{kind=link}
{kind=link}
NSTL文献检索系统中相关文献推荐功能的设计及实现
[张志平, 李琳娜 ]
]
]
|
|


针对国家科技图书文献中心文献检索系统,提出关于二次文献的文献相似度计算方法,设计并实现实时相关文献推荐子系统。最后,从理论上提出对推荐结果进行定量评价的指标,并进行效果评测,验证所设计的相关文献推荐子系统能进一步提高NSTL文献检索系统的服务质量。
This paper proposes a new method for calculating similarity between secondary documents of National Science and Technology Library(NSTL), subsequently develops and implements a subsystem of real-time related documents recommendation. At last, a measurement which can theoretically evaluate the quality of recommendation results is presented. And the experiment results demonstrate that the system can improve the service quality of document retrieval system of NSTL.
利用有效的数字资源开展有效的信息服务是数字图书馆建设的关键。国家科技图书文献中心(National Science and Technology Library, NSTL)作为我国权威的文献信息服务提供者,目前其文献检索系统所能提供的主要服务是基于关键词的检索,即提供一定的检索规则,让用户进行基于关键词匹配的检索。这种检索方式具有两个缺点:检索结果通常包含几百篇、甚至上千篇符合检索条件的文献,而用户的浏览能力是有限的,其往往仅浏览前几十篇文献,这有可能失去获得自己真正所需要的文献的机会;不同的用户使用相同的检索策略获得的检索结果是一样的,而使用相同检索策略的用户有可能具有不同的文献需求服务。
相关文献推荐是指用户在详细浏览某篇文献的标题、摘要等信息时,系统向用户推荐与该文献具有高度相似性的一些其他文献。当前已有一些数字图书馆,如ACS、谷歌数字图书馆、斯坦福大学数字图书馆、中国知网等,实现了相关文献推荐功能,所采用的主要技术分为以下4种[ 1, 2, 3, 4, 5]:
(1)系统预先离线地计算与某篇文献最相似的前n篇文献,然后将这n篇文献的标识号所构成的集合作为该篇文献的“相关文献”字段的值,当用户浏览检索结果中的该篇文献时,系统实时提取“相关文献”字段的值,然后根据文献标识号获取对应的文献进行相关文献推荐。该技术虽然具有较好的效率,但是离线计算量非常大;同时,由于在比较大的文献空间中计算文献之间的相关性,准确率会比较低;另外,其难以解决新增文献的相关文献推荐问题。
(2)系统根据文献的关键词进行相关文献推荐。当用户浏览检索结果中的某篇文献时,系统实时地提取与该篇文献具有相同关键词的文献,从而进行相关文献推荐。显然,该技术的推荐准确率较低。
(3)个性化推荐技术。数字图书馆中的个性化推荐技术根据用户检索历史及个人信息,构建用户偏好模型,并根据用户兴趣偏好主动为用户进行个性化推荐。这是近几年来数字图书馆实现相关文献推荐功能所采用的主要技术。NSTL下一步的工作就是为文献检索系统增加个性化推荐功能。
(4)关联规则挖掘技术。文献[5]考虑到传统的关联规则挖掘算法应用到相关文献推荐中有很大的局限性,提出了基于加权关联规则挖掘的相关文献推荐技术。但其需要用到论文引文信息,这对当前数字图书馆的现状来说不具有通用性,并且该文献中也没有给出如何确定最小支持度和最小置信度的方法。
本文针对NSTL文献检索系统,提出了一个针对二次文献的文献相似度计算方法,设计并实现了一个实时的相关文献推荐子系统。当用户浏览检索结果中的第i篇文献的摘要、关键词等详细信息时,实时计算该文献与检索结果列表中位于该文献后的文献之间的相似度,选择与其相似度最高的k篇文献作为相关文献进行推荐。由于该系统在用户基于关键词的检索结果空间下计算文献之间的相关性,检索结果空间相对于整个文献空间来说非常小,所以该系统的效率及准确率都比较高;同时,由于整个推荐过程是实时计算并进行推荐,可以较好地适应文献数据库动态变化的需求。
当前对文献相似度计算的研究主要集中在基于向量空间模型的方法。由于本文的相关文献推荐技术主要应用于NSTL系统,考虑到其所具有的文献大部分都是二次文献,没有可以直接利用的全文信息,故在进行文献之间相似度计算时,只利用文献的标题、关键词、摘要这三方面的信息。由于这三方面信息从不同层面、不同程度反映了文献的内容信息,在进行文献之间相似度计算时,分别计算标题、关键词、摘要之间的相似度,然后将这三个相似度值进行线性加权。
文献的标题简要概括了该篇文献所要介绍的内容,可以将其视为一个句子,从而将标题间相似度问题转化为句子间相似度问题。此处借鉴文献[6]所讨论的句子间相似度计算方法,但是由于文献标题的语法结构通常较为简单,此处的相似度计算只考虑uni-gram和bi-gram信息,具体如下:
将每个文献标题用两个向量(V1, V2)表示,其中,V1=(d11, d12, …, 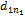
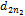
两个标题间的相似度由这两个标题的两个向量间分别的夹角余弦值决定,即TitleSim(Title1, Title2)=α×Cos(V11, V21)+(1-α)×Cos(V12, V22)。其中,α是调节因子,其取值范围为0<α<1。
2.2 关键词相似度
文献的关键词表示该文献所涉及的研究领域及所采用的关键技术,两篇文献相同的关键词个数也在一定程度上表明了其相似程度。受文献[7]的启发,用SameKeywords(Keywords1, Keywords2)表示两篇文献相同关键词的个数,Length(Keywords)表示某文献所具有的关键词个数,两篇文献的关键词相似度公式如下:
KeywordsSim(Keywords1,Keywords2)
= 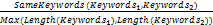
在计算文献摘要之间的相似度时,采用经典的TF×IDF方法[ 8]将每篇文献的摘要向量化,然后用夹角余弦计算两文献摘要之间的相似度,用AbstractSim(Abstract1, Abstract2)表示。
文献间相似度反映了两篇文献之间的相似程度,是一个0至1之间的数值,0表示两篇文献完全不相似,1表示两篇文献完全相似,相似度值越大表示两篇文献间的相似程度越高。文献d1与文献d2之间的相似度定义为:
Sim(d1, d2)=λ1TitleSim(Title1, Title2)+λ2KeywordsSim(Keywords1, Keywords2)+ λ3AbstractSim(Abstract1, Abstract2)
其中,λ1、λ2、λ3的取值范围为(0, 1),且λ1+λ2+λ3=1。
本文采用线性回归模型的方法解决文献标题之间相似度计算中的参数取值及文献之间相似度计算中的参数取值。线性回归模型试图用一条直线来解释自变量x和因变量y之间的关系[ 6],其一般形式为:
y=b0+ 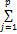
其中e表示残差,它的均值是0;b0是回归参数。选取100篇文献,相关领域专家给出这些文献之间的相似度,然后基于最小二乘法用MATLAB进行曲线拟合,从而确定这些参数的取值。本系统中的参数取值分别为:b0=0,α=0.679,λ1=0.427,λ2=0.260,λ3=0.313。
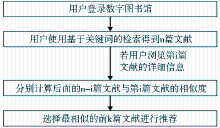
相关文献推荐子系统的流程如图1所示:
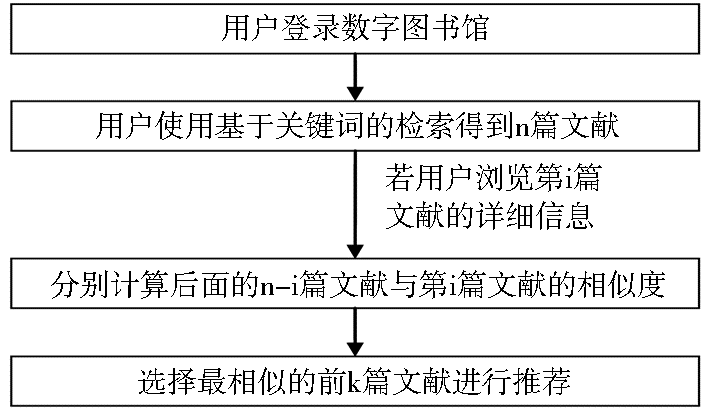 | 图1 相关文献推荐子系统 |
在图1所示的相关文献推荐子系统中,k是系统推荐的文献数目并且其值小于或等于n-i,是系统预先设置的参数。
由于NSTL文献检索系统返回的结果列表初步展示的只是文献的标题信息,当用户根据标题判断自己对于某篇文献有可能感兴趣时,可点击相应的链接进一步浏览文献的摘要、关键词、作者等详细信息。当用户浏览检索结果中第i篇文献的详细信息时,假设用户已对前i-1篇文献是否感兴趣做出了判断。当用户使用基于关键词的检索时,系统得到检索结果后首先将结果中的所有文献位于结果列表的序号及对应的文献标识传递给推荐系统,这样当用户详细浏览第i篇文献的信息时,只需将序号i传递给推荐系统,系统计算得到前k篇最相似的文献后,可以直接将对应的文献标识传递给数字图书馆检索系统,提取对应的文献信息进行推荐,从而提高推荐子系统的效率。推荐结果的具体展示方式为:在展示文献摘要、关键词等详细信息的页面下方显示这k篇文献的标题信息及相应详细信息的链接。
该子系统的具体实现语言为Java,开发平台为Eclipse 3.2,系统运行平台为Unix操作系统。前期为了试用及测试该系统,将其放置在一个独立的平台上运行。系统处理文献的效率为每秒100篇文献,所以目前该子系统的召回率不是特别理想。但考虑到其独立运行时与NSTL文献检索系统之间的数据通信所需的时间消耗,将其嵌入到NSTL文献检索系统后效率将有较大的提高;另外,在进行文献相似度计算时,由于分别计算标题、摘要、关键词三部分的相似度值,可将这三部分的计算设计为并行计算,提高系统效率。这两点都可以进一步提高子系统的召回率。目前,即将完成系统的嵌入工作,就目前NSTL三期的性能来看,理论上没有问题。
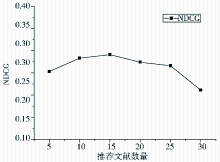
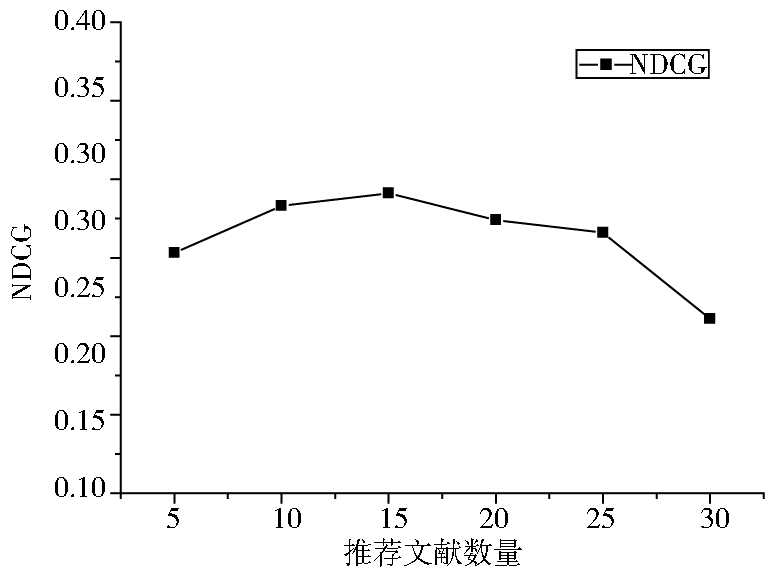
目前,还不存在对相关文献推荐结果进行评价的统一数据集及评价方式。本文借鉴信息抽取领域的一个度量指标NDCG[ 9, 10](Normalized Discounted Cumulative Gain)作为相关文献推荐结果的度量指标。
关于NDCG的详细定义请参阅文献[10],这里只做简略介绍。为了计算J个被推荐项的NDCG值,需要首先计算其平均DCG值,定义如下:
DCG= 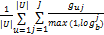
其中,U是参与评价的用户集合,|U|表示U中的用户数;J是被推荐的文献个数,j是某篇被推荐文献位于推荐列表中的位置,其取值为自然数;b是对数基数,典型的取值范围为[2, 10]之间的整数,最常用的取值为2,本文中b取值为2;guj表示用户u从被推荐的第j篇文献所获得的增益。NDCG的定义为:
NDCG= 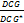
其中,DCG*是理论上最好的推荐结果的DCG值。在本文的实验中,所设置的评价尺度为2,若用户u认为某篇被推荐的文献确实是相关文献,则对其的打分为2;若用户u认为某篇被推荐的文献与需要被推荐的文献的相关性不大,则对其的打分为1,否则0。
虽然,NDCG主要用来对推荐结果列表中推荐项的先后顺序进行评测,即较好的推荐结果列表排序将会有较高的NDCG值,但考虑到所设计的相关文献推荐子系统主要由文献间相似度来确定相关文献的排列顺序,与需要被推荐的文献的相似度高的文献将位于推荐结果列表的前面,所以也可以用这个值来评价所设计的相关文献推荐子系统的性能。
本文针对国家科技图书文献中心文献检索系统,提出了一个针对二次文献的文献相似度计算方法,设计并实现了一个实时相关文献推荐子系统,最后借鉴信息抽取领域的评价指标对推荐结果进行了定量评价。针对科技文献而言,内容上相关的文献间通常具有相同的关键词,因此,文献相似度的计算虽然是在基于关键词的检索结果范围内,但推荐结果仍能提高国家科技图书文献中心文献检索系统的服务质量。实验评价虽然是定量评价,但仍需要人工的参与,由于用户自身的特点,评价结果仍然具有一定的误差,下一步的研究工作将在评价结果中引入用户影响因子。
| [1] |
|
| [2] |
|
| [3] |
|
| [4] |
|
| [5] |
|
| [6] |
|
| [7] |
|
| [8] |
|
| [9] |
|
| [10] |
|