{kind=link}
{kind=link}
{kind=link}
一种快速的个性化书目推荐方法
[徐嘉莉1  , 陈佳
, 陈佳2 ]
, 陈佳|
|


针对高校数字图书馆现有书目推荐方法存在的不足,提出一种快速的个性化书目推荐方法。该方法利用矩阵向量技术和压缩技术对Apriori算法进行改进,以提高数据资源的挖掘效率,然后利用改进的Apriori算法从读者的借阅记录中挖掘出图书之间的关联关系,以此为读者的借阅提供个性化的书目推荐服务。仿真结果能够证明该方法的有效性。
Aimed at the shortcomings of the bibliographic recommended methods in digital library, a Fast Personalized Bibliographic Recommendation Method (FPBRM) is proposed. By using the technologies of matrix vector and compression, the method improves Apriori algorithm that it can enhance the efficiency of data mining.Then the correlation between the books can be mined from the loan records by using the Improved Apriori Algorithm(IAA),which can provide personalized bibliographic recommendation for the readers. Finally,the simulation results show the effectiveness of the method.
当前,我国高校数字图书馆馆藏的内容越来越丰富,由此带来的信息“过量”和查询的易于“迷航”使用户不能方便、准确、及时地获取所需信息。如何帮助用户及时获取所需信息已成为数字图书馆的个性化服务迫切需要解决的问题。推荐系统的出现恰为这个问题的解决提供了方法。
国外个性化数字图书馆的建设已初见成效,如美国康奈尔大学图书馆的MyLibrary@Cornell系统[ 1],它已成为现今数字图书馆推荐系统的原型。国内许多高校图书馆也相继推出了各自的推荐系统,它们采用的书目推荐方法主要有热点书刊排行、专题推荐和新书推荐等,这些方法实现简单、可信度高但个性化程度较低[ 2]。为了提高个性化服务程度,文献[2]-[4]将关联规则挖掘[ 5]直接应用于读者借阅历史数据的分析中,挖掘出书目之间潜在的规则。这些基于关联规则挖掘的书目推荐方法提高了个性化服务程度,但由于它们是直接将Apriori[ 5]算法应用于借阅数据的分析,不可避免地继承了Apriori算法的不足:每次连接产生的候选项集太多;需要多次扫描数据库;在进行连接操作时需进行大量的判断、比较,因而挖掘效率较低,个性化服务质量没有得到充分提高。为提高挖掘效率,文献[6]-[8]先对Apriori算法进行改进,再将其应用于借阅历史数据的分析中,其中,文献[6]从减少候选项集的数目上对Apriori算法进行改进,一定程度上减少了空间消耗,但由于它是基于Apriori框架的,因此仍然存在Apriori算法的不足;文献[7]利用Hash表技术及减少生成候选集的数量对Apriori算法进行改进,一定程度上提高了挖掘效率,但由于需要产生候选项集及多次扫描数据库,其时间和空间的消耗很大;文献[8]采用基于FP-Tree频繁项模式的MFP-Miner方法,该方法完全脱离了Apriori算法的框架,不需要生成候选项集且只需扫描一次数据库,但需要保存庞大的FP-Tree、头链表、条件基等信息,因而需要消耗大量的空间,随着数据库记录的增加,这种不足将更加明显。
本文利用矩阵向量技术及事务压缩和项目压缩相结合的方法对Apriori算法进行改进,避免连接操作、不生成候选项集,且只需扫描数据库一次,以提高挖掘效率;然后利用改进的Apriori算法从读者的书目借阅历史记录中挖掘出关联规则;最后利用挖掘的规则向读者推荐书目,从而加强数字图书馆的个性化服务。
关联规则挖掘[ 5]就是从事务数据库中找出支持度和置信度分别大于最小支持度和最小置信度的规则。关联规则挖掘问题被分解为两部分:找出所有频繁项集;由频繁项集产生强关联规则。在关联规则挖掘中,由频繁项集产生强关联规则相对简单;如何迅速、高效地找出事务数据库中的全部频繁项集是关联规则挖掘的中心问题,也是衡量关联规则挖掘算法效率的主要指标。
关联规则中寻找频繁项集最经典的算法是Apriori[ 5]算法,但该算法每次连接产生的候选项集太多;需要多次扫描数据库;在进行连接操作时需进行大量的判断、比较工作,因而挖掘效率较低。高校数字图书馆每天产生的大量流通数据构成的数据库是一个大型数据库,直接利用Apriori算法挖掘书目之间潜在的规则会大大增加时间和空间的开销,从而影响系统的效率。
从Apriori算法的不足可以看出,提高Apriori算法效率的关键在于如何减少事务数据库扫描的次数、减少侯选项集的数量以及能否避免连接操作,这对于在每天都会产生大量流通数据的高校数字图书馆的借阅数据分析中能否提高挖掘效率显得尤为重要。为此,本文从减少数据库扫描次数、减少候选项集的数量及避免连接操作等方面对Apriori算法进行改进,以提高系统的效率。
为便于描述,定义相关性质如下:
性质1:任何非频繁的(k-1)-项集都不可能是频繁k-项集的子集[ 5]。
性质2:当所有频繁(k-1)-项集Xk-1中包含k-项集Xk的(k-1)-子项集的个数小于k时,Xk不可能是k维频繁项集[ 9]。
性质3:当事务T⊆I且该事务包含的项目数|T|=K时,求K+1维支持数时可从矩阵中删除T[ 9]。
(1)IAA算法的步骤
输入:事务数据库D={T1,T2,…,Tm},项集I={I1,I2,…,In},最小支持度min_sup,频繁项集的维数k
输出:Lk
算法过程如表1所示:
| 表1 IAA算法步骤 |
(2)关键算法描述
从IAA算法的步骤可看出,算法实现的核心在第2步、3步,第1步的实现参见文献[10],现仅对文中的第2步、3步的第(1)步的核心算法作如下描述:
①矩阵裁剪算法
输入:最小支持度min_sup, 矩阵A(m+2)×(n+1),其中m代表事务数,n代表项数
输出:矩阵Ar×p
算法实现:
min_supnum=min_sup*m;
do {// 删除不符合条件的列
for(j=1;j<=n;j++)
{if a[m+1][j]< min_supnum
{ for(i=1;i<=m;i++)
if(Ij in Ti) a[i][0]--;
delete 第j列;
}}
for all Ij∈Lk-1
if Ij在频繁(k-1)-项集中出现的次数小于(k-1)
{ for(i=1;i<=m;i++)
if(Ij in Ti) a[i][0]--;
delete 第j列;
}
//删除不符合条件的行
for(i=1;i<=m;i++)
if a[i][0] { for(j=1;j<=n;j++) if(Ij in Ti) a[m+1][j]--; delete 第i行;} }while 无行、列可删除 ②频繁K-项集生成算法 输入:矩阵Ar×p,组合对s,数组Bs×(k+1),min_supnum 输出:频繁项集Lk 算法实现: Lk=Ø; for(x=0;x { M=Ø; sup_num=0;// k-项集支持数sup_num初值为0 for(i=1;i { w=1; for(j=0;j { for(b=1;b if B[x][j]=a[0][b] break; w=w*a[i][b];//“与”运算 if (w==O) break; } sup_num= sup_num +w;// 计算k-项集支持数 } if sup_num >=min_supnum //求k-频繁项集 {for(j=0;j {t=B[x][j]; M=M∪{it}; } Lk= Lk∪M;}}
从IAA算法可以看出,它具有以下优点:
(1)IAA采用位运算的思想产生频繁k-项集,只需在生成布尔矩阵时扫描数据库一次且不产生庞大的候选项集,避免了Apriori算法存在的处理大量候选项集和重复扫描数据库及连接、剪枝的问题。
(2)挖掘过程中对矩阵进行裁剪,降低了空间消耗率,极大地减少了求高次频繁项集的运算时间。
(3)跨越了Apriori算法由低次到高次逐步查找频繁子集的限制,在不知k-1频繁项的前提下可以直接计算频繁k-项集,而且k越大,搜索的矩阵范围越小。这与基于Apriori的算法[ 6, 7]相比,避免了大量不必要的比较和计算。
(4)IAA算法在挖掘过程中采用数组结构和位运算操作,相比MFP-Miner[ 8]算法要保存庞大的FP-Tree、头链表、条件基等信息,节省了大量的存储空间。
FPBRM利用IAA算法挖掘高校数字图书馆流通数据背后隐藏的信息,掌握读者的借阅规律,预测读者的信息需求,为读者提供个性化的书目推荐。FPBRM的基本思想如下:
根据读者借阅数据的属性特点,在挖掘前对流通数据进行预处理,如减少数据库中的无用字段、对数据进行检查修正以保持不同数据源之间数据的一致性以及根据数据挖掘目标对数据分类提取等,不仅能提高输出结果的准确程度,还能减少数据处理量,节省系统资源,提高系统效率。主要从以下几方面进行预处理:
(1)本文主要针对挖掘出类似“读者借阅了A文献时,也会借阅B文献”或者“对A类文献感兴趣,也会对B类文献感兴趣”的关联规则,因此主要关心读者ID和书目记录号,其他信息均视为无用信息。
(2)由于读者一天内同时借阅的书籍与其专业有一定的关联,同一类书籍之间被同时借阅的概率比较大,而不同类书籍同时被借阅的机会较少,因此,本研究挖掘中图分类号为TP类的书籍,只关心TP类数据。
(3)由于中图分类号中含有“-”、“.”、“:”和空格,不利于数据的处理,所以统一将数据处理成只含有下划线、字母、数字的格式。
(4)删除一次只借阅一本书的记录。
选用某高校数字图书馆2005年3月至2009年3月的读者借阅历史数据库的部分数据,如表2所示;表3为书目库部分数据;表4为中图分类号对应表。对表2、表3进行预处理,将结果与表4连接,其结果如表5所示:
| 表2 借阅数据库 |
| 表3 书目库 |
| 表4 中图分类号对应表 |
| 表5 借阅事务数据库 |
关联规则的挖掘分为两个步骤:
(1)设最小支持度为0.2,利用IAA从表5中挖掘出形如“图书A-图书B”的频繁项集。
一般不考虑频繁1-项集,而且由IAA算法可知,它能在不知k-1频繁项的前提下直接计算频繁k-项集,因此可以直接挖掘频繁2-项集、频繁3-项集。部分挖掘结果如表6所示:
| 表6 满足最小支持度的频繁项集 |
(2)设min_conf为65%,根据表6导出置信度不小于最小置信度的强规则[ 5],并利用相关性[ 5]过滤掉会产生误导的规则,最后得到强关联规则,部分挖掘结果如表7所示:
| 表7 挖掘出的部分关联规则 |
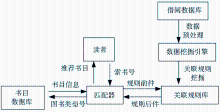
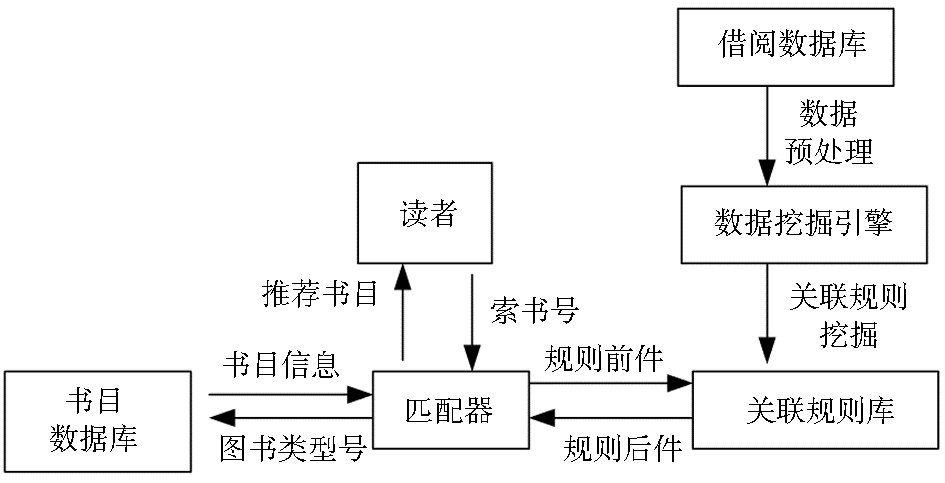
书目推荐服务模型由借阅数据库、数据挖掘引擎、读者界面、匹配器、关联规则库和书目数据库等部分组成,如图1所示:
 | 图1 书目推荐模型 |
数据挖掘引擎从借阅数据库中提取原始数据进行预处理,并挖掘强关联规则存储于关联规则库中,匹配器从当前读者的借阅信息中提取索书号,从关联规则库中寻找符合条件的规则,再根据这些规则向读者推荐其可能感兴趣的书目。
(1)21%的读者在借阅计算技术和计算机技术类、软件工具类的同时会借阅程序语言和算法语言类书籍;借阅计算技术和计算机技术类、软件工具类的读者有86%的可能借阅程序语言和算法语言类书籍。
(2)23%的读者在借阅计算技术、计算机技术类和Windows操作系统的同时会借阅程序语言、算法语言类书籍;借阅计算技术、计算机技术类和Windows操作系统类的读者有80%的可能借阅程序语言、算法语言类书籍。
(3)29%的读者在借阅计算技术、计算机技术类和网络浏览器类的同时会借阅程序语言、算法语言类书籍;借阅计算技术、计算机技术类和网络浏览器类的读者有87%的可能性借阅程序语言、算法语言类书籍。
(4)22%的读者在借阅计算技术、计算机技术类,图像识别及其装置类和计算机网络类的同时会借阅程序语言类书籍;借阅计算技术、计算机技术类,图像识别及其装置类,计算机网络类的读者有94%的可能性借阅程序语言类书籍。
书目推荐模型可以根据这些规则进行书目推荐,如:可以向借阅计算技术和计算机技术类、软件工具类的读者推荐程序语言和算法语言类书籍;向借阅计算技术、计算机技术类和Windows操作系统类的读者推荐程序语言、算法语言类书籍。这样,系统采用自动推荐书目的方式达到信息主动推送的目的,实现图书信息服务的智能化、个性化,大大方便了读者。
利用表2中的数据,在Windows XP(Intel(R) Pentium(R)M Processor 1.73GHz、内存为1GB)平台上、SQL Server 2000和Delphi7.0的环境下分别实现了FPBRM和BRMBA(Bibliographic Recommended Method Based on Apriori),处理结果分别如图2和图3所示。
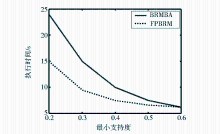
 | 图2 事务数相同、支持度变化两种方法对比 |
图2是在事务数目固定为500k(记k=500条记录)、支持度在0.2-0.6之间变化时两种方法的执行时间对比。从图2可以看出,在数据规模相同的情况下,当支持度在0.2-0.6之间变化时,FPBRM的执行速度比BRMBA快。这是因为FPBRM在求频繁项集时,将事务数据库表示成矩阵,并对矩阵进行裁剪,然后通过向量运算产生频繁项集,避免了采用BRMBA求频繁项集时所需的连接和剪枝。这既不需要产生庞大的侯选项集且仅需扫描数据库一次,减少了空间和时间的开销,因而其效率比BRMBA高。当支持度为0.2时,数据库中的频繁项集数目最大,其候选项集也最大,FPBRM的这一优势更加突出,因而其执行时间与BRMBA的执行时间相差也最大。因此,FPBRM更适合应用于数据量大且分散、经过几次筛选后频繁项集能快速缩减的大型数据库,如数字图书馆的流通数据库。
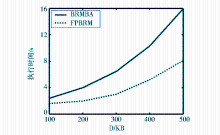
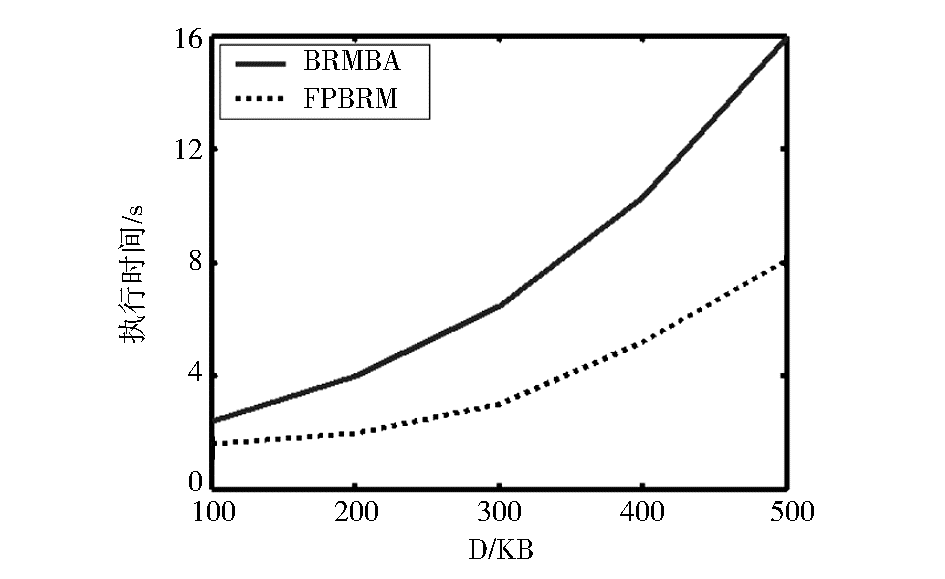 | 图3 支持度相同、事务数变化两种方法对比 |
图3是在最小支持度为0.2、事务数量发生变化时两种方法的执行时间对比。从图3可以看出,对于同等规模的测试数据库,FPBRM的执行时间小于BRMBA;随着数据库规模的增大,与BRMBA相比,FPBRM的执行效率更高。这主要是因为FPBRM在挖掘过程中对矩阵进行了裁剪,极大地减少了求高次频繁项集的运算时间;并且在不知k-1频繁项的前提下可以直接计算频繁k-项集,跨越了采用BRMBA时需由低次到高次逐步查找频繁子集的限制,而且k越大,搜索的矩阵范围越小,进一步减少了时间和空间的开销。因此,FPBRM更适合数字图书馆这样的大型数据库。
FPBRM首先对读者的借阅数据进行预处理,并将其转化为布尔矩阵,然后通过矩阵裁剪、向量运算产生频繁项集,进而产生强规则,最后利用强规则向用户推荐其感兴趣的书籍。它不仅能向读者提供个性化程度较高的书目推荐,而且只需扫描数据库一遍且不产生侯选项集并避免了连接和剪枝,减少了时间和空间的开销。与BRMBA相比,FPBRM具有较高的效率,更适合在高校数字图书馆的个性化书目推荐中应用。
下一步工作将结合用户的专业、年级、教育程度、性别、年龄等特征进行多维模式挖掘,以提供更全面的个性化服务。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|