{kind=link}
{kind=link}
{kind=link}
异构数据源的数据移植方案研究——以北京航空航天大学图书馆为例
[陶新权 , 郭光超, 杨晓光]
, 郭光超, 杨晓光]
, 郭光超, 杨晓光]
|
|


针对数字图书馆建设中的数据移植问题,通过对北京航空航天大学图书馆现有异构数据源的分析研究,结合DSpace数据存储方式的特点,设计实现一个基于.NET框架的数据移植解决方案,通过数据抽取、清洗、DC生成和装载等步骤,实现从原有系统到DSpace的数据移植。系统的应用能有效地利用信息资源、实现数据共享。
In view of data migration in digital library, this paper analyzes the existed data environment of Library of Beihang University, and with the storage structure of DSpace, it proposes an approach for data migration based on .NET framework. This solution could integrate the data from heterogeneous data sources and transfer them to the new DSpace system by means of data extraction, data cleaning, DC generation and data transform. The implementation of this system could improve the information usage and data sharing effectively.
数据移植是一个将数据从各种业务处理系统导入目标数据库的复杂过程。它需要处理来自多种业务数据源中的数据,这些数据源可能处在不同的硬件和操作系统之上,在编码、命名、数据类型、语义等方面都存在较大的差异,因此如何高质量地向目标数据库中加载这些数量大、种类多的数据,己成为信息系统实施所面临的一个关键问题[ 1]。本文详细介绍北京航空航天大学图书馆(以下简称北航图书馆)数据移植方案的设计和实施概况,以期与同行交流。
机构仓储是大学为其成员提供的一套服务,用于管理和传播大学的各个部门及其成员创作的数字化产品。机构仓储的建设意义包括两个方面:
(1)为了克服现阶段学术交流模式的弊端,提高学术成果交流的效率,实现学术资源的开放获取;
(2)为了能够长期保存机构的学术研究成果,提高机构的学术声誉,促进学术发展,体现其社会价值[ 2]。
北航图书馆结合本馆实际,经过分析比较采用DSpace开源软件构建机构仓储,包括航空航天特色资源、学位论文提交系统等。目前,航空航天特色资源库中存在两种形式的数据来源:TRS Server和龙道数据库,数据总量近3TB,均运行于Windows XP操作系统下。新建的DSpace系统则采用PostgreSQL数据库,运行于Linux操作系统下。
本系统将通过对北航图书馆现有异构数据源的分析研究,结合DSpace数据存储方式的特点,设计和实现一个数据移植工具,将分散异构的航空航天特色数据库进行整合,消除数据重复、DC信息不全、DC文件名错误和存储规则不一致等问题,形成一种新的虚拟性数字资源体系,从而有效地利用信息资源、实现数据共享。
DSpace系统数据存储形式有别于一般的文献管理系统,其数据组织模型与高校的学院、系、教研室/实验室等的组织结构大致相对应。其数据模型分别称为社区(Community)、集合(Collection)、条目(Item),其中条目为存储库中的基本存档单元,即指提交到DSpace系统的数据单元。条目之下还可分为数字包(Bundle)和比特流(Bitstream)。这些数据模型的结构关系是:若干比特流组成一个数据包,若干数据包组成一条条目,若干条目组成一个集合,若干集合再组成一个社区。条目对应实际中的具体文本,集合对应实际中的系别,社区对应实际中的学院。学院中包含系,每个系中存放着不同的具体文本[ 3, 4, 5]。
DSpace存档格式如下:
archive_directory/
item_000/
dublin_core.xml "合格的Dublin核心元数据
contents "每行文本文件包含一个文件名
file_1.doc "添加到该项目的文件比特流
file_2.pdf
item_001/
…………
dublin_core.xml文件中每个Dublin核心元素自己的项目在一个
(1)
(2)
(3)
文件的内容只是列举每行一个文件名的数据流,这个数据流的名称可以依照顺序来命名。
北航图书馆原有系统由多个数据库系统构成,各系统在设计开发时并没有考虑到当前的数据集成需求,从而导致了各个源数据库之间在编码、命名习惯、物理属性、属性度量单位等方面存在较大差别。原有数据从异构数据库进入机构仓储之前,就必须经过数据转换、数据清洗,消除异构数据之间的不一致性及错误的地方,以保证数据的质量。否则,不仅新系统不能正常运作,其数据也不能作为数据分析和科学决策的基础。另外,各个源数据库之间存在冗余数据,在进入机构仓储之前需要进行统一的处理,去除多余的数据。
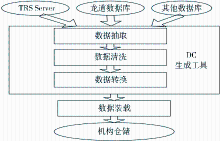
北航图书馆数据移植方案如图1所示:
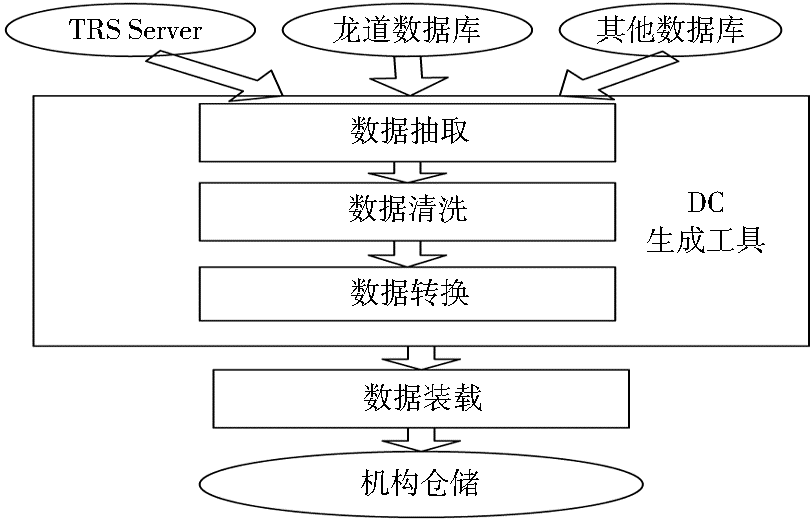 | 图1 北航图书馆数据移植方案 |
通过数据源接口DBInfo,将数据从各种原始的业务系统中读取出来,作为机构仓储输入数据,这是所有工作的前提。原有数据库系统所提供的数据接口分别支持TXT和XML格式,为了简化开发工作,使系统具有更好的可扩展性,首先将各种格式的数据统一转化为关系模型,将全部数据导入到SQL Server,在此基础上再进行后续加工处理。这样,当需要对新的数据源进行移植的时候,只需要编写新的接口程序,将新的数据源导入SQL Server即可,不再需要考虑为该数据源开发单独的数据移植工具。
在具体实现上,对于TRS Server可以利用其自身的导入/导出工具将数据直接导入到SQL Server,对于不能自行导入的,则将其转换为TXT文件。对于龙道数据库,首先要将其数据导出为XML格式的文件。在此基础上,对得到的TXT或者XML文件进行读取,并按照其自定义格式将其内部各数据项解析出来;然后对解析出的数据进行处理,将每条数据转化为对应一个资源条目的信息集;最后,通过C#中的ADO.NET(ActiveX Data Objects)和LINQ(Language INtegrated Query)这两种面向对象的数据接口来访问SQL Server,将生成的每个资源条目的信息集导入到SQL Server中,以便进行下一步工作。
按照预先设计好的规则对于来自不同数据源的数据进行检查和处理,清洗掉不合法的数据,确保数据集中的所有数据都是正确的和一致的。例如:在原系统的数据中存在着以下问题:
(1)文件编号问题:在原系统的某些文件编号的前面或后面带有没有意义的字符串。
(2)文件名大小写问题:在原系统中存在数据库中文件名与实际物理文件名大小写不匹配的情况。
(3)路径信息问题:原系统中部分数据存在没有文件路径信息,或者根据记录的文件路径信息找不到对应的具体文件的情况。
为了便于发现和更正错误,对于每个数据项都定义相应检查和处理机制,主要包括以下工作:
(1)数据项规范的制定:整理和定义了每个数据项的格式、数据类型和取值范围等要求,例如合法的文件编号格式。
(2)数据项检查:根据上述定义对读取到的数据项的值进行比对检查,例如检查指定数据条目下的文件是否存在。
(3)错误处理:如果在检查比对中发现了错误,则需要采用以下两种措施对错误进行处理:
①对数据进行更正,将其转化为正确的数据。例如:对于文件名大小写问题,由于在Linux操作系统下文件名是大小写敏感的,必须将数据库中的文件名与实际的物理文件名进行比对,对大小写不匹配的文件名进行更改,以防止出现错误。为了解决这一问题,利用C#提供的Path.GetExtension等方法来获得必须的文件路径结构,使用Path.ChangeExtension等方法对其进行更改。
②将错误进行记录,提示系统管理人员加以处理。例如:对于路径信息问题,在生成DC的过程中需要对数据条目的路径字段进行有效性检查,并且对指定文件是否存在进行判断,将错误的路径信息保存到一个文件中。利用C#提供的字符串匹配函数IndexOf来确定路径是以“\”为分隔符还是以“/”为分隔符,然后利用File.Exits方法来确定文件是否存在,如果不存在就利用文件的写入方法将该信息写入到一个文件进行保存。
按照源数据和目标数据之间的映射和转换关系,将来自不同数据源的数据加以合并、拆分、转换、映射等处理,使得异构的数据格式能够统一起来,符合机构仓储的模式设计要求。处理过程主要分为两个步骤:将同属一类的各个库合并为一个,在合并的过程中,要先解决表格式一致性,然后排除冗余的数据;是进行DC生成。具体工作如下:
(1)数据列的映射
原系统有些表结构和目标数据表结构不相符合,需要在原有表和目标表的各列之间建立映射关系,同时增加一些必要的列,使其符合目标表的要求。
(2)合并冗余数据
原系统各个库的数据表间存在数据冗余的情况,需要依据数据条目的唯一标识ID编号来发现冗余的数据项,并对其信息进行合并整理。
(3)文件路径
原系统中部分数据条目的路径信息的表示方法与DSpace系统的文件路径处理方式有冲突,在数据转换中需要对原系统路径信息进行检查和修正,使其符合DSpace系统的要求。
(4)DC生成
按照DC文档的语法格式将SQL Server表中的数据转换为DC文件。为每条数据生成一个DC文件,每个DC文件又包括一个Contents文件以及一个.XML格式的文件。Contents文件在导入DSpace系统的时候处理的是物理文件的路径信息,.XML文件在导入DSpace系统的时候处理的是文件的内容信息。
数据装载部件负责将数据按照物理数据模型定义的表结构将转换好的数据按计划导入到机构仓储中去。
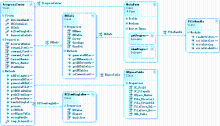
根据数据量的大小、复杂程度、移植效率、方便性等各方面综合评估,北航图书馆选用如下方式来进行数据移植:将数据批量导入SQL Server;转化成符合DSpace规则的DC元数据;将DC元数据批量导入DSpace;移植测试与修正。系统中的主要对象类如图2所示:
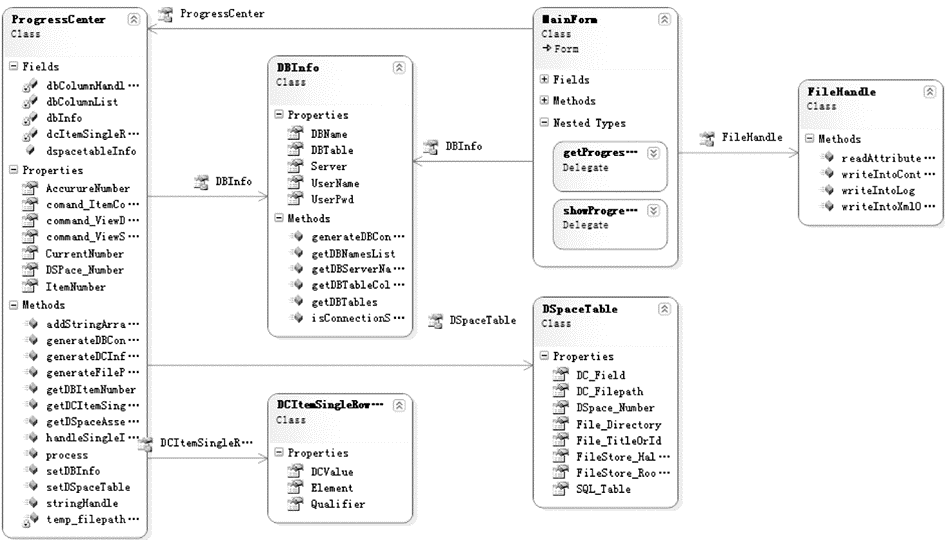 | 图2 系统对象类图 |
(1)DBInfo:用于同SQL Server进行通信,获取数据库的信息。
(2)DCItemSingleRowInfo:生成DC文件相关的XML格式文件。
(3)DSpaceTable:用于存取DSpace表中的数据,以便进行程序管理控制等操作。
(4)FileHandle:进行文件的读取以及DC文件的Contents和XML文件的生成。
(5)MainForm:系统主界面。
(6)ProgressCenter:主控程序,用来进行协调和完成总体功能的程序。
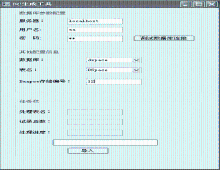
采用C#编写DC生成工具,依照服务器名提供的信息链接到相应的数据库,对该数据库中的相应信息进行读取,进行必要的提取和处理后生成符合DSpace规则的DC文件。
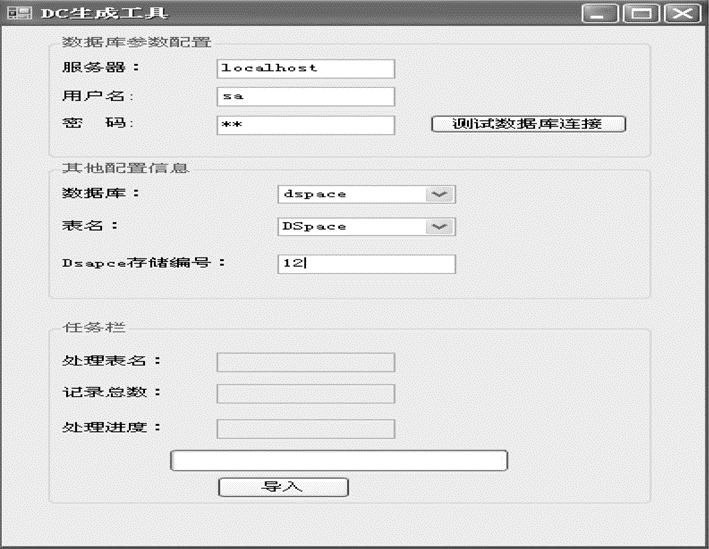
DC生成工具界面如图3所示:
 | 图3 DC生成工具界面 |
读取并处理记录信息的步骤如下:
(1)根据图3中输入的DSpace存储标号读取表1内的DSpace_Number信息,并提取出SQL_Table信息。
(2)根据SQL_Table信息读取相应数据库表并逐条处理。
(3)根据DSpace_Number对应的File_Directory和File_TitleOrId得到文件的路径。
(4)判断文件是否存在:文件存在,根据DSpace_Number对应的DC-Field信息进行字段处理;文件不存在,将文件路径写入一个记录文档中。
提取所需信息并生成dublin_core.xml文件的函数如下:
public bool writeIntoXmlOfDCSchema(ArrayList temp_elementandqualifierlist, String temp_filepath)
{……
xmlwriter.Formatting = Formatting.Indented; //定义XML格式
xmlwriter.WriteStartElement("dublin_core");
foreach (DCItemSingleRowInfo temp in temp_elementandqualifierlist)
{
xmlwriter.WriteStartElement("dcvalue");
xmlwriter.WriteAttributeString("element", temp.Element);
xmlwriter.WriteAttributeString("qualifier", temp.Qualifier);
xmlwriter.WriteString(temp.DCValue);
xmlwriter.WriteEndElement();//结束XML格式文件的写入
}
xmlwriter.WriteEndElement();
……}
提取所需信息并生成Contents文件的函数:
public bool writeIntoContens(string temp_contents, string temp_contentsfilepath)
{……
FileStream fs = File.Create(temp_contentsfilepath);//创建文件
StreamWriter sw = new StreamWriter(fs);
sw.Write(temp_contents);//写入文件内容
……}
将DC元数据导入DSpace,在命令行中输入如下命令:
dsrun org.dspace.app.itemimport.ItemImport -a -e buaa303@126.com -c 123456789/12345 -s F:/.PBDC -m F:/PBDC.txt:
参数含义:
-a:添加数据,-e:用户名,-c:句柄, -s:DC文件数据源,-m:导入数据记录文件。
在数据移植过程中,整合了北航图书馆收集、购买的几十万条数据,并且保证了数据的完整性和一致性,说明本文所用方案是可行的。数据移植的成功为机构仓储顺利上线奠定了良好的基础,目前航空航天特色资源已发布,在校园网内提供免费在线服务。数据移植是一个复杂和困难的过程,本文分析了异构数据源之间的移植问题并提出了相应的解决方法,为从事数据处理等研究人员提供了有益的参考。由于条件有限,对数据移植中如何按照质量需求来完善移植程序等问题还有待进一步深入研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|