基于清华汉语树库的有标记联合结构统计分析
[王东波 , 谢靖]
, 谢靖]
, 谢靖]
|
|


详细统计和分析有标记联合结构的内部语言学和外部语言学特征。内部特征方面主要考察该结构的词性序列分布、短语序列分布;外部特征方面主要考察该结构的句法功能分布和左右边界特征词。这些考察一方面为从量化的角度研究该结构提供相对精确的数据,另一方面为计算机自动识别该结构提供语言学知识。
The article counts and analyzes the internal and external linguistic features of Coordination with Overt Conjunctions (COC) in detail. It mainly investigates the internal linguistic features including the distribution of Part-Of-Speech(POS) and phrases sequences, as well as the external linguistic features including the distribution of syntactic function and the features of border lexicons. For one thing, the statistical data offers the linguistic knowledge for identifying COC, for another thing, the accurate data is used to investigate the COC.
汉语联合结构一直是短语结构自动识别中的一个难点[ 1]。由于其内部结构的复杂性以及结构边界的跨度比较大,作为联合结构重要组成部分的有标记联合结构更是汉语组块识别中非常困难的工作。有标记联合结构本身十分复杂,它的自动识别将为汉语树库的构建作好预处理工作,提高句法分析器的工作效率。例如, 在“在/p这/r 一/m 年/q 中/f ,/w 中国/ns 的/u [改革/vn 开放/vn 和/c 现代化/vn 建设/vn] 继续/v 向前/v 迈进/v ”句子中,如果把有标记联合结构“改革/vn 开放/vn 和/c 现代化/vn 建设/vn ”预先识别出来,就解决了句法生成树的一个大问题,使句子生成变得容易[ 2]。联合结构本身是一种离心结构,无论是从内部组成成分,还是从整体语法功能分布上看,自动识别都十分困难,如“新/a 、/w 奇/a 、/w 美/a 及/c 舞台/n 综合/b 魅力/n”这一简单的有标记联合短语,利用原先的统计方法进行分析效果就不很理想,而必须采用新的方法和策略,这对浅层句法分析中语块的识别和分析[ 3]研究会有一定的借鉴。汉语句法分析对机器翻译具有重要的影响,如果能正确识别作为
机器翻译重要部分的有标记联合结构,那么机器翻译的质量就可以得到改善。同时,有标记联合结构的自动识别作为浅层句法分析的一部分,对信息的自动提取也会有一定的帮助。
对于有标记联合结构的语言学特征和自动识别,有关学者进行了多方面的考察和研究。Agarwal和Boggess[ 4] 对已经进行了句法和语义标注的文本,使用基于规则的方法对英语有标记联合结构进行了识别,平均准确率为81.6%。由于是在已经深加工过的语料上识别有标记联合结构,相对来说比较简单。Akitoshi Okumura 和Kazunori Muraki[ 5]利用有标记联合结构的内部结构平行和对称的特性,开发了英语有标记联合结构识别模型。该模型在英日翻译系统中精确率达到了75%,由于识别的是技术报告的文本,相对来说难度不是很大。Sadao Kurohashi和Makoto Nagao[ 6]使用动态计算的方法计算日语联合结构各组成部分的相似值,从而检测各部分的平行性,进而判断整体是否为联合结构,平均准确率为88%,但仅仅分析了150个日语句子,语料规模太小。邓云华[ 7]针对联合结构的“标记性”进行了详细的阐述;马清华[ 8]利用语言的自组织理论对联合结构进行了多方面的探讨。他们基于某种理论,用定性的方法考察有标记联合结构,没有使用基于语料库的统计方法。吴云芳[ 2]以中文信息处理为出发点,全面考察了现代汉语中的并列结构,但语料库的规模相对偏小并且语料加工的深度不够,在一定程度上导致了得出的结论量化性不强或覆盖面不全。苗艳军等[ 9]从自动识别有标记联合结构的角度对该结构进行了初步的分类并总结了一些该结构的句法特征,但没有考察有标记联合结构嵌套的情况。在上述研究的基础上,本文基于大规模清华汉语树库,全面考察了组成有标记联合结构的词性序列和短语序列等内部特征,系统分析了有标记联合结构充当的句法成分和与其有关的左右边界特征词等外部特征。这些有标记联合结构语言学特征的考察,一方面可以为研究有标记联合结构提供量化的数据,另一方面也可以为自动识别有标记联合结构提供详尽的语言学知识。
本文在考察有标记联合结构的语言学特征的过程中所使用的方法主要是统计方法,同时由于统计数据主要来源于清华汉语树库(TCT973),因此会用到语料库的方法。
清华汉语树库[ 10]的语料是从大规模的经过基本信息标注(切分和词性标注)的汉语平衡语料库中,提取出100万汉字规模的语料文本,经过自动断句、自动句法分析和人工校对,形成高质量的汉语句法树库语料。具体情况如表1和表2所示:
| 表1 清华汉语树库的基本统计数据 |
| 表2 清华汉语树库的句子长度分布数据 |
其中,有标记联合结构在清华树库中被标成了“xx-LH”,具体如“[vp-PO 参与/v [np-DZ [np-DZ [np-LH [np-DZ 社会/n 产品/n ] 和/c 国民收入/n ] [np-LH 分配/vN 、/、 再分配/n ] ] 活动/n ] ] ”,在这个例子中存在两个“np-LH”有标记联合结构,并且是嵌套关系。
本文考察有标记联合结构的内部特征,主要从以下两个方面进行:
从100万字的清华语料中统计出了12 362 个有标记联合结构的词性序列,频次居于前14位的词性序列如表3所示。
从表3可以知道,频次在前14位的有标记联合结构占据了整个有标记联合结构的37.83%,而在其他统计中频次为一次的占35.88%。这两组数据说明了有标记联合结构的词性序列分布呈现两极化,一方面向频率高的靠拢,另一方面向频率极低的接近。
从频次排在前14位的词性序列中可以观察出,有
| 表3 有标记联合结构内部词性序列分布 |
标记联合结构内部的词性主要包括:名词(n)、指人专名(nP)、动词(v)、动名词(vN)、形容词(a)。由此可以看出,在这些联合结构中,构成有标记联合结构的词语集中在名词、动词和形容词,主要是名词上。
从频次排在前14位的有标记联合结构的词性序列中可以看出,单层单标记联合结构在整个语料库中占据了81.72%,并且这些单层单标记联合结构充分体现出了有标记联合结构的特征:有标记联合结构中心语的相似性和有标记联合结构的结构平行性,例如:“奢侈/a 或/c 节俭/a,动物界/n 和/c 植物界/n”,这些词性序列的分布为利用规则来识别有标记联合结构提供了充分的条件。
词性序列频次低于93的有标记联合结构内部比较复杂,中心语相似和结构平行性的特征体现得不太充分,并且由于语言现象的复杂性,有些根本就没有体现。例如:“[np-LH [np-AD 客观/a 的/u ] 、/w [np-DZ [dj-ZW 价值/n 中立/v ] 的/u [np-DZ 科学/n 活动/n ] ] ]”和“[vp-LH [vp-ZZ 更/dD [vp-PO 适/v [np-DZ [np-DZ 人体/n [ap-LH 卫生/a 和/c 美观/a ] ] 要求/n ] ] ] 以及/c [dj-ZW [np-LH [np-DZ 工农业/n 生产/vN ]、/w 国防/n ] 特需/v ]]”,这两个有标记联合结构的词性序列就没有特征可查,更无规则可循。类似的有标记联合结构规则出现的频次低,并且总量大,用基于规则的方法基本上无法识别,必须借助统计的方法来处理。
本文基于清华汉语树库,用统计的方法详尽地统计和分析了有标记联合结构内部的短语分布。根据统计的结果,频次出现100次以上的有标记联合结构内部短语序列分布如表4所示:
| 表4 有标记联合结构内部短语序列分布 |
根据表4的统计数据,频次100次以上的短语序列占据整个含短语的有标记联合结构的71.19%,因此有标记联合结构内部短语倾向于向高频的短语靠拢,分布相对比较集中。
从短语分布上看,联合结构内部短语主要包括:定中结构、述宾结构、附加结构、状中结构。定中结构是分布最广的一类结构,在表4中占据了80.00%;其次是述宾结构,占据了8.70%。因此,可以初步得出结论:如果在识别有标记联合结构中引进搭配的知识,定中结构和述宾结构搭配的知识是最重要的。
短语组成的序列充分体现了有标记联合结构的结构平行性,例如:“定中结构+联合标记+定中结构”和“述宾结构+联合标记+述宾结构”这类序列在结构上无论是前后两个短语还是前后两个成分基本上都是平行的,这一特征有助于根据联合结构一边的边界进而确定另一边界。例如,如果知道“[np-DZ 基础/n 理论/n ] 和/c [np-DZ 基础/n 技术/n ]” 是由两个定中结构组成的序列,并且左边界已经知道,那么根据结构的平行性,就很容易确定另一个边界。
根据统计结果,在6 408个有标记联合结构短语序列中有396个有标记联合结构中嵌套着联合结构,占整个有标记联合结构短语序列的6.18%。虽然嵌套的联合结构数量有限,但凡是有嵌套的联合结构,无论在结构上还是长度上都极其复杂,这势必给自动识别该类有标记联合结构造成一定的困难。
有标记联合结构内部特征考察主要是从有标记联合结构的微观角度分析联合结构的各种特征,而外部特征则是根据有标记联合结构所处的位置,从宏观的角度考察有标记联合结构。本文主要从有标记联合结构的句法功能分布和有标记联合结构左右边界特征词这两个方面考察有标记联合结构的外部特征。
陈小荷为实词分类拟定了一个含8种句法结构的考察框架[ 11]。徐艳华在8种句法结构的基础上增加了一类介宾结构,考察了实词的14种句法功能[ 12]。卢俊之等基于“语法功能匹配”的理论来实现句法自动分析的需要,不但考察了每一个实词的句法功能,而且考察了每类短语的句法功能;在考察功能时,将原来的9种句法结构推广到27种句法结构,句法功能也从原来的14种推广到60种[ 13]。
有标记联合结构作为联合结构的重要组成部分也有其自身的句法功能分布,这里所说的有标记联合结构的句法功能是有标记联合结构在上一级句法结构中所充当的语法功能。根据基于清华汉语树库的统计数据,有标记联合结构充当的频次在20次以上的句法功能分布如表5所示:
| 表5 有标记联合结构充当的句法功能 |
从表5可以看出,有标记联合结构主要出现在以下句法位置上:宾语、定语、带“的”定语、带“的”定语中心语、主语、定语中心语、介词宾语,它们占据了整个有标记联合结构句法分布的71.75%。这些分布数据一方面描述了有标记联合结构本身在整个句法体系中充当的句法功能,另一方面也为用搭配知识自动识别有标记联合结构提供了详细的数据依据。例如,基于介宾搭配实例的有标记联合结构边界识别,根据统计共有595个有标记联合结构位于介宾的位置,据观察联合结构的前半部分处于介词和联合标记之间,介词和联合标记可以形成一个框架,“对于/p[金融/n 政策/n 和/c 财政/n 政策/n]”这个例子,根据“‘对于’和‘和’”可以确定联合结构的前一部分,识别出左边界,然后根据联合结构对称性或语义相似性[ 14],进而可以确定后半部分的右边界。如果文本中介宾短语识别的正确率和召回率比较高,在识别有标记联合结构的时候可以通过介宾短语识别出有标记联合结构。
由于有标记联合结构是一种离心结构,内部组织比较分散,虽然其整体上分布也像其他短语一样主要集中在常见的句法位置上,但在不常见的兼语、连谓、框式结构甚至联合结构中都有一定数量的分布,这在一定程度上造成了联合结构识别的困难。
统计有标记联合结构左边界特征词的依据是:有的词语经常出现在有标记联合结构左边界的外部,而不经常出现在有标记联合结构的内部,即有标记联合结构的左边界一般不会跨越这些词。根据这一语言学现象,把有标记联合结构的边界范围限定在以“。!?”结尾的子句范围内,联合结构的左边界绝对不会跨越第一个联合标记,因此考察范围限定在从句子开始到第一个标记的范围内,称为β, 设 W 是任一个词,f(W_left_outside)表示W 在β范围内,在有标记联合结构外部出现的频次,f(W_left)表示W 在β范围内出现的频次,词W 成为有标记联合结构左边界特征词的频率计算公式如:
P(W)=
P值越高,说明W成为左边界特征词的可能性就越大,由于本文统计时用的语料规模是100万字,所以取P的经验阈值为0.8,也就是当P≥0.8,W就可能成为有标记联合结构的左边界特征词,然后结合人工语言学知识的内省,从中确定有标记联合结构的左边界特征词。频率值在前10位并且经过人工语言学知识内省后的左边界特征词如表6所示。
从这10个高频的边界特征词可以看出,边界特征词主要集中在以下几类词性上:
(1)动词,例如“是、使、提供、有”,这类动词的特点是它们后面跟的联合结构都十分复杂,作为左边界特征词的动词可以在一定程度上帮助识别有标记联合结构,例如“参加/v 男子组/n 角逐/v 的/u 有/v {国际/n 特级/b 大师/n {叶/nr 江川/nr 、/w 彭/nr 小民/nr 、/w 汪/nr 自力/nr} 和/c 国际/n 大师/n {童/nr 渊铭/nr 、/w 章/nr 钟/nr 、/w 林/nr 卫国/nr 、/w 李/nr 文良/nr} 以及/c 国际/n 棋联/j 大师/n 余/nr 少腾/nr} 等/u 8/m 名/q 棋手/n 。/w”;
| 表6 有标记联合结构左边界特征词 |
(2)介词,例如“在、就、为”等;
(3)副词,例如“将”等;
(4)另外还有一类代词,如表6中的“这”,边界特征词有时候可能不精确,表中关于“这”的例子就是一个很好的说明。这些边界词有助于为基于规则识别有标记联合结构制定相关的规则。
根据统计左边界特征词的方法,有标记联合结构的右边界范围也是限定在以“。!?”结尾的子句范围内,由于有标记联合结构的右边界特征词绝对不会跨越联合结构的最后一个联合标记,所以考察范围限定在从最后一个联合标记开始到句子结束的范围内,这个范围记做α。设 W 是任一个词,f(W_right_outside)表示W 在α范围内,在有标记联合结构外部出现的频次,f(W_right)表示W 在α范围内出现的频次,词W 成为有标记联合结构右边界特征词的频率计算公式如:
P(W)=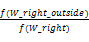
基于100万字的语料库规模考虑,把右边界特征词P的阈值也设定为0.8。根据语言学知识的内省并结合大于或等于0.8的P值,确定了右边界特征词的范围。频率值居于前10位的右边界特征词如表7所示:
| 表7 有标记联合结构右边界特征词 |
像左边界特征词一样,右边界特征词在“动词、副词、介词”上也有分布,如“是、提供、都、在”等。所不同的是,右边界特征词主要集中在助词上,表7中的助词有“等、了、的”等,其中助词中的“等、等等、的”作为右边界特征词的时候,与有标记联合结构结合得非常紧密,基本上是有标记联合结构的右边界特征词。左右边界词除了有助于为基于规则识别有标记联合结构制定规则外,还可以为基于机器学习的方法识别有标记联合结构提供相应的特征,如基于条件随机场识别有标记联合结构的时候,边界词就是一个非常重要的特征。
出于从量化的角度考察有标记联合结构和向自动识别该结构提供语言学知识的目的,本文基于清华汉语树库,用统计的方法详尽地统计和考察了有标记联合结构的内部和外部语言学特征,初步得出了一些结论,为全面了解有标记联合结构提供了一些量化的数据和语言学知识。为了更全面地考察有标记联合结构,下一步将会扩大语料统计的规模并从多角度统计分析有标记联合结构,以期获取更多的语言学特征。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|