1(National Science Library, Chinese Academy of Sciences, Beijing 100190, China) 2(Department of Library, Information and Archives Management, School of Economics and Management, University of Chinese Academy of Sciences, Beijing 100190, China)
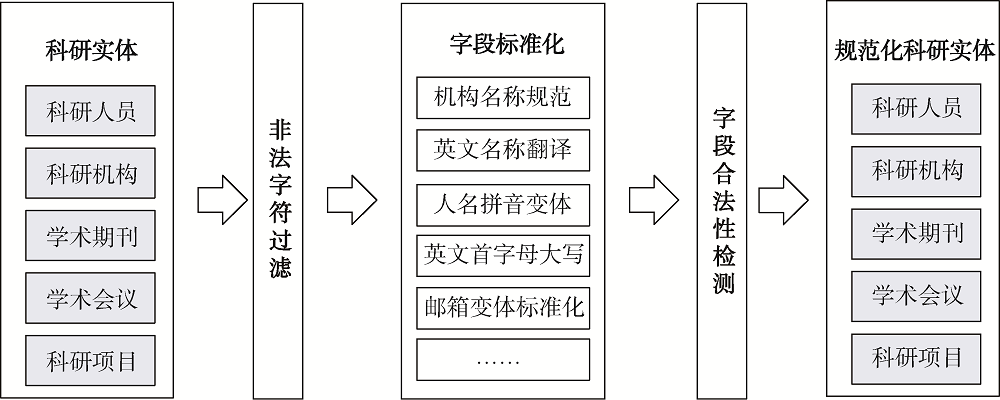
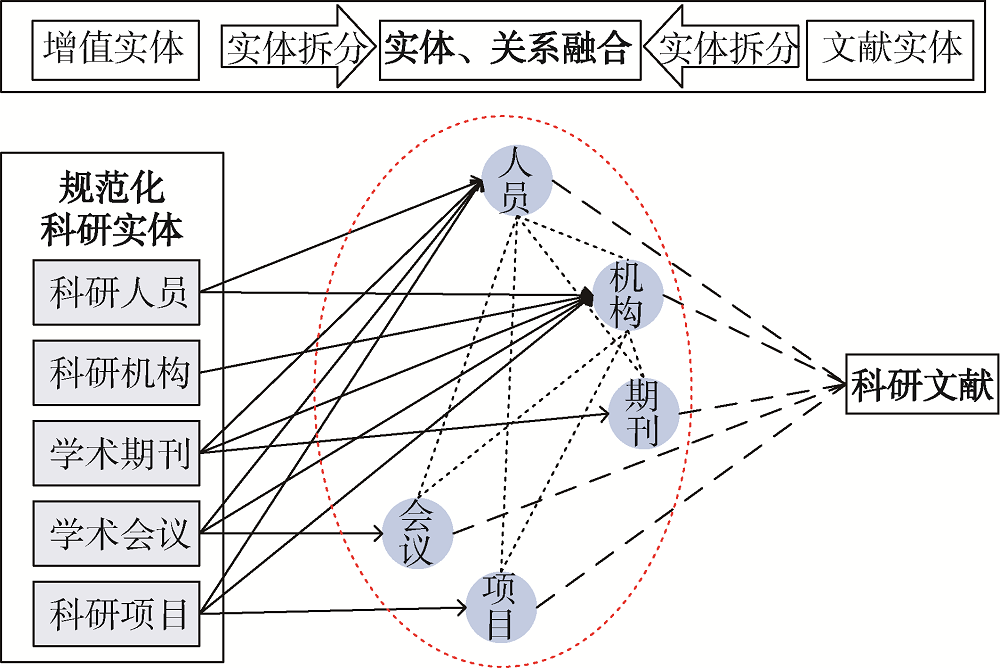
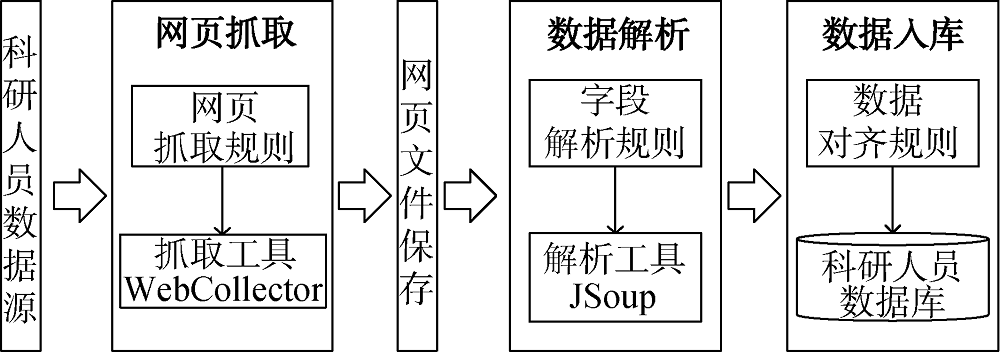
[Objective] This paper tries to address the issues facing sci-tech big data, such as source dispersal, low quality, and poor content. [Methods] We used value-added computing methods, such as data cleansing, entity alignment, entity field fusion, conflict detection, etc., to develop tools for the enrichment of sci-tech big data. [Results] The developed tools achieved entity data alignment at the levels of personnel, organization, conference, journal and relationship among them. The contents of the entity fields were increased by 5 to 10 times, and the entity analysis dimension was increased by 2 to 3 times. [Limitations] The timeliness and standardization of value-added data need to be optimized and improved based on service needs. [Conclusions] The proposed methods and tools enhance the knowledge discovery of the sci-tech big data and intelligent information analysis systems.
( Ni Fang, Zeng Hui, Zhuo Hui , et al. Research on Application of Web Services in Multi-Source Heterogeneous Data Integration on Agriculture[J]. Computer Technology and Development, 2016,26(8):129-133.)
( Lu Baichuan, Shu Qin, Ma Guanglu . Short-term Traffic Flow Forecasting Based on Multi-source Traffic Data Fusion[J]. Journal of Chongqing Jiaotong University: Natural Science, 2019,38(5):13-19, 56.)
( Zhang Weidong, Zuo Na, Lu Lu . Knowledge Fusion System Architecture Design of Government Website Information Resources[J]. Library and Information Service, 2018,62(17):112-119.)
( Cheng Xiufeng, Wang Xuejie, Xia Lixin . Investigation on Value-added Service in Research Data Management Systems[J]. Information Science, 2018,36(10):77-83.)
( Yu Qianqian, Zhang Jianyong . Practices of NSTL Integrating and Using Third-party Metadata[J]. New Technology of Library and Information Service, 2016(1):97-102.)
[6]
田磊 . 主题爬虫搜索策略的设计与实现[D]. 北京: 北京邮电大学, 2017.
[6]
( Tian Lei . Research and Implementation of Focused Crawler with Search Strategy[D]. Beijing: Beijing University of Posts and Telecommunications, 2017.)
( Wang Ying, Wu Zhenxin, Xie Jing . Review on Semantic Retrieval System for Scientific Literature[J]. New Technology of Library and Information Service, 2015(5):1-7.)
( Sun Haixia, Wang Lei, Wu Yingjie , et al. Matching Strategies for Institution Names in Literature Database[J]. Data Analysis and Knowledge Discovery, 2018,2(8):88-97.)
( Liu Kun, Li Chunli, Bai Fuchun . Biobiometric Study on the Name Authority Literatures in Library and Information Field in China[J]. Library Work and Study, 2017(12):66-71.)
( Meng Xiaofeng, Du Zhijuan . Research on the Big Data Fusion: Issues and Challenges[J]. Journal of Computer Research and Development, 2016,53(2):231-246.)
doi: 10.7544/issn1000-1239.2016.20150874
[11]
Zhu Z, Zhang D, Li L , et al. Developing Institutional Repositories Network: Taking IR Grid at Chinese Academy of Sciences as an Example[J]. Chinese Journal of Library and Information Science, 2011,4(Z1):24-34.
( Zhang Jianyong, Huang Yongwen, Yu Qianqian , et al. Design and Implementation of ORCID China Service ‘iAuthor’[J]. New Technology of Library and Information Service, 2015(3):84-91.)
[13]
Vidal-Infer A, Tarazona B, Alonso-Arroyo A , et al. Public Availability of Research Data in Dentistry Journals Indexed in Journal Citation Reports[J]. Clinical Oral Investigations, 2018,22(1):275-280.
( Zhang Lujie . Research on the Quality Controlment of Peer Review About NSFC Project Set-up[D]. Beijing: University of Science and Technology Beijing, 2015.)
( Zhang Lin, Qin Ce, Ye Wenhao . Automatic Recognition of Legal Language Entities Based on Conditional Random Fields[J]. Data Analysis and Knowledge Discovery, 2017,1(11):46-52.)