{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
关联数据及DBpedia实例分析
[白海燕 ]
]
]
|
|


基于关联数据的基本原则和发布方法,分析介绍DBpedia的实现技术:通过对WikiText格式数据进行语法解析和流程控制,实现对自由文本进行的结构化数据抽取和RDF表达,并基于URI参引、SPARQL查询和RDF文件转存等多种方法,实现多样化的Web数据获取;采用基于属性和基于模式的自动关联算法,与众多数据集之间实现关联。
Based on the principles and publishing method of linked data, this article introduces and analyses some technique issues of DBpedia. It extracts structured data from Wiki’s free text articles and expresses data in RDF by syntax parsing of WikiText and controlling of workflow. It also provides Web data in many ways such as URI dereference, searching based on SPARQL and RDF dumps.Finally,the paper uses automatic interlinking methods based on schema or properties algorithm to make linkages with a large amount of datasets.
2006年,WWW的发明者、被誉为互联网之父的Berners-Lee在《关联数据构建笔记》等一系列文章中分析了Web的发展和演化,提出了当下发展数据网络(Web of Data)的思想,而数据网络的核心和关键则是关联数据(Linked Data)。根据维基百科的解释[ 1]:关联数据是一种推荐的最佳实践,用来在语义网中使用URI和RDF发布、分享、连接各类数据、信息和知识,发布和部署实例数据和类数据,从而可以通过HTTP协议揭示并获取这些数据,同时强调数据的相互关联、相互联系以及有益于人机理解的语境信息。关联数据强调建立已有信息的语义标注和实现数据之间的关联,它具有框架简洁、标准化、自助化、去中心化、低成本的特点,为构建人机理解的数据网络提供了根本性的保障,为实现语义网奠定了坚实的基础[ 2]。
自2006年以来,关联数据得到了广泛的认同和快速的发展。2007年5月,互联网上构建并发布的关联数据约有5亿个RDF三元组(Triples);2008年,已有超过20亿的RDF三元组;至2009年5月,已有超过100个数据集(Datasets),RDF三元组已超过47亿个。
关联数据技术使互联网发生着深刻的变革。W3C的语义网和关联数据组织的Open Linked Data项目已经使20亿条传统网页上的数据(包括维基百科)自动或半自动地转换成了关联数据。DBpedia项目从维基百科(Wikipedia)的词条里抽取结构化数据,以提供更准确和更直接的维基百科搜索,并可使其他数据集与维基百科在数据节点上相链接。这种语义化技术的介入,使得维基百科简单、快速地衍生出众多创新性应用,如手机版本、地图整合、多面向搜索、关系查询、文件分类标注等。DBpedia也由此成为世界上最大的多领域知识本体之一,被美国科技媒体Read Write Web评为2009年最佳的语义网应用服务[ 3]。
本文以DBpedia为应用实例,从关联数据的发布与构建、关联数据的获取与使用以及不同关联数据集之间的关联构建三个方面,介绍了关联数据的主要技术与方法,以期对国内各类关联数据应用提供参考和借鉴。
Berners-Lee提出了关联数据构建和实现的4个基本原则[ 1]:
(1)使用URI作为任何事物的标识名称;
(2)使用HTTP URI让任何人都可以访问这些标识名称;
(3)当有人访问某个标识名称时,提供有用的信息;
(4)尽可能提供相关的URI,以使人们可以发现更多的事物[ 2]。
根据关联数据的4个基本原则,在Web中发布的事物必须具有可参引的HTTP URI标识。统一资源标识符 (Uniform Resource Identifier,URI)是互联网中数字对象标识的基准,也是语义Web的基础,它能够唯一地标识Web上的任意一个资源,其思想是在需要的时候通过链接引用资源,因此不需要对资源进行备份或集中管理。“资源”是能够被标识的任何对象,包括信息资源(Information Resource),如邮件、Word或PDF文档;非信息资源(Non Information Resource),如一个客观事物、人、地点或概念。
HTTP URI是可参引的(Dereferencable),即通过这个URI在Web上可获得相应资源的信息。对于返回资源的表达和显示格式,根据内容协商(Content Negotiation)机制,如果URI参引时要求的媒体类型(MIME-type)为Accept: Application/RDF+XML,则数据源必须能返回被标识资源的RDF/XML描述;由于一般的浏览器不支持RDF显示(如直接显示RDF源码或仅提供下载不支持显示),当HTTP头的媒体类型请求为Accept: Text/HTML时,则需要提供基于HTML的、适合阅读的格式。
当参引的URI标识的是信息资源时,服务器成功响应返回给客户端的HTTP代码,即HTTP 200;对于非信息资源被参引时,服务器无法返回一个表达,而是根据内容协商机制,数据源会返回给客户端HTTP 303代码,即重定向到描述该非信息资源的信息资源地址,客户端再次请求,得到一个描述非信息资源的信息资源。除了内容协商和重定向之外,非信息资源的URI由相关信息资源和片断标识符(如#)组成,也能够实现参引。
关联数据以RDF模型来表达事物、特性及其关系。RDF对资源的表达通过一系列的三元组来实现,每个三元组由主语(Subject)、谓词(Predicate)和对象(Object)三个部分组成,构成一个声明。主语是URI所标识的资源;对象可以是一个字符串,如字母、时间、数字等,也可以是一个URI,是与主语有关的其他资源的标识符,即RDF链接(RDF Link);谓词表明了主语和对象之间的关系,谓词也可以是URI,比如来自某一词表或URI集合。RDF链接不仅可以链接同一数据源中的资源,还可以与其他数据源链接,使得用户能跟随RDF链接浏览整个数据Web。RDF链接是数据Web的基础,它将独立的资源编织成数据Web,通过数据Web,关联数据浏览器或网络爬虫能够遍历整个网络[ 4]。
如何将已有的数据或新生成的数据发布为RDF三元组,是关联数据发布的核心。通常需考虑待发布数据的规模、更新频率和当前的存储方式。一般来说,RDF数据有以下4种生成方式。
(1)生成并发布静态RDF文件。这是一种最简单的关联数据发布方式,即将静态的RDF文件,通过Web服务直接进行发布。静态RDF文件可以手工创建,如发布个人的FOAF文件或RDF词表等,也可以通过软件将已有数据转换为RDF文件输出。这种方法适合数据规范不大或将较大的文件可拆分发布的情况,同时需要注意正确地配置MIME类型,并为非信息资源对象设置URI。
(2)通过关系型数据库的RDF转换实现。对于关系型数据库,关联数据可以看作是数据表的一种视图,可以使用某些工具来实现这种视图。如D2R(Database to RDF)服务模式基于数据库和目标RDF术语间声明的映射,能够对关系型数据库产生一个关联数据视图,并支持RDF浏览器和SPARQL端点对关系型数据库的访问,其核心是正确地实现和配置映射关系。D2R服务模式的具体应用系统有柏林DBLP书目服务器、汉诺威DBLP书目服务器、柏林自由大学Web系统小组服务器以及欧共体国家和地区服务器。
(3)通过其他类型信息的RDF转换实现。对于CSV、Excel、BibTeX格式的数据将其转换为RDF格式,可使用一些RDF化的工具,如ESW Wiki的ConverterToRdf ,SIMILE的RDFizers;将转换后的RDF存储在相应的RDF存储器中。理想的RDF存储器具有关联数据界面,即支持数据的Web获取。对于不支持关联数据界面的RDF存储器,可以选择支持SPARQL端点的存储,并将Pubby作为关联数据界面,置于SPARQL端点前。DBpedia采用的就是这种方式。
(4)通过对已有应用或Web API的封装来实现。越来越多的Web应用通过Web API提供自己的数据,如eBay, Amazon, Yahoo, Google and Google Base。各种不同的API提供了多样化的查询、检索接口以及多种格式的返回结果(如XML、JSON或Atom),造成了搜索引擎抓取和一般数据浏览器访问的困难。关联数据对Web API进行封装能够一定程度上克服这些问题,封装器可以将HTTP URI分配给由API提供的非信息资源,当被参引的URI请求为Application/RDF+XML时,封装器能够重写客户端的请求为相应的API,并将API请求的结果转换为RDF格式并发送回客户端[ 4]。
基于关联数据发布的基本要求,Wikipedia的关联数据发布首要问题是结构化数据的抽取与RDF化的表达。Wikipedia的文章主要是自由文本,因此,要进行RDF化的表达和网络获取,首先要进行数据的结构化处理。实际上,Wikipedia包含多种类型的、具有结构化特征的数据。
MediaWiki是运行于Wikipedia后台的软件。它所提供的所有编辑、链接、元数据标注都是在文章的文本内、通过增加特殊的语法结构来完成的,也就是说,无论是结构化的还是非结构化的数据,都以一种WikiText格式来表示。因此,通过解析文章的文本语法,可以获得结构化的信息,WikiText的结构如下[ 5]:
==heading ==
this is a paragraph
* this is a list item
* this is a another list itme
[[Wikipedia|link to article]]
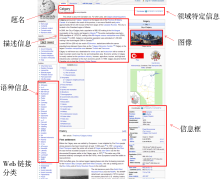
MediaWiki通过描述模板生成了大量结构化数据,如图1所示的题名、分类信息、图像、地理坐标、与外部Web页面的链接、Wikipedia不同语言版本之间的链接、信息框(Infobox)等。
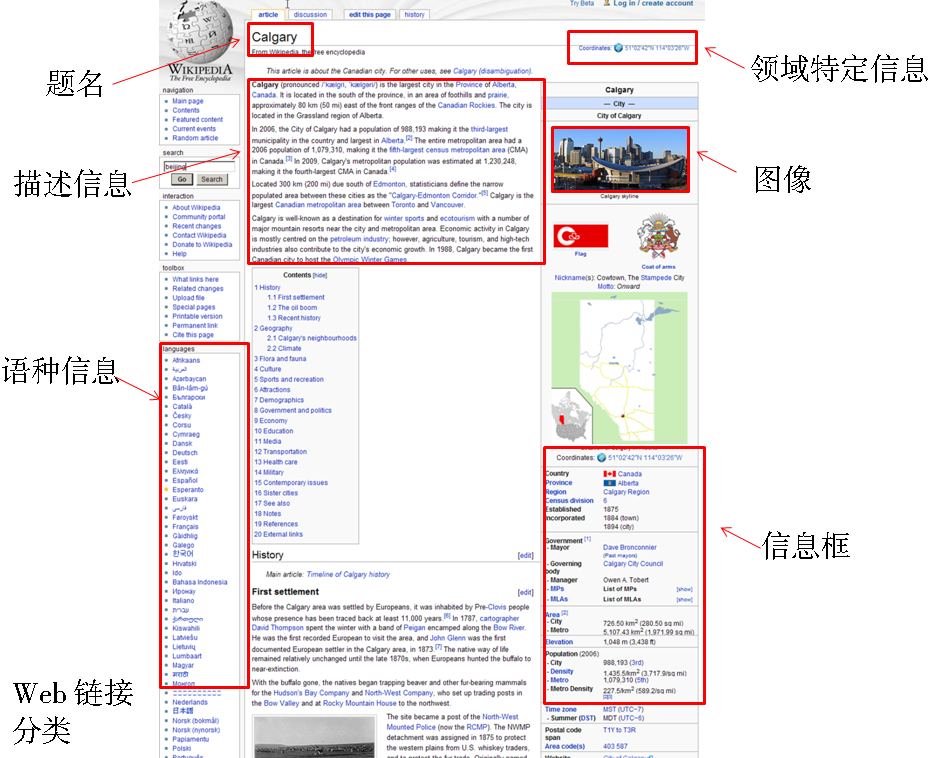 | 图1 Wikipedia页面的结构化数据 |
描述模板由模板名、字段名和字段值组成[ 5],如下所示:
{{ TemplateName
| field1=value1
|field2=value2
|field3=value3 }}
描述模板分两种:
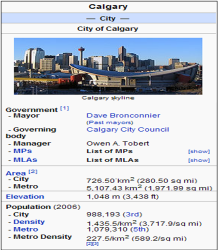
(1)信息框模板(Infobox Template),含有文章所讨论的主题和各种分面,通常这部分数据位于页面右侧的独立区域,是最重要的结构化数据来源,如图2所示。针对这部分信息,抽取算法可以检测所使用的模板,并利用模式匹配识别它们的结构,从而解析并转换为RDF三元组。由于信息框模板系统经过了一段时间的演变逐渐形成,因此缺少统一的规范,例如不同的模板对相同的属性可能使用不同的名称。信息框的早期抽取算法采用通用处理,将属性名称和值直接转换为三元组,对类似Birth Place和Place of Birth这样的相同属性是按不同名称处理的,而新的基于映射的抽取算法引入了DBpedia本体,基于模板与本体之间的映射来解决这个问题。
(2)非信息框模板,主要用于链接信息的描述,如链接到一个地图中的坐标、同主题的文章等。模板简化了抽取结构化数据和转化为其他格式的工作,因为数据是一致的,很容易解析为结构化的格式。在DBpedia中,所有从Wikipedia中抽取而来的实体都被分配了一个唯一的URI,形式为http://DBpedia.org/resource/Name,而这个Name是从原Wikipedia文章的URL中取得的,形如:http://en.wikipedia.org/wiki/Name[ 6]。
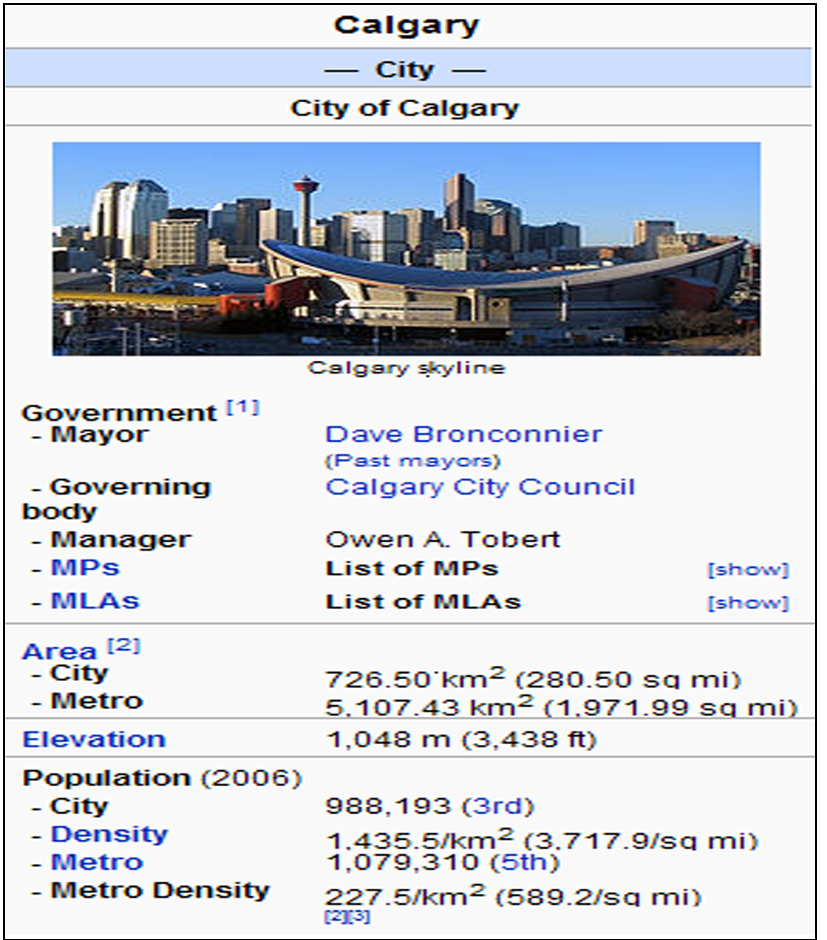 | 图2 信息框的表现及编码[ 6] |
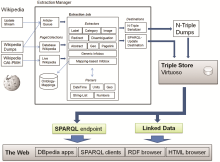
从结构化数据抽取的工作流来看,主要包括几个部分:页面收集器(PageCollection)是本地或远程Wikipedia文章源的抽象;目标器(Destination)存储或设置是否连续抽取RDF三元组;抽取器(Extractor)将特定的Wiki标记转换为三元组;解析器(Parsers)通过识别数据类型、不同单元之间的转换值和将标记拆分为列表来支持抽取器。抽取业务将页面收集、抽取和目标器组成一个工作流。这个框架的核心是抽取管理器,用来管理将Wikipedia的文章传送给抽取器,并将输出提交给目标[ 7]。结构化数据抽取与发布的系统框架如图3所示:
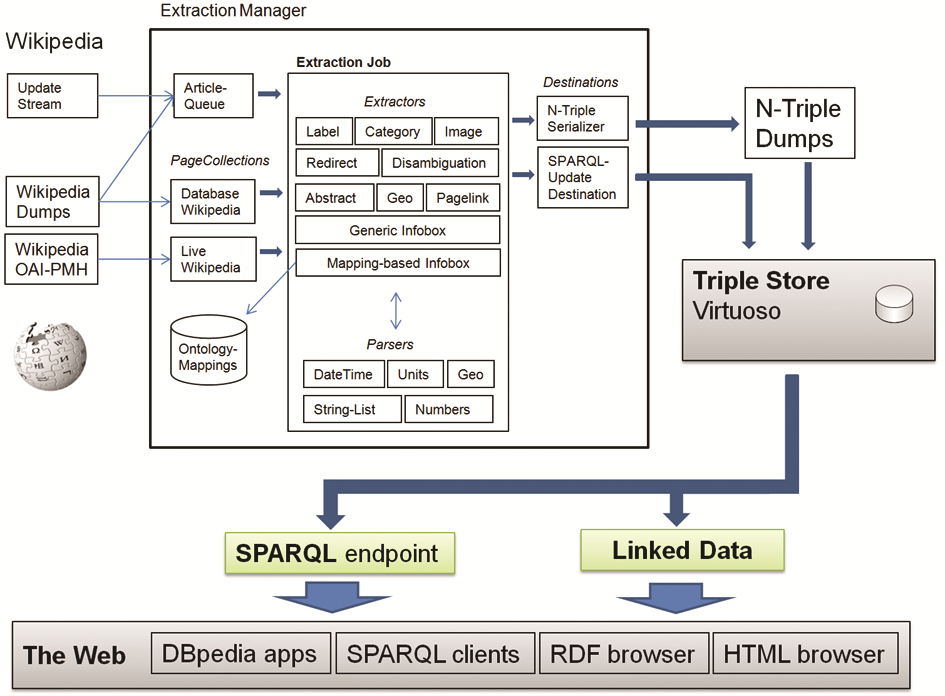 | 图3 结构化数据抽取与发布的系统框架[ 7] |
结构化数据经抽取并转化成RDF文件之后,存储于OpenLink Virtuoso存储器中,它能够提供SPARQL端点。为了获得关联数据视图,在SPARQL端点前面还部署了Pubby,能够为SPARQL端点提供一个关联数据界面。
在Web上获取关联数据,主要有以下三种方式[ 4]:
(1)关联数据参引方式。关联数据要求以HTTP URI标识资源,通过Web可以参引并得到相应的资源RDF描述及相关资源的RDF链接。具体方式包括:关联数据浏览器,如Disco、Tabulator、OpenLink Data等;语义爬虫,如SWSE、Swoogle等;语义Web查询代理,如Semantic Web Client Library和SemWeb Client for SWI Prolog等。
(2)SPARQL端点方式。SPARQL是一种基于模式匹配的RDF数据查询语言,SPARQL端点支持SPARQL协议的语言处理服务,能够接收客户端的查询请求,并对RDF数据源进行模式匹配,将结果返回给客户端。用户可以通过SPARQL端点,像使用SQL语言查询关系型数据库一样,在Web上精确地获得所需要的数据。
(3)RDF转存文件方式。将数据集中的RDF数据以某种序列化方式,如RDF/XML, N-Triples等格式输出,并提供下载,实现关联数据的获取和使用。
DBpedia支持上述三种通用的关联数据获取方式,可以通过Pubby关联数据界面、关联数据浏览器和各种爬虫来获取,同时支持SPARQL服务(http://DBpedia.org/sparql)和RDF文件下载(http://wiki.DBpedia.org/Downloads),并提供了丰富的用户界面和功能来促进DBpedia数据的多样化使用[ 8]。
(1) DBpedia与Web页面的简单整合
DBpedia是一种非常有价值的通用数据源,其数据可以内嵌入各种Web页面中实现简单的整合。例如,从DBpedia查询到一个数据表,包含有德国首都、非洲音乐家、计算机游戏等多种结构化数据,通过客户端的JavaScript或者服务器端的PHP语言将这些查询到的数据表嵌入到用户的页面中,并基于Wikipedia庞大的社区维护,通过DBpedia保持更新。
(2) 查询DBpedia.ORG
DBpedia.ORG提供多种形式的查询。它允许用户浏览DBpedia数据集,并且通过RDF链接到其他数据集如GeoNames、RDF Book Mashup或者是DBLP Bibliography而获得更多的信息。与基于关键词的Web常见的全文检索方式不同,结构化数据的查询提供了对数据关系的增值性使用,DBpedia利用数据关系,提供了从不同的维度和分面,逐步限定检索结果的功能。在查询的同时,DBpedia还结合了浏览功能。如检索关键词“Scorsese”,得到关于导演Martin Scorsese的介绍和其执导的电影,以及参与这些电影的演员。检索结果采用类似于PageRank的排序方法,引用的文章越多,则排序越靠前。
用户在得到排序的检索结果的同时还得到一个Tag云图。Tag云图来自于检索结果集所涉及的各个类,采用的分类标准是DBpedia分类和YAGO的分类。Tag云图可以帮助用户将检索结果缩小到特定的实体类型,比如演员是一个实体类型,即使一个用户输入的检索词没有包括任何关于演员的关键词,仍然可以通过Tag云图进行限定或精细化查询。
(3) 基于关系的查询构造
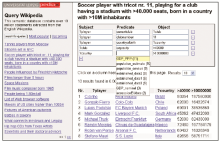
DBpedia提供了基于图模式的查询构造器。用户可以基于多个元组对知识库进行查询。对每一个三元组,有三个文本框分别针对主语、谓词和对象,用于变量、标识符或过滤器的输入。由于DBpedia中存在大量的数据模式,因此,用户在构建查询时必须要得到一些指引和建议。例如当用户在其中一个表格框中输入标识名称时,一个先期执行的查询会提供合适的选项。这就能确保所提出的标识符与图模式是真正关联使用的,并确保查询实际能够有结果产生。如图4所示,查询一名足球运动员,其球衣号码为11号,所效力的俱乐部拥有4万个以上坐位的主球场,并出生于人口大于一千万的国家;该查询需求采用多个三元组描述,并相应地输入查询构造器中,当以“?country”绑定国家变量,并限定其对象大于一千万时,系统会自动提供一系列谓词供选择。
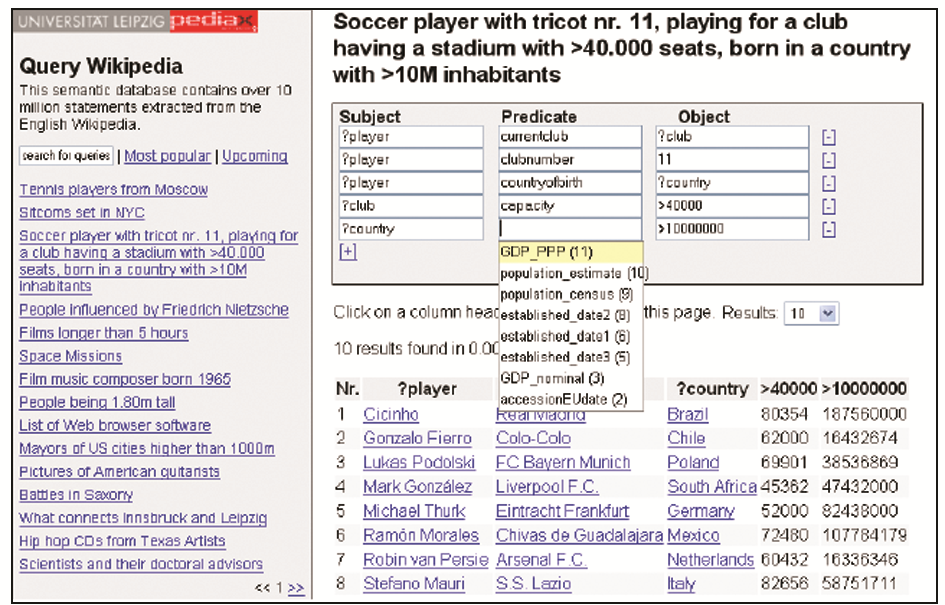 | 图4 查询构造界面[ 8] |
(4) 第三方用户支持
DBpedia的目标是支持各种针对Wikipedia的应用构建混搭平台。有大量的第三方应用使用DBpedia数据集,DBpedia经许可和授权,可提供数据集RDF文件的下载和转存。运行于Karlsruhe大学的Semantic MediaWiki,已经导入了DBpedia的数据集;WikiStory能够使用户对Wikipedia文章中的人物按时间线进行浏览;Object Sheet JavaScript可视化数据环境,允许基于DBpedia数据进行总表分析。
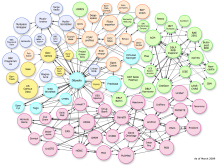
通过RDF链接实现不同数据集之间的关联,是关联数据技术应用最大的价值所在。RDF链接可以使Web冲浪者使用关联数据浏览器从一个数据源中的数据游历到另一个数据源,从而获得更多、更全面的信息;RDF链接还可以供搜索引擎和网络爬虫追踪,而爬行下来的数据可以进行更复杂的查询和检索。DBpedia与许多大规模的数据集和本体(如美国人口统计、GeoNames、 MusicBrainz、DBLP Bibliography、WordNet等)实现关联与互操作。由于广泛的主题覆盖面,DBpedia具有与各类大型数据集的通用数据,因此,被各种数据集首选作关联目标,而与DBpedia关联的数据集又通过DBpedia为中介,彼此相互关联,因此,DBpedia被称为关联中转站(Interlinking Hub)。图5显示了当前与DBpedia相关联的数据集,总计约2亿个RDF三元组。通过这些RDF链接,用户可以从一个DBpedia的计算机科学家链接到其在DBLP数据库中的出版物;从一个DBpedia图书看到来自于RDF Book Mashup的书评和售价;或者从一个DBpedia中的乐队到由MusicBrainz或DBTune提供的乐队歌曲[ 8]。
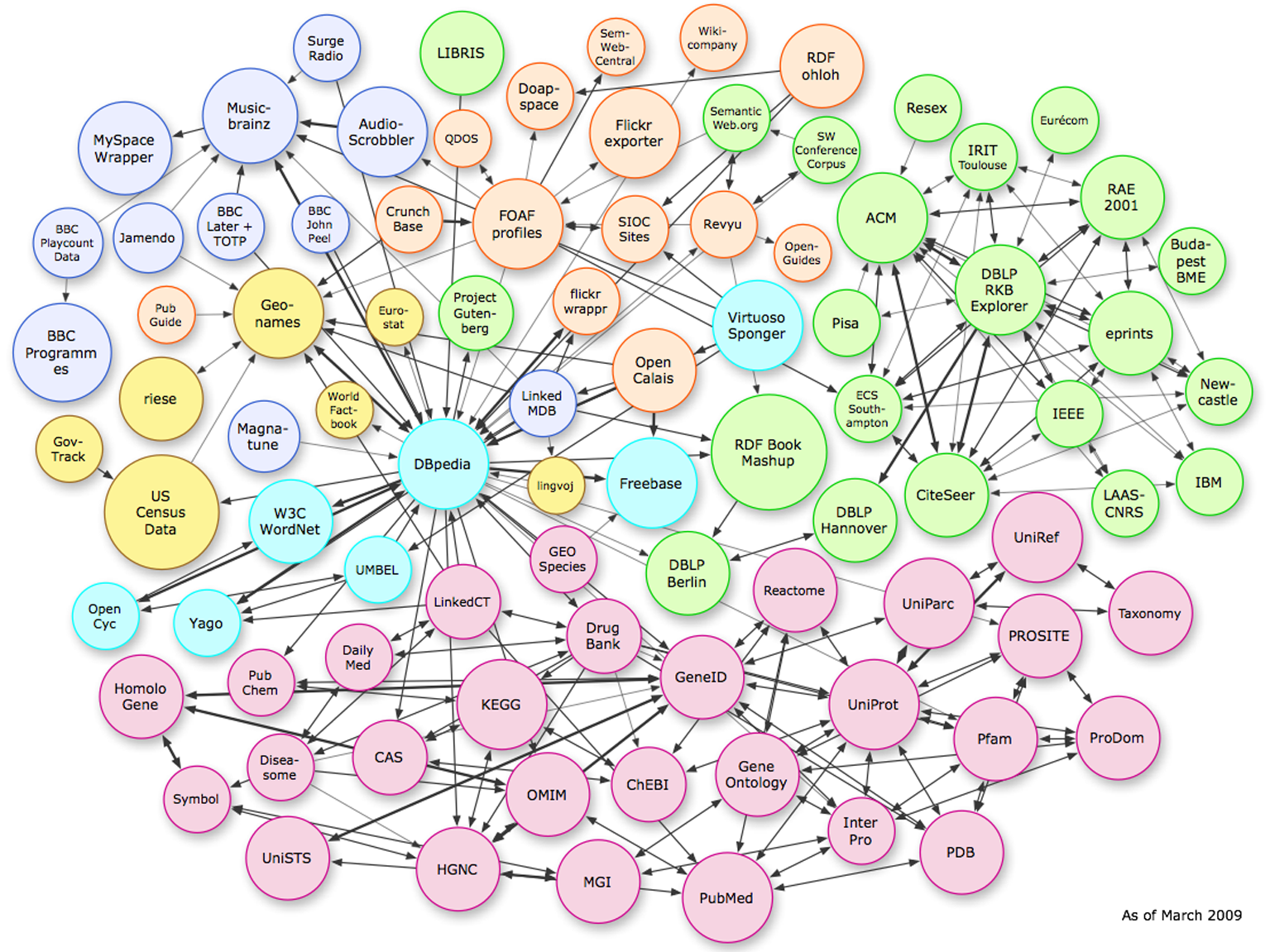 | 图5 与DBpedia关联的数据集 |
数据之间的RDF链接表现为三元组中谓词的使用,而应用领域决定了选择哪种RDF属性作为谓词。例如,在网络人际交往领域经常使用的链接属性为foaf:knows、foaf:based_near和foaf:topic_interest。最常见、最通用的链接属性是owl:sameAs,用于指向同一对象(非信息资源)的两个声明之间的关联。owl:sameAs链接表明两个URI引用实际上指的是同一事物。因此,该属性也用于映射不同的URI别名。
RDF链接可以通过人工设置生成,如FOAF文档。设置RDF链接,可以参考Linking Open Data Datasets了解开放数据源。选中特定的数据源之后,手工检索测试待链接的URI,如果数据源没有提供SPARQL查询或HTML Web表单检索,则可以使用Tabulator或Disco这样的关联数据专用浏览器来检验URI。此外,还可以借助于类似Uriqr或 Sindice这样的服务检索到适合链接的URI。Uriqr提供人名检索,用于发现人物URI,检索结果按该URI被其他RDF引用的权重排序,供人工判断挑选出最适合的URI。Sindice是对语义Web的索引,可检索哪一个数据源包括了某一个URI。因此,恰当地使用这类服务,有助于选择合适的URI链接目标。由于存在HTTP 303重定向,所选择的URI有可能是描述非信息资源的信息资源URI,这种情况下,应确保链接到的是非信息资源,而不是关于它的描述文档。
对于大规模的数据集,不适宜采用手工设置RDF链接,而需借助于一定的关联算法在不同数据集之间生成自动关联。目前还缺少有效、通用、易用的自动关联工具。因此,常见的做法是针对特定的数据源,开发专用的特定数据集的自动关联算法。
常见的算法有两类:
(1)基于模式的算法,即基于特定的命名模式。在各种领域,有各自普遍使用的命名模式,如出版界有ISBN号、金融界有ISIN号,如果这些标识被用做HTTP URI的一部分来标识特定的资源,就可以使用简单的模式匹配算法生成RDF不同资源之间的RDF链接。例如RDF Book Mashup采用ISBN号作为URI的一部分,《哈里波特与混血王子》一书的URI为http://www4.wiwiss.fu-berlin.de/bookmashup/books/0747581088。 DBpedia遍历其所有图书的ISBN号,生成一个与Book Mashup相应的URI,并创建DBpedia图书与生成的URI之间的owl:sameAs链接。应用此算法, DBpedia产生了9 000个内部RDF链接。
(2)基于属性的关联算法,即在没有通用标识符的情况下,将事物的属性特征作为生成自动关联的依据。例如DBpedia与GeoNames都包含有地理名称,要映射两者的重合部分,可通过识别相关属性的方法实现。GeoNames使用了基于属性的启发式算法,基于文章题名和语义信息如经纬度、国家、行政区划、地貌特征、人口和分类等,对两个数据集分别进行属性对比,最后得到70 500个相匹配的地名,使用owl:sameAs相互链接。其他算法如:BBC的关联数据,采用了词表映射、基于图的属性相似度比较等多种方式,实现与DBpedia的映射链接[ 4, 9]。
综上所述,关联数据是一种先进而简单易行的数据组织与发布技术。其信息组织的颗粒化程度更加细化、更加结构化和语义化,且能够支持自动和机器处理;通过统一的数据模型 (RDF)、统一的存取API (RDF/SPARQL)、一致的语义描述方法 (RDFS/OWL),提供了统一、标准、自助、去中心化的数据整合和混搭平台,为各类用户和应用提供了富于想象力的数据空间。
对于拥有大量结构化数据的图书馆界来说,关联数据的应用值得引起关注和大力推广。目前,瑞典联合目录系统将大约175个成员馆的600多万条书目记录及用户的书目评注和书目数据之间建立了关联,通过Web页面进行了RDF发布,同时与DBpedia进行了规范记录的链接。美国国会主题词表采用SKOS编码之后,整个LCSH在Web上开放、共享,成为具有相互联系并且可参引的数据,为网络资源利用LCSH建立资源之间的直接联系提供了一个很好的基础[ 10]。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|