{kind=link}
{kind=link}
基于Sphinx的特色数据库全文检索系统的设计与实现
引用本文
曾湛伟. 基于Sphinx的特色数据库全文检索系统的设计与实现. 现代图书情报技术, 2010, 26(6): 78-82
Zeng Zhanwei. Design and Implementation of the Full-text Retrieval System for Characteristic Database Based on Sphinx. New Technology of Library and Information Service, 2010, 26(6): 78-82
Permissions
Zeng Zhanwei. Design and Implementation of the Full-text Retrieval System for Characteristic Database Based on Sphinx. New Technology of Library and Information Service, 2010, 26(6): 78-82
Copyright©2010, The modern information technology editorial office
This article is the open access journal literature, in the following situations are free to use: academic research and academic exchanges, scientific research and teaching, etc., but don't allow for commercial purposes.
基于Sphinx的特色数据库全文检索系统的设计与实现
摘要
针对当前自建特色数据库检索系统存在的检索效率低、检索途径单一等问题,提出基于开源全文检索引擎Sphinx对特色数据库进行全文检索的方法,详细介绍系统实现的关键技术。通过对比测试,该系统能够提高检索速度和检索质量,满足用户的检索需求。
关键词:
Sphinx; 全文检索; 特色数据库
中图分类号:TP393.07
Design and Implementation of the Full-text Retrieval System for Characteristic Database Based on Sphinx
Abstract
In view of the problems such as searching inefficient, retrieval paths singleness of the self-built characteristic database, the paper proposes the method of full-text retrieval based on Sphinx which is an open source full-text search engine,and introduces key technologies of system implementation in details. The test results show that the system can improve search speed and search quality to meet users’ needs.
Keyword:
Sphinx; Full-text retrieval; Characteristic database
1 引 言
从CALIS一期项目提出全国高校专题特色数据库建设至今已经10多年,利用自身的优势积极构建具有本校特色的数据库已经成为高校图书馆数字资源建设中不可缺少的一项工作。为了满足教学和科研的需要,湛江师范学院图书馆自2002年开始根据学校的教学特色和馆藏资源收集情况建设了多个专题特色文献数据库,这些数据库采用“后台数据库管理系统(MySQL)+前台活动页面(PHP)”的模式构建。对于站内信息的检索,采用数据库管理系统自带的查询命令:‘like “%keyword%”’等来实现检索功能,只能提供单一的检索途径,如题名、作者、关键词等。随着信息资源的不断积累,特色数据库检索系统存在以下问题:
(1)数据库的记录不断积累导致检索性能急剧下降,系统对检索查询的响应速度越来越慢;
(2)无法进行全文检索,而过于简单的检索功能无法得到全面的数据记录信息,影响了用户检索信息资源结果的精确性;
(3)无法体现检索词与检索结果的相关度,还需使用者进一步对检索结果进行仔细筛选。
因此,如何为使用者提供更加快速、精确、智能和人性化的特色数据库站内全文检索是一个亟待解决的问题。笔者利用开源、高性能的Sphinx全文检索引擎进行开发,设计了一个全文检索系统,较为成功地解决了这个问题。
2 系统设计思路
目前,国内大量的PHP网站中真正应用站内中文全文搜索的站点并不多。大部分都仅仅只能进行标题检索,并对用户的检索频率和检索权限进行严格的限制。而国外的PHP英文应用网站中,大量的站点都可以支持站内全文搜索。其中部分原因得益于后端数据库技术的发展,例如MySQL数据库从3.23.2版开始就可以支持英文的全文检索。但是由于中文语言与英文语言体系及结构方面的不同,如中文的分词是按照字典、词库的匹配和词的频度统计,或是基于句法、语法分析的分词,所以MySQL对中文全文检索的支持几乎为零[ 1]。
实现站内全文检索一般是通过使用Google等第三方网站提供的站内全文检索或自建全文检索,由于自建全文检索具有索引更新更及时、专有词库能更好地适应数据库、更有利于数据整合等优势,所以更适用于特色数据库的建设需要。
比较主流的开源全文检索引擎有:Lucene和Sphinx,由于Lucene是用Java开发的,效率相对较低,对硬件要求也更高,所以笔者选择可以和MySQL数据库完美结合的Sphinx,与Lucene相比,其开发门槛低,运行速度快,支持中文分词,实现了特色数据库的全文检索功能。
Sphinx是一个基于SQL的开源全文搜索引擎软件,可以结合MySQL和PostgreSQL进行全文搜索,其提供比数据库本身更专业的搜索功能,使得应用程序更容易实现专业化的全文检索[ 2]。
Sphinx的主要特性是:
(1)高速建立索引(可达10MB/秒,而Lucene建立索引的速度是1.8MB/秒),高性能搜索(在2GB-4GB的文本上搜索,平均0.1秒内获得结果),高扩展性(在单一CPU上,实测可对100GB的文本建立索引,单一索引可包含1亿条记录);
(2)支持基于短语和基于统计的复合结果排序机制;
(3)支持不同的搜索模式(“完全匹配”,“短语匹配”和“任一匹配”)。
国内的Coreseek项目小组在Sphinx的基础上,对Sphinx的中文支持进行增强,包括:添加基于最大匹配算法的中文分词模块,支持GB18030、UTF-8等多种编码的数据源,并针对中文的具体特点对检索结果的排序进行了优化,使得Sphinx更加适合构建中文的全文检索系统[ 3]。
3 系统设计目标
为实现特色数据库全文检索功能,提供多种检索途径,提高检索速度,同时使检索结果更加精确,基于Sphinx的全文检索系统主要设计目标如下:
(1)提供快速的全文检索服务,可以在0.x秒的时间范围内将检索结果反馈给用户;
(2)能对检索结果进行相关度排序,提高检索质量;
(3)能对检索内容进行中文分词,保证检索的精度和速度;
(4)采用“主索引+增量索引”更新方式,以使用户能够及时地检索到最新信息。
4 系统设计
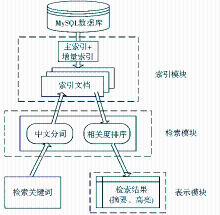
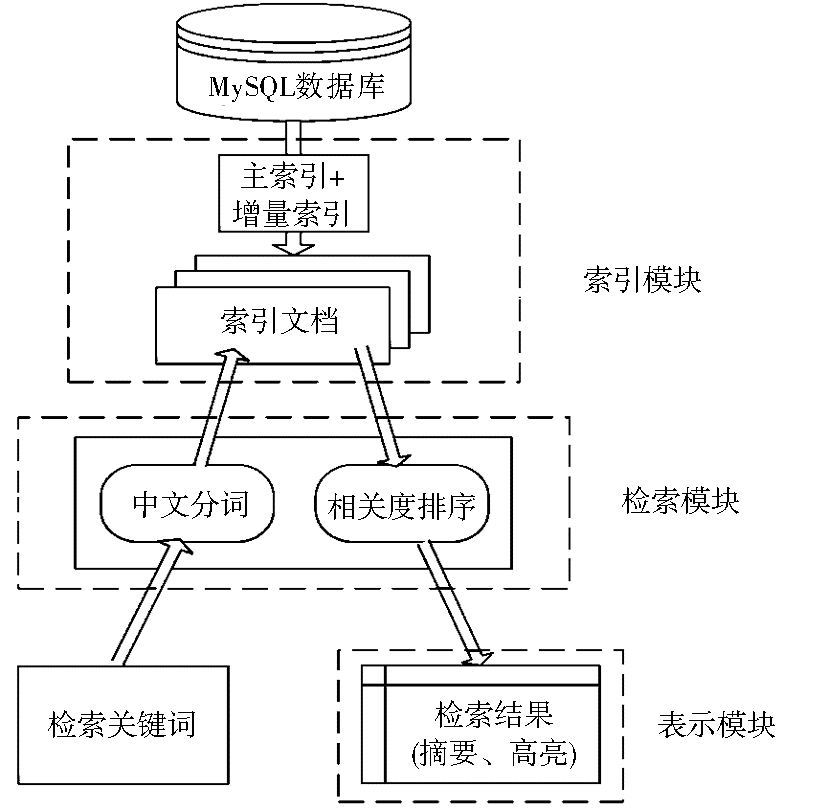
4.2 系统模块功能
(1)索引模块负责对MySQL数据库产生索引文档,并以增量索引的方式进行“近实时”的索引;
(2)检索模块用于产生检索表单,并提供用户可干预检索结果内容和排序的选项;
(3)表示模块用于显示排好序的检索结果,将检索结果相关部分生成摘要,并将检索的关键字高亮显示;
(4)中文分词负责在中文文档中正确切分中文词汇,并将结果交给检索模块;
(5)相关度排序对检索结果进行权值计算排序,为用户提供更准确的检索结果。
5 系统实现
5.1 关键技术
(1)中文分词
分词技术是全文检索系统的重点和难点。中文的全文检索和外文不一样,后者是根据空格等特殊字符来分词,而中文是根据语义来分词。国内的Coreseek项目小组专门为Sphinx 全文搜索引擎开发了中文分词包LibMMSeg[ 4]。LibMMSeg的分词算法是基于正向最大匹配和逆向最大匹配的算法,再结合中文分词词典来进行分词。对于采用词典方式的分词算法来讲,中文分词的正确率很大程度上取决于词典的词语数,而LibMMSeg自带的高频词库并不完善,因此需对LibMMSeg自带的词典进行扩展。
(2)检索结果排序
当检索结果太多时,大多数用户只浏览前面几条。如果没有相关度排序,可能造成准确的检索结果排在后面,用户不能浏览到,而排在前面的检索结果相关性却很小,无法为用户提供准确的检索结果。Sphinx的相关度排序是对词组评分和统计学评分进行权值计算得出检索结果排序[ 5]。词组评分是根据检索词与检索文档的精确匹配程度(即文档直接包含检索词),以及出现在文档中不同位置的信息给予不同的权重(例如标题、摘要等给予更高的权重)。统计学评分则基于经典的BM25函数,主要根据检索词在检索文档中的出现频率(高频导致高权重)和在整个索引文件中的出现频率(低频导致高权重)来计算权重。通过相关度排序可以为用户提供更加准确的检索结果,快速为用户找到需要的信息。
(3)检索结果高亮和全文摘要
根据用户输入的检索关键字,在检索结果中提取相应的摘要文本,然后根据设置的高亮格式,把该摘要中与关键字有关的内容以高亮的格式突出显示。这样可以使用户方便、快速地阅读到检索关键词,并通过摘要判断检索结果是否符合检索要求,无需仔细浏览全文,能为用户节约查找资料的时间。
5.2 实现过程
(1)系统安装
Sphinx系统安装过程很简单,可以从Coreseek项目组网站:http://www.coreseek.cn/products/ft_down/获取MMSeg和Coreseek Fulltext Server(已经集成了Sphinx和中文分词补丁)的源代码安装包,而且可以根据具体情况定制系统,由于tar.gz压缩包的安装过程较为简单,这里不再赘述。
(2)构建词库
LibMMSeg采用词典的方式进行分词,通常情况下,词典中的词条越多,分词的切分精度就越高。由于系统自带的高频词典只有不足11万词条,无法满足实际应用的需要,因此要对词典进行扩充。各种词条的来源可以方便地从搜狗细胞词库(http://pinyin.sogou.com/dict/)获得,然后按照LibMMSeg的词库格式添加到词典文件中。需要注意的是必须对添加的词条进行查重,避免同一词条出现多次,否则会在构造词典文件过程中提示错误。通过对词典文件进行扩充、提高词条覆盖率,使词典文件的词条数量达到了18万条,很大程度上保证了分词的准确性。
(3)创建主索引+增量索引
由于特色数据库的数据比较多,如果每次都去更新整个表的索引,系统开销将非常大,而每天需要更新的数据相对较少,因此在这种情况下可以使用“主索引+增量索引”(Main+Delta)的模式来实现“近实时”的索引更新[ 5]。
创建主索引tssjk:
vi /usr/local/csft/bin/main_index.sh #创建脚本文件main_index.sh
添加内容:
/usr/local/csft/bin/indexer --rotate tssjk
chmod +x /usr/local/csft/bin/main_index.sh #赋予主索引更新脚本可执行权限
crontab -e #设定每天凌晨定时重建主索引
添加内容:
30 3 * * * /bin/sh /usr/local/csft/bin/main_index.sh #设定每天凌晨3点30分重建一次搜索引擎的主索引
增量索引tssjk_delta的创建步骤与主索引相同,只是将crontab里的时间改为每20分钟更新一次。
为了在MySQL数据库中实现增量索引,创建辅助表sph_counter用于记录最后建立索引的记录ID,如表1所示:
| 表1 sph_counter索引ID记录表结构 |
(4)系统配置[ 5]
Sphinx安装完成后,接下来要对Sphinx进行配置,所有项目都在csft.conf文件中设定。下面是根据系统需要修改该配置文件的节选:
source tssjk //主索引名称
{
……
sql_query_pre= REPLACE INTO sph_counter SELECT 1, MAX(id) FROM tssjk
sql_query = SELECT id, title, content,sub,hits,UNIX_TIMESTAMP(date) AS date, FROM tssjk WHERE id<=( SELECT max_doc_id FROM sph_counter WHERE counter_id=1 )//指定需要索引的数据库字段,并根据sph_counter表所记录的最后索引ID号重建主索引
……
}
source delta:tssjk //增量索引名称
{
sql_query= SELECT id, title, content,sub,hits,UNIX_TIMESTAMP(date) AS date, FROM tssjk WHERE id>=( SELECT max_doc_id FROM sph_counter WHERE counter_id=1 ) //根据sph_counter表中最后记录ID对新增的数据作增量索引
}
index tssjk
{
source= tssjk //主索引名称
path= /usr/local/csft/var/data/tssjk //主索引的保存目录
charset_type= zh_cn.utf-8 //指定字符集编码类型并开启中文分词
charset_dictpath= /usr/local/csft/var/dict/ //词库uni.lib文件的目录
}
index delta:tssjk
{
source= delta
path= /usr/local /csft/var/data/delta
}
……
启动Sphinx守护进程,开始接受检索查询:
/usr/local/csft/bin/searchd
(5)系统检索代码
PHP调用Sphinx进行全文检索有两种方式:通过Sphinx官方提供的API接口;通过安装SphinxSE存储引擎,在MySQL中创建一个中介SphinxSE类型的表,再通过执行特定的SQL语句实现。由于API接口查询方式无需对MySQL数据库重新编译,调用方法简单,而且得到的检索结果比较全,因此本系统采用调用API接口的方式进行检索。主要检索代码如下:
……
include('sphinxapi.php'); //调用API接口文件
$cl = new SphinxClient(); //实例化对象
$cl->SetFieldWeights(array("title"=>10,"content"=>1)); //设置匹配字段的权重
$cl->SetArrayResult(true); //以数组的形式返回结果集
$cl->SetRankingMode(SPH_RANK_PROXIMITY_BM25); //检索结果相关度计算模式,同时使用词组评分和BM25评分
$res = $cl->Query ("$keywords", "tssjk delta"); //对主索引和增量索引同时进行检索操作
if ($res)
{
foreach ($res["matches"] as $docinfo)
{
$rs[]=$docinfo['id'];
}
return $rs;
}
Sphinx并不是直接返回检索结果内容,只是得到检索结果的ID数组,还需查询MySQL数据库才可以得到最终的结果集。
(6)检索结果摘要和高亮显示
检索结果全文摘要及关键词高亮显示有助于用户快速判断检索结果是否合适,使用BuildExcerpts函数实现该功能。
需要根据Sphinx返回的检索结果ID数组从MySQL数据库中取得检索结果的title和content字段内容,并存到数组$docs中;使用BuildExcerpts函数实现摘要和高亮显示关键词。Function BuildExcerpts($docs, $index, $words, $opts=array())[ 5]函数的使用方法如表2所示:
| 表2 BuildExcerpts函数的参数使用说明 |
系统检索界面及结果如图2所示:
 | 图2 检索结果输出界面 |
5.3 测试及性能分析
为了测试全文检索系统的性能,利用本馆自建的“中小学新课程资源数据库”作为测试站点进行比较测试,该样本站点含有3万多条数据记录。采取的方法是提交相同的查询关键字,分别使用MySQL自带的Like查询和本文构建的Sphinx全文检索,将两者返回的搜索结果进行比较分析, 其结果如表3所示:
| 表3 检索结果对比 |
由表3可见,Sphinx全文检索系统响应速度较快, 一般在0.3秒之内;而由于数据量大、服务器硬件性能等因素影响,MySQL标题检索响应时间较长, 达到了0.9秒。就检索结果来看, 由于Sphinx检索可以进行中文分词,将长查询关键字进行拆分组合检索,检索结果查全率更高,避免Like检索因无法完整匹配而产生零结果的现象。
6 结 语
通过构建基于Sphinx的特色数据库全文检索系统,无论是系统检索响应时间还是检索质量的提高都非常明显,“近实时”的“主索引+增量索引”使索引更新几乎无滞后,中文分词技术的应用提高了系统的查全率,可以为用户提供更加快速、精准的检索结果。这种通过集成Sphinx来为基于PHP+MySQL技术的网站提供站内全文检索的方法具有很好的通用性,借助该方法,不仅可以在网站构建时就直接实现站内全文检索,而且也能在不对现有网站的原有架构进行修改的情况下便捷地为网站提供一个性能优越的站内全文检索引擎。
参考文献
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|