者的推荐权重.Dwivedi等[8 ] 构建一个信任感知网络学习推荐系统TRCF-LS-KL,该系统结合学习者的学习风格、知识水平和不同学习者的信任度等方面对协同过滤算法进行改进.Bourkoukou等[9 ] 提出一种基于改进协同过滤算法和顺序模式挖掘的学习模型CF-SPM,该模型融合学习者的学习对象得分、学习时间和频率等以改进协同过滤算法,进而预测其他学习对象的得分,最后运用SPM算法对学习内容排序后进行推荐.Segal等[10 ] 提出联合协同过滤和社会选择理论的个性化学习推荐模型Edurank,通过协同过滤计算得到待推荐学生的相似学生集合,并根据相似学生集合在不同学习内容的答题情况,对学习内容进行难度排序,最后向学生推荐排序后的学习内容. ...
... Introduction of Classical Recommendation Model
Table 1 算法模型 优势 不足 Pearson-CF[15 ] 是经典的协同过滤算法,结合学习者的共同知识点平均分,使得相似度的计算更具客观性. 由于忽略了体现学习者学习情况的各种因素,导致相似度计算结果准确度欠佳. New-cosine[7 ] 引入权重方程,提升了学习成绩较好学习者的推荐权重,进而改进协同过滤算法. 学习者的学习情况各异,仅以成绩较好的学习者作为推荐标准,缺乏个性化,影响推荐效果. TRCF-LS-KL[8 ] 结合学习者学习风格、知识水平及信任模式对协同过滤算法进行改进. 仅通过问卷调查手段确定学习风格相对片面;由学习者指定被信任人的信任模式具有较大主观性. CF-SPM[9 ] 融合学习者的学习情况(学习对象得分)以及学习风格(学习某对象的时间、频率)改进协同过滤算法. 仅以学习时间和频率等个体差异较大的因素计算学习者的相似度时,存在较大偏差,客观性不足. Edurank[10 ] 联合协同过滤和社会选择理论,结合学习者以及相似学习群体的学习情况和认知水平改进协同过滤算法. 缺乏对学习者自身学习情况和学习风格等方面信息的挖掘,与个性化学习情况的结合程度较低.
由上述研究成果可知,忽略学习者在学习过程中展现的各种学习情况属性以及知识点之间的内在联系会明显地影响学习推荐模型的效果.因此,本文提出一种融合知识地图、度中心性以及协同过滤算法的个性化学习推荐模型(Learning Situation Based Personalized Learning Recommendation Model, LS-PLRM).在LS-PLRM中,一方面引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法,在此基础上构造一种基于学习情况的协同过滤算法;另一方面通过挖掘课程知识点之间的内在联系,构建课程知识地图. ...
A Recommender Model in E-learning Environment
2
2017
... (1)一些学者结合学习者学习情况等相关因素对传统的协同过滤算法做出改进,以期取得更好的学习推荐效果.Bobadilla等[7 ] 提出一种学习推荐算法New-cosine,该算法对每个学习者推荐的重要程度进行加权,提升学习成绩更好的学习者的推荐权重.Dwivedi等[8 ] 构建一个信任感知网络学习推荐系统TRCF-LS-KL,该系统结合学习者的学习风格、知识水平和不同学习者的信任度等方面对协同过滤算法进行改进.Bourkoukou等[9 ] 提出一种基于改进协同过滤算法和顺序模式挖掘的学习模型CF-SPM,该模型融合学习者的学习对象得分、学习时间和频率等以改进协同过滤算法,进而预测其他学习对象的得分,最后运用SPM算法对学习内容排序后进行推荐.Segal等[10 ] 提出联合协同过滤和社会选择理论的个性化学习推荐模型Edurank,通过协同过滤计算得到待推荐学生的相似学生集合,并根据相似学生集合在不同学习内容的答题情况,对学习内容进行难度排序,最后向学生推荐排序后的学习内容. ...
... Introduction of Classical Recommendation Model
Table 1 算法模型 优势 不足 Pearson-CF[15 ] 是经典的协同过滤算法,结合学习者的共同知识点平均分,使得相似度的计算更具客观性. 由于忽略了体现学习者学习情况的各种因素,导致相似度计算结果准确度欠佳. New-cosine[7 ] 引入权重方程,提升了学习成绩较好学习者的推荐权重,进而改进协同过滤算法. 学习者的学习情况各异,仅以成绩较好的学习者作为推荐标准,缺乏个性化,影响推荐效果. TRCF-LS-KL[8 ] 结合学习者学习风格、知识水平及信任模式对协同过滤算法进行改进. 仅通过问卷调查手段确定学习风格相对片面;由学习者指定被信任人的信任模式具有较大主观性. CF-SPM[9 ] 融合学习者的学习情况(学习对象得分)以及学习风格(学习某对象的时间、频率)改进协同过滤算法. 仅以学习时间和频率等个体差异较大的因素计算学习者的相似度时,存在较大偏差,客观性不足. Edurank[10 ] 联合协同过滤和社会选择理论,结合学习者以及相似学习群体的学习情况和认知水平改进协同过滤算法. 缺乏对学习者自身学习情况和学习风格等方面信息的挖掘,与个性化学习情况的结合程度较低.
由上述研究成果可知,忽略学习者在学习过程中展现的各种学习情况属性以及知识点之间的内在联系会明显地影响学习推荐模型的效果.因此,本文提出一种融合知识地图、度中心性以及协同过滤算法的个性化学习推荐模型(Learning Situation Based Personalized Learning Recommendation Model, LS-PLRM).在LS-PLRM中,一方面引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法,在此基础上构造一种基于学习情况的协同过滤算法;另一方面通过挖掘课程知识点之间的内在联系,构建课程知识地图. ...
A Difficulty Ranking Approach to Personalization in E-learning
2
2019
... (1)一些学者结合学习者学习情况等相关因素对传统的协同过滤算法做出改进,以期取得更好的学习推荐效果.Bobadilla等[7 ] 提出一种学习推荐算法New-cosine,该算法对每个学习者推荐的重要程度进行加权,提升学习成绩更好的学习者的推荐权重.Dwivedi等[8 ] 构建一个信任感知网络学习推荐系统TRCF-LS-KL,该系统结合学习者的学习风格、知识水平和不同学习者的信任度等方面对协同过滤算法进行改进.Bourkoukou等[9 ] 提出一种基于改进协同过滤算法和顺序模式挖掘的学习模型CF-SPM,该模型融合学习者的学习对象得分、学习时间和频率等以改进协同过滤算法,进而预测其他学习对象的得分,最后运用SPM算法对学习内容排序后进行推荐.Segal等[10 ] 提出联合协同过滤和社会选择理论的个性化学习推荐模型Edurank,通过协同过滤计算得到待推荐学生的相似学生集合,并根据相似学生集合在不同学习内容的答题情况,对学习内容进行难度排序,最后向学生推荐排序后的学习内容. ...
... Introduction of Classical Recommendation Model
Table 1 算法模型 优势 不足 Pearson-CF[15 ] 是经典的协同过滤算法,结合学习者的共同知识点平均分,使得相似度的计算更具客观性. 由于忽略了体现学习者学习情况的各种因素,导致相似度计算结果准确度欠佳. New-cosine[7 ] 引入权重方程,提升了学习成绩较好学习者的推荐权重,进而改进协同过滤算法. 学习者的学习情况各异,仅以成绩较好的学习者作为推荐标准,缺乏个性化,影响推荐效果. TRCF-LS-KL[8 ] 结合学习者学习风格、知识水平及信任模式对协同过滤算法进行改进. 仅通过问卷调查手段确定学习风格相对片面;由学习者指定被信任人的信任模式具有较大主观性. CF-SPM[9 ] 融合学习者的学习情况(学习对象得分)以及学习风格(学习某对象的时间、频率)改进协同过滤算法. 仅以学习时间和频率等个体差异较大的因素计算学习者的相似度时,存在较大偏差,客观性不足. Edurank[10 ] 联合协同过滤和社会选择理论,结合学习者以及相似学习群体的学习情况和认知水平改进协同过滤算法. 缺乏对学习者自身学习情况和学习风格等方面信息的挖掘,与个性化学习情况的结合程度较低.
由上述研究成果可知,忽略学习者在学习过程中展现的各种学习情况属性以及知识点之间的内在联系会明显地影响学习推荐模型的效果.因此,本文提出一种融合知识地图、度中心性以及协同过滤算法的个性化学习推荐模型(Learning Situation Based Personalized Learning Recommendation Model, LS-PLRM).在LS-PLRM中,一方面引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法,在此基础上构造一种基于学习情况的协同过滤算法;另一方面通过挖掘课程知识点之间的内在联系,构建课程知识地图. ...
Yotta: A Knowledge Map Centric E-Learning System
1
2010
... (2)基于知识地图的学习推荐方法.这类学习资源推荐模式以知识地图为支撑,基于课程内容之间的内在联系进行学习资源推荐.Zheng等[11 ] 构建一个以知识地图为中心的学习系统Yotta,根据课程的知识结构特点及其逻辑关系创建知识地图,建立学习资源与知识单元的联系,根据学习者在不同知识单元中的学习情况推荐合适的学习资源.Wang等[12 ] 提出一个基于知识地图的知识共享社区模型,该模型通过结合学习系统特性,基于知识地图引导学习者在社区中共享知识内容.李士平等[13 ] 提出使用颜色标记知识点及其之间的关系类型、协同共建资源、自动生成学习路径等促进自我导向学习的策略,论证了知识地图在自我导向学习中起到的积极促进作用.柯立秋[14 ] 提出一种基于知识地图的学习资源融合系统,该系统从知识元关联关系出发,结合学习资源相关标准,建立知识元与学习资源间的关联. ...
Acceptance of Knowledge Map Systems: An Empirical Examination of System Characteristics and Knowledge Map Systems Self-efficacy
1
2012
... (2)基于知识地图的学习推荐方法.这类学习资源推荐模式以知识地图为支撑,基于课程内容之间的内在联系进行学习资源推荐.Zheng等[11 ] 构建一个以知识地图为中心的学习系统Yotta,根据课程的知识结构特点及其逻辑关系创建知识地图,建立学习资源与知识单元的联系,根据学习者在不同知识单元中的学习情况推荐合适的学习资源.Wang等[12 ] 提出一个基于知识地图的知识共享社区模型,该模型通过结合学习系统特性,基于知识地图引导学习者在社区中共享知识内容.李士平等[13 ] 提出使用颜色标记知识点及其之间的关系类型、协同共建资源、自动生成学习路径等促进自我导向学习的策略,论证了知识地图在自我导向学习中起到的积极促进作用.柯立秋[14 ] 提出一种基于知识地图的学习资源融合系统,该系统从知识元关联关系出发,结合学习资源相关标准,建立知识元与学习资源间的关联. ...
基于知识地图的自我导向学习设计与实证研究
1
2016
... (2)基于知识地图的学习推荐方法.这类学习资源推荐模式以知识地图为支撑,基于课程内容之间的内在联系进行学习资源推荐.Zheng等[11 ] 构建一个以知识地图为中心的学习系统Yotta,根据课程的知识结构特点及其逻辑关系创建知识地图,建立学习资源与知识单元的联系,根据学习者在不同知识单元中的学习情况推荐合适的学习资源.Wang等[12 ] 提出一个基于知识地图的知识共享社区模型,该模型通过结合学习系统特性,基于知识地图引导学习者在社区中共享知识内容.李士平等[13 ] 提出使用颜色标记知识点及其之间的关系类型、协同共建资源、自动生成学习路径等促进自我导向学习的策略,论证了知识地图在自我导向学习中起到的积极促进作用.柯立秋[14 ] 提出一种基于知识地图的学习资源融合系统,该系统从知识元关联关系出发,结合学习资源相关标准,建立知识元与学习资源间的关联. ...
基于知识地图的自我导向学习设计与实证研究
1
2016
... (2)基于知识地图的学习推荐方法.这类学习资源推荐模式以知识地图为支撑,基于课程内容之间的内在联系进行学习资源推荐.Zheng等[11 ] 构建一个以知识地图为中心的学习系统Yotta,根据课程的知识结构特点及其逻辑关系创建知识地图,建立学习资源与知识单元的联系,根据学习者在不同知识单元中的学习情况推荐合适的学习资源.Wang等[12 ] 提出一个基于知识地图的知识共享社区模型,该模型通过结合学习系统特性,基于知识地图引导学习者在社区中共享知识内容.李士平等[13 ] 提出使用颜色标记知识点及其之间的关系类型、协同共建资源、自动生成学习路径等促进自我导向学习的策略,论证了知识地图在自我导向学习中起到的积极促进作用.柯立秋[14 ] 提出一种基于知识地图的学习资源融合系统,该系统从知识元关联关系出发,结合学习资源相关标准,建立知识元与学习资源间的关联. ...
基于知识地图的学习资源融合系统设计与实现
1
2018
... (2)基于知识地图的学习推荐方法.这类学习资源推荐模式以知识地图为支撑,基于课程内容之间的内在联系进行学习资源推荐.Zheng等[11 ] 构建一个以知识地图为中心的学习系统Yotta,根据课程的知识结构特点及其逻辑关系创建知识地图,建立学习资源与知识单元的联系,根据学习者在不同知识单元中的学习情况推荐合适的学习资源.Wang等[12 ] 提出一个基于知识地图的知识共享社区模型,该模型通过结合学习系统特性,基于知识地图引导学习者在社区中共享知识内容.李士平等[13 ] 提出使用颜色标记知识点及其之间的关系类型、协同共建资源、自动生成学习路径等促进自我导向学习的策略,论证了知识地图在自我导向学习中起到的积极促进作用.柯立秋[14 ] 提出一种基于知识地图的学习资源融合系统,该系统从知识元关联关系出发,结合学习资源相关标准,建立知识元与学习资源间的关联. ...
基于知识地图的学习资源融合系统设计与实现
1
2018
... (2)基于知识地图的学习推荐方法.这类学习资源推荐模式以知识地图为支撑,基于课程内容之间的内在联系进行学习资源推荐.Zheng等[11 ] 构建一个以知识地图为中心的学习系统Yotta,根据课程的知识结构特点及其逻辑关系创建知识地图,建立学习资源与知识单元的联系,根据学习者在不同知识单元中的学习情况推荐合适的学习资源.Wang等[12 ] 提出一个基于知识地图的知识共享社区模型,该模型通过结合学习系统特性,基于知识地图引导学习者在社区中共享知识内容.李士平等[13 ] 提出使用颜色标记知识点及其之间的关系类型、协同共建资源、自动生成学习路径等促进自我导向学习的策略,论证了知识地图在自我导向学习中起到的积极促进作用.柯立秋[14 ] 提出一种基于知识地图的学习资源融合系统,该系统从知识元关联关系出发,结合学习资源相关标准,建立知识元与学习资源间的关联. ...
协同过滤推荐算法综述
1
2009
... Introduction of Classical Recommendation Model
Table 1 算法模型 优势 不足 Pearson-CF[15 ] 是经典的协同过滤算法,结合学习者的共同知识点平均分,使得相似度的计算更具客观性. 由于忽略了体现学习者学习情况的各种因素,导致相似度计算结果准确度欠佳. New-cosine[7 ] 引入权重方程,提升了学习成绩较好学习者的推荐权重,进而改进协同过滤算法. 学习者的学习情况各异,仅以成绩较好的学习者作为推荐标准,缺乏个性化,影响推荐效果. TRCF-LS-KL[8 ] 结合学习者学习风格、知识水平及信任模式对协同过滤算法进行改进. 仅通过问卷调查手段确定学习风格相对片面;由学习者指定被信任人的信任模式具有较大主观性. CF-SPM[9 ] 融合学习者的学习情况(学习对象得分)以及学习风格(学习某对象的时间、频率)改进协同过滤算法. 仅以学习时间和频率等个体差异较大的因素计算学习者的相似度时,存在较大偏差,客观性不足. Edurank[10 ] 联合协同过滤和社会选择理论,结合学习者以及相似学习群体的学习情况和认知水平改进协同过滤算法. 缺乏对学习者自身学习情况和学习风格等方面信息的挖掘,与个性化学习情况的结合程度较低.
由上述研究成果可知,忽略学习者在学习过程中展现的各种学习情况属性以及知识点之间的内在联系会明显地影响学习推荐模型的效果.因此,本文提出一种融合知识地图、度中心性以及协同过滤算法的个性化学习推荐模型(Learning Situation Based Personalized Learning Recommendation Model, LS-PLRM).在LS-PLRM中,一方面引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法,在此基础上构造一种基于学习情况的协同过滤算法;另一方面通过挖掘课程知识点之间的内在联系,构建课程知识地图. ...
协同过滤推荐算法综述
1
2009
... Introduction of Classical Recommendation Model
Table 1 算法模型 优势 不足 Pearson-CF[15 ] 是经典的协同过滤算法,结合学习者的共同知识点平均分,使得相似度的计算更具客观性. 由于忽略了体现学习者学习情况的各种因素,导致相似度计算结果准确度欠佳. New-cosine[7 ] 引入权重方程,提升了学习成绩较好学习者的推荐权重,进而改进协同过滤算法. 学习者的学习情况各异,仅以成绩较好的学习者作为推荐标准,缺乏个性化,影响推荐效果. TRCF-LS-KL[8 ] 结合学习者学习风格、知识水平及信任模式对协同过滤算法进行改进. 仅通过问卷调查手段确定学习风格相对片面;由学习者指定被信任人的信任模式具有较大主观性. CF-SPM[9 ] 融合学习者的学习情况(学习对象得分)以及学习风格(学习某对象的时间、频率)改进协同过滤算法. 仅以学习时间和频率等个体差异较大的因素计算学习者的相似度时,存在较大偏差,客观性不足. Edurank[10 ] 联合协同过滤和社会选择理论,结合学习者以及相似学习群体的学习情况和认知水平改进协同过滤算法. 缺乏对学习者自身学习情况和学习风格等方面信息的挖掘,与个性化学习情况的结合程度较低.
由上述研究成果可知,忽略学习者在学习过程中展现的各种学习情况属性以及知识点之间的内在联系会明显地影响学习推荐模型的效果.因此,本文提出一种融合知识地图、度中心性以及协同过滤算法的个性化学习推荐模型(Learning Situation Based Personalized Learning Recommendation Model, LS-PLRM).在LS-PLRM中,一方面引入知识点掌握程度相似性因子、平均分相似性因子和知识点难度系数修正因子,设计一种基于学习情况的相似度计算方法,在此基础上构造一种基于学习情况的协同过滤算法;另一方面通过挖掘课程知识点之间的内在联系,构建课程知识地图. ...
Knowledge Map of Information Science
1
2007
... 知识地图(Knowledge Map)[16 ] 是一个有向无环图,是一种知识编码方法[17 ] ,展示和解释了“关于知识的知识”[18 ] .本文将知识地图应用于具体课程,分析课程领域内章、节、知识点间的内在逻辑关系,构建网络化的知识结构图. ...
知识学习与技术创新
1
2016
... 知识地图(Knowledge Map)[16 ] 是一个有向无环图,是一种知识编码方法[17 ] ,展示和解释了“关于知识的知识”[18 ] .本文将知识地图应用于具体课程,分析课程领域内章、节、知识点间的内在逻辑关系,构建网络化的知识结构图. ...
知识学习与技术创新
1
2016
... 知识地图(Knowledge Map)[16 ] 是一个有向无环图,是一种知识编码方法[17 ] ,展示和解释了“关于知识的知识”[18 ] .本文将知识地图应用于具体课程,分析课程领域内章、节、知识点间的内在逻辑关系,构建网络化的知识结构图. ...
知识教学的突破: 从知识到知识的知识
1
2016
... 知识地图(Knowledge Map)[16 ] 是一个有向无环图,是一种知识编码方法[17 ] ,展示和解释了“关于知识的知识”[18 ] .本文将知识地图应用于具体课程,分析课程领域内章、节、知识点间的内在逻辑关系,构建网络化的知识结构图. ...
知识教学的突破: 从知识到知识的知识
1
2016
... 知识地图(Knowledge Map)[16 ] 是一个有向无环图,是一种知识编码方法[17 ] ,展示和解释了“关于知识的知识”[18 ] .本文将知识地图应用于具体课程,分析课程领域内章、节、知识点间的内在逻辑关系,构建网络化的知识结构图. ...
A Graph-theoretic Perspective on Centrality
1
2006
... 度中心性(Degree Centrality)用于描述节点在网络结构中的重要程度.一个节点的邻居数目越多,其重要程度就越高[19 ] .应用于学习推荐领域,度中心性可以衡量一个知识点在课程知识地图的重要程度:度中心性大的知识点一般处于课程知识地图的中心;而度中心性小的知识点一般处于课程知识地图的边缘位置.在知识地图中,知识点隶属于知识模块,为简化计算,可将隶属于同一知识模块的所有知识点的重要程度看作是相同的,因此它们的度中心性也相同.基于同样假设,可将知识点的度中心性等同于所在知识模块的度中心性.某知识模块 m i C D ( m i )
Efficient K-Nearest Neighbor Graph Construction for Generic Similarity Measures
1
2011
... K近邻(K-Nearest Neighbor)算法的基本思想[20 ] 是:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)样本中的大多数属于某一个类别,则推断该样本也属于这个类别. ...
E-Learning Personalization Based on Hybrid Recommendation Strategy and Learning Style Identification
1
2011
... 分别通过准确率(precision)、召回率(recall)和F值评价推荐知识点的准确性,通过平均绝对误差(MAE)[21 ] 衡量知识点预测得分与实际得分的接近程度.各指标的计算方法如公式(11)-公式(14)所示. ...
Using the Student’s T-test with Extremely Small Sample Sizes
1
2013
... 为进一步分析4组学生经过不同推荐模型学习之后的差异性,采用数据分析工具SPSS对第二次测试作特别适用于小样本规模的T检验分析[22 ] .由于实验需要,各组人数需保持一致,因此在B组随机减少一名学生.分组样本统计如表7 所示,分组成对样本检验如表8 所示.可知各组应用不同模型进行学习之后,D组较其他组的测试得分均值更高,表明LS-PLRM的推荐效果更佳;标准差和均值的标准误差更低,表明经过LS-PLRM学习的学生群体成绩更加均衡,分离度较小. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}