{kind=link}
{kind=link}
{kind=link}
基于改进蚁群聚类的热点主题发现算法研究
[陆蓓 , 程肖, 谌志群]
, 程肖, 谌志群]
, 程肖, 谌志群]
|
|


针对热点主题发现是在聚类算法的基础上实现的特点,将改进后的蚁群聚类算法引入到该研究中,同时提出类别关注度(CAD)的概念,以此来判定类别的热门程度并区分出热门类别和冷门类别,在此基础上抽取热点主题集。实验结果表明改进后的蚁群聚类算法对热点主题的发现有一定的效果,对其他仿生优化聚类算法的引入有借鉴意义。
For the hot topics found is based on the clustering algorithm,this paper introduces the improved ant colony clustering algorithm,and raises Class Attention Degree (CAD) concept in order to determine the class of hot level and to distinguish popular categories as well as unpopular categories. Meanwhile,hot topic set is erxtracted on this basis. Experimental results show that the improved ant colony clustering algorithm has in certain effects to the hot topics found.
随着互联网的迅猛发展,网络已成为庞大的公共信息集散地和民众参政议政最常用的平台。社会民众通过网络所形成的网络舆情对社会产生的影响力越来越大,受到相关部门的高度关注和重视。截至2009年6月30日,中国网民规模达到3.38亿人,普及率达到25.5%。网民规模较2008年底增长4 000万人,半年增长率为13.4%,中国网民规模依然保持快速增长之势[ 1]。目前主流的热点主题发现算法采用话题发现(TD)与跟踪技术(TDT)实现。话题发现的主要任务是从输入的新闻报道中自动检测出未知话题并把结果归入到不同的话题簇中,在需要的时候建立新的话题簇。比如舆情中的关键词“非典”和“禽流感”,这些都是未知话题,TD需要检测并建立新的话题簇[ 2]。话题发现可以看作是一种按事件的聚类,发现的目的是要按照新闻报道表达的话题将其进行聚类。常用的聚类方法有:增量K-Means聚类、单遍聚类等[ 3]。
本文针对新闻文本的热点主题发现研究,分析常用聚类算法的优缺点,实验蚁群聚类算法对热点主题发现的效果。基于划分的K-Means聚类算法简单而且效果尚佳,但是该算法对于初始参数敏感,不易于找到全局最优解;蚁群算法易于找到全局最优解,但是收敛速度相对较慢。针对蚁群聚类算法的缺点,在热点主题发现算法中引入改进的蚁群聚类算法,取得了一定的成效,从而证明了蚁群聚类算法符合热点主题发现的要求。
1991年,Deneubourg等基于蚁群聚类现象建立了一种基本模型(Basic Model,BM),Lumer和Faieta将BM模型推广到数据分析范畴[ 4],其主要思想是把待聚类的样本集数据随机初始散布在一个二维平面内,然后在该平面上放置人工蚂蚁对其进行聚类分析。2002年,Labroche等提出基于蚂蚁化学识别系统的聚类方法,国内对于蚁群聚类算法的研究主要应用于数据挖掘[ 5]。总的来说,基于蚁群的聚类算法可分为以下几类:基于蚁穴清理行为的聚类算法;基于蚂蚁觅食原理的聚类算法[ 6];基于蚂蚁自我聚集行为的聚类算法;与其他方法结合,通过优势互补来改善的聚类算法,如与K-Means算法结合等[ 7]。随着该算法被一步步深入研究,各种改进后的算法竞相涌现,一种较为稳定的蚁群算法被积淀下来[ 8],相关定义如下:
(1)平均相似性:假设在时刻t某只蚂蚁在地点r发现一个数据对象o,则可将对象oi与其邻域对象oj的平均相似性定义为:
f(oi)=max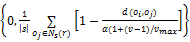
其中,α为相似性参数;v表示蚂蚁运动的速度;vmax为最大速度;Ns(r)表示地点r周围,以s为边长的正方形局部区域;d(oi,oj)表示对象oi和oj在属性空间中的距离。
(2)概率转换函数:概率转换函数式f(oi)的一个函数,将数据对象的平均相似性转化为拾起概率Pp=1-Sigmoid(f(oi))或放下概率Pd=Sigmoid(f(oi))。
(1)蚁群放置物体时采用紧凑算法
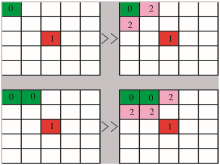
分析蚁群算法模型,蚂蚁对负载的物体进行放置操作时,对邻域内的点评估,进行选择放置或者继续搜索点的操作。在二维网格中,蚂蚁若找到合适的领域后进行直接放置操作,会产生一系列的问题。在二维平面图中若找到点直接放下物体容易产生松散的物体堆积,造成少量物体占据大量平面空间。在上述蚁群经典算法步骤中递归产生类时形成模糊类边界,给聚类算法收集阶段的工作带来麻烦,会影响最后的聚类结果。针对上述问题,本文提出了放置物体时的紧凑算法,效果如图1所示:
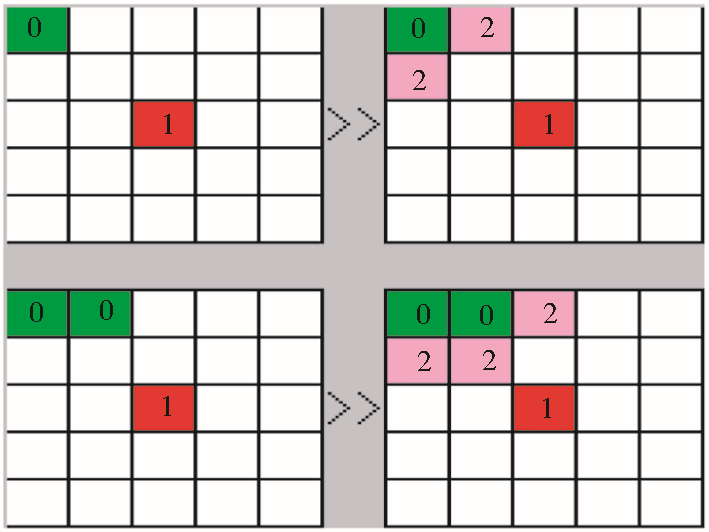 | 图1 蚂蚁放置物体位置图 |
在图1中,右图分别是左图采用紧凑算法后蚂蚁放置物体的二维平面图。标记为0的网格点,表明该点被物体占据;标记为1的网格点是经典蚁群算法中在放置物体时选择的点;标记为2的网格点是采用紧凑算法后蚂蚁放置物体的可能点。
蚂蚁放置物体时的紧凑算法具体描述如下:
①根据蚁群算法找到即将放置的点的邻域。
②遍历邻域中所有的点,利用相似度度量函数找出其中与放置物体最为相似的物体所在位置,记为A点。
③以A点为圆心,按半径为1,2,…,k(其中k≤Rmax)递增的方式查找未放置物体的网格点。
④若找到以A点为圆心并且Rmax为邻域半径的点,那么将蚂蚁的负载放下。若没有找到该点,则在该邻域内寻找最为不相似物体点B,将该物体从所在的位置去掉,随机选择其他位置点,将蚂蚁的负载放下。
通过算法的描述可知,紧凑算法在达到合理安排放置点、优化聚类算法内存空间的同时,可以有效限制某一个聚类的聚簇过大,防止超出预期范围。如设置Rmax之后,聚类算法的结果中,聚簇的最多物体点集为 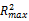
(2)对可被蚂蚁拾起的物体进行基于优先级队列的调度
某物体在经历蚁群的多次拾起、负载移动和放置之后,物体所在位置已经相当接近或者比较接近目标位置了,那么当蚁群再次对该物体进行负载时,属于一次空运动,也就是说在寻求最优解的过程中,作了一次无效解的尝试。针对这个问题,提出根据蚂蚁负载时所经过的步数对物体的优先级进行设置:
①若蚂蚁拾起物体后,没有移动即放下,或者在相对少的步骤之内就放下物体,则表明该物体已经处于某一相对正确的类中,将该物体放入优先级低的队列。
②若蚂蚁拾起物体后,走了相对较多的步骤才放下物体,则表明蚂蚁放下的物体刚刚加入某一类中,稳定性待测,则将该物体放入优先级高的队列。
③若蚂蚁拾起物体后走的步骤大于某一相对较大的阈值,则可认为该物体为噪声点,将该物体放入不可再被蚂蚁负载队列。
④当蚂蚁负载为空时,以较高的频率从优先级高的队列中获得物体,从而使得不稳定的点以更高的概率融入合适的类中。
(3)改进后的蚁群聚类算法
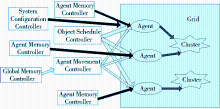
改进后的蚁群聚类算法中相关实体及其协作关系如图2所示:
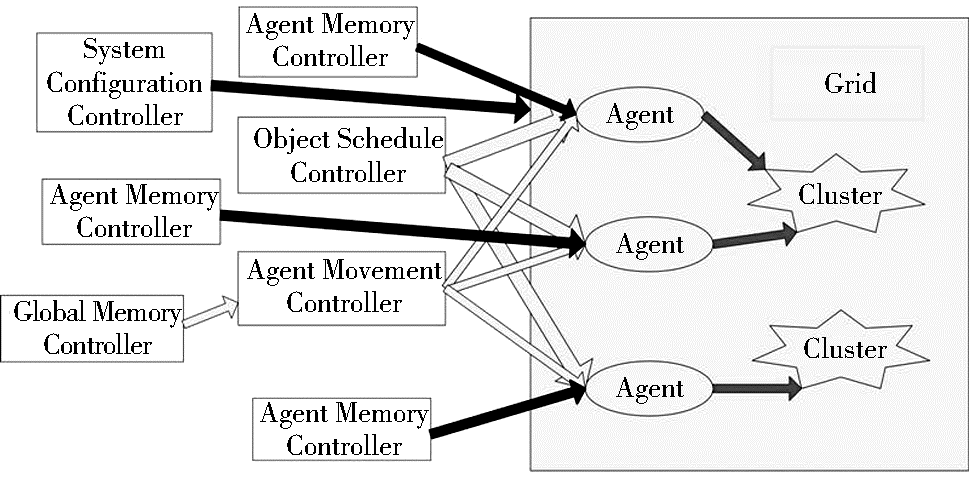 | 图2 改进后蚁群聚类算法中相关实体及其协作关系 |
改进后的蚁群聚类算法的相关实体如下:
①Grid:二维网格,是蚁群负载Object时搜索放置点时的活动范围。初始化时,Object随机散落在Grid上,供蚂蚁负载[ 8]。
②Agent:蚁群中的单个个体,即模拟蚂蚁的人工智能体,具备负载Object的功能,并且能够利用全局环境因素和局部环境因素进行搜索Object放置的最佳位置点[ 8]。
③Cluster:具有内在联系的文本集合,是指经过蚁群操作之后,按文本相似度关系,形成的一个聚簇的文本集合。
④Global Memory Controller:全局环境信息记忆体控制器,是指蚁群在对文本进行聚类的过程中需要用到的全局信息,蚁群通过全局记忆体进行全局信息修改和获取,从而影响最终的聚类结果,使得聚类结果收敛。
⑤Agent Memory Controller:蚁群个体局部信息记忆体控制器,是指蚁群在对某一文本进行聚类分派的过程中,为加速聚类收敛过程,利用自身先前对其他文本聚类分派积累的经验进行分派文本到特定的文本类别。
⑥Agent Movement Controller:蚁群个体行为控制器,是指蚁群在二维网格上移动时,综合全局环境信息、个体局部信息和文本自身信息,给出蚁群下一步行动(指拾起、放下或移动文本行为)的控制器。
⑦Object Schedule Controller:Object调度控制器,是指在综合前期移动过程信息以及自身文本与二维网格中周围文本的相似度信息的前提下,系统对尚未负载的蚁群进行物体分派的控制器[ 9]。
⑧System Configuration Controller:系统配置控制器,是指系统为了协调本软件的正确使用,设置相关必要信息的控制,例如尚未聚类的文本位置、文本数目以及聚类过程中用到的相关系数等。
本文对于原有算法所做改进的实体部分有:全局环境信息记忆体控制器、蚁群个体局部信息记忆体控制器、蚁群个体行为控制器。局部记忆体是指蚁群自身在搜寻文本放置位置时,对先前放置的位置点作相应的记录,那么蚁群在搜索时就会形成一个跳跃式的前进搜索过程,从而加速蚁群将相应的文本放置到正确的位置。如果没有根据局部记忆体找到合理的文本放置点,蚁群还可以根据全局记忆体寻找合适的文本放置点。上述的两种改进算法在实体中主要体现在全局环境信息记忆体控制器和蚁群个体行为控制器。改进后的算法优点有:较好的可伸缩性,可以通过改变蚁群中蚂蚁数量、网格大小等参数自动调节来实现聚类;对聚簇的形成是基于文本点的相似度,并不是以某点为中心形成的,从根本上避免了聚簇形状的问题等。
改进后蚁群聚类算法中的部分关键代码如下:
private void dropLoadToRandomPosition(Grid grid) {
//蚁群紧凑方法,去掉负载物体,随机放入其他位置点
GridPoint randFreePosition = grid.getFreePosition();
//得到网格中空闲点的位置
dropLoadToSpecTarget(grid, randFreePosition);
}
public Queue(int capacity) {//优先级队列方法
this.data = (T[]) new Object[capacity+1];
this.head = capacity + 1;
this.tail = 0;
this.capacity = capacity;
}
public AgentMemoryController() {//蚁群个体局部信息记忆体控制器方法
m_searchTracer = new ArrayList
m_direction = new ArrayList
m_maxHeight = Config.getConfig().getGridHeight();//得到网格长度
m_maxWidth = Config.getConfig().getGridWidth();//得到网格宽度
m_isPickupPositionTraveled = true;
}
热点主题的相关报道在一段时期内密集出现,在一定程度上说明该主题是一个热点。根据TF-PDF的思想[ 10],本文提出类别关注度的概念,用来衡量一段时间内类别受关注程度,即热门类别的判定。对文献[11]中提出的相关公式进行改进,改进后的公式如下:
CADM(i,t)=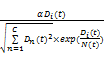
其中CADM(i,t)为时间段t内站点上类别i的媒体关注度,t可以是任意长时间;Di(t)是站点上类别i所包含的相关报道数目;N(t)是站点上报道总数;C为该站点上的类别总数;针对门户网站新闻报道对热点主题的影响力α取经验值0.5。类别关注度CADM(i,t)的重要因素是exp( 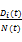
热门类别发现的研究目标是发现一段时间内媒体所密切关注的新闻主题,而热点主题一般是在热门类别的基础上形成的,若热门类别和冷门类别的类别关注度差别不大,这样很难将热门类别区分出来,从而难以断定其影响力。因此热门类别发现模型需要能明确区分热门类别和冷门类别,本文提出类别区分度来作为热门类别发现评价的指标,用以评价该模型对热门类别和冷门类别的区分能力,改进后的公式如下。
Dis(H,C)=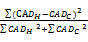
其中,Dis(H,C)为类别区分度,CADH为该模型判定的热门类别关注度,CADC为该模型判定的冷门类别关注度。对于同样的数据,Dis(H,C)越大,说明该模型能更好地区分出热门类别和冷门类别,对于热点主题的提取效果就会更好。
本文采用向量空间模型来表示新闻文本的特征,以空间上向量之间的相似度来确定语义的相似度,选取词作为向量的特征项,在向量空间模型中文本D被转换为n维空间的向量,其形式为:D=D(T1,w1,T2,w2,…,Tn,wn),其中Ti为特征项,wi为特征Ti的权值。
新闻文本一般分为标题和正文两个重要部分,因为新闻文本的标题是正文的简要描述信息,所以要赋予较高的权重,以此来区分标题和正文的重要性。同时新闻文本除内容词之外,还包括很多命名实体[ 12],如:人名、地名等,这些命名实体对不同的热点事件也起着不可忽视的作用,因此对于特征项i的权值计算采用如下公式[ 13]:
wi=tfi×idfi×fi(w)(4)
其中,fi(w)用来分别对标题中的词、正文中的词和命名实体赋予不同的权重, tf和idf均采用经典的算法。
主题信息的描述即类别信息的描述,本文采用提取特征权重排列较高的词作为主题的描述信息,通过设置阈值的方法组成主题集,称为粗主题集,然后对取得的粗主题集通过人工筛选的方法去除主题无用词,确定有实际意义的主题集,这个主题集在一定程度上可以反映出这个类别的内容。例如:粗主题集=(宾川、地震、云南、房屋、灾区、大理…),去除主题无用词之后的主题集=(宾川、地震、云南),此主题集可以描述这个类别的大致内容。
(1)实验环境配置:CPU为Core2 E4300,内存为E4600 3GB,硬盘为Seagate 160GB 7200r/m,操作系统为Windows Vista,实现程序语言为Java,运行环境为Eclipse。
(2)样本数据预处理。实验选取门户网站Sina国内新闻,下载2009年11月1日到15日的新闻,样本数据的选取是根据Sina网站每周热点新闻排行中的新闻标题所下载的新闻文本,共3 749篇。实验目的是为了验证本文提出的算法对热点主题发现的有效性,为下一步处理大规模文本数据奠定基础。经过去除停用词、删除HTML标签等预处理步骤后,新闻文本抽取成标题、时间、正文三部分格式的存储文档,并经过处理自动编上ID号以便观察,形式如下:
﹍
#HDUIR-ID#92
#HDUIR-TI#我国航天事业的奠基人钱学森逝世
#HDUIR-TIME#20091101
#HDUIR-CONTENT#中国共产党的优秀党员……
﹉
在第一阶段热点主题探测之后,共发现23个类别,在这些实验数据基础上计算类别关注度,统计文本数量,发现热点主题,并列出排在前10位的热门类别和后2位的冷门类别,具体如表1所示:
| 表1 热门类别与冷门类别 |
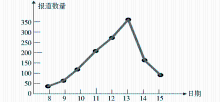
根据式(3)计算得出Dis(H,C)=0.93514,说明该算法能很好地区分热门类别和冷门类别。从表1 的数据看出,在2009年11月1日到15日期间,Sina网国内新闻上关注度最高的主题是甲流、极端天气等新闻,说明这些是媒体比较关注的热点主题,也说明新闻报道越多,其类别关注度越高,越容易形成热门类别。同时,在实验过程中发现,关于极端天气的新闻报道在2009年11月1日到7日一周内有183篇,而在后一周变化极大,共有1 208篇,其中在11月12日和13日达到高峰分别有274和368篇,该主题的发展曲线如图3所示。
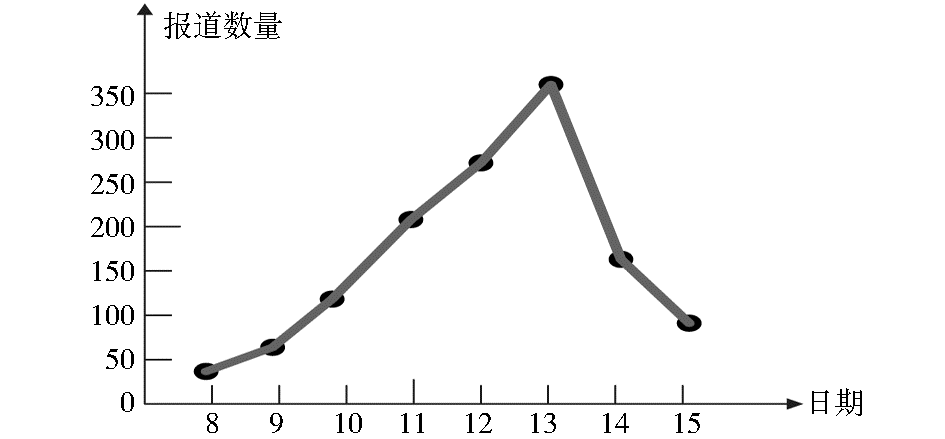 | 图3 11月8日到15日主题h2的发展曲线 |
本文尝试把改进后的蚁群聚类算法引入到热点主题发现研究中,提出了改进措施:在蚂蚁放置物体时采用紧凑算法;对于可被蚂蚁负载的物体采用基于优先级队列的调度算法。在此聚类的基础上提出类别关注度(CAD)的概念,以此来判定类别的热门程度,同时区分出热门类别和冷门类别,然后抽取热点主题集。实验结果证明了该方法的准确性和可行性,对引入其他仿生优化聚类算法有一定的借鉴意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|