Matching Strategies for Institution Names in Literature Database
Sun Haixia1,2, Wang Lei2, Wu Yingjie2, Hua Weina1, Li Junlian2()
1School of Information Management, Nanjing University, Nanjing 210093, China 2Institute of Medical Information, Chinese Academy of Medical Sciences, Beijing 100020, China
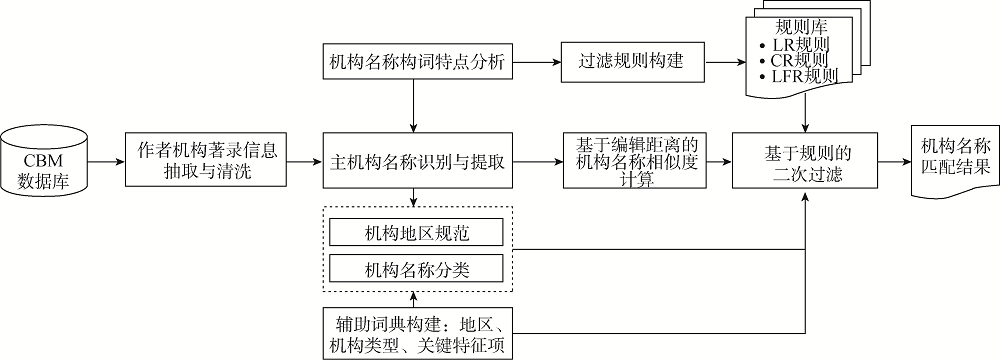
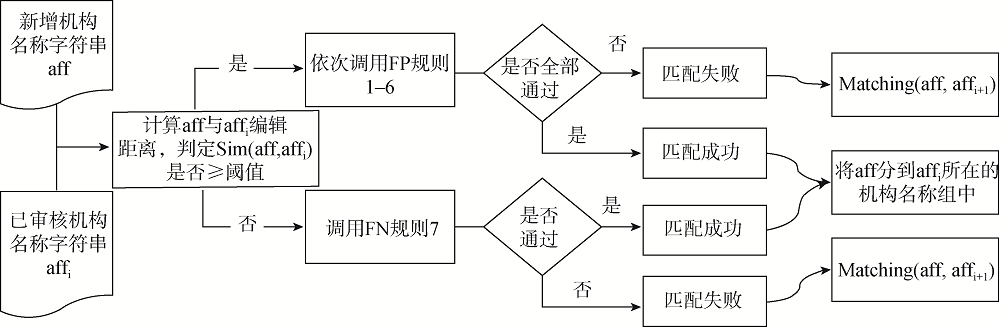
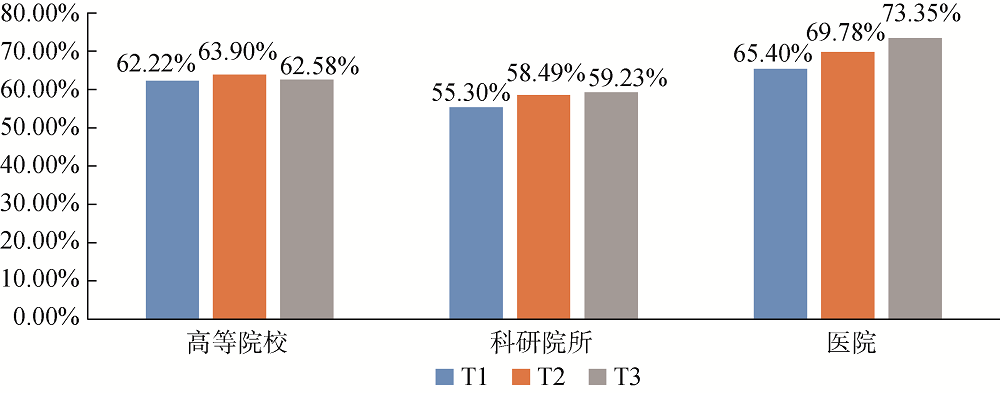
[Objective] This paper designs and implements matching strategies for institution names in literature database, aiming to regulate their storage and management. [Methods] We first established seven name matching rules based on their regions, types and naming characteristics. Then, we designed four hybrid matching strategies combining rules and Levenstein distance. Finally, we evaluated the four hybrid strategies with institution names from the papers indexed by Chinese Biomedical Literature (CBM) database during 2006-2011. [Results] More than six million affiliation strings from CBM were matched, which included higher education institutions, hospitals and research institutes. We found that the hybrid matching strategy based on region, naming characteristics and Levenstein distance obtained the highest precision (all above 80%), recall (64.82%), and F-value (71.66%). [Limitations] The rules and related dictionary were mainly constructed with human experience and their coverage is limited. There are some errors in the identifying institution names. The proposed strategy cannot address the issues caused by the transformative actions of institutions. [Conclusions] The proposed strategies could improve the performance of scientific research literature databases.
Khalid M A, Jijkoun V, De Rijke M.The Impact of Named Entity Normalization on Information Retrieval for Question Answering[C]//Proceeding of the IR Research, 30th European Conference on Advances in Information Retrieval,Glasgow, UK. Berlin, Heidelberg: Springer-Verlag, 2008: 705-710.
(Tang Jinling.Study on Issues of Author Affiliations on Papers Included in International Three Key Retrieval Systems: Case Study of Name of University[J]. Information Research, 2014(9): 80-84.)
doi: 10.3969/j.issn.1005-8095.2014.09.021
(Su Xinning.Report on Academic Influence in Library, Information and Documentation Science (2000-2004)[J]. Journal of the China Society for Scientific and Technical Information, 2006, 25(2): 131-153.)
doi: 10.3969/j.issn.1000-0135.2006.02.001
(Zeng Jianxun, Wang Lixue.Construction of Knowledge Evaluation-oriented Authority Files[J]. Library and Information Service, 2012, 56(10): 101-106.)
[5]
Abramo G, D’Angelo C A, Pugini F. The Measurement of Italian Universities’ Research Productivity by a Non Parametric-Bibliometric Methodology[J]. Scientometrics, 2008, 76(2): 225-244.
doi: 10.1007/s11192-007-1942-2
[6]
French J C, Powell A L, Schulman E.Automating the Construction of Authority Files in Digital Libraries: A Case Study[C]//Proceedings of International Conference on Theory and Practice of Digital Libraries.Berlin,Heidelberg: Springer, 1997: 55-71.
[7]
Liu W L, Doğan R I, Sun K, et al.Author Name Disambiguation for PubMed[J]. Journal of the Association for Information Science and Technology, 2014, 65(4): 765-781.
doi: 10.1002/asi.23063
(Sun Haixia, Li Junlian.Construction of Authority File of Author Affiliations[J]. Journal of Medical Informatics, 2015, 36(11): 42-47.)
doi: 10.3969/j.issn.1673-6036.2015.11.010
(Chen Jinxing, Zhu Zhongming.Research Progress of the Name Authority Control for the Contributor[J]. New Technology of Library and Information Service, 2009(12): 12-17.)
[10]
Jonnalagadda S R, Topham P.NEMO: Extraction and Normalization of Organization Names from PubMed Affiliation String[J]. Journal of Biomedical Discovery and Collaboration, 2010, 5(1): 50-75.
doi: 10.1186/1747-5333-2-2
pmid: 2990275
[11]
Jiang Y, Zheng H T, Wang X, et al.Affiliation Disambiguation for Constructing Semantic Digital Libraries[J]. Journal of the American Society for Information Science and Technology, 2011, 62(6): 1029-1041.
doi: 10.1002/asi.21538
[12]
Torvik V I, Weeber M, Swanson D R, et al.A Probabilistic Similarity Metric for Medline Records: A Model for Author Name Disambiguation[J]. Journal of the American Society for Information Science and Technology, 2005, 56(2): 140-158.
doi: 10.1002/asi.20105
pmid: 14728536
[13]
Cuxac P, Lamirel J C, Bonvallot V.Efficient Supervised and Semi-Supervised Approaches for Affiliations Disambiguation[J]. Scientometrics, 2013, 97(1): 47-58.
doi: 10.1007/s11192-013-1025-5
[14]
French J C, Powell A L, Schulman E.Using Clustering Strategies for Creating Authority Files[J]. Journal of the American Society for Information Science, 2000, 51(8): 774-786.
doi: 10.1002/(ISSN)1097-4571
[15]
Huang S, Yang B, Yan S, et al.Institution Name Disambiguation for Research Assessment[J]. Scientometrics, 2014, 99(3): 823-838.
doi: 10.1007/s11192-013-1214-2
(Sun Haixia, Cheng Ying.Study on String-based Matching of Information Intergration[J]. New Technology of Library and Information Service, 2007(7): 22-26.)
[17]
Jacob F, Javed F, Zhao M, et al.sCooL: A System for Academic Institution Name Normalization[C]//Proceeding of 2014 International Conference on Collaboration Technologies & Systems.IEEE, 2014: 86-93.
[18]
Bollegala D, Ishizuka M, Matsuo Y.Measuring Ssemantic Similarity Between Words Using Web Search Engines[C]// Proceeding of the 14th International Conference on World Wide Web. 2007: 757-766.
[19]
Aumüller D, Rahm E.Web-based Affiliation Matching[C]// Proceeding of International Conference on Information Quality. DBLP, 2009: 246-256.
(Yang Bo, Yang Junwei, Yan Sulan.Research on Rule-based Normalization of Institution Name[J]. New Technology of Library and Information Service, 2015(6): 57-63.)
[21]
Onodera N, Iwasawa M, Midorikawa N, et al.A Method for Eliminating Articles by Homonymous Authors from the Large Number of Articles Retrieved by Author Search[J]. Journal of the American Society for Information Science and Technology, 2011, 62(4): 677-690.
doi: 10.1002/asi.v62.4
(Zhang Xiaoheng, Wang Lingling.Identification and Analysis of Chinese Organization and Institution Names[J]. Journal of Chinese Information Processing, 1997, 11(4): 21-32.)