


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于Web-Harvest的Web信息抽取系统的设计与应用
[詹佳佳 ]
]
]
|
|


详细介绍信息抽取开源软件Web-Harvest,并在其基础之上进行功能扩展和改进,设计一个通用性强的Web信息抽取系统,重点阐述开发系统的设计思想和系统流程,并简单介绍系统的数据库表设计。最后,介绍该Web信息抽取系统的应用。
In this paper,an open source software for information extraction called Web-Harvest is detailly introduced firstly.With functional expansion and improvement,a Web information extraction system based on Web-Harvest is designed.The paper focuses on the system design idea and system process,and the design of database tables is also briefly described. Finally,the application of the system is introduced.
随着Internet的发展,网络上信息资源越来越丰富。由于某种研究或应用的需要,组织和个人往往会通过人工或者程序来获取网络上的各种信息。例如,政府会通过监测网络舆论以及时控制非法舆论的传播;企业会通过浏览竞争对手的网站来获取竞争情报;消费者会通过比较各个商家提供的产品信息(如价格等)来进行购物决策等。因此,如何在“信息海洋”中快速准确地采集有用信息,成为各种信息应用的关键研究课题。
信息抽取(Information Extraction, IE) 正是解决这个问题的一种方法。它把文本里包含的信息进行结构化处理,变成表格一样的组织形式[ 1],以供后续应用。而Web信息抽取则是从 Web页面所包含的无结构或半结构的信息中识别用户感兴趣的数据,并将其转化为结构和语义更为清晰的格式(XML、关系数据、面向对象的数据等)[ 2]。
近年来,国内外涌现出多种可行的信息提取方法,其中基于包装器进行抽取是比较实用的。李宏伟等人针对网页结构的不确定性和易变性,设计了一种基于预定义模式的Web包装器进行信息抽取[ 3]。这种方法采用预定义的方式,其缺点是采用手工操作,比较复杂。针对这种不足,有学者提出一种包装器产生系统和基于激发学习的框架,通过设计一个用户交互接口来实现信息的半自动抽取[ 4],也有人提出通过基于模式发现的方法来实现抽取的全自动化[ 5]。刘桂峰等人则提出了一种基于DOM树的Web数据对象自动抽取方法。该方法首先将网页解析为DOM树,然后将结构相似的子树抽取出来作为侯选数据对象,再计算候选数据对象的内容相似度,内容相似度低的则为数据对象[ 6]。刘云中等人也提出了一种基于隐马尔可夫模型的文本信息抽取方法,利用文本排版格式、分隔符等信息进行文本信息抽取[ 7]。此外,还有一些学者利用开源信息抽取工具,在其基础上进行改进来实现信息抽取。陈俊彬等人以Heritrix为基础,结合HTMLParser的信息抽取,提出一种基于Heritrix的精确抽取方法,并实现对论坛信息的精确抽取[ 8]。徐健等人则通过在Nutch基础之上进行多种扩展和改进,提出基于Nutch的Web网站定向采集系统[ 9]。
前人通过各种方法实现了Web信息抽取,但仍无法满足现实工作中的应用需求。由于现实中人们的信息抽取任务和抽取需求具有多变性,加之Web信息的多变性,开发出一种性能好、应用广的抽取系统十分困难。因此,本文尝试设计一种信息抽取系统,既可以实现信息的精确抽取,又具有较强的通用性。
在开源信息抽取工具Web-Harvest的基础上,参考前人采用包装器抽取信息的思想,设计基于Web-Harvest的Web信息抽取系统。特别针对Web-Harvest本身在抽取过程管理、数据集成等方面的不足,进行了功能上的拓展和改进。在系统设计中,采用松耦合结构架构,将信息抽取各过程与抽取过程管理控制独立并分别设计,使系统具有较好的可拓展性,有利于信息抽取的后续应用。
Web-Harvest是一种采用Java语言编写的开源Web信息提取工具,提供了一种从所需的页面上提取有用数据的方法。它主要运用了XSLT、 XQuery、正则表达式等技术来实现对Text/XML的操作[ 10]。
相比其他抽取工具,Web-Harvest具有以下优点:
(1)通过执行基于XML 配置文件的方式来实现信息抽取,对于每个特定的抽取任务只需要编写一个配置文件,具有较好的通用性。
(2)定义了一系列用于处理数据和控制流程的处理器集合,同时采用链式方式执行,灵活方便地构建抽取规则。
(3)提供了能被容易地集成到配置文件里面的实时的脚本语言,如BeanShell和JavaScript.BeanShell,处理能力强大。
(4)开源软件,通过编写自己的Java 方法可以轻易扩展其提取能力。
笔者对三个典型的Web抽取工具进行了比较,结果如表1所示:
从表1可以看出,与其他工具相比,采用Web-Harvest进行信息抽取拓展性更强,但其在抽取过程管理和处理效率方面存在不足。因此,针对这些不足,在Web-Harvest基础上进行相关功能的拓展,设计Web信息抽取系统。
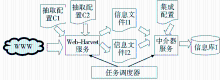
整个Web信息抽取可分为抽取和集成两个过程。可利用Web-Harvest来实现抽取的过程,以实现抽取的灵活性;集成过程则采用自编的中介器(Mediator)进行数据集成与存储。针对Web-Harvest开源软件本身没有信息抽取过程管理的不足,本系统设计了任务调度器,对信息抽取过程进行合理的调度和控制。Web信息抽取过程如图1所示:
 | 图1 Web信息抽取过程 |
(1)抽取过程:包含预定义阶段和抽取阶段。
①预定义阶段:需要对所抽取的网页集进行分析,预先定义好抽取规则、抽取字段等相关信息。通常情况下,根据实际所要抽取的主题信息,按照需求对少量的且有典型性的网页源代码进行分析,由此得到具体信息来预定义配置文件。在定义配置文件时,要充分考虑利用Web-Harvest定义的处理器来抽取信息,采用如XSLT、XQuery和正则表达式等操作Text/XML 的相关技术来配置抽取规则。需要注意的是,Web-Harvest配置文件各个处理器需要由固定语法来书写。
②抽取阶段:Web-Harvest抽取程序读取预定义的配置信息,按照配置文件中的执行步骤进行相关处理,将抽取结果存放在中间的信息文件。
(2)集成过程:包含配置阶段和抽取阶段。
①配置阶段:用户需要自定义元数据存储配置文件,用于数据的集成。可定义存储的具体关系数据库URL,数据表名和表的模式,信息文件各字段与数据表字段的对应关系等。同时,由于Web数据具有类型不明显、表示多样性的特点,需要对各字段指定唯一的数据类型和默认值。在对某个主题进行信息抽取时,由于各抽取源不统一,信息文件间可能出现语义不一致的情况,如度量单位不统一,也可以对该字段指定单位转化关系。此外,还必须规定转换出现异常的处理方式,以保证集成程序的健壮性。
②抽取阶段:中介器根据元数据存储配置文件,对信息文件进行处理,并将记录存储到指定的数据表中。
(3)过程管理:将Web-Harvest和中介器封装成独立的外部服务,并由任务调度器进行调度与控制。
由于Web信息更新快,现实中的信息抽取工作往往是周期性的、重复的。因此,将信息抽取工作分为三个层次进行调度管理:计划,任务和服务。
①服务是最基本的单位,它表示对应的外部程序实体(如Web-Harvest和中介器等),可以直接运行。定义一个服务的过程如图2所示:
 | 图2 定义服务的过程 |
服务的运行需要服务规则的支持,而不同的服务使用的规则不相同,因此,定义规则要有两层的过程, 如图3所示:
 | 图3 定义服务规则的过程 |
②任务(即处理)是对服务组合的包装。用户可以选择服务(包含抽取服务、集成服务)的任意组合并设置运行顺序。因此可在服务和服务规则定义完成后,定义一个任务(处理)。定义的任务如图4所示:
 | 图4 定义任务的过程 |
③计划可由一系列的任务来组成,是最高的调度单位,运行时间点和运行周期等信息均在计划中定义。定义一个计划的过程如图5所示:
 | 图5 定义计划的过程 |
因此,整个调度过程如图6所示:
 | 图6 任务调度的过程 |
用户可以自定义抽取计划,定时执行或者周期性地运行抽取任务。在抽取任务中,用户可以选择服务(包含抽取服务、集成服务)的任意组合。抽取服务和集成服务的运行需要输入相应的配置信息。用户可以按照需要对抽取和集成阶段进行相关配置。系统提供了对抽取和集成阶段需要的配置文件进行动态管理的功能,以方便用户信息抽取的操作。
将Web-Harvest和中介器封装成外部服务进行管理,对服务执行所需的配置信息也进行管理,使得系统具有较强的可扩展性,方便后续应用的添加。
信息抽取的系统流程设计如图7所示:
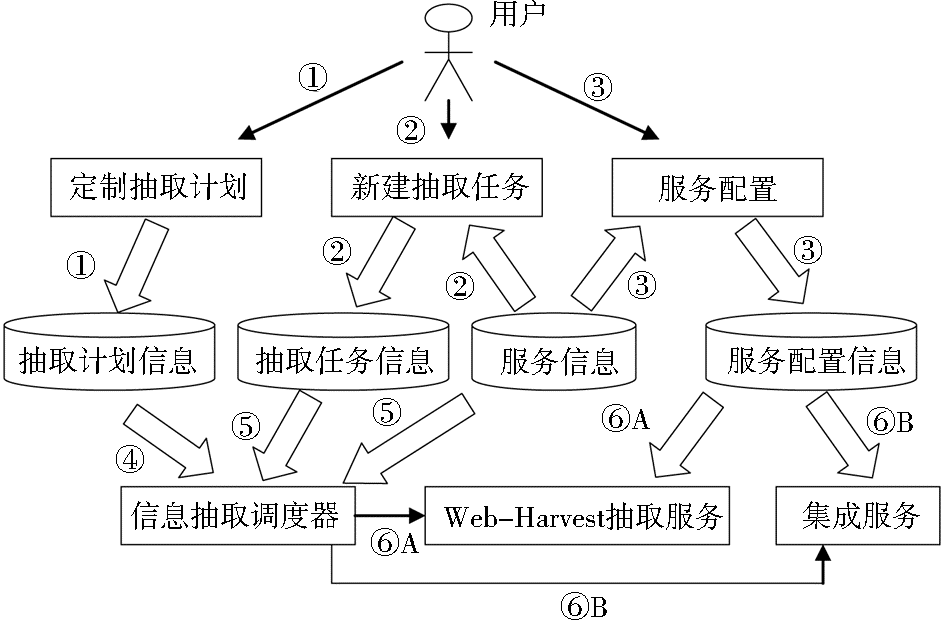 | 图7 信息抽取的流程 |
(1)定制抽取计划:用户定制抽取任务的运行周期数以及运行的时间点等相关信息,写入到抽取计划信息表中。
(2)新建抽取任务:用户选择一个服务或者多个服务组合的任务。系统首先读取服务信息表中所有的服务条目,供用户添加服务。用户设置服务运行先后顺序等信息后,写入到抽取任务信息表中。
(3)服务配置:用户在新建抽取任务时,需要为添加的服务指定服务需要的配置参数等信息。系统首先读取服务配置信息表中原有的配置记录,供用户选择原有的配置信息;用户也可按照需要,新建配置信息。用户配置完毕后,写入到服务配置信息表中。
(4)信息抽取调度器读取抽取计划信息表,根据计划信息和当前时间点判断是否启动抽取任务。
(5)当某一计划到达时间点时,信息抽取调度器执行该计划。首先,信息抽取调度器读取抽取任务信息和服务信息,为下一步线程的启动做准备。在线程启动前,调度器判断当前系统资源(CPU和内存等)的使用情况,并根据实际情况对线程调度进行控制。
(6)在系统资源运行允许的条件下,调度器按照任务信息启动对应的服务线程。
①Web-Harvest服务线程启动,并读取对应的配置信息,进行信息抽取。
②数据集成服务线程启动,读取对应的配置信息,对抽取得到的文件进行数据集成。在调度过程中,系统记录线程运行的各种状态。
经分析,系统设计的数据表主要包括用户表、计划表、任务表、服务表和配置表。采用Visio工具对系统主要数据表进行建模,如图8所示:
 | 图8 数据表设计图 |
在当前系统实现中,服务信息记录中仅包括Web-Harvest服务和中介器服务,服务配置信息也仅仅包含上面两个程序相关的配置。服务信息表中,记录了服务ID、服务的名称、程序调用的接口、服务描述等信息。服务配置信息中,记录了配置信息ID、配置信息描述、所属服务ID、配置文件路径、相关描述等信息。
当系统添加后续服务功能时,除了独立开发服务程序,仅仅需要在服务表中添加一个数据记录,填写服务的名称和服务调用接口。如果新增的服务有输入和输出参数,则需要提供对应的配置文件,然后在配置表中添加相应的数据记录。
在该信息抽取系统设计中,采用了基于模板配置的信息抽取和基于配置的数据集成,在网络中具有较广的通用性,如网络舆情采集、企业竞争情报获取、产品价格库的建立等。用户可以根据自己感兴趣的主题需求,定制抽取计划,进行信息的采集。同时,系统具有一定的可拓展性,可以在系统中方便地开发和添加信息抽取的后续服务,例如信息查询、信息挖掘分析等。
下面以抽取笔记本最新报价(来自太平洋今日报价,网址为:http://product.pconline.com.cn/notebook)为例,对该系统的应用进行相关阐述。
将对笔记本报价的相关字段信息(包括产品、价格、趋势、报价商家数)进行抽取,如图9所示:
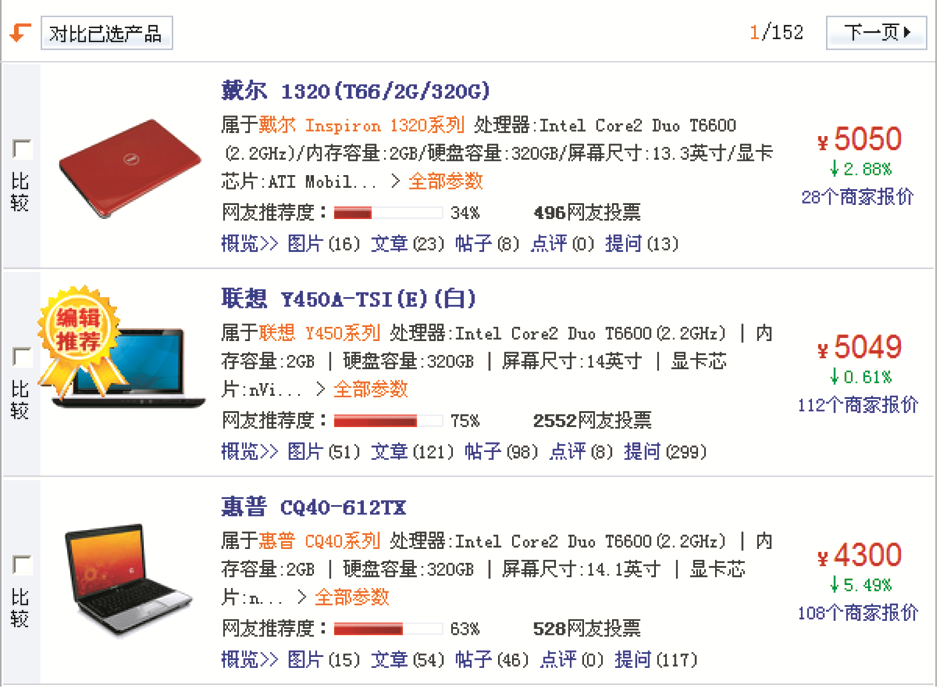 | 图9 太平洋网今日报价的网页部分信息 |
(1)编写Web-Harvest抽取配置文件,存放到指定的文件夹中,然后在系统中新建服务规则。先将该规则类型选定为Web-Harvest服务,然后填入配置文件的路径等信息(假设服务表记录中已存在Web-Harvest服务)。
对今日报价的信息进行抽取的配置文件脚本如下所示:
-
-
-
-
]]>
-
-
-
-
-
-
declare variable $item as node() external;
lec $product:=data($item//i[1]/a/@title)
let $value:=data($item//i[1]/a/em)
let $tendency:=data($item//i[2]/a/i)
let $num:=data($item//i[3]/a)
return
]]>
]]>
为让读者更了解Web-Harvest,下面对处理步骤进行详细介绍:
①第一段的执行步骤:获取信息列表。
1)下载第一个网页http://product.pconline.com.cn/notebook源代码的内容,清除下载内容里面的HTML以产生XHTML;
2)利用表达式“//a[contains(text(),'下一页') and @target='_self']/@href”获取下一页的链接;
3)利用表达式“//div[@class='productR']”来定位信息块;
4)经过10次的重复查找,得到信息块的列表,并保存在变量prices中。
②第二段的执行步骤:利用上一段的抽取结果来提取相应的信息。
1)在loop循环语句中,迭代变量prices中的每一个item;
2)利用XPath 表达式获取每个item的product、value、tendency和num;
3)将结果保存在notebook文件夹下的price.xml文件中。
抽取配置利用了Web-Harvest自带例子的分页函数进行抽取。分页函数的配置文件脚本如下所示:
-
-
-
-
-
-
-
-
-
-
${sys.fullUrl(pageUrl.toString(),nextLinkUrl.toString())}
-
下载分页列表函数中,参数pageUrl 是指开始的那个页面的URL,参数itemXPath是指要在页面里取得的一个list的XPath表达式,参数nextXPath 是指下一个页面的URL的XPath表达式,而maxloops 是指循环下载的页数,最终返回下载信息列表。
(2)在系统中新建抽取任务,并添加Web-Harvest抽取服务,选择第一步新建的服务规则。
(3)在系统中新建抽取计划,选择第二步新建的任务,并指定该任务立即执行。
经过以上步骤,执行后可以得到信息文件prices.xml,如下所示:
-
-
-
-
以上对抽取服务进行了相关演示,抽取任务可设置为周期性运行,来抽取笔记本电脑每天的价格信息。除此之外,可在抽取任务中添加集成服务、指定集成规则,来对抽取所得的信息文件进行集成,将之存放到指定的数据库中。
本文基于Web-Harvest开源软件,设计了一个通用性强的Web信息抽取系统。该系统基于模板配置进行信息抽取和数据集成。用户可以根据自身需要,定制相关规则,对信息源进行抽取。同时,针对Web-Harvest本身没有对抽取过程进行管理的问题,设计了任务调度器进行抽取过程的管理和控制。此外,系统具有一定的可拓展性,可以方便地添加新开发的后续服务功能。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|