
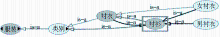
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于领域本体的专利信息检索系统研究与实现
[吴红 , 李玉平, 胡泽文]
, 李玉平, 胡泽文]
, 李玉平, 胡泽文]
|
|


针对传统信息检索方法在当今网络信息环境下所面临的问题,提出基于领域本体的专利信息检索模型,从用户检索请求处理、本体构建、本体可视化与语义扩展、检索及存储的过程和技术实现进行研究,并开发一个基于服装领域本体的专利信息检索原型系统。比较测试表明,该模型在确保信息检索准确性的同时能够极大地提高其全面性。
Aiming at some problems in traditional information retrieval under the present network information environment, the paper puts forward patent information retrieval model based on domain Ontology, and makes in-depth study on the process and technical implementation of user retrieval request disposal, Ontology construction, Ontology visualization and semantic expansion, retrieval and storage. A prototype patent information retrieval system is also implemented. Via a series of retrieval effects tests, the model can ensure accuracy of information retrieval and greatly improve the comprehensiveness of information retrieval.
随着Internet的飞速发展,专利信息已成为网络资源必不可少的一部分,如何开发和利用它们成为目前研究的热点和难点。目前,国内外已经出现了很多专利信息检索与利用方面的软件和工具,如美国汤姆森集团的专利软件[ 1]、台湾连颖公司开发的PatentGuider[ 2]等,这些软件和工具能够快速有效地对网络专利信息进行检索和利用,不过其采用关键字匹配的信息检索技术与方法忽略了词间的语义关系,不能解决同义词、多义词、词间上下位关系等问题,造成信息检索不全面、不准确。针对这个问题,国内外学者从语义或概念的角度对专利信息检索技术与方法进行了广泛而深入的研究。如Sekar等通过同一语义对应多概念方式检索专利信息[ 3]、翟东升等通过WordNet语义词典,对用户初始检索表达式进行语义扩展[ 4]、吕祥惠等分析用户查询模式,提出基于本体和Web 挖掘技术的Patent Digger体系结构[ 5]。上述研究为提高专利信息检索的全面性提出了不同的研究方法,但是还存在一些问题。其中,文献[3]对用户专业能力要求较高,用户需要对本专利领域的概念充分理解,才能检索到全面准确的信息。文献[4]把WordNet语义词典作为用户检索请求语义扩展的基础,但是WordNet语义词典不提供汉语概念,不适用于中国专利信息的检索;另外,WordNet是一个通用的语义词典,在专利领域的语义扩展方面缺乏概念描述的专业性。文献[5]需对用户查询模式进行分析、训练,过程复杂且对于复杂的用户请求语句分析效率较低。
针对目前信息检索与利用方面存在的问题,本文提出基于领域本体的专利信息检索模型,并构建服装领域本体,实现基于服装领域本体的专利信息检索系统。系统借助领域本体丰富的概念语义关系和清晰的层次结构,对用户检索请求进行语义扩展,形成规范的语义扩展检索表达式,使检索信息更全面、更准确,并可视化本体概念语义图,以更直观的方式向用户展示所检索领域的关键概念及其之间的语义关系,从而简化用户与系统的交互操作。实验结果表明,该模型能够极大地提高信息检索的全面性和准确性。
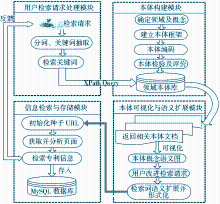
基于领域本体的专利信息检索模型分为用户检索请求处理、本体构建、本体可视化与语义扩展、信息检索与存储4个模块,如图1所示:
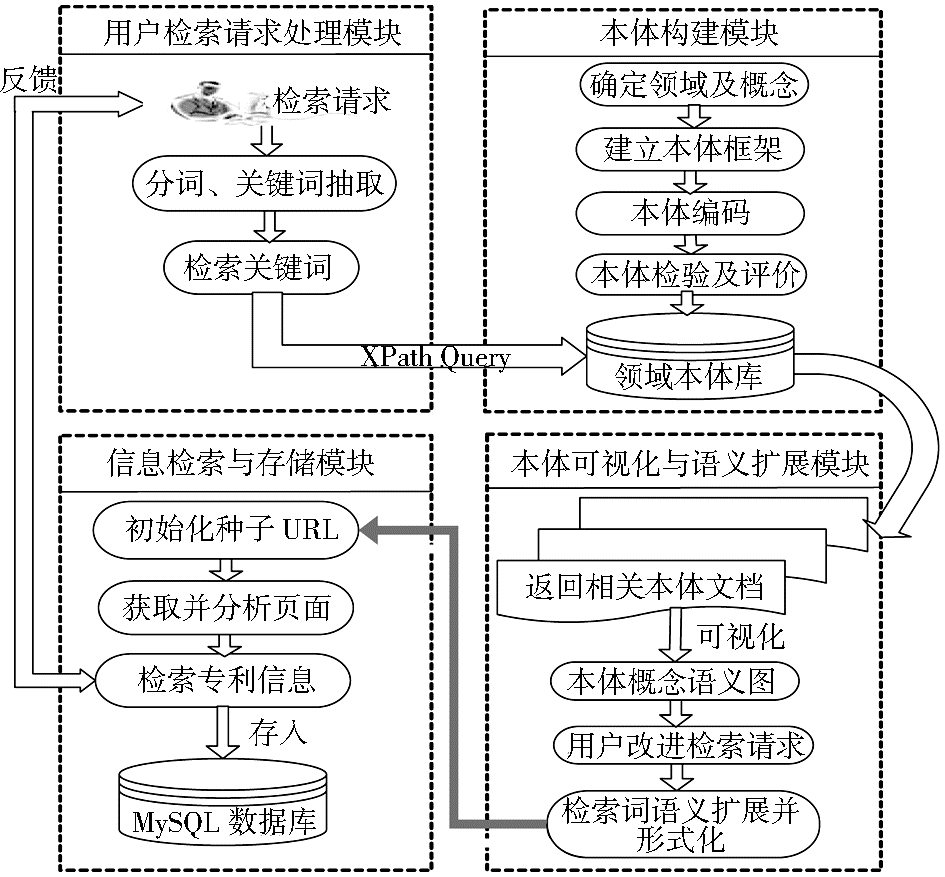 | 图1 基于领域本体的专利信息检索模型 |
(1)该模型对用户检索请求语句进行自动分词,提取关键词。
(2)将关键词转化为规范化的本体查询语言,查询领域本体库,获取与查询关键词密切相关的领域本体概念,并在用户信息检索界面上可视化该领域本体的概念语义图。
(3)用户通过语义图选择与检索主题更相关、更专业的领域概念,系统根据语义图中概念之间的语义关系对选择的概念进行语义扩展,并组合成规范的检索表达式,从相关专利网页上检索专利信息反馈给用户,用户选择部分或全部检索到的专利信息,系统将这些信息存储到MySQL数据库中。
该模块对用户检索请求进行分词、提取关键词、规范成本体查询语言等处理。采用中国科学院的基于“多层隐马模型”的汉语词法分析系统ICTCLAS[ 6]将用户检索请求语句分为若干个词语,根据停用词表去除停用词,抽取关键词。用XPath查询语言将抽取后的关键词表示成规范的查询表达式,从领域本体库中查询相关本体文档。
在对用户检索请求进行处理的过程中,为了简单高效地使用分词系统ICTCLAS和节省用户磁盘空间,通过调用PHP的Snoopy类[ 7],实现专利信息检索系统与汉语词法分词系统ICTCLAS网络版的有机结合。Snoopy类用来模仿Web浏览器的功能,完成获取网页内容和发送表单的任务。
该模块主要在国际专利分类(International Patent Classification,IPC)[ 8]和知识词典HowNet(知网)[ 9]基础上利用Protégé本体构建工具进行专利领域本体的构建。目的是利用IPC在专利分类、HowNet在概念及其语义关系上的优势降低专利领域本体构建的难度。
(1) 国际专利分类法与HowNet
国际专利分类表的内容设置包括了与发明创造有关的全部知识领域,该表是目前唯一国际通用的专利文献分类和检索工具。
从专利分类表的内容和结构可以看出,IPC对各个知识领域进行了详细的层次分类。根据用户的需求,可以把部、分部或者大类作为本体的专业领域和范围。但是,IPC描述概念的关系比较单一,上下位关系清晰明了,而同位及其他关系表达不完善。因此,为了更好地解决IPC在本体构建过程中存在的问题,需要综合应用HowNet[ 9]。HowNet是一个以英汉双语所代表的概念以及概念的特征为基础的、以揭示概念与概念之间以及概念所具有的特性之间的关系为基本内容的常识知识库。利用HowNet可以查找等价类、同位类等概念,有利于解决本体构建过程中的同义词、同位关系等问题。
(2) 专利本体构建与存储
①专利本体的构建方法
本文选择七步法[ 10]作为构建本体的重要依据。同时,根据构建专利领域本体的特点,对七步法稍作变化,具体构建过程分为4步:
1)确定本体的专业领域、范围和目的。
根据IPC的特点,将大类作为本体的专业领域和范围,选择服装领域进行研究,即国际专利分类表中A部的A41服装大类。利用本体的目的是解决语义冲突[ 11],使得关于某一主题的知识表达更加准确,进而检索更全面、更准确的专利信息。
2)建立本体框架。
目前,完善一个等级体系有几种可行的方法:自顶向下法、自底向上法和混合法[ 12],参考IPC和词典选择混合法定义概念之间的等级关系、定义类的属性。
3)对领域本体进行编码、形式化。
使用OWL[ 13]作为本体描述语言。OWL主要由类、属性以及它们的实例描述组成,其中类和属性分别对应本体模型中的概念和关系。
4)对本体进行检验和评价。
引入Racer[ 14]推理机对本体概念的基本关系进行语义推理。Protégé中有专用接口可引入Racer,在构建本体库时使用Racer可以判断本体库内概念的一致性,便于及时发现错误。通过实现基于领域本体的专利信息检索系统对本体的可行性、可用性、概念及其语义关系的丰富性等进行评价。
②专利本体的存储
主要利用文献[15]的本体存储查询方法对构建的本体文档进行存储。
该模块将查询到的相关本体文档反馈给用户,并在信息检索界面可视化为本体概念语义图,用户可以根据语义图改进检索请求。具体流程如下:
(1)利用用户检索请求处理模块中规范化的查询表达式和文献[15]中XPath语言查询本体文档的方法,查询Xindice领域本体库,返回与用户检索主题相关的本体文档。
(2)调用Image_GraphViz-1.2.1[ 16]可视化图形包中的GraphViz.php文件中的Image_GraphViz.class,将返回的相关本体文档在用户信息检索界面上可视化为本体概念语义图,由于系统界面大小的限制,本体概念语义图将以弹出窗口的形式呈现给用户。
(3)用户通过语义图选择与检索主题相关度更高、更专业的领域概念,系统自动调用Jena[ 17]推理机应用程序接口,根据设定的推理规则推理出概念的上位类、下位类和等价类,并根据公式SCi=1/L(Ci)[ 18]计算概念的语义权重。其中,SCi为概念Ci在本体概念语义图中的语义权重,L(Ci)为概念Ci在本体概念语义图中的层次。
(4)系统根据概念的语义权重对用户选择的概念和推理出来的同位、上位、同义概念进行组合,形成规范化的检索表达式。
(1)初始化URL种子,将初始化的URL种子作为专利数据源,对数据源中的专利数据特点、结构等进行分析研究,设计适用于专利数据表及其之间的映射关系,并创建专利数据库。
(2)通过分析专利数据源的专利检索网页的源文件,查找出网页中采用POST或GET方式[ 19]传送的表单数据,即表单元素HIDDEN(隐藏域)的NAME和VALUE属性的值,并分析出数据传送规则。
(3)把规范化的检索表达式转换成参数传递给采用POST或GET方法传递的表单变量,通过参数传递获取远程网站的后台专利数据库中符合用户检索主题的专利信息,并将其存储到本地专利数据库中。
采用Apache2.0+MySQL5.0+PHP5[ 20]组合开发系统。综合考虑本体构建工具是否支持中文、是否免费下载使用、可扩展性以及用户群的数量等因素,选择本体构建工具Protégé4.1(简称Protégé)[ 21]。
(1)确定国际专利分类表中A部的A41服装大类为服装领域本体的专业领域。
(2)利用Protégé建立的本体如图2所示:
 | 图2 服装本体的构建界面及其概念语义图在Protégé中的显示 |
(3)本体的OWL描述如下:
关于属性的描述:
<!-- http://www.semanticweb.org/ontologies/2010/3/服装.owl#申请(专利)号 -->
<owl:ObjectProperty rdf:about="#申请(专利)号"/>
<!-- http://www.semanticweb.org/ontologies/2010/3/服装.owl#分类号 -->
<owl:ObjectProperty rdf:about="#分类号"/>
……
关于类的描述:
<!--http://www.semanticweb.org/ontologies/2010/3/服装.owl#服装 -->
<owl:Class rdf:about="#服装 ">
<owl:equivalentClass rdf:resource="#衣服"/>
</owl:Class>
<!--http://www.semanticweb.org/ontologies/2010/3/服装.owl#类别 -->
<owl:Class rdf:about="#类别">
<!-- http://www.semanticweb.org/ontologies/2010/3/服装.owl#衬衫 -->
<owl:Class rdf:about="#衬衫">
<owl:equivalentClass rdf:resource="#衬衣"/>
<rdfs:subClassOf rdf:resource="#类别"/>
</owl:Class>
<!-- http://www.semanticweb.org/ontologies/2010/3/服装.owl#男衬衣 -->
<owl:Class rdf:about="#男衬衣">
<rdfs:subClassOf rdf:resource="#衬衫"/>
</owl:Class>
……
(4)启动RacerPro推理机进行推论,并保存推理后的本体文件。
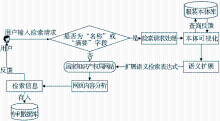
系统实现流程如图3所示:
 | 图3 基于服装领域本体的专利信息检索系统流程图 |
(1)运行系统,用户输入信息检索请求。
(2)系统判断该检索请求属于哪个字段,如果属于“名称”或“摘要”(或者同时属于两者)字段,那么对检索请求进行分词并提取关键词,组合成规范化的查询表达式,从服装领域本体库中查询相关本体文档,并可视化为本体概念语义图反馈给用户;如果不属于,转至步骤(4)。
(3)用户根据语义图,选择更能反映其检索主题的概念,这些概念被转化成系统可以识别的检索式。
(4)系统根据初始URL种子,分析中国知识产权局网站的专利信息检索页面的源文件,检索符合用户主题的专利信息,并将检索到的信息存储到MySQL数据库中。
(1)用户检索请求处理模块的实现
用户输入检索请求“男式衬衣”并提交给系统,系统判断其为“名称”字段,于是通过PHP的Snoopy类调用分词系统ICTCLAS网络版,对“男式衬衣”进行分词。
实现分词功能的代码如下:
$snoopy = new Snoopy(); //实例化Snoopy对象
$vars = array('name' => ' thisstart男式衬衣thisstop', //从FORM里分析出POST提交的参数
'App' => 'ICTCLAS2009版');
$snoopy->referer = "http://www.ictclas.org/test.html"; //来源网页地址
$snoopy->submit("http://www.ictclas.org/cgi-bin/ICTCLAS2008.cgi", $vars);
//执行POST提交
var_dump($snoopy->results); //输出返回的结果
preg_match('|<p>.*?<hr>|Uis', $snoopy->results, $match);
//通过正则匹配表达式截取出<hr>以前的代码
$html = $match[0]; //定义分词结果数组
$words = array();
$dom = str_get_html($html); //创建dom
foreach ($dom->find("font") as $font){ //读取所有的font
if($font->color =="#0000FF"){continue;} //去除分词结果中“/v”这类表示词性的代码
$word = trim(preg_replace('|<.*?>|', '', $font->innertext));//去除innertext中类似“< >”内容和空格,使$word中仅为经过切分的词语
if(!$word){ continue; } //直到取得所有的词
分词结果$words中的内容为“男式”、“衬衣”。去除停用词后为“男式”、“衬衣”,即为系统提取的关键词。
(2)本体可视化与语义扩展模块的实现
系统将提取的关键词转化为规范化的XPath查询语言,从本体类XML索引文档中查找到相应的本体类及对应的本体文档Key,并根据Key从Xindice领域本体库取出对应的本体文档,然后调用GraphViz.php文件中的Image_GraphViz.class将返回的相关本体文档可视化为本体概念语义图,如图4所示:
 | 图4 衬衣本体概念语义图 |
用户通过点击图4中“男衬衣”的领域概念从而改进检索请求,系统根据用户的操作调用Jena推理机应用程序接口,推理出“男衬衣”的上位类概念“衬衣”、“服装”和“衬衣”的等价类“衬衫”,并根据类在语义图中的层次,利用语义权重公式计算概念的语义权重。
本体可视化主要实现代码如下;
include(/服装.owl); //调用服装本体
require_once'Image/GraphViz.php'; //调用GraphViz.php文件
$graph=new Image_GraphViz(); //实例化Image_GraphViz类
$knownnode= "PREFZX服装:</服装.owl>" + "SELECT ? *" +"WHERE ? node=$words[1]";
//查找服装本体符合提取后的$words[1](衬衫)关键词的概念节点
for(i=0;i<$knownnode;$i++)
{$Xpath=" PREFZX服装:";
$Xpathend="WHERE ? node=$knownnode[$i]";
$ancestor=$Xpath. " SELECT ? Superclasses".$Xpathend; //查找“衬衫”父节点
$child=$Xpath. " SELECT ? Subclasses".$Xpathend; //查找“衬衫”子节点
$equ=$Xpath. " SELECT ? Equivalentclasses".$Xpathend; //查找“衬衫”同位类节点
$graph->addNode("Node1",$ancestor); //可视化父节点
…… //依次可视化“衬衫”及其同位类、子节点
$graph->addEdge("Node1"=>"Node2"); //可视化父节点和“衬衫”之间的边
…… //其余边同上
$graph=Image(); }
语义扩展功能的代码如下:
getUserrequest($useWord); //获取用户改进后的概念
Reasoner reasoner=new GenericRuleReasoner(Rule.parseRules(rules));
//根据推理规则创建相应的推理机
$Con=getModelByRules (服装.owl, $useWord,Superclasses);
//推理出$useWord的上位类存入数组$Con中,$useWord其余相关概念的推理类似
for(i=0;i<$Con;$i++) //以下为根据语义权重扩展“上位类”、“等价类”、“下位类”概念
{ $LC[$j]=getLayer($Con[$j]);
if($LC[$j]-a<$LC[$j]< $LC[$j]+a )
{ $SC[$j]=1/$LC[$j]; }
$class[$j]=classPropertyof($Con[$j]);}
if($SC[$j]==max($SC)) {$superClass=%$class[$j]%;}
for(i=0;i<$ SC[$i];$i++)
{ if($SC[$i]<$SCuseWord)
{$subClass="$class[$j] ";
$subClass=$subClass." or $class[$i] ";}
if($SC[$i]==$SCuseWord){ $useWord =." or %$Con[$i]% ";}}
$searchword=($subClass or $useWord) and $superClass;
(3)信息检索与存储模块的实现
根据上述形式化的用户检索请求获取专利检索结果的网页内容,通过分析网页内容获取相应的专利信息,主要实现代码如下:
$url="http://search.sipo.gov.cn/sipo/zljs/hyjs-jieguo.jsp?flag3=1&selectbase=11,22&sign=0&recshu=20&searchword=".urlencode($sql); //初始化的URL种子
$strs=file_get_contents($url); //获取网页内容
public function getopenday($openday) //取得相应的专利信息
{ $posb=strpos($openday,'公开(公告)日')+52;
//专利信息的规则,从网页中抽取“公开(公告)日”及其后面52个字符的内容
$res=substr($openday,$posb+6,10); //获取日期
$patopenday=strip_tags($res); //去除所有HTML,XML和PHP的标记
return $patopenday; //返回获取的“公开(公告)日”内容
…… } //其他字段内容的获取,原理相同
通过Insert语句将取得的专利信息存储到专利数据库Patent的patent_downinfo表中,完成用户专利数据检索。
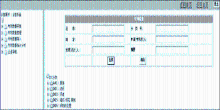
采用开发的原型系统作为实验平台,系统界面如图5所示:
 | 图5 原型系统界面 |
利用信息检索模块将中国知识产权网站的17 535条服装领域数据作为实验数据集。8组服装领域常用的检索请求作为实验检索表达式,利用语义扩展程序对8组检索式进行语义扩展。原始检索表达式和语义扩展后检索表达式的检索结果如表1所示:
| 表1 系统测试结果对比表 |
从表1可以看出,通过服装本体对用户检索请求进行语义扩展后,系统在保证检索结果准确性的同时,明显地提高了查全率,8组测试的查全率平均提高81.9%。
本文在传统专利信息检索的基础上引入专利领域本体,参考IPC和HowNet,降低了构建专利领域本体的难度。通过PHP的Snoopy类实现了专利信息检索系统与分词系统ICTCLAS网络版的有机结合,与传统用Java接口连接不同,无需下载分词系统,既节省磁盘空间,又便于分词操作。同时提出通过调用GraphViz.php文件中的Image_GraphViz.class实现本体文档可视化的方法,为方便用户根据本体概念语义图选择与需求更相关、更专业的领域概念提供解决思路。实验证明,基于领域本体的专利信息检索既能确保专利信息检索的准确性,又显著地提高了其全面性,为用户的后续工作(如专利信息可视化分析)打下良好的基础。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|