





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
基于开源环境下的本地数字资源系统的设计与技术实现
[钱红丽1 , 马自卫2 , 李高虎3  ]
]
]
|
|


对开源环境下的本地数字资源系统进行框架和流程设计,在此基础上详细分析相关开源技术和服务实现。设计本地数字资源的统一处理模式,实现基于Lucene的本地各类资源的统一检索服务、基于Web Service与门户系统统一检索的集成服务。
This paper firstly designs the framework and process of local digital resource system based on open source. Then related open source technologies and services are analyzed. The system designs the unified local processing mode in various kinds of resources, and realizes unified search service of local resource based on Lucene and unified search integration services to portal system based on Web service.
基于开源环境下的本地数字资源系统是数字图书馆的一个子系统,它为数字图书馆提供本地数字资源,承担了本地数字资源构建的重任。基于数字资源对象文件的多样性,系统提出了以对象文件为核心的数字资源统一处理模式,实现了对象文件的文本上传与抽取、标引与审核发布、存储与索引的流程化处理。并通过开源技术实现了本地数字资源的相关服务,如基于Lucene的本地各类数字资源的统一检索服务,为数字图书馆门户的统一检索系统提供分布式本地数据源的Web Service服务,以及在此基础上的一些Web 2.0服务。在数字图书馆集成环境下,充分展现了资源和信息的价值。
数字资源主要包括两个部分的信息:原有的描述性信息,即元数据;真实存在的信息,即对象文件。元数据是用来描述相关对象文件各种信息的文本数据。电子资源存在多样性的特点,因此要求描述对象文件的元数据各不相同[ 1]。
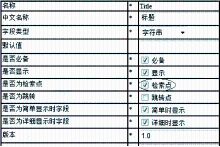
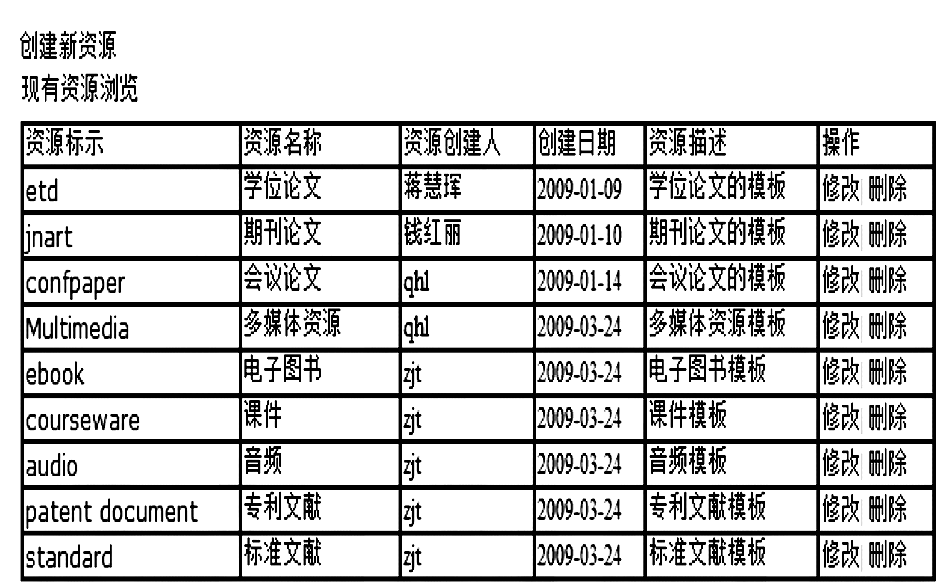
针对不同的对象文件类型,需要建立不同类型的资源模板;同时每一种对象文件所需要的元数据字段也不相同,为了实现本地资源的统一检索,建立DC[ 2]元数据与资源元数据字段的一一映射关系。在本系统的设计与实现中,提供了9种不同类型的资源模板,分别是学位论文、期刊论文、会议论文、多媒体资源、音频资源等,如图1所示:
 | 图1 不同类型的资源模板 |
为了满足各类资源的可扩展性和可维护性,系统管理员还可以通过添加、修改、删除等操作维护资源模板。
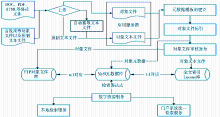
在对多种资源模板管理的基础上,本文为数字图书馆门户系统的统一检索提供本地自建的各类数字资源。数字图书馆门户系统[ 2]中的资源通常包括分布式商业数据库资源、Internet网页资源、OAI收割资源和本地自建数字资源[ 3]。设计实现本地各类资源的集成检索和获取,提供门户系统的统一检索服务、构建规范化的分布式统一检索的不同类型的对象资源是数字资源处理的核心问题。各类对象资源统一处理模式的主要流程如图2所示:
 | 图2 各类对象资源统一处理模式的主要流程 |
在各类不同资源的构建中,对象文件是系统处理的核心数据流。因此将各类对象资源统一处理模式的主要流程分为4个部分:对象文件的文本抽取、上传;对象文件的标引、审核、发布;对象文件的存储、索引;在基于本地数字资源构建的基础上,通过Lucene等技术实现了本地自建资源的集成检索服务,具体包括本地检索服务和为门户系统统一检索服务提供本地数据源。
DOC、PDF、HTML等格式的不同资源对象文件被保存到应用服务器下,同时利用自动文本文件提取技术抽取对象文件,形成对象文本文件,保存到应用服务器的相应文件下,并且对象文本文件与对象文件一一对应[ 4]。由于目前音视频的文件无法抽取出文本文件,因此采用人工预制文本文件的方式,在上传音视频对象文件的同时,上传预制的文本文件。上传后的对象文件和对象文本文件的命名规则为:采用以管理员命名的文件夹和年、月、日、时、分、秒等多级形成的时间命名规则。例如:用户qhl在2010年1月13日17点48分15秒上传了一个文件“数字图书馆.pdf”,那么在应用服务器中,文件会被保存到/qhl目录中,文件名是20100113174815.pdf。
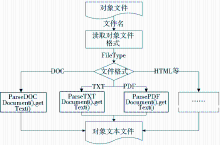
通过自动抽取过程,将DOC、PDF、HTML等格式的对象文件抽取成对象文本文件,如图3所示:
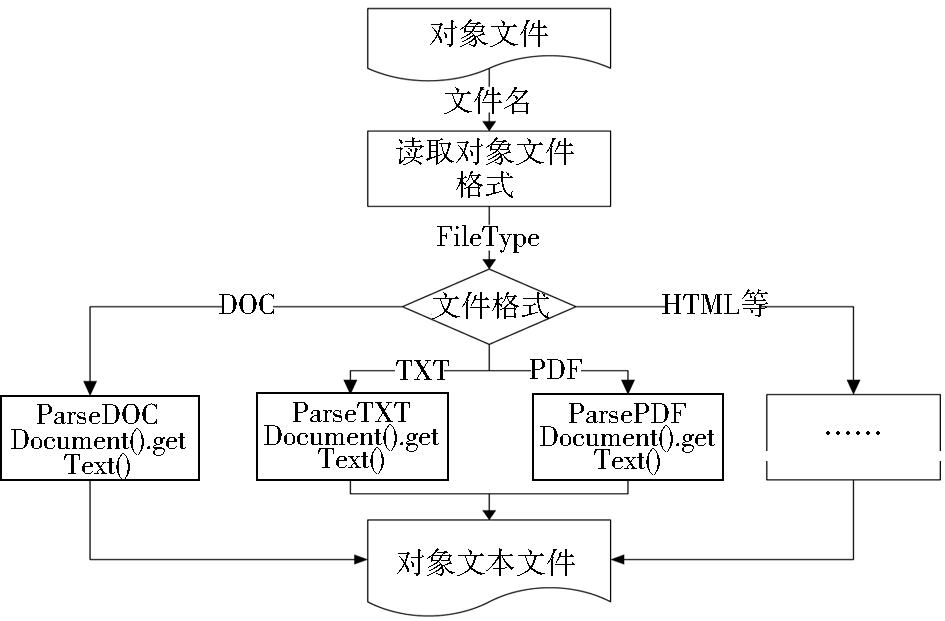 | 图3 对象文件自动抽取过程 |
对象文件根据文件名读取对象文件格式,通过相应的方法将对象文件抽取成对象文本文件。例如上传的对象文件被保存为20100113174815.pdf,通过文件名读取对象文件格式为PDF,然后通过ParsePDFDocument().getText()方法进行文本抽取,生成与对象文件相对应的对象文本文件20100113174815.pdf.txt。
自动抽取过程关键代码如下:
/**
* getText
*从各种objFile格式的文件中抽取出文本,存放到txtFile中
* @param objFile File
* @param txtFile File
*/
public void getText(File objFile, File txtFile) throws Exception {
String filetype = objFile.toString().substring(objFile.toString(). lastIndexOf('.') + 1);
String content = "";
System.out.println(objFile.toString());
System.out.println(txtFile.toString());
//对HTML文件进行解析
if (filetype.toLowerCase().equals("html")
filetype.toLowerCase().equals("htm")) {
phd = new ParseHTMLDocument();
try {
content = phd.getText(objFile);
}
catch (Exception ex) {
throw new Exception("get text using ParseHTMLDocument err:" +ex.toString());
}
}
//对DOC文件进行解析
if (filetype.toLowerCase().equals("doc")) {
pdd = new ParseDOCDocument();
try {
content = pdd.getText(objFile);
}
catch (Exception ex) {
throw new Exception("get text using ParseDOCDocument err:" + ex.toString());
}
}
//对TXT文件进行解析
if (filetype.toLowerCase().equals("txt")) {
ptd = new ParseTXTDocument();
try {
content = ptd.getText(objFile);
}
catch (Exception ex) {
throw new Exception("get text using ParseTXTDocument err:" + ex.toString());
}
}
//对PDF文件进行解析
if (filetype.toLowerCase().equals("pdf")) {
ppd = new ParsePDFDocument();
try {
content = ppd.getText(objFile);
}
catch (Exception ex) {
throw new Exception("get text using ParsePDFDocument err:" + ex.toString());
}
}
//抽取结束,生成文本文件
FileWriter fw = new FileWriter(txtFile);
BufferedWriter bw = new BufferedWriter(fw);
bw.write(content);
bw.flush(); //将数据更新至文件
fw.close(); //关闭文件流
//写文件完成
}
各类数字资源统一加工模式流程如图4所示:
 | 图4 各类数字资源统一加工模式流程图 |
管理员选择相应的模板,根据系统中已经建立好的模板元数据字段进行加工标引,标引完成后,确认提交,文件进入待审核阶段。用户进入审核页面,对待审核的记录进行审核,审核通过后,该记录进入发布阶段。同时,审核发布成功的记录也会把相应的对象文件放到FTP服务器中,这样就可以从FTP服务器中浏览或下载对象文件到本地。
在标引阶段,也可以暂时保存标引的内容,以便下次继续标引,当确认标引已完成后,该条记录则进入待审核阶段。同样,在审核阶段,如果审核未通过,将会重新回到标引状态,由用户重新标引完成后,再次进入待审状态;审核通过,才会进行信息的发布。
在标引、审核、发布过程中,为了监控系统的工作流程,设置对象文件所处的状态字符以表示加工对象文件所处的阶段,如表1所示:
| 表1 记录状态表 |
审核、发布完毕,对象文件将会被上传到FTP对象文件库,而对象文本文件则上传到Lucene库,建立全文索引。
在本地数字资源构建中,发布的对象文本文件将会利用Lucene全文索引技术。系统利用中文分词将对象文件中的文本部分进行全文索引,然后将全文索引记录和元数据记录、对象文件关联起来,通过对全文索引的检索来实现系统对对象文件内容本身的检索。
Lucene 作为一个用Java语言编写的全文索引/搜索引擎工具包,可以方便地嵌入到各种应用中,实现针对应用的全文索引/检索功能。因为Lucene并非一个完整的应用,所以要利用它实现全文检索,还需要进行二次开发。
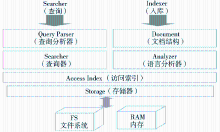
Lucene功能强大,主要包括两部分:文本内容经切词后索引入库;根据查询条件返回结果。两大功能的逻辑如图5所示:
 | 图5 Lucene逻辑功能接口图 |
Lucene的主要功能通过其中的三个接口实现,分别为:
(1)IndexWriter接口:实现入库逻辑,加入文档并全文抽取索引;
(2)Searcher接口:实现查询逻辑,检索全文索引数据库;
(3)Hit接口:从Searcher接口的返回值中读取检索命中的结果集。
通过DC元数据和Lucene全文索引技术,将不同类型资源的字段与DC元数据字段一一对应,保证统一检索查询数据的一致性。
DC元数据中的题名与学位论文中的Title建立映射,创建者与Creator建立映射关系等,如图6所示:
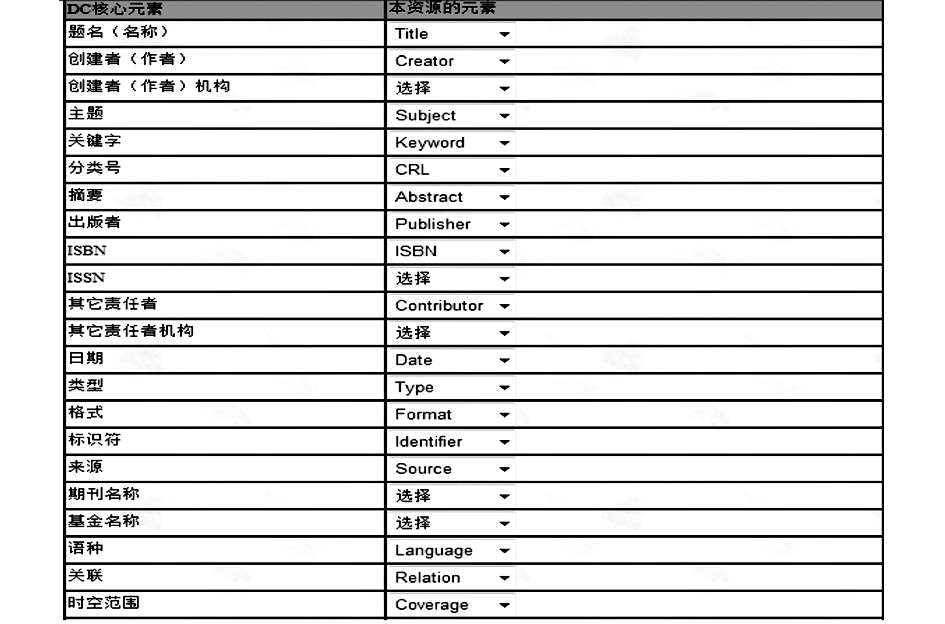 | 图6 DC元数据与本地资源元数据字段的映射关系 |
被上传到FTP的对象文件,其命名规则为:recordID.[T|P].[doc|pdf|ppt|mp3……],而且存放目录由5级构成:资源类型/年/月/日/recordID。如对象文件69.T.doc的存放目录为/edt/2010/4/20/69/69.T.doc。
系统把一条记录的所有元数据字段内容和对象数据对应的文本文件内容进行合并和中文分词,然后存放到全文索引库中。全文索引库的关键字段为记录控制号recordID,该号与元数据记录中的记录控制号recordID是一个含义。这样就实现了对象全文和元数据的统一的全文检索,对传统的数据库字段检索进行了提升。核心代码如下:
//进行全文索引
IndexResource ir = new IndexResource();//初始化对象
ir.makeIndex(lucenedbpath, record_id, filepath);
document = new Document();
//索引recordID
document.add(Field.Keyword("recordid",String.valueOf(trecord.getRecordID())));
//索引ResourceName
document.add(Field.Keyword("resourcename",trecord.getResourceName().toLowerCase()));
//索引与DC对应的15个字段
document.add(Field.Text("Title",GetDCValue.getDCValue(trecord.getResourceName(),recordid, "DC_Title")));
//索引Title字段
document.add(Field.Text("Creator",GetDCValue.getDCValue(trecord.getResourceName(),recordid, "DC_Creator")));
//索引Creator字段
……//索引其他字段
索引完成后,不仅可以利用字段检索,而且可以利用全文进行检索。
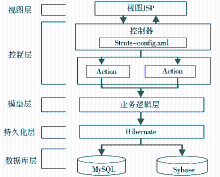
系统采用Struts+Hibernate的架构进行设计,Struts 是一个基于模型-视图 -控制器 (Model-View-Controller,MVC) 模式的开源框架。MVC是用来控制变化的一种设计模式,它减弱了业务逻辑接口和数据接口之间的耦合。开发人员利用其进行开发时不用再编码实现全套MVC模式,极大地节省了时间。系统体系结构如图7所示:
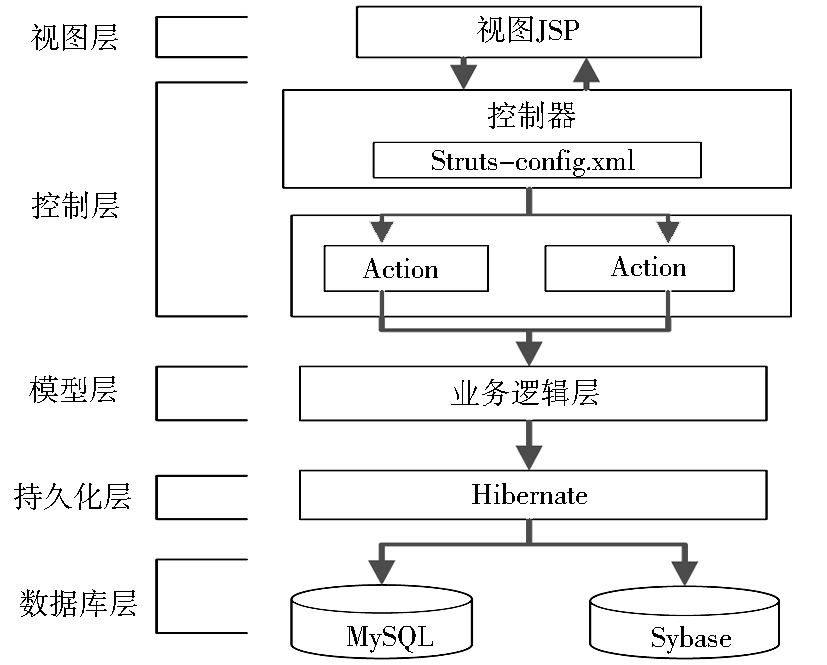 | 图7 系统体系结构图 |
(1)视图层是面向用户的界面,是用户与系统之间交互的媒介,系统中所有用于进行信息展示和获取的输入都由视图层来实现。如模板管理界面、标引界面、审核界面、发布界面、检索界面、显示检索结果界面、对象文件浏览与下载界面都在视图层。
(2)控制层主要是Struts通过一个Action Servlet,把用户的请求根据配置文件Struts-config.xml发送到相应的Action对象,然后在Action对象中调用相应的模型层来实现具体功能。
(3)模型层接收来自控制层的请求,提供控制层所需的业务逻辑,负责与持久化层之间通信,是连接控制层和持久化层的桥梁。该层主要包括业务对象和业务服务。业务对象是业务领域内的实体,如用户、检索词、资源元数据等。业务对象除了封装数据之外,还有处理这些数据的方法。业务服务是业务领域内的业务逻辑,比如用户的认证、资源的管理、数据的提交以及加工标引、审核、发布等。该层主要通过面向对象的编程和面向接口的编程等实现。
(4)持久化层采用Hibernate技术实现,即对于数据库的映射采用Hibernate 框架。该层主要提供业务数据的保存、更新、删除、查找等服务,为业务逻辑层提供接口。
(5)数据库层用来存储各种数据信息,比如用户信息、检索词信息、检索结果的保存、资源的元数据信息等。数据库系统包括Sybase数据库、MySQL数据库等。
为了满足简单字段、详细字段、检索点等的功能需要,在资源模板中给出了相应属性的选定,增加了系统的灵活性和可用性,如图8所示:
 | 图8 定义的检索点 |
为了保证数据库中的元数据、FTP对象数据和Lucene库索引数据的一致性,系统采用统一的recordID。在标引完毕提交过程中,被定义为检索点的字段信息将被保存到数据库中,生成唯一的recordID号,为Lucene库、FTP服务器与MySQL建立相应的连接服务。
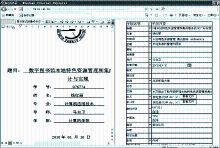
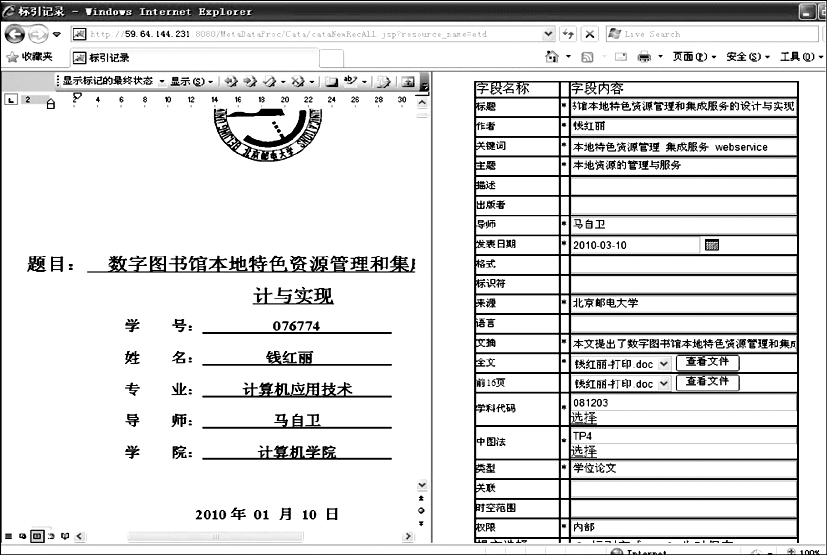
以“学位论文”为例,标引界面如图9所示:
标引区域为双屏,左侧用来显示用户的对象文件,右侧用来显示该资源的标引信息,如作者、标题等。用户在标引对象文件时,需要通过点击“查看文件”按钮,选择相应的对象文件或者文本文件,该对象文件或者文本文件将会显示在左侧的对象区域,方便用户编辑资源信息。
标引完毕后,将提交并等待审核发布。审核发布至关重要,主要目的是发现标引问题并提出解决措施,例如标引缺项、标引有误等。如果没有问题,审核发布后,对象文件将会被上传到FTP对象文件库,而对象文本文件则上传到Lucene库,建立全文索引。
本地资源检索服务支持两种检索方式:对于单种资源的字段简单检索和能够同时检索所有资源的高级全文检索。
(1)简单检索是对单个资源的元数据中定义为检索点的字段内容进行数据库Like模糊检索。
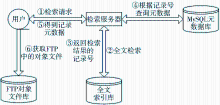
(2)高级检索是对Lucene库的检索,其全文检索流程如图10所示:
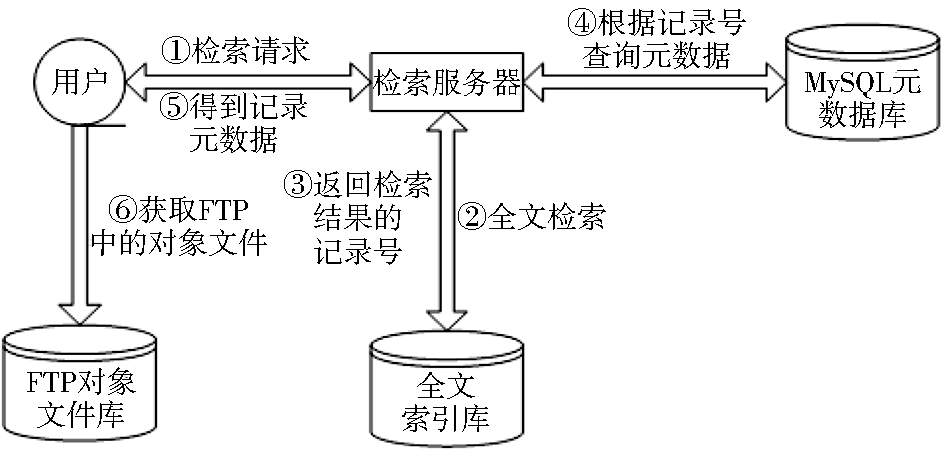 | 图10 全文检索流程示意图 |
①用户输入检索词,提交到检索服务器。
②服务器接收到检索条件后,将检索条件进行中文分词,发送到全文索引库中进行检索与匹配。
③全文索引库根据自己的索引内容查找符合条件的记录,并把记录号返回给服务器。
④服务器根据记录号到关系数据库中查找该记录的元数据信息。
⑤服务器把查找到的元数据信息返回给用户,检索结束。
⑥元数据信息中包含对象文件的地址信息。如果用户需要下载查看对象文件,可以根据地址信息到FTP服务器中下载全文文件。
全文检索方式是对数据库检索的一个扩展,充分实现了关系数据库和文件数据库的整合检索。需要注意的是:数据库的记录号=FTP服务器的记录号。
以数字图书馆为条件在全文中搜索,检索界面如图11所示:
由于检索结果信息数据量庞大,因此选取其中的两条进行展示,如图12所示:
 | 图12 全文检索结果集(节选) |
本系统为数字图书馆门户集成系统中的统一检索系统提供规范化的本地数字资源。集成统一检索服务是基于Web Service技术架构的检索服务[ 5]。作为数字图书馆门户系统4种数据源之一的服务端,它为数字图书馆门户集成系统统一检索提供检索服务。
Web Service 服务端的实现采用XFire框架[ 6],XFire是与Axis 2并列的新一代Web Service框架,通过提供简单的API支持Web Service各项标准协议,以方便快速地开发Web Service应用。
XFire 框架中有两种方式将简单的Java对象 POJO(Plain Ordinary Java Objects)发布成 Web 服务:
(1)直接使用 Web 服务接口和 Web 服务实现类POJO来发布;
(2)基于 JSR181 标准和注释技术将被注释的 POJO 发布成 Web 服务。
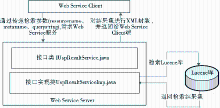
本系统数字资源服务端Web Service设计采用第一种方式,如图13所示:
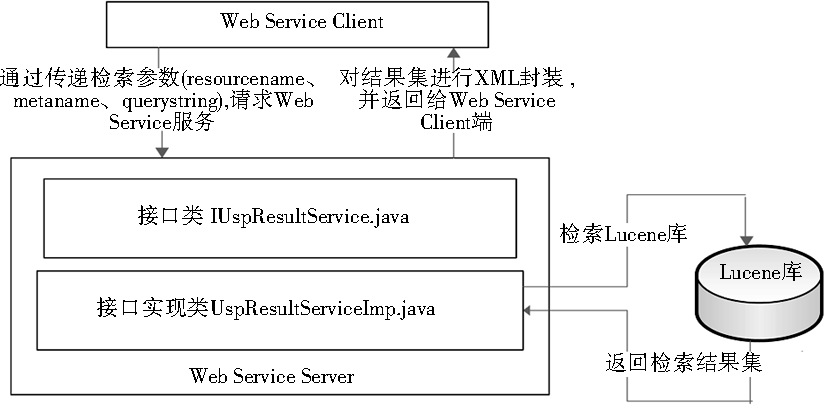 | 图13 Web Service 服务设计示意图 |
Web Service服务端由接口IUspResultService.java和其对应的实现类UspResultServiceImp.java组成。当Client端通过传递检索参数(resourcename、metaname、querystring)触发Web Service端的一次检索,检索由实现类UspResultServiceImp.java执行,其检索机制是对本地Lucene库的一次检索,并把符合检索条件的检索结果以结果集的形式返回。实现类对结果集进行XML封装并返回给客户端,完成Web Service检索服务的执行过程。
以resourcename=etd,metaname=title,querystring=java为例,返回给Web Service客户端的XML[ 7]形式的结果集如图14所示:
 | 图14 Web Service接口提供的XML形式的结果集 |
以统一检索客户端为例,统一检索客户端可以对这些XML[ 8]形式的数据进行网页分析,生成符合其规范的新的检索资源。也可以从统一检索系统检索本地自建数字资源,通过Web Service接口调用,查看本地数字资源的检索结果,如图15所示:
 | 图15 本地数字资源与统一检索系统集成界面 |
本地数字资源系统还实现了基于Lucene检索的特色服务,如RSS订阅服务、“我的检索历史保存”服务、邮件推送服务等,体现了Web 2.0技术在数字图书馆中的应用。
数字图书馆建设过程中的核心问题是本地数字资源的构建问题,在Web环境下,不仅需要生成描述各种不同类型数字资源的元数据,还需要思考对象文件的存储与传送的问题。从这些问题出发,本文采用开源开发环境和开源技术,设计实现了各类数字资源的统一处理模式,并对相关开源技术和二次开发技术进行分析并给出关键代码,最终实现了以对象文件为核心的统一处理模式和对象文件的文本抽取与上传、标引与审核发布、存储与索引的流程化处理。在数字资
源构建的基础上,实现了数字资源的Web服务,体现了在开源和集成环境下,本地自建数字资源的重要性和实用性,对数字图书馆资源建设有一定的参考意义。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|