{kind=link}
{kind=link}
基于加权XML模型的XML数据与DTD模式匹配
[李树青 , 程国达, 王维民]
, 程国达, 王维民]
, 程国达, 王维民]
|
|


首先说明利用加权XML数据模型分别得到标准XML参考实例和XML数据实例的方法,并对DTD约束修饰符的表达方法进行介绍。其次,详细阐述相似度算法的实现方法,重点说明在XML数据实例中寻找与标准XML参考实例的匹配节点算法和计算标准XML参考实例与XML数据实例的相似度算法。最后,对相关实验及其结论进行总结。
This paper first introduces standard XML reference instants and XML data instants based on the weighted XML data model. Then it displays the expression ways of constraints in DTD. Furthermore, the paper also shows the approaches on how to implement similarity algorithm,with an emphasis on how to find out a matching node with standard XML reference instants and to get the similarity algorithm of standard XML reference instants and that of XML data instants.
XML数据具有事先定义好的文法规则(Grammar),包含DTD(Document Type Definition)和Schema两种主要形式。这些内容都可以定义对应XML数据中的元素和属性,并且对它们之间的结构关系也可以做详细的规定。和传统的关系型数据库一样,XML文法规则对于XML文档验证、索引和检索来说都具有重要的辅助作用[ 1]。
其中,DTD是一种较为简单有效的XML数据模式定义方法。它有两方面的作用:
(1)提供一种约束XML数据结构特征的强制手段,通过检查DTD中的模式定义,系统可以检测已有的XML数据是否规范,并对不符合要求的XML数据给出具体的错误信息。它的相关应用很常见,如各种XML数据编辑器等。
(2)利用DTD作为一种并不严格的建议标准,推荐不同的XML数据符合它的定义要求,但是如果XML数据不符合,系统也并不会给出错误信息,而是认为该XML数据在一定程度上不符合DTD的规范定义。事实上,在各种商业数据交换领域中,由于难以对不同的参与者进行有效的强制约束,所以即便是在特定领域中人们已经制定了相关的DTD规范,也难以确保所有的相关XML数据都能够严格符合DTD的要求。但由于数据交换的需要,此时亟需一种手段来对这些格式并不十分严谨但却在很大程度上遵守DTD模式要求的不同XML数据进行相似度匹配。这种问题也被称为XML数据的模式匹配(Schema Matching)。
与此相关的应用领域有很多,如根据DTD模式对XML数据进行分类,在XML文档聚类时抽取结构特征构造新的DTD,基于结构特征信息进行XML数据检索,对XML文档的定题情报服务(Selective Dissemination of XML Documents)等。同时,该项研究有助于很多数据库领域的应用实现,如在数据仓库中将不同格式的XML数据映射成统一的模式,或者在数据库系统中利用已有的DTD模式对XML数据进行结构性验证[ 2]。
从概念上说,一般而言,DTD模式通过约束关系定义了一组相互连接的XML元素、子元素和属性,而XML数据与DTD模式的相似度匹配可以表达为一个函数,该函数接受XML数据与DTD模式这两个参数,返回一个用于表征相似程度的度量值[ 3]。
通常人们把某个特定应用领域中被大家认可的标准XML数据交换格式称为领域模式(Domain Schema),而把某个参与组织所发布的特定XML数据格式称为源模式(Source Schema)。
在现有的研究领域中,大量的研究工作主要集中于XML文档之间的相似度计算,对于XML数据及其DTD模式之间的相似度研究却不多见[ 2]。较早开展的相关研究主要集中在关系型数据模型和ER模型等领域[ 4],随后的相关研究主要集中于比较不同源模式之间的相似度[ 5]。近年来,随着XML数据应用的快速发展,XML模式匹配问题受到人们的广泛关注[ 2]。
从总体来看,计算XML数据与DTD模式之间的相似度,可以采取两种不同的方法:
(1)将DTD看成是XML数据结构的抽象,该种方法可以被称为外延方法(Extensible Approach),此时取出一个需要比较的XML数据实例,并计算与其他XML数据实例的相似度,最后可以将全部计算结果中最大的相似度值作为最终的相似度。这种方法的好处在于可以利用现有的XML数据相似度计算方法来进行。
(2)将DTD看成是约束XML数据的一组规则集合,该种方法可被称为内涵方法(Intensional Approach)。该方法需要利用每个XML数据与DTD模式进行相似度的比较计算。和前一个方法相比,该方法计算量要小得多,但是需要人们研究和设计一种有效的模式匹配方法[ 4]。本文的研究也采取了这个思路。
(1)基于树编辑距离的匹配方法
传统的模式比较方法主要采用基于树编辑距离(Tree Edit Distance)的方法。在各种以数据为中心(Data-Centric)的XML数据组织模式中,由于数据结构较为严谨,便于数据交换和机器自动化处理,所以基于树编辑距离的方法适合处理该种类型的XML数据[ 6]。
Nierman和Jagadish等人的方法是一种提出较早并且具有较高准确度的方法,特别是在判断部分XML文档内容即XML文档子树相似度方面效果较好[ 7]。对于算法性能而言,该方法具有和一般编辑距离方法相同的时间复杂度。后来的很多学者据此也提出了许多改进算法,如有的学者利用该方法进行XML文档聚类的研究工作[ 8];还有学者将XML文档和DTD结构都表示成有向标签树结构,并忽略所有属性元素,同时综合考虑各种DTD限制修饰符的作用,并利用基于编辑距离的方法提出了一种新的相似度测度方法[ 9]。
BiBranch方法通过一个整数值来描述两者比较模式的差异度,该整数值越小,则相似度越大[ 10]。然而,该方法也存在很多问题。如BiBranch方法考虑了节点次序,而事实上在XML检索中往往关注是否命中节点本身,对位于同一节点下的直接下级节点往往并不在意它们之间的相互次序。再如BiBranch方法由于采用编辑距离的操作方法,单纯以节点编辑操作数量为差异度的衡量标准,没有很好地区分丢失节点和增加节点两者的差异。有学者据此提出一种新的模式相似度比较方法(Source Schemas against a Domain,SSD),该方法侧重于覆盖面的比较,认为两个模式如果存在更多相同的元素,则相似度更大。同时,该方法考虑节点关系的影响程度,其中忽略同级节点元素的次序关系,对那些对结构关系没有影响的冗余节点也予以忽略[ 5]。
纵观上述研究,这些利用树编辑距离的方法往往具有较高的算法复杂度,而且每种方法都是适应不同应用系统的要求而提出的,缺乏通用性的特点。
(2)基于机器学习的匹配方法
这些方法往往结合使用多种匹配器(Matcher),每种匹配器都采用一种有效的独立方法。在实际使用中,人们可以根据需要灵活调整这些匹配器的组合,来构造更为有效的复合方法。
如一种较早提出的XML模式匹配方法就是学习源描述法(Learning Source Description,LSD),它主要使用机器学习的方法来半自动化发现不同模式之间的映射关系,据此计算它们之间的相似度。它需要两个处理阶段:
①训练阶段,此时系统要求用户提供反映模式映射关系的数据源样本集合,并以此得到训练学习规则;
②映射阶段,利用不同的学习规则可以得到不同种类的相似度测度值,如名称匹配器(Name Matcher)主要根据元素属性的文本内容来计算相似度等[ 11]。
然而,该方法需要大量的人工操作,特别是在样本训练阶段。后续研究学者提出了很多新方法,无需预处理和复杂的机器学习过程,这些方法主要采用基于图论的一些模式匹配算法。如有学者提出一种基于句法的DTD文档相似度判断方法,将整个DTD结构看成一个有向无环根树(Rooted Directed Acyclic Graph),采用自下而上的方法:首先根据叶节点的名称来判断它们的相似度,然后计算上层中间节点的相似度,对于它们相似度的计算而言,主要是利用这些节点所含有的下级子图结构相似度来进行[ 12]。
还有学者通过定义几种能够捕获不同DTD模式之间差异度的操作方法,并利用一种基于启发式功能的成本估算方法从中选择最优的操作步骤。对于每个源DTD中的节点,该算法会在目标DTD中相同节点层次和更低的节点层次中发现候选的匹配模式。但是该方法存在两个局限性:有些转换操作不能很好地适应一些较为模糊的数据结构;该方法没有很好地结合语义信息来提高其匹配精度[ 12]。
相反,另外一些学者就指出如果能够充分利用这些语义信息,就可以改善匹配精度,并减少结果中的不一致现象[ 13]。
(3)基于语义分析的方法
在XML模式相似度研究领域,还有一个研究分支侧重于对XML数据元素的信息内容进行分析。传统的内容方法一般都是将节点内容看成是字符串类型,然而事实上随着XML所能表达的数据内容越来越丰富,人们逐渐需要给不同的节点内容指定不同的数据类型,如数值型和布尔型等。类型不一样,所对应的相似度计算方法也不一样。这种XML模式相似度可以被称为XML文法相似度[ 1]。
有学者利用通用语义模型(Universal Semantic Model)来表达XML的模式和进行不同模式的相似度计算。该语义模型主要由三部分组成,分别是本体类别(Ontological Categories)、属性(Properties)和上下文限制(Contextual Constraints)[ 14]。还有学者利用组合方法计算XML模式的相似度,该方法结合考虑了两种成分:通过最小共同类型计算得到的最大信息量;类型的声明信息[ 15]。还有学者提出了7条简化原则来将XML模式转化为可以存储相同信息和叶节点基数限制特征的最精简结构[ 16]。
一些学者不再考虑简单的DTD模式,而是考虑约束内容更为丰富的Schema模式。有人提出需要对复杂数据类型和自定义数据类型进行考虑,但是没有给出具体的处理方法[ 13]。还有学者却提出应当忽略这些复杂数据类型和用户自定义数据类型[ 17]。同时,上述学者都没有过多考虑诸如ALL和OR等Schema操作符的处理方法及其对相似度计算的影响。
在更近的研究中,有学者对Schema模式中的复杂数据类型进行研究,提出类型层次树(Type Hierarchy)的概念,即利用扩散限制关系将不同类型组织成一个完整的层次结构。对于两个复杂元素的相似度比较而言,测度主要利用类型层次树和元素的结构相似度,根据数据类型的名称来得到语义相似度。但是作者并没有将此方法扩展到完整的Schema模式匹配计算过程中[ 15]。
值得注意的是,在这些已有的研究文献中,很多学者都对标准的DTD模式标准进行了适应性的修改,如为了有效地实现相似度计算,很多学者对一些常见的DTD规则进行简化,去除对规定是否可以存在的“?”修饰符和规定可以重复出现的“+”修饰符等的考虑;有的学者所考虑的XML文法都较简单,往往忽略对重复元素(Cardinality)和可选元素(Alternativeness)的约束处理。不同方法的性能具有很大的差异,对于如何有效衡量不同算法的有效性,有学者提出检验XML模式匹配算法有效性的一个简单标准就是根据任务中所需的人工处理工作量大小[ 18]。
本文所提出的方法没有沿用上述传统模式,而是首先对标准DTD模式,即XML领域模式,定义一个XML标准参考实例,其中的每一个节点都被分配一个权值,对该值的分配采取权值扩散的策略和引入约束操作符的限制,并且利用这种节点权值来表达各种结构特征和约束信息,将这个XML标准参考实例称为标准XML参考实例,同时把各种XML源模式实例称为XML数据实例。利用标准XML参考实例作为与其他XML数据实例进行比较的依据,并以比较结果作为XML数据实例与DTD模式的相似度匹配结果。
(1) 简单标准XML参考实例的定义方法
为说明方便,先给出一个DTD模式,注意它的所有节点都有Weight权值属性,如图1所示:
(a)DTD模式定义代码 (b)DTD模式的树状视图
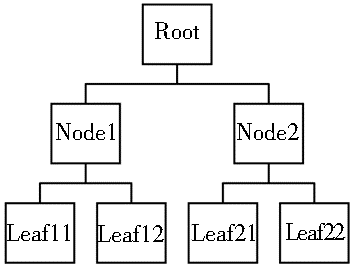 | 图1 一个DTD模式样例 |
对于节点权值的分配方法,可以采取以下步骤:
①给每个叶节点分配一个数值为1的权值。
②采取自下而上的扩散策略,非叶节点的权值为所有直接子节点的权值之和。
具体表述如下:
weightNodei=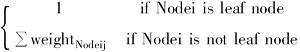
在公式(1)中,节点Nodeij为当前节点Nodei包含的所有直接下级一层节点。以下公式中的定义与此相同,将不再说明。
据此,可以得到图1中DTD模式的标准XML参考实例,如例1所示:
例1:
(2) 带有约束修饰符的标准XML参考实例定义方法
除了节点说明信息外,DTD模式通常还会对节点元素定义多种约束修饰符,其中重要的修饰符有如下5种:“?”、“*”、“+”、“|”和“,”。其中,“?”表示所修饰节点元素可以出现0次或者1次,“*”表示所修饰节点元素出现次数大于或等于0次,“+”表示所修饰节点元素出现次数大于或等于1次,“|”表示当前节点的下级节点元素只能并必须有一个元素出现,“,”表示所分隔的每个节点构成一个完整的序列。
值得注意的是,对于约束修饰符,由于主要用于限制XML数据实例的节点出现次数,所以难以通过权值分配在标准XML参考实例中加以体现。相反,应该在与标准DTD结构比较的XML数据实例中予以体现。因此,除“|”和“,”外,对于其他约束修饰符在此都不予考虑,得到标准XML参考实例。
对于“|”修饰符的多个节点元素,只能有一个出现在XML数据实例中,所以在标准XML参考实例中,利用这些供选择节点的平均权值作为扩散权值,具体计算如下:
weightNodei=avg(weightNodeij)(2)
对于“,”修饰符的多个节点元素,前文已经说明过,将采用所有相关节点的权值之和作为其上级非叶节点的权值,在此不再赘述。
(1) 简单XML数据实例的定义方法
假设有XML数据实例如例2所示:
例2:
该XML数据实例并不完全对应如图1所示的标准DTD结构,它有以下几个特点:
①XML数据实例与DTD模式的结构性差异可以通过节点权值的差异体现出来,而且权值的差异在一定程度能够反映结构的差异程度。
②该种权值可以表示节点层次结构对相似度的影响程度,一般而言,层次越高的节点影响程度越大。事实上,在该种XML数据实例中,层次越高的节点往往具有越高的权值,因此在相似度计算时将会产生更为明显的作用。
(2) 带有约束修饰的XML数据实例定义方法
前文已经说明了几种约束修饰符的表达方法,下面重点介绍一下其他DTD约束修饰符在XML数据实例中的表达方法:
① “?”表示方法
从概念上看,虽然此修饰符表示所修饰元素最多只能出现1次,但是该元素也可以不存在。因此,只有XML数据实例中具有超过一个的相应节点元素,才会被认为不规范。为了表达这种限制,可以在XML数据实例的权值扩散中,对出现多次的节点元素,将其所有子节点的权值之和扩散到当前节点中。显然,当前节点包含的子节点重复次数越多,则当前节点的权值与标准XML参考实例的权值差异就会越大。具体计算如下:
weightNodei=
②“*”表示方法
从概念上看,该修饰符的约束能力近似于“?”,只是在最多出现次数上没有限制,约束力更为宽松。简单的处理方法可以不考虑此修饰符的影响,采用忽略的方法。然而,在各种实际应用中,对于此修饰符所修饰的元素,由于不同的XML数据实例往往具有较多重复次数的元素值,而且元素值差异较大,所以有必要在权值设计上反映这种差异。采取的方法是对出现多次的节点元素,只将其最小权值扩散到上级节点中。之所以选择最小值,主要是以此来反映它与标准DTD模式结构的相同性。具体计算如下:
weightNodei=min(weightNodeij)(4)
③“+”表示方法
由于该修饰符要求所修饰元素至少要出现一次。因此,只有当XML数据实例不存在该节点时,才会代表一种不规范的特征。事实上,这种差异完全可以通过节点权值得以体现,如果XML数据实例相应节点没有子节点,则当前节点无法获得扩散过来的权值。同时,在后文的相似度计算方法中,还会进一步考虑到这种节点丢失产生的结构差异度。因此,本文没有考虑此种约束修饰符对权值扩散的直接影响。
大多数情况下不必考虑节点和属性等元素的先后次序[ 1],所以本文对此问题没有考虑。
利用上述方法得到标准XML参考实例与待比较的XML数据实例,可以进一步计算两者的相似度。为此需要解决两个问题:
(1)在XML数据实例中寻找与标准XML参考实例的匹配节点;
(2)计算标准XML参考实例与XML数据实例的相似度。
XML数据实例是通过采用不同的权值扩散策略来体现不同约束修饰符的约束能力。为此,首先在XML数据实例中准确定位相关节点的位置。由于不同的XML数据实例与标准DTD模式相比,在结构上往往存在较大的差异,所以需要设计一种算法来有效地找到对应的节点。
假设标准XML参考实例为xr,XML数据实例为xi,两者的相似度算法伪代码可以表示为:
//循环处理标准XML参考实例中每一个叶节点路径
for each leafpath lprefi of xr {
//如果该路径上的节点含有约束修饰符
if (hasConstraintInPath (lprefi)){
int indexPath; //与标准XML参考实例中叶节点路径对应的XML数据实例叶节点路径
int minED= MAX; //临时变量,存储编辑距离转换的最小值
int indexNode; //与标准XML参考实例中节点对应的XML数据实例节点
double minWeight; //临时变量,存储节点权值的最小差值
//循环处理XML数据实例中每个叶节点路径
//根据编辑距离来获取与标准XML参考实例最相似的匹配节点路径
for each leafpath lpintj of xi
if (minED > editDistance(lprefi, lpintj)){
indexPath = j;
minED = editDistance(lprefi, lpintj);
}
//循环处理标准XML参考实例中当前节点路径的每一个节点
//按照从叶节点到根节点的倒序方向处理,以确保处理过的节点不再被处理
for each node nk of lprefi in leaf-to-root order{
//如果该节点含有约束修饰符
if(hasConstraintInNode(nk)){
//循环处理XML数据实例中最相似节点路径的每一个节点
//获取与标准XML参考实例中当前节点权值差异度最小的XML数据实例节点
//分配相应的约束修饰符
for each node ml of lpintindexPath{
int difference=abs(getWeight(nk, lprefi), getWeight(ml,lpintindexPath));
if (minWeight> difference){
indexNode = l;
minWeight= difference;
}
addConstraint(mindexNode);
}
//在XML数据实例当前处理节点路径中删除已经添加过约束修饰符的节点,以确保处理过的节点不再被处理
lpintindexPath = substring(lpintindexPath, indexOf(mindexNode), length(lpintindexPath));
}
}
}
}
说明如下:
(1)该方法用于在标准XML参考实例中寻找与含有约束修饰符的当前节点最匹配的XML数据实例节点,并将相应的约束修饰符标记下来,为后续的XML数据实例权值扩散提供判断依据。
(2)该方法首先以每个标准XML参考实例的叶节点完整路径作为处理单元,采用基于编辑记录的测度方法,在XML数据实例中寻找最为合适的节点所在路径。然后,该方法寻找当前路径上权值差异度最小的节点,以此节点作为命中节点并分配相应的约束修饰符。
(3)XML数据实例中已经处理过的节点无需再次参与下一轮的比较运算,所以需要按照从叶节点到根节点的方法来遍历标准XML参考实例每条叶节点路径上的所有节点,同时不再比较XML数据实例中已经处理过的节点。
对于既有的标准XML参考实例和XML数据实例,仍然可以采用利用权值的差异度来表示结构差异度的思路,得到一种新颖的相似度计算方法。
假设标准XML参考实例为xr,加权XML数据实例为xi,两者的相似度算法伪代码可以表示为:
Collection S; //存储所有比较节点的集合
//存储XML数据实例中所有叶节点与对应标准XML参考实例中叶节点权值差值的数组
//该数组长度为XML数据实例中叶节点个数,表明要考虑所有XML数据实例中叶节点的匹配情况
double[] minDifferenceValue = new double[countOfLeafnode(xr)];
//循环处理标准XML参考实例中每一个叶节点路径
for each leafpath lprefi of xr {
//循环处理XML数据实例中每一个叶节点路径
for each leafpath lpintj of xi {
int totalDifferenceOfLevel; //临时变量,存储当前叶节点路径上的权值差异总和
//根据标准XML参考实例和XML数据实例,得到对应节点路径上的全部待比较节点
S = getUnionSet (getAllNodeInPath (lprefi), getAllNodeInPath (lpintj));
//累加对应节点路径上的全部待比较节点的权值差值
for each s of S{
totalDifferenceOfLevel += abs(getWeight(lni,s)-getWeight(lnj,s));
}
//获取与标准XML参考实例当前节点路径权值差值总和的最小值
if(minDifferenceValue[index(lni)] > totalDifferenceOfLevel){
minDifferenceValue[index(lni)] = totalDifferenceOfLevel;
}
}
}
//以最小的权值差值总和作为最终的相似度测度数值
//该相似度计算方法的测度结果为大于等于0的一个浮点数,该数值越小,则越相似
return min(minDifferenceValue);
为了对上述方法的有效性进行验证,笔者在目前正在进行的一个基于个性化推荐服务的用户个人信息体管理系统(Personal Information Agent,PIA)上进行实验。实验的硬件平台环境为:CPU Intel Core 2 Duo P8400,内存 PC3-8500 DDR3 2.0GB。软件平台为:Windows Server 2003,SQL Server 2005,JDK1.6,Eclipse 3.3。
实验分为两个步骤:对上述相似度测度基本方法的有效性进行测试;在具体项目平台上测试用户满意度。
所有的标准XML参考实例和XML数据实例都是以表记录的方式存储在SQL Server 2005数据库中。其中,XML数据实例所在表为XMLInt,例2所示XML数据实例的存储信息如表1所示:
| 表1 XMLInt表的部分记录 |
标准XML参考实例所在表为XMLRef,结构类似于XMLInt,图1所示DTD所生成的标准XML参考实例存储信息如表2所示:
| 表2 XMLRef表的部分记录 |
需要说明以下三点:
(1)两张表都存储了对应XML数据中的所有节点路径及其相应权值,为了计算方便,节点路径采取倒序的表达方式。
(2)在XMLRef表中,增加了一个表达最匹配的XML数据实例节点路径的字段,字段值在计算中会随着比较对象的变化而更新,如表2所显示的值就是与表1所示XML数据实例比较后的计算结果。之所以在XMLRef中存储该信息,是因为通常认为一个遵守DTD的XML数据实例应该具有较多的对应DTD规定元素,XML数据实例中缺少对应DTD规定元素要比出现多余节点更能反映出一种不相似的状态。所以,通过遍历标准XML参考实例的所有节点路径,在XML数据实例中寻找最相似的节点路径,然后据此分配约束修饰符并为后续相似度计算提供基础。
(3)XMLRef表还有表示是否含有修饰符和约束修饰符类型的字段,可以在XML数据实例分配约束修饰符时使用。
对于表1和表2所示的标准XML参考实例和XML数据实例,它们的相似度计算结果如表3所示:
| 表3 相似度计算结果 |
最终的相似度计算结果为0.25,反映了部分相似的特点。
实验还对两种极端情况做了对比测试:
(1)比较完全不相似的XML数据实例,使用数据为表1所示的标准XML参考实例和表4所示的XML数据实例,相似度结果如表5所示:
| 表4 一个完全不相似的XML数据实例记录 |
| 表5 相似度计算结果 |
最终的相似度计算结果为1.75,反映了高度不相似的特点。
(2)比较完全相似的XML数据实例,使用数据为表1所示的标准XML参考实例和表6所示的XML数据实例,相似度结果如表7所示:
| 表6 一个完全相似的XML数据实例记录 |
| 表7 相似度计算结果 |
最终的相似度计算结果为0,反映了完全相似的特点。
通过测试,得出如下结论:
(1)如果比较的标准XML参考实例和XML数据实例完全相同,则相似度为0;两者越不相似,则相似度测度值越大,该值能够反映不同程度的结构差异。
(2)如果比较的标准XML参考实例和XML数据实例完全不相同,最终得到的相似度测度值会大于1,而且该值会随着DTD结构本身的复杂度而变大。
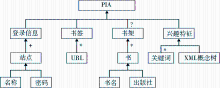
利用该方法在正在实施的基于个性化推荐服务的用户个人信息体管理系统(PIA)上进行用户满意度测试。该系统主要利用Web用户的各种Web访问信息和个性化特征信息来自动化地构建用户个性化本体,并以此进行个性化信息推荐服务。在实验中,采用DTD结构来定义用户的个性化本体,如图2所示:
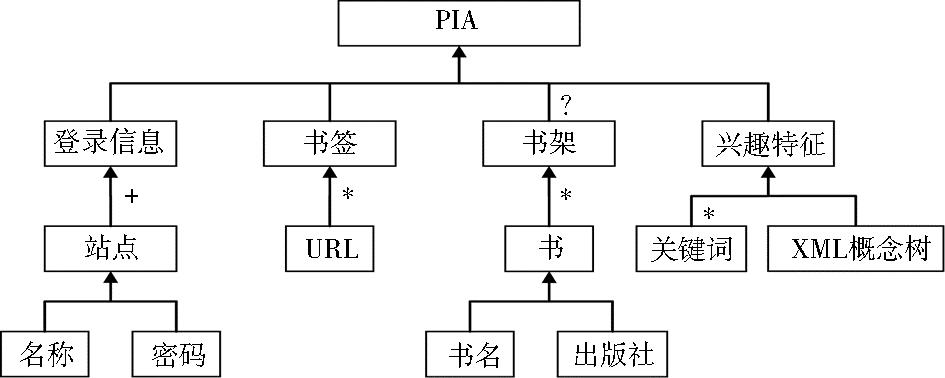 | 图2 PIA结构 |
实验首先得到系统中已有的20个PIA个性化本体信息,并进行适当的手工修正,要求12位测试用户对所有的PIA信息按照与DTD模式的遵守规范程度进行排序。把排序汇总后的结果看成一个二维表格,如表8所示:
| 表8 测度结果表格说明 |
表格中的每一列表达一个测试用户的评价排序结果,每一行表达一个排序等级,层次号越小则越相似。其中的每一个单元格内容表达一个PIA个性化本体信息,如R2表示第二个PIA个性化本体信息。
据此,定义了一个用户满意度的间接测度指标,即:
Indexsatisfaction=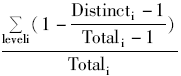
其中,Totali表示排序层次i上所有的PIA个性化本体信息个数,此处为常量12,Distincti表示排序层次i上彼此不同的PIA个性化本体信息个数。显然,该测度值为一个0到1之间的小数,数值越大说明不同用户的评价结果越一致。
系统实验进行了3次,平均用户满意度为0.77,但是如果只考虑层次号小于5和大于15的结果,发现平均用户满意度更高,为0.83。这在一定程度上说明了该方法能够较好地区别最满意的结果和最不满意的结果,对处于两者之间的相似结果判断能力相对较低。
本文提出了利用加权XML数据模型实现XML数据与DTD模式的相似度匹配方法,并对该方法的理论基础、实现过程及其实验结论都做出了详细说明。初步的实验表明该方法满足要求,同时具有算法简单和缩放性强的特点。但是也发现了该方法所存在的问题,特别是对于约束修饰符的表达和相似度算法中匹配节点的定位与寻找,笔者还在测试以期找到更优秀的替代方法。同时也发现,在进行XML数据与DTD模式相似度匹配比较时,除了要考虑元素的结构对应特征外,还要考虑一些语义信息,如XML数据实例中元素的名称可能与DTD模式中规定的标准名称虽然同义但是字面却存在差异。所以,在下一阶段的研究中,笔者将结合节点语义信息,从更多方面增强对XML数据与DTD规范一致性的判断准确性。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|