
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于概念格的数字图书馆用户用法细分——数字图书馆用户使用方法的关联规则挖掘
[滕广青, 毕强 ]
]
]
|
|


以概念格理论为基础,用形式概念分析的方法通过对数字图书馆用户使用方法的关联规则挖掘,建立灵活的规则挖掘机制,并依据提取的关联规则对数字图书馆用户进行用法细分,对在更大程度上满足更多用户的个性化需求进行尝试。
Based on concept lattice theory, this paper attempts to set up a flexible rule mining mechanism through a formal concept analysis and conducts a detailed market segmentation of digital library users’ usage according to the association rules extracted with this mechanism to meet the digital library users’ individual demand to a greater extent.
近年来,作为数字图书馆领域研究重点的用户服务研究已经积累了较为丰富的理论成果,但是海量的数字资源和不断追求个性化服务的用户在本质上已经改变了人们对图书馆的传统观念。研究发现,用户期望数字图书馆能够提供所有的互动模式,以便其自行选择来满足需求。这使得已有的基于传统用户细分方法的研究成果已经无法适应现代数字图书馆发展的需要,如何构建面向更多用户的数字图书馆用户细分的理念和方法成为数字图书馆发展建设必须解决的重要问题。
随着数字图书馆建设的相关研究在全球范围内的不断深入,用户研究逐渐成为数字图书馆研究领域中的一个重点内容。国内学者主要从满足用户个性化需求的角度对用户分类、用户偏好、用户体验、用户模型等方面进行了研究[ 1, 2]。其间,客户关系管理理论(CRM)、信息构建理论(IA)、长尾理论(LT)等被相继引入到数字图书馆用户研究领域当中[ 3, 4]。在技术层面上,除了传统的统计计量技术外,数据挖掘技术也逐渐被应用于数字图书馆用户研究[ 5]。国外在数字图书馆用户研究方面除了突出技术色彩和理论交叉性外,另一个显著的特点是更注重从非营利组织营销的角度强调实证研究[ 6, 7]。
在关联规则挖掘领域,自1993年Rakesh Agrawal等率先提出关联规则分析问题,其后相继出现了采用多循环方式的AIS算法、Apriori算法、DHP算法等,以及增量式更新的FUP算法、IUA算法等和并行发现的DD算法、PDM算法、DMA算法、FDM算法等。随着挖掘算法的不断更新和改进,关联规则挖掘被广泛地应用到商业零售、医疗保健、金融保险、工业制造等诸多领域。进入21世纪后,概念格作为一种新的数据分析和知识形式化处理的工具被广泛应用于关联规则的挖掘[ 8, 9],并取得了一定的成果。
目前,在数字图书馆用户研究与关联规则挖掘研究中,其焦点主要集中于具有显著特征的用户群识别和具有较高支持度的规则提取。对于非主流用户来说,其数据往往被看作是零散无序、杂乱无章的。传统的关联规则挖掘方法几乎都会忽略这些“无足轻重”的数据,转而探寻更具有代表性的模式。而在巨大的利基(Niche)市场驱动下的网络“长尾效应”使得非主流用户的潜在价值已经远远超过主流用户,传统的80/20法则已经被颠覆,“海量的资源+海量的用户+极低的成本”使得人们不得不重新认识数字图书馆的用户信息活动。现代数字图书馆亟需建立一种能够最大程度地满足更多用户个性化需求的用户细分机制。
按照用户使用数字图书馆的行为模式来制定访问体验称为用法细分。一般情况下,一个组织只能满足一种或有限几种用户行为需求,从而“取主要,舍利基”。数字图书馆应该能够在概念格理论基础上改进自身的设计和建设来满足不同行为模式用户的所有需求,考虑面向不同行为细分市场的所有元素,进而实现对数字图书馆用户的用法细分,并以此来满足更多用户的个性化需求。
通过形式概念分析(FCA)构建的概念格是形式背景中概念及其关系的表示形式,其与形式背景是相互对应的,概念格中的概念具有闭合属性[ 6],所以利用概念格模型开展关联规则挖掘问题研究可以实现对规则知识的最佳阐释。
数字图书馆中存储用户使用信息的事务数据库TD可以理解成为一个形式背景K=(U,D,R ),其中U 是数据库TD中的事务集合,D 为数据库中所有可能特征的集合,R 是U 和D 之间的一个二元关系,则存在唯一的一个偏序集合与之对应,并且这种偏序集合产生一种格结构。格中的每一个节点是一个序偶(称为概念),记为(X,Y),其中X 称为概念的外延,Y 称为概念的内涵。令I={i1,i2,……,im}是TD中所有属性的集合,其中每一个元素是数据库中的一个属性,称为项。TD中的每个事务T 是一组项目,且满足T⊆I。一个项集A 就是TD中的属性集合,是I 的一个子集。若A⊆T,则称事务T 支持A。一条关联规则是一个形如A⇒B的蕴含式,其中A⊆I,B⊆I,A∩B=ø,A 和B 分别称为关联规则的先导和后继。关联规则A⇒B在TD中的支持度s 表示数据库TD 中至少有s%的记录同时支持项集A 和项集B,反映了规则的有用性;置信度c 意味着支持项集A 的记录中至少有c%的记录也支持项集B,反映了规则的确定性。即s =|A∪B | / |TD|,c =|A∪B | / |A |。关联规则挖掘就是找出大于最小支持度和最低置信度阈值的关联规则。
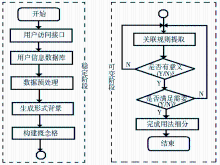
基于概念格的数字图书馆用户用法细分是在基于概念格的数字图书馆用户市场细分研究基础上进行的完善。尽管研究能够充分实现按照最能体现用户群特征的细分变量进行用户市场细分,但仍然没能很好地解决利基市场中的长尾效应问题,大量非主流用户的个性化特征很容易被淹没在数据海洋中。这是由于一般基于概念格的关联规则挖掘方法都是在建格过程中事先植入阈值参数,而为了保障挖掘时间的可行性,事先给定的阈值往往会较高。一旦需要调整相关阈值挖掘更多规则,则必须重新进行运算构建新的概念格结构,如此得到的概念格复用性低,且费时费力。本研究的重点在于建格过程中只考虑对象与属性间的偏序关系(基本建格思想),不考虑阈值因素,概念格的结构不受阈值大小干扰,概念格构建完成后,在不影响概念格结构的情况下挖掘提取不同支持度与置信度阈值的关联规则(特别是低支持度的规则),从而挖掘更多的非主流用户的潜在价值。其基本思路为:先建格,后提取。系统流程图如图1所示:
 | 图1 基于概念格的用法细分系统流程图 |
系统流程图由“稳定阶段”和“可变阶段”组成。
(1)在“稳定阶段”只要挖掘所用的数据源不发生变化,构建出的概念格结构就是稳定的,并且可以在后续的规则提取中复用。这一阶段的关键在于数据预处理环节。由于最终提取的规则总是有支持度和置信度阈值的约束,因此良好的数据预处理对于保证挖掘结果的有效性是十分必要的。
(2)“可变阶段”是系统的核心部分。基于概念格的数字图书馆用户市场细分研究中概念格构建完成后,就可以根据概念格聚类实现用户市场细分。本研究则继续在所得到的概念格基础上挖掘用户使用方法的关联规则。具体技术思路是如果所得到的规则不具有实际意义(一般由领域专家判定),则调整支持度和置信度阈值,再次在原格结构基础上重新提取。如果所得到的规则具有一定实际意义,则根据其是否足以反映非主流用户的用法特征判断其是否满足了细分需要。如果细分要求不能得到满足(例如:反映的仍然是主流用户的特征),则再次调整阈值在原格结构上重新提取被忽略的规则。如果满足了细分要求,则根据所得到的规则完成用法细分。
笔者特意选择使用了基于概念格的数字图书馆用户市场细分研究中相同的数据源。该数据源以实验网站为平台,包含“IP地址”、“页面内容”、“文档类型”、“驻留时间”、“访问时段”、“接入带宽”、“使用频率”等反映用户使用数字图书馆用法行为特征的字段;同时辅以(市场)细分变量数据库,分别识别出“IP地址”中的“城市IP”、“乡村IP”、“教育网IP”等,识别出“文档类型”中的“PDF(多为学术信息且追求质量)”格式、“XLS(多为财经信息且便于统计分析)”格式等。使用相同的数据源有利于更好地说明和反映研究工作的“接续性”和“完善性”。
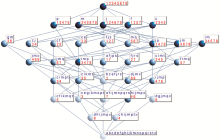
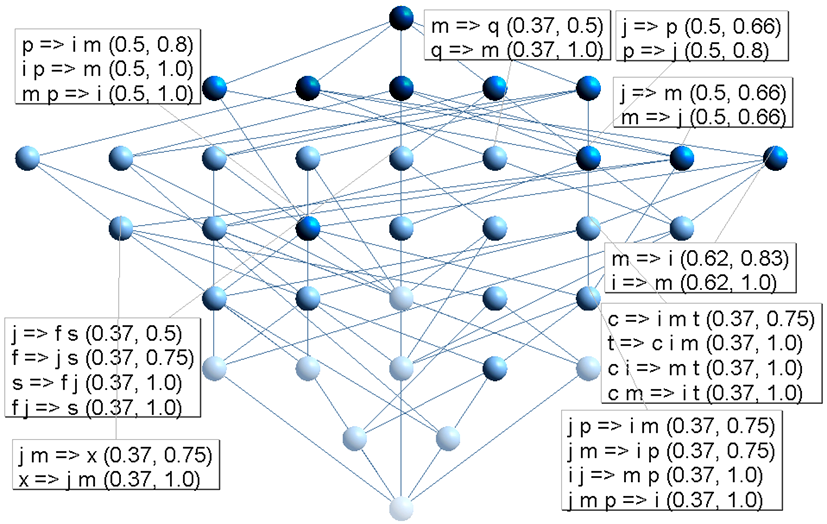
由于本研究的主要目的之一是挖掘用户使用数字图书馆用法的关联规则,加之对于所生成的概念格结构的算法无关性,本研究特别选择了Lattice Miner作为形式概念分析的概念格构建工具。Lattice Miner是构建、可视化和探索概念格(伽罗瓦格)的数据挖掘原型,它尤其适合形式概念和关联规则的生成,并且可以方便地通过调整支持度和置信度阈值发现潜在的规则。由实验数据源产生的初步概念格如图2所示:
 | 图2 初步生成的概念格 |
(注:a教育网IP,b教育发达区IP,c城市IP,d乡村IP/低速接入,e变动IP,f学术信息/PDF,g财经信息,h家居信息,i时尚信息,j驻留时间长,k驻留时间短/一般使用,m HTML,n MP4,o XLS,p白天访问,q傍晚访问,r深夜访问,s高速接入/经常使用,t中速接入,x偶尔使用)
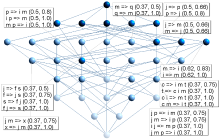
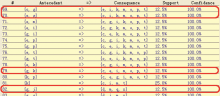
图2中每一个节点就是一个概念,反映了对象与属性的统一,节点颜色由深到浅表示每个概念所包含的对象数由多至少,属性则由少至多。在概念格结构既定的情况下,设置支持度阈值为30%,置信度阈值为50%,获得的关联规则如图3所示:
 | 图3 支持度阈值为30%、置信度阈值为50%情况下的关联规则 |
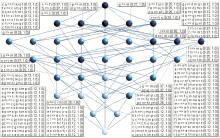
基于概念格的关联规则挖掘不需要像传统的挖掘方法那样事先将相关阈值植入建格过程,而是在概念格构建完成后由领域专家根据需要设置相应阈值,最大程度上简化了规则提取的难度。因此能够方便地通过调整支持度与置信度阈值获得更多的规则。分别将支持度与置信度阈值调整为10%和100%,得到的规则如图4所示。如果有必要,还可以进一步调整相关阈值,从而获得更为细致的规则。
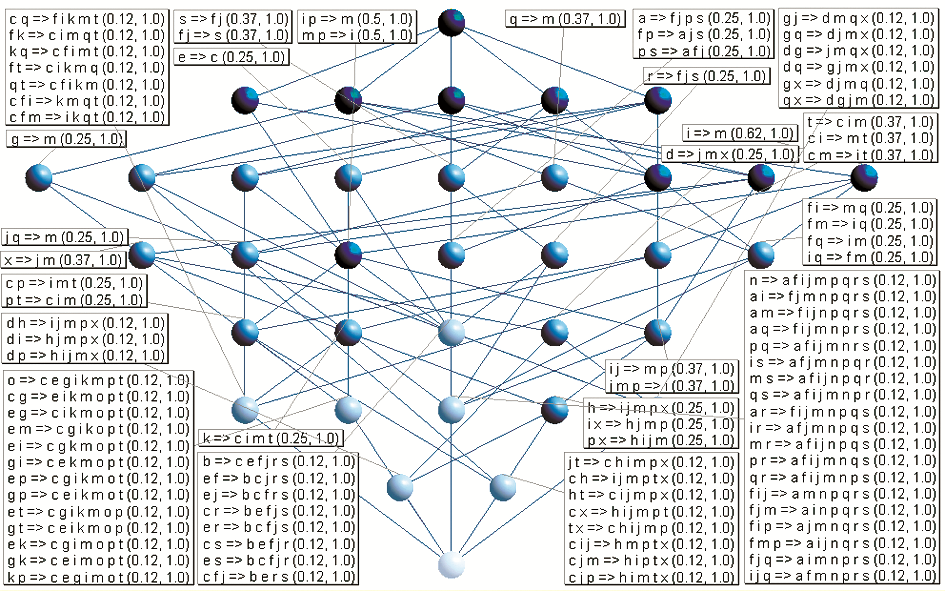 | 图4 支持度阈值为10%、置信度阈值为 100%情况下的关联规则 |
挖掘用户使用数字图书馆方法的关联规则的目的是将其用于指导数字图书馆用户细分,从而满足不同用户的个性化需求,提高数字图书馆用户个性化服务的水平。在已往研究中,一般基于概念格的数字图书馆用户市场细分已经明显优于传统的图书馆用户市场细分,其能够更为科学合理地提供用户细分的口径指标,并且可以提供多粒度的细分机制,应用于一般用户服务标准下的中、小数字图书馆或者普通专业数字图书馆是比较适合的。但是对于更为庞大的数字图书馆系统(资源更丰富、用户更众多)来说,其用户行为模式纷繁复杂,甚至同一个用户也会在不同时段、不同目的的驱使下寻求不同的用户体验。同时,规模越大的数字图书馆其长尾效应越明显,更多的非主流用户往往蕴含着更大的潜在价值。因此,对于大规模和超大规模数字图书馆,采取基于概念格的用法细分的策略对于提高用户个性化服务水平是十分必要的。
(1)以图3中挖掘得到的关联规则为例。规则“j(驻留时间长)=>p(白天访问)”的支持度为50%,置信度为66%。这说明该节点代表的所有用户中有50%的用户在数字图书馆“长时间驻留并在白天访问”,其中在“长时间驻留”的用户中有66%的用户在“白天访问”数字图书馆。至此,可以说以“j=>p”规则对用户进行用法细分得到的仍然是占该节点50%份额的主流用户。但是在另一节点中,规则“j=>fs(学术信息+PDF文档+高速接入+经常使用)”的支持度为37%,置信度为50%。这说明该节点代表的所有用户中有37%的用户使用数字图书馆的用法特征为:“长时间驻留+访问学术信息+PDF文档+高速接入+经常使用”,其中仅“长时间驻留”的用户中就有50%的用户同时具有:“访问学术信息+PDF文档+高速接入+经常使用”的用法特征,如图5所示:
 | 图5 支持度阈值为30%、置信度阈值为50%情况下的关联规则举例 |
(2)如果认为37%的用户份额仍然不足以体现对更多的零散用户的个性化需求的关注,那么在调整支持度与置信度阈值后得到的图4反映出的关联规则中则体现了这一点。在图4的特定节点中,规则“gj(财经信息+驻留时间长)=>dmqx(乡村IP/低速接入+HTML文档+傍晚访问+偶尔使用)”的支持度仅为12%,置信度为100%。这说明该节点代表的所有用户中有12%的用户在访问数字图书馆过程中表现出的用法特征为:“长时间驻留+访问财经信息+在乡村IP以低速接入+访问HTML文档+傍晚访问+偶尔使用”,并且其置信度为100%。根据规则可以假设,这部分用户可能是寻找致富信息的农民,他们的接入速度较低,偶尔使用,访问非学术文档(学术文档多为PDF格式),但是每次驻留时间较长(可能由于使用技巧与熟练程度的问题)。这里也许会有质疑,那些企业家、投资人难道不是“访问财经信息并长时间驻留”吗?根据本研究选用的实验数据源,这一问题在另一个节点中得到了解答。规则“cg=>eikmopt”、“eg=>cikmopt”、“gk=>ceimopt”处于同一节点,且支持度和置信度均为12%和100%。以规则“gk=>ceimopt”为例,其说明该节点代表的所有用户中有12%的用户表现出的用法特征为:“驻留时间短+一般使用+访问财经信息+具有城市IP+变动IP+关注时尚信息+HTML文档+XLS文档+白天访问+中速接入”。这部分用户(假设是前文提到的企业家、投资人等)居住在城市并经常出差变换城市、时间紧,每次访问驻留时间短、偏好便于分析统计的表格文件、白天访问且关心时尚,由于可能使用无线或移动设备上网,其接入速度并不高,如图6所示:
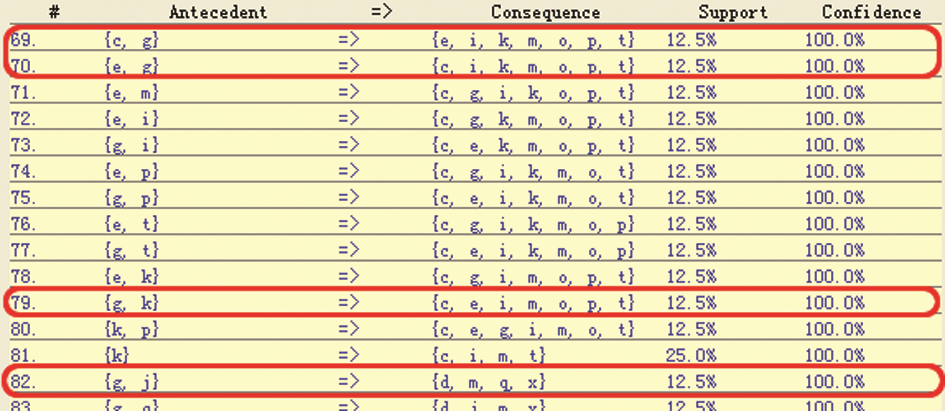 | 图6 支持度阈值为10%、置信度阈值为100%情况下的关联规则举例 |
基于概念格的用法细分就是要把零散但是大量的用户个性化需求纳入用户细分的视野,挖掘过程中获得的规则并非都是具有实际意义的,但如果有必要,在很低的支持度与置信度的条件下同样可以获得许多在实际应用中有意义的规则。杭州市免费向市民提供CNKI检索服务,那么一位居住在杭州的教师或者科研人员则可以离开校园网访问CNKI资源,对于中国知网这很可能是一个低支持度和低置信度的规则,但并不意味着这种非主流的行为模式就应该被忽略。
基于概念格的数字图书馆用户使用方法的关联规则挖掘研究有助于发现用户使用方法之间的联系,找出用户利用数字图书馆获取信息、知识的行为模式,可以用来指导数字图书馆科学地安排知识组织、知识导航、知识检索等工作。研究中改变了过去一味强调较高支持度与置信度下的“强规则”观念,不但通过阈值
调整获得更多具有实际指导意义的规则,而且稳定的格结构便于在规则提取中复用,进而实现了针对利基市场长尾服务的用法细分,最大限度地满足了更多用户的个性化需求。
随着人们对计算机网络技术掌握程度的不断提高,越来越多的用户将具备自己选择满足个性化需求的服务方式的技能,而且用户不会总是心甘情愿地“被管理”。如何更好地让用户自己选择服务方式,帮助用户自行选择、自我管理等问题有待于在未来的工作中进一步努力研究。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|