
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
网络课程资源自动量化评价研究
[王满 , 徐朝军]
, 徐朝军]
, 徐朝军]
|
|


引入数据挖掘和信息抽取技术,提出网络课程资源量化评价指标,构建网络课程资源量化评价系统模型,对资源实时跟踪监测,输出数据作为专家主观评价的补充,初步实验表明该量化评价方案具有较强的客观性和可行性。
This paper imports data mining and information extraction techniques, introduces Web course resources quantitative evaluation index, and builds a model for quantitative evaluation system for real-time tracking and monitoring key indicators, which exports data as the supplementary of expert subjective evaluation. Preliminary experiment shows that this quantitative evaluation has a strong objectivity and feasibility.
互联网和媒体技术的飞速发展,推动人类信息传播走向以数字技术、网络技术和多媒体技术为特征的网络传播时代。计算机数据挖掘技术因其自动运算及可以发现Web资源潜在规律和模式促进了其在教育领域的研究应用。本文从客观量化的角度,提出网络课程资源量化评价实施方案,从海量课程数据中自动提取能够有效体现资源建设和使用过程的相关信息并加以统计处理,输出客观的量化数据,为各级主管部门的网络课程建设和评价工作提供决策依据。
目前,计算机自动处理技术在网络课程评价中的应用研究主要涉及以下几个方面:应用数据挖掘技术动态选择和生成相应学习资源的网络课程智能模型[ 1]、针对学习者访问模式的Web日志挖掘[ 2, 3]、基于Apriori算法的多媒体关联规则挖掘[ 4]、基于模糊数学方法的网络课程评价系统[ 5, 6]等。
本文从网络课程评价理论[ 7, 8, 9]出发,结合技术实现的可行性,从网络课程的可用性、资源建设、交互设计3个一级指标、8个二级指标对网络课程资源使用过程进行量化评价,具体指标描述如表1所示。
| 表1 网络课程资源量化评价指标 |
所有指标项都可以通过自动化的网络数据采集程序从网络课程站点自动采集、统计,无需人工干预。对采集的数据清洗过滤,对上述指标项fij归一化处理后,再结合其权重wij计算该课程的总分S为:
s= 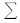
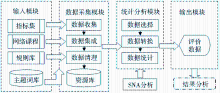
网络课程网站除了具有一般网站的特点以外,还具有很强的主题相关性,因此本系统采用面向特定领域的主题搜索策略,经过统计分析和基于规则的信息抽取,提取评价数据。该系统的框架结构如图1所示:
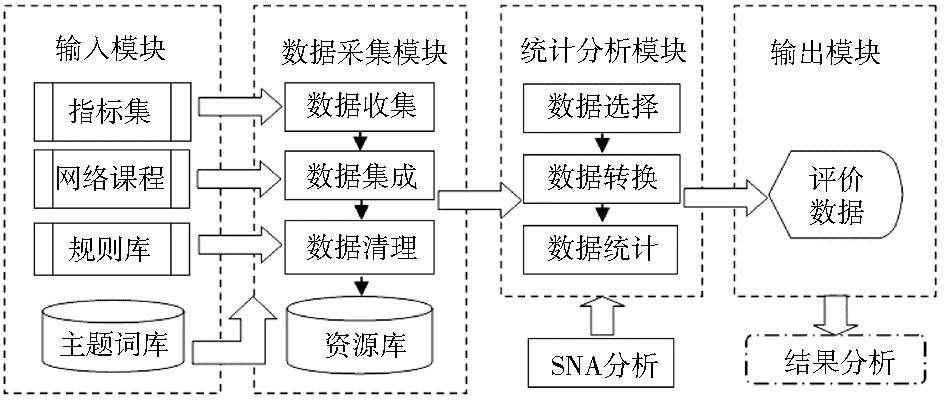 | 图1 系统框架结构 |
数据采集模块利用主题网络蜘蛛技术,从待评价网络课程网站提取所有原始数据,具体包括下载、分析站内每一个网页、教案、课件、教学视频等教学资源,从中抽取文件大小、发布时间等物理数据,以及实现论坛信息抽取。在蜘蛛爬行策略上,蜘蛛只集中在指定的课程网站上进行URL遍历,并高效识别课程中新增资源链接和其他变化。
课程网站除教与学的内容外,还包括大量的装饰性图片、动画、文字,以及对课程评价无用的链接。为保证统计数据的准确性,本文采用基于规则的数据清洗策略:根据锚文本描述过滤站内链接,然后通过网页标题来判断该页面是否有用,对资源的过滤策略主要有文件字节数、图片物理尺寸、出现频度等,如:装饰性图片、Flash在物理尺寸上一般是长条形且出现频度较高,导航性、提示性图标的文件尺寸相对于教学图片要小得多。
在网络课程领域,与主题相关的术语频繁分布在网站的文本中,且与主题相关度越高的术语出现的频率越高,因此本文采用基于LCS算法的领域词典构建技术,结合相似度计算抽取网络课程领域中整体出现频率较高的术语,经过处理自动生成领域词典。
(1)改进的LCS算法
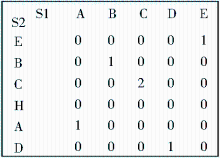
经典的LCS算法[ 10]可以提取非连续的公共子串,在中文领域词典的构建中,这些非连续的词不能作为领域词。本文采用动态规划LCS算法,并改进算法的执行效率,提取连续的最大公共子序列。原理如下:用矩阵来记录两个字符串两两字符之间的匹配情况,若不匹配,则该位置标志为0;若匹配,则该位置的值是它前一位的值加1,例如S1={ABCDE},S2={EBCHAD},其匹配矩阵如图2所示:
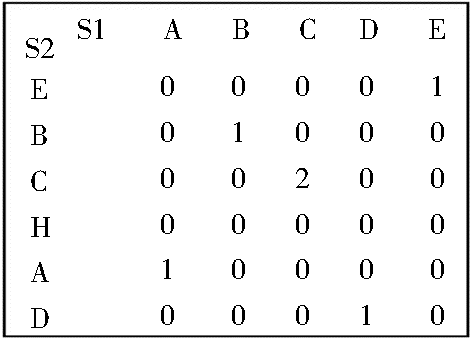 | 图2 LCS矩阵 |
在该矩阵中,最大数2为这两个字符串连续最大公共子串的长度,字符串匹配的开始位置数组标号为:最大数值所在的数组标号-最大公共子串的长度+1,即(2-2+1=1)。则提取的最大公共字串为字符串S1中从数组标号1开始、长度为2的子字符串,即“BC”。
(2)生成领域词典
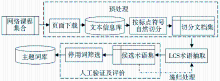
基于LCS算法的领域词典自动生成实现流程如图3所示:
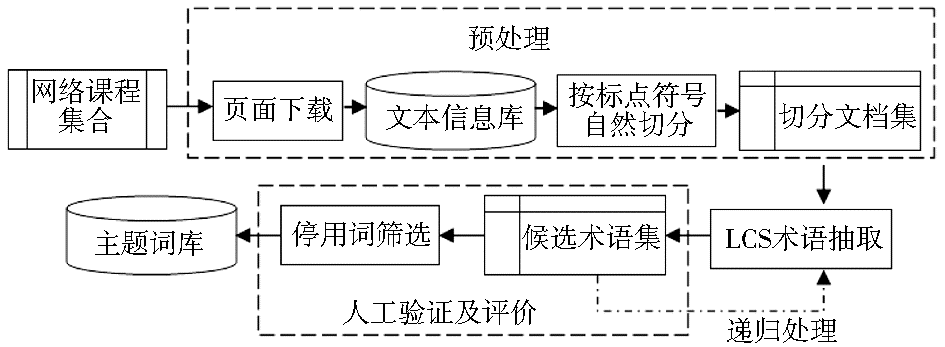 | 图3 基于LCS的领域词典自动生成流程 |
预处理模块完成去除网页集中所有HTML标记和乱码等“噪声”,过滤无效页面,去停用词,消除词形词缀变化(动词的时态、语态变化,形容词、副词的比较级与最高级,名词复数等)。在汉语中,标点符号是对文本进行最基本、最完整的语义单元划分,因此对抽取的网页文本按标点符号自然切分,存储长度大于1的字符串集合形成切分文档集。
两两比较切分文档集中语句片段的相似度,提取相似度最高的两语句片段的最大公共子串,同时统计最大公共子串的词频。将词频大于1的所有子串作为候选领域词的集合,结合人工判断多次递归抽取后,利用规则优化候选领域词,过滤错误的组合模式,生成网络课程领域的主题词典。
网络课程常常采用留言板或学习论坛的形式与学习者交互,反馈学习结果,因此本文以论坛或留言板等页面的抽取数据作为课程交互设计的评价依据。通过对网络课程网站论坛页面HTML源码进行分析,发现同一网站的发帖页面格式几乎相同,书写均比较规范,不同的只是发帖内容和时间等文本数据。因此本文采用基于模板的论坛信息抽取技术[ 11]。
首先自动过滤无用标记,例如<font>、<a>、<span>、<img>等以及所有标记内的属性。以一门网络课程中的留言板页面为例,其页面主题结构如下:
<div>
<div>
<ul>
<li>authorText</li>
</ul>
</div>
<div>
<div>标题:<h3> titleText </h3></div>
<div>[timeText by authorText] </div>
<div></div>
<div>
<table>
<tr><td> mainText </td></tr>
</table>
</div>
<div>
<div> returnAuthor 回复: returnTime </div>
<div>
<table>
<tr><td> returnText </td></tr>
</table>
</div>
</div>
</div>
<div></div>
</div>
本文采用基于正则表达式的渐进式模式匹配策略提取论坛数据。结合.NET平台支持的正则表达式平衡组技术,匹配嵌套的最大信息块,如上文匹配嵌套的最大Div标签的正则表达式模式设计为:
得到存放论坛数据的信息块后,再根据各个模块的匹配模式提取数据到相应的命名组中,以上留言板的信息匹配模式如表2所示:
| 表2 发帖信息匹配模式 |
笔者以Visual Studio 2003 C# 、SQL Server 2005为开发环境,开发了网络课程资源量化评价系统模型,系统运行硬件环境为P4 2.8GHz CPU,512MB内存。在确定样本后进行了测试,结果显示该方法可以有效地对网络课程资源建设、使用过程进行自动的量化评价。
本文选取了教育部2007年12月21日公布的《教育部财政部关于批准2007年度国家精品课程建设项目的通知(教高函〔2007〕20号)》中的411门本科课程作为实验对象。参考国家精品课程集成项目优质资源共享网站(http://search.jpkcnet.com/crsp/websiteInfo.do?method=index)中提供的网址,结合人工查找,得到411个网站实验样本。
系统对网站的可用性、资源建设两个一级指标中的连通性、资源增长、资源更新、链接可用性、资源类型等二级指标进行了跟踪统计,其中网站连通性、资源更新两个指标是宏观层面上的统计,后两个指标是针对选取的某几门课程网站做的微观统计,对交互设计指标项的实验是通过对几个代表性的网站留言板页面提取分析,从而得出实验数据。
(1)可用性
系统在5个不同的时间,对上述411个网站进行了跟踪,平均每月有120.8个网站不能正常访问,占29.39%,且呈上升趋势;平均每月有两个网站所用的服务器发生了变化,占0.49%,具体数据如表3所示:
| 表3 网站连通性跟踪统计 |
(2)资源增长
在这5次跟踪中,部分网站的资源链接数有了少量增加,如表4所示。在2008年11月至2009年5月期间,411个网站中只有33个网站(占8.03%)的资源链接有增加,链接增加总数为136,平均每个网站增加的资源数还不到1个。
| 表4 资源更新统计 |
(3)链接可用性、资源类型比例
在上述宏观统计的基础上,笔者选取了8门课程(理学、工学、材料学、医学、法学等),在2009年6月对其链接可用性和资源类型进行了统计,如表5所示。在这些网站中,图片和文档类型的资源占资源总数的大部分,动画和音视频资源相对较少,有些网站还含有其他类型的资源,如安装程序、打包资源等。
| 表5 链接可用性、资源更新、资源类型统计 |
(4)论坛交互
利用开发的网站课程资源自动量化评价系统,笔者提取了样本中411门课程信息,得到了论坛页面的交互使用情况统计数据,如表6所示。可以看出,高校网络课程中,对论坛或留言板等交互设计不是很重视,现有的交互平台没有真正应用起来,仅有7.06%网站的交互页面真正投入使用。
| 表6 2007年国家精品课程网站统计结果 |
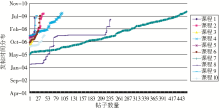
笔者从29门交互良好的网站中,根据帖子数量状态分布和论坛的可抽取程度,选择了10门课程作为实验对象,在2010年1月份提取网站交互数据,由于网络课程网站领域内的论坛较少更新,因此本文只给出这10门课程所有发帖的时间分布图,如图4所示。2007年评出的国家精品课程网站大部分都是在评估期间建立起来的,因此在2007年网站内的交互页面发帖比较频繁,2008-2009年间发帖相对较少,而且时间波动幅度较大,间歇性发帖现象普遍。由此可见,有些网站在评估结束后较少关注该门课程网站的使用。
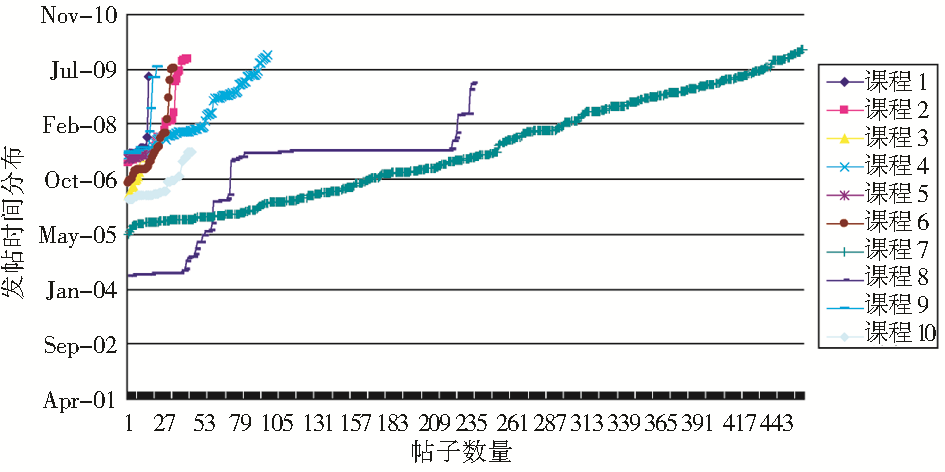 | 图4 发帖时间分布 |
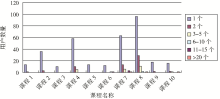
针对论坛用户行为,笔者统计了样本网站用户发帖数量分布,如图5所示。大部分的网络课程论坛用户活跃度不高,发帖数为1或2的用户占绝大部分,只有少数用户对课程有长时间的关注和交流。
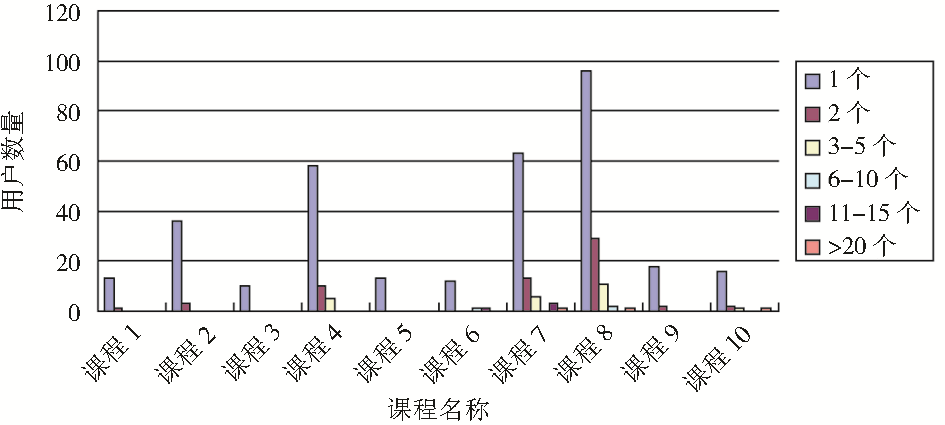 | 图5 用户发帖数量分布 |
以其中一门课程为例,系统输出用户交互矩阵,导入到UCINET 6.0社会网络分析软件中,分析网络整体结构。从宏观层面上反映社会网络的特征有许多指标,如网络规格与密度、特征向量中心度、互惠性、连通性等[ 14]。本文从网络课程评价的角度,着重体现社群网络的密度和中心度,通过矩阵运算,得到该网络的密度为0.0696, 中心度为23.22%,说明该网络较为稀疏,成员之间联系松散,互动较少。导入NetDraw中得到这门课程的用户交互网络图[ 15],如图6所示:
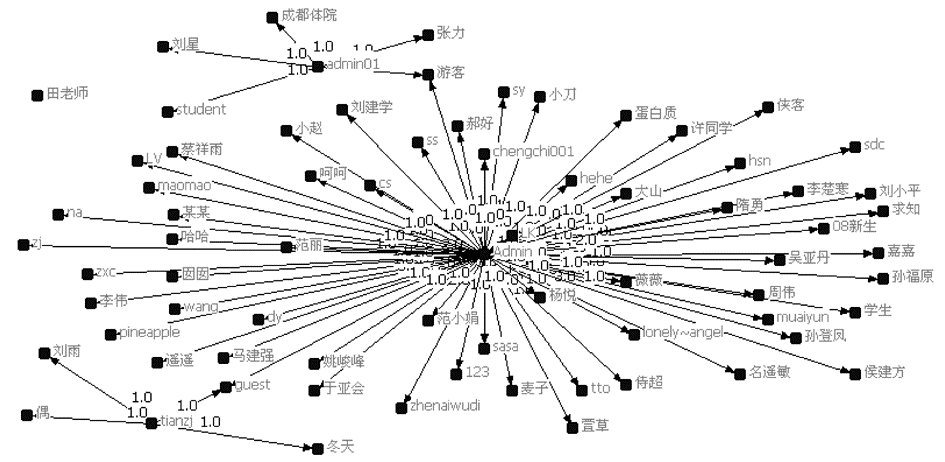 | 图6 用户交互网络 |
通过图6可以看到,该网络的核心发言人是“Admin”、“admin01”、“tianzj”用户,显然处于整个网络的领导地位,一般为课程教师;只存在一个边缘用户“田老师”,经核实为课程主讲人,之所以没有和网络中任一节点存在交互,是因为有一条发帖是课程主讲教师发布的通知,且网站只有管理员才有权限回复,所以其他节点之间均没有交互,但课程主讲教师对学习者提出的问题或自由评价均给予了反馈。
从上述实验数据来看,网络课程网站的稳定性不够,资源建设更新不足,交互设计页面没有得到很好地推广使用,已有网络课程的使用现状很不乐观。通过本系统的实验研究,证实制定的网络课程资源量化评价指标均可实现,相应的指标数据能反映网络课程资源的使用现状和存在的问题,而且此系统需要较少的人工干预、容易操作、运行效率较高,在网络课程评价领域具有较强的通用性和实用性。
由于实验周期只有6个月,所监测抽取的数据还不是很全面,受网页语义分析、主题识别与跟踪等技术的影响,对师生交互有效性等语义信息的抽取还不够。因此,进一步扩大实验规模和周期,加强师生交互信息分析,丰富并完善量化评价指标体系,增强评价系统的通用性和实用性是后续工作的重点,为网络课程建设和评价提供了新的思路和解决方案。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|