
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
通用查重比对模板系统的VBA实现
[徐海 , 姚翔]
, 姚翔]
, 姚翔]
|
|


主要介绍南京航空航天大学图书馆于2009 年自行开发的中文期刊采访通用查重比对系统的设计与实现过程。通过采用Excel VBA技术,设计开发出一套针对不同刊商目录数据通用的数据查重比对模板,在采访工作中实现准确而高效的批量查重比对, 并提供友好可交互的图形界面。该系统可以促进图书馆采访工作的自动化、科学化。
This article discusses the design and implementation of general duplicate checking and comparison template system used for Chinese periodical acquisition. Based on the technology of Excel VBA,this system which is developed by Library of Nanjing University of Aeronautics and Astronautics in 2009, designs and develops a general duplicate checking and comparison template aimed at all kinds of providers’ directory data. It achieves accurate, efficient and batch duplicate checking and comparison in the library periodical acquisition work and provides a friendly graphic interface. The system promotes the automation and scientization of library acquisition work.
期刊采访中的征订期刊查重比对工作是利用各种检索途径调查、了解本馆期刊的预订、收藏及订购经费情况, 以便有的放矢地预订、购买、增补期刊, 合理分配经费,有计划、按比例地进行文献资源建设。
目前,全国期刊种数基本保持在10 000种左右,每年甚至每月都有期刊关停并转,改版频繁。高校图书馆期刊征订除了通过传统的邮局发行渠道,还会有其他渠道,一般会有几家期刊发行代理商(以下简称刊商)合作。每家刊商提供的征订目录覆盖的期刊数大约在6 000-7 000种之间,彼此交叉重复,每年期刊种类和价格都会有增减变化。期刊社每年会根据刊商的发行政策调整发行策略,因此刊商的征订数据每年都有变化[ 1]。
期刊订购标准不统一,各家刊商各行其是,没有统一、唯一的识别代码,给期刊订购工作带来了困难。刊商的技术力量相对薄弱,无法满足图书要求。在图书馆业界,期刊也没有形成像图书一样上规模、成体系的规范流程和标准。
变化是期刊的一大特性,和期刊相关的一系列工作(如订购、签收、阅览、装订)都要跟随发生变化,琐碎且量大。期刊订购阶段性强、时间紧、任务重,手工操作容易出错,漏订、重订时有发生。在经费分配上,图书馆需对各家刊商款额有明确把握,必须在前期得出所订期刊的准确价格。期刊征订是一项延续性的工作,期刊的增删变化只占小部分,但为了确定合理的订购方案,每年都必须对目录做全面整理,因此在确定订购数据之前,查重比对是必不可少的工序。
以南京航空航天大学图书馆为例,2008年中标刊商三家,加上非中标刊商天津期刊联订中心和零星采购,共有5种途径订购期刊。处理方法是将上一年度的确认订单与新一年度的刊商的征订数据比对,确定新一年度的订单,再将未找到的订单数据和另一家刊商征订数据比对,确认余下的订单,反复进行这道工序,直到全部刊商数据比对完毕,余下的期刊通过零星采购渠道直接和刊商联系订购。
由于手工进行查重比对工作不但繁琐单调,而且很容易出现错误,本馆所使用的汇文期刊系统模块不能很好地满足工作需要,市场上的一些查重比对软件又不够灵活适用,因此本馆采用Excel VBA技术,自行开发出针对不同刊商目录数据通用的数据自动查重比对模板,有效地解决了这一问题。
在实际的查重比对过程中,主要工作内容包括查重比对数据的导入、比对字段的选择、字段格式的预处理、数据查重、数据比对及结果输出等。其中比对字段格式不一致的问题与数据查重比对是需求分析中最复杂、最关键的两部分。
不同刊商提供的征订数据中刊号、刊名没有一个固定统一的标准,变动性大。
以刊号(邮发代号)“2-2”为例,在不同的刊商征订数据中邮发代号会有不同的格式,如表1所示:
| 表1 刊号(邮发代号)的不同格式 |
在刊号(非邮发代号)不能比对成功的情况下,则以刊名为关键字段进行比较。但由于中文的半角/全角的原因,会造成非字符符号(除了中文、英文及数字以外的符号)格式的不一致,具体表现如表2所示:
| 表2 非字符符号半角/全角的不同格式 |
因此,在数据查重比对之前,必须先进行比对字段数据的格式预处理操作。
数据查重是将上一年度己确认订单数据与新一年度的刊商目录数据通过精确比对关键字段,实现查重的目的。重点与难点在于将重复部分标识出来,然后再把重复部分和未重部分分离出来。
数据比对则是在己查重的基础上,通过比对诸如单价、年价,计算出价格的增长数量、增幅等,实现把握期刊价格,调整预算,从而更合理地制定期刊订购方案。重点与难点在于比对相应字段及增长数量、增幅的计算等。
同时,由于查重比对数据量非常大,因此选择合理的程序算法非常重要。通过有效地控制好查重比对过程中的时间/空间代价,实现时间高效率、空间低消耗的查重比对。
本文所设计的系统主要功能包括6个部分,分别为数据导入、比对字段的选择、格式预处理、数据查重、数据比对与VBA封装。
(1)数据导入:实现将源数据(欲查重比对数据)和目标数据(总数据)分别导入到同一个Excel工作簿中的两张工作表中,数据源可包括Excel表、TXT文本、Access及SQL Server数据库等。
(2)比对字段的选择:选择源数据与目标数据两者欲比对的关键字段(这些字段是由程序自动抽取目录数据的标题字段形成的)。如果两者数据同属于邮发期刊数据,则选择邮发代号作为比对字段,否则以刊名作为比对字段。
(3)格式预处理:实现对Excel中字段信息的格式调整,包括去除空格,位数不够补0,使用特殊符号(比如*)替代比对数据中的所有非字符符号(除了中文、英文及数字以外的符号)等。
(4)数据查重:实现对源数据(欲查重比对数据)在目标数据(总数据)中进行查重操作,标识重复部分,有效分离重复部分和未重部分,最后将查重结果输出至Excel中。
(5)数据比对:实现对源数据(欲查重比对数据)在目标数据(总数据)中进行比对操作,如比对期刊单价、年价,计算出价格增长数量及增幅等,并将比对结果输出至Excel中。
(6)VBA封装:实现将VBA 代码封装成DLL文件,并在Excel 中引用DLL 的方法,保证VBA 源代码的数据安全。
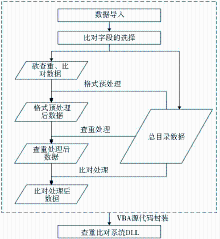
系统流程如下:
(1)导入欲查重比对的期刊数据与刊商总目录数据至Excel中。
(2)选择欲查重比对的期刊数据与刊商总目录数据两者欲比对的字段。
(3)对不同刊商的标准不同,将格式不一致的字段数据进行格式预处理,实现欲查重比对数据与总目录数据的格式一致性,达到通用模板的效果。
(4)数据查重,生成新的查重处理后的表数据。
(5)数据比对,生成新的查重比对后的表数据。
系统流程如图1所示:
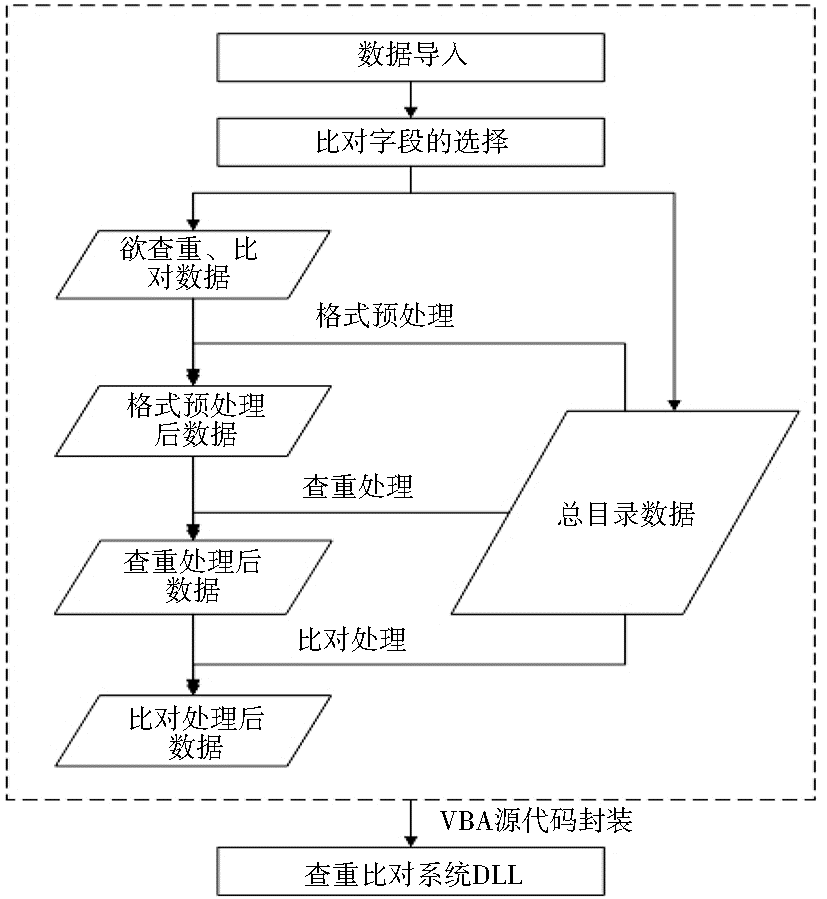 | 图1 查重比对系统流程图 |
本文所设计开发的通用查重比对模板系统是基于Excel平台上的VBA Application,开发平台为Excel 2003,开发语言为VBA[ 2]。
一般刊商所提供的期刊目录数据为Excel表,均可直接导入至Excel中,然后程序自动抽取它们的标题字段作为比对字段。以本馆需要处理的刊商数据源为例,主要有以下几家:
(1)南京大学期刊采编中心邮局发行期刊目录/非邮局发行期刊目录。
(2)南京图书馆亚信期刊采编中心邮局发行期刊目录/非邮局发行期刊目录/中国人民大学社会科学报刊复印资料目录。
(3)北京人天书店期刊中心期刊目录。
(4)全国非邮发报刊联合征订服务部(即天津期刊联订中心)期刊目录。
不同刊商数据源导入示意图如图2所示:
 | 图2 不同刊商数据源导入示意图 |
可以发现,不同刊商的期刊目录数据中的刊名、刊号命名用法不统一,格式不一致,字段排列也无规律。以南京大学期刊采编中心邮局发行期刊目录数据为例:邮发代号被命名为报刊代号,格式采用的是紧凑格式;而南京图书馆亚信期刊采编中心邮局发行期刊目录数据中则将邮发代号命名为邮发号,格式采用的是带零完整格式;其他非邮发期刊目录刊号则采用各自编定的刊号,没有一个统一的标准。
因此,在不同刊商的期刊目录数据被导入后,应根据具体情况选择相应比对字段,确定是否比对邮发代号或是刊名,以及字段格式是否需要预处理操作等。
由于不同刊商所提供的刊名、刊号没有一个固定统一的标准,随意性较大,因此在进行数据查重比对之前需要进行字段格式预处理操作。
字段格式预处理操作首先选取欲查重比对的标题字段,如邮发代号、报刊代号或刊名等(数据导入时程序会自动抽取出字段格式模型,比如以邮发号02-002为例,该字段格式模型为XX-XXX),然后再针对以下情况进行格式预处理操作,实现格式的一致性。
(1)位数不够补零,比如总目录征订号为02-002(相应模型格式为XX-XXX),而欲查重比对邮发代号为2-2(相应模型格式为X-X),位数不够,则将2-2补零成02-002。
(2)去除空格,比如邮发代号为2- 2(相应模型格式为X- X),中间多一个空格,则去除空格,调整为2-2。
(3)使用特殊符号(比如*)替代比对数据中的所有非字符符号,这主要是针对刊名中存在的全角/半角等非字符符号,通过非字符符号替代,达到刊名查重比对的格式一致性。
例如: 潮流志:YOHO,青春(全角)
潮流志:YOHO,青春(半角)
格式预处理后都变为:潮流志*YOHO*青春
字段格式预处理的相关程序部分源码如下:
Public Sub FillZero (ByVal str As String) ‘邮发号位数不够补零函数
‘以“-”为分隔符,从str分离出左右子串。如str=“02-002”,则分离后, strL=“02”,strR=“002”
strL = Left(str, InStr(str, “-“) - 1)
strR = Right(str, Len(str) - InStr(str, “-“))
‘在邮发号 “XX-XXX”中,以“-”分隔,则左边位数为2,右边位数为3
iLenL = InStr(str, “-“) - 1 ‘str中左边的位数
iLenR = Len(str) - InStr(str, “-“) ‘str中右边的位数
‘ iMaxL为带零完整邮发号中的左边位数,iMaxR则为右边位数
If iLenL < iMaxL Then
For j = 1 To iMaxL - iLenL
strL = "0" + strL ‘左边补零
Next j
End If
If iLenR < iMaxR Then
For j = 1 To iMaxR - iLenR
strR = "0" + strR ‘右边补零
Next j
End If
str = strL + strR ‘左右合并,补零完成
End Sub
Public Sub DelSpace (ByVal str As String) ‘去除邮发号中空格的函数
Do While InStr(str, " ")
str = Left(str, InStr(str, " ") - 1) + Right(str, Len(str) - InStr(str, " "))
Loop
End Sub
‘使用特殊符号(*)替代所有非字符符号函数,nonCh为非字符符号
Public Sub ReplaceNonCharacter (ByVal str As String, ByVal nonCh As String) Do While InStr(str, nonCh)
str = Left(str, InStr(str, nonCh) - 1) + "*"
+ Right(str, Len(str) - InStr(str, nonCh)) ‘用 * 替代nonCh
Loop
End Sub
实践证明通过上述格式预处理后,能达到精确的查重比对效果。
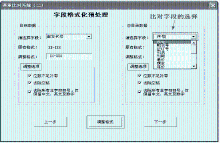
字段格式预处理界面如图3所示:
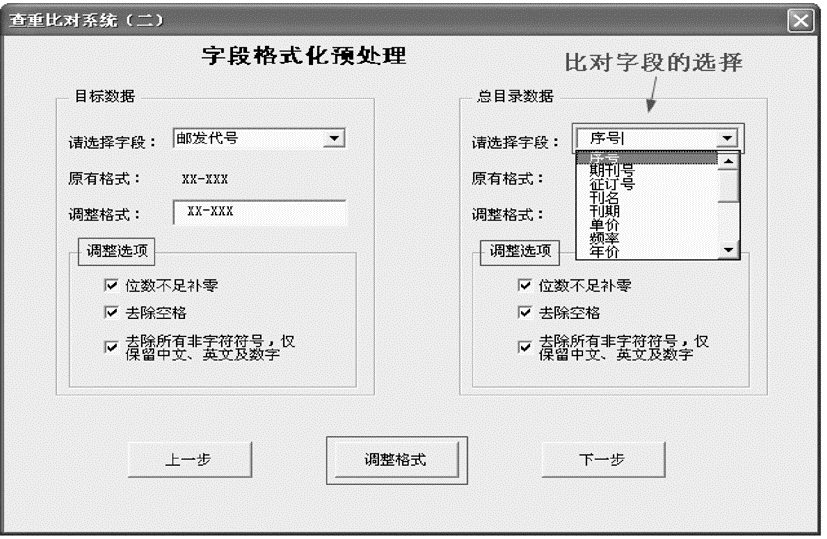 | 图3 字段格式预处理界面 |
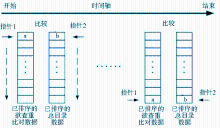
在进行数据查重比对之前,首先利用Excel自带的数据排序函数在后台程序中对欲查重比对的期刊数据和刊商总目录数据均按指定查重比对字段进行排序,同为升序或降序(此处假设为升序);然后设两个指针(记为指针1与指针2)分别指向两边数据的首部,依次向下遍历,进行比较。详细过程如下:
(1)if a < b,则说明a不在总目录数据中,不重。指针1下移,指向下一个数据,指针2不动。
(2)if a = b,则说明a在总目录数据中,查重成功。指针1与指针2均下移,指向下一位数据。
(3)if a > b,则说明在总目录数据中还未找到与a相重的数据。指针1不动,指针2下移,指向下一个数据。
(4)循环往复,直到指针1或指针2移到数据末尾,则比较结束。
整个查重比对过程只需遍历一遍数据,时间复杂度T(n)=O(f(n)),且比较时不需要额外存储空间,达到高效率、低消耗的算法实现[ 3]。
查重比对算法示意图如图4所示:
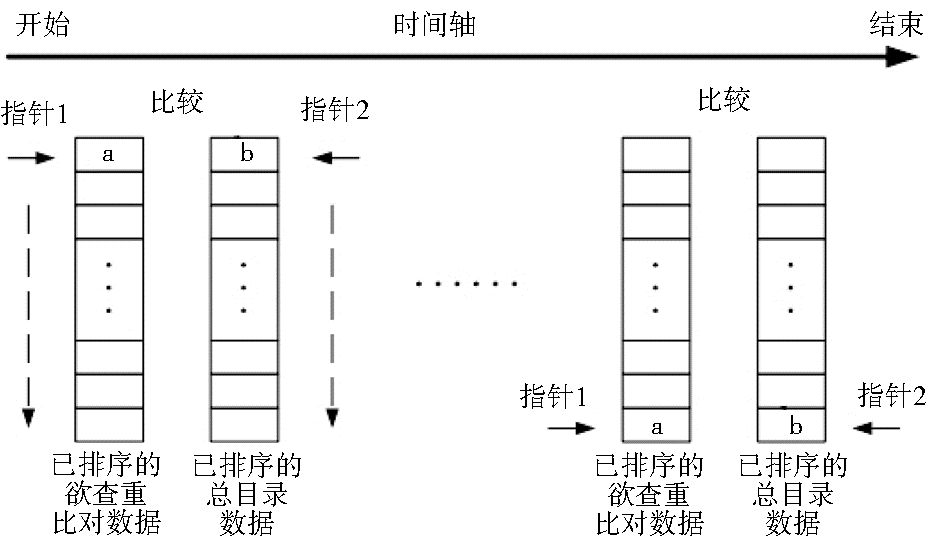 | 图4 查重比对算法示意图 |
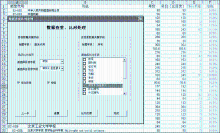
在数据查重实现过程中,通过添加一字段“重否”来标识是否查重成功,以“0”表示不重,以“1”表示己重。采用上述查重比对算法逐行遍历比较,比较完成后再以“重否”字段进行排序,可有效地将未重部分分离输出。同时将己重部分进行数据比对,如比对两者年价,计算出年价的增长数据与增幅,可有效地把握订购价格。数据比对后的结果输出如图5所示:
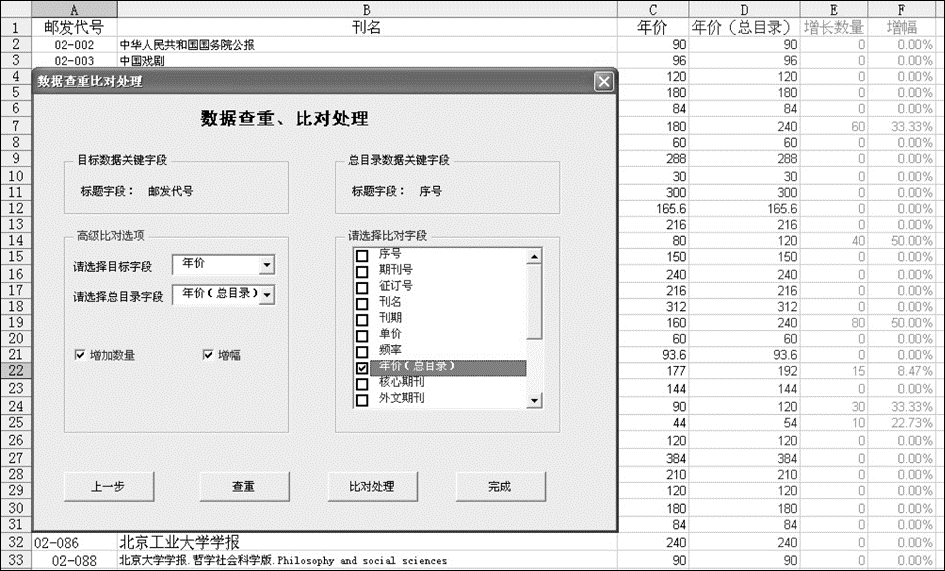 | 图5 查重比对后的结果输出 |
通过以上设计与实现,通用数据查重比对模板系统在2010年南京航空航天大学图书馆的期刊征订工作中取得了非常好的效果。不仅实现了不同刊商目录数据查重比对的通用有效处理,提高了工作效率,同时还对刊商的服务水平有了更深入的了解,能够更合理地分配经费,在期刊订购中掌握主动权。
由于本系统适用范围广,对于外文期刊及图书查重比对同样适用,同时还可以按照不同途径和需求组合出相应的期刊公务目录,有效运用于实际工作中。
| [1] |
|
| [2] |
|
| [3] |
|